基于深层特征融合的行人重识别方法*
2020-03-04熊子婕杨荻椿曾春艳
熊 炜,熊子婕,杨荻椿,童 磊,刘 敏,曾春艳
(1.湖北工业大学电气与电子工程学院,湖北 武汉 430068; 2.美国南卡罗来纳大学计算机科学与工程系,南卡 哥伦比亚 29201)
1 引言
行人重识别(Pedestrian Re-identification),是利用计算机视觉技术检索出不同摄像头下相同行人的技术[1]。在监控视频中,由于相机分辨率和拍摄角度的缘故,通常无法得到质量非常高的人脸图像,此时行人重识别就成为了一个非常重要的替代技术。由于行人重识别在视频监控应用中的重要地位,以及越来越多的大规模行人重识别数据集的提出,行人重识别在计算机视觉中越来越受重视。然而由于行人姿态变化、环境光照影响、遮挡等问题,行人重识别是一个相当具有挑战性的问题。
目前行人重识别方法主要分为2类:基于特征表示的方法和基于度量学习的方法。
基于特征表示的方法主要提取具有鲁棒性的鉴别特征来表示行人。Wei等[2]提出采用deeper cut算法估算行人的4个关键点,将输入图像分成3个部分,然后从全局图像和部件图像中学习描述子,以此来学习更加精细的局部特征。Su等[3]为解决行人姿态变化以及视角差异的问题,提出采用姿势估计的方法对行人图像分块,并对不同块加权来增强行人细节特征。Liu等[4]提出了一种基于注意力机制的深度神经网络HPNet(HydraPlus Network),引入来自多层级的多尺度注意力特征,并将行人的全局和局部特征联合组成新的行人特征。Zhao等[5]为解决人体错位的问题,提出一种人体区域对齐的方法,利用训练好的网络将人体分割成几个有区分力的区域,分别计算每个区域的特征向量。Yao等[6]提出了部分损失网络PL-Net(Part Loss Network),对现有大部分只提取全局特征且容易过拟合而不考虑局部特征的方法做了改进,该网络可自动检测人体部件,增加模型的判别性。
基于度量学习的方法主要通过学习一个距离函数,使同一行人的距离小于不同行人的距离[7]。它的目的是寻找一种新的距离度量,将原始的行人特征(如HOG特征[8]和SIFT特征[9])转换到一个新的度量空间中,在这个度量空间中,具有相同标签的样本更近,标签不同的样本具有较大的距离。基于深度学习的行人重识别方法中,这种距离度量学习算法被称为排序损失。其中最典型的排序损失是三元组损失(Triplet Loss)[10],给定一个目标样本,其中一个正样本与目标样本具有相同的标签,另一个负样本具有不同的标签,通过三元组损失调节使目标样本正距离小于目标样本负距离。除了三元组损失外,还有其他类型的度量学习损失,如柱状图损失(Histogram Loss)[11]和四元组损失(Quadruplet Loss)[12]。
