基于多尺度先验深度特征的多目标显著性检测方法
2019-12-12李东民梁大川
李东民 李 静 梁大川 王 超
随着互联网技术的快速发展,数字图像、视频等多媒体数据呈现爆发式增长,基于数字图像及视频的图像处理技术也在迅猛发展.显著性检测通过模拟人类视觉系统选择图像中具有重要信息的区域[1],可将其作为其他图像处理步骤的一种预处理工作,并已成功应用于目标识别、目标跟踪和图像分割[2−4]等多种计算机视觉任务之中.
近年来国内外计算机视觉领域在图像显著性检测的研究方面提出许多行之有效的方法.Borji 等[5]将这些方法分为两类,一类方法基于模拟生物视觉系统构建注意力预测模型(Visual saliency prediction)[6−9].Itti 等[6]提出的IT 算法,根据人眼视觉特性,针对多尺度图像通过底层特征的中心–周围对比度得到相应的显著图,并通过显著图融合获取最终显著图.由于人类视觉系统生物结构复杂导致此算法计算复杂度极高.近年来基于频域的显著性检测模型成为此类方法中关注热点,Hou 等[7]提出一种普残差方法,认为图像包含显著信息和冗余信息,通过在图像幅度谱上做对数运算并利用平均滤波器进行卷积运算得到冗余信息,以幅度谱与卷积结果的差值表示显著信息再反变换到空间域上获得显著区域.在谱残差方法基础上Guo 等[8]提出相位谱四元傅里叶变换法,通过相位谱提取图像多特征分量得到显著区域,利用四元傅里叶变换将亮度、颜色和运动信息一起并行处理来计算时空显著性.Li 等[9]提出超傅里叶变换方法,通过对谱滤波进行扩展,利用超复数表示图像多为特征并使用傅里叶变化得到时空显著性.
另一类方法基于计算机视觉任务驱动构建显著目标检测模型(Salient object detection).这类方法通常包括两个步骤.首先检测图像中突出显著区域,在此基础上分割出完整目标.虽然这类方法本质上本质是解决前景与背景分割问题,但与图像分割相比显著性目标检测根据内容将图像分割为一致区域.一些经典算法使用底层特征对图像内容进行表示[10−14],比如Cheng 等[10]使用图割方法对图像进行分割,通过稀疏直方图简化图像颜色,利用空间位置距离加权的颜色对比度之和来衡量图像区域的显著性.Shen 等[11]提取图像的颜色特征、方向特征以及纹理特征得到特征矩阵,利用主成分分析(Principal component analysis,PCA)对矩阵进行降维表示再计算对比度得到显著图.Yang 等[12]通过将图像划分为多尺度图层,针对每个图层计算其颜色特征与空间特征的对比度,融合多个图层生成的显著图获取最终显著图.该方法能够保证显著性目标的一致性与完整性,但当显著性目标较小时,会将显著性目标当作背景融入到背景区域.Cheng 等[13]采用高斯混合模型将颜色特征相似的像素聚为图像区域,综合考虑各区域的颜色对比度和空间分布,以概率模型生成显著图.Li 等[14]以稀疏表示分类(Sparse representation-based classification,SRC)原理为基础,对分割图超像素块进行稠密和稀疏重构,通过多尺度重构残差建立显著图.
使用不同底层特征的显著性检测方法往往只针对某一类特定图像效果显著,无法适用于复杂场景下多目标图像,如图1 所示.基于视觉刺激的底层特征缺乏对显著目标本质的理解,不能更深层次的表示显著性目标的特征.对于图像中存在的噪声物体,如与底层特征相似但不属于同一类目标,往往会被错误的检测为显著目标.杨赛等[15]提出一种基于词袋模型的显著性检测方法,首先利用目标性计算先验概率显著图,建立一种表示中层语意特征的词袋模型计算条件概率显著图,最后通过贝叶斯推断对两幅显著图进行合成.中层语意特征能够比底层特征更准确的表示图像内容,因此检测效果更加准确.Jiang 等[16]将显著性检测作为一个回归问题,集成多分割尺度下区域对比度,区域属性以及区域背景知识特征向量,通过有监督学习得到主显著图.由于背景知识特征的引入使算法对背景对象有更好的识别能力,进而得到更准确的前景检测结果.
近几年来,基于深度学习的自动学习获取深度特征(或高层特征)的方法已经开始在图像显著性检测中得到应用.李岳云等[17]通过提取超像素块区域和边缘特征,送入卷积神经网络学习得到显著置信图.采用条件随机场求能量最小化的区域进行显著性检测.对单显著目标检测效果较好,但由于特征选择问题不适用于多目标图像.Li 等[18]通过深度卷积神经网络来学习得到获取图像超像素区域的局部和全局深度特征来进行显著性检测MDF (Multiscale deep features),检测效果相比于一般方法有明显著的提升,但运行速度较慢.Hu 等[19]通过结合卷积神经网络和区域验证的先验知识获取局部和全局特征.算法检测效果较好,但高度复杂的模型影响了算法运行效率.本文着重研究图像背景信息相对复杂的多目标情况,提出一种基于先验知识与深度特征的显著性检测方法.首先对图像进行多尺度分割,对第一个分割图通过卷积神经网路提取所有超像素块的深度特征并计算显著值,并生成预显著区域.将其余分割图的预显著区域超像素块输入卷积神经网络,通过提取的深度特征计算显著值并更新预显著区域.不断迭代此过程得到各尺度下的显著图,最终通过加权元胞自动机方法对多尺度显著图进行融合.目标先验可过滤大部分背景信息,减少不必要的深度特征提取,显著提升算法检测速率.

图1 复杂背景下的多目标图像Fig.1 Multi object image in complex background
本文结构安排如下:第1 节详细阐述基于多尺度目标先验与深度特征的多目标显著性检测方法;第2 节通过与已有算法在公开数据集上进行定性定量比较,评价本文所提方法;第3 节总结本文所做工作并提出下一步研究方向.
1 显著性检测方法
本节提出了一种基于深度特征显著性检测算法,总体框架如图2 所示.对于输入图像l,首先采用超像素分割算法将图像分割为数目较少的超像素块.对所有超像素块提取深度特征,通过主成分分析提取包含图像关键信息的多维特征.基于关键特征计算得到粗分割显著图,从中提取初始显著区域组成超像素集Supselect.利用Supselect集中超像素与背景区域超像素相似性,对其进行优化.对输入图像不同尺度超像素分割,选择包含Supselect集中超像素块的区域进行深度特征提取,基于相同方法得到这一尺度下显著图Maps和Supselect集.最终采用加权元胞自动机融合得到最终显著图Mfinal.
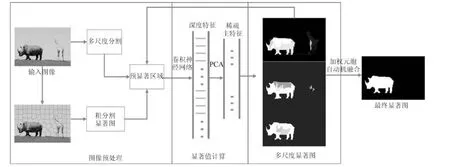
图2 本文算法总体架构图Fig.2 The overall framework of our method
1.1 基于多尺度分割的显著区域提取
超像素分割是根据颜色、纹理和亮度等底层特征,将相邻相似的像素点聚成大小不同图像区域[20],降低了显著性计算的复杂度.常用的超像素生成算法有分水岭[21]和简单线性迭代聚类(Simple linear iterative clustering,SLIC)[22]两种分割算法.本文结合二者各自特点,在粗分割时采用SLIC 方法,获取形状规则,大小均匀的分割结果.在细分割时采用分水岭算法获得良好的对象轮廓.
对于N个分割尺度s1,···,sn,在某一分割尺度下得到的超像素集用表示分割尺度sj下的超像素个数,为sj分割尺度下第i个超像素.L,a,b}为该超像素中像素点两种颜色特征的特征向量.
