结合指令预取和缓存划分的多核缓存WCEC优化
2020-01-06安立奎韩丽艳
安立奎,韩丽艳
1.渤海大学 数理学院,辽宁 锦州121013
2.渤海大学 信息科学与技术学院,辽宁 锦州121013
1 引言
在硬实时多核系统中,任务执行时间必须满足时间截止期,这对于硬实时系统的可靠性和可调度性来说非常重要。同时对于能量供应受限的硬实时系统,例如卫星的传感监视系统、普适系统等,最差情况下的能量消耗WCEC(Worst-case Energy Consumption)也是一个必须要考虑的因素[1-3]。

图1 支持指令预取器的嵌入式多核架构
由于片上缓存占据了多核处理器的较大面积和拥有较高的访问频率,缓存消耗的能量超过了系统片上能量消耗的50%[4],因此减少缓存能量消耗对延长系统的使用期来说非常关键.随着芯片技术的不断进步,顺序指令预取技术可以减少缓存能量能耗[5-6]。顺序指令预取的缓存能量效率与指令预取度密切相关,对于硬实时多核系统中的多个子任务来说,采用相同预取度不利于减少整个系统的缓存WCEC,这就非常有必要对指令预取度进行优化来提高指令预取的能量效率。Gu 等人[7]提出了一个能量有效的支持指令预取的单核嵌入式模型,用循环译码的指令缓存减少能量消耗。对于单核中的多个抢占式任务,Gran等人[8]用单层指令预取缓冲区和锁缓存来优化任务的WCET 和WCEC。在文献[7]和[8]中,也仅考虑的是单核下的单层指令缓存的能量消耗,并没有考虑有多个并发任务的硬实时多核系统的缓存能量消耗。
最近的研究表明多个并发任务在多核共享缓存上的干扰,降低了系统的性能,增加能量消耗。缓存划分技术通过把共享缓存的一部分分配给每个处理核来消除干扰,降低能量消耗,关于这方面的研究已经做了大量的工作[9-14]。Reddy等人[9]用缓存划分技术消除多个任务在共享缓存上的干扰,减少缓存能量消耗。Wang 等人[12]结合DCR(Dynamic Cache Reconfiguration)和缓存划分减少多个硬实时任务的缓存能量消耗。其研究的任务集彼此独立,并且没有分析指令预取对于硬实时多核系统的缓存能量消耗的影响。
本文通过查阅文献发现至今还没有结合指令预取和缓存划分的缓存能量消耗优化方面的研究工作。为了减少硬实时系统的缓存WCEC,延长系统的使用期,本文提出硬实时多核系统结合指令预取和缓存划分的最差情况下缓存能量消耗优化方法。首先建立了结合指令预取和缓存划分缓存WCEC 能量优化模型,然后设计了结合指令预取和缓存划分的ILP线性规划方程,在保证硬实时系统满足时间截止期的情况下,优化其WCEC;最后,对硬实时系统DEBIE进行实例分析,验证优化方法的有效性。
2 嵌入式多核模型和研究动机
2.1 嵌入式多核结构和任务模型
如图1 是一种支持指令预取的嵌入式多核模型。有NC个同构的处理器核。每个核有私有的L1指令/数据缓存,所有的核共享L2 联合缓存,共享L2 缓存有W路(way),通过路缓存划分技术[13],它被分成了NC部分,即,L2缓存划分因子路被分给了运行硬实时任务的核Ci(i=1,2,…,NC) 。缓存的替换策略是LRU(Least Recently Used)。L1 和L2 缓存通过硬实时总线连接。如图2 是一个基于路划分的例子(4核,1组,8路组关联),L2缓存通过路的粒度进行划分,每个处理器核被分配了一些路,并且此处理器只允许访问分给它的那些路。
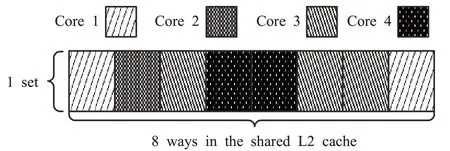
图2 一个基于路的缓存划分的例子(4核,1组,8路组关联)
顺序指令预取器采用支持Prefetch-on-Miss 预取策略的Next- N -Line 指令预取。如果处理器需要处理的当前指令i 被映射到L1指令缓存行p 在L1指令缓存上没有命中,那么L1 指令缓存预取器I-prefetcher 就会发出预取L1 指令缓存行p+1,p+2,…,p+N 的操作请求。如果需要预取的指令行已经在L1 指令缓存,预取请求被丢弃,否则预取请求进入一个FIFO(First In First Out)队列,随后请求会被发送到L2缓存。为了支持指令预取优化机制,采用文献[15]的方法,利用编译器在任务之间留下程序预取度信息指示,在程序运行的时候,预取硬件检测到这些指示的预取度,然后用检测到的预取度来预取指令。
本文研究的硬实时系统有NT个相互依赖的硬实时子任务,并发多任务的执行环境是一个基于静态优先级的非抢占系统,每一个任务被分配给唯一的一个静态优先级,如果多个任务被映射到同一核上执行,优先级高的任务先执行。如果任务开始执行,在它完成前,不允许被别的任务抢占。任务之间的小的通信和同步时是通过邮箱(mailbox),并且邮箱足够大,消息不会溢出。消息在系统内部的通信状况通过消息跟踪语言MSC(Message Sequence Chart)描述。
2.2 能量模型
首先假设NT个硬硬实时任务已经被映射到相应的处理核上,并且独占L2共享缓存的相应分区。
硬件预取器通过一些硬件表来实现,所以它的能量消耗可以被准确的模拟[5],这里参照文献[5],硬件预取器由一个512 bit的FIFO预取缓冲器构成。