本文提出了一种深层特征融合的行人重识别网络模型,从空间维度提升网络性能。首先,利用卷积层和池化层多次提取网络深层特征,使用融合后的深层特征作为行人图像的特征属性,融合后的特征具有更好的细粒度特征表达能力。其次,为提高模型的泛化能力,在深层融合特征后加入一个批量归一化层,同时采用标签平滑损失(Label Smoothing Loss)函数和三元组损失函数对模型进行联合训练。与2017和2018年优秀的算法进行对比实验结果表明,本文所提方法在Market1501、DukeMTMC-reID、CUHK03和MSMT17 4个数据集上都取得了更高的行人重识别率。
2 基于深层特征融合的网络模型
2.1 网络结构
目前行人重识别在特征提取部分主要采用残差卷积网络Resnet-50[13]作为骨干网络(Backbone),然后根据特征映射进行距离度量,计算图像相似度。考虑到从空间维度提升网络性能以及提高模型的泛化能力,本文采用Se-resnet50[14]作为骨干网络,利用卷积层和池化层多次提取网络深层特征并对融合特征进行批量归一化BN(Batch Normalization)处理。本文采用的行人重识别网络结构如图1所示,网络结构包括深层特征提取和融合特征批量归一化2个部分。
在深层特征提取部分,本文采用Se-resnet50网络提取图像的全局特征,其网络内部结构如图2所示,该网络是将SENet(Squeeze-and-Excitation Networks)嵌入Resnet-50中,SENet分为压缩和激励2个部分。SENet采用“特征重标定”方法进行特征通道间的融合,通过自己学习获取特征通道的权重并进行分配,提升有用特征通道的权重,同时削弱相关性小的特征通道的权重。在压缩部分,对Resnet-50输出的C个空间维度为H×W的特征映射fi,通过全局池化压缩成C个空间维度为1×1的特征向量。在激励部分,通过如图2所示的瓶颈结构(Bottleneck)捕捉信道之间的内部关联,学习信道的注意力因子。最终将学习到的注意力因子分配到相应的信道上,输出C个大小为H×W的带有注意力标注的特征映射f′i。
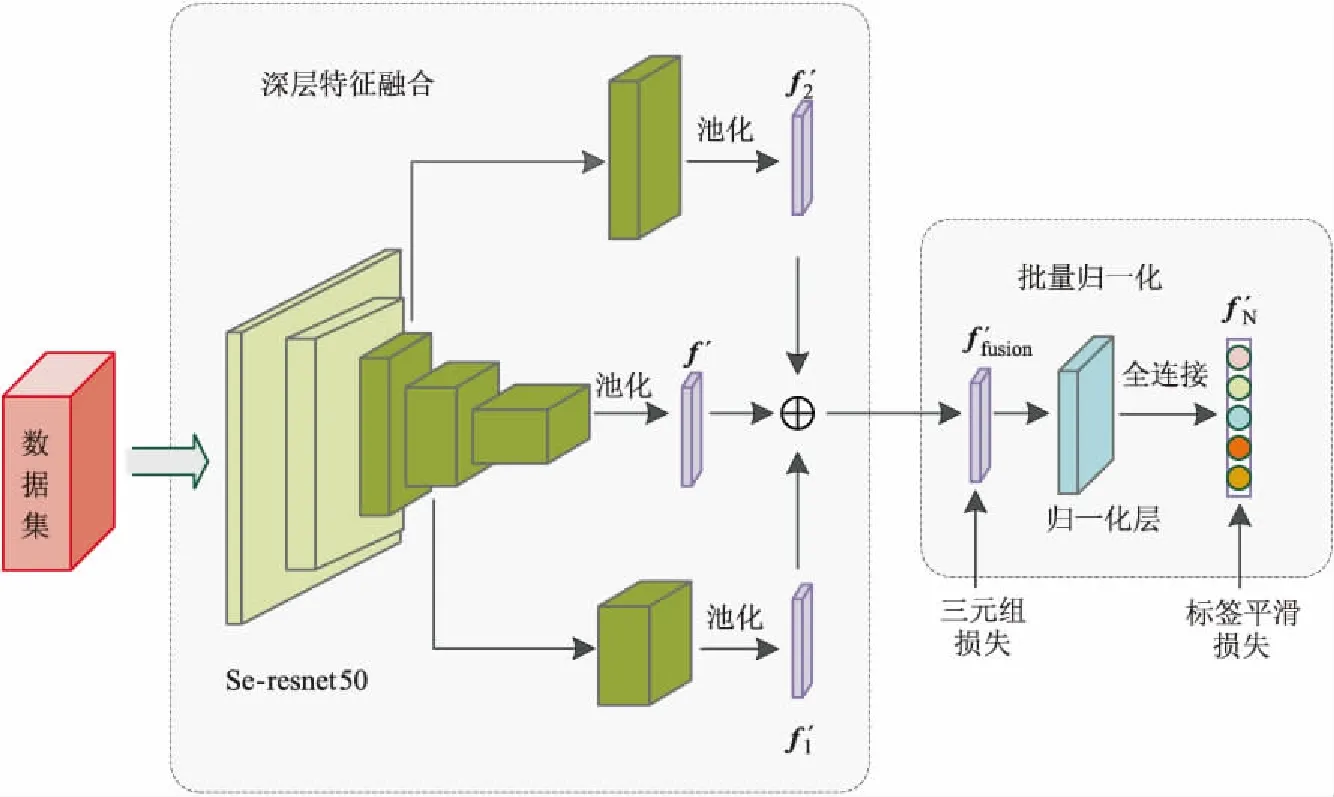
Figure 1 Structure of pedestrian re-identification network图1 行人重识别网络结构
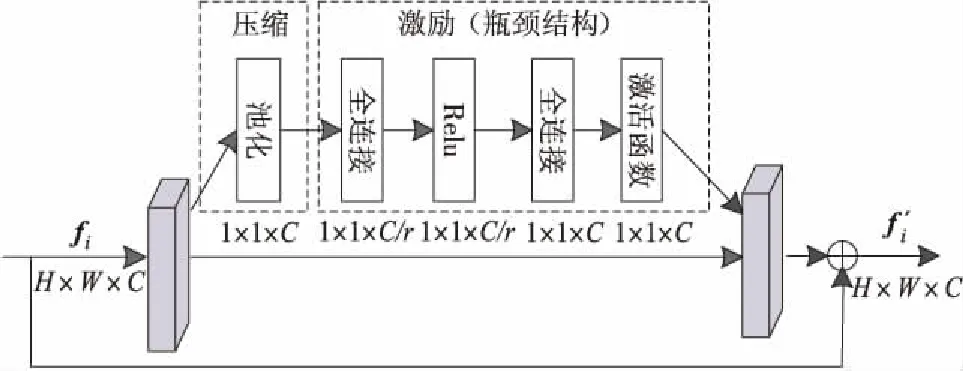
Figure 2 Structure of Se-resnet50图2 Se-resnet50结构