1.1.1 预选区域提取
将粗分割尺度sj的分割图作为输入,通过深度特征提取和显著值计算(在第1.2 节和第1.3 节中详细介绍)得到的显著图Mapj.Mapj作为下一个分割尺度检测时的目标先验知识,用以指导预选目标区域提取.对显著图Mapj进行二值化处理,采用自适应的阈值策略,将Mapj的值分为K个通道.用p(i)表示属于通道i的像素数量,并确定所有通道中像素数量最多的通道k,通过式(1)计算阈值T.
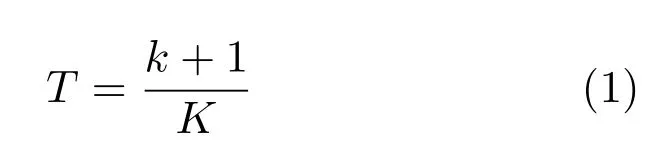
为防止T取值过大,确保在显著目标占据图像大部分空间时,较为显著的像素不被二值化为0.每个通道像素数目必须满足p(i)/area(I)<ε,其中area(I)为图像l的像素个数.ε是落在[0.65,0.95]范围内的经验值.所得二值化目标先验图为MapBj.
使用MapBj作为目标先验知识,选取下一个尺度sj+1下相应位置的超像素区域构成预选显著性超像素集Supselectj+1Mj+1是在分割尺度sj+1上提取的预选显著目标超像素个数,Mj+1
1.1.2 区域优化
预选目标超像素集Supselectj+1可能包含一些背景区域或缺失部分显著区域.需对预选目标区域进行优化,将Supselectj+1中可能的背景区域去除掉,并将背景区域中可能的显著性区域加入进来.
根据两种颜色空间特征的欧氏距离来构造超像素之间的相异矩阵Difmat,表示超像素之间的相异性.Difmat是一个Nj+1阶对称矩阵.
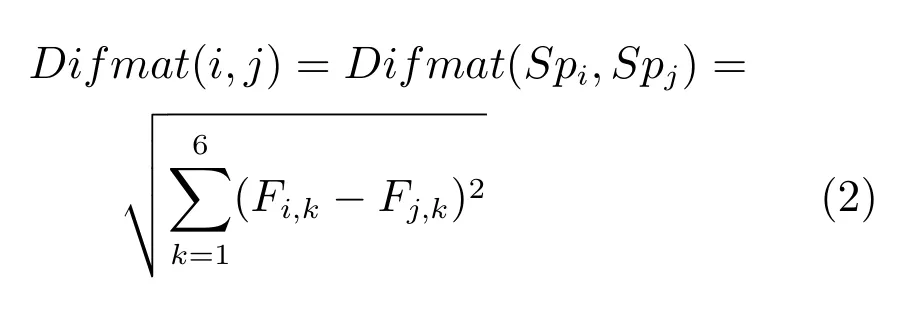
其中,Fi,k为超像区域Spi的第k个特征,k从1到6 分别对应R,G,B,L,a和b特征.对于SpkSupselectj+1,通过式(3)计算局部的平均相异度
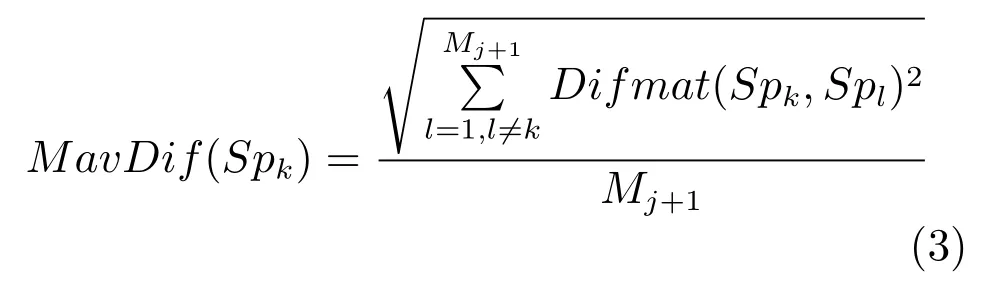
其中,Spk,SplSupselectj+1,Mj+1是预选显著区域集Supselectj+1中超像素个数.计算Supselectj+1中每个超像素Spk与其相邻的背景区域的平均相异度
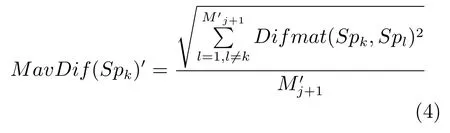
其中,SpkSupselectj+1,SplSupselectj+1,且Spk与Spl相邻,表示背景区域中与Spk相邻的超像素个数.如果MavDifDavDif(Spk),表明Spk与相邻的背景区域的相似度更高,则将Spk从Supselectj+1删除.
同样,对于任意SphSupselectj+1,可计算Sph与相邻背景区域中的平均相异度MavDif及Sph与相邻预选显著区域的平均相异度MavDif(Sph).如果满足条件MavDifMavDif(Sph),则说明与其他背景区域相比,Sph与相邻显著区域的相似度更高,则将Sph加入到Supselectj+1中.
通过比较Supselectj+1中超像素与其他显著区域及背景区域的相异度,从而不断更新Supselectj+1,直到Supselectj+1中超像素不再变化.
1.2 预显著区域深度特征提取
本节基于卷积神经网络的深度特征提取方法如图3 所示.在首次超像素分割时提取所有超像素的深度特征,在之后的深度特征提取过程中,只对Supselect集中超像素进行提取.在一定的分割策略下,大大降低计算量,提高计算速度.
假设不是首次分割,对于每一个超像素Spi(SpiSupselect)分别提取局部区域深度特征和全局区域深度特征.
超像素的局部特征包括两部分:1)包含自身区域的深度特征Fself;2)包含自身及相邻超像素区域的深度特征Flocal.
首先,根据预选目标超像素集Supselect,提取每个超像素Spi(SpiSupselect)所在的最小矩形区域Rectself(如图3 区域内的荷花).由于多数超像素不是规则的矩形,提取到的矩形一定包含其他像素点,这些像素点用所在超像素的平均值表示.通过深度卷积网络就可以得到只包含自身区域的深度特征Fself.
仅有特征Fself经过显著性计算得到的显著值是没有任何意义的,在不与其他相邻超像素显著性的对比情况下,无法确定它是否是显著的.因此还需提取包含Spi自身及其相邻超像素的最小矩形区域Rectlocal,从而获得局部区域的深度特征Flocal.
区域在图像中的位置是一个判断其是否显著的重要因素.通常认为位于图像中心的区域比位于边缘的区域成为显著区域的可能性更高.因此,以整幅图像作为矩形输入区域Rectlocal,提取全局区域的深度特征Fglobal.
