基于ARMA模型的在线油液监测故障预警研究 *
2019-12-26李美威1谢小鹏1贺石中
李美威1 谢小鹏1 冯 伟 贺石中
(1.华南理工大学机械与汽车工程学院 广东广州 510640; 2.广州机械科学研究院有限公司设备状态检测研究所 广东广州 510700)
在线油液监测是指在设备不停机的情况下,通过各种在线传感器对油液理化指标和铁磁磨粒等进行实时监测,根据监测参数来判定设备的运行情况,并进行相应的故障诊断[1]。早期的异常检测能够避免更多的严重后果,保证系统性能和效率并减少维修费用。在整个在线监测过程中,当系统严重偏离其正常情形时就会导致异常发生[2],异常检测就是识别出监测数据偏离正常情况的程度。对在线油液监测数据进行趋势分析和预测,以提前发现异常并报警,可有效避免故障发生。目前,常用的趋势分析方法有回归拟合、统计分析、支持向量机、时间序列分析、灰色理论和人工神经网络等。趋势预测的方法有很多,但是适用于油液监测系统的较少[3]。
针对油液检测特征的趋势分析,国内外学者都展开了大量研究。林丽等人[4]基于油液在线监测的磨粒信息对齿轮箱磨损状态进行了诊断和预测。张红和龚玉[5]以光谱分析为例,运用灰色理论对磨损趋势进行了预测。高经纬等[6]对内燃机润滑油中的各元素运用时序模型进行了趋势分析,以判断内燃机的磨损状态。TOBON-MEJIA等[7]使用小波分解技术和基于高斯混合隐马尔科夫来估计轴承的寿命。SOUALHI等[8]运用基于向量回归机的方法对轴承进行了监测分析。上述研究主要是通过离线油液分析或是对一个周期内某个特征进行实验拟合分析再运用于在线,这往往需要大量的时间去收集足够全面的数据,而且用某个周期内的特征变化代表所有情况是不准确的。
在线监测数据往往是不平衡的,能监测到的故障数据比正常数据通常要少得多,这使得许多传统的诊断方法并不适用于这种问题[9]。而各种设备故障的发生往往会有一个潜在过程。针对在线数据的这些特点,本文作者对设备运行平稳期的监测数据构建ARMA模型,然后对整个时期的模型残差进行分析,将监测数据特征量在故障发生之前的一段时间内的残差划分为平稳期和故障潜伏期,设定故障潜伏期残差界限值,一旦残差越界即可提前报警。
1 ARMA模型
1.1 模型定义
自回归滑动平均(Auto Regression Moving Average,ARMA)模型是研究平稳随机过程的典型方法。ARMA模型认为一个时间序列的相互依存关系表现在原始数据的延续性上,在某时刻的值受到历史值和噪声的影响[10-11]。对于一个离散的时间序列{x1,x2,......,xn,......},ARMA数学模型表示为
xt=μ+φ1xt-1+φ2xt-2+......+φpxt-p+εt-
θ1εt-1-......-θqεt-q
(1)
式中:xt是当前值;μ是常数项;p和q是模型阶数;φi和θi是模型参数;{εt}是白噪声序列。
当q=0时,ARMA(p,q)模型就退化成自回归AR(p)模型,即
xt=μ+φ1xt-1+φ2xt-2+......+φpxt-p+εt
(2)
当p=0时,ARMA(p,q)模型就退化成移动平均MA(q)模型,即
xt=μ+εt-θ1εt-1-......-θqεt-q
(3)
1.2 模型定阶和参数估计
在使用ARMA(p,q)模型对时间序列进行拟合时,首先需要对时间序列进行平稳非白噪声检验。可使用单位根检验和Ljung-Box检验进行序列的平稳非白噪声检验。ADF检验通过检验序列中是否存在单位根来判断序列的平稳性[12],如果序列存在单位根则为非平稳序列,否则就是平稳序列。Ljung-Box是对时间序列是否存在滞后相关的一种检验方法[13],如果序列存在滞后相关则为非白噪声序列,否则为白噪声序列。
检验完序列为平稳非白噪声后,就可使用ARMA(p,q)模型进行分析。首先需要确定模型中的p和q值。ARMA(p,q)模型的阶数主要是根据序列的自相关系数和偏自相关系数的拖尾性和截尾性来判断。其对应的模型如表1所示。