这里假设处理器的频率是1.0 Hz,用的是32 nm 工艺,本文参照文献[16]中的缓存能量消耗计算模型计算单个硬实时任务T 支持指令预取的最差情况下的缓存能量消耗,如公式(1),对于不同的预取度n(n ≥0),当n为0时,表示没有采用预取操作,这时候关闭预取器:在指令预取度是n 情况下任务T 最差情况下的缓存能耗E(T,n),是由最差情况下的静态能耗Estatic(n)和动态能耗Edynamc(n)组成的。其中Cstatic(n),Pstatic(n)分别是缓存和硬件预取器的单位时间内的静态能耗,tn是当预取度是n 时的任务最差情况执行时间WCET。动态能耗Edynamc(n)由缓存的动态能耗Ec_dynamc(n)和预取器的动态能耗Ep_dynamc(n)组成,Eaccess表示一次访问缓存所消耗的能量,caccess(n)是当预取度为n 时的最差情况下访问缓存次数。Emiss表示一次缓存缺失所消耗的能量,cmiss(n)是当预取度为n 时的最差情况下访存缺失次数。Eprefetch表示一次预取时额外访问缓存的能量消耗,cprefetch(n)表示最差情况下当预取度是n 时由于预取额外需要访问缓存的次数,这里cprefetch(0)=0。Enext_access表示一次访问下一级缓存所消耗的能量,Eup_stall表示由于缓存缺失,处理器停顿所消耗的能量,Eblock_fill表示把取回的指令填充到缓存所消耗的能量,Ep_access表示一次访问预取器所消耗的能量,paccess(n)是最差情况下访问预取器次数。
这里Cstatic、Pstatic、Eaccess、Eblock_fill、Ep_access通过CACTI5[17]测得,在32 nm工艺下,预取器消耗0.359 mW的静态能耗,每次访问的能耗是0.002 nJ。
对于每一个硬实时任务T 、tn、caccess(n)、cmiss(n)、paccess(n)通过支持指令预取的缓存WCET 分析工具[18]测得。
2.3 研究动机
对文献[19]中的硬实时Mälardalen wcet benchmarks,如图3 是不同预取度下支持指令预取的缓存WCEC,结果被不支持指令预取(预取度N 是0)的结果归一化了。这里假设有4 个同构的处理器核,32 nm 工艺,芯片的频率是1.0 GHz,5阶段流水,顺序执行,分支预测是完美的(perfect),L1 指令/数据缓存大小是256 Byte,缓存行大小是16 Byte,直接映射。L2 缓存大小是1 KB,缓存行大小是32 Byte,2路组关联。