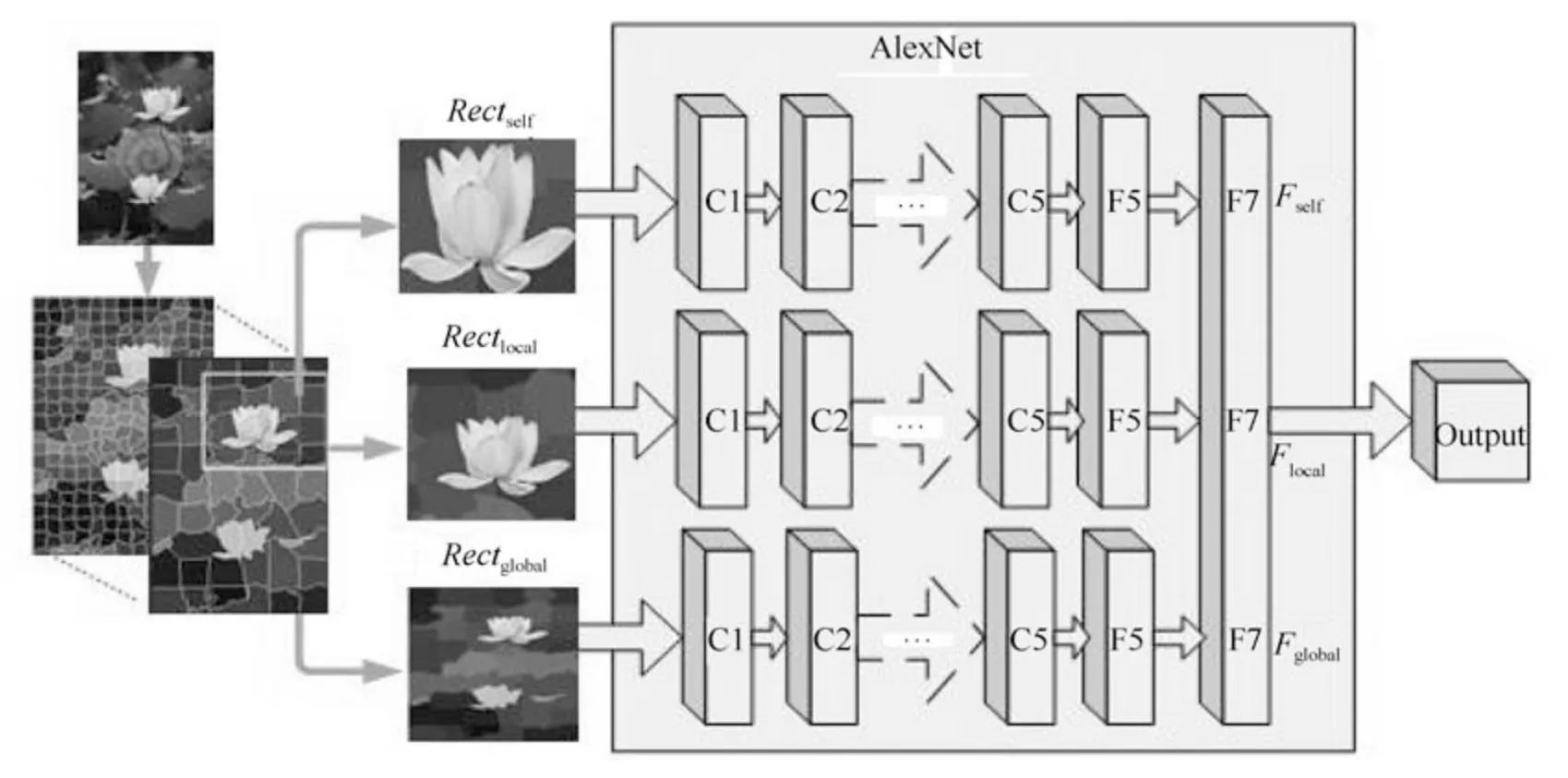
图3 基于卷积神经网络的深度特征提取架构图Fig.3 Deep features extraction based on convolutional neural network
深度卷积神经网络模型是由一个数据输入层、多个卷积层和下采样层、全连接层和输出层共同构成的深度神经网络[23].卷积层和下采样层构成神经网络中间结构,前者负责特征提取,后者则负责特征计算.在一个或者多个下采样层之后会连接一个或多个全连层,每个全连层都可将特征进行输出.卷积层输出结果为
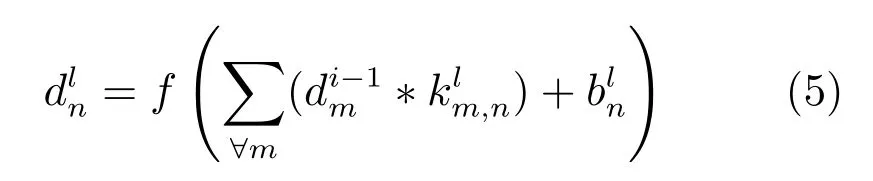
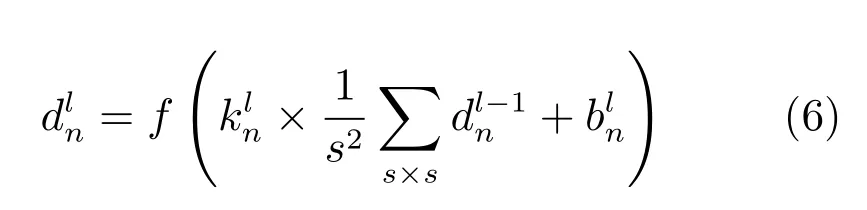
其中,s×s是下采样模板尺度,为模板权值.本文利用训练好的AlexNet 深度卷积神经网络模型来提取预选目标区域的深度特征,并在此模型基础上去除标签输出层以获取深度特征.将预处理后图像输入模型,卷积层C1 利用96 个大小为11×11×3的图像滤波器来对大小为224×224×3 的输入图像进行滤波.
卷积层C2,C3,C4,C5 分别将上一层下采样层的输出作为自己的输入,利用自身滤波器进行卷积处理,得到多个输出特征图并传给下一层.全连接层F6 和F7 每层都有4 096 个特征输出,每个全连接层的输出结果可为
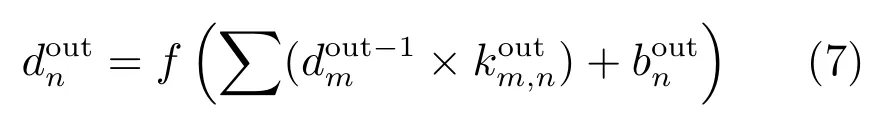
1.3 基于深度特征的显著值计算
主成分分析(Principle component analysis,PCA)[24]是最常见的高维数据降维方法,可以把p个高维特征用数目更少的m个特征取代.对于n个超像素,卷积神经网络输出特征可以构成一个n× p维的样本矩阵W,p12 288.通过式(8)计算样本的相关系数矩阵R(rij)p×p
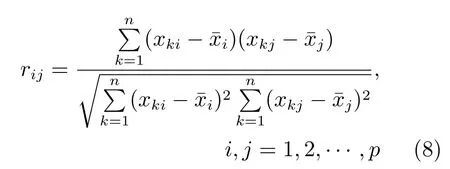
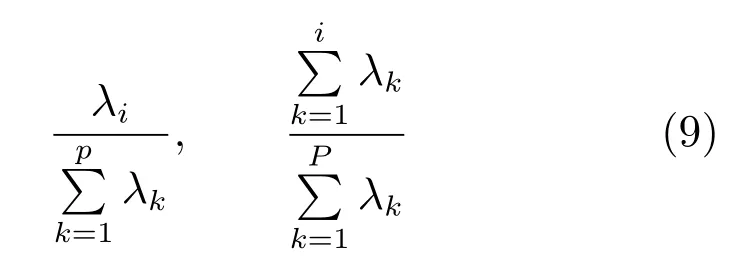
计算每个特征值λi对应的正交单位向量zzzi[zi1,zi2,···,zip]T,选取累计贡献率达到95% 的前m个特征对应的单位向量,构成转换矩阵Z[zzz1,zzz2,···,zzzm]p×m.通过式(10)对高维矩阵M进行降维,Spi(df)(fi,1,fi,2,···,fi,m)表示降维后的m维主成分特征.图像不同尺度的分割图使用同一转换矩阵提取主成分特征.
