基于机器学习方法的个人信用风险评估研究
2020-02-22王铬
王铬

摘 要:互联网金融在国内的兴起,使得个人信贷风险成为许多企业关注的热点。本文通过对LendingClub网站中个人信用贷款数据集的探索,构建基于xgboost和logistic regression组合算法xgboost-LR模型、随机森林和支持向量机算法三种机器学习方法,对个人信用风险进行全面的评估。通过实证数据分析,其中新构建的xgboost-LR算法评价效果最好,能够更加准确地预测个人信用风险。
关键词:信用风险评估 xgboost-LR算法 随机森林 支持向量机
中图分类号:F224.9 文献标识码:A 文章编号:1674-098X(2020)10(c)-0157-03
Abstract: With the rise of Internet finance in China, personal credit risk has become the focus of many enterprises. Based on the exploration of personal credit loan data set in LendingClub website, this paper constructed three machine learning methods based on XGBoost and Logistics regression combination algorithm xGboost-LR model, random forest and support vector machine algorithm to comprehensively evaluate personal credit risk. Through empirical data analysis, the newly constructed XGBoost-LR algorithm has the best evaluation effect and can predict personal credit risk more accurately.
Key Words: Credit risk assessment; Xgboost - LR algorithm; Random forest; Support vector machine
随着我国金融业的日渐兴盛,各种各样的金融产品层出不穷。对于投资者尤其是放贷方来讲,就需要综合考虑风险控制,这也是企业运营的基础性工作。面对海量数据,从中迅速可靠地判断贷款者的个人信用风险是非常困难的事情(见表1),单靠人工是无法完成的。目前机器学习方法已经非常成熟,然而比较合理地运用到金融领域的个人风险评估还不是很多。本文试图探索利用机器学习算法来对个人信用风险进行评价。在个人信用风险评估领域,logistic regression是非常成熟的模型,它将违约概率作为标准。然而这个算法有许多的缺陷,主要对于特征变量要求很高。为了克服这一个缺点,本文采用了xgboost算法来提取组合特征。为了训练机器学习模型并进行验证,本文借助了LendingClub提供的历史借贷数据,首先用xgboost以CART为基学习器挖掘出反映个人信用风险组合特征,然后将xgboost通过最小化损失函数方法分割出来的组合特征加入原始数据集,构建logistic regression个人信用风险评估模型。通过与其余算法实际对比验证,发现新构建的xgboost-LR算法评价效果最好,能够在最短的时间内完成运算,得出预测结果,准确率也令人满意。
1 基于机器学习方法的个人信用风险评估
1.1 xgboost-LR算法
在基于logistic regression个人信用风险评估领域中,以特征变量预测能力筛选构造的特征集往往不能充分度量信用風险。xgboost算法对于个人信用风险组合特征的挖掘能力,几乎决定了xgboost-LR模型效果的好坏。xgboost-LR是 logistic regression和xgboost的组合模型,首先通过Xgboost模型构造对个人信用风险具有区分性新的组合特征,然后结合原始特征训练logistic regression个人风险评估模型。xgboost模型十分地好用,其应用于个人信用风险评估的时候,xgboost的参数设置需要十分的科学和合理。xgboost模型参数主要包含通用参数、任务参数和辅助参数。xgboost构建对个人信用风险具有区分性的组合特征时,采取合适的参数使模型效果大大提高效率和准确性。其基本步骤如下:
Step1:xgboost模型采取合适的参数,对历史借贷数据集进行训练,构建棵决策树。
Step2:列举所有迭代生成的回归树:
其中,qi表示每棵树的叶子节点数,表示叶子的score。
Step3:对于任意借贷客户,其必然会落在每棵树的某个叶子节点上。假设该借贷客户在第n棵树落在第in个叶子节点中,则由第n棵树构造的组合特征为[01,02....,1in,...,0qn],0表示该借贷客户没有落在此叶子节点,1正好相反。
Step4:将Tn个组合特征加入原始数据特征集组成新的数据集,输入到logistic regression算法中。
1.2 使用随机森林算法的风险评估原理
Breiman(2001)首次结合了 Bagging 集成思想和决策树算法,在随机子空间的理论基础上,提出了随机森林(Random Forest,简称RF)算法。Bagging是并行式集成学习中最具有代表性的方法之一,它直接基于自助采样法(bootstrap sampling)。RF算法在以决策树为基学习器构建Bagging集成的基础上,在决策树的训练过程中进一步引入随机属性选择。传统决策树在划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分,对风险过大的主体进行预警。
1.3 使用支持向量機方法的风险评估原理
为了解决分类和回归问题,Vapnik于1995年提出支持向量机(Support Vector Machine,简称SVM)。由于在文本分类任务中表现出卓越的性能,很快成为机器学习的主流技术。SVM的基础思想是推导出一个可以最大化两类间边距的最优超平面,SVM的一个优点是通过非线性函数?将数据投影到一个高维空间,可以找到一个非线性的决策边界。
2 个人信用风险评估的建模分析及应用
从LendingClub网站上下载2019年第1季度个人信用贷款数据集,一共包含了115675人的贷款信息,144个特征。特征包括借款人申请贷款金额、借款人年收入、借款人分期还款金额等;目标变量为loan_status(贷款状态),包括违约和不违约两大类。针对数据集的不平衡问题,我们采取合成少数过采样技术(Synthetic Minority Oversampling Technique, 简称SMOTE)进行处理平衡数据。SMOTE算法克服了简单随机过采样算法容易导致的过拟合问题,SMOTE算法的基本思想是对少数类样本进行分析,并根据少数类样本人工合成新样本添加到数据集中。这样一来,我们数据集足够训练成熟我们的算法模型。通过SMOTE方法平衡正负样本后样本总个数:227812;正样本占50.00%;负样本占50.00%。而后对模型评价指标进行选取。
采用传统的与accruacy类似的评价指标时效果并不突出。为了更好地评价模型效果,指标必须能够做到给那些将所有样本都判定为正样本的模型以低分,因此,我们采用接收者操作曲线下面积(Area Under Receiver Operating Curve,简称AUROC)作为模型的评价指标。AUROC的值被定义为ROC曲线下的面积,取值范围一般在0.5和1之间。由于很多时候ROC曲线并不能清晰地说明分类器的效果,而作为一个数值,使用AUROC值作为评价标准分类效果更好,并且对应AUROC值更大的分类器效果越好。
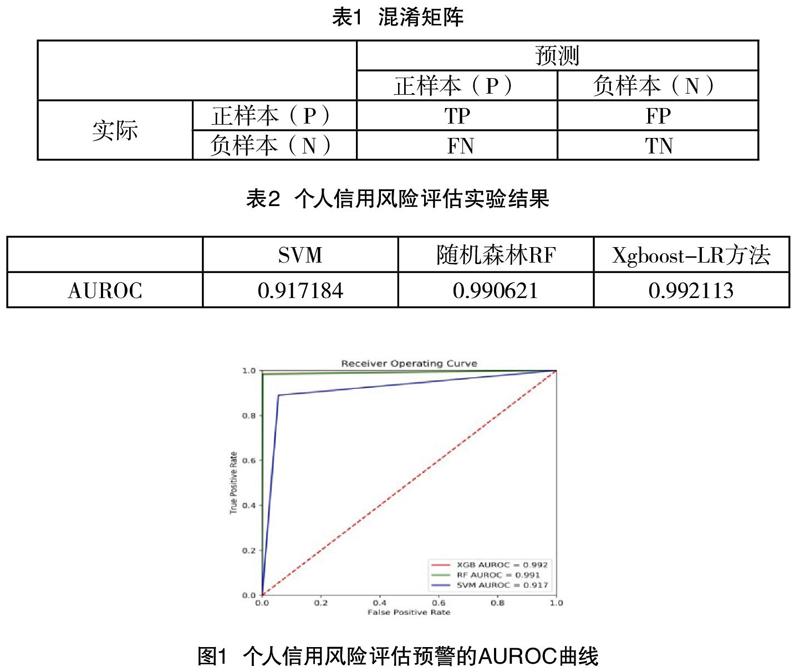
使用python实现所构建的三种机器学习算法,运行个人信用风险评估预警模型,可以鉴别信用风险较高的个人。所得到的三种模型的AUROC值如表2所示,可以看出xgboost-LR模型对企业风险的评估和预警效果最好,AUROC值高达0.992。RF模型与xgboost模型结果相差不大,AUROC值也达到了0.990。相比较而言,SVM的AUROC的得分值最低,但是也达到了0.917以上。
根据三种模型实验结果绘制的AUROC曲线,如下图1所示。
