基于视觉的三维目标检测算法研究综述
2020-01-06李宇杰李煊鹏张为公
李宇杰,李煊鹏,张为公
东南大学 仪器科学与工程学院,南京210096
1 引言
基于视觉的目标检测是图像处理和计算机视觉领域的重要研究方向之一,可应用于自动驾驶系统中的车辆、行人、交通标志等目标检测[1]、视频监控中的异常事件分析,以及服务机器人等诸多领域。近年来,随着深度神经网络的发展[2],包括图像分类、目标检测以及语义分割等方面的研究均取得了显著进展[3]。特别是在目标检测领域,出现了以R-CNN、Fast RCNN、Mask RCNN为代表的two-stage网络框架和以YOLO、SSD为代表的one-stage 的网络框架。无论何种框架,基于深度学习的二维目标检测算法在准确性和实时性上较以往基于特征的机器学习方法都获得了较大提升,在KITTI[4]、COCO[5]等公开数据集的测试中均取得了显著的成绩。但是,由于二维目标检测只用于回归目标的像素坐标,缺乏深度、尺寸等物理世界参数信息,在实际应用中存在一定局限性,特别是在自动驾驶车辆、服务机器人的感知中,往往需要结合激光雷达、毫米波等传感器实现多模态融合算法[6],以增强感知系统的可靠性。
因此,研究者们提出了三维目标检测的相关方法,旨在获取三维空间中的目标位置、尺寸以及姿态等几何信息。现有的三维目标检测算法根据传感器不同,大致可以分为视觉、激光点云和多模态融合三类。视觉方法由于其成本低、纹理特征丰富等优势,在目标检测领域中被广泛使用,并且可根据相机类型分为单目视觉和双目/深度视觉两类。前者关键问题在于无法直接获取深度信息,从而导致目标在三维空间中的定位误差较大。而后者不仅提供了丰富的纹理信息,还具有较为准确的深度信息,目前相比前者具有更高的检测精度。但双目/深度视觉对光照条件等因素更加敏感,容易导致深度计算的偏差。
相比于视觉数据,激光点云数据具有准确的深度信息,并且具有明显的三维空间特征,也被广泛应用于三维目标检测中。目前基于激光点云的三维目标检测算法大致有以下两种方法:三维点云投影和三维空间体素特征。例如,Complex-YOLO[7]、BirdNet[8]、VeloFCN[9]等方法利用不同的点云投影方法将三维点云转换为二维图像,利用Faster RCNN、YOLO等[3]标准的二维目标检测网络实现目标检测,然后再使用位置维度回归恢复目标在三维空间中的几何姿态。3DFCN[10]、Vote3Deep[11]、VoxelNet[12]等方法利用三维体素的方法编码点云的三维特征,利用三维卷积实现点云信息下的几何姿态推断。但是,单独激光点云信息缺少纹理特征,因而较难实现目标的检测分类,特别是当激光点云较为稀疏时,甚至无法提供有效的空间特征。因此,MV3D[13]、AVOD[14]等方法融合了激光点云与视觉信息实现多模态下的三维目标检测。该类方法利用图像的纹理等特征实现目标检测,结合激光点云的深度信息恢复目标的三维几何位置、姿态等信息。
另外,根据不同场景尺度,可以将三维目标检测任务分为室内与室外场景两大类。由于室内与室外场景存在较大差异,如目标大小、种类、环境的复杂度等等,使得两者的研究方法也存在很多不同。其中,室外场景主要解决大尺度场景下的车辆、行人、自行车等目标的检测和定位问题,为动态环境中的机器人决策规划提供依据;室内场景由于目标类别、尺寸和目标姿态随着视角的不同,特征也存在较大差异,因此主要解决的是目标的定位和姿态估计问题。
Naseer 等人[15]总结了现有的室内场景下2.5/3D 语义分割、目标检测、位姿估计和三维重建等环境感知算法。Arnold等人[16]从单目视觉、激光点云以及多模态融合的角度总结分析了现有的针对道路场景下的三维目标检测算法。Shen 等人[17]总结了目前基于2D/3D 数据的目标分类和检测算法,其中针对三维目标检测任务,主要分析了基于双目视觉的室内场景下和基于激光点云数据的室外场景下三维目标检测。本文主要系统总结近年来基于视觉的三维目标检测方法,调研现有的针对室内外不同场景下的检测方法,包含了基于单目、双目和深度相机视觉的主流网络结构,如图1 所示。此外,本文在KITTI[4]、SUN RGB-D[18]等数据集上对目前主流的三维目标检测算法进行实验对比研究。最后,根据目前三维目标检测算法存在的问题,提出其未来的发展方向。
2 室内场景的三维目标检测

图1 基于视觉的三维目标检测算法整理
相比于室外场景,室内场景具有较为显著的特点。首先,室内场景的尺度较小,不会出现室外场景中远距离目标;其次,室内场景中目标种类更加多样,包含沙发、书桌、电视等多类目标,同类目标的外观特征往往也存在较大差异。因此,针对室内场景下的三维目标检测需要更丰富的输入信息,因而在传感器的选型上研究者更偏向于双目/深度相机,其相关检测方法也是基于具有深度先验信息的数据。本章将系统介绍室内场景下各三维目标检测改进算法,并对各算法优缺点进行分析,如表1所示。
双目/深度相机具有完整的丰富的深度图信息(Depth Map),因此在立体成像与3D 目标检测中被广泛研究与应用。Depth Map 是指包含与视点的场景对象表面的距离有关的信息的图像或图像通道,其类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。在双目/深度视觉算法中,图像纹理特征、深度特征等多特征融合[19]是针对三维目标检测的有效解决方法。
