基于MIMIC-III数据库对ICU患者结局预测的研究
2019-12-12黄菩臣练作为陶敏杨永强杜江赵蕴龙
黄菩臣,练作为,陶敏,杨永强,杜江,赵蕴龙
1. 南京航空航天大学 计算机科学与技术学院,江苏 南京 211106;
2. 上海交通大学附属上海市第一人民医院,上海 201620
引言
伴随着数据挖掘技术的发展及国家对医疗领域的日渐重视,计算机技术和医疗领域相结合日益受到社会重视。在此背景下,临床医疗数据挖掘正逐渐成为热点研究领域。
其中,关于ICU患者结局预测的研究一直是该领域研究的热点,该方向的研究主要是利用计算机或数学建模方法,使用数据库数据对患者进行死亡率的预测。马京杭等[1]通过收集妊娠合并SLE患者的临床资料,训练并建立预测妊娠结局的神经网络模型,并验证具有较高的准确性。甘惠玲等[2]通过对机械通气患者的临床资料进行APACHE II评分,预测重症肺炎致急性肺损伤患者的撤机结局。Basic等[3]使用加拿大衰老临床脆弱量表的数据,通过建立数学模型预测患者结局,帮助医生进行诊断筛查。
另外,关于MIMIC-III数据库的研究主要集中于预测某种特定疾病对患者的病情影响。Mengling等[4]使用MIMIC-III数据库鉴别使用TTE和未使用TTE对患有败血症的重症患者的影响,具有重要的参考意义。张英凯[5]在国内首次使用MIMIC-III数据库在对患者结局进行预测,但其仅适用于肝脏系统功能障碍相关病患,受众人数较小。
本文利用机器学习手段,使用MIMIC-III数据库来对ICU患者结局进行预测。本研究期望通过机器学习算法建立预测模型,实现对重症监护数据库患者结局的预测,以此来辅助诊断。同时,对样本集关键特征进行分析,以判断关键样本特征对重症监护数据库结局的影响。
1 材料与方法讨论
1.1 MIMIC-III 数据库介绍
MIMIC-III:MIT麻省理工大学下属管理的一个公共临床数据库,全称为Medical Information Mart for Intensive Care,对公众免费开放,收集了2001年到2016年之间来自于BIDMC医学中心的ICU房病人数据超过5万例。包含了病人人口统计特征、基本体征记录、医疗干预记录、护理记录、影像学检测结果与出院记录等诸多医疗数据[6-7]。
