网络多媒体数据中舆情关联主题的挖掘方法
2020-01-06刘润奇贺兴时南夷非
刘润奇,贺兴时,南夷非,王 博
1)西安工程大学理学院 陕西西安 710048;2)西安交通大学智能网络与网络安全教育部重点实验室 陕西西安 710049
近年来,微博和论坛等新媒体的快速发展极大方便了人们的生活,但也为网络谣言和舆情的快速传播提供了温床,给社会稳定和安全带来了巨大挑战[1].据不完全统计,在中国目前微博月活跃用户共3.76亿人,日活跃用户达到1.65亿人,每天产生的帖子不计其数.随着5G网络的推行,会进一步提升网络使用的便捷度,加快舆情事件的传播速度.与此同时,越来越多的舆情事件依托图片和视频等多媒体文件进行传播以躲避传统的基于文本的舆情事件检测,本课题组在2018年7—9月对新浪微博中的博文进行了分析,发现55%的博文包含图片信息,35%的博文包含视频信息,这些异构的多模态数据给舆情的有效监管造成了较大的困难.
舆情事件在近两年被大量研究.梁冠华等[2]将舆情划分为潜伏期、发生期、持续期和恢复期,并结合不同阶段的特征,设计了涵盖舆情防范风险、发生风险、传播风险和消退风险的指标体系,综合评估舆情的演化态势.陈建敏等[3]也从指标体系出发,提出涉军网络舆情安全评估指标体系的内容构成,具体包括发布者指标、受众指标、激体指标、本体指标和传播指标,综合评估涉军舆情的评估方法.丁晟春等[4]根据“帖子-主题”二模网络模型和关键词以及社区属性对网络舆情态势进行评估.郑魁等[5]提出一种网络舆情热点信息的自动发现方法.该方法对文本进行分词和词频统计,从词频表中去除停用词得到突发事件热点信息关键词列表,对网络信息及时检索,为突发事件应急决策提供技术支持.张艳丰等[6]采用扎根理论提取指标要素,通过直觉模糊推理算法和模糊综合评判法进行网络舆情监测预警.杨频等[7]提出一种网络舆情的定量分析方法,该方法将对于某话题的文本集合作为输入,输出一个实数表示文本中所表达的观点倾向程度.陈星宇等[8]从客户的参与、认知和情感3个维度出发,根据3维手动预定义关键词,并基于这些关键词找到特征客户,最终以特征客户作为训练集,获得更多关于3个维度内容客户特征的关键词,以达到进一步细分客户的目的.这些方法的提出一定程度解决了网络舆情的监控问题.如何在文本信息检测的基础上,进一步处理图片和视频等多媒体数据的检测,是一个亟需解决的问题.为此,本研究提出结合深度神经网络的多媒体文本信息识别方法,并在此基础上提出了多粒度潜在狄利克雷分布(multi-granularity latent Dirichlet allocation, MG-LDA)[9]与jieba分词[10]相结合的舆情关联主题抽取方法,以期挖掘社交平台多媒体多数据中蕴含的舆情事件.
1 识别方法框架
本研究选择新浪微博(http://weibo.com/)上近期关于性侵、疫苗和网贷3个社会反响强烈的舆情事件为研究对象,采用Scrapy框架设计爬虫实现这些事件中文本、图片和视频等多媒体数据的爬取.通过分析收集到的数据,发现文本数据占64%,图片和视频数据占36%,且绝大部分图片和视频包含文本信息.因此,为便于处理,将视频分帧,并与图片数据一并处理.由于许多图片的分辨率严重失衡,如低至365×16 367 像素,可将其分割为1 000×1 000像素的固定图像块.同时,删除一些无文字的图和严重失真的无效图,以保证数据集的可靠性.