图3 指令预取度对于缓存WCEC的影响
从图可以看出顺序指令预取在不同的预取度下获得的能量效率不同,cnt最大,预取度是4时,最差情况下的能量减少43.7%,bsort100最差,在预取度是4时,能量反而增加了43.9%。这是因为由公式(4)可知,指令预取的能量获益是减少的缓存静态能耗和增加的预取器与缓存动态能耗中和的结果,每个程序的特性不同,预取效率不同,所以WCEC呈现的结果是非线性的。
运行在多核上的硬实时系统具有多个相互依赖的硬实时子任务,由于每个硬实时子任务的特性不同,所有任务采用相同的预取度,所有处理器核分配相同的L2 缓存因子,不利于提高硬实时系统的最差情况下能量效率。因此,就非常有必要对分配给硬实时系统中子任务的指令预取度和每个处理器的L2划分因子进行进行调整,来优化系统的缓存WCEC。
3 支持指令预取和L2缓存划分的WCEC优化
3.1 WCEC优化模型描述
本文为需要优化的硬实时多核系统建立下面的模型:
(1)多核处理器有NC个处理器核C={c1,c2,…,cNC}。
(2)T 是硬实时系统所有具有依赖关系的子任务的集合T={T1,T2,…,TNT},子任务到NC个处理器核上的映射不固定。每个子任务都有一个时间截止期F={f1,f2,…,fNT},整个系统有一个时间截止期SD。
(3)L2 共享缓存共有W 路,通过基于路的缓存划分,分配给了NC个处理器核,每个核可以分配的L2缓存划分因子可以是P={p1,p2,…,pW} ,其中pi=i ,(i=1,2,…,W)。
(4)D 是顺序指令预取度集合D={d0,d1,…,dND},其中di=i ,(i=0,1,…,ND),由于太大的预取度会给多核系统的负载带来沉重负担,影响系统性能,这里本文设定预取度最大阈值为4,预取度为0 表示不支持指令预取,关闭指令预取器。
本文假设:
(1)L 是任务T 到处理器C 的映射,L:T →C,每个硬实时子任务被映射到一个处理器核。
(2)M 是任务T 到预取度D 的映射,M:T →D,每个硬实时子任务被设定一个指令预取度。
(3)R 是处理器C 到L2划分P 的映射,R:C →P,每个处理器核指定一个L2缓存划分因子。
通过硬实时系统的MSC,本文得到了硬实时系统任务之间的依赖关系,用Pred(Ti)来表示任务Ti的前驱的集合,只有Pred(Ti)中的任务都执行结束,任务Ti才可以执行。用Starti(L,M,R)表示任务Ti的在映射L、M 和R 下的开始时间,用Finishi(L,M,R)表示任务Ti在映射L、M 和R 下结束时间。那么任务Ti的开始时间是Ti所有前驱任务结束时间的最大值,如公式(8):
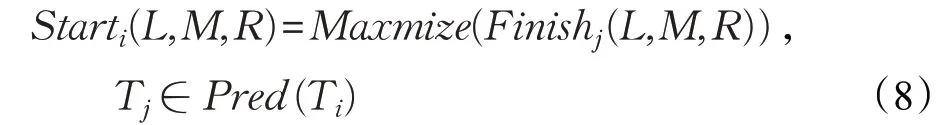
任务Ti的结束时间是Ti开始时间与任务Ti本身在映射L、M 和R 最差执行时间WCETi(L,M,R)的和,如公式(9):
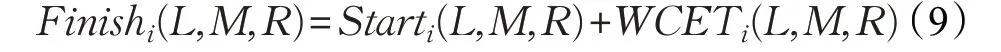
硬实时系统的在映射L、M和R下的WCRT(L,M,R)是运行在所有核上任务的结束时间的最大值,如公式(10)所示:
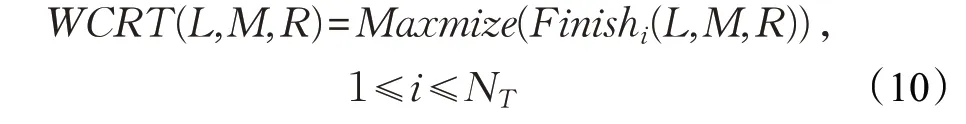
用WCECi(L,M,R)表示硬实时系统的子任务Ti在映射L、M 和R 下最差情况下的缓存能量消耗,硬实时系统的在映射L、M 和R 下的最差情况下的缓存能量消耗WCEC(L,M,R)是所有子任务在映射L、M 和R 下的最差缓存能量消耗的和,如公式(11):

