融合邻居选择策略和信任关系的兴趣点推荐*
2020-03-04刘子恺
刘 辉,曾 斌,刘子恺
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065; 3.重庆信科设计有限公司,重庆 401121;4.重庆邮电大学计算机科学与技术学院,重庆 400065)
1 引言
近年来,随着互联网技术的不断进步,人们通过智能终端获取位置信息越来越方便和准确,促使基于位置的社交网络LBSN(Location-Based Social Network)的推荐趋于火热,如国外的Foursquare、Gowalla和Yelp挑战赛等。LBSN与传统网络相比增加了地理位置信息,用户可以对当前访问的兴趣点POI(Point-Of-Interest)进行签到,且用户可以与好友分享自己的签到信息。在这个背景下,推荐系统成为了一种可选择的挖掘方法,从LBSN到Twitter等传统网络越来越频繁地使用位置推荐功能。
社交网络出现后,越来越多的推荐算法利用社交网络提供的丰富信息来改进传统推荐算法的性能,特别是解决传统协同过滤方法中的冷启动问题。文献[1]提出基于信任关系的推荐方法CoSRA+T(CoSRA Trust),该方法是对基于用户相似性的推荐方法CoSRA 的改进,将用户的信任关系融入推荐系统中,能提高推荐的精度。文献[2]提出基于用户偏好和背景嵌入的深度神经网络架构,学习用户和兴趣点相关的各种背景环境来预测用户对候选兴趣点的喜好程度。虽然现有的推荐方法结合了信任关系,但并没有针对用户社会地位进行有效的分类,因此在推荐系统中,针对不同的领域,考虑用户在不同领域的社会地位可以更加准确地反映实际的推荐过程,从而有效地改进推荐算法的性能。
综上所述,本文提出了一种融合用户相似性、地理位置和信任关系UGT(User-Geography-Trust)的混合推荐算法,综合考虑了多种情境因素。本文的贡献主要为:(1)对用户签到信息添加时间权重,充分利用用户的签到信息,提升推荐精度;(2)提出了一种基于朋友的邻居选择策略,筛选出目标用户的邻居用户,以此来提高对目标用户的偏好预测精度;(3)分析了用户的属性,给出了社会地位和信任度的计算方法。将信任关系融合到推荐系统中,有助于提升推荐精度,避免不良用户的恶意推荐。实验结果表明,本文算法在推荐精度上相较传统的基于用户相似性的协同过滤算法有很大的提高,并且保证了推荐结果的可信度,能够有效地抵御恶意推荐。
2 相关工作
本节主要介绍3类兴趣点推荐算法,包括基于协同过滤的推荐、基于地理位置的推荐和基于信任关系的推荐。
