密集场景的双通道耦合目标检测算法
2020-03-01刘洁瑜魏文晓
刘洁瑜,魏文晓,赵 彤,沈 强
(1.火箭军工程大学,西安 710025;2.北部战区联合作战指挥中心,沈阳 110000)
图像制导是目前精确制导系统中常用的制导方式之一,通过安装在制导武器导引头的摄像机实施拍摄地面信息,对获取的图像进行实时分析处理确定目标的位置信息,因此目标检测算法既要有高实时性又要有高精确度[1]。在空对地这类特殊场景下,图像中包含的背景信息变化多样(光照,遮挡等),目标尺度较小,分布密集的目标较多,加大了检测难度。
近些年,深度学习技术发展迅猛,特别是卷积神经网络(Convolutional Neural Network,CNN)能够自动学习结构化特征,在计算机视觉领域发展迅速。将卷积神经网络应用到检测任务,充分利用了卷积神经网络强大的特征提取能力[2]。随后目标检测领域的发展趋于两大类检测算法,一类是双阶段算法,检测精度较高,但由于其分为两个阶段进行分类预测,速度受限;另一类是单阶段算法,其去除了生成候选区域的阶段,直接回归预测分类,检测速度快,但相比于双阶段算法检测精度有一定程度的降低。为此,众多学者通过增强算法中CNN 的表征能力[3,4]或者平衡正负样本[5,6]的方法提升单阶段算法的检测精度,使其可以与双阶段算法媲美。虽然基于CNN 的单阶段目标检测算法取得了一定的成果,但是在密集目标和小目标的检测上效果不佳。为了提升对小目标的检测精度,2016年Liu Wei 提出了SSD[7]算法,采用了一种多尺度预测的思想,在6 个不同特征层上同时预测候选边界,以适应图像中不同尺度的目标。2017年,Tsung-Yi Lin 提出了特征金字塔网络(FPN)[8],用深层特征对浅层特征的辅助作用,有效地提升了Faster R-CNN[9]检测小目标的精度。之后,DSSD[3],FSSD[10],YoloV3[11],MSSD[6],RefineDet[12],MDSSD[13]等算法分别借鉴FPN 融合上下文信息的思想,建立了多尺度特征融合结构,有效地提升了小目标的检测。图1所示为利用经典的SSD 算法和YoloV3 算法对自制空对地数据集进行密集小目标(舰船目标)检测的测试。

图1 经典算法的检测结果Fig.1 Test results of the classical algorithm