2014年,Gupta等人[20]将2D目标检测的R-CNN[3]网络框架引入到基于深度图像的目标检测中,并增加基于深度图的CNN模块,建立了3D空间的目标检测网络框架。该方法提供了一种深度图三通道编码方式,包括了水平视差、离地高度、像素局部表面法向量和重力方向的夹角,这种编码方式称为HHA 特征,并对HHA 特征进行线性缩放,使其映射到0~255 范围内,形成类似与RGB图像格式的三通道深度图作为深度特征提取网络Depth RCNN 的输入,结合R-CNN 的2D 目标检测,生成2.5D的区域提议候选框,最后利用支持向量机(SVM)[21]进行目标分类,如图2所示。2015年,Gupta等人[22]利用HHA特征[19]与可变部件模型(DPM)[23]结合,训练基于深度图像的三维目标检测模型,通过检测网络实现自下而上的语义分割方法。相比之前将HOG特征扩展到深度图像中的深度梯度直方图[24],HHA编码方式增加了深度特征维度,使得目标深度特征更加丰富。并且,三通道的编码方式充分考虑了目标深度几何特征间的互补关系,有效地解决了深度信息在目标垂直方向上的不连续性。但同时该方式忽略了不同特征间的独立成分,只强调了各深度信息之间的相关性,使得该编码方式存在一定的局限性。另外,HHA 特征深度图的生成增加了相应的计算量,较难实现端到端的训练网络。
所谓的2.5D是指利用传统的2D检测网络,对单目图像与深度图进行类似的处理过程,这也是基于深度图像的目标检测算法中常用的处理方法。文献[25]提出的AD3D 同样是基于2.5D 的方法解决深度图像的三维目标检测与姿态估计任务。AD3D用Fast RCNN[3]实现2D区域提取,结合深度特征初始化三维检测框,采用三维检测框参数回归的方式精细化检测结果。相比于Depth R-CNN[20]方法,AD3D 设计了三维检测网络,省略了SVM的训练过程。Lahoud等人[26]提出的2D-driven方法同样利用RGB图像丰富的纹理信息实现目标的区域分割,利用深度图特征提取目标的方向角信息,结合多层感知器学习目标的三维空间位置和大小。2.5D 检测网络的优点在于其网络结构相对简单,有效利用了较为完善的2D检测网络实现三维目标信息回归。但是其缺点也十分明显,利用RGB 图像和深度图像的独立处理网络,忽略了目标原始的三维空间特性。
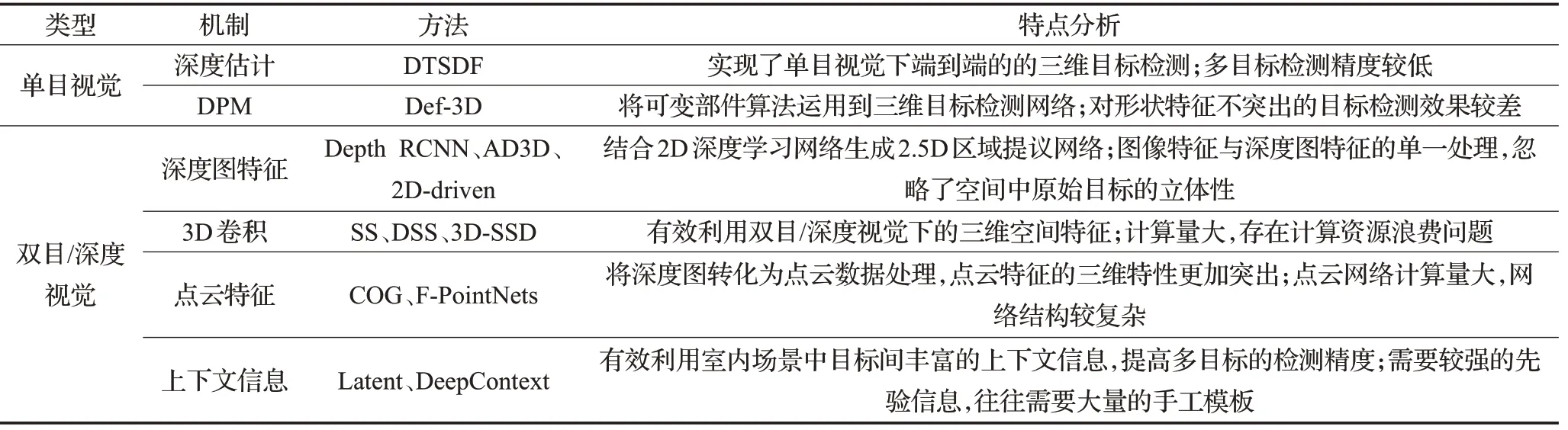
表1 室内场景下3D目标检测算法对比分析

图2 2.5D目标区域提取网络
以Faster RCNN、SSD、YOLO 为代表的2D 深度学习网络在目标检测领域取得了十分不错的成绩[2]。因此,采用2D网络实现目标识别与分割,结合深度信息回归精确的三维检测信息是三维目标检测的常用方法,例如Depth RCNN[20]、AD3D[25]、2D-driven[26]等算法。2D目标检测效果的提升在于其模型的有效性,于是研究者们提出能否建立有效的提取目标三维空间特征的3D CNN 网络模型。2016 年,Song 等人[27]提出了深度滑动形状(Deep Sliding Shapes,DSS)的3D CNN 网络,该网络首先对深度图像采用距离函数算法(TSDF)处理生成3D 立体场景,将该立体场景作为特征提取网络的输入,并借鉴Faster RCNN 的RPN[3]网络提出了多尺度区域提取网络(Muilt-scale RPN)的3D 区域提取算法,如图3所示。针对大小不一的多目标检测,采用多尺度的三维滑动窗口实现目标的三维空间区域提取,通过目标中心坐标以及长宽高尺寸的偏移量回归3D 检测框。DSS[27]改进了滑动形状算法[28]中利用CAD 模型手工制作目标3D 特征的方法,直接从立体场景数据中学习物体特征,使得网络的处理过程得到简化,并且提高了在SUN RGB-D数据集下的检测精度。但是3D卷积运算量远远大于2D卷积运算量,因此,DSS针对整个感知域的3D 卷积操作使得网络的计算量较大。于是,Luo 等人[29]提出了基于SSD 网络[3]的三维空间检测网络3DSSD,采用了2D目标检测网络作为前馈网络,实现目标的快速分割从而有效地减少目标三维搜索空间,再利用3D滑动窗口实现目标三维空间端到端的检测。相比于深度滑动形状算法,在检测精度和运算速度上都得到了较大的提升。
立体空间的三维卷积有效提取了目标的三维空间特征,但是视觉传感器获取的只有目标的表面特征,目标内部特征信息是无法获取的,因此立体空间的三维卷积常常出现空卷积的情况,造成了计算资源的浪费。因此,文献[30]利用深度图像生成三维点云,以点云形式作为网络输入,结合基于点云处理的PointNets3D目标识别网络,提出了基于深度图像的3D检测网络F-PointNets。对于给定的深度图像,F-PointNets 首先利用2D 检测网络实现单目图像的目标识别,通过图像-世界坐标系转换,确定点云识别提议区域,再利用PointNets 3D 目标识别网络对区域类点云信息进行识别检测,确定目标位置、姿态等三维信息。该方法不仅在室外场景的KITTI数据集下得到了比较理想的结果,在室内场景的SUN RGB-D数据集上也同样有较好的表现。针对深度图像的点云特征表示,Ren等人[31]提出了方向梯度云(Clouds of Oriented Gradients,COG)特征建立三维目标姿态和二维图像形状的联系关系。相比与激光的原始点云数据,利用深度图生成三维点云存在相应的误差。另外点云数据的稀疏性直接影响目标检测的准确性,尤其针对小目标检测时,点云数据往往十分稀疏甚至丢失。因此,该类算法针对室内场景的多目标检测精度的提升并没有运用在室外场景时显著。
