联合损失优化孪生网络的行人重识别*
2020-03-04张惊雷
樊 琳,张惊雷
(1.天津理工大学电气电子工程学院,天津 300384;2.天津市复杂系统控制理论及应用重点实验室,天津 300384)
1 引言
行人重识别Re-Id(Re-Identification),也称行人再识别,其目的是在多摄像机间进行行人检索,是图像检索问题的1个子问题[1],在公安刑侦、智能安防、智能商场等领域应用广泛。但是,由于实际拍摄中行人图像易受到光照、遮挡和相机像素差异等因素影响,同一行人在不同相机下拍摄的图像差异较大,给识别带来困难,因此行人重识别技术仍面临很大挑战。
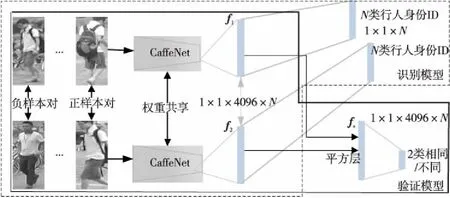
Figure 1 Classic siamese network图1 经典孪生网络
行人重识别研究可分为特征表示和度量学习2种方法。特征表示法的目的是从输入图像中提取出鲁棒性强的行人表观特征,经典算法如Jungling等人[2]提出的尺度不变特征变换SIFT(Scale-Invariance Feature Transform)。这类方法主要根据经验来设计需提取的特征,但这些特征仅适用于当前数据类型,不具有普适性。度量学习法是使用距离度量函数来度量行人表观特征相似度的方法,经典算法如Liao等人[3]提出的XQDA(Cross-view Quadratic Discriminant Analysis)。这类方法主要根据样本的类别标签组成正负样本对,再将正负样本对的特征映射到距离空间,并使正样本对的距离小于负样本对的距离。传统的行人重识别系统是将2种方法独立进行分析和改进,对识别精度的提高并不明显。近几年来,深度学习类方法逐渐应用到行人重识别中,经典的深度学习模型是将特征提取与度量学习融合到1个网络中,称为孪生网络(Siamese Network)。如2014年Yi等人[4]提出的孪生卷积神经网络框架SCNN(Siamese Convolutional Neural Network)和2016年Wang等人[5]提出SIR(Single-Image Represention)和CIR(Cross-Image Representation)结合的网络框架。随着深度学习的不断发展,出现了卷积层数达10层以上的深度卷积神经网络CNN(Convolutional Neural Network)模型,如VGGNet、GoogLeNet和ResNet等,在识别任务中能够自动提取鲁棒性较强的特征。