从图1(a)中可以看出,SSD 算法检测失效,没有检测到一个正例。图1(b)中,对小目标具有很强鲁棒性的YoloV3 算法虽然识别出部分正例,但是依旧存在大量漏检问题。因此针对空对地场景中的密集小目标较多的特点,本文以YoloV3 网络为基础算法提出一种密集场景聚焦的双通道耦合目标检测算法,建立了密集场景检测通道和实例检测通道。模仿人眼的聚焦能力,针对空对地视角下密集分布的小目标进行变尺度检测。自制空对地密集目标数据集进行验证,实验结果表明,本方法具有一定的先进性,为密集小目标的检测提供了一种新思路。
1 算法设计
在基于CNN 的单阶段目标检测算法中,输入图像的尺寸往往是固定的。一般采用线性插值的方法对输入尺寸不同的图片进行重建,而对于输入尺寸较大的图像,这种方法极大地牺牲了图像的质量,很可能造成关键信息丢失的情况,尤其对象是密集小目标。如果单纯提升检测算法的输入尺寸,虽然可以解决信息丢失的问题,但是会造成算法的复杂度剧烈升高,对计算机内存产生更大消耗。为此,本文模仿人眼变分辨率检测的思想,单独地对图像中难检测区域进行变分辨率检测。
在视觉搜索任务中,目标通常随机分布在场景中的任意位置。但是在真实场景中,目标的位置往往是受到限制的,例如要寻找舰船目标时,通常会在水面上搜索,而不是陆地上,这便是人眼典型的情景线索辅助式搜索。人眼在对特定目标进行搜索时,对视场中每个位置的关注度(分辨率)是不同的。对一些场景线索强度高的区域,眼球会相应地进行调整[14]。于是,这些区域的视图相对来说更加清晰,分布在此区域中的目标更容易被发现。在空对地这类目标区域实例分布密集、区域之间分布稀疏的场景中,类似人眼这种异常区域聚焦检测的方法将取得很大优势。
为了模仿人眼聚焦搜索的方法,本文设计了一种双通道耦合的目标检测算法,其流程图如图2所示。通过YoloV3 算法检测感兴趣目标,同时也对密集场景区域进行检测。当发现图像中存在密集场景时,保留当前目标检测结果,同时将密集区域的局部图像再次作为输入图像进行检测,直到图像中没有检测到密集区域。将基于YoloV3 算法得到的局部图像的检测结果和全局检测结果进行融合,得到最终的目标选框。考虑到密集场景属于情景因素,与目标实例为不同属性的特征,场景和目标之间耦合关系也较复杂,极大地增加了检测的难度,因此本文在网络后端分为两通道独立地利用YoloV3 算法进行检测。其中一个通道检测密集场景,另一个通道检测目标实例。
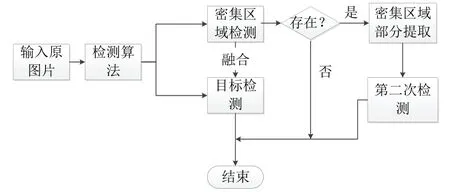
图2 算法流程图Fig.2 Algorithm flow chart
2 网络结构
YoloV3 算法是Yolo 系列第三代算法,兼顾了速度和精度,当输入图像尺寸为416×416 时,在COCO 数据集上精确度达到了55.3%,而速度仅需22 ms。密集场景聚焦的双通道耦合目标检测算法是在YoloV3 的网络框架上进行改进,将密集场景检测网络和目标实例检测网络进行一体化设计,在密集区域与目标实例之间建立耦合关系提升检测精度,算法的结构如图3所示。下面对网络的各模块进行设计。
