几种数据挖掘方法用于中医证候分析的对比研究
2019-12-30许玉龙盛梦园王哲王晓辉吕雅丽修沁
许玉龙 盛梦园 王哲 王晓辉 吕雅丽 修沁
摘要:目的 探討不同无监督数据分析方法分析中医证候的效果差异。方法 基于临床采集的肝炎肝硬化患者中医症状数据,比较层次聚类、因子分析、复杂网络、K-means方法从症状和患者角度分析中医症状数据、挖掘其潜在规律、根据医学知识对数据分类及归纳得到证候的差异。结果 从症状角度分析,层次聚类基于症状变量之间的距离关系进行聚类,能反映近似的症状从而推导出证候;因子分析用降维寻求少数潜在变量来综合反映原始指标的大部分信息,能反映出证候的主要症状。但这2种方法都无法将一症状同时归纳到多个证候,不适合临床实际中某症状属于多种证候的情况。复杂网络通过症状及症状的关系构建网络,较适合于对某种确定证候所涉及的症状进行分析,但不太适合对证候的推导与辨证。从患者角度分析,层次聚类和K-means对患者人群聚类后,可把相似的患者聚为一类,但不能同时从多个侧面进行聚类,即无法体现一个患者同时具有多种证候,不适合实际临床中的多种证候兼夹情况;对比专家组经验并分析频次发现,二者聚类结果一般。结论 使用常规数据挖掘方法分析中医数据,在挖掘从症状到证候的关系时,单个方法能完成单一角度分析,但无法同时满足症状属于多种证候、患者具有多种证候的兼夹情况等多角度分析,需要改进或尝试采用新的方法研究从症状到证候的数据挖掘问题。
关键词:层次聚类;因子分析;复杂网络;K-means;中医证候
中图分类号:R241;R2-05 文献标识码:A 文章编号:1005-5304(2019)12-0097-06
DOI:10.3969/j.issn.1005-5304.2019.12.020 开放科学(资源服务)标识码(OSID):
Comparative Study on Data Mining Methods for Analysis on TCM Syndromes
XU Yulong1, SHENG Mengyuan1, WANG Zhe1, WANG Xiaohui1, LYU Yali1, XIU Qin2
1. Institute of Information and Technology, Henan University of Chinese Medicine, Zhengzhou 450046, China; 2. Tingzhou Hospital of Fujian Province, Longyan 366300, China
Abstract: Objective To explore the differences in the effects of different unsupervised data analysis methods in the analysis on TCM syndromes. Methods Based on the collected clinical data of TCM symptoms of hepatitis cirrhosis patients, four methods including hierarchical clustering, factor analysis, complex networks and K-means were compared to analyze TCM symptom data, mine potential rules, classify data according to medical knowledge and conclude syndromes from the perspective of symptoms and patients. Results From the perspective of symptom analysis, hierarchical clustering considered the distance relationship between symptom variables to cluster, which could reflect the approximate symptoms and derive the syndromes; Factor analysis used dimension reduction to find a small number of potential variables to comprehensively reflect most of the information of the original indicators, which could reflect the main symptoms of syndromes. However, neither of these methods could summarize a symptom into multiple syndromes at the same time, and was suitable for the situation in which a certain symptom belonged to multiple syndromes in clinical practice. Complex networks built networks through the symptoms and their relationship, which were more suitable for analyzing the symptoms involved in some certain syndromes, but were not suitable for the derivation and differentiation of syndromes. From the perspective of patients, hierarchical clustering and K-means clustered patients and grouped similar patients into one category, but could not cluster from multiple aspects at the same time. That meaned, it could not reflect a patient with multiple syndromes at the same
time, and then was not suitable for a variety of syndromes in the actual clinical situation; By comparing the experience of the expert group and analyzing the frequency, it was found that the results of the two clusters were mediocre. Conclusion In the case of using conventional data mining methods to analyze TCM data, a single method can finish analysis with a single angle when mining the relationship from symptom to syndrome. However, it is impossible to simultaneously satisfy multi-angle analysis with the conditions of symptoms belonging to multiple syndromes and patients having multiple syndromes. It is necessary to improve or try to use new methods to study the data mining problem from symptom to syndrome.