(1) 基于协同过滤的推荐。协同过滤推荐算法是由Goldberg等人[3]在1992年提出的,该算法是利用用户的历史活动记录(一般为用户-签到矩阵)来进行推荐,不需要分析用户概要信息和兴趣点描述信息,是目前应用最广泛的推荐技术,可分为基于模型的推荐和基于记忆的推荐。Lee等人[4]认为用户签到受个人喜好、好友影响和兴趣点远近距离3个方面影响,综合用户偏好、好友和地理信息提出混合推荐算法,明显提高了推荐结果的精度。随着云计算时代的到来,朱夏等人[5]提出了一种适用于云计算分布式处理环境的基于协同过滤的个性化推荐机制RAC。Wu等人[6]使用马尔科夫链的局部随机游走算法,提出了一种融合时间、空间和社会关系的朋友推荐模型。上述方法均需要用到用户的历史活动记录,由于用户-兴趣点签到矩阵数据极度稀疏,导致协同过滤算法的推荐精度并不高。
(2) 基于地理位置的推荐。基于地理位置的推荐是利用用户大量签到位置轨迹数据和社交活动数据进行推荐,现有的大多数关于位置推荐的研究都基于协同过滤和用户地理位置偏好两者之间进行组合。Pham等人[7]考虑兴趣点之间的空间影响,提出了一种外地区域推荐算法来衡量一个区域的吸引力。考虑到用户签到的空间影响,可以缩小搜索空间,提高推荐系统的性能。Lian等人[8]提出一种加权矩阵分解模型,利用用户的活动区域向量和兴趣点的影响区域向量来对模型中用户和兴趣点的潜在因素进行增广;Kurashima等人[9]提出了一种基于地理主题模型的假设,即如果一个兴趣点离用户当前签到的地点或其访问的地点更近,那么用户访问该兴趣点的可能性更大;为了模拟不同用户的LBSN签到的中心数量,Ye等人[10]利用简单的线性组合,将基于邻居的协同过滤与基于幂率的模型相结合,来实现用户的地理位置建模。这些方法的缺点是都无法很好地处理用户冷启动问题。
(3)基于信任关系的推荐。基于信任关系的推荐是由Massa首次提出的,之后有很多基于信任关系的推荐算法问世,这些算法可大致分为2类:一类是基于隐性信任的算法,另一类是基于显性信任的算法。Chen等人[11]认为用户对项目的偏好会随着时间的推移发生变化,提出了一种基于矩阵分解的TTSMF(Trust and Time Social Matrix Factorization)算法,将时间序列信息、用户信任关系和分数矩阵相结合,推荐精度高于现有的协同过滤推荐,特别是当目标用户的项目得分较低时,甚至是没有得分时,该算法也能取得较好的推荐效果。Cho等人[12]提出了一种基于概率矩阵分解的SoReg算法,通过分解信任关系矩阵和评分矩阵,生成了低维的潜在用户向量、特征向量和项目向量;然后利用这3个向量进行评分预测;最后结合用户评分和用户之间的信任关系来进行推荐。
总体来说,现有的研究工作对用户的偏好捕获考虑不够充分,同时忽略了信任关系和签到频次及签到时间对兴趣点推荐的影响,导致算法推荐精度较低。因此,本文提出了一种融合用户相似性、地理位置和信任关系的混合推荐算法,线性组合后得到推荐结果,能更好地提高推荐精度。
3 问题的描述