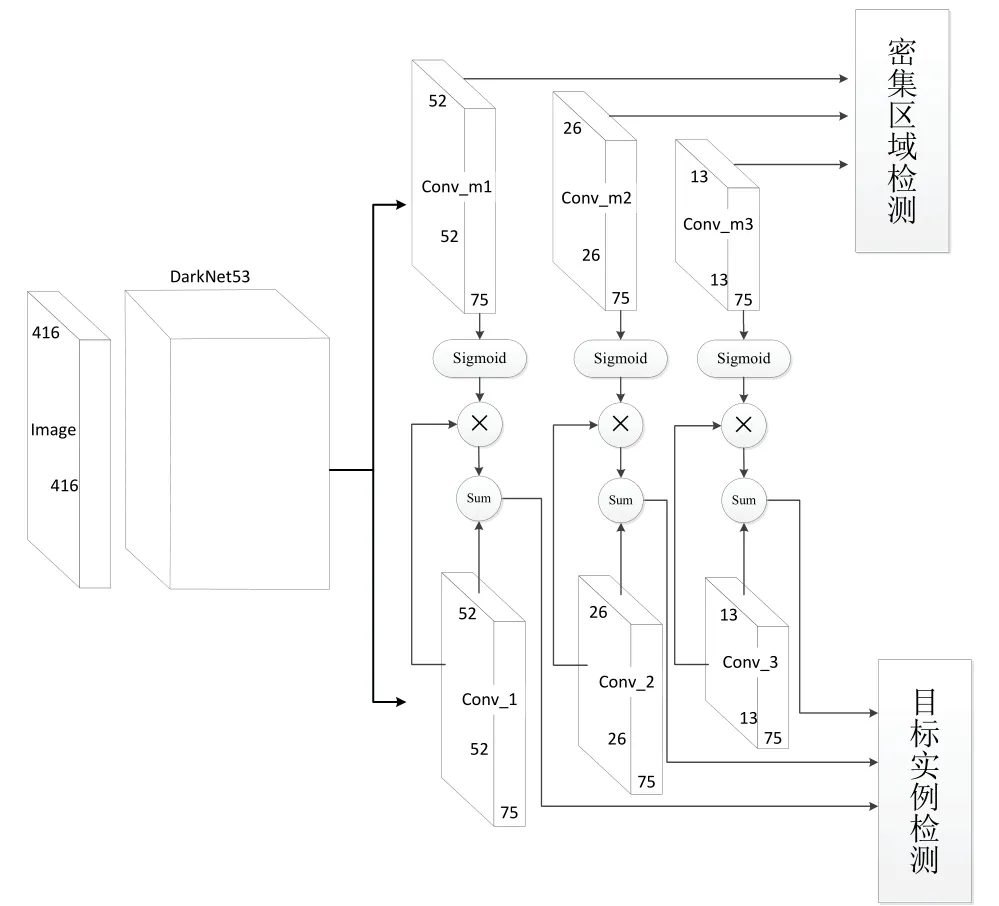
图3 密集场景聚焦的双通道耦合网络结构Fig.3 Two-channel coupling network structure focused on dense scenes
2.1 特征提取网络
本算法采用DarkNet53[11]作为特征提取网络。为了减少特征提取时池化层造成的信息丢失,DarkNet53 采用了全卷积的结构进行下采样。其网络结构和参数如图4所示。图4中Conv 代表卷积层,每层的卷积后都加入了BN(Batch Normalization)层和Relu 激活函数。绿色边框是DarkNet53 的下采样层,特征图每次缩小为原始的一半。黄色边框为残差结构,由若干1×1 和3×3 的卷积层堆叠,每组残差块的输入与输出之间增加了链接路径(shortcut)使得模型在训练时可以动态地调节复杂度,避免出现梯度消失和梯度爆炸的情况。模型总共包含52个卷积层和一个全连接层(在图中省略)。黑色边框为第3、4、5 个残差结构的输出特征图。
2.2 特征金字塔融合结构
算法在特征提取网络的Conv1、Conv2 和Conv3 层分成两个相同的通道进行特征融合,融合结构同YoloV3如图5所示。图中卷积层的参数同图4,每层卷积之后同样经过BN 层和Relu 激活函数。相比较YoloV2 的直通层(passthrough layer),YoloV3 采用FPN 的思想,对深层特征进行上采样之后与浅层特征融合。不同于FPN相加的融合方式,YoloV3 采用的Cat 操作更好地保留了网络各层的信息,而后通过多个1×1 和3×3 的卷积对各通道的信息进行整合,对小目标检测明显加强。灰色框为最终的增强后的特征层,在密集区域检测通道生成Conv_m1、Conv_m2 和Conv_m3 特征层,在实例检测通道生成Conv_1、Conv_2 和Conv_3 特征层。
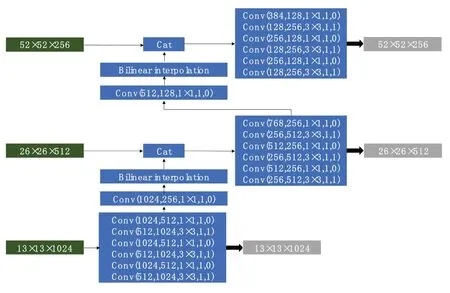
图5 特征金字塔融合结构和参数Fig.5 Characteristic pyramid fusion structure and parameters
2.3 通道耦合结构