1.2 样本特征
在相关医疗专家的指导下,梳理MIMIC-III数据库中的多个重要特征。选取得到的特征有血压、呼吸频率、体温、心率、血氧饱和度、动脉血氧饱和度、氧分压等。它们都用一个ITEM来表示(后文记为ITEM特征)。
在综合考虑重要程度、数据复杂性、数据缺失程度等多方面因素后,筛选出十七个关键特征:葡萄糖含量、乳酸含量、心率、无创血压-收缩压、呼吸频率、血氧饱和度、体温、动脉血氧饱和度、无创血压-舒张压、血红蛋白、钠含量(全血)、白蛋白、血肌酐、钾含量、钠含量、血红蛋白凝血酶原时间和血小板数量。其对应的ITEM标号如表1所示。
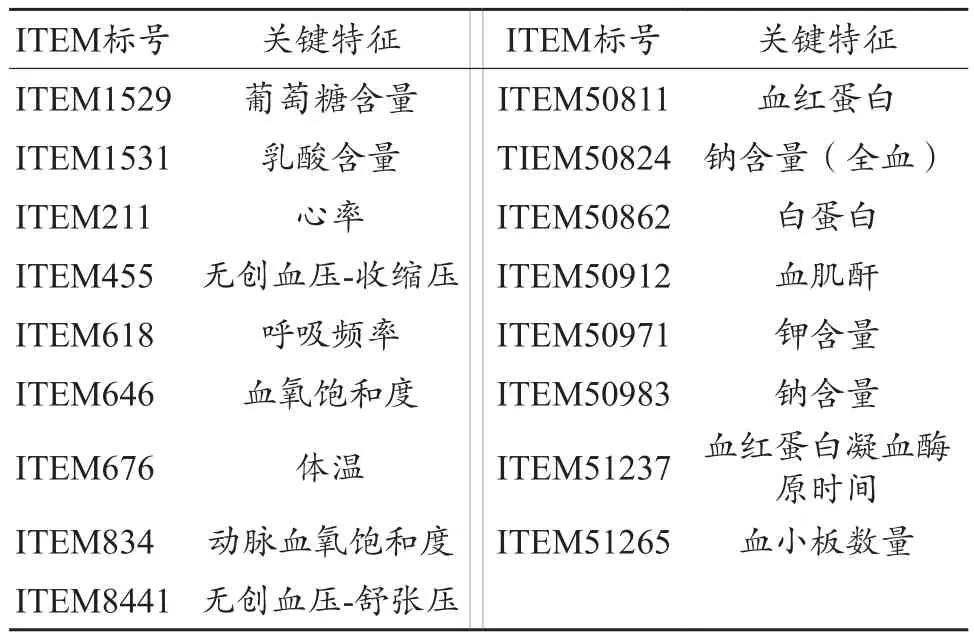
表1 ITEM标号对应的关键特征
1.3 方法讨论
对患者结局的预测只有死亡或存活两类。本研究的目的在于找到最适合的算法进行分析。
在当前最流行的深度学习[8-9]、逻辑回归等七类分类算法中,我们选定了逻辑回归算法和支持向量机中的线性SVM算法进行探究,原因在于以下两个方面。
(1)逻辑回归运算速度快,简单易于理解。动态改变各个特征的权重,能容易地更新模型,吸收新的数据,可以动态调整分类域值[10]。聂竞飞等[11]通过Logistic回归分析得到自变量的权重,从而可以了解哪些要素是能够引发疾病的危险因素。Zhang[12]通过进行似然比检验的方法进行逻辑回归模型构建,从而提高模型的拟合优度。De Caigny等[13]提出一种基于逻辑回归和决策树的混合算法,以便进行数据分类。
(2)SVM可以解决小样本下机器学习的问题,提高泛化性能,解决高维、非线性问题,避免神经网络结构选择和局部极小的问题。Harris[14]使用聚类支持向量机进行信用评分,提高了分类性能水平。汤荣志等[15]对支持向量机必须的数据预处理过程的数据归一化提供了科学依据。刘忠宝等[16]提出基于分类超平面的非线性集成学习机NALM,其方法能以较少的支持向量来解决大规模样本分类问题。赵长春等[17]采用支持向量机序列最小优化算法,具有比原始算法更快的训练速度和稳定的训练结果。