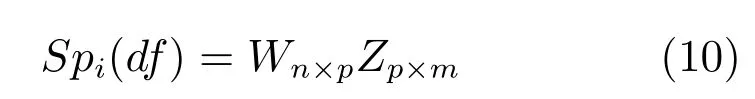
1.3.1 对比特征
对比度特征反映了某一区域与相邻区域的差异程度.超像素Spi的对比特征值wc(Spi),是用它与其他超像素所有特征的距离来定义的,如式(11)所示
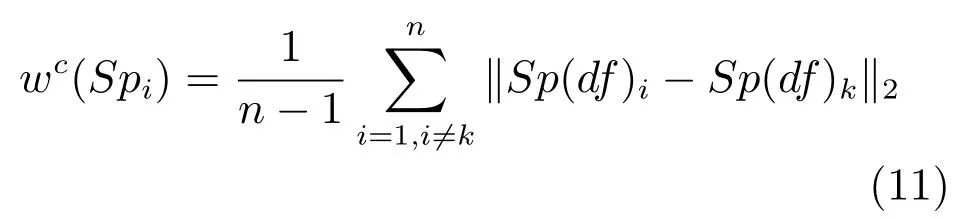
其中,n表示超像数的个数,2 是2-范数.
1.3.2 空间特征
在人类视觉系统中对不同空间位置的关注度不同,越靠近中心越能引起注意.图像中不同位置的像素到图像中心的距离满足高斯分布,对任一超像素Spi,其空间特征值ws(Spi)用式(12)计算
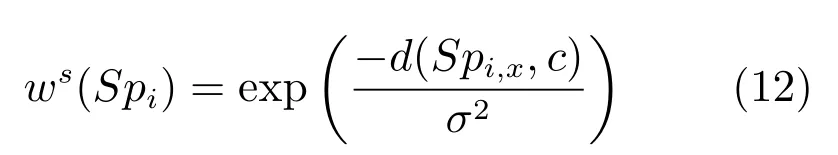
其中,Spi,x为超像素Spi的中心坐标,c为图像中心区域.与图像中心的平均距离越小的超像素块空间特征值越大.超像素Spi的显著值用式(13)表示
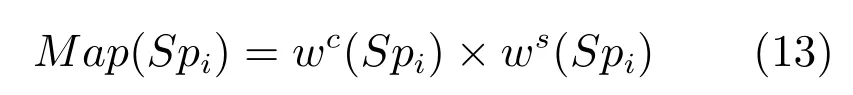
计算得到第一个分割图的显著图Map1,作为后序分割尺度的目标先验知识来指导预选目标区域的提取和优化.
1.3.3 目标先验显著性计算
通过目标先验知识提取预选目标区域Supselect后,超像素集中显著性区域占绝大部分,即显著性区域不在是稀疏的.因此,再按照式(11)计算对比特征值是不准确的.
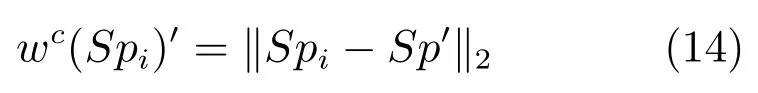
在已知目标的大致空间分布的情况下,特别是分散的多目标情况,根据图像中心来计算空间特征不够准确.可以根据已知的显著目标空间分布来以目标先验图中的显著性区域的中心来代替图像中心进行计算,如式(15)所示.
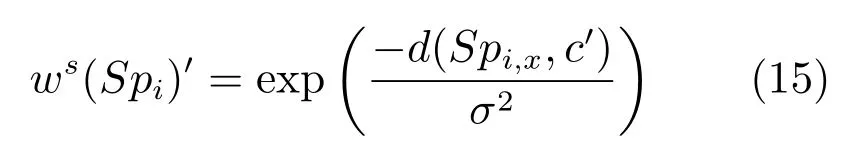
其中,Spi,x为超像素Spi的中心坐标,为目标先验图中的显著性区域的中心.如果存在多个独立的显著性区域,那么表示与超像素Spi最近的显著性区域的中心.由式(13)计算最终显著值得到目标先验下的显著性图Mapi,i代表不同的尺度.
1.4 基于加权元胞自动机的显著图融合
Qin 等[25]提出了多层元胞自动机(Multi-layer cellular automata,MCA)融合方法.显著图中每一个像素点表示一个元胞,在M层元胞自动机中,显著图中的元胞有M−1 个邻居,分别位于其他显著图上相同的位置.
如果元胞i被标记为前景,则它在其他显著图上相同位置的邻居j被标记为前景的概率λP(ηi+1).同样,可以用µP(ηi+1)来表示元胞i标记背景时,其邻居j成为背景的概率.
对于不同方法得到的显著图,可以认为是相互独立的.在同步更新时认为所有显著图的权重是一样的.不同分割尺度下的显著图之间有指导和细化关系,在融合的过程中权重不能认为是相等的.在不同的分割尺度中,假设首次分割尺度得到的显著图的权重为λ1,用wiλ1来表示.不分割尺度下的显著图权重用式(16)表示为
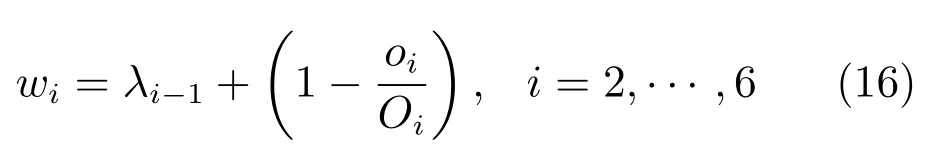
其中,Oi表示预选目标集中所有超像素包含的像素总数,oi表示第i幅显著性区所包含的像素数量.将λ1的初始值设置为1,同步更新机制f:MapM−1→Map,定义为
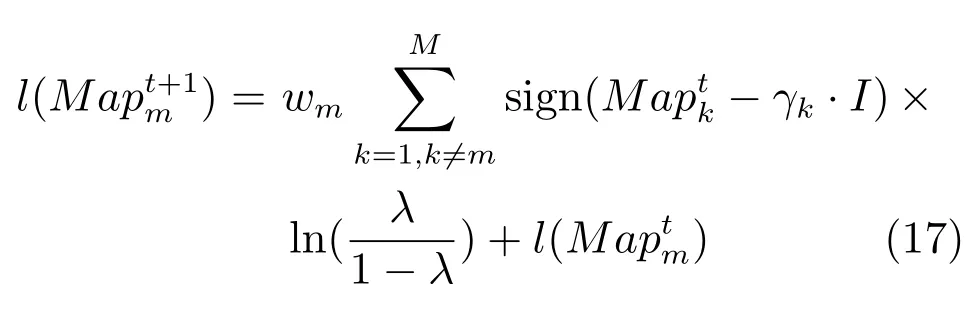
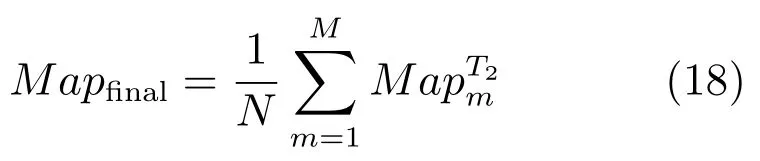
将多尺度分割显著图经过加权MCA 融合后得到最终的显著图,从而完成单幅图像的显著性检测.根据前面内容对本文的基于深度特征的多目标显著性检测算法的整个流程进行了总结,如算法1 所示.
算法1.基于深度特征的多目标显著性检测算法
输入.原始输入图像I和多尺度分割个数N和每个尺度下的分割参数.