本文提出将Se-resnet50的2个中间层特征提取出来获得图像深层次的全局特征属性表示,提取的2个中间层特征维度分别为512和1 024,对这2个不同尺度的中间层特征分别采用平均池化方法,获得2 048维的深层特征f′1,f′2,最后将2个中间层特征与网络输出的2 048维的特征映射f′拼接为融合特征f′fusion=[f′,f′1,f′2],以提高模型对图像深层特征的描述能力。
在融合特征批量归一化区域,为提高网络的泛化能力,在输出的C个融合特征(即批处理特征值)后面加入一个归一化层,首先计算批处理特征值的均值,然后计算其方差,对批处理特征值进行归一化处理,使其均值为0,方差为1。同时,在批量归一化层中引入了2个可学习参数γ,β,将C个融合特征的特征值作为样本对参数γ,β进行训练,对批处理特征值进行尺度变换和偏移。具体过程如图3所示,其中图3a为没经过任何处理的融合特征的sigmoid函数,深层融合特征分布在梯度平滑的区域时,网络在训练过程中将很难收敛。图3b对融合特征进行归一化处理后,将数据移到sigmoid函数中间区域,该区域具有最大梯度,能更有效地训练网络。为保证模型的非线性表达能力,图3c对归一化的深层融合特征进行尺度变换和偏移,使其更接近于真实分布。
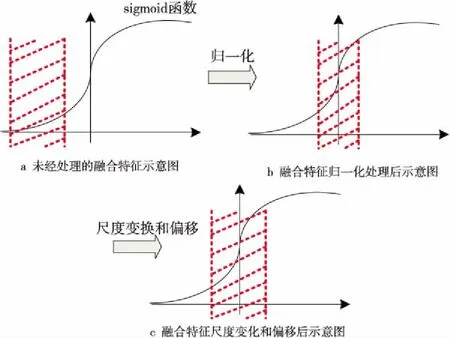
Figure 3 Batch normalization process of fusion feature图3 融合特征批量归一化过程
2.2 损失函数
2.2.1 标签平滑损失函数
在行人重识别系统中,行人训练样本通常会存在少量的错误标签,这些错误标签可能会影响预测结果,标签平滑损失函数被用来防止模型在训练过程中过度依赖标签。
假设输入行人图像且其类别为i时,yi为图像中行人的标签,若yi属于类别i,则其值为1,否则为0。本文对行人标签进行了平滑处理,在每次训练过程中,给标签设置一个错误率ε,则实际标注的行人标签y′i如式(1)所示:
(1)
设qi是网络预测实际标注的行人标签y′i属于类别i的概率,如式(2)所示:
(2)
其中,M为数据集中的行人个数。由交叉熵损失函数可得标签平滑损失如式(3)所示:
(3)
其中,pi为网络预测标签yi属于类别i的概率。
2.2.2 三元组损失函数
本文通过三元组损失训练模型使得任意目标样本与正样本之间的距离最小,与负样本之间的距离最大。三元组损失函数如式(4)所示:
Ltri=[dp-dn+α]+
(4)
其中,dp为目标样本与正样本之间的欧氏距离,dn为目标样本与负样本之间的欧氏距离,α为三元组损失的阈值,本文中阈值设为0.3。
2.2.3 联合损失函数