在室内场景下,目标种类往往较多,针对不同目标的检测精度存在较大差异,例如针对床、桌椅等三维尺寸较大,几何形状较为明显的目标检测精度较高,而针对三维尺寸相对较小的目标,例如灯、电视机等,因此提高小目标检测精度是提升室内场景下目标检测性能的关键。考虑到室内场景下灯、电视机等小目标的位置先验特征,研究者们发现小目标往往以一个较大目标表面作为物体的支撑面,那么针对小目标的定位检测就可以与其支撑物体关联,提升小目标的定位精度,同时可以缩小对于小目标的搜索空间从而减少运算量。2018年,Ren等人[32]提供了一种基于潜在支持表面(Latent Support Surfaces,LSS)的三维目标检测算法,该算法利用潜在的支持面来捕捉室内场景中的上下文关系,解决之前用于深度图像的3D表示方法在表示具有不同视角样式的目标时的局限性,并提升对小目标检测的有效性。但针对一些没有明显支撑面的目标,例如浴缸、书架等,该方法并没有较好的处理结果。

图3 3D目标区域提取网络
利用室内场景中目标相互间的上下文关联信息不仅可以提升对小目标的检测精度,同时可以减少对上下文信息较弱区域的编码,将计算资源投入到具有强上下文信息关联区域。因此,Zhang 等人[33]提出了基于上下文信息编码的三维目标检测网络DeepContext。该网络将输入图像场景匹配一个预定义的三维场景模板,模板中定义了每个目标的位置关系,利用场景模板直接编码上下文局部特征,通过目标的外观特征和强上下文信息,实现目标的三维信息提取。另外,该方法利用强上下文信息和模板信息,有效地提升了如床头柜、椅子等易遮挡目标的检测精度。但因为模板数据的不完善,基于模板匹配的目标检测往往存在较大的局限性,当实际场景与模板场景集间不完全匹配时会造成较大的预测误差。
针对室内场景下的三维目标检测任务,现有的研究工作中大多数是基于深度图像的检测网络,这是因为基于单目视觉的三维检测网络很难应对多类目标、复杂的室内场景。尽管如此,仍然有研究者提出了基于单目视觉的室内场景三维目标检测算法。2012 年,Fidler 等人[34]将DPM[23]扩展到单目视觉下的三维目标检测,将每一个目标类表示为一个可变形的三维长方体,通过物体部件与三维检测框表面之间的变换关系,有效地实现了部分形状特征明显的室内目标的三维检测,例如床、书桌等具有明显长方体特征目标。
为了提高室内场景下多目标的检测精度,Zhuo 等人[36]提出了深度估计网络和3D RPN[27]结合的端到端的基于单目视觉的三维目标检测网络。该网络将单目视觉下的三维目标检测主要分为了三部分:深度估计网络、三维体素生成模块和3D RPN网络。在标准的距离函数(TSDF)[27]中,将三维空间划分为等距体素,通过深度映射得到三维体素中心到最近表面点的距离,但最近邻搜索过程无法实现端到端的训练。针对这一问题,该网络提出了可微距离函数(DTSDF),与距离函数(TSDF)在整个三维空间中寻找最近曲面点不同,DTSDF沿着每个体素的可见射线进行最近点搜索,从而使整个过程可微,实现端到端的训练网络。此外,该方法引入了残差网络[34],用于预测深度估计的不确定性。最后,通过3D RPN网络实现目标三维特征提取,得到目标的三维检测框和置信度。
在双目/深度视觉下的室内场景三维目标检测算法中,根据区域提取的卷积类型大致可以分为两类,即2.5D 区域提议网络和3D 区域提议网络。基于2.5D 区域提议网络优点在于结合2D 检测网络和深度图特征,可快速实现目标区域的提取和三维参数回归得到较为精确的目标三维检测框。而3D区域提议网络则利用三维卷积直接提取目标的三维空间特征,容易实现端到端的网络训练模型。但相比与传统的二维卷积,三维卷积计算量更大,并且在实际场景中,往往只能获得目标的表面特征,因此三维卷积的方法也会带来计算资源的浪费。而单目视觉下的室内目标检测,一般结合深度估计网络则会造成误差的累计传递,检测精度远远低于双目/深度视觉算法。但单目视觉算法的优势同样较为明显,其只使用单一传感器完成立体空间的三维目标检测,使得系统稳定性加强,不易受到环境干扰,另外使传感器成本大大降低。
3 室外场景的三维目标检测
室外场景下的三维目标检测主要是针对车辆、行人等道路场景下多目标的三维检测框回归问题。相比于室内场景,室外场景的目标检测任务更具有挑战性,其主要表现在以下两个方面:(1)由于场景视野的变化,包含较多远距离的小目标、遮挡以及视野截断的目标;(2)室外场景中背景、光照等条件更加复杂。因此,在室外场景下的三维目标检测需要更加精确的三维空间定位和尺寸估计。本章将分别从单目视觉和双目/深度视觉两方面系统介绍室外场景下的三维目标检测算法,如表2所示。
3.1 基于单目视觉的三维目标检测
单目图像可以为R-CNN、YOLO 等[2]二维目标检测网络提供丰富的外观、形状等纹理信息,实现目标在图像平面的分类与定位。但针对三维目标检测任务,由于缺少深度信息,单一的纹理信息无法直接确定目标在三维空间中的位置、姿态等信息。因此,通常结合先验信息融合[37]、几何特征、三维模型匹配、单目视觉下的深度估计网络等方法回归目标的三维几何信息。
Chen 等人[38]在2016 年提出了Mono3D 目标检测方法,如图4 所示。该方法将基于单目视觉的3D 目标检测分为两步:(1)根据先验假设进行密集采样,生成若干个3D 目标候选框;(2)对3D 检测框进行重投影生成目标的2D 检测框,利用Faster RCNN 网络[2]提取特征,结合语义、上下文信息、位置先验信息以及目标形状先验信息等,计算检测框的能量损失函数,提取精确的3D目标检测框。Mono3D 使用了与3DOP[39]相同的网络结构,在卷积层之后将网络结构分为两个分支,一个分支进行候选框内的特征提取分析,另一个分支进行候选框周围的上下文特征提取分析,最后通过全连接层获取目标的类别、检测框以及航向信息。Mono3D[38]利用复杂的先验信息提取3D 检测框,在能量损失计算中存在误差累计的问题,因此,Mono3D 在检测精度的性能上并不是十分突出。另外,候选框的密集采样和融合多个先验特征使得整个网络的计算量十分庞大,检测速度上与2D 检测器相比存在一定差距,无法实现端到端的预测模型。