图1为本文的研究流程,研究流程分为主题选定、数据预处理、数据可视化、实验验证、得出结论。
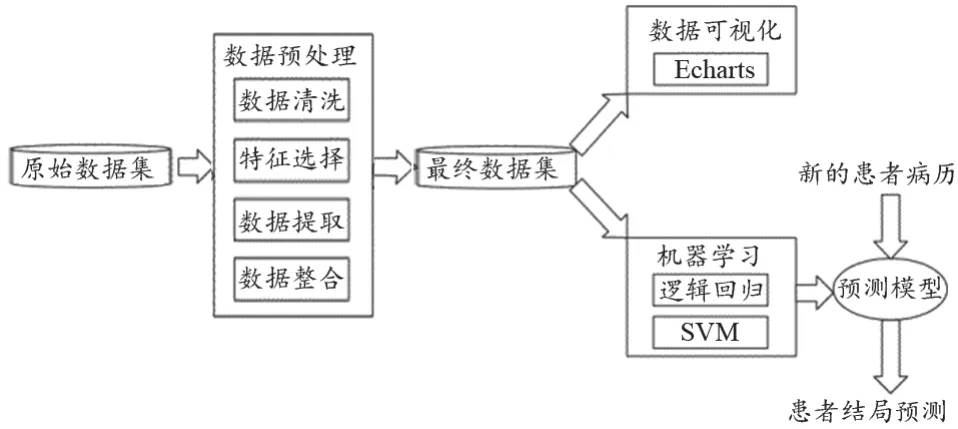
图1 研究流程
2 实验研究
首先,对MIMIC-III 数据库中的数据进行预处理,得到最终数据集。其次,通过机器学习算法(逻辑回归和线性SVM)进行ICU病房患者结局预测(存活/死亡)研究。最后,对实验结果进行总结。
2.1 数据预处理
数据清洗过程从以下几方面进行。
(1)数据清洗。MIMIC-III数据库中ICU病房记录特征值比较多。在该研究中,需要剔除历史较久远、参考价值不高、缺失较多的数据。数据清洗的目标,是得到有效的、可以直接使用的数据。
(2)特征选择。选取前文中筛选出的十七个关键特征作为研究特征。
(3)数据提取。使用SQL数据库语言进行数据提取。在进行筛选时,为防止由于存活和死亡数据量差异过大,选择患者最后一次入院记录。此外,对清洗后每一条数据追加存活判断符,零表示存活,非零表示死亡。
(4)数据整合。整理结果得到含有1400条数据的数据集(后文记为1400样本集,表2)。
表2 数据集内容
2.2 基于逻辑回归的结局预测
2.2.1 算法执行
算法过程按以下几个方面执行。
(1)数据初始化。通过识别换行符和空格符,对数据进行分割,得到每条数据的各项指标值。将处理好的数据放入一个二维数组中存储。
(2)数据归一化。指标的数量较多,且某些数据值的极差很大,容易对最终结果产生影响。进行数据归一化之后,所有的数据都规约到[0,1]区间,可以避免极差过大的影响。
(3)调节置信概率。置信概率是一个与数据和算法无关的常量,但对预测结果有直接影响。在算法执行过程中,需要多次手动调节其值,以达到最佳结果。
(4)执行逻辑回归算法。将经过(1)、(2)步骤的测试集输入模型迭代,执行得到最优法向量w和截距b,进而求出测试集的正确率。
(5)输出,每进行一次调参,即运行一次模型,记录得到的当前参数对应的预测结果。
2.2.2 输出结果及分析