Keywords: hierarchical clustering; factor analysis; complex networks; K-means; TCM syndromes
中医辨证施治的过程,即从症状到证候的分析与确定是中医诊病的关键步骤[1]。但中医证候的隐匿性、模糊性等特点导致其诊断过程难以形成统一的标准[2]。现代技术研究中医证候的常用方法有统计分析、因子分析、聚类算法等[3]。统计分析仅能统计出症状出现的次数、均值、方差等。因子分析把症状视为实数值变量,并假设其由一组相互独立的实数值隐变量(代表证候)通过线性关系来确定。聚类算法是对症状进行分析,并基于数据的知识将其聚成不同的类别[3-6]。隐结构分析是特殊聚类算法[7],依据统计学和概率知识对症状数据分析,找出隐变量并建立相应隐结构模型,然后依据模型对患者进行聚类划分。
笔者基于肝炎肝硬化患者的中医临床症状数据,采用层次聚类、因子分析、复杂网络、K-means方法,分别从症状和患者角度挖掘证候,并参考专家组经验辨证结果,将挖掘结果分析对比,探讨不同方法在中医证候挖掘中的合理性,为相关研究提供参考。
1 几种数据挖掘方法简介
1.1 层次聚类
层次聚类分为分裂法和凝聚法。常用的是凝聚法[8],即由下向上对小的类别进行聚合,其基本过程为:①给定要聚类的N个对象及N×N的距离矩阵(或相似性矩阵)。②将每个对象归为一类,共得到N类,每类仅包含1个对象,类与类之间的距离就是它们所包含对象的距离。③找到最接近的2个类合并为一类,类的总数减少1个。④重新计算新类与所有旧类之间的距离。⑤重复③④,直到最后合并为1个类为止(此类包含了N个对象),树的顶层是聚类的根节点,根节点覆盖了全部的数据点。层次聚类的优点是可以一次性得到整个聚类过程,缺点是计算量较大,分析大数据时,花费时间较长。
1.2 因子分析
因子分析是从分析多个原始指标的相关关系入手,找到支配这种关系有限的不可观测的潜在变量,即公因子,并用这些潜在变量来解释原始指标之间相关性的多元统计分析方法[9-10]。换言之,因子分析是用降维视角,从多个原始指标的相关系数矩阵出发,探索能综合大部分指标信息的独立潜在变量,即寻求少数的几个变量来综合反映所有变量信息。因子分析是多元统计分析中的一个重要方法,其特点是消除症状的多元共线性,对症状进行降维。
1.3 复杂网络
复杂网络是对现实生活中事务的抽象表达,是图的一种重要应用[11]。复杂网络中用图的顶点表示实体,用边表示实体之间的联系,随着数据量的增加,实体之间的联系更为错综复杂,便形成了高度复杂的网络。复杂网络的优点是可以显示绝大部分的联系;缺点是复杂度高,不宜观察和分析。复杂网络采用网络化建模研究复杂现象,把每个症状看作节点,症状之间的关系看作边,症状及其之间的关系便可以用复杂网络来描述[11]。通过分类、筛选等分析方法对网络图进一步分析,可以挖掘中医数据的潜在信息。
1.4 K-means
K-means算法是基于距离的划分聚类算法,通过不断地迭代和重新计算聚类中心,直至收敛进行聚类[12-13]。其步骤为[13]:①从n个数据对象任意选择k个对象作为初始聚类中心。②根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分。③重新计算每个(有变化)聚类的均值(中心对象)。④当每个类不再发生变化时,结束,n个数据对象被划分为k类;否则,跳转到②。K-means算法的优点是快速、简单、效率高,缺点是聚类效果受K值的影响,需事先给定K值,當它难以预估时聚类效果不理想。
2 数据来源
