一种融合语义地图与回环检测的视觉SLAM方法
2020-03-01郑冰清刘启汉张小国
郑冰清,刘启汉,赵 凡,张小国,王 庆
(东南大学仪器科学与工程学院,南京 210096)
定位与地图构建(SLAM,Simultaneously positioning and mapping)技术作为机器自身定位以及构建三维场景地图的关键技术,目前已经成功应用到无人车、无人机、快递机器人、智能清洁机器人等产品上[1]。SLAM 技术通过安装在载体上的传感器获取场景信息,在定位传感器自身位置的同时构建环境地图,可基于单目相机、双目、RGBD、激光等传感器实现。与昂贵的三维激光等有源传感器相比,相机价格便宜、提供场景信息更丰富,作为低成本解决方案,基于视觉的SLAM 技术(V-SLAM)近年来发展迅速。
相对而言,现有视觉SLAM 系统的研究重点主要在相机传感器的运动与定位信息估计上,而地图构建部分的模型多停留在点云模型阶段,难以满足更智能化应用场景的需求。因此,为了提供更丰富的空间分析和交互地图信息,在SLAM 技术上增加场景地图的语义信息变得尤为迫切。
传统的语义地图构建方法使用条件随机场模型、支持向量机等方法进行场景及目标的检测和分割,但受性能限制,方法准确率低、效果不佳[2]。近年来,目标检测、语义分割等深度学习网络不断发展,给语义建图带来了新思路。Cheng J 等[3]将CRF-RNN网络和ORB-SLAM结合,使用神经网络获取图像像素语义,通过数据关联模块将语义信息关联到三维点云,形成语义地图,但该方法实时性有限。目标检测神经网络返回的结果并不能很好地契合物体的轮廓[4],为了获得更好的三维语义地图,常联合其他策略。SünderhaufN 等[5]使用单阶多框检测器(Single Shot MultiBox Detector,SSD)网络获取二维语义,基于深度图进行三维分割,再将二者关联形成语义地图。YangS等[5]使用卷积神经网络(Convolutional Neural Networks,CNN)获取语义预测值,结合超像素和占据地图使用条件随机场(Conditional Random Fields,CRF)优化语义标签,提高了语义标注的准确度。Semantic Fusion[6]结合Elastic Fusion 和卷积神经网络,利用帧间长时间密集关联性,将不同视角的语义分割预测融合到一个地图中,可构建出稠密的室内语义地图。Li等人[7]提出一种单目SLAM 的半稠密语义建图方案,算法选择关键帧进行语义分割,再将二维语义信息经帧间的空间一致性处理后映射成三维语义信息。与上述思路不同,SLAM++[8]通过对比、匹配处理后的实时观测数据和预先建立的数据库,可构建对象级的地图,但该方法限制了系统处理目标的种类,可拓展性差。
与此同时,目前一些先进的开源SLAM 系统多依赖于静态环境假设,然而真实环境中存在大量的动态物体,这些运动特征如果参与解算会严重影响位姿解算精度,动态环境中静态对象的假设会导致整个SLAM过程的恶化[9]。
针对上述问题,本文提出一种融合语义地图与回环检测的视觉SLAM 方法。本文算法基于我们前期研究成果[10]改进,原算法在室内动态场景下表现优异,但其回环检测模块的特征点权重调整策略计算量较大,且模块间的强耦合性限制了系统的优化。鉴于此,本文融合语义信息,去除特定动态障碍物对系统的影响,可实现更高效精准的回环检测;另一方面,已有研究成果缺少对场景地图的高级表达,本文融合语义信息和分割后的点云聚类信息,通过构建条件随机场模型实现语义地图的构建。