文献[15]中提出的情景引导模型证明了局部特征对视觉搜索的辅助作用。在本网络中,密集区域检测通道独立地计算图像中目标的分布特征,对目标分布密集的区域构建了一个凸显地图。凸显地图提取了区域目标的综合属性,对目标的定位分类有一定的积极作用,因此将Conv_m1、Conv_m2 和Conv_m3 特征层与Conv_1、Conv_2 和Conv_3 特征层之间建立耦合结构,如图3所示。采用Sigmoid 函数对目标实例通道的特征图进行选择性增强,密集区域凸显地图的强度决定信息的增强程度。在增强后的特征图上进行目标实例的边框的回归。
2.4 锚 点
单阶段算法首先将初始框(default boxes)按照标注框(ground true boxes)的信息进行编码,将网络生成的边界框(bounding boxes)回归到编码后的初始框上,因此锚点上产生的初始框对算法的精度有极大的影响。分别对密集区域和目标特征图中每个锚点产生3 类初始框,每个通道共9 类边框。传统的YoloV3 算法利用K-Means 算法来确定每个边框的尺寸,考虑到K-Means算法对初始值设置较敏感,并且当数据集较大时,算法容易收敛到局部最优,因此本文在聚类前采用K-Means++[16]算法获取初始值。密集区域的边框尺寸直接按照K-Means++算法进行聚类,而目标边框的样本由两部分组成,分别是密集区域的实例边框和原始图像中的实例边框。由于在网络输入端对图像进行了线性插值的重建,对像素较大的图像来说,某些目标的尺寸会过小,网络无法提取此类目标的特征信息。这些干扰目标的边框样本使聚类中心产生偏离,增加了边框误差,因此本文将重建后尺寸小于15×15 像素的边框样本滤除。最终在密集区域聚类结果为:(51,55)、(99,77)、(70,143)、(186,93)、(131,150)、(206,194)、(149,323)、(317,180)和(333,327),对目标的聚类结果为:(5,3)、(5,8)、(11,9)、(13,20)、(26,12)、(25,29)、(53,28)、(42,58)和(87,77)。
2.5 损失函数
本网络分别检测两个属性的目标,因此损失函数包含密集区域的检测损失和目标实例的检测损失,如式(1)所示。两个损失函数的计算同文献[7],位置损失采用smooth L1,分类损失采用Log loss,如式(2)(3),计算方法如式(4)(5)所示。采用难样本挖掘(hard negative mining)对正负样本进行平衡,正负例比例设置为1:3。
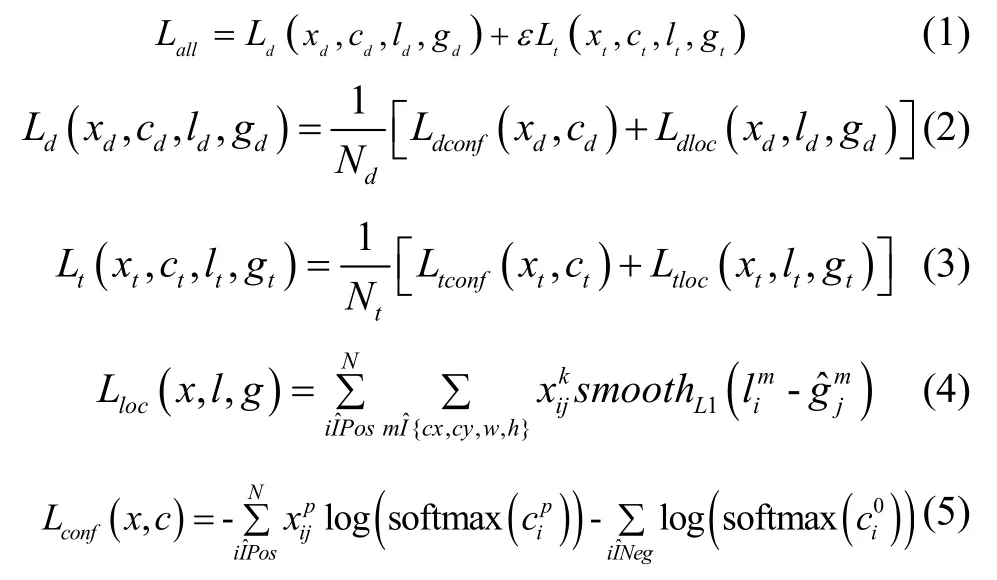