本研究采用肝炎肝硬化患者的临床数据,数据来源于2011年11月-2012年9月在解放军302医院、湖北省中医院、首都医科大学附属北京地坛医院、首都医科大学附属北京佑安医院、北京中医药大学东方医院、中国中医科学院西苑医院、首都医科大学附属北京中医医院及广西中医药大学第一附属医院的门诊或住院患者。选取100例,每例有97个症状变量,包含舌象变量22个,脉象变量11个。数据原始编号为采集数据时的患者编号,为方便数据分析,将数据重新编号为0、1、2……
课题组参照现行的肝硬化诊疗共识、指南及指导原则[14-17],结合前期文献回顾和临床调查结果,再经多位临床肝病专家进行论证后,形成《肝炎肝硬化常见证候要素辨识标准》。参照标准对患者是否存在气虚证、气滞证、热证、湿证、水停证、血瘀证、阳虚证、阴虚证共8个基本证候要素进行判定,结果用0和1表示。数据除编号列外,其他列中1代表有此证候或症状,0代表没有此证候或症状。在聚类分析时,专家组辨证结果不参与计算,仅作为理论值,验证不同方法的分析效果。专家组由北京中医药大学、河南中医药大学中医诊断学的多名教授学者组成。
3 不同方法从症状划分角度挖掘数据
3.1 层次聚类
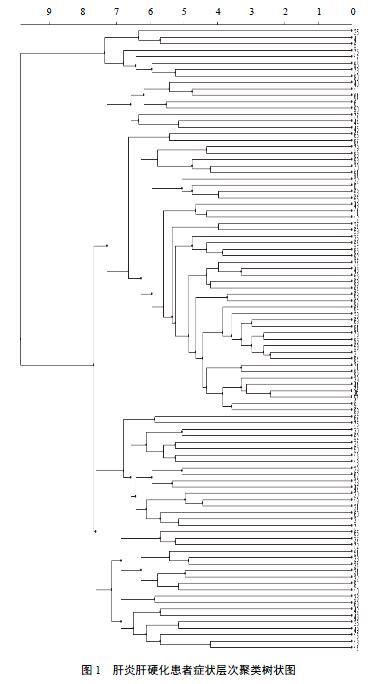
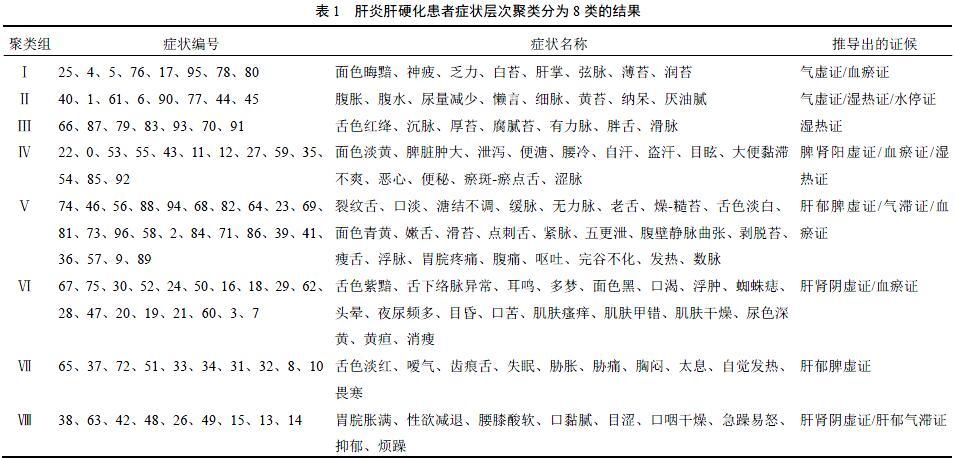
从症状划分角度对数据进行层次聚类,聚类效果见图1。层次聚类先自动聚成树状图,然后根据需要对数据进行分类,图连接度采用complete-linkage[8],图中纵坐标0~96代表症状,横坐标代表不同类之间的距离。将图1划分为8个类,依据其对应的症状信息和中医知识,推导出的证候见表1。聚类结果把同类近似的症状划分在一起,推导出相关证候。临床上某一症状往往会出现在多种证候中,但该方法无法将某个症状同时划分到多个证候。另外,层次聚类没有对主要症状和次要症状进行筛选。
3.2 因子分析
将收集到患者四诊信息进行频率分析,筛选得到出现频率≥30%的症状共40个,用于因子分析。进行KMO检验及Bartlett球形检验以判断数据是否适合进行因子分析。若KMO<0.5,则认为各变量间相关性较差,样本量小,需要扩大样本量;若KMO>0.5,即可认为共同因子多,相关性好,可以进行因子分析。Bartlett球形检验用于检验相关矩阵是否为单位矩阵,一般来说,P<0.05表明原始变量之间可能存在有意义的关系,适合因子分析,P>0.10则表明数据不适宜应用因子分析。
采用主成分相关性矩阵法抽取公因子,因子旋转协方差法,分别对本研究数据进行上述检验,得到KMO=0.624,Bartlett球形检验P=0.000(方差=1581.289,自由度=780),故认为可以进行因子分析。
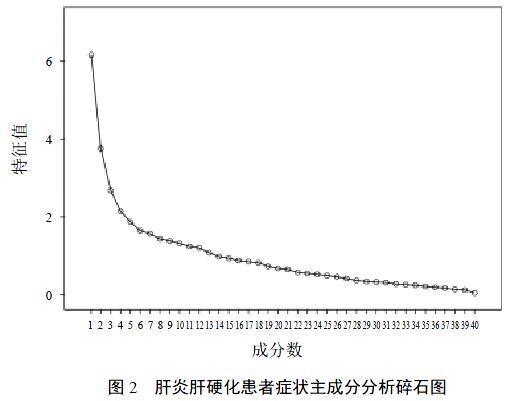
采用主成分分析法,40个症状总方差解释表的表头信息包括成分、起始特征值(合计、方差、累积)、提取平方和载入(合计、方差、累积)、旋转平方和载入(合计)。相应的碎石图见图2。
根据总方差解释表和碎石图,选择特征值>1的成分作为公因子。依据因子结构矩阵(行名为症状,列名为13个公因子编号,值代表载荷系数),认为载荷系数>0.4的值有意义,提取到13个公因子的主要症状及证候分析,见表2。可以看出,因子分析在对症状解释时,每个因子的大部分症状可对应1个或多个证候,且涉及的病位较少,可见因子分析在提取证候方面具有一定的优势。但它与层次聚类类似,无法将某个症状同时划分到多个证候,而临床实际中一个症状往往会出现于多种证候中。
3.3 复杂网络