本文的缓存能量优化目标是寻找映射L、M 和R,使得当在硬实时系统和它的所有子任务在满足时间截止期的情况下,最小化其WCEC,即公式(12)~(14):

3.2 优化WCEC的ILP方程
对于3.1 节中建立的结合指令预取和缓存划分的WCEC优化模型,本文设计了的相应的ILP线性规划方程,建立过程如图4所示。

图4 ILP线性规划方程建立流程图
从图4 可以看到,对于一个硬实时系统,建立规划方程首先初始化变量来确定处理器的核数、实时系统子任务数量、L2 缓存大小和预取度取值范围。然后建立子任务到处理器核的约束,保证每个子任务被分配到唯一的一个处理器核上,建立核到L2缓存划分的约束,确保每个处理器核拥有唯一的L2 缓存划分因子,建立子任务到预取度的约束,保证每个子任务采用唯一的预取度。上面3个约束建立后,就可以通过建立子任务选取WCET和WCEC的约束来确定每个实时子任务的WCET和WCEC,再建立硬实时系统的WCRT和WCEC的约束,最后建立优化目标约束,使得整个硬实时系统的WCRT满足时间截止期的情况下,最小化系统的WCEC。
3.2.1 任务到核的映射约束
C1 首先定义0-1变量Cij,表示任务Ti是否被映射到核Cj上,0 ≤Cij≤1,where 1 ≤i ≤NTand 1 ≤j ≤NC。
3.2.2 核到L2缓存划分的约束
C3 如果L2缓存共有W 路,P={p1,p2,…,pW},(pi=i)(i=1,2,…,W)是L2 缓存划分因子,定义0-1 变量Lij,表示核Ci是否被分配了L2缓存划分因子pj,0 ≤Lij≤1,where 1 ≤i ≤NCand 1 ≤j ≤W 。
3.2.3 任务选择WCET和WCEC的约束
C6 如果任务可以选择的预取度的集合D={d0,d1,…,dND},di=i (i=0,1,…,ND),定义0-1 变量Tijk,表示任务Ti是采用预取度dj,此时的L2缓存划分因子是pk,因此有
C7 用数组W[i][j][k]存储任务Ti采用预取度dj,L2缓存划分因子是pk下的WCET,用整型变量Wi表示任务Ti应该选择的WCET,因此有0 ,where 1 ≤ i ≤NT。
C8 用数组E[i][j][k]存储任务Ti采用预取度dj,L2缓存划分是pk下的WCEC,用整型变量Ei表示任务Ti应该选择的WCEC,因此有0 ,where 1≤i≤NT
C9 定义0-1变量Aijkm,表示每一任务Ti被分配了唯一的处理器核Cj,预取度dk,L2 缓存划分因子是pm,对1≤i≤NT,1≤j≤NC,0≤k≤ND,1≤m≤W 有:

3.2.4 硬实时系统WCRT和WCEC计算约束
C10 为了计算硬实时系统的WCRT,本文需要计算所有核上的任务的最晚结束时间。定义0-1 变量Mijk表示任务Ti与任务Tj是否映射到核Ck上,有:

把上面的方程线性化,有:

C11 定义另外一个0-1 变量Mij表示任务Ti与任务Tj是否映射到同一个处理器核上,有:

把上面的方程线性化:

C12 如果两个任务Ti与Tj映射到同一个处理器核上,定义0-1 变量Bij,表示任务Ti在任务Tj之前执行,定义0-1变量Bji表示任务Tj在任务Ti之前执行,对于1≤i≤NT-1,i≤j≤NT有:

C13 对于任务Ti,用整型变量Si表示任务Ti的开始时间,用整型变量Fi表示任务Ti的结束时间,用0-1变量Dij表示任务Tj是否是任务Ti的直接后继,有:
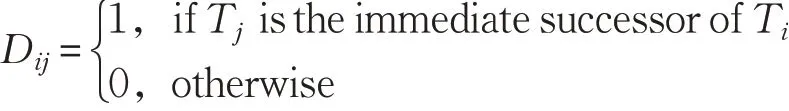
对于直接依赖的两个任务,后继任务的开始时间要小于前驱任务的结束时间,for ∀Ti,Tj,有:

C14 对被映射到同一核上的任务,先执行的任务的结束时间要小于后执行任务的开始时间,有:

这里MC是比所有任务的WCET的和都大的一个常量。
C15 对于所有的任务根据公式(9),Fi-Si-Wi=0,1 ≤i ≤NT。
C16 对硬实时系统的WCRT,有WCRT-Fi≥0,1≤i≤NT。
3.2.5 优化目标
C18 本文优化的目标是硬实时系统和所有子任务满足时间截止期SD 的情况下,最小化WCEC,即Minimize WCEC,当WCETi≤fi,1≤i≤NT,WCRT ≤SD。
4 实验评估
本章评估提出的支持指令预取和L2缓存划分的硬实时多核系统缓存WCEC优化方法。
4.1 评估环境
这里假设有4个同构的处理器核,32 nm工艺,芯片的频率是1.0 GHz ,5阶段流水,顺序执行,分支预测是完美的(perfect),L1 指令/数据缓存大小是256 Byte,缓存行大小是16 Byte,直接映射。这里L2 行大小是32 Byte,16 组,L2 缓存是10 KB,通过CACTI5[17]收集能量计算参数,利用IBM CPLEX12.2 ILP 求解器[20]来求解WCEC优化方程。本文使用的benchmark是DEBIE,它是由Patria Finavitec和UniSpace Kent联合开发的空间碎片探测器系统[21],根据DEBIE 的系统状态和功能,在文献[22]中对子任务进行了并行化处理。
所有的实验运行在Intel®Core™I5-3230 机器上,有4 GB内存,运行Ubuntu Linux 8.04操作系统。
4.2 实验结果
本节中,任务映射由ILP方程确定,用下面的符号表示硬实时系统DEBIE在不同优化方法下的缓存WCEC。
(1)E_base:此时系统不支持指令预取优化,也不支持缓存划分优化,通过路划分技术[13],L2 缓存被平均分配给了所有的处理器,它用作归一化时的基底。
(2)E_ip(n):文献[8]中的缓存WCEC 优化方法,此时系统采用固定的指令预取度n,但不支持L2 缓存划分优化。
(3)E_ocp:文献[9]中的缓存WCEC优化方法,此时系统通过L2 缓存划分来优化WCEC,但是系统不支持指令预取。
(4)E_oip+E_ocp:本文中的系统既支持L2 缓存划分优化,也支持指令预取优化的缓存WCEC。
4.2.1 比较不同优化方法下的缓存WCEC
为了验证本文优化方法的有效性,如图5把本文中的结合指令预取及L2缓存划分的缓存WCEC优化方法(E_oip+E_ocp)和已有的支持L2 缓存划分(E_ocp)[9]和支持固定预取度(E_ip(n))[8]缓存WCEC优化方法进行比较,指令预取度 n 从1、2、3 到4。所有结果都被E_base归一化了。
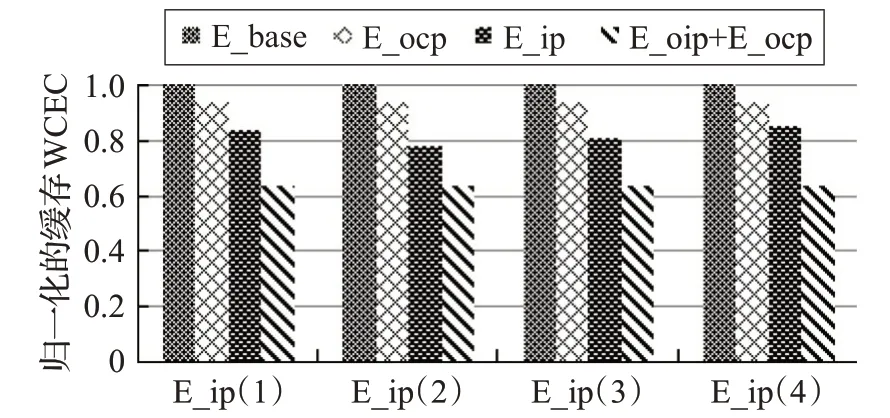
图5 不同优化方法下的缓存WCEC
从图5 可以看到,在不同的预取度 n 下,E_ip(n)都比E_base小,说明指令预取可以减少最差情况下的缓存能量消耗,这是因为指令预取的能量优化效率和访存次数以及静态能量在总能量中的比重有关系。在32 nm的处理器中,静态能量消耗在总能量消耗中的比重增大,指令预取大大减少了系统的最差情况执行时间,因此尽管它增加了一部分动态能耗,它最终也能够减少总的能量消耗。当预取度是2时,指令预取的能量获益是最大的,达到了21.9%。L2 缓存划分能耗E_ocp 比E_base 减少了6.3%,这说明L2 缓存划分对于减少WCEC 也是有效的。E_ocp 是经过L2 缓存划分优化后的WCEC,因此它比不优化的E_base要小。
这里还可以看到E_oip+E_ocp比E_ip(n)平均减少了22.5% ,比E_ocp 平均减少了36.6%,这说明本文中的缓存WCEC方法是有效的。当预取度是1,3和4时,本文的WCEC优化效率好于当预取度是2的情况,这是因为当预取度是2的时候,指令预取可以获得最好的能量效益,此时本文方法能量优化效率比预取度是1,3和4时会降低。
4.2.2 L2 缓存大小对于优化方法的影响
为了分析L2缓存大小对于本文提出的优化方法的影响,图6比较了不同L2缓存大小下的E_oip+E_ocp和E_base,L2缓存大小分别为4 KB、6 KB、8 KB和10 KB,所有结果都被E_base归一化了。

