一种整合语义对象特征的视觉注意力模型
2020-02-24赵歆波
李 娜, 赵歆波
(1.西北工业大学 计算机学院,西安 710129; 2.陕西省语音与图像信息处理重点实验室,西安 710129)
视觉注意力机制是人类视觉快速扫描场景后获取高度相关信息的大脑信号处理机制.视觉注意力模型是指计算机利用视觉搜索得到的各种特征,估计人类注意力显著信息的技术.对于许多计算机视觉任务,人类视觉注意力建模是重要的科学问题.例如,对于视频压缩,人眼感兴趣区域(Region of Interesting, RoI)是需要重点保留的关键信息.对人机交互和广告设计来讲,准确了解人眼在场景中哪些信息感兴趣,可以更好设计出满足用户需求的产品.生物认知学为人类视觉注意机制研究提供了生物学基础[1].当人眼观察视觉信息时,经大脑特定部位选择性地感知的信息会在人眼视网膜的黄斑上成像.例如,功能磁共振成像(Functional Magnetic Resonance Imaging, FMRI)显示人类大脑的梭形面部区域感知面部信息[2],大脑的旁海马区感知地方和建筑物[3-4]信息.受认知研究启发,本文记录并分析了人眼在观察场景时的眼动数据,得出语义对象区域为人类关注的高意识区域,这些语义对象特征会更吸引视觉注意力.
近年来,众多科研工作者对人眼运动进行了研究,涌现出大量基于不同理论的视觉注意力模型.一些研究人员在低级注意力模型上取得了进展.其中最有影响力的是由Itti[5]等提出的基于特征整合理论[6]的自下而上注意力模型.该理论利用颜色,方向和强度等低级特征预测图像中吸引人眼注意的显著区域.基于神经反应去相关的思想,Diaz等[7]提出了自适应白化显著性模型(Adaptive Whitening Saliency, AWS).Zhang等[8]提出了自然统计显著模型(Saliency Using Natural statistics, SUN),该模型将视觉特征的自身信息作为自下而上的显著性.Torralba[9]提出了一种用于视觉搜索的贝叶斯框架用于显著性计算.Harel[10]等提出了基于图论的显著模型(Graph Based Visual Saliency, GBVS).Vig等[11]利用机器学习方法计算图像区域的显著性.Tavakoli等[12]利用无监督模型提取的特征用于显著性计算.尽管这些模型表现良好,但却忽略了语义对象特征对人类视觉注意力的吸引.
Judd等[13]和赵等[14]将低级特征和语义特征整合到了学习框架中.Kummerer等[15]和Mahdi等[16]利用预训练的深度学习模型提取低级特征及语义特征用于显著性预测.但是,这些模型使用的语义特征比较有限,而实验结果表明,视觉注意力模型的性能通过语义特征的引入获得了极大地提高.虽然这些模型使用了语义特征作为自上而下的指导信息,但提取的语义信息类别很有限.
人类感知语义信息的过程涉及了大量大脑感知神经,其过程极其复杂.然而,深度学习在图像语义分割领域成果斐然,涌现了各种性能优良的网络,如(FCN[17], DeepLab系列等[18-19]),深度学习网络本质就是人脑的仿生结构,而图像语义分割就是计算机自动从图像中识别并分割出对象区域,这与本文提取出在人眼观察场景时人脑感知的语义对象特征的目的不谋而合,因此,本文将性能优异的语义分割网络迁移到视觉注意力模型中,来提取语义对象特征,大大增多了语义信息的类别数量.
此外,除了由人类认知控制的自上而下的视觉注意外,还有一种潜意识的机制,即自下而上的视觉注意力,吸引人眼注意一些低级特征[6].因此,本文经过分析,提取了28个吸引人眼的低级特征,除RGB颜色,亮度,强度等常见的低级特征之外,由于Lab颜色模型是基于人对颜色的感觉,所以本文同时提取了Lab颜色空间的显著性特征.
本文利用深度学习网络提取语义对象特征,将其与刺激人眼的低级特征通过支持向量机(Support Vector Machine, SVM)进行整合,训练这些特征与眼动跟踪技术获取的真实注视点之间的映射关系,得到能预测人眼注视点的视觉注意力模型.