观察3种个人信用风险评估模型在数据集上的实验结果AUROC曲线可以发现,所选模型在此数据集上的评估表现都比较好,可以较快地达到评估的良好状态。并且程序的运行时间较短(3种方法都可以在10min内完成),可以随着数据更新实时多次运行,做快速的风险评估和预警。因此基于机器学习模型对个人信用风险进行评估和预警是有效可行的。
3 结语
本文将logistic regression与xgboost组合算法xgboost-LR应用到个人信用风险评估领域,单一logistic regression模型对个人信用风险评估,由于其很难拟合特征之间交互作用对信用风险的影响,导致其预测精度偏低,可以通过xgboost提取对信用风险具有区分性的组合特征,避免重要信息的遗漏,提高预测精度。并且同时使用随机森林模型和支持向量机模型评估个人信用风险,AUROC值也都可达到0.9左右,具有较稳定地判别信用风险较高的个人。在实际工作中,可以将几种方法综合应用,达到更好的预测结果。
参考文献
[1] Li H,Cao Y,Li S,et al. XGBoost Model and itsApplication to Personal Credit valuation.IEEEIntelligentSystems,2020.DOI:10.1109/MIS.2020.2972533.
[2] Munkhdalai L,Munkhdalai T, et al. An Empirical Comparison of Machine-Learning Methods on Bank Client Credit Assessments[J]. Sustainability, 2019,11(3):699-722.
[3] Wang S,Fu B,Liu H, et al. Feature Engineering for Credit Risk Evaluation in Online P2P Lending[J]. 2017, 9(2):1-13.
[4] Sang H V,Nam N H,Nhan N D.A Novel Credit Scoring Prediction Model based on FeatureSelection Approach and Parallel Random Forest[J]. Indian Journal of Science & Technology,2016 :9-20.
[5] Yulian Mo,Yu Fei.The Application of Credit Approval Based on Machine Learning Classification Method [J].Hans Journal of Data Mining Vol.06 No.03 2016 :10.
[6] Chen T, He T, BenestyM. xgboost:Extreme Gradient Boosting[J].2016, 5 (9) :222-208.
[7] 徐婷婷.随机森林在P2P网贷借款信用风险评估中的应用[D].济南:山东大学,2017.
[8] Li G, ShiY,Zhang Z. P2PDefault Risk Prediction based on XGBoost, SVM and RF Fusion Model[C]// 1st International Conference on Business, Economics, ManagementScience(BEMS2019),AtlantisPress.2019.
[9] Li H,Cao Y,Li S,et al. XGBoost Model and itsApplication to Personal Credit valuation.IEEEIntelligentSystems,2020.DOI:10.1109/MIS.2020.2972533.
[10] Munkhdalai L, Munkhdalai T, et al. An Empirical Comparison of Machine-Learning Methods on Bank Client Credit Assessments[J]. Sustainability. 2019,11(3):699-722.