输入条件为1400样本集、置信概率prob(变动范围为[0.05,0.2])。其中对样本集进行了分割,转化处理为规范数据。输出时,每进行一次调参,即运行一次模型,记录得到的当前参数对应的预测结果。通过多次调参,得到一系列的预测结果数据(表3)。
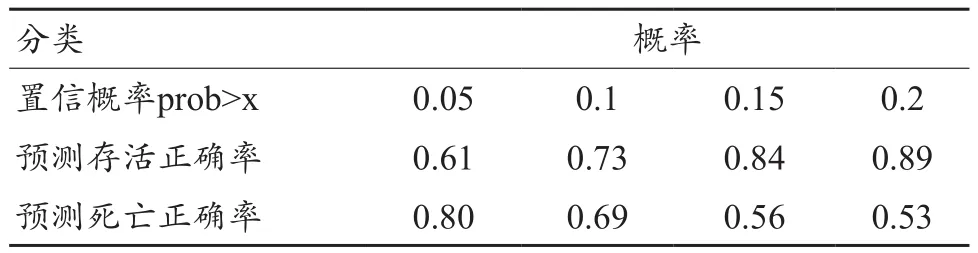
表3 1400样本集预测结果
其中“置信概率prob>x”表示“当输出结果y大于置信概率时判定为存活,否则为死亡”;“预测存活正确率”和“预测死亡正确率”分别为对预测集中存活和死亡结果判断的正确率。
将结果集绘制成图2的折线图效果,其中每条线表示各自正确率随置信概率的变化情况。当置信概率调整到合适值时,预测存活和死亡正确率相等,能达到0.7左右。
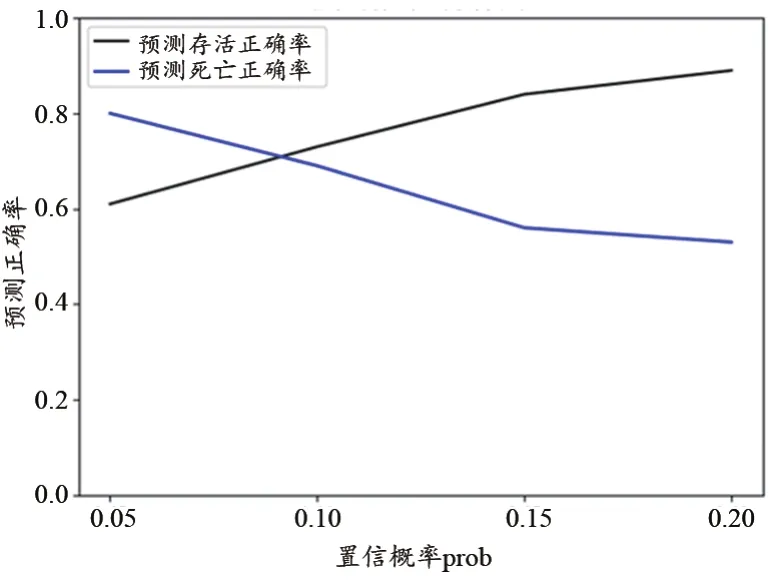
图2 样本集预测结果
2.3 基于支持向量机的结局预测
2.3.1 算法执行
算法过程从以下几个方面执行。
数据初始化。将数据按行分割,每行分为17个指标值和一个存活判断值,重新组合为二维数组。
调节超参数。内容包括:① 松弛变量C代表了模型对离群点的重视程度,C越大代表模型对离群点越重视;② 容错率toler表示模型允许错误判断占总数的百分比;③ 迭代轮数设置了算法执行时,对中间变量alpha的迭代次数。通过调节松弛变量和容错率等超参数,实现对预测结果的调节,最终影响正确率。
执行SVM算法。输入数据集和标签集,执行SVM算法,并在指定迭代轮数后,求得对应的截距b和中间变量alpha的值。然后用alpha求得法向量w。
计算正确率。通过用截距b和法向量w求得的超平面,对测试集进行预测,并求得测试集正确率。
最后进行输出,每进行一次调参,就运行一次模型,得到当前参数对应的预测结果,包括存活正确率和死亡正确率。
2.3.2 输出结果及分析
输入条件为1400样本集、松弛变量C(变动范围为[0.1,0.9])、容错率toler(变动范围为[0.1,0.4])。通过不断人工调节C和toler的值,得到预测正确率的变化曲线。输出时,每进行一次调参,就运行一次模型,得到当前参数对应的预测结果,包括存活正确率和死亡正确率。经过多次调参,得到一系列线性SVM预测结果值,再进行汇总和归纳后得到样本集预测结果(表4)。