基于此类模型的典型算法有2017年Zheng等人[6]提出的深度孪生网络框架IDE(ID-discriminative Embedding),2017年Sun等人[7]提出的SVDNet深度学习框架,2018年陈首兵等人[8]提出的孪生网络和重排序结合的重识别算法。
本文提出一种用联合损失优化孪生网络的行人重识别算法。这是基于经典孪生网络的改进算法,该算法为增加难分样本对的区分度,使用2种损失监督信号对搭建好的网络进行训练。利用训练好的模型提取特征,然后计算行人图像特征与图库特征间的余弦相似度并排名;最后通过计算欧氏距离与杰卡德距离的加权对候选行人排名表重排序,使正确匹配图像排序提前。实验表明,该算法不仅能同时识别身份ID和判断输入图像对的关系,而且还能学习到更具分辨力的特征,降低了错误匹配率。
2 经典孪生网络
行人重识别的孪生网络包括2个CNN模型,即识别模型和验证模型,如图1所示。识别模型完成目标多分类,包括2个用来预测身份ID的模型,主要由2个参数共享的卷积神经网络(图示中以CaffetNet举例)构成;验证模型完成目标二分类,即用来判断输入行人图像对是否为同一人。
2.1 识别模型和识别损失
如图1所示,孪生网络中包含2个结构相同的分支,均使用经过ImageNet数据集预训练过的深度CNN模型作为特征提取的骨架网络,并且2个网络共享权重,图中以CaffeNet为例。首先用卷积层代替深度CNN模型最后的全连接层(1 000维),此卷积层的输出为1×1×4096的向量f(图中指f1和f2),以数据集Market-1501[9]为例,行人共有751名,所以这个卷积层共有751个1×1×4096的向量。在卷积层后添加Softmax函数将输出规范到1×1×N(N为训练集中行人总数,如Market-1501中N为751),然后使用交叉熵损失进行身份的预测,即识别损失,计算公式如式(1)所示:
(1)
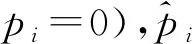
识别模型进行的是多分类识别任务,预测输入图像中的行人身份ID,识别模型只能进行身份预测,不能判断图像对是否为同一人。
2.2 验证模型与验证损失