分析数据特点后发现,社交媒体中的图片具有独特的特征,如文本信息多有不同角度的旋转,且文字样式和颜色多变.因此,为提升不同颜色、不同角度的文本识别精度,需先对偏转的文字进行水平处理,对彩色文字进行灰度处理.其中,特殊的白色字体需进行反转处理.最后,结合所提取的文本信息,采用MG-LDA和jieba分词相结合的方法,挖掘图片中蕴含的舆情主题.MG-LDA比传统的LDA(latent Dirichlet allocration)[11]主题识别方法更易发现全局主题中的局部特征,即能够提取更多文本中的有效信息.jieba分词则是一款十分优秀的开源分词引擎,它结合了基于字符串匹配的算法和基于统计的算法,采用动态规划查找最大概率路径,找出基于词频的最大概率组合,可以在分词速度快的同时,保持较高的分词精度.结果表明,本研究方法可有效实现不同格式多媒体数据中不同颜色、不同角度、不同位置的文本识别与提取,并在此基础上实现舆情关联主题的挖掘,有效提高多媒体数据中舆情主题的监管效率.
多媒体数据中的网络舆情事件关联主题检测模型框架如图1,对应步骤的具体描述为:
1)数据收集与预处理.结合自媒体的特征,在Scrapy框架下设计网络爬虫,收集包括文本、图片和视频等多模态数据,对视频数据进行离散化处理,形成图片.
2)文本信息识别.使用连接文本提议网络(connectionist text proposal network, CTPN)[12-13]方法实现图片数据中文字的检测,用密集卷积神经网络(DenseNet)和连接时序分类(connectionist temporal classification, CTC)结合的方法进行文字识别,通过图片切割、水平调整、灰度处理等方法实现不同分辨率、不同角度和不同颜色的文本提取.