1 算法框架
本文的系统框架在文献[10]基础上针对室内动态场景提出语义的改进回环检测算法,并针对点云模型空间分析和交互性差的问题提出语义地图的构建方案。系统采用多线程结构,除了文献[10]中详细描述的跟踪线程、局部建图线程和回环线程外,添加了单帧语义识别线程和语义建图线程。
如图1的上半部分所示,本文SLAM方法使用文献[10]中分析的视觉定位算法对每一帧图像进行相机位姿估计,并将图像坐标信息投影到世界坐标系获得特征点三维信息,利用目标检测算法对关键帧的场景目标进行检测和边框提取,结合关键帧的位姿、语义标注信息和特征点向量集进行场景的回环检测。图1的下半部分描述了语义地图的构建过程,结合场景结构信息和点云表面凹凸性对前端输出的无规则点云地图进行分割,然后使用CRF数据融合算法将分割的点云场景与场景语义信息相融合,得到3D的场景语义地图。
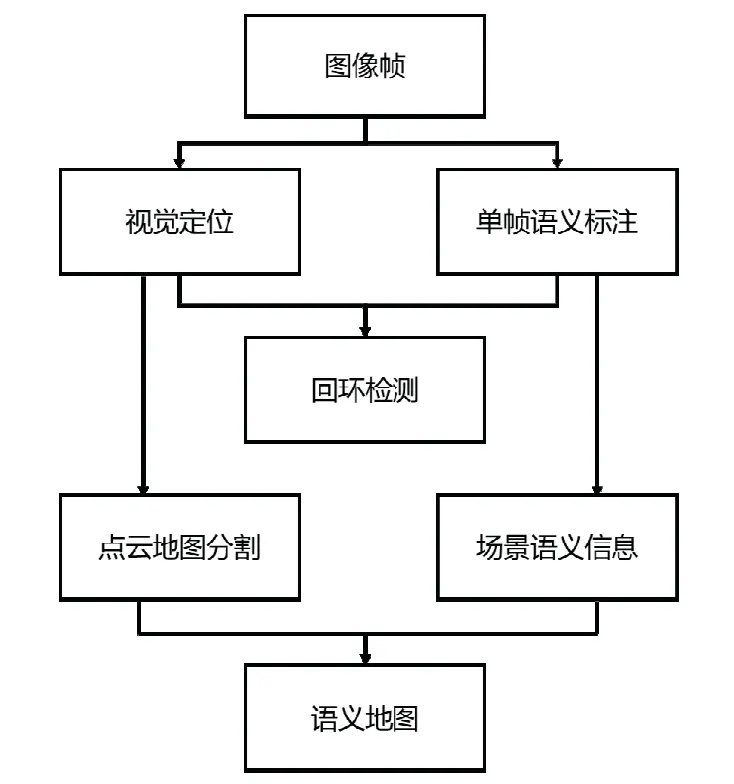
图1 RGB-D SLAM 算法框架Fig.1 The framework of the proposed RGB-D system
2 语义回环检测
随着相机不断运动,系统计算出的相机位姿和点云位置会随着时间产生累积误差,且这种误差无法因局部BA 优化完全消除。回环检测模块将当前采集到的图像与之前访问过的场景图像进行匹配,利用此约束消除累积误差,是保证SLAM 系统准确建图并维持图像一致性的优化方法。
2.1 回环检测模块的基本原理
回环检测的核心是场景识别算法,本文场景识别的算法基于词袋(Bag of words,BoW)模型[11],该算法通过视觉单词来描述图像集中的特征。视觉词典通过预训练生成,使用特征出现与否以及出现的次数等信息生成图片对应的特征向量,比较不同图像之间的特征向量来判断它们之间的相似程度。SLAM系统对所有关键帧生成描述符空间的特征向量,通过比较已有的描述向量集判断回环。
现实问题是,在动态场景下运动物体在场景中的移动轨迹难以预判,可能会造成回环检测失效:一方面,当运动特征点占据图像帧较大比重时,系统可能会因为检测到同一运动物体而将不同场景误判为回环;另一方面,在同一场景下若运动物体离开或出现,可能造成图像帧特征点不匹配,导致系统难以准确识别出当前正确的回环。
为了补偿动态环境中的定位制图漂移问题,文献[10]在系统的词袋方法中集成了特征点权重调整策略,但该策略依赖于跟踪线程中对所有视频帧特征点的检测匹配操作,不同模块之间的耦合性和计算量较大。考虑到现实场景中的移动物体类型通常较单一,且在室内移动物体以人为主,因此本节将融合语义信息,针对特定类型目标对关键帧进行单帧图像的语义检测,并通过去除特定运动物体提高系统的鲁棒性,本方法既避免了传统方法低层特征检测的失误,又可减小特征检测的视频帧范围。
2.2 单帧图像的语义标注