由于本文采用标签平滑损失[15]和三元组损失[12]对模型进行联合训练,然而这2种损失计算的特征映射是不一致的。标签平滑损失需要构造多个超平面,将每个类的特征分布在不同的子空间中。在使用标签平滑损失函数优化模型时,余弦距离更适用于标签平滑损失函数。但是,三元组损失函数是对欧氏距离中的类内紧密性和类间可分离性进行了增强。如果使用这2个损失函数同时对融合特征映射进行优化,会存在目标不一致的问题,甚至会增加训练难度。
为联合标签平滑损失和三元组损失,本文将批量归一化层加入到融合特征映射f′fusion和全连接层之间,融合特征映射f′fusion进入批量归一化层后输出标准化融合特征映射f′N。由于批量归一化层将所有特征属性全部分配给了同一个标签,故采用f′N计算标签平滑损失,用f′fusion计算三元组损失。最终,本文模型的损失函数为Lloss=Lid+Ltri。
3 实验结果及分析
3.1 实验数据与评估标准
本文在Market1501[16]、CUHK03[17]、DukeMTMC-reID[18]和MSMT17[19]4个数据集上对提出的行人重识别方法进行对比实验,各数据集的介绍如表1所示。
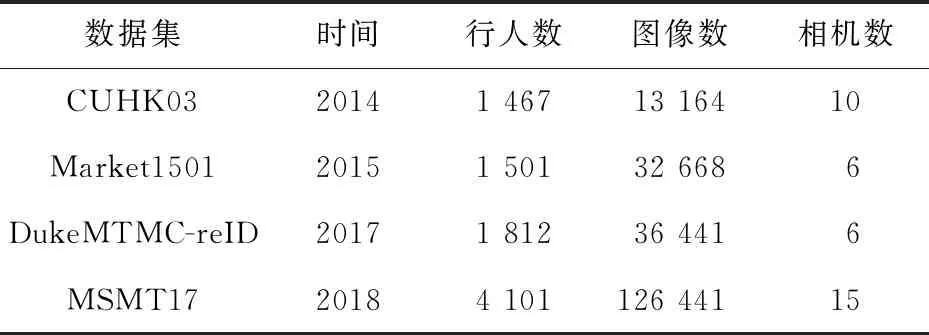
Table 1 Datasets introduction表1 数据集介绍
Market1501数据集[16]采集于清华大学,包含32 668幅行人图像,一共有1 501个行人标签。数据集中包含训练集以及测试集,训练集中有751个行人标签,平均每人约有17.5幅图像;测试集中有750个行人标签。
CUHK03数据集[17]采集于香港中文大学,包含13 164幅行人图像,一共有1 467个行人标签。该数据集是Matlab数据文件格式,由检测、标注和测试3个部分组成。
DukeMTMC-reID数据集[18]采集于杜克大学,包含36 441幅行人图像,一共有 1 812个行人标签。数据集中包含训练集以及测试集,训练集中有702个行人标签,平均每人约有23.5幅图像;测试集包含17 661幅图像。
MSMT17数据集[19]是目前最大且最接近真实场景的数据集,该数据集采集于校园内,通过15个摄像头采集180小时,最终得到126 441幅行人图像以及4 101个行人标签。数据集中包含训练集以及测试集,测试集中有3 060个行人标签,平均每人约有30.6幅图像;测试集中有11 659幅查询图像以及82 161幅行人图像。
实验中使用第1次命中匹配准确率(Rank-1)以及平均准确率mAP(mean Average Precision)作为评价指标对模型进行评估。
3.2 参数设置与分析
3.2.1 参数设置