输出.显著图fori1:N
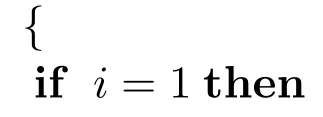
1)根据确定好的参数,用SLIC 对图像l进行超像素分割;
2)确定每个超像素的输入区域Rectself,Rectlocal,
3)将输入区域送入Alexnet 网络,提取深度特征[Fself,Flocal,Fglobal];
4)将所有超像素的深度特征构成矩阵W,利用PCA 算法计算W的转换矩阵A,获取主成分特征;
5)根据主成分特征计算无目标先验的显著值,得到首次分割显著图Map1;
else
6)根据确定好的参数,用分水岭算法对图像l进行超像素分割;
7)将显图Mapi−1当作目标先验图,提取并优化预选目标区域集Supselect;
8)确定Supselect中每个超像素的输入区域Rectself,Rectlocal,Rectglobal;
9)将输入区域送入Alexnet 网络,提取深度特征[Fself,Flocal,Fglobal];
10)将所有超像素的深度特征构成矩阵W,用转换矩阵A得到主成分特征;
11)根据主成分特征计算有目标先验的显著值,得到显著图Mapi;

12)计算每个尺度下的显著图的权重wi;
13)用加权MCA 对得到的N幅显著图进行融合,得到最终的显著图Mapfinal.
2 实验结果与分析
2.1 数据集介绍
数据集SED2[26]是目前比较常用的多目标数据集,它包含了100 幅图像和相应的人工标注图,每幅图像中都包含了两个显著目标.HKU-IS[18]包含近4 500 幅由作者整理挑选的图像,每幅图像中至少包含2 个显著目标,并且目标与背景的颜色信息相对复杂,同时提供人工标注的真实图.本文是针对多目标的检测算法,因此只选择HKU-IS 中具有两类或两个以上目标的2 500 幅图像进行实验.另外为分析本文算法各部分性能,从HKU-IS 中随机选择500 幅图像建立测试数据集,在进行参数选择和评价PCA 以及自适应元胞自动机性能时均使用此测试集.
2.2 评价标准与参数设置
在本节的实验中,通过对比显著图的准确率(Precision)–查全率(Recall)曲线(PR 曲线)、准确率–查全率–F-measure 柱状图(F-measure 柱状图)与平均绝对误差(Mean absolute error,MAE)柱状图三个标准来评价显著性检测的效果,从而选出相对较好的分割尺度.
查准率与查全率是图像显著性检测领域最常用的两个评价标准,PR 曲线越高表示显著性检测的效果越好,相反PR 曲线越低,相应的检测效果就越差.对于给定人工标注的二值图G和显著性检测的显著图S,查准率Precision 与查全率Recall 的定义如式(19)所示
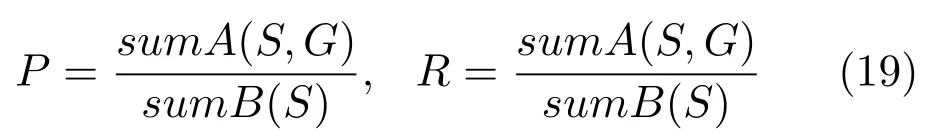
其中,sumA(S,G)表示显著性检测的视觉特征图S和人工标注的真实二值图G对应像素点的值相乘后的和,sumB(S)、sumB(G)分别表示的是视觉特征图S 和人工标注的真实二值图G上所有像素点的值之和.
不同于准确率–召回率曲线,在绘制准确率–召回率–F-measure 值柱状图时,利用每幅图像的自适应阈值T对图像进行分割
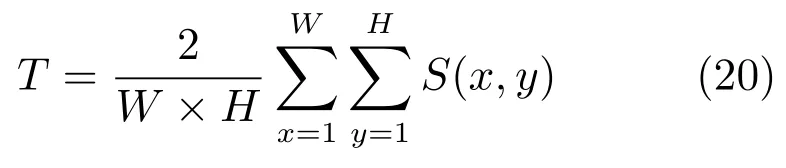
其中,参数W与H分别指代图像的宽度与高度.对每个数据集中的显著图,计算它们的平均准确率与召回率.根据式(21)计算平均的F-measure 值,F-measure 的值超高超好.F-measure 值用于综合评价准确率与查全率,在显著性检测中查准率要比查全率更加重要,所以β2的值常设置成0.3[19].
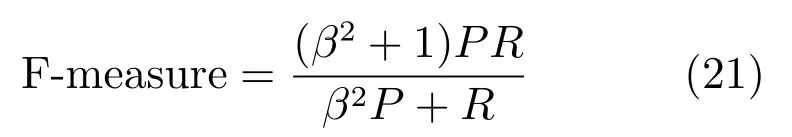
平均绝对误差通过对比显著图与人工标注图的差异来评价显著性模型[20].根据式(22)可以计算每个输入图像的MAE 值,并利用计算出的MAE 值绘制柱状图,MAE 值越低表明算法越好[21].
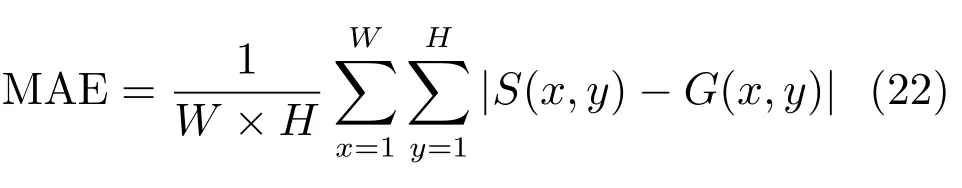
2.2.1 确定分割尺度
本文算法参数主要为分割尺度.分割尺度太多会增加计算复杂度,太少则会影响显著性检测效果的准确性.因此,根据经验设置15 个分割尺度并将其限定在[20,25]范围内.
在随机选取的数据上进行实验,根据经验设置15 个分割尺度,提取分割图中所有超像素的深度特征计算显著图.不同分割尺度显著性检测结果的Precision-Recall 曲线图如图4 所示.从中选择6 个效果较好的分割尺度.通过对比分析发现分割尺度1,3,4,6,8,13 这6 个分割尺度下的显著性检测效果相对较好.选择这6 个分割尺度作为本文算法的最终分割尺度.