目前针对单帧图像的语义标注主要采用目标检测算法,随着深度学习的飞速发展,深度学习已经成为主流的目标检测算法,它们依据基本原理可分为两类:(1)基于候选区域;(2)基于回归方法。其中,YOLO[12]展示了一种整合分类和定位步骤的新思路,实现了端到端的检测,将目标检测算法的检测速度提升到每秒45帧,从而提供了实时目标检测能力。比较而言,YOLO及其后续算法[12-14]在实时性能上远远优于基于候选区域的目标检测算法,考虑到实时性在SLAM 算法中的重要性,本文采用YOLOv3算法作为语义地图中的语义标注算法。图2展示YOLOv3对SLAM 系统获取相机图片进行目标检测的运行效果。

图2 语义标注示例Fig.2 Semantic label example
2.3 融合语义的语义回环检测算法
融合语义信息的回环检测步骤如下:(1)利用单帧语义标注算法对关键帧图像进行目标分类后,将检测到的移动障碍物边框与关键帧图像尺寸相对应;(2)对关键帧提取ORB特征点[15],并记录特征点的位置及描述子,结合单帧语义标注到的移动障碍物进行静态场景分割;(3)将分割后的图像ORB特征进行视觉单词统计,输入词袋树得到当前帧的视觉单词向量;(4)通过反序文件快速找到关键帧视觉信息数据库与当前帧的共享词汇个数,当共享词汇树大于一定阈值时,保留这些关键帧对;(5)最后通过计算相似度找到最相似的视觉关键帧,当这个关键帧满足共视性、几何一致性、时间一致性要求时[15],即认为回环检测匹配上了历史某一关键帧,得以进行回环校正。
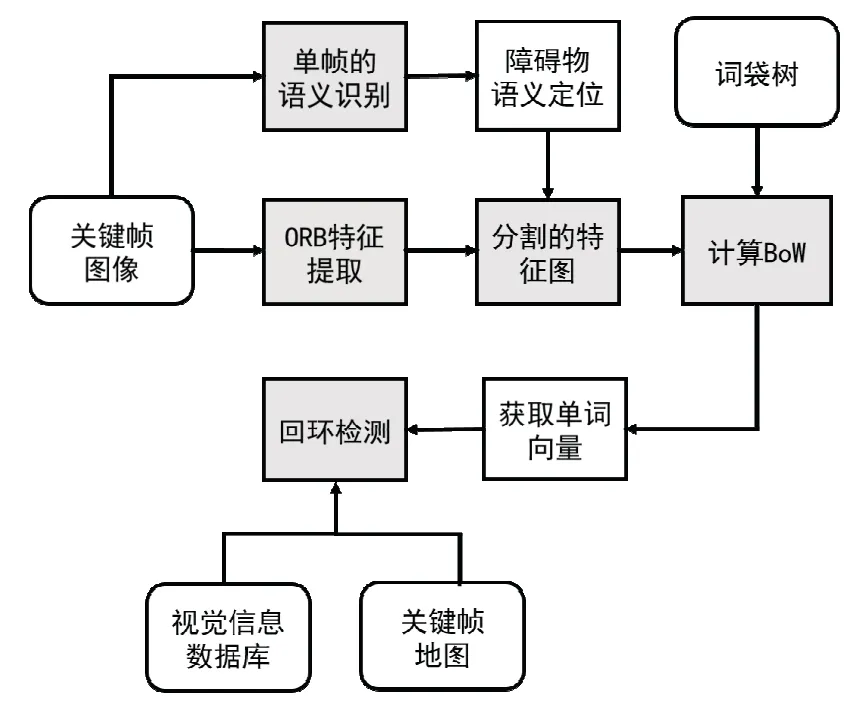
图3 融合语义信息的回环检测流程图Fig.3 Flowchart of loop detection based on semantic information
融合语义信息的回环检测流程图如图3所示,针对关键帧图像,一方面提取图像的ORB特征,另一方面采用单帧语义识别对图像进行多类目标的语义识别,识别到障碍物类别并记录其在图像中的位置坐标。相对于通过词袋模型直接对图像ORB特征进行词汇构建的传统回环检测方案,本文的算法联合目标检测方法,对图像中的移动物体进行图像分割,即分割图像相应位置的ORB特征点。分割后的图像ORB特征点不包括场景中的运动障碍物ORB特征,保留了场景位置的静态属性。对分割后的图像 ORB特征构建单词向量,结合关键帧的三维地图坐标信息,以相邻节点的位置坐标为中心,在半径为R 的圆形区域的关键帧中进行回环搜索,并寻找共有词汇树超过设定阈值的关键帧,根据相似性度量的方法进行匹配相似度计算,确定共视性和一致性原则匹配后,定位到对应帧的关键节点并对此时的地图实施地图累计误差校正。
3 语义地图构建
本节阐述融合场景的语义标注和点云分割的语义地图生成方法,对视频关键帧进行二维图像的语义标注,同时对场景输出点云进行结构分割,最后基于条件随机场模型求解语义地图。其中二维图像的语义标注步骤已在2.2 小节中阐述。
3.1 点云地图分割
RGB-D SLAM 系统可分为稠密和稀疏两类[16-17],稠密RGB-D SLAM 计算复杂度较高且缺少对场景的结构表达。针对这个问题,首先利用特征点图与深度图的匹配关系,输出图像特征经三维映射后的场景点云地图,然后采用超体素聚类[18]的方式对点云进行降采样并将点云转换为面片结构,最后综合考虑场景的全局结构信息和物体局部表面凹凸性质,对面片集进行分类。面片分类操作前需要预先提取场景点云的平面结构信息,并基于平面结构分类面片集,无归属的面片则根据其凹凸性[18]进行分类,整体策略可用式(1)表示:

f(.)=1表示两相邻面片属于同类物体,f(.)=0则表示相邻面片被分类为不同物体。式(1)展示了所有分类的情况:(1)当相邻面片的标签l相同时,即相邻面片属于同一平面结构,被归为一类;(2)当相邻面片均不属于任何一个平面,且局部凹凸性判断显示为凸,则被归为同一类;(3)当相邻面片属于不同平面,则被分割为两类。
3.2 基于条件随机场的语义信息融合
通过将场景点云进行超体素聚类及面片分割,场景中的点云被分割成不同的聚类C={c1,c2,...,cM},针对关键帧进行语义标注则获得其对应点云的语义标签,这样三维场景中的点云就具有语义标签的初始值,最后需要对点云的聚类信息和语义标注信息进行融合。一种简单的融合思路是针对每个点云聚类,基于三维空间信息将语义标注获得的语义标签进行空间映射,然而此方法需要克服的难题有:(1)二维图像的语义标签候选框中存在错误的内容,这些标签被传递到三维点云中,需要根据前后多帧的信息进行指导修正;(2)零散的三维点云标签缺乏局部一致性,需要进一步修正。
通过构建条件随机场(Conditional Random Field,CRF)模型可在聚类的初始标签上进一步优化地图的语义信息。条件随机场可以看作判别式的无向图,依据输入相应的变量,预测输出变量的条件概率分布,被广泛应用于图像分割和自然语义处理领域。通过把点云信息转换成标签,定义相应的能量函数,通过最大化后验概率进行优化,从而完成点云的三维语义标注。为了实现语义地图的局部一致性,减少存储量同时提升计算效率,语义融合地图仍旧采用超体素作为节点。
针对点云中的每个聚类集合ci中的超体素语义标注的问题,构建图G(V,E),假设ci中有n个超体素,超体素V={vi,i∈ (1,n)}构成G中的节点,E={eij}代表超体素vi和vj之间的边。计算ci中的超体素语义标签的问题可以转换为最小化能量方程的优化问题:
语义标注标签L={li,i=1,2,...,n}表示ci中的所有超体素的标注结果,φi(.)表示数据项,φij(.)表示平滑项,k是两项之间的平衡因子,在本文中设置为1。
3.3 数据项构建
数据项定义为将超体素vi标记为标签li的置信度,需要统计每个超体素的初始标签,具体方法为:将三维地图使用八叉树的数据结构表示,超体素中包含的立体体素中标签为p的比例越大则认为超体素属于p标签的可能性越大。
对于每个立体体素,统计其内部三维点的标签直方图,选定统计概率最大的标签作为该立体体素的标签。根据超体素中的立体体素标签,数据项初步定义为:
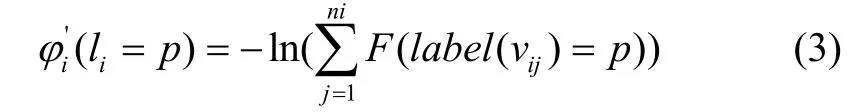
其中假设超体素vi中的立体体素个数为ni个,分别表示为vij,j=1,2,...,mi,label(vij)表示立体体素vij的标签,F(.)定义为:
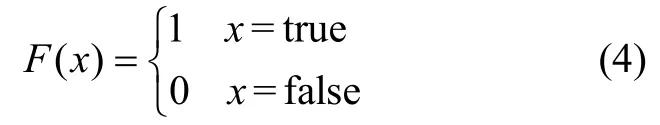
考虑到二维图像的语义标签候选框中可能存在错误,如图2语义判定为bowl 的物体其实是胶带,在tvmonitor 和keyboard 的语义候选框中包含了桌面和背景等与被检测物体无关的噪声信息。这些错误的语义信息传递到三维空间中将会导致错误的语义地图信息,上述问题可以根据前后多帧的语义信息进行修正,并通过融合多帧观测修正数据项以获得更准确的语义信息。将每一个超体素vi的质心xi投影到前后K帧关键帧图像上,对投影得到的mi个点xij(j=1,2,...,mi)的标签做统计,投影得到的点中标签为p的比例越大则认为超体素vi类别为p的可能性越大:
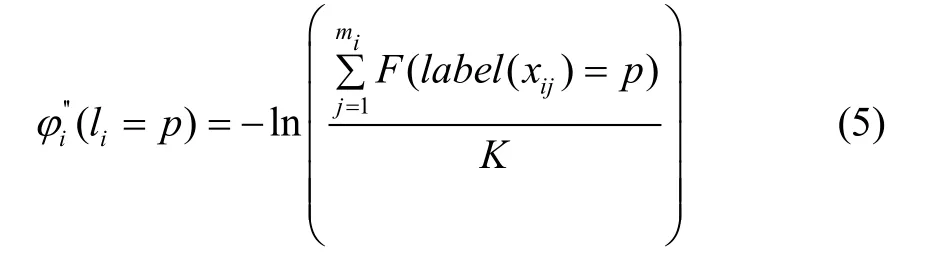
综合上述两点,数据项构造为:
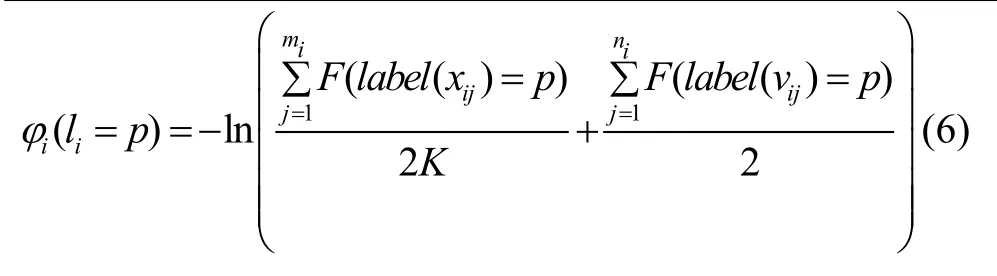
3.4 平滑项构建
点云地图的语义标签平滑操作常基于以下假设:三维点云中相邻节点的标签倾向于一致。本文基于此,针对每个聚类中的每个超体素vi,找ni个同聚类中与其最近的超体素,针对这ni个超体素vj,定义平滑项如下:
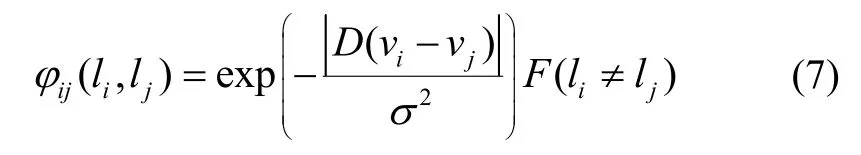
其中D(vi-vj)表示超体素vi和vj质心的距离,当被选中的相邻超体素与当前超体素属于同一聚类,且不属于同一语义标签时φij(li,lj) ≠ 0;当平滑项不为0时,vi和vj距离越近,平滑项能量越大,起到惩罚不平滑状态的作用。
由于本文的能量函数平滑项φii(li,li)=φjj(lj,lj)=0,而φij(li,lj)>0,满足半度量约束,可使用图割算法求解能量函数。
4 实验及分析
为了验证融合语义信息的场景回环检测和地图构建算法的可行性,本节将从语义地图生成效果和语义回环算法的检测效果两个方面进行实验测试。实验中,使用RGB-DTUM 数据集以及在真实场景中拍摄的数据图像验证本文方法。本章节实验软件配置如表1所示,实验使用的预先训练好的YOLOv3模型[14]的训练超参数设置如表2所示。

表1 实验的软件配置Tab.1 Configuration of experimental platform
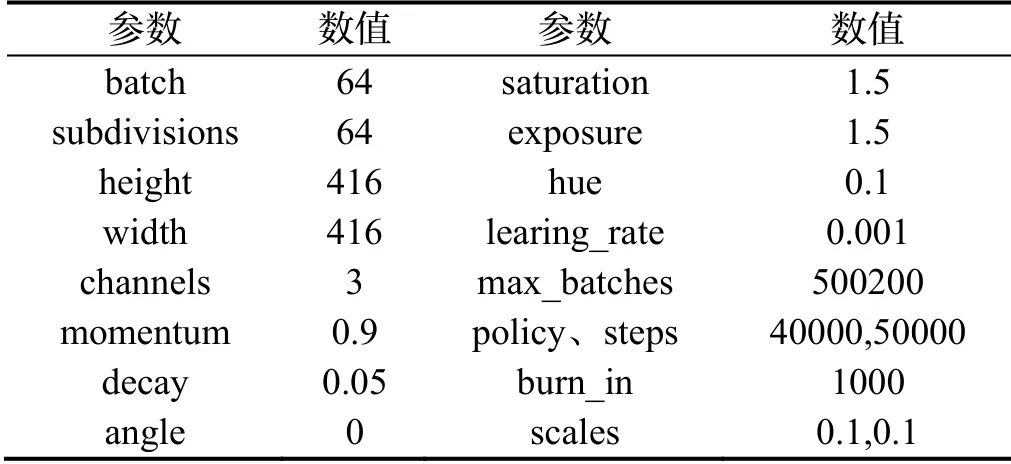
表2 YOLO 网络模型训练的超参数设置Tab.2 Training parameter settingsof YOLOv3
4.1 语义地图实验
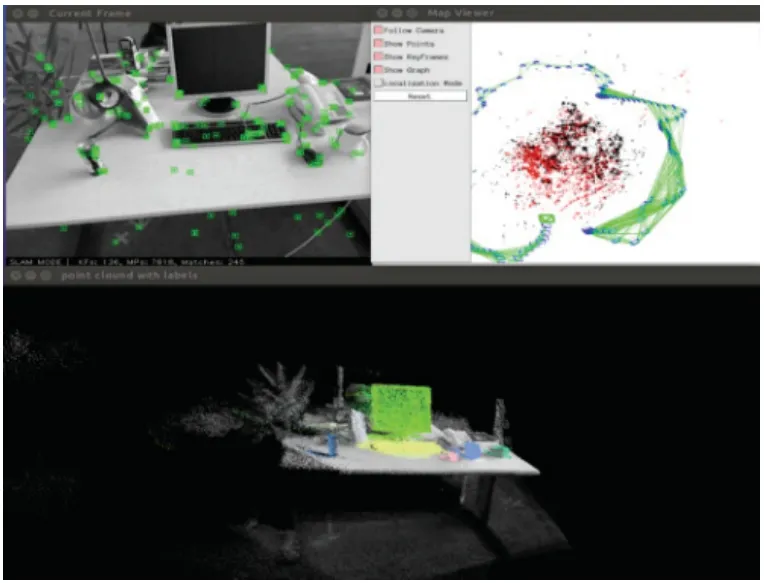
图4 语义地图算法运行界面Fig.4Operation interface of semantic mapping algorithm
如图4是语义地图构建算法的运行界面,图中显示三个窗口,左上角的帧窗口显示当前数据帧图像以及提取到的特征点,右上角的位姿地图点窗口显示相机的位姿轨迹和场景地图点,与文献[15]一致;下面的窗口是带语义标签的点云图,由目标检测算法检测到的语义标注信息映射到原始点云图中所得,将不同的语义物体对应的点云空间标注为不同的颜色用于区分显示。场景分割和语义融合操作在后台运行,原始点云图、带语义标签的点云图、场景分割点云图分别保存至磁盘中的系统运行文件位置,并生成最终的语义地图pcd 文件。
图5、图6、图7展示的是TUM数据集中的Desk序列的原始图、点云地图分割图和带语义标签的点云图。从图6中看出,监视器、玩具熊、桌子和地面这几个物体都被有效地分割区分,而桌上的盆栽由于其结构复杂度较大难以分割,除此之外,桌面上的键盘、鼠标和水杯的特征点也与桌面融为一体。图7是将目标算法检测的语义标注信息映射到原始点云的语义标签点云图,可以看到检测出语义的物体对应的点云空间被标注为不同的颜色,如绿色的监视器、黄色的键盘等等,实验中是对带标签的点云进行后续操作,颜色仅用于显示。