1 眼动数据采集与分析
为了研究普通人在观看场景时的视觉行为,本文从用于语义分割的VOC2012数据库[20]里带有语义分割标签的2 913张图像里挑选出研究用的图像.图像选取时最主要的原则是图像中语义对象尺寸不能过大,因为当语义对象尺寸占了图像绝大部分面积时,统计出的眼动注视点落入语义对象区域的数量是没有意义的.同时,兼顾数据库语义对象的多样性,尽可能地均衡了各类语义对象的数量,最终选择了2 000张图像进行研究.然后记录人眼观察这2 000张图像时的眼动跟踪数据,形成新的数据库VOC2012-E.该数据库用于对注视点的定量分析,并为显着性模型的研究提供基准图像.与其他公开语义对象分割的数据集相比,本文建立新数据集的主要动机是分析注视点信息.
本文利用Tobii TX300眼动仪记录受试者的眼球运动,其可以进行高精度和高准确性的眼动追踪.实验中,为保证数据的有效性,每次只播放100张图像,每张图像播放5s,在播放下一张图像前自动进行快速校准,每次采集大致进行10~15 min,共有10名受试者参与实验.
如表1所示,本文统计了每张图像的眼动注视点落入语义对象区域的总数,然后计算出落入语义对象区域的注视点占全部注视点的平均占比,数值超过83.53%,这表明语义对象特征吸引了受试者大部分的注意力.因此,为了提高视觉注意力模型预测的准确性,语义对象特征的引入意义重大.

表1 眼动注视点统计
如图1(b)所示,汇总实验中记录的所有受试者的真实眼动注视点,叠加到原图1(a)上,得到眼动点的分布情况.图1(c)重点突出语义对象与眼动点分布的关系,经过进一步分析,无论目标较大的图像(第8列图像牛),还是目标较小的图像(第9列图像羊),语义对象都吸引了受试者大部分的注意力.图d为将真实眼动注视点进行高斯滤波得到的基准图像,用于第4节的注意力模型的训练.