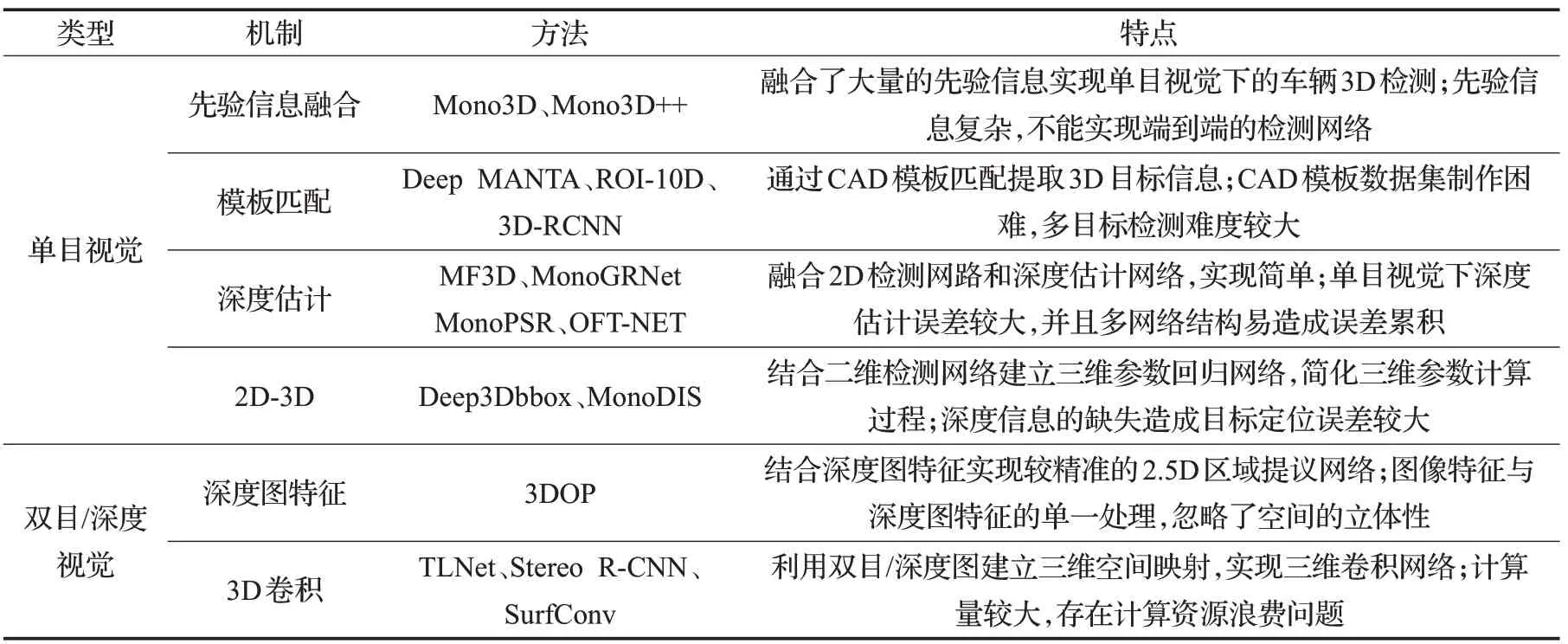
表2 室外场景下3D目标检测算法对比分析

图4 Mono3D目标区域提取特征
Mousavian 等人[40]利用2D 目标检测器网络的学习经验,提出了Deep3Dbbox的3D目标检测方法。该方法扩展了2D 目标检测器网络,利用回归的方法获取目标的三维尺寸以及航向角。与之前大多方法采用L2回归目标航向角不同,该网络借鉴滑动窗口的思想,提出了Multi-bins 混合离散-连续回归方法。Multi-bins 结构将方向角离散化分为多个重叠的bin,利用CNN网络估计每个bin的置信度和相对于输出角的旋转残差修正。在目标尺寸回归中,则直接采用L2 损失函数计算尺寸估计残差。通过网络预测,确定了目标的3D 尺寸和航向角,然后恢复物体的三维姿态,求解目标中心到相机中心的平移矩阵,使3D检测框重投影中心坐标与2D检测框中心坐标的误差最小。相比于Mono3D[38]方法,Deep3Dbbox[40]利用2D 目标检测方法简化了网络结构,使得计算量大大减少,提升了运算速度。但在检测精度上并没有大幅度的提升,这主要是因为深度信息的缺失,导致目标在世界坐标系中的位置计算存在较大误差。Deep3Dbbox通过最小二乘法解算三维检测框与二维检测框的位置匹配关系,再利用奇异值分解得到图像-相机坐标转换矩阵,该方法能较好解决简单目标的三维位置估计问题,但针对尺寸较小、存在遮挡等目标的定位精度大大降低。
因此,研究人员对深度计算提出了相应的改进方法。Xu等人[41]提出的MF3D方法融合了Deep3Dbbox[40]以及单目视觉的深度估计算法,利用Deep3Dbbox 卷积网络估计目标的3D尺寸和航向角以及sub-net网络生成深度图,对目标ROI 区域与深度图融合,计算目标在世界坐标系下的位置信息。Qin等人[42]提出的MonoGRNet方法采用实例级深度估计方法,与MF3D[41]生成整个输入图像的深度图不同,MonoGRNet 只对目标区域进行深度估计,在一定程度上简化了计算过程。Manhardt等[43]提出的ROI-10D将基于Resnet-FPN的2D检测网络结构[3]与深度估计特征图结合,再利用CAD模型匹配得到目标具体的3D信息。除了融合单目深度估计算法以外,在基于KITTI 数据集的3D 目标检测中,利用车辆、行人等刚体目标的几何约束计算位置深度是研究者们的另一种思路。例如,Ku 等人[44]提出的MonoPSR 利用相机成像原理,计算3D尺寸与像素尺寸比例关系进而估计目标深度位置信息。Roddick等人[45]提出的OFT-NET算法根据图像与三维空间对应关系,建立了图像特征与三维空间特征的正交变换,将基于图像的特征图反投影到三维空间的鸟瞰图中,再利用残差网络单元[35]处理鸟瞰特征图。基于单目视觉的深度计算方法大致可以分为两类:(1)基于卷积神经网络的深度估计;(2)基于几何特征与成像原理的深度转换。但是目前基于单目视觉的深度估计本身也是视觉算法领域的研究热点和挑战,其估计精度远远没有达到实际应用的标准,因此基于该类方法的三维目标检测算法的检测精度往往较低。而基于几何约束的深度估计则只能针对特定种类目标,无法实现多类目标的高精度检测,对实验数据具有较高的要求。另外,针对小尺寸目标的检测效果较差,适用于视野范围较小的场景。
无论是基于先验信息的Mono3D[38],还是基于CNN网络提取特征的Deep3Dbbox[40]系列算法,都存在对于遮挡、截断目标检测精度差的问题。针对这一问题,Chabot等人[46]提出了Deep MANTA采用多任务网络结构,实现目标位置、形状估计以及车辆的部件检测。该方法定义了一组车辆关键点表征车辆的外部形状,例如车顶角、车灯、后视镜等,利用一个两级的区域提议网络回归2D边界框与车辆关键点定位,再与人工建立的3D标准模板库进行目标形状匹配,得到完整精确的3D 目标姿态信息。同样的,He等人[47]提出Mono3D++则采用EM-Gaussian算法实现遮挡或截断目标的关键点检测与补全,结合Mono3D[38]定义的先验信息能量损失函数实现3D 目标的精确检测。Kundu 等人[48]提出的3D RCNN方法将物体的CAD 模型进行PCA 建模,利用一组基向量表征物体的3D 形状和姿态,最后利用卷积神经网络实现2D 图像到3D 物体的重建。通过关键点检测与CAD 模板匹配结合的方法是目前解决遮挡、截断目标检测地有效方案[49],但存在一定的局限性,首先是模板数据的获得较为困难,且对多目标检测精度较低。另外,无论是Deep MANTA,还是Mono3D++,都主要提升了目标在图像坐标系下的三维信息,而对相机坐标系下的定位精度并没有得到较大的改善,依旧不能解决深度估计造成的定位误差。