图5、图6、图7展示的是TUM数据集中的Desk序列的原始图、点云地图分割图和带语义标签的点云图。从图6中看出,监视器、玩具熊、桌子和地面这几个物体都被有效地分割区分,而桌上的盆栽由于其结构复杂度较大难以分割,除此之外,桌面上的键盘、鼠标和水杯的特征点也与桌面融为一体。图7是将目标算法检测的语义标注信息映射到原始点云的语义标签点云图,可以看到检测出语义的物体对应的点云空间被标注为不同的颜色,如绿色的监视器、黄色的键盘等等,实验中是对带标签的点云进行后续操作,颜色仅用于显示。

图7 带语义标签的点云图Fig.7 Point clo ud with semantictags
图8是融合了语义标注信息图和点云分割图生成的语义地图,地图中不同颜色代表的语义物体可在色卡中读取。可以看出,在点云分割图中被合并到桌面平面的键盘、水杯和鼠标通过语义信息与背景桌面很好地区分开来,而基于多帧的语义融合算法,场景中结构复杂的盆栽也提取成功。

图8 RGB-D TUM 数据集语义地图实验图Fig.8 Semanticmapping testsof RGB-D TUM datasets
4.2 语义回环实验

图9 测试数据集场景Fig.9 Datasetsfrom the laboratory and the campus
为了测试语义回环模块在真实环境中的表现,在如图9所示的实验室环境中进行测试,测试数据集均为PNG格式的1560*1080图像,共进行4次测试,每次测试包括一到两次回环。
本文统计回环检测评价指标真阳性(TruePositive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(False Negative,FN)的出现次数,并计算准确率P(Precision)和召回率R(Recall)。实验场景中不同回环检测算法的检测表现如表3所示,分别是文献[15]中的传统词典法和本文的语义回环算法。
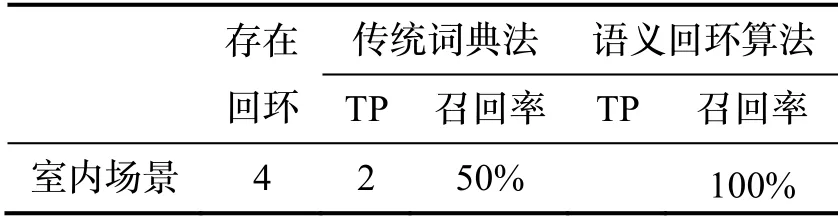
表3 不同回环检测算法的对比表现Tab.3 Comparisonof different loop-detection algorithms
传统词典法和语义回环这两种算法在实际场景中的准确率为100%,即实验中算法没有出现FP(事实上并不是回环,系统错误地认定为回环)的情况。在SLAM系统中,FP会导致错误的回环从而严重影响系统精度,系统在判断场景相似度后会进行位姿解算、图像特征匹配检验、地图点匹配检验等核验步骤,从而避免FP现象。实验室场景包含相似的键盘、显示屏、桌椅等,尽管包含相似物体的关键帧之间词袋相似度很高,系统运行过程中回环检测模块区成功分出了包括相似物体的两个场景,并没有错识成回环。
在召回率方面,本文的语义算法则明显超过传统词典法。在如图9所示的室内场景中,由于运动物体(人类)占比较大且运动物体上检测到的特征点较多,传统词典法未能检测到部分回环,而语义回环算法则全部检测成功。图10给出了实验室环境下系统使用两种回环算法的运行轨迹对比图。