如图1所示,将经过骨架网络得到的2个特征向量f1和f2嵌入到平方层中作比较,平方层的计算公式为:fs=(f1-f2)2,f1和f2均为4 096维向量,fs为平方层的输出。然后添加卷积层和Softmax函数,将fs嵌入到二维向量中,得到输入的2幅图像属于同一人的预测概率。验证模型同样使用交叉熵损失来预测二者的关系,即验证损失,计算公式如式(2)所示:
(2)
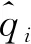
因此,可将验证模型视为二分类任务,输入是1对图像,目的是对比2幅图像是否属于同一人,即给定1个标签s∈{0,1},0表示不同行人,1表示相同行人。
2.3 对孪生网络的评价
孪生网络将验证模型和识别模型结合,能够同时识别行人身份和判断输入对的关系,但对数据集中的难分样本对进行重识别时仍然存在较高的误匹配率。
3 本文算法
针对上述问题,本文提出一种联合损失优化孪生网络的深度学习算法,算法将Focal Loss[10]函数作为验证损失,交叉熵函数作为识别损失,将两者联合对孪生网络进行优化,并加入重排序算法提高第1匹配率(Rank-1:就是计算在第1个样本命中或匹配正确的概率)。
3.1 ResNet-50模型
经典孪生网络使用CaffeNet与ResNet-50的CNN模型作为特征提取网络,在2个大型数据集上的实验结果表明,ResNet-50的Rank-1与mAP分别比使用CaffNet时高约17.4%和20.3%[6]。CNN模型中卷积层数的加深能够提取到更加丰富的特征,但网络层数的加深会使得网络的性能下降。
为解决上述问题,2015年微软研究院He等人[11]提出了一种深度残差网络ResNet(deep Residual Network),通过加入残差单元来解决由于网络加深而产生的网络性能下降问题。残差单元是一种类似“短路连接”的连接方式,如图2所示的残差单元,也称“bottleneck design”,X identity表示短路连接作为输入,也称为恒等映射,中间的3部分用F(X)表示残差中的差部分,因此最后的输出为y=F(X)+X。输入1个256维的向量,通过1×1卷积将256维通道降到64维,经过卷积操作,最后再利用1×1卷积恢复到256维。加入1×1卷积核起到降维的作用,可以减少参数数目,加快训练,提升精度。
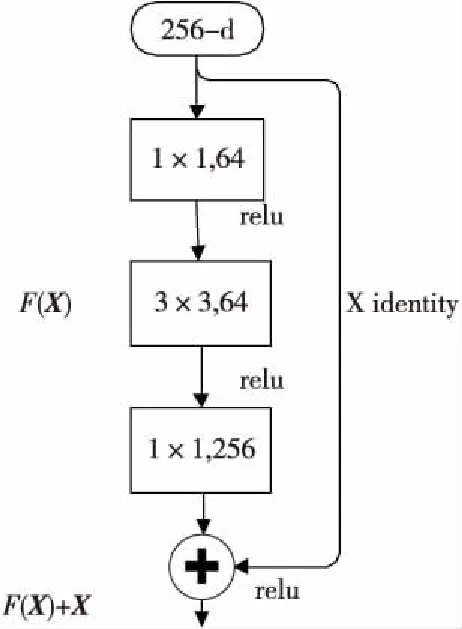
Figure 2 Residual unit图2 残差单元
ResNet-50模型每层参数如表1所示。
3.2 联合损失优化孪生网络算法