表格中C为松弛变量,toler为容错率,“x/y”:x表示测试集存活正确率,y表示测试集死亡正确率。
由上表得到,当C在0.2~0.6之间时,未出现极端情况,因此选取松弛变量C=0.4,测试此时集正确率随容错率的变化(图3)。
由线性SVM的结果可知,当容错率为0.17或0.4时,二者正确率相等,都为0.5左右。显然,线性SVM也能处理判断死亡率的问题,但限制于数据本身的问题,虽然也能对数据进行分类预测,却不能达到令人满意的效果,最终准确率只能达到50%。
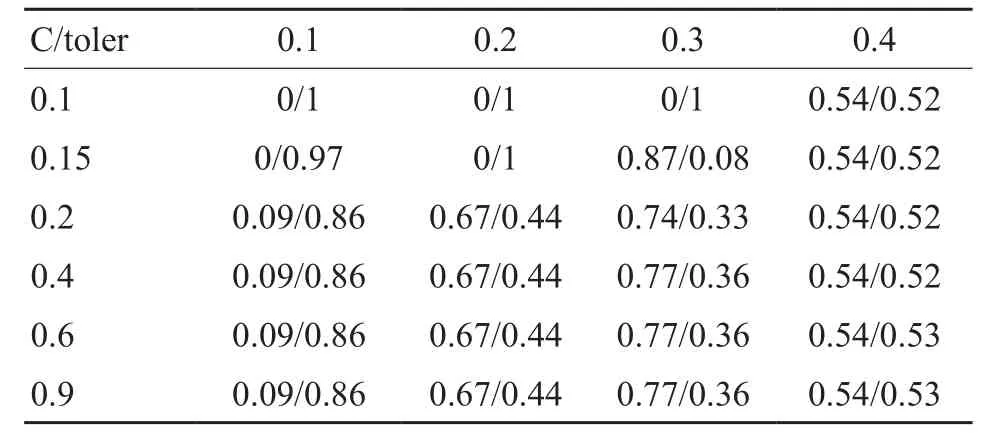
表4 1400样本集预测结果
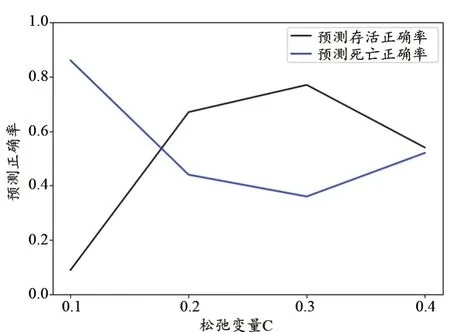
图3 基于支持向量机的集正确率随容错率的变化
2.4 结果
通过对以上两种算法进行实验和比较,我们可以得出以下结果。
对比分析时间,逻辑回归花费的时间最少,大约在30 s左右;线性SVM最慢,运行一次运算需要5 min。从处理速度上考虑,逻辑回归较好。
分析准确率,逻辑回归能达到70%左右的准确率;线性SVM只有50%。可见,从处理准确度上来讲,逻辑回归也较好。
综上,逻辑回归在时间和准确率上都占有很大的优势,能很好地实现对患者结局的预测。
3 可视化研究
数据可视化研究部分基于ECharts开源可视化库实现。共分为两个部分,第一部分为MIMIC-III数据库整体特征进行可视化,第二部分为特征元素可视化。
3.1 整体特征
3.1.1 存活死亡情况
根据MIMIC-III总体数据的存活死亡情况,可知存活比例占66.12%,死亡比例占33.88%(图4)。
3.1.2 男女比例情况
MIMIC-III总体数据的男女比例情况表明男性比例占43.85%,女性比例占56.15%(图5)。

图4 MIMIC-II数据库存活死亡情况

图5 MIMIC-II男女比例情况
3.2 ITEM特征
3.2.1 血小板