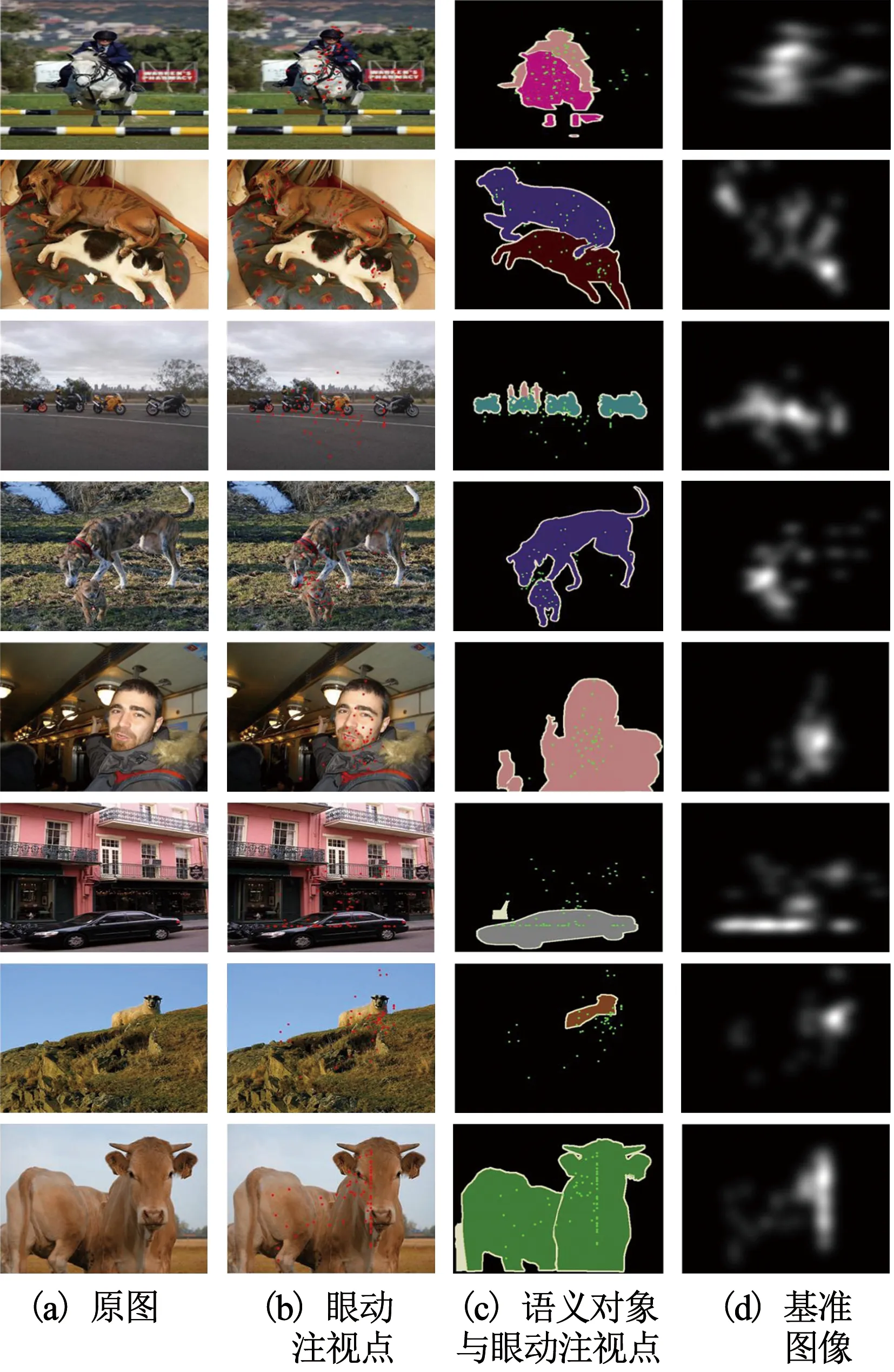
图1 眼动跟踪实验
2 语义对象特征的提取
根据实验分析得出的语义特征提取的必要性,利用FCN网络从图像语义分割的角度出发提取图像的语义对象特征.与语义分割任务不同,本文提取的语义对象特征是否具有精确边缘,并不影响视觉注意力模型的预测人的注视点,但特征提取的时间和硬件成本却对视觉注意力模型的训练至关重要.因此,综合比较了常见语义分割模型,本文利用综合性能最好的FCN-8s网络提取语义特征,同时为了保证特征提取的鲁棒性和有效性,对其进行了改进:采用了参数线性整流(Parametric Rectified Linear Unit, PReLu)函数取代了线性整流函数(Rectified Linear Unit, Relu);使用适应性矩估计(Adaptive monent estimation, Adam)优化网络的学习率.
图2为本文利用的FCN-8s的网络结构.在本文使用的网络结构中,在卷积之后不再使用Relu激活函数.虽然Relu激活函数由于自身只有线性关系,收敛速度很快,但是当输入为负数时,Relu的输出被设为0,导致对应权重无法更新,即该神经元坏死,将会对任何数据都无法响应.为解决这一问题,本文采用PReLu激活函数,其计算公式如下
(1)
式中:a的取值是在0~1之间变化的数,i为不同的通道.如式(1)所示,与Relu函数不同的是,当PReLu的输入为负数时,它的输出非0,从而避免了神经元坏死,而且PReLu只增加了很少的参数,所以只增加了很少的网络的计算量.