3)关联主题识别.结合2)中提取的文本特征,采用jieba模块进行分词处理,并使用MG-LDA对其进行主题识别.
4)舆情演化趋势管理.深度融合图片数据中关联主题的识别结果和文本数据中的识别结果,以期更准确掌握舆情的演化态势.
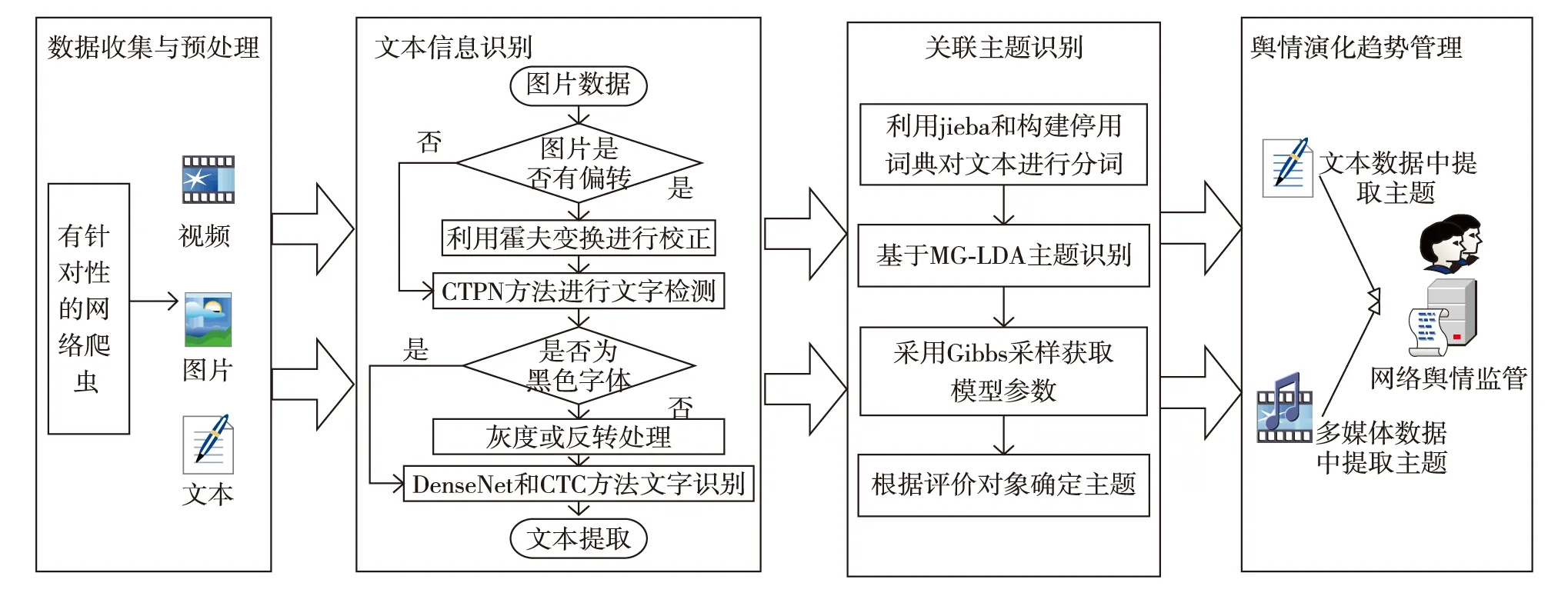
图1 舆情检测框架
2 多媒体数据中文字识别方法
2.1 具有旋转角度的文字定位方法
传统的文字定位方法大多采用bottom-up,即先用滑动窗口等方法提取候选区域,再用支持向量机(support vector machine, SVM)和卷积神经网络(convolutional neural network, CNN)等算法做字符分类器,最后做字符聚类、字符分组和字符切割等使其形成文本线.但这种方法不够鲁棒、候选区域过多、需人工干涉,且易造成误差积累.HE等[14]提出top-down方法,通过先检测文本区域再测出文本线来提高识别准确率.随着深度神经网络的发展,TIAN等[15]提出新型文字定位方法CTPN,结合了CNN和RNN优点.深度学习为图像中文本信息的抽取奠定了良好的理论基础,提升了文本识别的效率和准确度.但是,这种方法只对水平文字具有较好的效果,对偏转的文字检测效果则欠佳.本研究通过在CTPN方法定位文字前先对图片进行旋转处理,再对文本区域进行水平化,利用霍夫变换检测直线对有偏转角度的图片进行校正,提升了文本识别方法的鲁棒性.具有旋转角度的文字定位方法的操作流程如图2.