本文同时使用交叉熵损失和Focal Loss 2种函数在搭建好的ResNet模型上进行训练。2个识别模型中均使用交叉熵损失,将提取到的特征向量映射到(0,1)中,最小化分类概率,使预测类别更接近真实类别。在验证模型中使用Focal Loss,作用是减小较容易分类样本的权重和增加对难区分样本的关注度,得到分辨力更强的特征。采用2种损失对网络进行监督训练,使模型学习到较鲁棒的特征,能有效解决相似行人难以区分的问题。本文算法整体框架如图3所示。
在识别模型中,行人图像经过ResNet-50卷积神经网络进行特征提取后得到特征向量f1和f2,然后利用交叉熵损失函数CE(Cross Entropy loss)进行行人的身份预测,计算公式如式(3)所示:
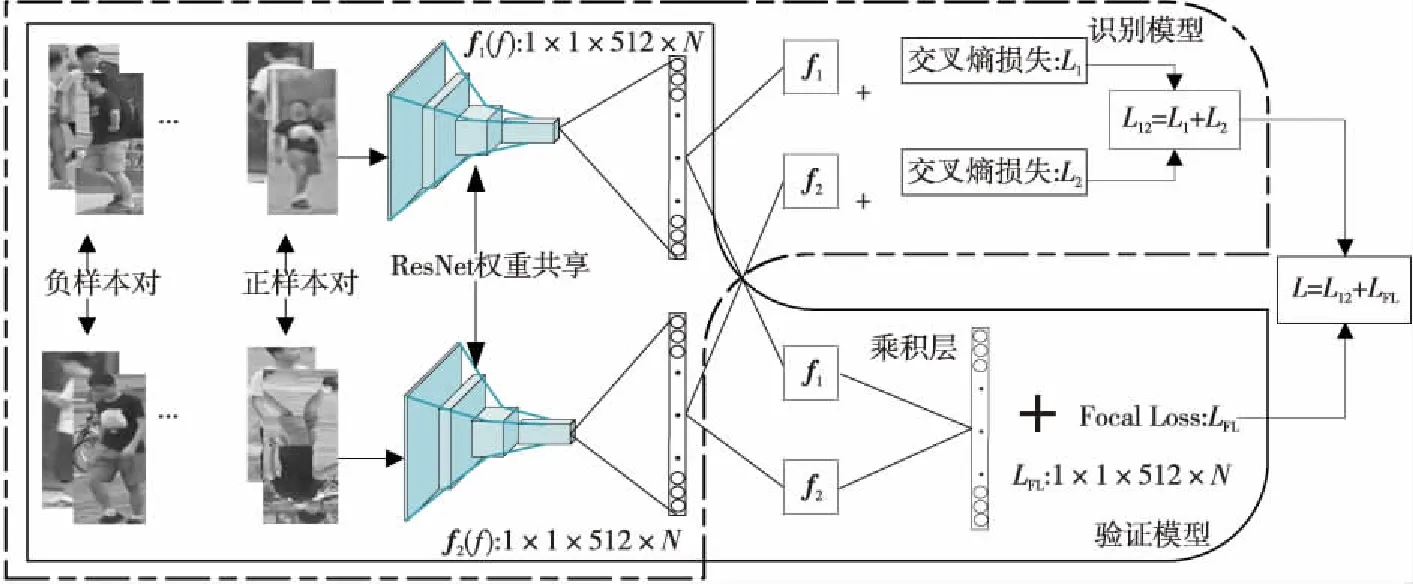
Figure 3 Improved siamese network图3 改进的孪生网络框架
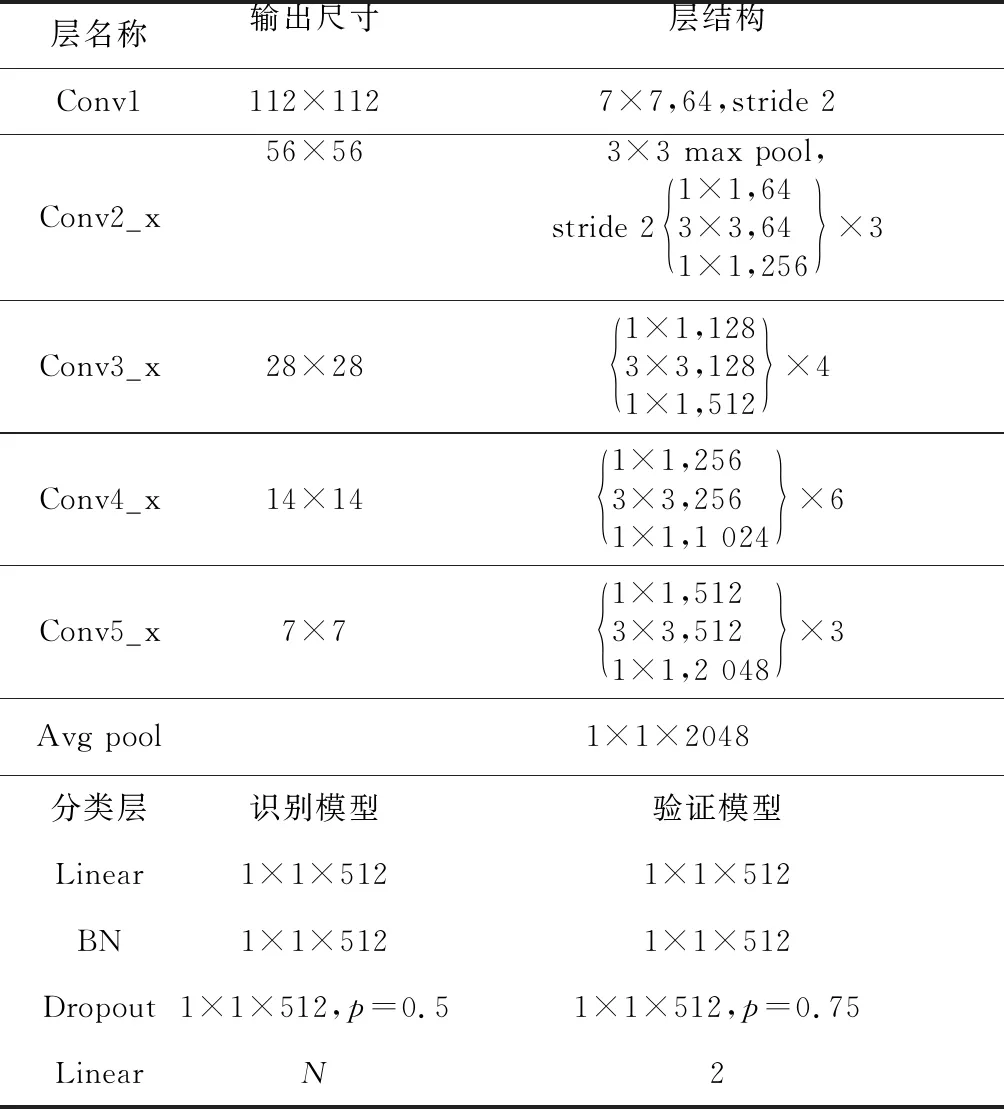
Table 1 ResNet-50 network parameters表1 ResNet-50网络参数
(3)
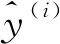
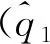
Focal Loss函数基于标准二分类交叉熵损失(如式(4)所示)进行改进,最初是在交叉熵损失上添加1个系数作为控制权重,如式(5)所示:
CE(pt)=-log(pt)
(4)
CE(pt)=-αtlog(pt)
(5)
其中,pt表示预测的输出概率,值在0~1。
只加入1个控制系数,仅平衡了正负样本比例,但还不足以区分难分样本对,又进行如下改进:
FL(pt)=-(1-pt)γlog(pt)
(6)
从式(6)可以看出,当γ大于0时,若输入为正样本对,预测概率大的样本比预测概率小的样本损失小;若输入为负样本对,预测概率小的样本比预测概率大的损失小。改进以后使得难区分样本的损失会变大,则使模型更关注难区分样本对,将式(5)和式(6)相结合,可得到Focal Loss的标准形式:
FL(pt)=-αt(1-pt)γlog(pt)
(7)
其中,αt和γ协调控制输出。文献[10]给出了2参数优化的原理,因此本文沿用了优化结果,取αt=0.25和γ=2,最后得到联合损失函数如式(8)所示:
L=LCE1+LCE2+Lfocalloss
(8)
其中,LCE1和LCE2代表2个识别网络的识别损失,Lfocalloss代表验证损失。
将2种损失相结合,不仅能平衡正负样本比例所占权重,而且使模型更关注较难区分的样本,从而降低误匹配的概率,联合损失在训练网络时能够加快模型的收敛速度,也能达到较好的识别效果。
3.3 重排序算法
在行人重识别中加入重排序算法[12]能进一步提高识别精度。重排序算法的主要思想是:在得到查询结果的初始排名列表后,通过求原始距离(欧氏距离)和杰卡德距离(Jaccard Distance)的加权和来重新修改原始列表,使得更多的正样本排到前面,从而提高行人重识别的精度。重排序算法的框架如图4所示。
首先给定1幅查询行人图像p和图库G,G={gi|i=1,2,…,N},提取查询行人和图库行人的特征和k互近邻(k互近邻表示当给定1幅行人查询图像时,另1幅图像排在查询结果最靠前的第k个位置,即2幅图像同时互为k近邻,称为k互近邻)特征,行人之间的原始距离采用欧氏距离,计算公式如式(9)所示:
(9)
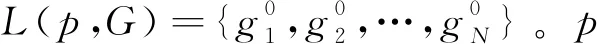
(10)
其中,|·|表示在集合中有k个样本。p的k互近邻是指2幅行人图像均排在对方排序列表的第k个位置,定义为:
S(p,k)=[(gi∈M(p,k))∩(p∈M(gi,k))}
(11)
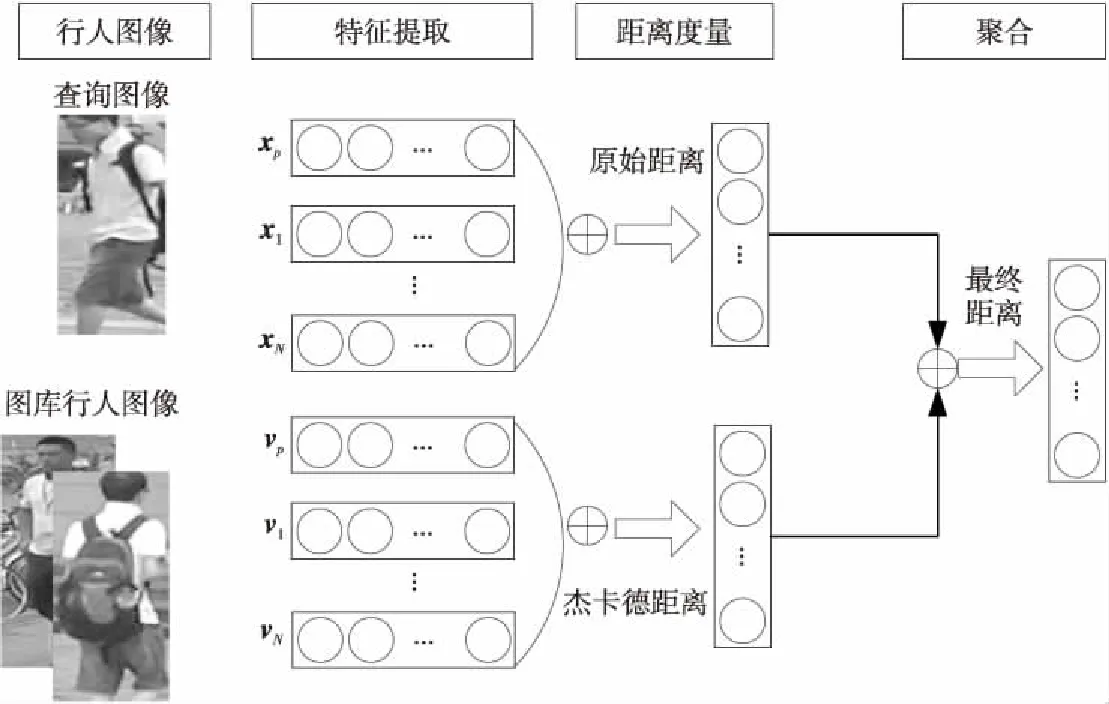
Figure 4 Framework of re-ranking图4 重排序框架
因受到遮挡、光照等变化影响,有些正样本可能不在k互近邻里,因此将S(p,k)加入到更鲁棒的k/2互近邻的S*(p,k)中。取S(p,k)中的任意1个样本q和k/2的互近邻样本得到集合S(q,k/2),并与p的k互近邻集合S(p,k)相加得到S*(p,k),公式如下:
S*(p,k)←S(p,k)∪S(q,k/2),∀q∈S(p,k)
(12)
然后计算p和gi之间的k互近邻特征的杰卡德距离,计算公式如式(13)所示:
(13)
其中,|·|表示集合中候选人行人数量,S*(p,k)和S*(gi,k)共享元素越多,则gi越可能成为正确的匹配。
最后将原始距离和杰卡德距离结合得到pi与gi之间的最终距离,对初始排序表进行重排序,得到最终的距离公式,如式(14)所示:
d*(p,gi)=(1-λ)dJ(p,gi)+λd(p,gi)
(14)
其中,λ∈[0,1],当λ=0时,只计算杰卡德距离;当λ=1时,只计算原始距离。在得到最终距离后,按照最终距离对图库中匹配到的行人图像进行升序排序。
4 实验与结果分析
本文的实验环境是浪潮英信服务器NF5280M4,GPU采用NVIDIA GeForce GTX 1080Ti,操作系统为Ubuntu16.04,深度学习的框架是PyTorch。实验分训练-测试-评价3个步骤。为评估改进后孪生网络性能,采用大型数据集Market-1501(751幅行人图像组成训练集,750幅行人图像组成测试集)和DukeMTMC-reID(702幅行人图像组成训练集,702幅行人图像组成测试集)[13]进行实验。
采用平均精度均值mAP(mean Average Precision)和累计匹配特征CMC(Cumulated Matching Characteristic)曲线2种评价指标,较为关注的是Rank-1(第1匹配率)、Rank-5(第5匹配率)和Rank-10(第10匹配率)。
4.1 实验设置及参数分析
根据实验环境对改进的网络结构进行参数设置,采用随机梯度下降SGD(Stochastic Gradient Descent)优化算法训练网络。训练中,对图像进行数据增强操作,如随机翻转、平移、填充等,采用批训练,批处理尺寸(Batch Size)为32,动量因子设置为0.9,训练的时期(epoch)共60次,前20次学习率为0.1,以后按照0.1的速率衰减。在验证模型中不仅使用了乘积层,又引入了1个均量层,计算的方法是取平方层中特征表示fs和乘积层中特征表示fM的和的平均值,计算公式为:f=(fs+fM)/2,称为均量层。测试中,无数据增强操作,Batch Size取值为256。采用余弦距离进行相似性度量,公式为:cosθ=(fq/‖fq‖2)×(fg/‖fg‖2),fq和fg表示查询图像和图库图像的特征,‖·‖2为特征的L2标准化。
在Market-1501数据集上对参数λ进行测试,然后选取最好的参数应用到DukeMTMC-reID数据集上。从图5可以看出,当λ为0.3时,Rank-1和mAP均取得最优值。
4.2 实验结果分析
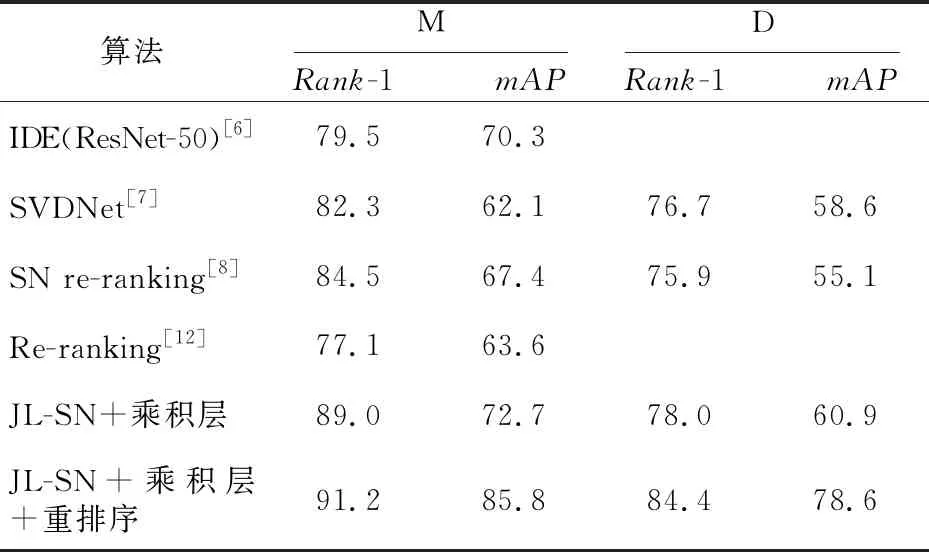