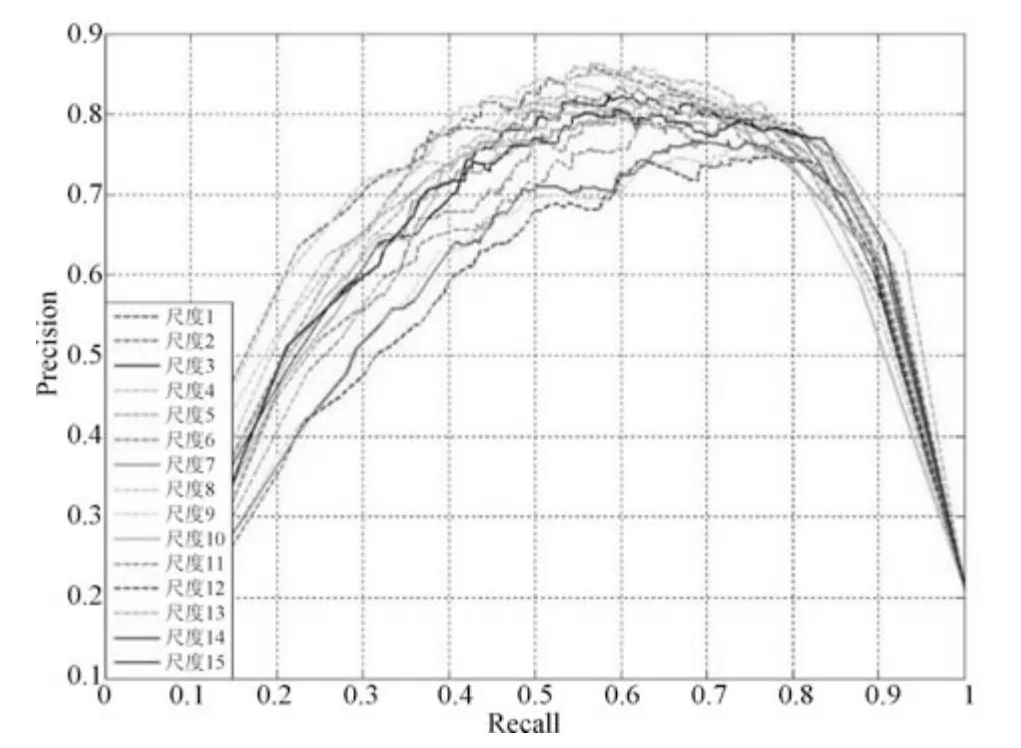
图4 不同分割尺度下显著性检测的PR 曲线图Fig.4 Precision-Recall curves of saliency detection in different segmentation scales
2.2.2 预显著区域提取策略选择
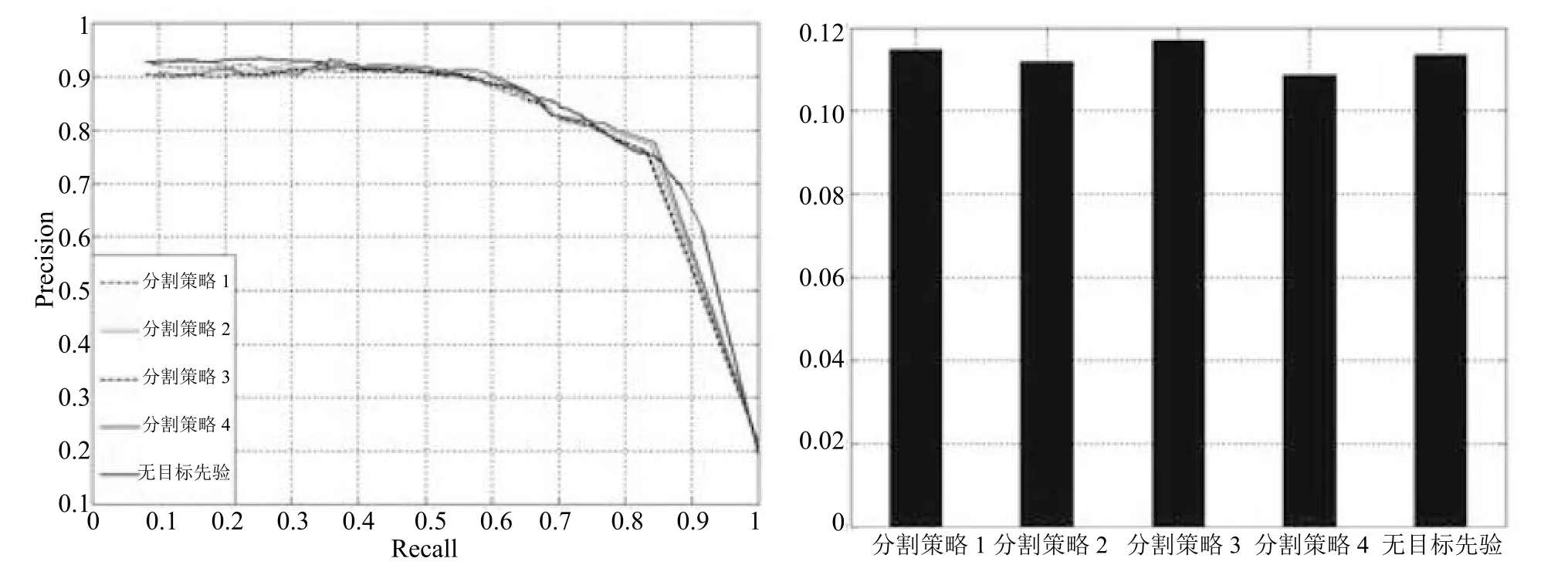
图5 不同分割策略下显著性检测的PR 曲线图以及MAE 柱状图Fig.5 Precision-recall curves and MAE histogram in different segmentation strategies
在结合目标先验知识后,不同的分割策略组合得到的结果并不一致,且运行速度也存在较大差异.按照分割所得超像素个数进行组合,可分为由少到多、由多到少、多少多交叉和少多少交叉共4 种组合策略.在这4 种分割组合策略和不加目标先验情况下显著性检测结果的PR 曲线图以及MAE 柱状图如图5 所示.运行时间如表1 所示.由图可以看出,4 种策略的PR 曲线大致相当,但策略4 的要稍高于其他3 种分割策略,与无标先验的的显著性检测相差不大.从表中可以看出策略4 运行速度最快,与无目标先验的检测相比,在检测效果相差无几的情况下,平均每幅图像的检测时间提高了50% 左右.
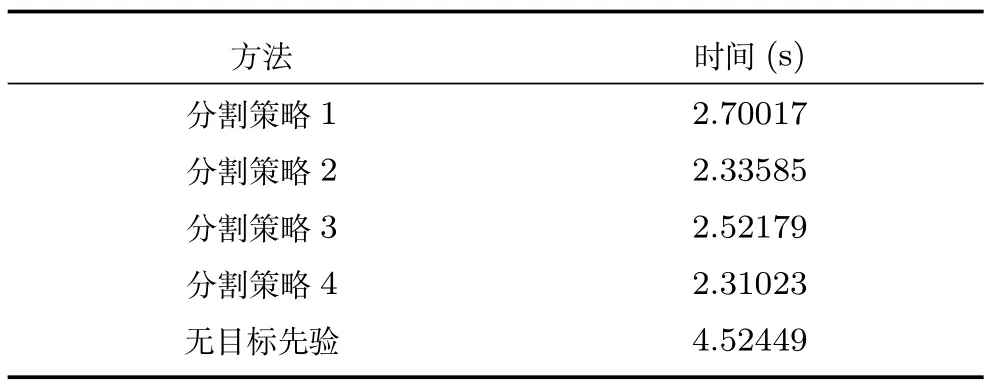
表1 不同分割策略下平均每幅图像检测时间Table 1 The average detection time for each image in different segmentation strategies
2.2.3 PCA 参数确定
为验证PCA 算法从深度特征中选取主成分的有效性,本节通过测试集的500 幅图像中各超像素块中所提取的深度特征作为数据集,通过可解释方差(Percentage of explained variance,PEV)[27]来衡量主成分在整体数据中的重要性,该指标是描述数据失真率的一个主要指标,累计率越大,数据保持率越高.计算方式为
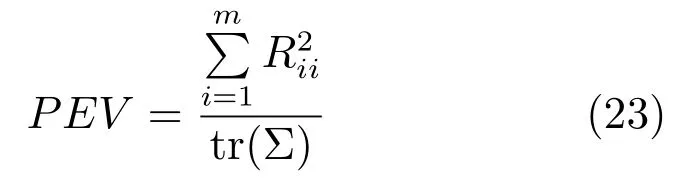
其中,为主成分矩阵奇异值分解后的右矩阵,Σ 为协方差矩阵.图6 给出前50 个主成分与累计可解释方差.从图中可以看出随着主成分个数的增加累计可解释方差呈上升趋势,但这种上升趋势会随着主成分个数的增加而逐渐放缓.当主成分个数超过10 后累计可解释方差达到80% 以上,认为其能够代表数据整体信息,在本文设计算法中选取前10 个主成分进行显著值计算.