在基于单目视觉的目标三维检测中,常常级联了多个卷积神经网络实现三维姿态的多参数回归,例如检测网络与深度估计网络相结合等方法。这种级联做法会造成网络误差的累计传递,从而使得目标三维检测的误差较大。为了解决回归误差累计的问题,Simonelli 等人[50]提出了基于参数解耦变换的MonoDIS。简单来说,该方法用一个10 元数组表示目标的三维几何姿态,并将其分为尺寸、深度信息、航向角以及中心点图像投影坐标四组参数组,采用解耦的方法分离参数误差,即分别对其中任一参数组回归计算损失函数,而其他参数则保留为真值。三维姿态信息的解耦处理使得MonoDIS网络的损失参数在训练过程中下降更快,避免了各参数间误差传递的干扰,其在KITTI数据集上的验证结果也表明更优于其他级联网络的检测准确性。
目前,基于单目视觉的3D 目标检测算法已成为研究热点,其研究方法大致可以分为两类:(1)根据区域提取生成目标候选框,结合一系列定义的先验信息回归精确的3D检测框;(2)利用CNN网络直接提取目标的3D特征信息,再结合模板匹配、重投影、深度估计等方法解算位置信息,得到精确的3D 检测框。单目方法在数据处理上有其独有的优势,且单一传感器使用成本较低,主要缺点是缺少深度信息,限制了3D 目标的检测和定位精度,尤其是对于遮挡、截断以及远距离目标的检测。
3.2 基于双目/深度视觉的三维目标检测
对于单目视觉的三维目标检测算法来说,深度信息的估计偏差是导致检测精度较低的主要原因,尤其是对远距离和遮挡目标的定位。双目/深度相机依赖其准确的深度信息的优势,在三维空间的视觉算法应用中,尤其针对目标检测与定位任务,相比于单目视觉算法具有明显的检测精度的提升。
在室内场景的三维目标检测过程中,Depth RCNN[20]利用2D 检测网络和HHA 特征提取CNN 网络实现3D目标检测,基于HHA 特征的深度图编码方式对室外场景下的目标检测同样适用,如图5 所示。针对这一方法,Chen 等人[39]提出了道路场景下的3D 目标检测网络3DOP。该网络结构在目标检测的框架中借鉴了Fast R-CNN网络结构[3],结合单目图像与HHA[20]特征生成高质量的候选区域框,并提出了3D 目标多特征先验的能量损失函数,其中先验特征包含了语义信息、点云密度、上下文信息等,采用结构化支持向量机训练模型,得到高质量的目标提取框和姿态信息。

图5 Depth RCNN网络结构
在基于深度图像的三维目标检测中,将深度特征作为网络输入是最常用的方法,该类方法在双目视觉中同样适用,但在双目图像中获取深度图会带来额外的计算量。因此,在双目视觉的三维目标检测算法的研究中,如何利用左、右相机单目检测目标的关联性实现基于双目视觉的三维目标检测是研究的热点。针对这一问题,Li 等人[51]提出了基于Faster RCNN[2]扩展网络的Stereo R-CNN三维目标检测网络。Stereo R-CNN将双目图像作为网络输入,取代了网络的深度输入,通过两个FPN[3]网络以及立体区域提议网络,同时对左右两侧图像进行目标检测并生成目标关联对,结合Mask RCNN[3]的关键点检测计算粗略的3D 目标检测框,再通过左右目标ROI区域对准恢复精细的3D检测框。相比于其他基于深度图像的三维目标检测算法,Stereo R-CNN 方法的特点是不需要深度输入,但其在KITTI数据集上的检测效果提升了近30%。
同样的,Qin 等人[52]提出了基于立体三角测量学习网络TLNet的双目视觉三维目标检测算法,不同于以往的像素级深度图,该方法利用立体图像的几何对应关系,构建目标级的深度关系。TLNet首先利用两个基于单目的3D 目标检测器分别实现左右图像的3D 目标检测,利用三维滑动窗口在立体图像RoI区域之间显式构造目标级几何对应关系,对目标进行三角定位。相比于单目的3D目标检测结果,三角测量法提高了检测精度,使得目标定位更加精确。另外,TLNet引入了特征加权策略,通过测量左右关联性来增强信息特征通道,采用权重调整方案滤除噪声和不匹配信道的信号,从而简化了学习过程,使网络更专注于目标的关键部分。无论是TLNet,还是室内场景下的DSS[27]、3D-SDD[29]算法,都可以看出相比将深度图作为附加输入的做法,直接对三维空间进行三维卷积可以有效提升精度。但是,目标特征往往只存在于物体的可见表面,因此三维卷积会带来很多额外的计算量。于是,Chu等人[53]提出了SurfConv,该算法采用基于深度感知的多尺度二维卷积取代了三维卷积,对三维空间深度离散化,沿着目标表面进行分层卷积。SurfConv 方法既解决了二维卷积的尺度方差问题,也减轻了三维卷积过程对内存的消耗。
基于深度/双目视觉的三维目标检测通常可以分为两类:(1)基于单目图像和深度图的双通道卷积神经网络融合的方法;(2)基于三维空间卷积的方法。另外,相比于深度图像,双目图像可以利用左右单目图像的匹配关系建立三维空间映射,从而可以在不需要深度输入的前提下实现三维空间目标检测。
在室外场景下的三维目标检测算法中,无论是单目视觉还是双目/深度视觉,在解决思路上存在一定的相似性,例如双目/深度视觉下的2.5D/3D 区域提议方法,单目视觉下的深度估计等等。但针对室外场景中车辆、行人等目标的三维检测,由于其类别具有鲜明的几何特性、位置特性等信息,可以充分利用模板匹配、先验信息融合等方法提升特定目标的三维空间检测精度。此外,相比于室内场景,室外场景的感知范围更广,目标尺度变化更大,三维空间卷积会造成计算量的大幅度增加。因此,利用单目视觉检测算法提升三维检测的准确性和实时性是目前室外场景下三维目标检测的关键。
4 数据集与评价指标
4.1 室内/外场景数据集介绍
深度神经网络模型的有效性是建立在大数据基础上,其快速发展与ImageNet[54]、PASCAL VOC[55]等公开数据集的发展与利用密不可分。因此,本章重点介绍现有室内/外场景下的3D 目标检测数据集,给出3D 目标检测的评判依据,并在后文中讨论分析前述方法的实验结果。