本文方法在Pytorch深度学习工具包上实施,实验平台是基于64位的Ubuntu16.04操作系统,显卡型号为iGame GeForce RTX 2070,卷积神经网络选用的是Se-resnet50,运用随机遮挡、裁剪和旋转对训练数据进行增强,输入行人图像大小为224×224。初始学习率设为3.5×10-5,随着迭代次数逐渐增加到3.5×10-4,然后分别在迭代到40和70次时降到3.5×10-5和3.5×10-6,迭代次数设为120次。训练时批次大小设为32,优化器为ADAM。采用标签平滑损失函数与三元组损失函数联合训练模型。
3.2.2 骨干网络的选择
为验证Se-resnet50的优越性,本文分别以Resnet-50和Se-resnet50为骨干网络在Market1501数据集上进行训练,训练过程中仅采用softmax损失对骨干网络进行优化,实验结果如表2所示。
由表2可知,Se-resnet50网络相比于Resnet50网络,虽然在训练时间上增加了16.11 min,但Se-resnet50在Rank-1上提升了2%,在mAP上提升了3.8%,该结果表明本文采用的Se-resnet50网络可以更有效地提取行人特征。

Table 2 Experimental results based on Resnet-50 and Se-resnet50 backbone networks on Market1501 dataset表2 Market1501数据集上基于Resnet50和Se-resnet50骨干网络的实验结果
3.2.3 深层特征融合模型
本文为提取行人深层特征属性,将Se-resnet50中间层特征分支提取出来先输入池化层然后融合,为验证深层特征属性的有效性,对只提取中间层特征f′1与原始特征f′融合训练,提取2个中间层特征f′1、f′2与原始特征f′融合训练,提取3个中间层特征f′1、f′2、f′3与原始特征f′融合训练以及原始特征单独训练进行实验,实验结果如表3所示。本次实验仅采用三元组损失函数训练模型,并未在网络结构中加批量归一化层。
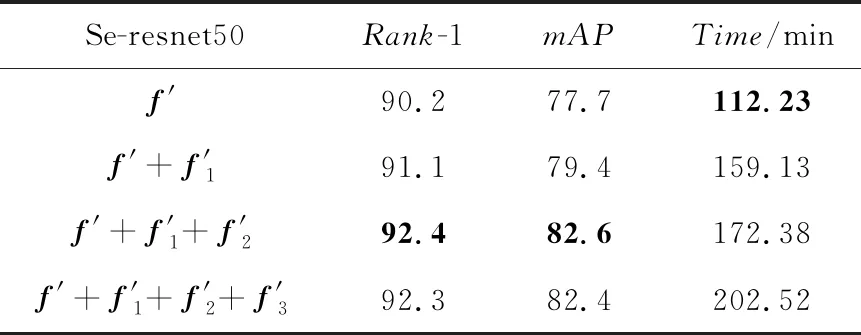
Table 3 Experimental results of extraction of deep feature fusion on Market1501 dataset表3 Market1501数据集上提取深层特征融合的实验结果
由表3可知,在Market1501数据集上,提取中间层特征与原始特征融合训练的方法相较于原始特征单独训练方法均有提升,最高可在Rank-1和mAP指标上提升2.2%和4.7%,表明了深层特征提取对模型优化的有效性。