典型的LBSN包含了用户集和兴趣点集2种实体集合,如图1所示。为了便于研究,令U=(u1,u2,…,un)表示用户集,L=(l1,l2,…,lm)表示兴趣点集,其中n和m分别表示用户数和兴趣点数。除了以上2种实体集合,用户历史签到信息对兴趣点推荐尤为重要,用户的签到记录组成用户-兴趣点签到频次矩阵F=[fu,l]n×m,签到频次矩阵中的元素fu,l表示用户u在兴趣点l上的签到频次。相较于使用二值来表示用户是否访问一个兴趣点,用户的签到频次直观地反映了用户对兴趣点的偏好程度,在一个兴趣点签到的次数越多,用户可能更加偏好该兴趣点。
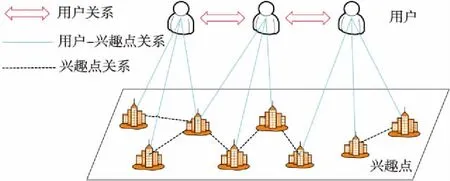
Figure 1 Structure of LBSN图1 LBSN结构
4 用户偏好建模
4.1 签到矩阵处理
考虑到用户签到数据的时效性,采用可控变量的指数函数作为历史签到时间权重。与用户所有时间的签到信息相比,最近的数据更能准确地反映当前用户的签到频次,而时间间隔较近的签到数据对于推荐贡献更大。为降低时间复杂性,设置一个时间间隔阈值H,当用户的签到间隔大于或等于阈值H时,对签到数据进行处理。则更新后的用户签到矩阵FT为:
(1)
其中,ftu,l为用户u在兴趣点l上签到的频次,|tnow-tu,l|表示用户u对兴趣点l签到时间与当前时间的间隔。λ为训练得出的权重。
4.2 基于用户的协同过滤推荐
传统构建推荐系统的方法有基于内容CB(Content-Based)的推荐方法和协同过滤CF(Collaborative Filtering)推荐方法。CB是指每个用户在给定的一组环境下表现出来特定的行为,而这种行为在类似的环境下会重复出现;而CF是在特定的群体中,人们在相似的环境下表现也类似。在CB中,用户的行为是通过用户过去的行为来进行预测的;而在CF中,用户的行为是通过其他志同道合的人的行为来预测的。本文采用的是基于用户的协同过滤推荐。为了能在CF方法中获得推荐,需要求出目标用户在候选兴趣点上签到的概率。经典的基于用户的协同过滤模型如式(2)所示:
(2)
为了在预测时正确区分邻居的选择和他们意见的权重,对式(2)进行了如下修正,则可得出用户u在兴趣点l上签到的概率P(u,l)为:
(3)
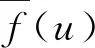
(4)
首先要做的是筛选出目标用户的邻居集合;而邻居的选择需要确定其他用户与目标用户的相似度。该过程涉及到这个数据集中的所有用户,因为任何与目标用户相似的用户都可能参与偏好评估,然而邻居的选择会受到LBSN中的几个因素影响。
在此背景下,本文采用一种基于朋友的邻居选择策略,如图2所示。在这个策略中,使用系统中用户自己创建的社交网络信息,可以对目标用户的签到频次做出估计的邻居仅限于与目标用户有社交关系的用户,这些关系可以是直接朋友关系和间接朋友关系;根据给定的策略选择邻居集后,再用式(3)评估目标用户在候选兴趣点上的签到概率。该策略通过探索以目标用户为中心的社交网络,搜索k个用户,预测目标用户的偏好。