表1 ARMA模型定阶基本原则
确定模型阶数后,估计模型中的参数。使用最小二乘估计法对模型参数进行估计[14],最小二乘法能充实使用序列值,精度较高。此时,记
a=(μ,φ1,φ2,......,φp,θ1,θ2,......,θq)T
(4)
Ft(a)=μ+φ1xt-1+φ2xt-2+......+φpxt-p-
θ1εt-1-......-θqεt-q
(5)
计算残差:
εt=xt-Ft(a)
(6)
计算残差平方和:
φpxt-p+θ1εt-1+......+θqεt-q)2
(7)
使式(7)达到最小的参数值a即为参数的估计值。由于白噪声序列的值无法确定,所以需要运用迭代的方法进行计算。
1.3 模型检验与优化
在模型构建完成以后,就可以得到拟合残差序列。如果残差序列为白噪声,则认为拟合模型充分提取了原始序列中的所有信息,这样模型才显著有效。所以需要使用Ljung-Box方法对残差序列进行白噪声检验以判断模型的有效性。
在进行模型定阶时只是主观判断相关系数的拖尾性和截尾性来确定p和q的值,但该模型不一定是最优模型。选用最小信息量准则(Akaike Information Criterion,AIC)来进行模型优化,AIC准则通过模型的似然函数值和参数个数来衡量模型的拟合效果[15],即
(8)
通过比较多个模型的AIC值,即可选取AIC最小的模型作为最优模型。
1.4 故障潜伏期界限值设定

K均值是一种聚类方法。对于一维K均值,其算法如下:
(1)随机选取序列中的2个数作为初始中心点k1、k2;
(2)分别计算所有点到k1和k2的距离d1和d2,若d1≤d2,则记为1类,否则为2类;
(3)更新中心点,将所有1类点的均值赋给k1,所有2类点的均值赋给k2;
(4)重复步骤(2)、(3),直至k1和k2不再变化。
由于数据是一维时间序列,即可使用两中心点的均值作为界限值,即
thresholdε=(k1+k2)/2
(9)
2 实验验证与分析
2.1 实验数据
以某水电站水轮机组为研究对象,用实时获取的推力油槽油液含水量进行模型验证和分析。该机组安装了广研检测的在线油液监测仪,可实时采集机组油液的各项特征,采样周期为1 h。该设备在运行过程中遭受了水污染,油液含水量大幅上升。水分会使油液乳化,降低油液黏度和油膜厚度,还会促使油品氧化,加速腐蚀,恶化油质,所以应保证油液中的含水量尽可能地低。文中选取一次含水量超标的数据作为样本数据进行分析,总共454条数据,根据油液标准设定的含水量界限值为1×10-4(质量分数,下同),含水量实时趋势如图1所示。

图1 原始数据时序Fig 1 Original time series
2.2 平稳序列建模

使用ADF检验序列平稳性,其检验结果如表2所示。
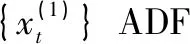
表2 序列检验结果


表3 序列检验结果
2.2.2 模型定阶与参数估计

图2 序列自相关函数Fig 2 Time autocorrelation function (ACF)

图3 序列偏相关函数Fig 3 Time partial autocorrelation function (ACF)
从图2和图3中可看出,其自相关表现出明显的拖尾性,偏相关在9阶之后取值均在置信区间内,可认为偏相关9阶截尾,根据表1可判定为AR(9)模型。再分别对AR(7)、AR(8)、AR(9)、AR(10)、AR(11)进行分析,比较它们的AIC,选取最优模型。5种模型的AIC值如表4所示。

表4 各模型的AIC值对比
从表4可知,AR(9)模型的AIC值最小,则选取AR(9)模型进行序列拟合,并运用最小二乘法对AR(9)模型进行参数估计,其参数估计结果如表5所示

