向量灰色模型的建立及应用
2019-12-17周伟杰党耀国
周伟杰, 党耀国
(1.常州大学 商学院,江苏 常州 213164; 2.南京航天航空大学 经济与管理学院,江苏 南京 211006)
0 引言
准确的预测是科学决策与规划的前提。预测的方法有许多种类,比如基于统计分析的自回归积分滑动平均模型(Autoregressive Integrated Moving Average,简称为ARIMA)、基于神经网络的径向基函数(Radial Basis Function,简称RBF)等。这类模型通常需要样本有较多的信息含量。然而,现实系统往往具有模糊性,信息获取的完整性难以满足。为此,针对系统的不确定性与复杂性,我国学者邓聚龙提出灰色系统理论,在工业、生态、社会经济等领域中得到了广泛应用[1~5]。
根据影响因素个数,预测有单变量预测与多变量预测。以GM(1,1)为核心的模型群主要针对单变量灰色时间序列[6,7]。如Zhao等利用差分演进算法对GM(1,1)模型进行了优化,并用于农村纯收入建模分析中[8]。利用信息覆盖原理,考虑时间幂次项对建模的影响,Li提出了结构自适应灰色预测模型,用于具有异质性指数规律的数据建模[9]。基于核和灰度,以及直觉模糊数的犹豫度和记分函数,李鹏和朱建军建立了直觉模糊数下的GM(1,1)模型[10]。由于系统往往包含多个变量,变量之间存在相互影响、相互制约的关系,为此学者们提出了多变量灰色预测模型(Multivariable Grey Model,简称MGM)及其优化形式。如翟军等基于经济系统变量的相互影响、相互关联这一事实,提出多变量MGM(1,m)模型,实例证明了MGM(1,m)模型的建模精度优于GM(1,1)模型[11]。崔立志等基于向量连分式理论,用有理插值、梯形公式与外推法对MGM(1,m)模型的背景值进行重构,从而提高了模型的模拟与预测精度[12]。考虑到MGM(1,m)模型背景值存在的误差,刘寒冰等利用非齐次指数函数优化背景值计算公式,并将优化后的MGM(1,m)模型用于路基沉降预测,取得了较高的精度[13]。熊萍萍等对MGM(1,m)模型的特征、背景值、以及非等间距序列下的模型进行了系统研究,使模型有了更广泛的应用[14~16]。针对背景值系数固定为0.5的缺陷,Zeng和Li提出了多变量灰色预测模型的动态背景值系数,并利用粒子群算法对系数进行了优化,发现了固定背景值系数离最优系数越近,模拟值越精确这一现象[17]。Wu 等将分数阶累加引入到多变量灰色预测模型中,并用粒子群算法对分数阶阶数进行了优化。将新模型应用于山东省电力消耗分析中,结果表明新模型具有较高的建模精度[18]。
然而,在MGM(1,m)模型实际应用与分析时,发现存在两方面问题。1)建模数据失真的情形,如在例1石家庄市空气质量指数(Air Quality Index,简称AQI)与Particulate Matter 2.5(简称PM2.5)建模时,MGM(1,2)模型中AQI的模拟值出现负数,PM2.5的模拟值也出现数倍于真值。例2对江苏省国内生产总值(Gross Domestic Product,简称GDP)与能源消费建模,发现MGM(1,2)模型得出GDP的模拟值出现数倍于真值的情况,能源消费的模拟值与真值相比缩小了数倍。2)模型参数较多,增加估计的不确定性,使得模型的稳定性变差;此外,模型预测解析表达式复杂,运用到指数矩阵,计算的复杂性增大,不利于分析变量之间的相互关系。鉴于以上分析,本文从系统中关联变量具有趋同性这一特征出发,提出一种新的多变量灰色预测模型——向量灰色模型(Vector Grey Model,简称VGM),并用实例说明了新模型的实用性和有效性。
1 传统MGM(1,m)模型
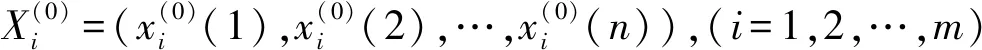

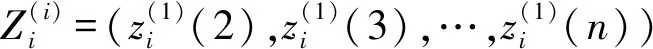

(1)
(2)
为MGM(1,m)模型的基本形式。记
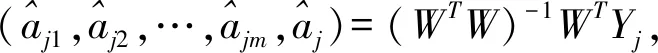
式(1)多变量MGM(1,m)模型的响应式及其还原式为:
(3)
(4)

2 向量灰色模型(VGM(1,m))
(5)
为向量灰色模型(VGM(1,m))的基本形式,称微分方程组
(6)