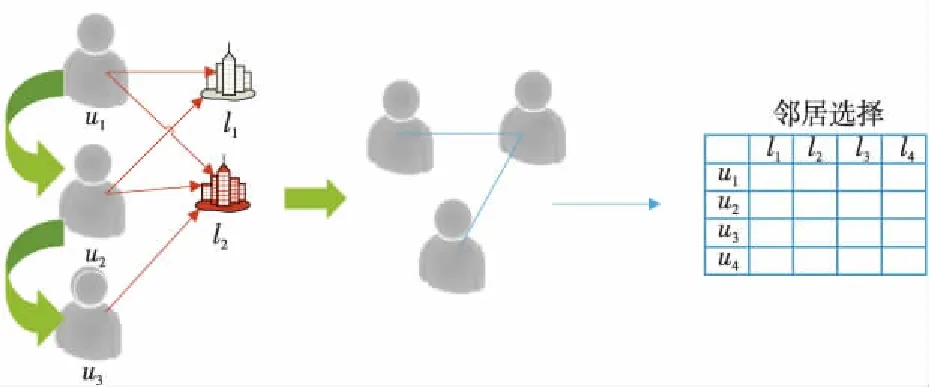
Figure 2 Neighbor selection strategy图2 邻居选择策略
4.3 基于地理位置的推荐
一些研究人员利用LBSN的签到数据作为理解人类移动模式的有用信息来源[12,13],从中得出2个结论:(1)用户与签到地点之间的距离分布类似于一个Power-Law分布,即指定用户已签到的大多数位置彼此接近;(2)用户倾向于去自己感兴趣的地点签到,例如他们的家或工作场所,即使有些地点可能会离家偏远。且由拖布勒第一定律[14]可知,一切事物都与其他事物相关,但近距离的事物比远距离的事物更相关,这表明距离相近的兴趣点更可能具有相似的特征。本文采用朴素贝叶斯算法来计算地理位置在推荐中的影响。用户ui签到过的兴趣点集合用Li表示,则该用户在任意一对兴趣点签到的概率为:
(5)
其中,d(lm,ln)为2个兴趣点之间的距离;lm,ln为Li中任意一对兴趣点。则由贝叶斯算法可得用户ui在候选兴趣点lj签到的概率为:
(6)
其中,lj为候选兴趣点;li为签到集合Li中任意兴趣点;d(lj,li)为兴趣点li到候选兴趣点lj的距离。PT[d(lj,li)]为用户在2个兴趣点都签到的概率,PT(ljLi)表示用户同时在lj和li签到的概率。
4.4 基于信任关系的推荐
为了将信任融入到兴趣点推荐中,本文考虑了几个不同角度的重要因素,包括用户在社交网络中的声誉,即社会地位以及用户与用户之间的互动。
在社交网络中用户总倾向于选择他们所相信的朋友们或是专家为其推荐的兴趣点,且用户之间的信任关系越强,其受到的影响越大;用有向图G(U,E)表示社交网络的信任关系图,其中U表示社交网络中的用户节点集;E表示这些用户之间关系的一组边;每条边被赋予一个值,表示用户之间的信任度。如图3所示,展示了用户u1~u5之间的信任度;u1~u5表示5个用户。社交网络和信任网络是不同的,社交网络的好友关系是相互的,而信任网络中的信任关系是单向的,即用户u1信任u2,并不代表用户u2也信任用户u1;而这些用户与用户之间的链接,是由同一网络中的其他用户对某个特定用户进行全面评估产生的。
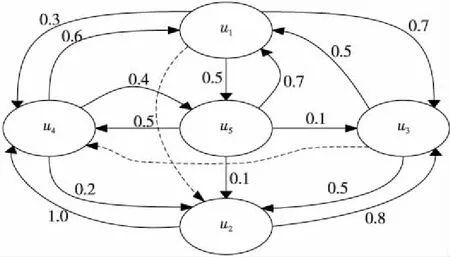
Figure 3 Trust network图3 信任网络
根据社交网络的交互行为,用户的属性反映了用户的特征,本文将用户的属性分为3个,并对这些属性进行分析。
(1)用户活动力:其反映的是用户是否发表过动态,社交网络中的用户活动力通常是通过用户的交互来衡量的,其定义如下所示:
(7)
其中,Nr(ui)表示用户ui更新动态的次数;t表示时间周期。