表2是在数据集Market-1501和DukeMTMC-reID[13]上,分别使用不同的验证模型(平方层、乘积层和均量层),然后使用联合损失训练孪生网络得到的实验结果,还包括在使用乘积层和均量层的联合损失模型之后加入重排序算法的实验结果。其中本文使用联合损失优化孪生网络算法(Joint Loss optimized Siamese Network in person re-identification)记作JL-SN。表3是多种算法在2个数据集上的对比。
表2实验结果表明,采用联合损失的孪生网络,在Market-1501数据集上的评价指标相比于仅使用交叉熵损失的经典孪生网络,性能分别提升了9.5%(Rank-1)和12.87%(mAP),加入重排序后2项指标分别提升了11.73%和25.59%;在DukeMTMC-reID数据集上的评价指标中,虽然第1匹配率相比低了约1%,但第5和第10匹配率相比于经典算法均提高了约1%,在加入重排序后,提高了5.26%(Rank-1)和17.91%(mAP)。
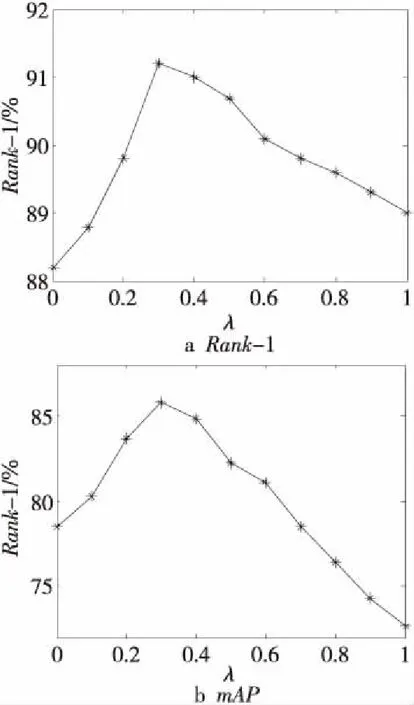
Figure 5 The value of the parameter λ on the Market-1501 dataset图5 在Market-1501数据集上参数λ的取值结果
Table 3 Comparison of various algorithms onMarket-1501(M) and DukeMTMC-reID(D) datasets
表3 Market-1501(M)和DukeMTMC-reID(D)数据集上多种算法对比%
算法MRank-1 mAPDRank-1 mAPIDE(ResNet-50)[6]79.570.3SVDNet[7]82.362.176.758.6SN re-ranking[8]84.567.475.955.1Re-ranking[12]77.163.6JL-SN+乘积层89.072.778.060.9JL-SN+乘积层+重排序91.285.884.478.6
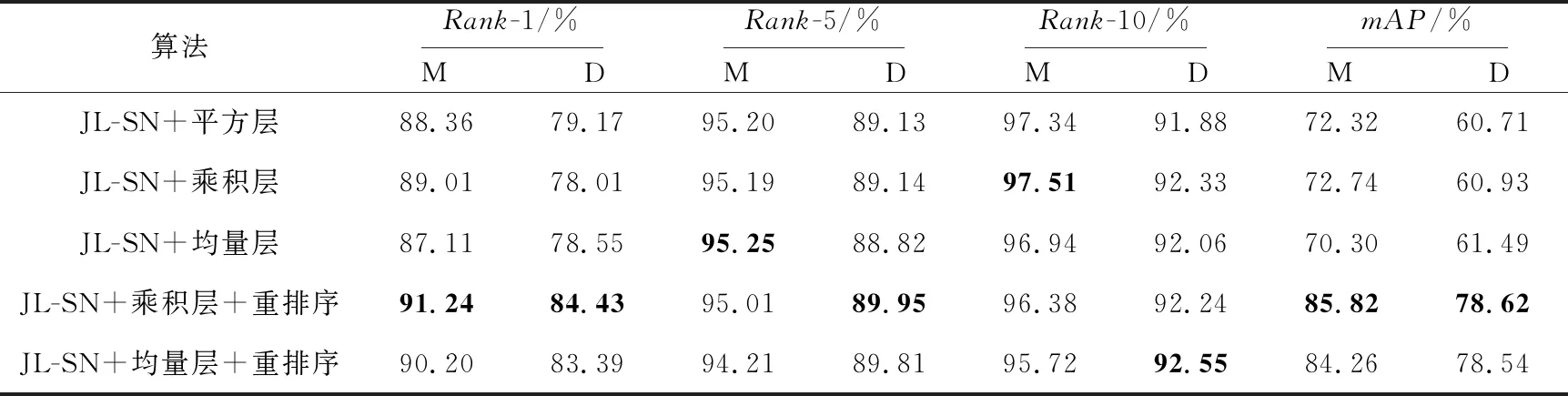
Table 2 Comparison of experimental results on Market-1501(M) and DukeMTMC-reID(D) datasets表2 Market-1501(M)和DukeMTMC-reID(D)数据集上实验结果对比