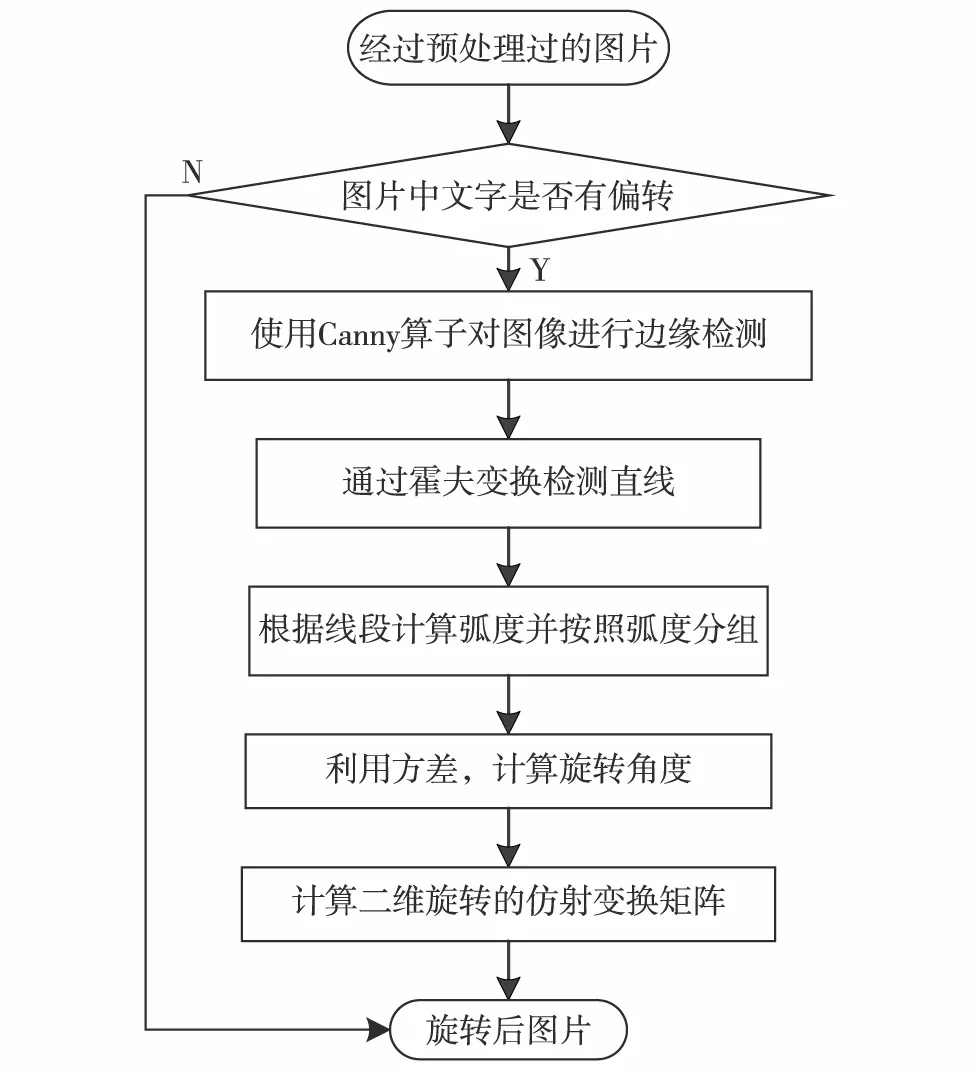
图2 校正偏转角度文字流程
2.2 多颜色文字提取方法
DenseNet 是一种具有密集连接的卷积神经网络.在该网络中,任意两层之间都有直接的连接,每层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入.DenseNet与ResNet的主要区别在于后者是求和,而前者是做拼接,这种网络与传统网络相比更能提升信息和梯度在网络中的传输效率.
CTC[12-13]主要用来解决时序类数据的分类问题,即实现输入序列到输出序列的映射.本研究采用密集卷积神经网络DenseNet提取文字图像底层特征,加入时域连接模型CTC解码获得识别的文字.但是该模型是在黑色标准字体下训练得到的,对于包含其他颜色文字的图片处理效果欠佳.据此我们首先对图片进行灰度处理,使其三维像素矩阵转换为二维.对于白色字体进一步对其进行反转处理,即像素值由0转为255,依此来提升不同颜色字图的识别效果.多颜色文字提取的操作流程见图3.
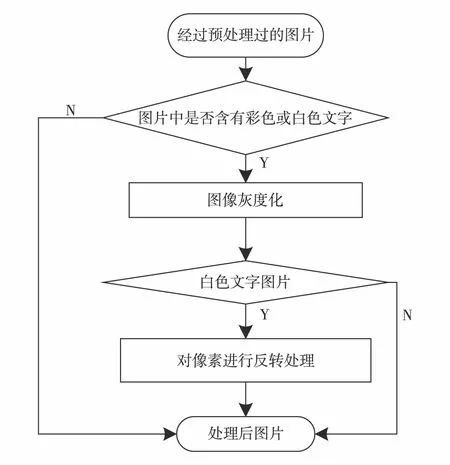
图3 处理有色文字流程
3 基于MG-LDA与jieba分词的图像主题识别方法
由于本研究采集到的图片是针对同一类型事件的,识别后的文本数据在文本结构特征上更易出现难以挖掘主题的现象,所以采用MG-LDA[9]模型建模,通过区分全局主题和局部主题,可更好地发现图片中讨论的舆情要素.根据文献[9]方法获得模型参数,并基于jieba 和构建停用词典对词语进行分词处理.基于MG-LDA的图像主题识别方法的具体流程见图4.