由实验结果可知,提取2个中间层特征与原始特征融合训练的方法在Rank-1与mAP指标上,高于提取1个中间层特征与原始特征融合训练的方法1.3%和3.2%,高于提取3个中间层特征与原始特征融合训练的方法0.1%和0.2%。虽然提取2个中间层特征与原始特征融合训练的方法与提取3个中间层特征与原始特征融合训练的方法结果相差不大,但在提取2个中间层特征与原始特征融合训练的方法的模型训练时间更短。与提取3个中间层特征的方法相比,虽然在Rank-1与mAP指标上相差不大,但模型训练时间减少了30.14 min。综合行人重识别率与模型训练时间分析可知,提取2个中间层特征进行融合训练是最有效的。
为验证批量归一化层与联合损失函数的有效性,本文以Se-resnet50为骨干网络以及提取2个中间层特征与原始特征融合的方法为基础模型,对是否加入批量归一化层在Market1501数据集上进行实验,实验结果如表4所示。
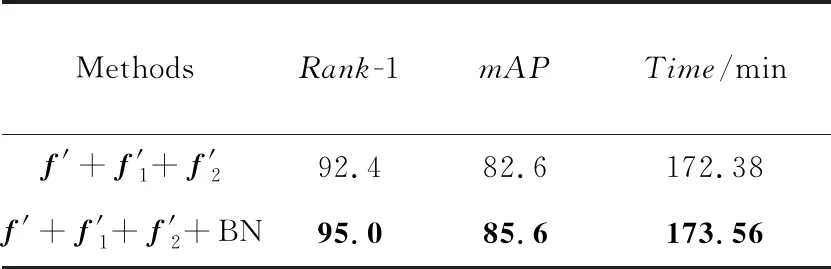
Table 4 Experimental results with or without batch normalization layer on Market1501 dataset表4 Market1501数据集上有无批量归一化层的实验结果
由表4可知,加入批量归一化层训练的方法比未加批量归一化层训练的方法在Market1501数据集上有大幅度提升,在Rank-1和mAP指标上分别提升了2.6%和3.0%。虽然在模型训练时间上与未加批量归一化层训练的时间相近,增加了1.17 min,但有效地提高了行人重识别率。
3.3 相关方法比较
为验证所提行人重识别方法的有效性,分别在Market1501、DukeMTMC-reID、CUHK03和MSMT17 4个数据集上实验,实验中未采用Re-ranking对行人重识别率进行提升。通过与2017和2018年优秀的算法进行对比,在4个数据集上本文方法的结果均有显著提升。图4是部分实验的查询结果图,第1列为行人查询图像,后10列为查询结果,其中黑框为错误结果,无框为正确结果。

Figure 4 Query results of pedestrian re-identification图4 行人重识别的查询结果图
在Market1501数据集上加入深层特征融合以及批标准化处理后,实验结果如表5所示,对比方法的评估结果分别摘自文献[20 - 23]。在该数据集上本文方法均优于其他的方法,且在mAP指标上有大幅提升,达到了85.6%,Rank-1达到了95.0%。
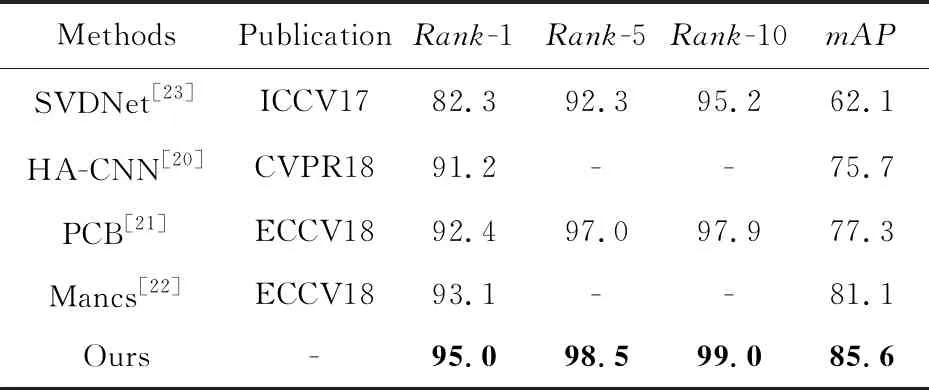
Table 5 Performance comparison with mainstream methods on Market1501 dataset表5 Market1501数据集上与主流方法的性能比较