(7)
在社会治理系统共建共治中,协同治理是创新社会治理最基本的方式,也是改进社会治理方式、坚持系统治理的具体体现。由社会组织和公众参与的社会协同共治,既是党的领导、政府主导下的社会治理过程,也是多元主体参与社会治理的基本职能。在新时代,要想实现共建共治共享的社会治理目标,我们必须锐意改革,有所创新,坚持问题导向,把政府治理与社会协同和公众参与结合起来。因此,在创新社会治理中,必须确立多元主体的社会协同的重要地位,通过为社会组织和公众赋权增能,最大限度地发挥多元主体在社会治理系统共建共治中的协同作用。
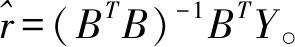
证明将行为序列数据代入VGM模型,得:
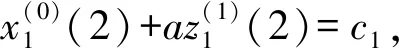
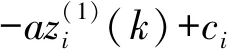

(8)
通过一次累减还原,VGM(1,m)模型中原始序列的模拟或预测值为:
(9)
原有的MGM(1,m)模型共有m2+m个参数需要估计。参数越多,则需要一定的样本量才能保证参数估计的准确性,这对于贫信息系统有时难以满足。此外,模型中自变量过多,建模时可能会出现多重共线性或过拟合现象。相比之下,向量灰色模型VGM(1,m)只需估计m+1参数,为此模型的稳定性得到了提高。在参数计算方面,VGM(1,m)参数估计中的是一个稀疏矩阵,BTB求逆的计算量要小于MGM(1,m)的WTW求逆;同时,MGM(1,m)的参数A需要对m个不同的WTW进行求逆,这增加了大量的计算。从向量灰色模型的结构来看,新模型适用于系统中具有趋同性变量之间的建模。变量的发展具有相似性的系统在现实生活中是比较常见的,比如经济水平的上升与投资、消费的拉动关系,环境质量的提高与污染物排放减少等。
3 实证分析
以空气质量、经济-能源、农村家庭收入、投资-经济系统中的变量为研究对象,来检验及说明向量灰色模型的建模效果。其中,前两个实例用于检验向量灰色模型是否能消除MGM(1,m)模型建模时出现的失真现象,后两个实例用于分析VGM(1,m)的建模精度。利用绝对误差百分比(Absolute Percentage Error,简称APE)来比较模型的建模精度:
(10)
3.1 空气质量与PM 2.5关系的建模
雾霾污染已成为全国人民关注的焦点话题,一般以空气质量指数(AQI)来划分污染等级。雾霾天气不仅影响人们的日常生活,而且也危害人们的身体健康。与其它污染物相比,雾霾污染物中的PM 2.5对人体的伤害更大,会引起哮喘、支气管炎和心血管病等方面的疾病。为此,本例对石家庄市AQI与PM 2.5进行建模分析。
以2016年8月至11月份的数据建模,利用传统多变量灰色模型MGM和向量灰色模型VGM建模,结果见表1。从中可以看出,MGM模型对AQI、PM2.5数据的模拟出现失真,如2016年9月、10月以及11月的AQI模拟值均为负数,2016年9月、10月以及11月的PM2.5模拟值是真值的5.51倍、6.98倍和7.25倍。而对于VGM模型,其模拟值与真值接近,说明VGM的建模是有效的。
3.2 能源消费与经济增长关系的建模
经济的快速发展,离不开对能源的需求,研究能源消费与经济增长之间关系,可为能源政策、经济发展目标的制定提供支撑。本例以2010年至2014年的江苏省GDP数据和能源消费量为样本,利用MGM(1,2)和VGM(1,2)模型进行建模分析,结果见表2。

表2 江苏省GDP与能源消费建模分析(单位:亿元、万吨标准煤)
从表2可知,MGM的建模模拟数据没有出现负数,但是与真值相差很大。其中GDP的真值是模拟值的数倍,如2014年GDP的真值是65088.32亿元,模拟值仅为7521.538亿元,真值是模拟值的8倍多。同时,能源消费的模拟值又是真值的数倍。如2014年能源消费的真值为29863.03万吨标准煤,模拟值为128370.8万吨标准煤,模拟值是真值的4倍多。VGM模型下的GDP与能源消费模拟值与真值比较接近。从实例1与实例2来看,传统多变量MGM模型在实例建模时,会出现建模数据失真的情况,而新构建的向量灰色模型VGM能解决这一问题。
3.3 农村家庭收入变量的建模
农村家庭的人均纯收入中有高收入户和低收入户,他们受到全社会经济水平的这一因素的影响,在本例中对2005年至2009年的数据进行VGM(1,2)和GM(1,1)模型建模,2010和2011年的数据作为预测,结果见表3和表4。