图4 MG-LDA主题识别流程
4 实验与分析
4.1 数据收集
本研究选择新浪微博中近期3个社会舆论反响强烈的敏感话题为研究对象,爬取收集性侵、疫苗和网贷3个热点事件下的文本、图片和视频数据,结果如表1.其中,文本表示博文的数量;图片表示博文中包含图片的数量;彩色文本表示包含有彩色文字图片的数量;歪斜文本表示包含有偏转角度文本图片的数量.由表1可见,歪斜文本和彩色文本占比不小,需要根据它们的特征进行适当的处理,才能取得理想的识别效果.
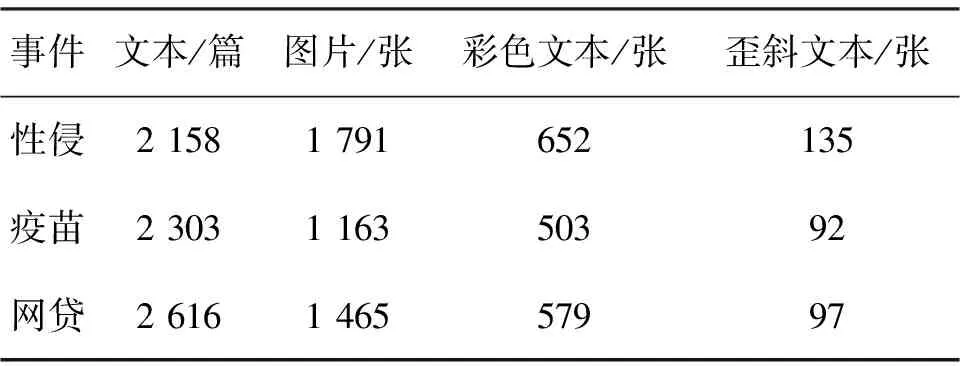
表1 舆情事件数据集统计
4.2 文本提取结果分析
采用本研究方法,从图片中获取和直接获取的文本,处理后的数据集如表2.其中,文本数据为直接从文本数据中提取的字符数量;图片数据为经过对图片进行文本信息识别提取的字符总量.由表2可见,图片中文本数据的占比超过50%,表明对图片中的文本数据进行识别和分析非常重要.
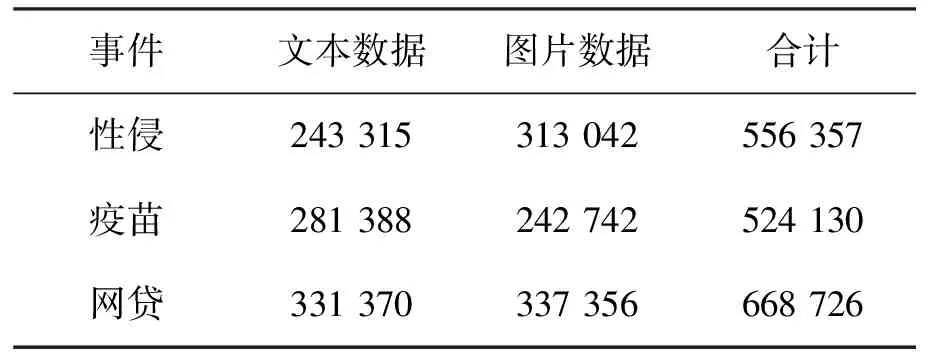
表2 文本处理结果
使用文本数据的提取率、准确率和算法的时间复杂度3个指标评估算法性能.文本数据的提取率为能够从图片数据中准确识别并提取文本的比例,用来衡量是否能够提取出图像数据中的文本数据.文本信息提出的准确性为识别出文本信息的正确率.时间复杂度为处理一定数量的图片所需时间,用来衡量所提方法的实用性.对所收集到的4 419张涉及3个舆情的图片数据进行文本识别,结果发现,采用本研究方法对歪斜字体进行旋转处理和对图片中存在的彩色字体进行灰度或反转处理,提取率为96.23%,准确率为95.31%;而不对图片做任何处理的未改进方法,提取率为50.23%,准确率为65.23%,可见本研究方法可大幅提升识别方法的提取率和准确率.