表5 参数估计结果
则模型的表达式为
xt=26.288 9+0.639 8(xt-1-26.288 9)+
0.123 6(xt-2-26.288 9)-0.004 1(xt-3-26.288 9)-
0.020 6(xt-4-26.288 9)+0.003 8(xt-5-26.288 9)+
0.027 3(xt-6-26.288 9)+0.378 8(xt-7-26.288 9)-
0.243 5(xt-8-26.288 9)-0.160 6(xt-9-26.288 9)+
εt=6.716 8+0.639 8xt-1+0.123 6xt-2-0.004 1xt-3-
0.020 6xt-4+0.003 8xt-5+0.027 3xt-6+0.378 8xt-7-
0.243 5xt-8-0.160 6xt-9+εt

图4 AR(9)模型拟合结果和原始数据比较Fig 4 Comparison of fitting results of AR(9) model and original data
2.2.3 模型检验
验证拟合模型的残差序列是否为白噪声序列。同理,使用Ljung-Box检验方法对残差序列的3、6、9期和12期滞后进行自相关分析,其结果如表6所示。

表6 残差Ljung-Box检验结果
从表6中可知残差序列的3、6、9和12期滞后的检验概率远大于0.05,并且均接近于1,则可认为残差序列为白噪声序列,模型有效。
3 残差序列分析


图5 原始时间序列及其拟合结果Fig 5 Original time series and its fitting results
3.1 对残差序列进行统计分析


图6 不同时期残差统计直方图Fig 6 Residual statistical histogram of different period
从图6中可以看出,平稳期残差是一个白噪声序列,大致符合正态分布。而故障潜伏期的残差分布发生了较大变化,对故障潜伏期的残差序列进一步分析划分界限值。
3.2 对残差进行K均值聚类

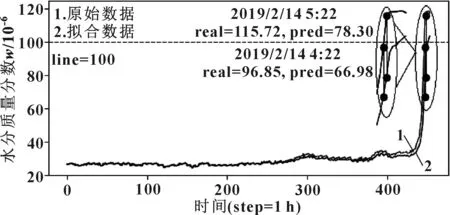
图7 原始序列报警示意图Fig 7 Alarming schematic diagram of original time sequence
从图7中可以看出,油液含水量的界限值为1×10-4, 2019年2月14日4∶22时的实测值为9.685×10-5,尚未达到报警界限值,而且此时下一步的预测值为7.83×10-5,也未达到报警界限值,即不会提前报警。只有在2019年2月14日5∶22时的实测值为1.157 2×10-4,超过报警界限值,系统及时报警。即在这种情况下,系统在测量值超过报警界限值时会及时报警,但无法提前报警。
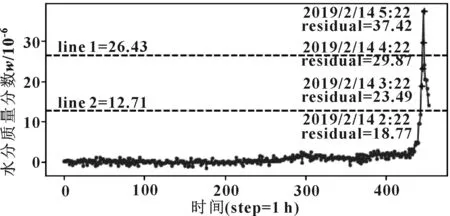
图8 残差报警示意图Fig 8 Alarming schematic diagram of residual
从图8中可以看出,根据3sigma原则确定残差界限值2.643×10-5,在2019年2月14日4∶22时的残差值为2.987×10-5,超过残差界限值,系统发出警报,即系统提前1 h发出警报。而根据K均值得到的界限值1.271×10-5,在2019年2月14日2∶22时的残差值为1.877×10-5,超过残差界限值,系统发出警报。相对于3sigma原则,使用K均值可在相同的采样周期下大大增加提前报警的时间,而且报警时的含水量相对更小,可有效地防止设备故障发生和进一步恶化。
4 结论
(1)利用ARMA模型对设备平稳运行时期的在线油液监测数据进行建模,利用该模型可及时掌握监测特征量的变化趋势,运用残差来表示设备偏离平稳状态的程度。
(2)针对ARMA模型对非平稳期的预测精度较低且只能进行一步预测的特点,利用模型拟合残差判定设备处于正常期还是故障潜伏期,并通过K均值聚类将设备发生故障前的残差进行二分类,将两类中心点的均值作为正常期与故障潜伏期间的界限值。
(3)通过实际的监测数据进行模型验证和分析,结果表明,通过此方法可提前系统警报时间,有效控制油液监测特征量的值并且防止设备故障发生。