表3 GM和VGM的建模参数
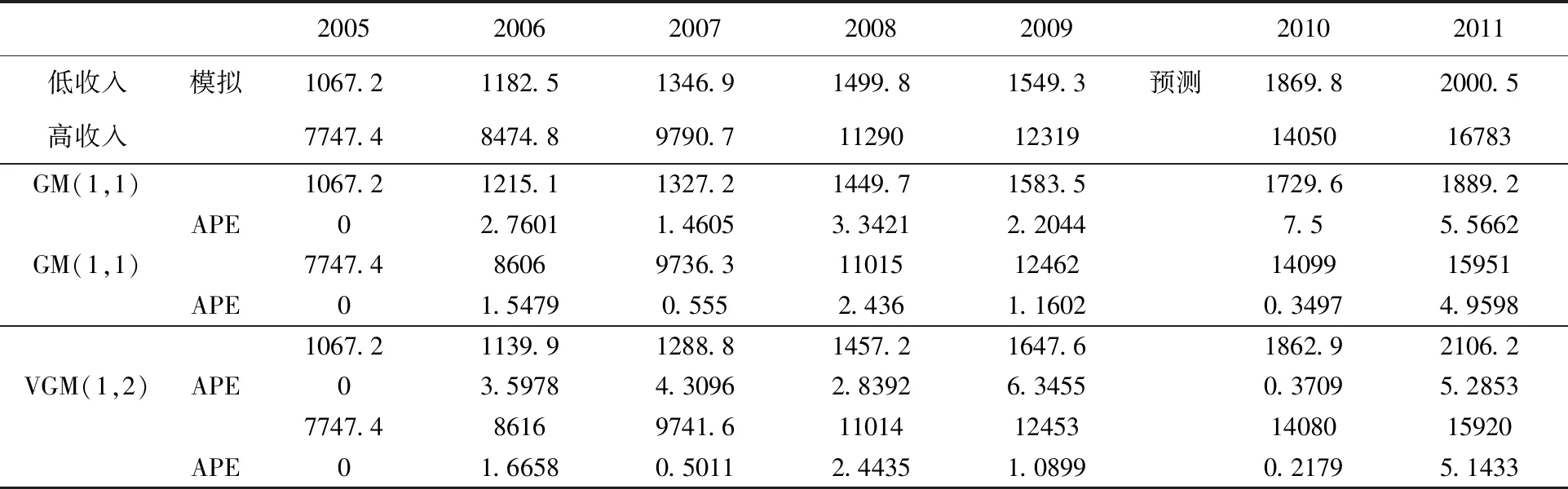
表4 农村居民家庭人均纯收入:低收入户与高收入户的建模(单位:元)
表3为GM(1,1)和VGM(1,2)模型对低收入户和高收入户的建模参数,b=1068.0675、b=7129.7767分别为低收入与高收入GM(1,1)模型中的灰色作用量。c1=940.3387和c2=7146.5380是VGM(1,2)模型中的常数项。表4为两个模型的模拟和预测数值。可以看出,对于2006年、2007年、2009年的低收入以及2006年、2008年的高收入,GM(1,1)模型模拟值的绝对误差百分比要小于VGM(1,2)模型,其余年份的低收入和高收入GM(1,1)模拟误差大于VGM(1,2)模型。对于预测值,除了高收入户的2011年数据,VGM(1,2)的预测误差高于GM(1,1)模型,其余年份的低收入和高收入预测误差均小于GM(1,1)模型,说明VGM(1,2)模型具有更高的预测精度。
3.4 固定投资与经济增长关系的建模
社会固定投资是影响经济发展的一个主要因素,本例采用南京市GDP和固定投资总额数据为样本,用VGM(1,2)模型和GM(1,1)对其建模分析。以2006年至2011年的数据为建模数据,预测2012年的数据,结果见表5和表6。
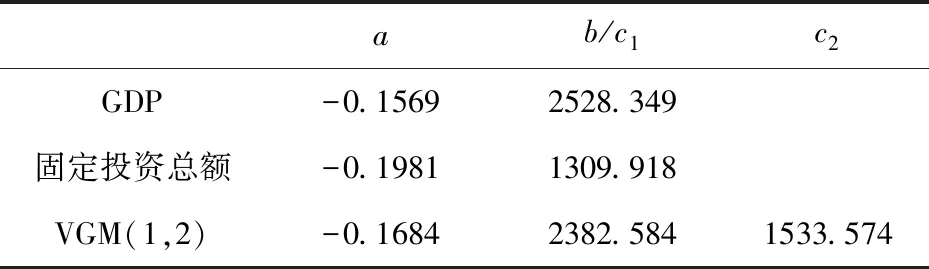
表5 GM和VGM的建模参数
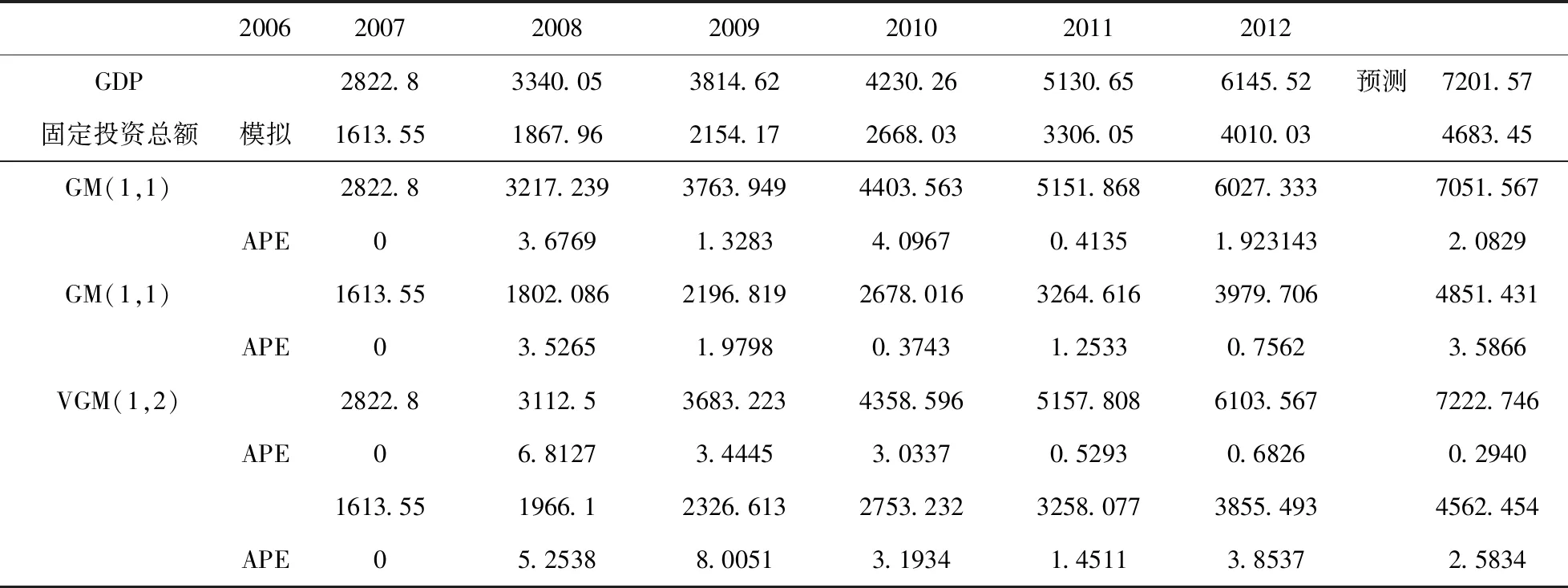