式(1)中,Lall表示网络的总损失,Ld和Lt分别是密集区域和目标实例的损失,ε为目标实例损失的权重因子。式(2)(3)中Ldconf和Ltconf分别为密集区域和目标实例的置信度损失,Ldloc和Ltloc为位置损失,Nd和Nt为被标注框编码到的初始框数目。式(4)中表示第k类目标的第i个预测框和第j个初始框之间的交并比(IOU),若IOU 大于阈值则为1,否则为0(阈值一般取0.5)。为第i个预测框的四个位置参数,为第j个初始框的四个位置参数(相对位置)。按照与初始框的IOU 是否大于阈值(一般取0.5)将预测框分为Pos 和Neg,Pos 表示正样本,Neg 表示负样本。式(5)中表示第i个预测框对第p类目标的预测值,使用softmax 函数转化为概率表述。
2.6 网络的预测
首先对两个通道的预测结果分别采用非极大值抑制进行处理,选择与各通道相适应的交并比阈值去除同类重叠的边框。保留实例检测通道的各类别预测边框,对密集区域检测通道的预测框进行阈值处理,去除一些得分较低的边框。考虑到预测框为固定方位的四边形,无法紧贴目标轮廓,必然会包含大量背景误差。尤其在空对地这种目标密集分布的场景中,预测框之间相交的背景部分对非极大值抑制算法有更大的影响,因此本文采用了soft-nms[16]这种软阈值的方法。而后,将预测得分较高的密集区域从原图中裁剪出来,重新输入到网络中进行检测。若在裁剪后的图像中再次检测到密集区域,则将密集区域的图像继续重新输出到网络中,直到图像中没有密集区域。最后将所有实例检测通道的预测框进行整合,再次使用soft-nms 算法对边框进行筛选,得到最终的目标实例框。
3 验证与分析
实验在Ubuntu16.04 系统的Pytorch 框架下运行,并使用CUDA8.0 和cuDNN5.0 来加速训练。计算机搭载 的 CPU 为 Corei7-8700k,显 卡 为 NVIDIA GTX1080Ti,内存为32G。
3.1 数据集制作
为验证本文算法的有效性,建立了空对地密集区域数据集。本文数据集由谷歌地球上截取的1600 张图像和DOTA[17]数据集上筛选的800 张图像组成。图像包含5 类目标,分别是船、汽车、卡车、飞机和密集区域。标注框为常见的(x,y,w,h)类型,其中(x,y)代表边框的中心位置,(w,h)为边框的宽和高。图像尺寸跨度较大,从最小的300×300 像素到最大的4000×4000 像素。每张图像都包含了至少5 个目标实例,最多甚至包含2000 个目标实例。实例的尺寸最小为30×30 像素,最大为1000×1000 像素(密集目标区域)。按照1:4 的比例,将数据集分为了测试集和训练集。不同于其他常见数据集,本数据集中增加了密集区域这种较为抽象的标注。在标注中,我们基于以下三个原则对密集区域进行描述:
1)对于任意密集边框Mn,其内部包含的目标实例λi满足i>5。
2)对任意Mn内的目标实例λi(xi,yi,wi,hi),总能找到另外一个λj(xj,yj,wj,hj)满足公式<30。
3)若λi∈Mn,则λi的边框所有顶点均在Mn内部。
由于数据集中,拍摄视距为近低空,因此图像场景涵盖范围有限,训练集每幅图像的密集区域边框最多为4 个。部分数据集标注图像如图6所示,采用labelimg 软件进行标注。其中目标实例由黑色实线绿色顶点的方框标注,图6中阴影边框为部分密集区域类别的标注框。
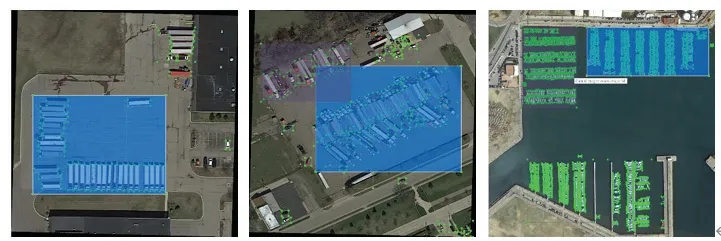
图6 部分标注数据集Fig.6 Partially labeled data set
3.2 算法效果验证
由于密集区域的检测仅为二分类,并且密集区域尺度相对较大,重叠度较低,相对于目标实例的检测来说难度更低。因此在网络训练时,应更注重对目标实例的检测,本文将损失函数的ε设置为0.7。
网络预测阶段,在密集区域检测,目标实例检测和最终的预测框整合三个阶段分别采用了soft-nms 算法。由于密集区域之间分布较稀疏,并且在标注时边框之间重叠较少,因此将阈值设置为0.3;检测目标实例检测的阈值采用常用的0.6;预测框的整合阶段与双通道的检测之间相互独立,并且不会影响检测精度,因此将阈值设置为0.4。
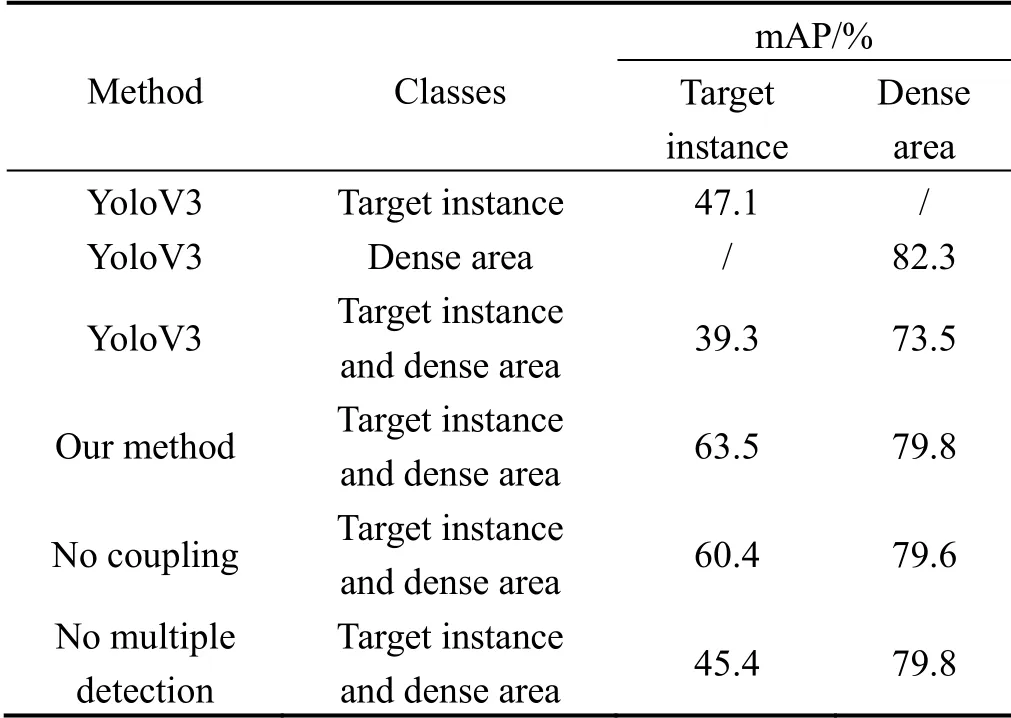
表1 算法有效性分析Tab.1 Analysis of algorithm effectiveness
对本算法的有效性进行分析,如表1所示。目标检测准确度用mAP 表示。若网络仅采用YoloV3 算法对四类目标实例进行检测时,精度仅有47.1%。仅单独对密集区域进行检测时,精度达到了82.3%,远高于目标实例的精度。当同时对目标实例和密集区域进行检测时,平均精度分别为39.3%和73.5%,相比原始算法精度下降较多。这是由于目标数目增加,网络检测难度加大;密集区域这类抽象的目标与目标实例之间存在耦合关系,对分类产生影响;同时,本数据集目标实例的选框较小,而密集区域的选框相对较大,对初始框的生成有更高的要求。本文算法对目标实例和密集区域的平均检测精度为63.5%和79.8%。将本文算法双通道之间的耦合关系去除后,目标实例的检测精度下降为60.4%,证明了通道耦合结构的有效性。将预测阶段的密集区域变分辨率检测去除后,目标实例检测精度下降为45.4%,说明变分辨率检测对算法精度有极大的提升。在本文算法的测试中,密集区域检测通道的检测精度基本维持不变,这是因为在此网络中的耦合结构和预测结构对密集区域通道参数的影响较少。密集区域检测通道的检测精度相对于同时检测目标实例和密集区域的YoloV3 算法有所提升,这是因为本文网络独立地检测密集区域,减少了与目标实例之间的耦合,同时针对该通道设置初始框。然而由于两个通道共享DarkNet53 特征提取网络的参数,因此密集区域的检测精度达不到YoloV3 单独检测时的精度。