(2)用户关注度:在社交网络中,关注度高的用户将获得更多的关注和认同,这种良性现象将增强用户与用户之间的信任关系。根据这种现象,可以使用改进了的个人主页的 PageRank 值来衡量用户的关注度,其定义如下所示:
(8)
其中,C(ui)表示ui关注了的用户;N表示所有用户数;δ是调节因子;Act(ui)为用户活动力。
(3)社会地位值:在社交网络中,每个用户的影响力不同,由式(8)可得用户的关注度,对N个用户按关注度进行排序,设用户ui的排名为ri∈[1,N],则用户ui的社会地位值定义为:
(9)
由式(9)可知用户排名第1时,其si=1;且随着排名的下降,其社会地位值也随之下降,即用户的关注度越低,与之对应的社会地位值越低。
一般来说,在系统中如果一个用户被很多用户信任,那么这个用户在信任关系网络中的影响力应该大于那些只被少数用户信任的用户。这种观点同样能应用到对用户偏好的影响上,即被很多用户信任的用户具有较大的影响力,其个人的意见及言论往往会影响其他人的选择。基于该思想,认为在信任关系网络中被很多用户信任的用户在社交网络中的影响也会更大。因而,可以利用式(10)对用户之间的信任关系进行重构:
(10)
其中,Tuv表示用户u对用户v的信任度;Tu代表用户u信任集合,|Tu|表示集合中元素的个数;Nk和Nv分别表示信任用户k和用户v的用户个数。
综上所述,在信赖其他用户的情况下,用户ui去候选兴趣点lj签到的概率为:
(11)
其中,Di表示用户ui信任的用户集合;Tuiuk表示用户ui对用户uk的信任度;ftkj表示用户uk在兴趣点lj上的签到频次。
5 混合推荐系统
5.1 混合框架
在第3节中详细介绍了基于用户的协同过滤、基于地理位置和基于信任关系3种推荐方法,这3种推荐方法虽然能够为用户推荐兴趣点,但推荐效果并不是很好。人们更倾向于接纳信赖的朋友的推荐,因此接着分析用户的属性和信任关系计算方法。在LBSN中,用户根据其所信任朋友的签到历史考虑去一个新地点的可能性,更符合实际。因此,本文将用户的用户相似性、地理位置和信任关系这3种影响进行线性组合,确定用户ui在候选兴趣点lj上签到的概率为:
0≤λ,α,β≤1;λ+α+β= 1
(12)
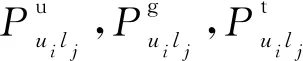
在该系统中对于伪造签到频次的恶意用户,即使他们与目标用户相似度很高,也不能对目标用户的兴趣点推荐产生决定性的影响。恶意用户不管是通过直接朋友还是间接朋友关系都不能获得目标用户的足够信任,最终也无法对目标用户进行恶意推荐。
5.2 规范统一模型
本文将利用min-max标准化来处理原始数据,将基于用户的推荐、基于地理位置的推荐和基于信任的推荐规范化如下:
(13)