将使用语义回环检测算法的系统所获得的运行轨迹与传统词典法进行对比。传统词典法利用关键帧场景中的ORB 特征点计算相机位姿,利用词袋模型进行回环检测,所获得的轨迹如图10(a)所示。语义回环检测系统检测出特定的动态物体(该场景中为人),并在词典中去除动态物体的特征向量,提高静态物体特征点的百分比。从图10中标红色实线圈的地方可以看出,语义回环检测系统检测出回环,而传统词典法在对应的地方并没有检测出回环。
为了进一步获得语义回环检测算法的定量实验结果,在TUM 数据集上进行对比实验。具体实验中,以ORB-SLAM2 系统的VO 部分为载体,分别加入不同回环检测模块,对比系统的整体精度表现。表4展示了对原始的词典回环检测法和语义回环算法进行对比的实验结果,测试对象包括静态环境图像序列、低动态序列和高动态序列,其中静态、动态和高动态的定义见文献[9]。
(1)从表4整体可以看出,使用语义回环检测算法能使系统在大多数高动态序列中表现有所提升;而在低动态场景和静态场景下,使用改进的回环检测算法的系统性能与传统词典法几乎一致,其原因是这些场景中不包括动态回环,即回环的场景前后并未出现动态物体。
(2)在低动态场景desk_person 序列中,系统的跟踪线程运行过程中使用运动模型跟踪失败,系统继而使用了关键帧特征比对法,提取并匹配当前帧与最近关键帧的特征并解算位姿,这个过程中使用了词典加速匹配进程。具体做法是在已经获得图像特征点集合的基础上根据词典对特征进行分类,用分类后的特征类别代替原本的特征描述子,即用数字代替向量进行比对,显然速度可以大大提升。而本文的语义回环检测去除了动态物体的特征点,使用静态特征进行匹配并解算位姿,所以算法精度有所提升。该结果表明,改进后的词典法在帧间匹配也可起到提高精度的作用。
(3)在高动态场景中,walking_static 序列没有性能提升的原因是该序列中相机基本保持在同一位置,未能满足“回到同一场景”这一回环检测的基本条件。
(4)在高动态场景walking_xyz、walking_halfsphere和walking_rpy 中,使用语义回环检测算法的系统表现相比原算法提升了48.1%,这三个数据集的相机分别按照左右上下(xyz)、画半圆(halfsphere)、旋转(rpy)三种方式移动,而实验者则在场景中随意移动,由于在回环的检测中去除了实验者的动态特征点,提高了回环检测的准确度从而提升了系统精度。其中walking_xyz 的精度提升特别明显,一方面是因为去除了动态物体的回环检测,另一方面是因为相机移动较快,系统偶尔会出现跟踪失败的现象,此时系统会开启重定位模块,重定位时需要使用词典加速当前帧与关键帧集的特征匹配,由于词典中去除了动态物体的特征点,所以精度有了较大提升。
表5展示了静态加权的回环检测算法文献[9](下文中简称为静态加权算法)以及本章提出的语义回环算法在TUM 动态数据集上的对比结果。
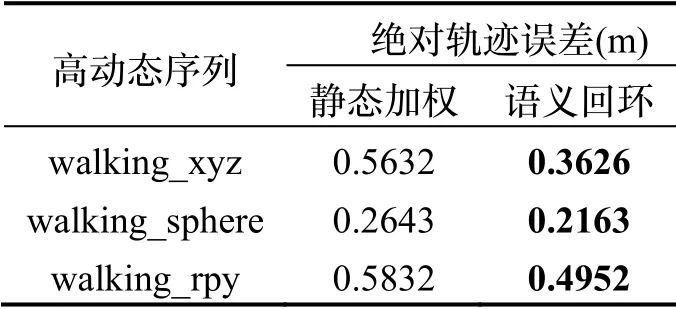
表5 静态加权算法和语义回环算法在TUM 序列上的表现Tab.5 Performance of systems with different loop detection algorithms on TUM sequences