借助中医药挖掘系统及复杂网络分析软件Uci6进行数据处理和网络构建[11]。首先利用中医药挖掘系统将数据进行整理[11],得到相关的关系矩阵,见表3。
计算各症状的点度中心度和中介中心度,并使用Newdraw绘制网络图,见图3。点度中心度比较靠前的主要有乏力、弦脉、润苔、肝掌、面色晦黯、薄苔、急躁易怒等,中介中心度比较靠前有腰膝酸软、腹水、神疲、乏力、浮肿、急躁易怒、胸闷等,见表4。运用Newdraw→Analysis→SubGroup→Factions进行分类,并依据中心度大小显示节点情况的可视化图,共分为8个子群,见表5。
根据点度中心度及出现频率≥30%筛选症状。子群一:腹水、神疲、乏力、懒言、自觉发热、抑郁、烦躁、急躁易怒、肝掌、肌肤干燥、面色黑、面色晦黯、目涩、目昏、头晕、胸闷、太息、胁胀、胁痛、胃脘胀满、腹胀、腰膝酸软、纳呆、厌油腻、口苦、口黏腻、口咽干燥、失眠、尿色深黄、性欲减退、舌色紫黯、舌下络脉异常、黄苔、润苔、细脉、弦脉。辨证为:虚实夹杂证。子群二:黄疸、舌色红绛、白苔、薄苔。辨证为:热证。
可以看出,复杂网络通过症状及症状的关系构建网络,只能得出2个证候,难以推导出多个不同的证候。该方法较适于对某种确定证候所涉及的症状进行分析,根据中心度值来确定某证候主要与次要的症状,但不太适合对多种证候的推导与辨证。
4 不同方法从患者划分角度挖掘数据
4.1 层次聚类结果
从患者角度进行层次聚类,聚类过程和结果与从症状划分方法类似。从聚类结果来看,得到的8个类别中,每个类包含患者个数都不相同,且每个类中的患者大都有多种证候要素兼夹,但聚类结果只能把该类别归为一种证候。
但从全局来看,聚类效果较差,原因是1个患者可能同时具有多种证候,而层次聚类只能将1个患者划分到1个证候类。与从症状划分的聚类结果相比,该聚类组Ⅵ与从症状划分的聚类组Ⅰ有较少部分相似;但有些类缺乏较好对应,说明层次聚类的2種角度分析结果既相似又有区别。
4.2 K-means聚类结果
设定K=8,K-means算法运行后将聚成8类。
参考专家组辨证经验,8个聚类组中,除类Ⅰ、Ⅶ外,特别是类Ⅱ和Ⅳ的患者大都有多种证候要素兼夹,无法推断出某聚类组属于哪个类。类Ⅰ和Ⅶ的效果较好,类Ⅰ把湿证和热证的证候要素聚在一组,但数量较少;类Ⅶ把血瘀证候要素聚在一起,可以推测聚类组为血瘀证类。该聚类的类Ⅱ与层次聚类对患者的类Ⅳ相同;该类Ⅰ与层次聚类对患者的类Ⅰ相似,因此K-means聚类和层次聚类在对患者聚类后得到的结果相似。
由于患者存在多种混合证候,且K-means的聚类效果受K值的影响很大,故尝试将K值设为9、10、11类,结果变化不大,聚类效果仍不理想。整体而言,K-means聚类效果略优于层次聚类,但由于大多数分组存在证候混合情况,而K-means也仅能将患者划分到一个类别,所以整体效果不理想。
5 小结
本研究对比4种不同的无监督方法在挖掘中医证候时的差异。①从症状划分角度来看,层次聚类和因子分析能在一定程度上提取证候,但聚类效果一般。复杂网络聚类效果较差,更适合于确定单一证候后,对该证候所涉及的所有症状进行分析,不适于多种症状-证候的分析。②从对患者人群划分角度来看,层次聚类和K-means效果类似,能将相似的患者划分到一起,但效果一般。因为不能同时从多个侧面进行聚类,即无法体现一个患者同时具有多种证候,不适合实际临床中的多种证候兼夹情况。对于层次聚类,上述2种角度分析的结果既相似又有区别,相比而言,层次聚类从症状角度分析得到的结果更好