其中,maxuser,maxgeo,maxtru分别表示P(u,i),P(lj/Li),P(ui,lj)的最大值;minuser,mingeo,mintru分别表示P(u,i),P(lj/Li),P(ui,lj)的最小值。
5.3 参数推导
对于参数的推导,本文采用的方法是梯度下降法,首先将式(12)进行多元线性回归处理,则有:
f(x)=fc(x)=c1x1+c2x2+c3x3
(14)
其中,
f(x)=Puilj
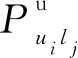
(15)
损失函数为:
(16)
最后得出最优化参数为:
(17)
(18)
(19)
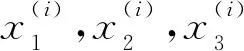
6 实验结果及分析
6.1 实验数据集和参数的选取
本文实验使用了2个真实签到数据集Foursquare和Gowalla。为了保证实验的有效性,从中剔除了签到次数少于10且好友人数少于5的用户,剔除被签到次数少于5 的兴趣点。最终得到的Foursquare数据集包含3 067个用户的180 544条签到记录,其中兴趣点数量为27 564个。Gowalla数据集包含6 304个用户的808 172条签到数据,兴趣点数量为53 827个。对Foursquare和Gowalla这2个数据集中的每位用户随机选取其80%的签到数据作为训练集,余下20%的签到数据作为测试集。根据5.3节所叙述的参数推导方法,选取最优参数作为本文的实验值。这些参数的值如表1所示。

Table 1 Experimental parameter value表1 实验参数值
6.2 评价指标
本文采用2个在推荐算法中应用较为广泛的评价指标:准确率precision@N和召回率recall@N。TOP-N代表最终的推荐数量,准确率表示算法推荐结果与用户反馈的契合程度,能够反映推荐的准确性。召回率则被用来评估算法的执行效率,体现的是用户偏好的推荐对象能被推荐的概率,反映推荐的全面性。计算方法为:
(20)
(21)
其中,R(u)表示推荐算法在执行训练集后得到的兴趣点推荐列表,T(u)则表示用户在测试集上的实际签到过的兴趣点列表。
6.3 对比实验
为了验证本文提出的融合用户相似性、地理相似性和信任关系的混合兴趣点推荐算法(UGT)的推荐效果,本文将其与以下几种推荐算法进行实验对比,各对比算法介绍如表2所示。
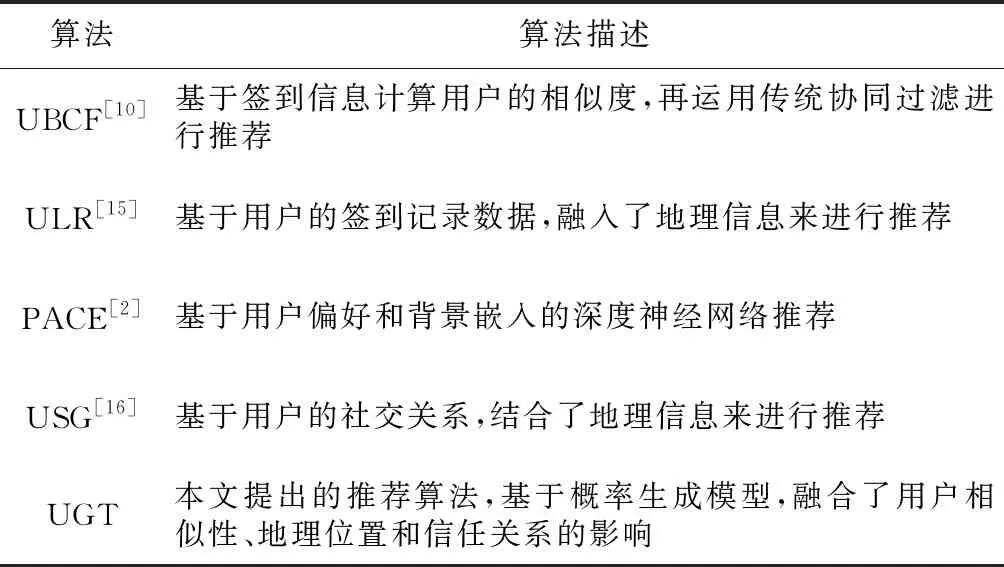
Table 2 Recommendation algorithms used in experiment表2 实验中使用的推荐算法
(1)各算法在不同时间阈值H下的结果对比。
本实验主要观察各算法在不同时间阈值下的结果。图4中横轴H表示时间阈值,其大小决定了用户签到数据的贡献度,进而影响推荐算法的推荐结果。纵轴precision@N和recall@N分别表示在不同时间阈值下各推荐算法对应的准确率和召回率,实验中分别设置阈值范围为0≤H≤5,单位为年,实验结果如图4所示。