为进一步验证算法的有效性,将各阶段图像进行可视化对比。图7为输入的原始图像,尺寸为4969×3569 像素,图中包含的目标为飞机,实例数目为148 架。最小的飞机尺度仅为42×44 像素,在输入网络进行压缩后,降为4×5 像素,在进行特征提取时基本失效。传统的YoloV3 的检测结果如图8所示。

图7 原始输入图像Fig.7 Original input image
图8中,可以明显发现算法对小目标的检测效果极差(图像右下角的区域),尤其当小目标分布密集时,算法将实例之间的特征混淆,出现一个框同时框住多个目标的情况。
在本文算法的第一阶段检测中,密集区域检测通道的结果如图9所示。图中共检测到4 个密集区域,与标注信息一致。

图8 YoloV3 算法的检测结果Fig.8 YoloV3 algorithm detection results

图9 密集区域检测结果Fig.9 Dense area test results

图10 目标实例检测结果Fig.10 Target instance test results
目标实例检测结果如图11所示,当算法耦合了密集区域的信息之后,对密集目标和小目标有了更强的鲁棒性,检测到了更多目标实例。同时,证明了双通道耦合结构的优越性。
在第二阶段,分别对4 个密集区域再次进行检测,结果如图11所示(以左上角和右下角的密集区域为例)。可以发现,在右下角密集区域检测中,原始的难检测目标基本检测正确。而左上角的区域却检测失效,没有一个正例被检测到,这是因为此密集区域的长宽比失调。在输入网络压缩到416×416 像素时,目标实例形变严重,极大的影响了特征的提取和识别。
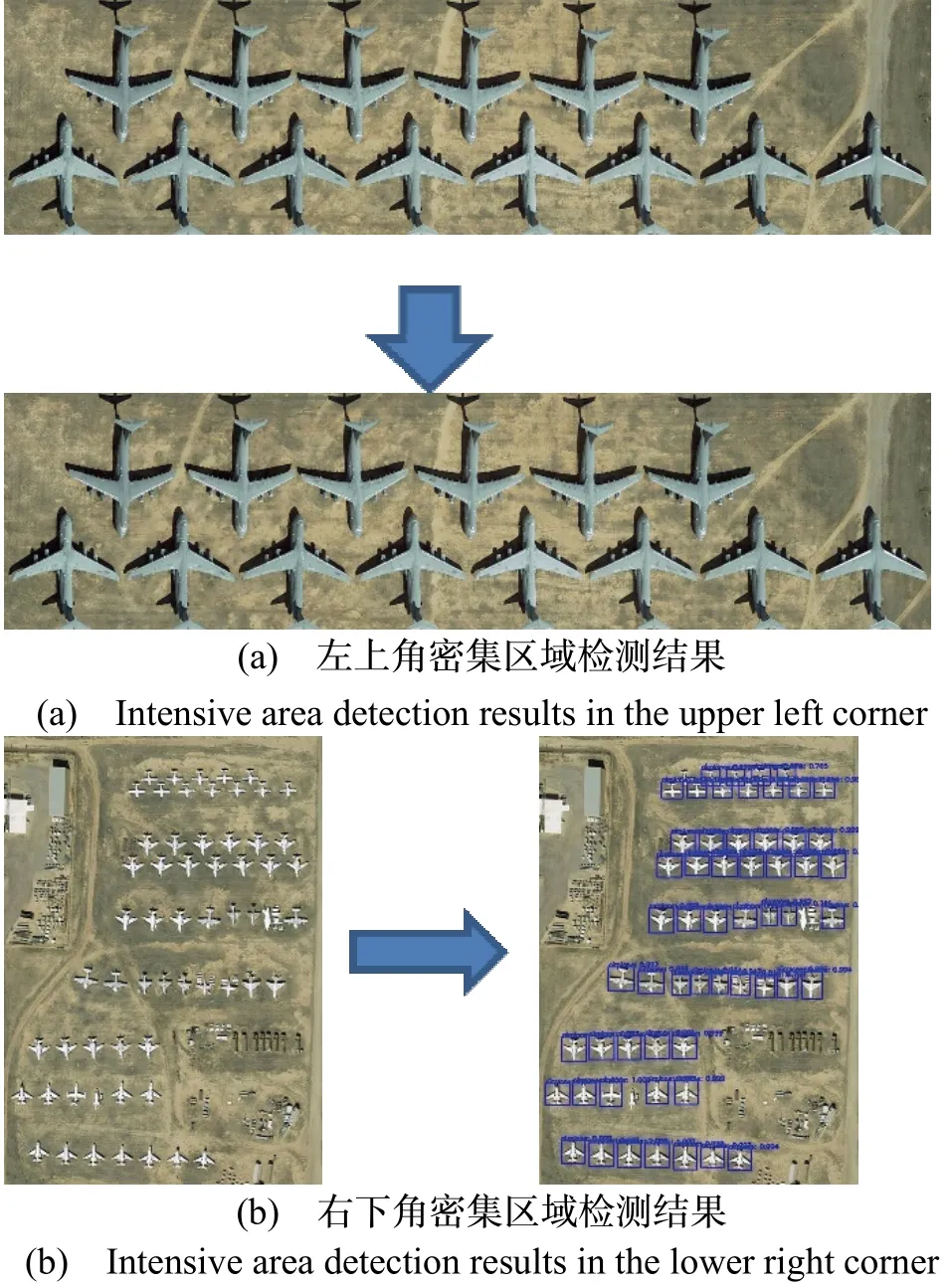
图11 密集区域的检测Fig.11 Detection of dense areas

图12 本文算法的检测结果Fig.12 Test results of our method
由于第二次检测后,没有再出现密集目标,因此最终检测结果如图12所示,目标最终的边框由第一次和第二次检测结果通过soft-nms 算法筛选后得到。图中可以看出,相比传统YoloV3 检测结果和第一次检测结果有了极大的提升。