针对室内场景下3D目标检测和姿态估计任务的公开数据集主要有SUN RGB-D[18]和NYU Depth Dataset[56]。SUN RGB-D由10 335张深度图像组成,包含了47种不同的室内场景以及19 个目标类别,对每张图像都进行了2D 和3D 信息的人工标注,共有146 617 个2D 检测框和64 595 个3D 检测框的精细标注。NYU Depth Dataset 是由纽约大学发布的针对室内目标检测任务,利用Kinect 传感器进行深度图像采集的公开数据集。该数据集将室内场景分为浴室、卧室、厨房、客厅等多种类别场景,其中NYU Depth Dataset V1 包含了7 类场景,64 个不同室内场景共2 347 张深度图像,NYU Depth Dataset V2 包含了26 类场景,464 个不同室内场景共1 449 张深度图像。除此以外,还有RGB-D Object Dataset[57]、Cornell RGB-D dataset[58]等室内场景下目标检测数据集。
KITTI[4]数据集是针对自动驾驶环境感知算法研究中最常用的公开数据集之一,该数据集具有丰富的激光点云数据、图像数据、惯性导航数据以及GPS数据,可用于视觉测距、2D/3D 目标检测、目标跟踪、语义分割、光流等计算机视觉算法的研究。针对基于图像的3D目标检测任务,KITTI 数据集由7 481 张图片组成训练/验证集,7 518张图片组成测试集,超过了200K的3D目标标注信息。KITTI 数据集将3D 目标分为car、pedestrian、cyclist 等共8 种类别,标注信息包括类别、2D 检测框坐标、3D 中心点坐标、3D 尺寸、遮挡、截断以及航向角等信息。如表3所示,针对目标的大小、遮挡和截断情况,KITTI 数据集将目标分类为简单、中等和困难三类,根据对不同目标的检测结果做出算法评估。

表3 KITTI数据集目标分类
NuScenes[59]数据集是由nuTonomy 与Scale 发布的大规模自动驾驶数据集,该数据集不仅包含了激光点云数据、图像数据,还包括了Radar数据。另外,该数据集的图像采集为360 度采集,5 个相机分布覆盖了车体的360度方向同时采集图像数据,使得图像数据视野更具多样性。nuScenes数据集由1 000个场景组成,其中850个场景作为训练验证集,另外150 个场景作为测试集。每个场景长度为20 s,有40 个关键帧,并对每个关键帧中的目标进行手工标注。nuScenes数据集主要针对3D目标检测任务,共标注了道路场景下23类目标的3D检测框信息,并且标注信息可实现与KITTI集标注格式间的转换。相比于KITTI数据集,nuScenes数据集数据规模更大,另外包含了白天、夜晚以及不同天气、光照等更多场景状况的应用。
PASCAL3D+[60]是在PASCAL VOC2012 数据集基础上,针对3D目标检测与姿态估计任务,进行3D目标标注的公开数据集。PASCAL3D+对PASCAL VOC2012中的12个刚性类别目标进行了3D注释,结合ImageNet为每个类别增加了更多的图像数据,并针对每一个类别进行了三维信息统计,生成相应的3D CAD模型。与其他的室外场景下的3D数据库相比,PASCAL3D+对每个类别都有超过3 000 个对象实例,类别数据更加丰富。其他的针对室外场景的3D目标检测公开数据集还有如NYC3DCars、LabelMe3D等等。
表4归纳总结了各室内/外场景下的3D目标检测数据集特点,室内、室外场景在目标特征、环境干扰因素等方面都存在较大的差异。相比之下,室内场景下的目标类别更多样化,无论是NYU Depth Dataset 还是SUN RGB-D等数据集,都包含了床、餐桌、灯具、浴缸等10类以上的标记类别,并具有餐厅、卧室、办公室等不同室内场景分类,不同场景特征区分也较为明显。而室外场景下的目标检测,主要针对车辆、行人等道路环境中存在较多的目标,目标的外观、形状等纹理特征均较为明显。另外,室内和室外场景的视野范围存在较大差异,室外场景下图像可视范围较大,因而存在较多距离较远的小尺寸目标,目标间的遮挡情况更加突出。

表4 三维目标检测公开数据集对比
4.2 评价指标
在二维目标检测任务中,通常采用查准率(Precision)和查全率(Recall)是定性分析检测网络的有效性,采用平均准确率(Average Precision,AP)定量评估单类检测结果精度。所谓的查准率,是指被判断为正例的目标中检测正确的比例;查全率是指所有正例中被检测出的比例。在目标检测中,定义了目标检测框和真实值的重叠率IoU,通过设定IoU阈值t 判断检测结果中真正例TP、假正例FP、假反例FN的数量。

通过给定的不同阈值t ,得到对应的查准率和查回率值,从而绘制Precision-Recall曲线积分计算目标检测平均准确率(Average Precision,AP)。当t 是离散数据时,AP 为不同阈值t 的查全率对应的查准率的平均值。为了简化计算,PASCAL VOC[55]数据集采用了插值方法计算检测器的AP 值,在[0,1]上以步长为0.1 等间距取查全率上的查准率值。
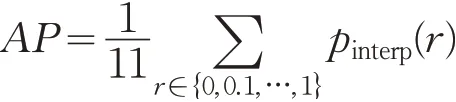