图6 不同L2大小的归一化的缓存WCEC
从图6中可以看到当L2缓存是10 KB的时候,本文的优化方法的能量效率最高。这说明本文的WCEC 优化方法的效率与L2 缓存大小有关系。当L2 缓存大于4 KB 的时候,缓存WCEC 已经被本文的方法优化到了最小,L2 缓存越大,计算E_base 时,分配给每个处理器的L2 缓存划分因子越大,整个系统的执行时间并没有显著减少,因此静态能耗变大,总的能耗也变大。当L2缓存是10 KB 时的E_base,比L2 缓存是4 KB、6 KB 和8 KB时的E_base要大,因此归一化的结果越小,本文能耗优化效率越高。
4.2.3 处理器核的数目对于优化方法的影响
为了分析处理器核的数目对于本文提出的优化方法的影响,如图7 比较了不同处理器核下的E_oip+E_ocp 和E_base,处理器的核数分别为2、3 和4,所有结果都被E_base归一化了。
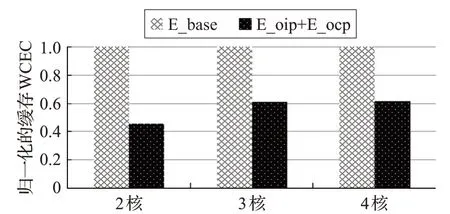
图7 不同处理器核数下的归一化的缓存WCEC
从图7中看到,当处理器是2核的时候,通过本文方法优化后的最差缓存能量比不优化时的最差缓存能量减少了54.4%,这比处理器是3 核与4 核的时候要好。这是因为不同处理器核下的能耗优化效率与硬实时系统中子任务的并行度有很大的关系。从文献[22]中可以看到,DEBIE 系统在某一时间点,至多有3 个子任务并行运行,当处理器的核数多于3时,E_base很少改变,而本文中的方法已经把WCEC优化到最小,所以对于3核与4核,优化效率也未改变。当处理器是2核时,本应该并行的子任务也需要串行执行,同3 核相比,利用本文方法,缓存WCEC优化的空间更大,效率提高的也越明显。
5 结论
对于能耗有很高要求的并发多任务硬实时多核系统,本文提出支持指令预取和缓存划分的缓存WCEC优化方法,该方法通过建立ILP 方程,调整子任务的预取度和L2缓存划分因子对硬实时系统的最差情况下的缓存能耗进行优化。通过对粒子探测系统DEBIE 的分析,表明本文提出的支持指令预取和缓存划分的缓存WCEC优化方法大大减少了系统的缓存WCEC,其优化的效率与硬实时系统任务的并行度与处理器数目,L2缓存大小有密切关系。
下一步,计划改进本文的方法,对支持数据预取的并发多任务硬实时系统进行分析,并把指令预取和数据预取结合起来对硬实时系统地最差情况下的能耗进行优化。