3.3 算法性能分析
考虑到该算法的实际应用,选择计算速度较快的单阶段检测算法进行对比。单阶段检测算法目前主要分为SSD 系列和Yolo 系列,对传统SSD 算法、YoloV2算法、YoloV3 算法以及目前表现较好的FSSD 算法与本文算法对比,结果如表2所示。其中正例定义为与标注信息的IOU 大于0.5。FPS 为每秒检测帧数。
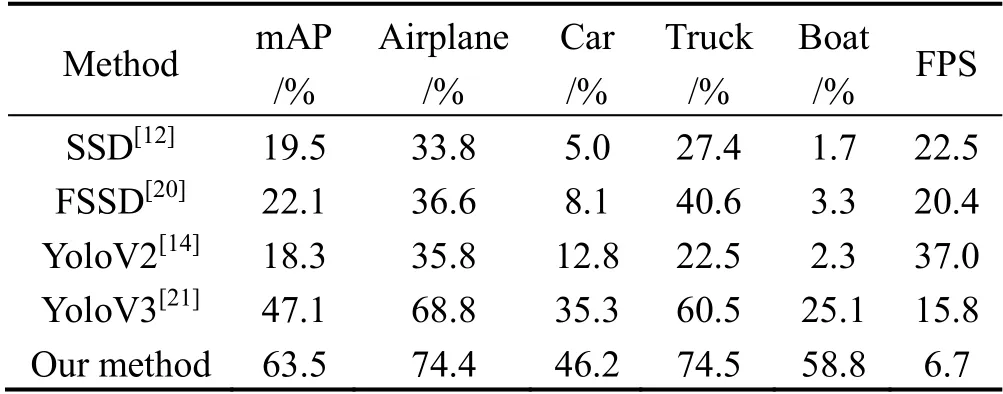
表2 各类算法性能对比Tab.2 Performance comparison of various algorithms
从表中可以看出在检测精度上,基于SSD 网络的检测算法和YoloV2 算法在本文数据集中表现较差,尤其是在检测舰船类目标时基本失效。YoloV3 在本数据集上适应性较强,相比于SSD 算法提升了27.6%的平均精度,并且在舰船的检测上有了大幅度的提升。而本文提出的算法达到了最高的检测精度,相比YoloV3 算法提升了16.4%的平均精度,在各个类别的检测上都有较大提升。在检测速度上,YoloV2 延续了其速度的优势,但是检测精度最低。由于本文算法多次对密集区域进行检测,每次提取的密集区域都要重新经过网络进行特征提取、定位和分类,因此随着密集区域和算法复杂度的增加,相较于YoloV3 损失了一定的检测速度,但是精度却有极大提升。总体来看,本文算法在性能上要超过其他算法。
将本文算法的部分检测结果进行可视化,结果如图13所示。由于数据集中图像尺寸变化较大,因此统一将检测结果压缩到1000×1000 像素。图中可以看出,本文算法对密集小目标的检测度较高,尤其是在检测舰船目标上(以a 为例),相比图1中传统的SSD 网络和YoloV3 网络有较大提升。


图13 本文算法部分检测结果Fig.13 Part of the test results of our method
4 结 论
密集小目标的检测是空对地场景下目标检测领域中一个极具挑战性的课题,为此本文提出了一种双通道密集场景聚焦的算法。首先分析了深度学习目标检测算法在密集小目标检测中存在的问题;而后结合人眼搜索的特点,在传统YoloV3 网络的基础上独立地建立了一条密集场景检测通道,对检测到的密集区域再次变尺度检测;最后自制空对地场景的密集区域数据集,对本文算法进行了验证。实验表明,本文算法能有效地对目标进行检测,相比传统的YoloV3 算法在精度上有16.4%的提升,为空对地密集小目标的检测提供了一种新的思路。然而,总的来说,算法依旧存在较多漏检和错检问题,在非密集区域,小尺度目标的检测度依旧较低,这也是未来需要解决的问题。