而在3D检测任务中,针对室外场景下车辆、行人等目标,常常采用KITTI数据集下定义的评价指标评估检测器的性能。KITTI评价指标包含3个主要内容:2D检测框平均准确率AP2D、3D 检测框平均准确率AP3D以及平均角度相似性AOS。其中,AP2D采用二维目标检测器的AP 计算方法,将世界坐标系下三维检测框投影到图像坐标系下,通过IoU计算AP值。但在三维检测中,图像坐标系下坐标并不能直接表示三维检测框的准确性,其原因不难解释,由于世界坐标系与图像坐标系的转换关系,对于世界坐标系下不同大小、不同位置下的目标,当其投影到二维图像上时可能得到相同的二维检测框。因此,Chen 等人[13]在MV3D 中引入了AP3D指标,与AP2D计算过程的不同在于其IoU 值为世界坐标系下三维检测框检测值与真值的重叠率。针对三维目标检测任务,KITTI数据集定义了AOS指标用来评价目标航向角预测结果。根据定义,有如下计算过程:
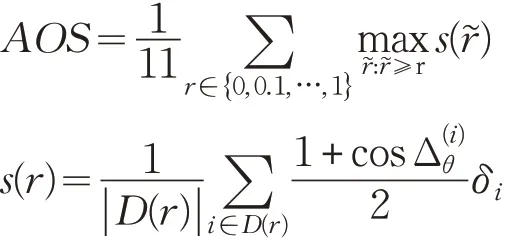
式中,r 为PASCAL 中二维目标检测的查全率,s(r͂)为方向相似性,定义为所有预测样本与真实值余弦距离的归一化。D(r)表示在查全率r 下所有预测为正样本的集合,表示检出目标i 的预测角度与真实值的差。为了防止多个检出匹配到同一个真实值,如果检出目标i 已经匹配到真实值(IoU至少50%)设置δi=1,否则δi=0。

表5 SUN RGB-D数据集三维检测结果对比%
5 实验及分析
本文分别介绍了室内场景和室外场景下基于图像的三维目标检测算法,其中对于室内场景下的检测和姿态估计算法,主要采用SUN RGB-D数据集进行各算法的性能比较;对于室外场景下的三维目标检测,主要采用KITTI 数据集以及评估标准对各算法进行实验结果的对比与分析。主要实验结果对比与分析如下。
针对室内场景下的三维目标检测任务,表5给出了不同算法在SUN RGB-D 数据集上10 类标记目标的实验结果。从表中结果可以看出,各算法对于多目标的检测准确率相差较大,例如对于马桶、床等目标的识别准确率可达到80%以上,但对于书柜、床头柜的识别准确率却在50%以下。另外,实现结果表明F-PointNets 算法[30]对于室内场景的三维目标检测同样具有较好的表现,多类目标下的平均准确度达到了54%,但不同目标间依旧存在较大差距。造成目标识别精度差距较大的原因主要有两方面,首先是数据集本身特点,在SUN RGB-D 数据集中各种类目标数量存在差异;其次是目标本身的特点,例如床头柜、梳妆台等目标,其本身尺寸相对较小,且在室内场景中往往处于被遮挡状态,使得其纹理和深度信息相对较少,为目标检测与定位造成一定的难度。根据表5,可以看出DeepContext 算法有效提升了该类目标的检测精度,该算法通过定义室内场景模板,提升了诸如床头柜、椅子等易被遮挡物体的检测精度。
在三维目标检测任务,Mono3D[38]、Deep3Dbbox[40]、3DOP[39]等算法均利用2D 检测器实现目标的检测与分类,再进一步回归目标的三维特征信息,因此2D检测结果也直接影响三维目标检测的准确性。表6 给出不同的三维目标检测网络在KITTI数据集下,车辆目标的二维检测结果以及平均航向角预测结果。从表中可以看出,二维目标检测结果均较为理想,尤其对于简单目标来说,在IoU 阈值设置为0.5 时基本可以达到90%以上。其中基于双目视觉的Stereo R-CNN[51]对简单目标的识别平均准确率达到了98.53%,相比于大多数基于单目视觉方法提升了近5%。针对车辆目标的航向预测准确度也同样达到了较高的水平,对于简单目标达到了90%以上,中等目标达到了85%以上。但对于存在大部分遮挡、截断或者尺寸较小的困难目标,无论是二维检测的平均准确率还是航向角预测,准确率都未达到80%。因此,如何提高存在遮挡、截断、小尺寸等目标的有效识别率仍是目标检测任务中有待解决的关键问题。

表6 KITTI数据集车辆目标检测AP2D、AOS指标对比%
三维目标检测的目的是获取目标在世界坐标系下尺寸、位置和航向信息,因此,采用Chen 等人[13]提出的三维目标平均检测率评估预测结果。表7 总结归纳了室外场景下车辆目标三维检测平均准确率结果,并对比了IoU 阈值分别设置为0.5 与0.7 对检测结果的影响。根据表7 结果显示,当IoU 阈值为0.5 时,基于单目视觉的三维目标检测算法中,MonoGRNet[42]检测结果最为理想,相比于Mono3D[38]等方法准确率提升了近一倍,对于简单目标的检测准确率可以达到50%左右。当IoU 阈值设为0.7 时,各算法准确率均有大幅的下降,其中准确率最高的MonoDIS[50]算法针对简单目标只能达到18.05%,而对于困难目标准确率均在10%以下。相比之下,基于双目/深度图像的三维检测结果提升了很多。其中,在IoU=0.5 时,对于简单目标的识别率最高达到了85.84%,对困难目标的识别也达到了57.24%。当IoU=0.7 时,对于三类目标,F-PointNets[30]的检测准确率分别达到了83.76%、70.92%和63.65%,相比于3DOP算法[39]提升了近10倍。

表7 KITTI数据集车辆目标检测AP3D指标对比
对比表7的实验结果不难发现,基于双目/深度图像的三维目标检测结果大大优于单目图像的检测结果,这主要就是因为单目图像中深度信息的缺失。其中,MonoGRNet[42]、MF3D[41]等表现较好的算法中均融合了基于单目视觉的深度估计算法,但由于单目视觉的深度估计本来存在较大误差,因此导致了目标位置的误差。由此可见,深度信息对于三维目标检测的重要性。