分别在中央处理器(central processing unit, CPU)和图形处理器(graphics processing unit, GPU)环境下进行时间复杂度分析,基于与Python3.6相匹配的Anaconda库,使用TensorFlow、Keras、OpenCV等模块实现.实验结果如图5.由图5可见,在GPU环境下可以大幅度的压缩计算时间,进一步满足了实效性的要求.

图5 不同环境下时间复杂度对比
4.3 关联主题结果分析
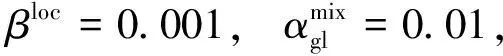
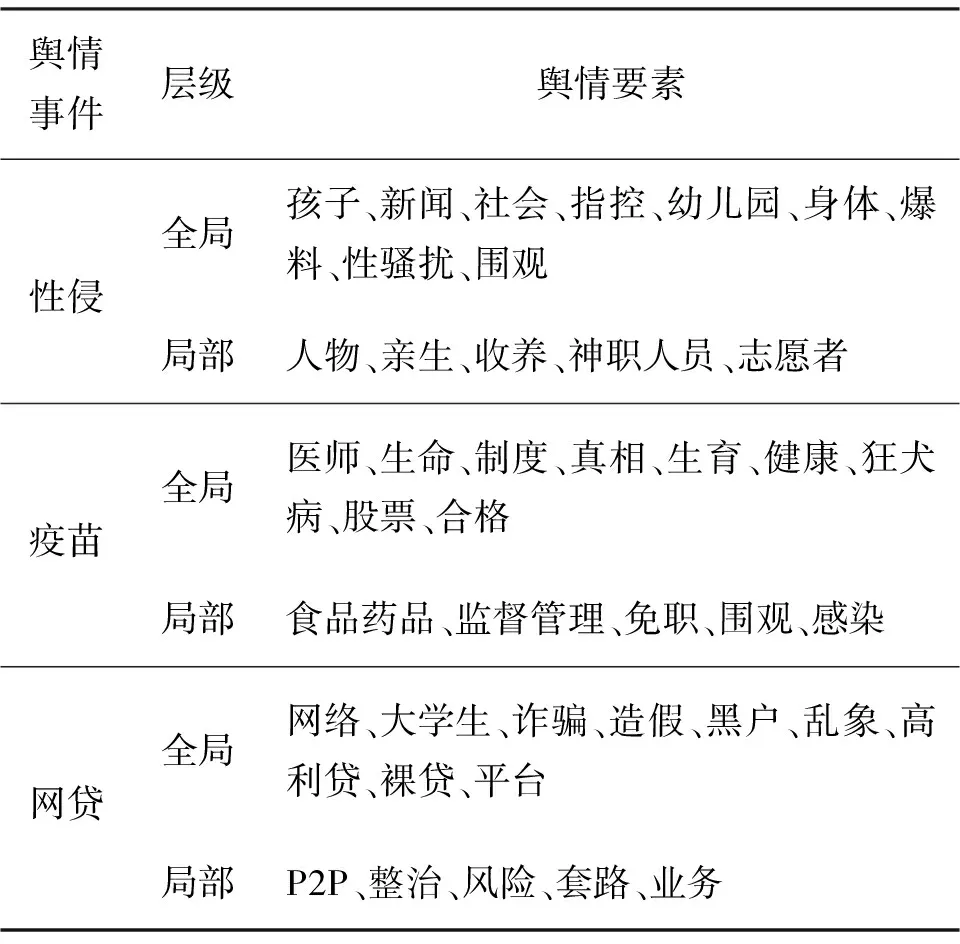
表3 文本数据主题识别结果