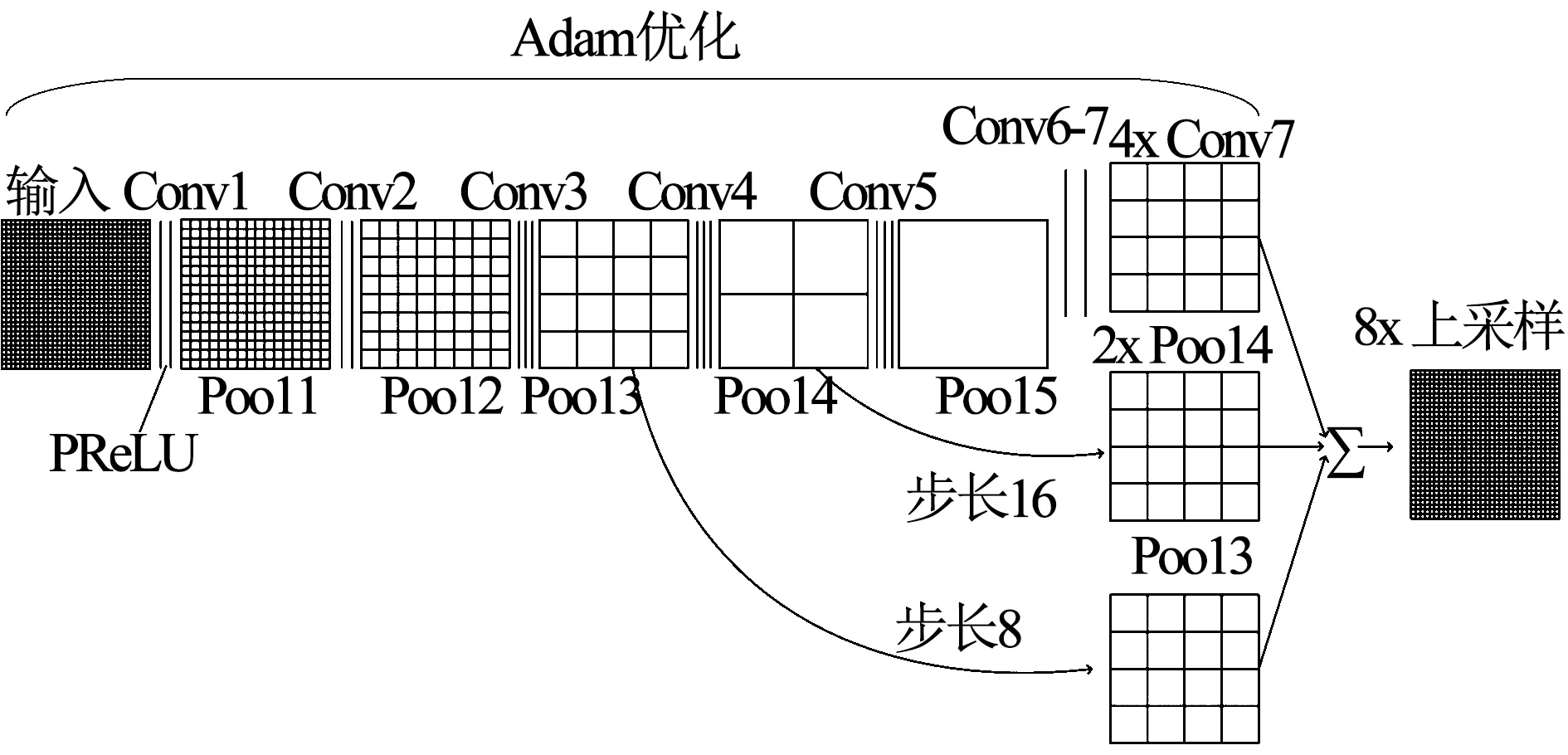
图2 本文使用的FCN-8s网络结构
此外,在网络的训练过程中,本文不再采用梯度下降优化算法,而是利用Adam优化算法调整网络更新权重和偏差参数.梯度下降法虽然是最常用的优化算法,但是为其选择合适的学习率比较难,学习率太小会导致网络收敛过于缓慢,而学习率太大可能会影响网络收敛.而且不同特征应采用不同的更新率,比如,出现频率较小的特征,应有更大的更新率,但是梯度下降法的学习率是固定的.而Adam优化算法可以为每个特征计算自适应学习率,同时改进了梯度下降法的缺点,如学习率消失、收敛过慢等.在本文提取语义特征的实际过程中,Adam优化算法效果良好,收敛速度比梯度下降法更快,使特征提取更为有效.图3为本文改进后的FCN-8s架构提取的语义对象特征FS示例.图3(a)为原图,图3(b)为提取的语义对象特征,图3(c)为人工标记的语义对象.