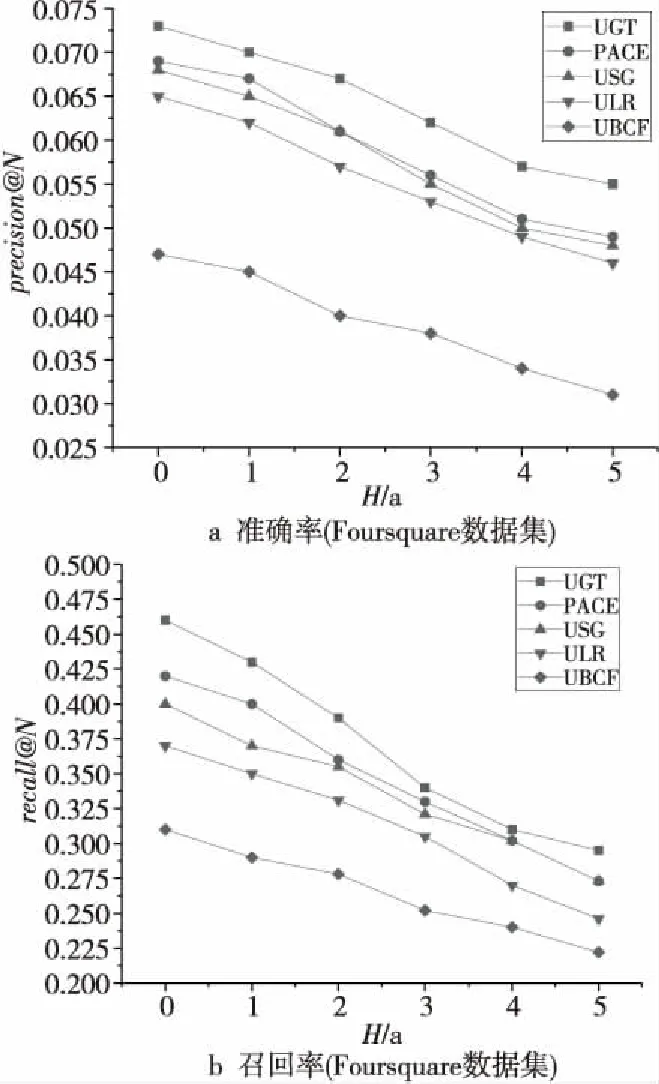
Figure 4 Influence of check-in frequency in recommendation图4 签到频次在推荐中的影响
通过实验1结果可以看出,随着时间阈值H的增加,各算法的准确率和召回率均有所下降,因为随着时间阈值H的增加,用户的兴趣可能会发生变化,对应时间间隔越大的签到信息对推荐结果的贡献越大,而用户最近的签到数据更能反映用户的偏好,因此控制好时间间隔对于推荐结果有着重要的意义。
(2)各算法在不同推荐数量下的结果对比。
本实验主要观察各算法在不同兴趣点推荐数量(TOP-N)下的结果。图5所示为在Foursquare数据集和Gowalla数据集上各算法的性能比较,图5中的横轴TOP-N代表了所推荐的兴趣点个数,纵轴precision@N和recall@N分别代表在不同推荐兴趣点数量时各推荐算法对应的准确率和召回率。实验中分别设置N=5,10,15,20,算法中的其余参数均设为满足算法性能最优化时的参数值。图5给出了各类算法在不同兴趣点推荐数量下准确率和召回率的比较结果。
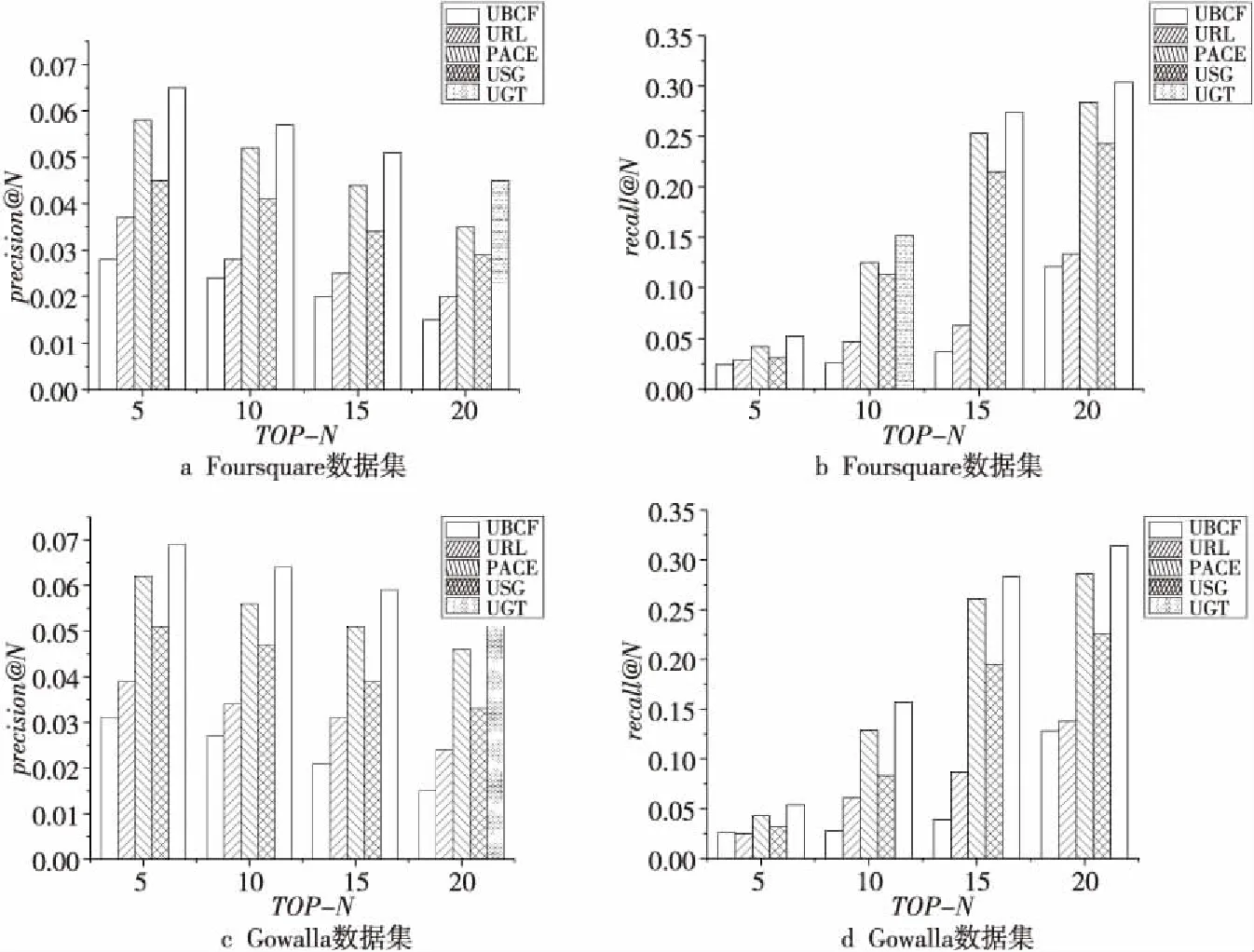
Figure 5 Performance comparison of each algorithm under different recommended quantities图5 各算法在不同推荐数量下的性能比较
从图5中可以得出:
①随着TOP-N值的增加,各类算法的准确率均有所下降,但召回率均有所提升,但本文提出的UGT算法在各种情况下都表现出了较好的推荐性能。
②UGT、ULR、PACE、USG与UBCF相比在性能上均有了较为明显的提升,这说明考虑多个因素比单因素能得到更好的推荐效果,且UGT算法提升最为明显。
③相比较ULR,本文的UGT算法推荐效果更优,表明融合信任关系可提高准确率和召回率,也避免了恶意推荐。
实验结果表明,相对于另外4种推荐算法,无论是在准确率还是召回率上,本文UGT算法的性能明显更好。
7 结束语
本文利用用户在LBSN中的历史签到信息、兴趣点的位置属性和用户信任关系,提出了一种混合兴趣点推荐算法。对签到信息添加时间权重,充分利用了用户签到信息;提出了一种基于朋友的邻居选择策略,筛选出目标用户的邻居用户,以此来提高对目标用户的偏好预测精度;分析了用户的属性,给出了社会地位和信任度的计算方法。将用户信任关系融合到推荐系统中,可以有效地改善推荐系统的性能,使得推荐的准确率和召回率更高,用户满意度更好。下一步的研究工作是深入挖掘用户行为的时空模式,以此来提高推荐性能。