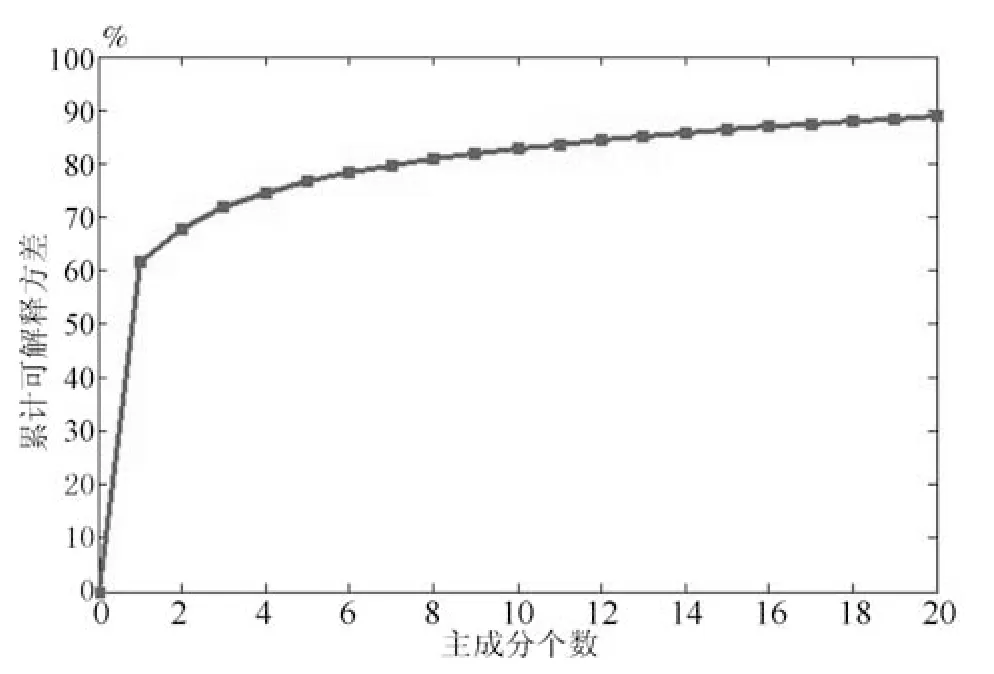
图6 主成分个数与累计可解释方差关系图Fig.6 The relationship between the number of principal component and percentage explained variance
2.2.4 元胞自动机评价
为评估自适应元胞自动机融合有效性,对测试集使用9 种不同方式得到显著图,分别是本文所选6种分割尺度、线性融合[17]、MCA[24]以及加权元胞自动机.通过PR 值与MAE 值对这9 种方法进行评价,所得结果如图7 所示.
通过对比可以发现,不同分割尺度下所得显著图的PR 曲线十分相似,但是查准率与查全率均不理想.通过线性融合方法得到的显著图能改善单一尺度检测结果的鲁棒性使其在检测结果更加稳定.MCA 融合方法明显好于线性方法得到的显著图,而改进后的加权MCA 方法得到的多尺度分割融合图具有更好的查准率,因此所得融合结果将更加准确.从MAE 柱状图中也可看到相同结果.
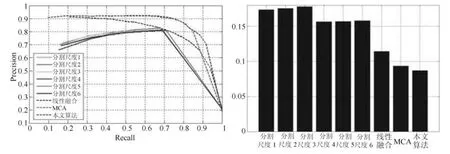
图7 不同融合方法的PR 曲线与MAE 柱状图Fig.7 Precision-Recall curves and MAE histogram of different fusion methods
2.3 实验结果对比
为验证本文提出的多目标显著性检测方法的性能,在两个数据集上同10 种显著性检测算法进行对比,包括FT09[28],GC13[13],DSR13[29],GMR13[12],MC13[14],HS13[14],PISA13[30],HC15[10],SBG16[31],DRFI[16]和MDF15[18].除MDF 算法外,其他都是基于底层特征进行显著性计算的,也是近几年显著性检测算法中相对较好的一些经典算法.而MDF 算法是最早的应用深度卷积神经网络进行显著性检测的算法之一,且是目前为数不多的提供了源代码的深度学习算法.
2.3.1 主观评价
从主观的视觉上,图8∼10 分别显示了在两个数据集上的视觉显著图.从左至右依次是:原始输入图像,对比算法DSR,FTvGCvGMR,HCvHSvMCvPISA,SBG,DRFI,MDF 的显著图,以及本文算法显著图和人工标注的真实图.
图8 显示了本文算法与其他算法在数据集SED2 上的显著图对比情况.通过对比可以看出,本文算法对位于图像边缘的目标(如图8 中的第2∼4 行和9 行)的检测效果明显优于对比算法.此外对于图像中的小目标(如图8 中第4∼6 行)检测效果也很优异.
图9 和图10 是不同算法在复杂多目标数据集HKU-IS 上的显著图对比情况.与图8 相比,图9 中图像的背景相对要复杂一些,而图10 中的图像都包含了3 个以上的显著目标.通过与其他算法显著图的对比可以看出,本文算法和MDF 算法相比于其他算法在多目标的复杂图像的显著性检测的效果更好,这充分特征了深度特征在图像表达方面的优势.本文算法经过加权MCA 融合后的显著图中,显著目标区域内显著值的一致性要明显著优于其他方法.
2.3.2 定量比较
为了更加客观地评价本文算法与其他算法,本文根据不同的评价标准,在两个数据集上进行了对比实验分析.
图11 是根据准确率–召回率和准确率–召回率–F-measure 值评价标准,不同检测算法在数据集SED2 上检测结果的PR 曲线图和F-measure 柱状图.通过图11 对比分析可以看出本文算法在数据集SED2 上的PR 曲线与F-measure 柱状图上与MDF 算法相当,但明显优于其他对比算法.这与主观视觉特征的评价相致,进一步体现了深度特征在图像表达上的优势.
图12 是不同检测算法在数据集HKU-IS 上的PR 曲线图和F-measure 柱状图,可以看出在复杂数据HKU-IS 上,本文算法与MDF 算法相比,随着查全率的变化,查准率各有高低,但都能保持较高的水平.但在F-measure 值上,本文算法要比MDF算法高出7.18%.
相比于数据集SED2,数据集HKU-IS 的图像中包含更多的显著目标和相对复杂的背景信息.与除MDF 算法外的其他算法相比,无论是PR 曲线值,还是F-measure 值,本文算法都明显高于其他对比算法,并且与在数据集SED2 的结果相比,优势更加明显.这些充分体现了本文算法在图像信息相对复杂的多目标显著性检测中的优越性,如显著性目标位于图像边缘、多个显著性目标、显著性目标包含多个对比度明显的区域等情况.