3 低级特征的提取
人类的早期视觉通路会利用视网膜及初级视觉皮层提取如强度,颜色和方向等若干低级特征.因此为提高视觉注意力模型的性能,本节经过反复实验及结果比较,选取了包含了28个低层特征的特征集FL={f1,f2,…,f28}:图4中(1)~(13)图为13个亮度特征,其通过金字塔滤波器对3尺度的多分辨率亮度图像进行4方向的滤波得到;图4中(14)~(16)图为利用ITTI[5]模型计算得到的颜色,强度,方向3个特征;由于Lab颜色模型是基于人对颜色

图3 本文利用改进的FCN-8s提取的语义对象特征

图4 28个低级特征
的感觉,因此本文利用FT[21]模型提取Lab色彩空间特征(图4中(17)图);图4中(18)~(23)图为计算红、绿、蓝三颜色通道值及概率值,分别得到的3个色度特征及3个色度概率特征;图4中(24)~(28)图为利用中值滤波器对6尺度的彩色图像进行滤波,并计算三维色度直方图而得到的5个色度直方图特征.
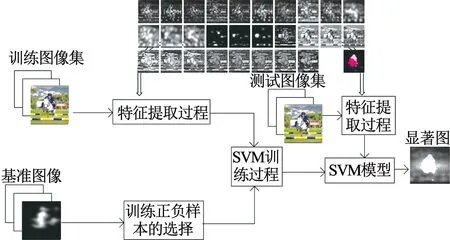
图5 视觉注意力模型训练过程
4 视觉注意力模型的训练
提取语义对象特征FS和低级特征集合FL之后,得到本文提取的特征集合F={FS,FL}.为获取提取的特征集F与本文构建的VOC2012-E数据库里记录的眼动追踪数据的映射关系,本文引入机器学习理论,利用非线性分类器模拟人脑神经系统的非线性映射.在统计学习理论中发展起来的SVM方法是一种通用学习方法,其在非线性分类应用中有非常好的表现.因此,本文利用SVM理论,训练得到每个特征与视觉注意力之间的关系,并在训练过程中,本文基于特征整合理论对特征集合F里的特征进行并行处理[5],最后利用训练得到的映射关系生成视觉显著图.
具体地,训练过程中,取样本集S⊂T,T为基准图像的训练集.样本s∈S.令
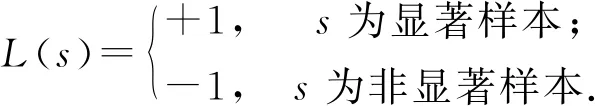
设P为基准图像的像素集,P={p1,p2,…,pN},N为基准图像中像素的个数.O(pi)表示像素的显著度,i=1,2,…,N. 对像素集P进行排序得到有序集合Po={po1,po2,…,poN},其中O(po1)≥O(po2)≥…≥O(poN).在利用SVM模型进行训练时,本文选择Sp⊂S作为正样本,Sn⊂S作为负样本,其中Sp={po1,po2,…,pom},m=0.05N,Sn={pol,pol,…,poN},N-l=0.3N,最终预测出显著图,训练过程的流程图如图5所示.
5 实验及结果分析
为评测本文视觉注意力模型的性能,将其与8种经典的视觉注意力模型在VOC2012-E数据库上进行比较,这8种模型分别是AIM[22],AWS[7],Judd[13],ITTI[5],GBVS[10],SUN[8],STB[23]和Torralba[9],然后在MIT300测试数据集上在线测试性能, 除以上8种模型之外,本文模型同时与4种先进的视觉注意力模型在MIT300数据库上相比较,这4种模型分别是eDN[11],UID[12], Deep Gaze2[15], DeepFeat[16].评价函数选取受试者工作特征曲线下面积(Area Uner Curve, AUC),线性相关系数(Correlation Coefficient, CC)及归一化扫描路径显著性(Normalized Scan Path Saliency,NSS). AUC是度量视觉注意力模型预测出的显著图与基准图像的差异的一个评价函数,通常,AUC的值介于0.5~1.0之间,AUC越大,模型的表现与基准图像更相近.CC用来衡量视觉注意力模型预测的显著图与基准图像的线性相关性. NSS为人眼凝视位置在模型输出显著图上的归一化显著值为
(2)
(3)
式中:S为模型的输出显著图,σs和μs为模型输出显著图上的均值与标准差.