血小板的功能是稳定内皮细胞,防止内皮细胞被不同形式的氧化组织损伤。血小板减少是危重病患者最常见的异常指标之一[18]。
在[0,100]区间内,病死者的比例比存活者的比例高,而[100,500]区间存活者的比例较病死者的比例高(图6)。由此可知,病死者的血小板数量比存活者的血小板数量明显降低。
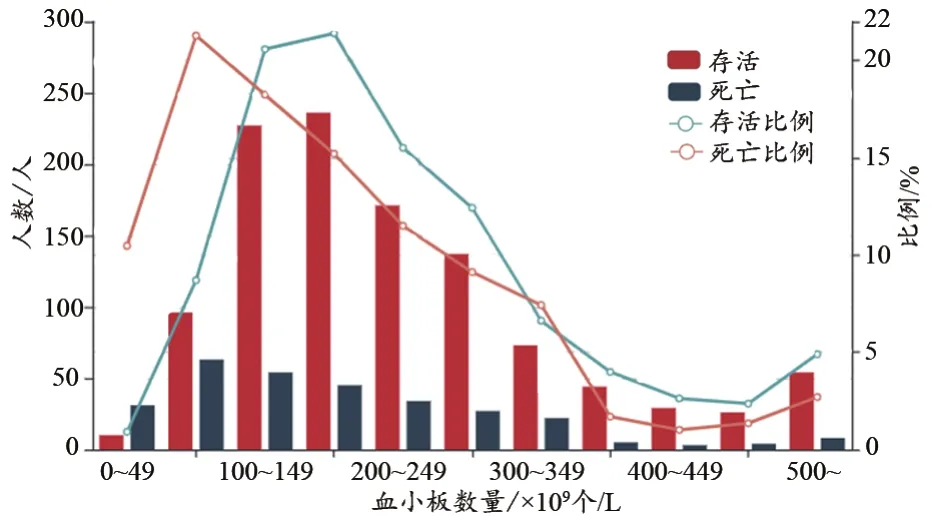
图6 血小板含量与存活/死亡人数的关系(1400样本集)
3.2.2 乳酸
血乳酸水平是反映危重患者组织氧供需平衡的重要指标。在危重病患者中,由于各种原因导致组织缺血缺氧,组织无氧代谢增加,进而机体组织清除乳酸能力下降,会使血乳酸水平明显升高。
乳酸含量在1~3 mmol/L区间的存活者的比例较高,乳酸含量在4 mmol/L以上的区间,病死者的比例比存活者的比例高(图7)。由此可见,病死者的乳酸含量比存活者的乳酸含量明显升高。
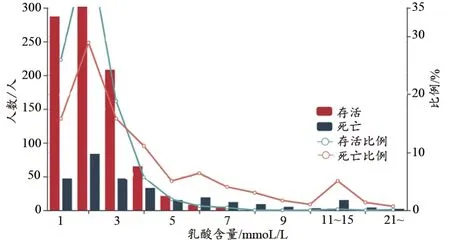
图7 乳酸含量与存活/死亡人数的关系(1400样本集)
3.2.3 血肌酐
血肌酐[19-20]含量在[0.6,1.5]区间的存活者的比例较病死者的比例高,血肌酐含量在[0.1,0.5]以及1.6以上区间的病死者的比例较存活者的比例高。以2800样本集为研究对象,分析血肌酐含量与存活/死亡人数(图8)。
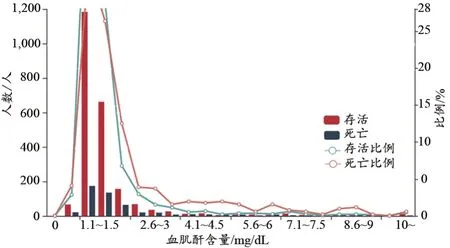
图8 血肌酐含量与存活/死亡人数关系(2800样本集)
4 讨论与展望
本文基于MIMIC-III数据库,提取出与ICU患者结局相关的十七个关键特征。患者结局预测模型使用了两类算法:逻辑回归和线性SVM。研究结果显示,逻辑回归算法较优,准确率可达70%,且耗时短、实用性较高。同时,对提取出的关键样本特征进行可视化研究的结果显示,血小板、乳酸、血肌酐等的含量与患者结局之间具有关联性。目前模型仍存在样本量小、数据缺失等问题,建议使用更大的数据库获取大样本集,以弥补这方面的缺陷。患者结局预测模型虽然存在一定的不足,但基本上实现了对结局的初步分析以及对各种指标影响力的判断,有一定的准确性和信服力。