在DukeMTMC-reID数据集上加入深层特征融合以及批标准化处理后,实验结果如表6所示,对比方法的评估结果分别摘自文献[20-23]。在该数据集上本文方法在Rank-1以及mAP2个评价指标上均取得了大幅提升,分别提升了2.2%和5.3%,达到了87.1%和77.1%。
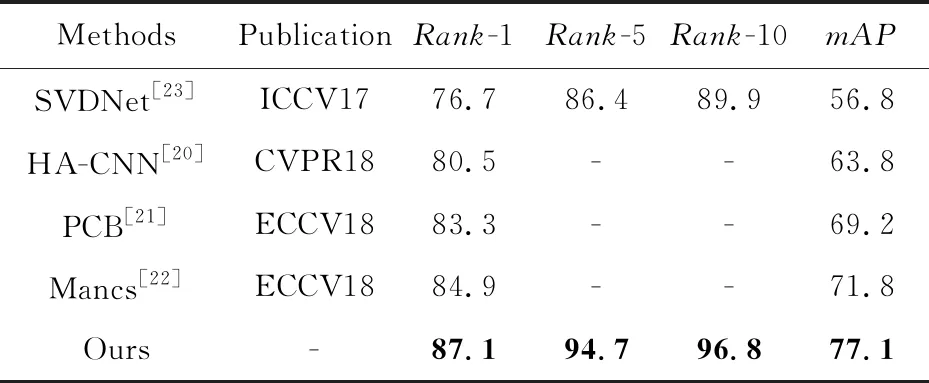
Table 6 Performance comparison with mainstream methods on DukeMTMC-reID dataset表6 DukeMTMC-reID数据集上与主流方法的性能比较
在CUHK03数据集上加入深层特征融合以及批标准化处理后,实验结果如表7所示,对比方法的评估结果分别摘自文献[20,21,23]。在该数据集上本文方法均优于其他的方法,且在mAP指标上有大幅提升,达到了61.1%,Rank-1达到了62.0%。
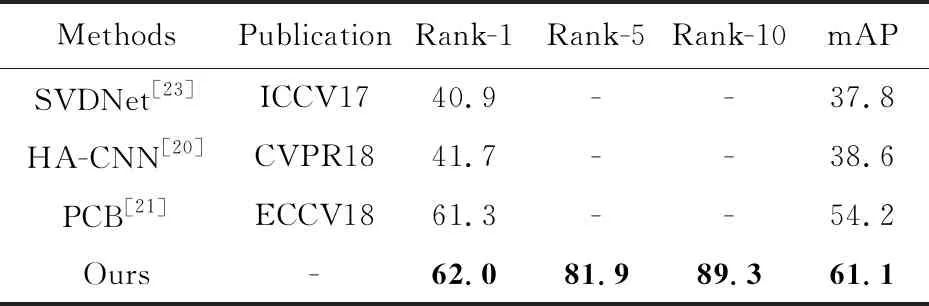
Table 7 Performance comparison with mainstream methods on CUHK03 dataset表7 CUHK03数据集上与主流方法的性能比较
针对2018年新提出的数据集,在MSMT17数据集上加入深层特征融合以及批标准化处理后,实验结果如表8所示,与其对比方法的实验均来自于文献[19]。本文方法对该数据集的行人重识别率有显著提升,在Rank-1以及mAP2个评价指标上均取得了大幅提升,分别提升了13.5%和17.8%,达到了74.9%和51.8%。
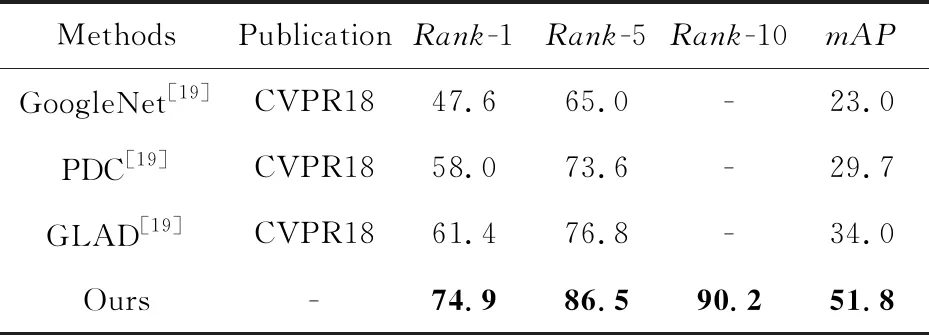
Table 8 Performance comparison with mainstream methods on MSMT17 dataset表8 MSMT17数据集上与主流方法的性能比较
4 结束语
本文提出了一种深层特征融合的行人重识别方法,从空间维度提升网络性能。该方法利用卷积层和池化层多次提取Se-resnet50网络深层行人特征,使用融合后的深层特征作为行人图像的特征属性。在深层融合特征后加入一个批量归一化层,同时采用标签平滑损失函数和三元组损失函数对模型进行联合训练,提高模型的泛化能力。实验结果表明,本文所提行人重识别方法在Market1501、DukeMTMC-reID、CUHK03和MSMT17 4个数据集上都取得了更高的行人重识别率。在未来工作中将进一步研究更为有效的特征提取方法,提高行人重识别性能。