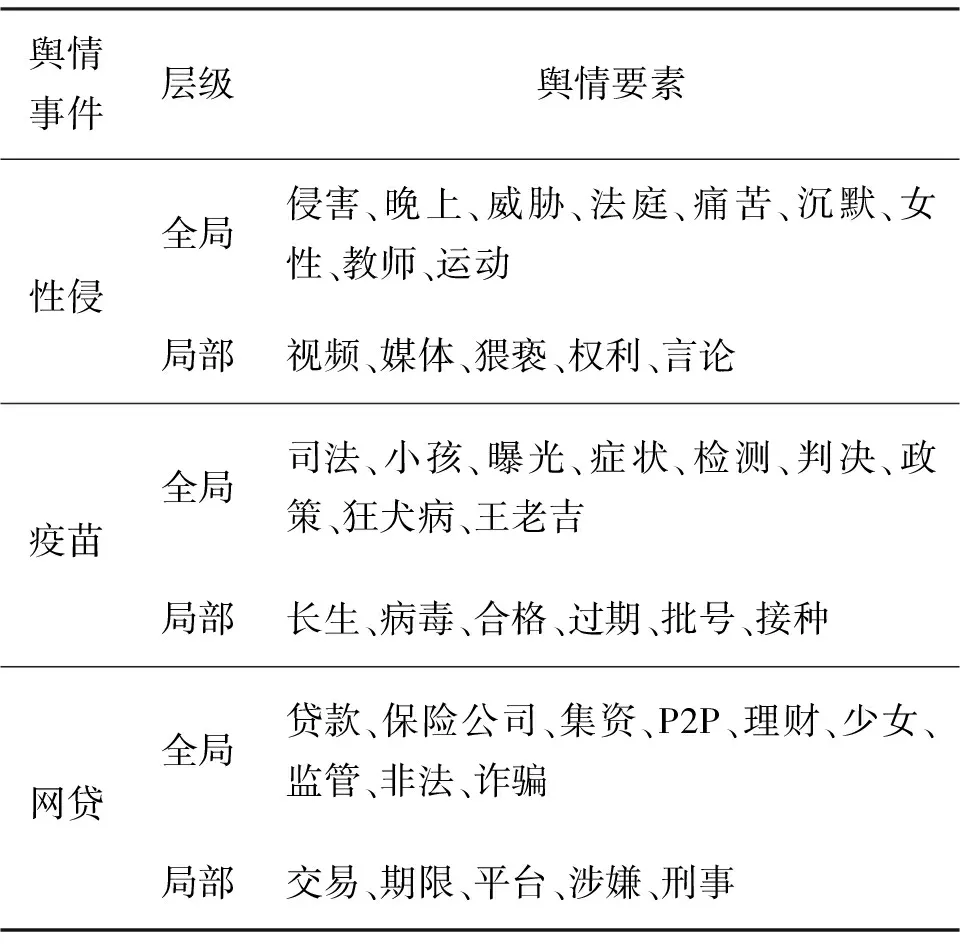
表4 图像数据主题识别结果
结 语
通过研究社交媒体图片的文本识别方法及其在网络舆情监管的应用,结合所收集的图片的特征,针对图片中因字体歪斜、字体颜色多变等特点给文本提取带来的困难,提出了不规则图片数据中文本的识别与提取方法,并对所提文本的主题特征进行了分析.对收集到的新浪微博上关于性侵、疫苗和网贷3个热点事件的关联文本和图像数据的提取和主题识别结果表明,所提方法在社交媒体图片的文本识别中具有较好的性能,能够解决社交媒体图片不规则字体的提取,为网络舆情监管提供了有力的技术支撑.下一步,我们将主要分析如何识别一些图片中存在的多语言文字,进一步挖掘图像中蕴含的和网络舆情相关的语义信息.