图6为9种模型预测显著图的实验结果图的示例,输入图片来自于VOC2012-E数据库.从实验结果可以看出,与其他8种模型相比,本文预测的显著图中语义对象特征是高显著性的,这说明本文提出的视觉注意力模型显然更接近于人类视觉认知.
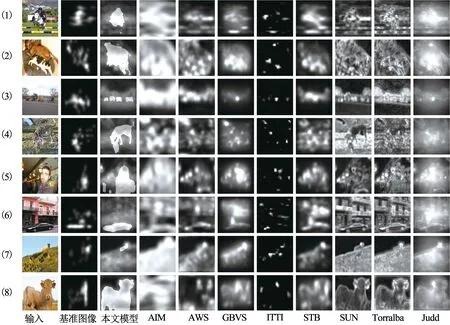
图6 视觉注意力模型预测的显著图对比
表2为9种模型在VOC2012-E数据库上的评价函数结果比较.从表2可以明显看出,三种评价函数AUC,NSS和CC评价结果都表明本文模型性能优于其他模型.本文模型的AUC值最高(0.823),其次是Judd(0.822)和GBVS(0.810),而ITTI模型的AUC值仅为0.531,这意味着本文算法与其他模型相比,更接近于基准图像.本文模型的NSS值为1.360,其次是GBVS (1.263)和Judd (1.242),而STB模型的NSS值只有0.399,在9种模型中最低,仅为本文模型的1/4.本文模型的CC值(0.557)也最大,而CC值越高,注意力模型预测的显著图与注视点之间的相关性越高.因此,本文模型预测的显著图更接近于人眼注视点,这是因为本文模型的提出是受人类自由观察自然场景的感知过程的启发,在模型训练过程中融合了语义对象特征和典型的低级特征.
此外,为了进一步评估本文提出的模型,本文在公开数据库MIT300进行评测,该数据库包含了9个受试者观察300张自然图像时人眼注视点的基准数据,评测结果如表3所示,除了前文比较的8种模型之外,同时比较了4种先进的模型:Deep Gaze2及Deep feat同样整合了高级特征与低级特征;eDN同样利用SVM整合特征;及无监督模型UID.
根据表3结果,AUC最高值为Deep Gaze2模型(0.84),而本文模型的AUC值与GBVS,Judd, eDN及DeepFeat模型的AUC值相近,但是本文模型的NSS值(1.27)在12种模型中最高,而且本文模型的CC值与DeepFeat模型的CC值并列最高(0.49).其中,整合了同样高级特征与低级特征的Deep Gaze2模型与Deep feat模型与本文模型总体表现最优,而本文模型略胜一筹,这说明了本文整合语义特征的先进性.虽然同样利用SVM整合特征的eDN模型的NSS值较低(1.14),但其AUC值与本文相同,CC值也较高,说明了本文利用SVM整合特征的有效性.因此本文模型在MIT300数据库上性能表现良好,可以有效地预测人眼注视点.

表2 9种模型在VOC2012-E数据库上的实验结果比较

表3 12种模型在MIT300数据库上的实验结果比较
6 结 论
本文提出了一种整合了语义对象特征的视觉注意力模型.通过建立眼动跟踪数据库VOC2012-E,研究并记录普通人在观察自然场景时的眼动数据,经过分析得出语义对象特征在吸引人们的注意力时有重要作用.然后,受语义分割启发,利用深度学习网络FCN-8s提取语义对象特征,同时用激活函数PReLu,优化函数Adam改进网络使其更有效地提取的语义对象特征.接着,提取在人类潜意识层吸引人注意力的如方向,颜色,强度特征等28个低级特征.最后训练机器学习分类器SVM将之前提取的语义对象特征及低级特征映射到人类视觉空间,训练后的模型可以预测自然场景的人眼视觉显著图.经过在VOC2012-E及MIT300数据库的测试,与其他8种经典模型及4种先进模型相比,本文提出的视觉注意力模型性能更好,更符合人类观察图像时的视觉习惯,即语义对象高显著.