此外,表7对各室外场景下的三维目标检测算法的运行速度进行了总结对比,表中总结的运行速度数据主要来源于KITTI数据集的3D目标检测任务。从表中的对比结果可以看出,目前三维目标检测算法的运行速度普遍在0.1 s以上。其中,Mono3D[38]和3DOP[39]的运行速度甚至达到了3 s 以上,这是因为其复杂的先验信息融合和密集的区域提议生成方式。针对单目视觉的三维目标检测算法,MonoGRNet[42]采用实例级的深度估计算法,忽略非目标区域的深度估计,使得网络运算量进一步减少,将运行速度提升到了0.06 s/张。其次,在双目/深度视觉中,F-PointNets[30]算法的处理速度达到了0.17 s/张,相比于其他双目/深度视觉算法运行速度提升了近一倍。F-PointNets算法将深度图转换为点云数据,基于三维点云网络实现三维目标检测,相比于直接在立体空间中运用三维卷积的方法,省略了大量的空卷积过程,减少了计算量。另外,对比基于单目和双目/深度视觉算法的运行速度不难发现,目前单目视觉算法的运行速度并没有显著优于双目/深度视觉算法,这是因为目前单目视觉方法主要结合了深度估计网络,增加了网络的复杂度,使得计算量增加。因此,如何在提升检测精度的同时简化网络,减少计算量,是目前提升三维目标检测算法性能的关键。
相比于道路场景下车辆目标检测,各算法对行人、自行车等其他目标检测结果对比的研究则较少。表8总结归纳了部分算法给出的针对室外场景下行人与自行车等目标的三维目标检测平均准确率(AP3D)结果,其中IoU 阈值取0.5。通过表中结果对比不难发现,在行人、自行车等目标识别中,基于双目/深度图像的检测结果远远优于基于单目图像的检测结果。其中,基于深度图像的F-PointNets 算法模型[30]在行人检测中准确率达到了40%以上,自行车检测准确率达到了50%以上,而基于单目图像的算法中效果只能达到10%左右。同时,将表7 与表8 结果对比可以发现,对于车辆目标的三维识别准确率要高于行人、自行车等目标的识别准确率,这主要因为行人、自行车等目标相比与车辆目标来说,尺寸更小,姿态更具有多样性,因此在定位与姿态估计任务中更加困难。

表8 KITTI数据集行人、自行车目标检测AP3D指标对比%
6 结束语
本文系统总结了近年来基于视觉的三维目标检测算法,针对室内、室外不同的应用场景,分析了三维目标检测任务的难点,归纳了不同场景下基于单目、双目/深度视觉的三维目标检测算法。另外,系统介绍了针对三维目标检测的评价指标,并在KITTI、SUN RGB-D等数据集上进行了实验结果的对比分析。针对三维目标检测,实验结果的对比分析表明:
(1)在室内场景中,针对不同目标的检测精度差距较大,其中,对于床、马桶等形状特征明显的目标识别准确率较高,而橱柜、桌椅等目标识别率相对较低。
(2)在室内场景中,基于三维特征提取的检测网络,例如F-PointsNets[30]、3D-SSD[26]等,多目标的平均识别准确率高于其他基于2D检测网络方法。
(3)针对室外场景中的车辆目标三维检测任务,其二维检测精度和航向角检测精度达到了较好的水平。其中,针对简单目标的检测精度可达到95%以上,对于困难目标检测精度达到80%。
(4)针对室外场景中的目标三维空间信息估计,深度/双目视觉下的检测精度远远高于单目视觉下检测精度。其中,针对车辆目标,IoU 阈值为0.7 时,基于深度/双目视觉的F-PointsNets[29]算法三维信息估计精度可达到60%以上,而基于单目视觉的检测效果最高只能达到13.42%。针对行人、自行车等目标,IoU 阈值为0.5 时,基于深度/双目视觉的检测算法精度可达到40%以上,而基于单目视觉的检测精度在10%以下。
(5)在室外场景中,对基于单目视觉的三维目标检测算法的分析比较表明,融合深度估计网络的检测算法精确率普遍高于其他基于几何特征、三维模型检测算法。
相比于二维目标检测网络,三维目标检测在准确性、实时性等关键指标方面还有较大的提升空间。经过对现有的三维目标检测算法的分析与总结,未来对该任务的研究方向可包含以下方面:
(1)对于室内场景下的三维目标检测,需要提升多目标检测精度。特别地,针对一些室内场景下的特殊目标,如尺寸较小,纹理特征不明显,易非刚性形变,外观特征多样等目标,如何提升三维姿态检测精度是进一步研究的关键。
(2)对于室内场景下的三维目标检测,目标之间往往存在一定的关联,能否利用目标间的关联约束提升室内场景下多目标的检测和定位精度可以进一步研究。
(3)对于室外场景下的三维目标检测,如何解决遮挡、截断和远距离的小尺寸目标的检测与定位精度是亟需解决的关键问题。
(4)无论是室内场景,还是室外场景下,基于单目视觉的三维目标检测精度均较低,关键在于如何提升单目视觉下的目标三维空间定位精度。目前,依靠融合基于单目视觉的深度估计网络存在两个主要问题:一是深度估计算法本身存在较大误差,不能满足定位精度需求;二是网络融合增加了网络架构的复杂度,计算量大大增加。
(5)目前基于双目视觉下的三维目标检测网络大多基于二维目标检测架构,融合深度图特征实现目标的三维检测,常用的深度图特征有HHA[20]、COG[31]等;另一方面,通过三维立体场景恢复,实现三维特征提取。这两类方法对检测精度都有较大的提升,但是都存在特征提取计算量较大,网络架构较为复杂的问题。因此,如何简化深度/双目视觉下的三维目标检测网络是进一步研究的重点。
基于视觉的三维目标检测网络包含了目标在三维空间的定位、姿态估计和图像坐标系中的三维检测框恢复。相对于二维目标检测来说,三维目标检测更具有实际应用的需求,关系到了自动驾驶、机器人等领域中感知系统的有效性。因此,基于视觉的三维目标检测已成为计算机视觉研究中的重要方向。