表3实验结果表明,采用联合损失的孪生网络的行人重识别算法,在2个大型数据集上的Rank-1和mAP均优于对比算法,并且在加入重排序之后的联合损失孪生网络算法,第1匹配率已达到91.2%的高精度。
图6和图7分别是基于经典孪生网络的行人重识别算法(仅使用交叉熵损失函数)和本文算法(使用联合损失函数)的对比和第1错误率(Top1-error)的对比,训练中设置每迭代10次记录损失和Top1-error。从图6和图7中可以看出,使用联合损失监督训练的算法收敛速度较快,Top1-error较低。
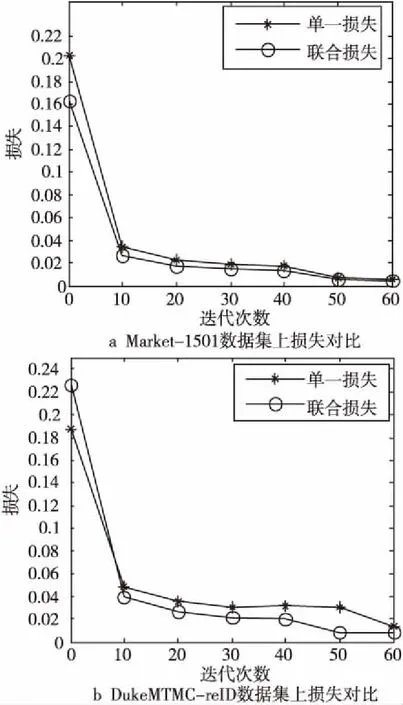
Figure 6 Comparison of joint loss and cross entropy loss图6 联合损失与交叉熵损失对比图
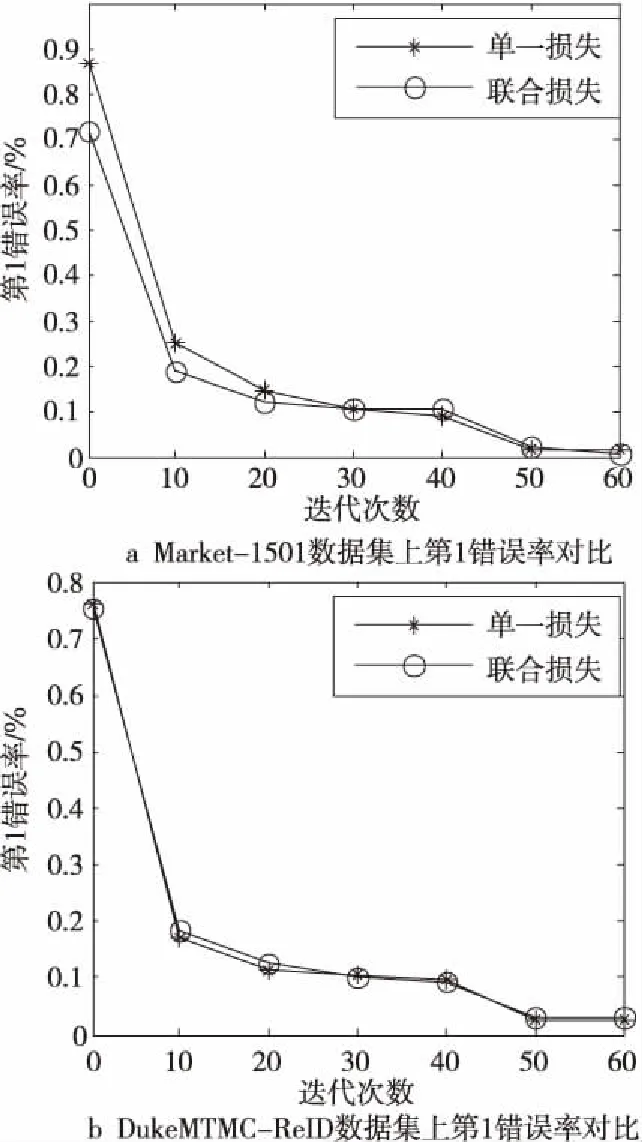
Figure 7 Top1-error rate comparison图7 第1错误率对比图
5 可视化结果
为进一步证明联合损失对重识别任务的有效性,本文在Market-1501数据集上进行了可视化结果展示,如图8所示。其中,图8a和图8c表示基于经典孪生网络的重识别结果,图8b和图8d表示联合损失优化孪生网络算法的结果。第1列表示查询的行人图像,图中选取前10名的排名表,数字1~10表示排名的顺序,粗线框图像代表正确匹配的行人图像,其它图像表示错误匹配的结果。在实验结果中,正确匹配结果排名越靠前,并且正确匹配的数量越多,相应的识别精度和mAP均会提高。在第1组实验对比中,经典算法中正确识别的行人个数为3,本文正确识别行人个数为5,数量的多少影响算法的评价指标;第2组对比实验中,本文算法与经典算法正确识别的行人个数一样,但本文算法识别到的行人排名较靠前,能提高第1匹配率和mAP。

Figure 8 Visualization results on Market-1501 dataset图8 Market-1501数据集上可视化结果
6 结束语
本文在经典孪生网络的基础上进行改进,使用交叉熵损失和Focal Loss联合损失对网络进行监督训练,提高了网络的鲁棒性,得到了分辨力更强的模型;加入重排序算法使图像错误匹配率进一步降低。在两个大型数据集上的实验结果表明,本文算法与经典孪生网络算法相比,识别精度提高较多。