表6 南京市GDP与固定投资总额建模分析(单位:亿元)
表5给出了VGM(1,2)和GM(1,1)模型对南京市GDP和固定投资总额的建模模型参数,b=2528.349、b=1309.918分别为南京市GDP和固定投资总额GM(1,1)模型中的灰色作用量。c1=2382.584和c2=1533.574是VGM(1,2)模型中的常数项。表6为建模的模拟值与预测值。可以看出,GM(1,1)模型对南京市GDP和固定投资总额模拟值的绝对误差百分比小于VGM(1,2)模型的年份更多,说明GM(1,1)模型的模拟精度较高。而对于2012年GDP和固定投资总额的预测值,VGM(1,2)模型的误差为0.2940%和2.5834%,GM(1,1)模型的误差为2.0829%和3.5866%,说明VGM(1,2)模型的预测精度更高,即VGM(1,2)模型的泛化能力更强。这其中原因可能在于:GM(1,1)在建模时孤立了社会固定投资与经济增长的关系,而VGM(1,2)模型考虑到二者的内在相互关系,从而使模型在预测未来发展趋势时更具优势。
4 结论
为了解决传统多变量灰色模型建模时的失真现象,本文构建了向量灰色多变量预测模型,并给出了模型参数的估计方法。从模型结构上看,新模型的表达式更简单,这有利于分析变量之间的相互关系,为后续对模型的优化研究提供支撑。同时,与传统模型相比,模型参数变少,从而增加了参数估计的稳定性,使模型的预测更具有可信性。新模型的提出拓展了现有灰色预测模型体系。