从表5可以看出语义回环检测算法在高动态序列中表现优于静态加权算法。因为静态加权算法使用低层特征检测动态物体,基于跟踪线程对静态点和动态点之间距离的判断来提取静态区域,这一检测过程容易受到静态阈值的影响,针对特定物体的准确度不及语义标注算法。但静态加权算法也有其优点,它的使用不受运动物体种类的限制,预训练和参数调试的过程也相对简单。
由于语义回环检测算法在动态场景下的表现优于静态加权算法,将已有研究成果,文献[9]中的静态加权算法替换为语义回环检测算法,并在动态数据集上进行绝对轨迹标准误差的对比,结果如表6所示。
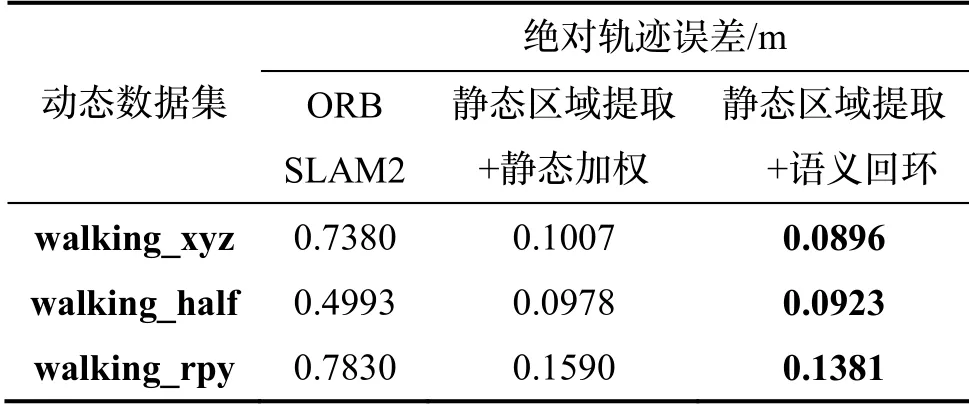
表6 三类算法的绝对轨迹误差比较Tab.6 Comparison of absolute trajectoryerrorsof three types of algorithms
从表6可以看出,将回环检测方案更新为语义回环检测算法后,动态场景下的整体系统精度又有了小幅提升,由于前端的静态区域提取算法已经在跟踪线程规避了动态物体的误差影响,所以相对已有研究成果精度提升幅度不大,最新系统相比ORB-SLAM2精度在动态场景下提升了83.9%。将不同算法在walking_rpy数据集中的定量平移误差进行比较,包括X 方向和Y方向,实验结果如图11所示。
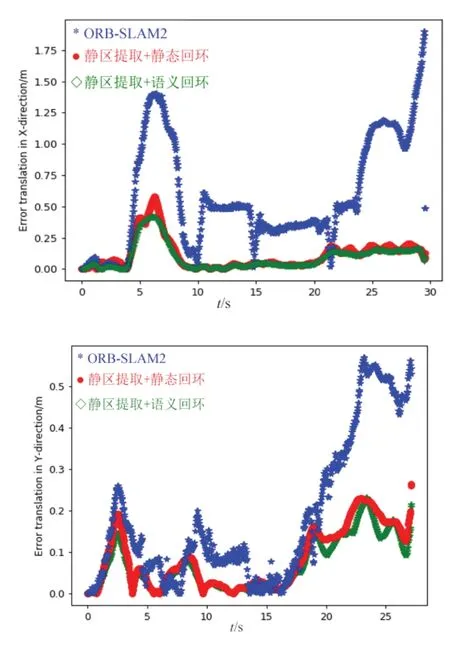
图11 不同算法在walking_rpy 数据集中的平移误差比较Fig.11 Translation errorsof different algorithmsin walking_rpy dataset
从图11可以看出在该序列中,本文改进算法的平移误差相对ORB-SLAM2更小,能提供更稳定的性能和准确的位姿解算。综上所述,在相机移动的动态场景下,使用本文的语义回环检测算法能使得SLAM 系统的表现大大提升,而在低动态场景和静态场景下性能保持不变。在使用语义标注算法代价不高,即系统的运行空间和运行效率不受目标检测算法影响的情况下,采用语义回环检测相比静态加权的回环检测算法可以得到更好的定位效果。
本小节在数据集和实际场景中,从语义地图生成效果和语义回环检测的性能评估两个方面进行了实验测试,证明了融合语义信息的回环检测和地图构建算法的可行性。
5 结论
本文提出了一种融合语义信息的语义地图构建和语义回环检测算法。针对点云地图特征信息层次较低、缺乏实用性的问题,提出语义地图的构建方案。利用目标检测算法针对关键帧进行二维图像的语义标注;接着结合场景结构和点云凹凸信息对点云地图进行分割;最后基于条件随机场模型将二维图像的语义标注信息与场景分割的聚类信息相融合求解语义地图。针对动态场景下运动物体在场景中的移动轨迹难以预判、造成回环检测失效的问题,提出结合语义信息的改进回环检测算法。基于关键帧的语义标注信息,结合运动特征点去除的思路对词典法进行改进,通过去除特定动态物体提高动态场景下的系统定位精度。通过在数据集和室内真实场景中的实验证明了上述算法的可行性,本文的语义回环算法在室内动态场景下相比使用原算法的系统精度提升了48.1%。
本文的语义地图构建算法为全局算法,后续将研究增量的地图构建算法提高实时性。此外,在构建语义地图时,运动物体会导致场景地图中出现重影,后续研究也将着重于去除运动障碍物的三维语义地图构建方法。