由上述可以认为,常规聚类算法在对症状聚类、对症状数据划分时,一个症状只能属于或不属于某一个证候类。所得到的是症状变量的类,不是症状事件的类,其含义不是一些患者(证候)同时具有一些症状。在实际情况中,证候是对患者人群的划分,用于揭示样本某方面的特征和性质,且一个患者可能同时具有多种证候,每个证候都涉及相应的多种症状。而常规聚类在对患者人群划分时,不能处理证候兼夹情况,无法分析样本的特征和性质,不能揭示证候在样本中的分布规律。
综上所述,目前常用的单一数据挖掘方法不能同时满足分析症状属于多种证候、患者具有多种证候的兼夹情况。需要改进、合并多种算法,或尝试使用其他方法(如隐结构分析方法[7,18])来研究中医症状到证候的数据挖掘问题。
参考文献:
[1] 寇冠军,唐健元.中医证候研究现状及证候中药研究关键[J].中药药理与临床,2017,33(4):213-214.
[2] 王阶,李海霞,孙占全,等.基于复杂算法的中医证候研究[J].北京中医药大学学报,2006,29(9):581-585.
[3] 蔡伟达.证候研究中常用的数据分析方法的文献研究及基于隐类的抑郁症隐变量分析[D].北京:北京中医药大学,2015.
[4] 张连文,周雪忠,陈弢,等.论证候研究中变量聚类结果的诠释[J].中国中医药信息杂志,2007,14(7):102-103.
[5] 魏华凤,季光,郑培永.证候诊断规范化研究的现状分析[J].中西医结合学报,2007,5(2):115-121.
[6] 李仁义.数据挖掘中聚类分析算法的研究与应用[D].成都:电子科技大学,2012.
[7] 王天芳,张连文,赵燕,等.隐结构模型及其在中医证候研究中的应用[J].北京中医药大学学报,2009,32(8):519-527.
[8] JOHNSON S C. Hierarchical clustering schemes[J]. Psychometrika, 1967,32(3):241-254.
[9] 于小林,张艳霞,张晓梅.基于因子分析法的重症肺炎中医证候分布及演变规律研究[J].环球中医药,2018,9(11):1337-1342.
[10] 王强,张弦,王盛隆,等.基于因子分析的支气管哮喘急性发作期患者中医证候[J].世界中西医结合杂志,2017,12(12):1637-1641.
[11] 刘佳佳,林树元,郑卫军,等.基于复杂网络的太阴中风证临床诊断指征筛选[J].上海中医药杂志,2018,52(12):14-17.
[12] 王千,王成,冯振元,等.K-means聚类算法研究综述[J].电子设计工程,2012,20(7):21-24.
[13] 吴夙慧,成颖,郑彦宁,等.K-means算法研究综述[J].现代图书情报技术,2011(5):28-35.
[14] 张育轩.肝硬化临床诊断、中医辨证和疗效评定标准(试行方案)[J].中国中西医结合杂志,1994,14(4):237-238.
[15] 危北海,张万岱,陈治水,等.肝硬化中西医结合诊治方案(草案)[J].中国中西医结合杂志,2004,24(10):869-871.
[16] 刘成海,危北海,姚树坤.肝硬化中西医结合诊疗共识[J].中国中西医结合消化杂志,2011,19(4):277-279.
[17] 李延龙,吴秀艳,王天芳,等.基于因子分析的801例肝炎肝硬化患者的证候研究[J].辽宁中医杂志,2018,45(4):673-675.
[18] 许玉龙,吴秀艳,李延龙,等.基于隐结构分析建立中医证候分型规则的三种方法[J].世界科学技术-中医药现代化,2019,21(1):101-108.
(收稿日期:2018-08-19)
(修回日期:2019-04-05;編辑:陈静)