图8 不同算法在数据集SED2 上的视觉显著图Fig.8 Saliency maps of different algorithms on dataset SED2
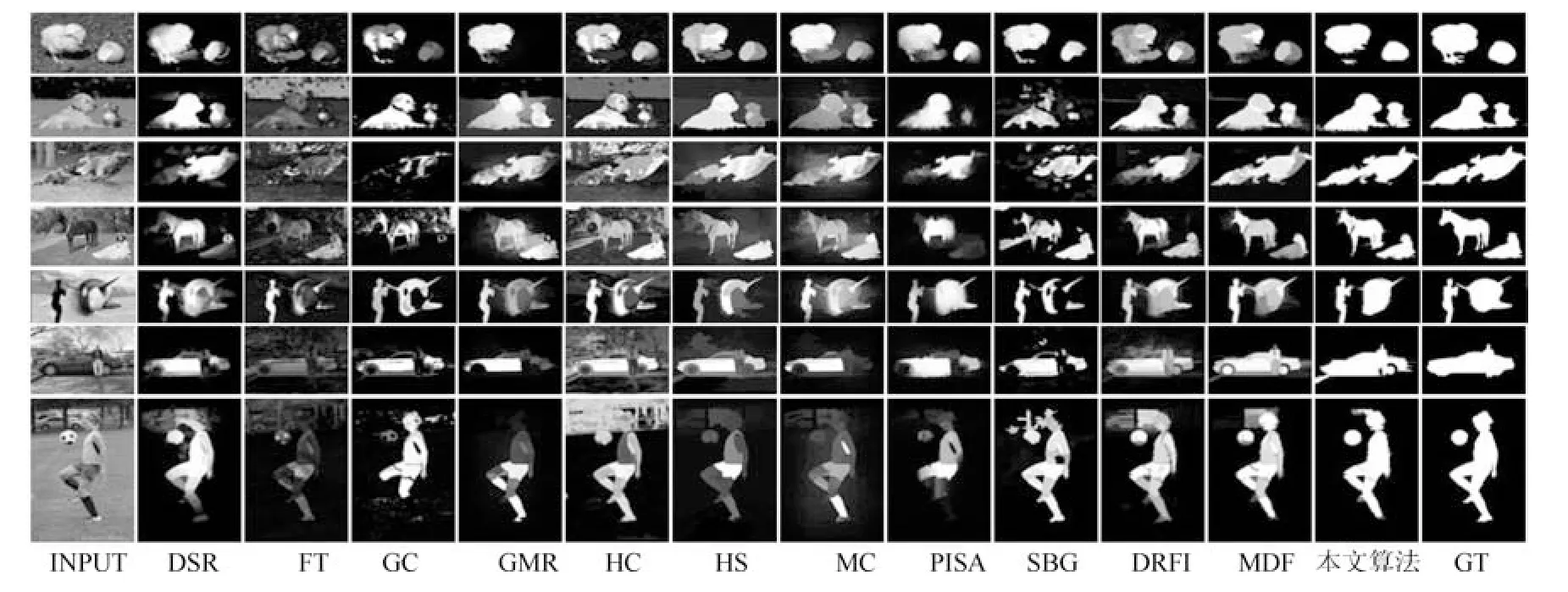
图9 不同算法在具有不同类别目标的数据集HKU-IS 上的视觉显著图Fig.9 Saliency maps of different algorithms on dataset HKU-IS with different classes of objects
图12 是不同算法根据平均绝对误差这一评价标准在两个数集上的MAE 柱状图.同样,本文算法的平均绝对误差远低于其他算法,在两个数据集上降低到了10%以内,并且在数据集HKU-IS 更是降到了7.2%.
2.3.3 运行时间
不同算法在对图像处理的速度上也存在明显的差异,如表2 所示.在显著性检测的速度上,本文方法要比FT、GC 等算法要慢的多,这也是基于深度学习算法的不足之处.但与MDF 算法相比,处理效率上提高7 倍左右,这说明本文的目标先验知识的应用在提高速度上的有效性.
综上所述可以看出,无论从视觉特征图上进行主观评价,还是基于三种评价标准上的客观分析,本文算法与其他算法相比都具有十分明显的优势.而MDF 算法与其他基于低层特征的算法相比优势同样也较为明显.这些都证明了本文算法的在显著性检测上的有效性,同时也表明基于深度学习的显著性检测算法在计算机视觉领域的巨大潜力.

图10 不同算法在具有多个目标的数据集HKUIS 上的视觉显著图Fig.10 Saliency maps of different algorithms on dataset HKU-IS with different multiple objects
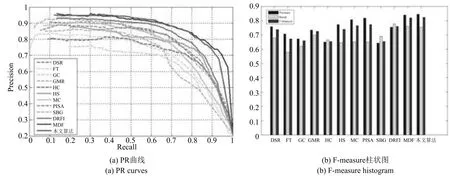
图11 不同算法在数据集SED2 上的PR 曲线图和F-measure 柱状图Fig.11 PR curves and F-measure histogram of different algorithms on dataset SED2
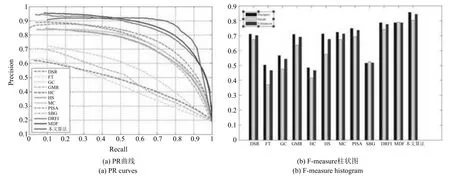
图12 不同算法在数据集HKU-IS 上的PR 曲线图和F-measure 柱状图Fig.12 PR curves and F-measure histogram of different algorithms on dataset HKU-IS
3 结束语
基于深度学习的显著性检测算法能够克服传统的基于底层特征的显著性检测算法在检测效果上的不足,但运行速率与之相比又有明显不足.本文提出一种多尺度分割和目标先验的目标预提取方法,在此基础上通过深度特征提取进行显著值计算,使用加权元胞自动机对尺度显著图进行融合与优化.本文方法虽然在多目标显著性检测的效果和速度上有所提升,但仍存在许多不足,主要工作将继续完善深度神经网络的构建和效率提升等问题.
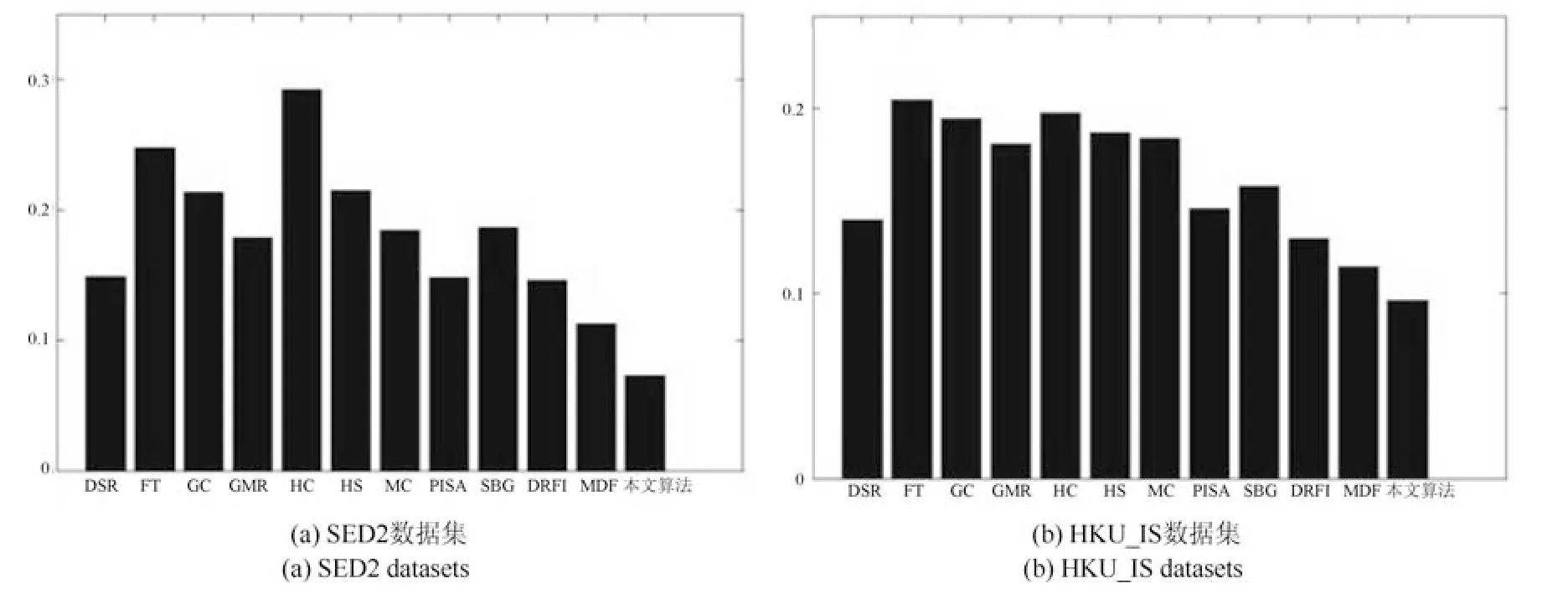
图13 不同算法在数据集SED2 和HKU-IS 上的MAE 柱状图Fig.13 The MAE histogram of different algorithms on dataset of SED2 and HKU-IS

表2 平均检测时间对比表Table 2 Table of contrast result in running times
