智能语音助手的知识服务能力评价研究
2019-11-20赵一鸣朱奕蓉吴林容
赵一鸣 朱奕蓉 吴林容
摘 要:文章从基础能力、初级知识服务能力、高级知识服务能力三个方面,筛选出十个二级指标,通过层次分析法确定指标权重,根据智能语音助手现阶段的智力水平,为每个二级指标选取了相应的测试问题,构建了智能语音助手的知识服务能力评价体系,最后以三个主流的智能语音助手为对象进行了实证评价分析。构建的评价指标体系具有实用性和动态性,基础能力的权重最大,初级知识服务能力和高级知识服务能力次之,实证研究的结果表明,现阶段主流的中文智能语音助手已经具备了一定的知识服务能力,但仍然存在较大的提升空间。
关键词:智能语音助手;知识服务;知识服务能力;层次分析法
中图分类号:TP242.6 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2019070
Evaluating the Knowledge Service Capability of Intelligent Voice Assistants
Abstract In this paper, ten secondary indicators are selected from three aspects: basic ability, primary knowledge service ability and advanced knowledge service ability. Then, the index weights of these indicators are determined by analytic hierarchy process. According to the intelligence level of intelligent voice assistant at present stage, the corresponding test questions are selected for each secondary indicator, and the evaluation system of knowledge service ability of intelligent voice assistant is constructed. Finally, three mainstream intelligent voice assistants are evaluated and analyzed by this evaluation system. The evaluation index system constructed in this paper is practical and dynamic, the weight of basic ability is the largest, followed by primary knowledge service ability and advanced knowledge service ability. The empirical results show that the mainstream Chinese intelligent voice assistant has certain degree of knowledge service ability at now, but there is still much room for improvement.
Key words intelligent voice assistant; knowledge service; knowledge service ability; analytic hierarchy process
1 引言
近年來,随着人工智能以及语音识别技术的不断发展,智能语音助手逐渐为人们所熟知。目前国内外比较成功的智能语音助手包括亚马逊Alexa 、谷歌助手Google Assistant、苹果 Siri、微软 Cortana、百度度秘、咪咕灵犀、天猫精灵等。来自前瞻产业研究院的资料显示,在2018年中国智能语音市场的规模已经突破了160亿元[1]。美国市场研究机构Strategy Analytics近日发布的报告也认为,2023年全球将有90%的智能手机拥有智能语音助手[2]。
智能语音助手被广泛应用在医疗健康服务、图书馆服务、知识管理等场景中,而在这些场景下,语音助手均可以视作知识服务主体。它需要根据用户的语音输入内容识别用户多样化需求,再为满足需求获取和加工信息,最后利用内在程序以及一些具体的功能如诗歌创作、知识问答、智能提醒等来反馈信息并提供服务。
目前有关智能语音助手的研究,主要集中在语音助手的设计与优化、语音助手在不同场景中的应用、用户对语音助手智能程度的评价等方面,对于智能语音助手知识服务的相关研究非常匮乏。本研究试图回答以下问题:智能语音助手是否具备一定的知识服务能力?如何评价智能语音助手的知识服务能力?应该从哪些方面提升智能语音助手的知识服务能力?
2 文献综述
2.1 智能语音助手
现阶段智能语音助手的相关研究有许多。一部分研究着眼于拓展智能语音助手在不同场景的应用。如医疗健康领域[3-4]、智能家居应用[5]、自动驾驶领域[6]、或者个人与集体的知识管理领域[7-8]等。另一部分研究则关注智能语音助手的设计与优化。如从语音识别层面、语言表达层面[9]进行分析,或者针对现有的开发方法和逻辑框架进行改进[10]。
还有一些研究,则是将注意力放在了使用智能语音设备的用户身上。有些学者通过设计模型[11]或设置特殊场景[12],分析用户行为来确定用户的满意程度。另一些学者通过爬取用户评论数据、收集用户使用记录等方式,间接获得用户反馈,完成对智能语音助手的评价[13]或对语音助手进行优化设计[14]。也有学者直接通过问卷调查法、访谈法或实验法,得到不同人对语音助手智能程度的主观评价[15]。
2.2 智能产品评价
最著名的测试人工智能是否具有智能的方法是图灵测试[16],通过相互隔离的交谈后是否能准确分辨另一方是人还是计算机,来判断计算机是否具备智能。但是,也有学者质疑了这种人为判断方法的客观性[17]。
对智能產品的定性评测包括:Bringsjord等[18]提出的 Lovelace Test,该测试通过让智能系统创造小说或画作来判定智能系统是否具有人的认知能力;Riedl[19]在Bringsjord研究的基础上设计了一个改良版的Lovelace 2.0 Test,认为如果程序按照要求所创作的内容被判定为合乎逻辑或引发裁判共鸣,那么此人工智能系统就可以被认为具有智能;Malinowski和Fritz[20]通过让测试对象描述图片内容并回答相关常识性问题来进行智能判断;Ohlsson等[21]将针对4-7.25岁孩子的Verbal IQ测试应用在人工智能的智商测定中。
有学者从定量角度对智能产品的智力水平进行评价,如杨强[22]提出“终身学习测试”,通过判断计算机能否通过学习提升知识水平来判断其是否是智能的;刘峰[23]利用德尔菲法对人工智能的智商测量标准进行确定,并提出了定量评测问题,通过设计出的互联网智力评测系统,完成了对全球50个搜索引擎和人类对照组的智商测试。另外,刘峰[24]将人工智能的智商分为通用智商、服务智商和价值智商三类,并针对不同方面的智能,进行了一定程度上的指标区别。
3 智能语音助手的知识服务能力评价体系构建
3.1 评价指标体系构建
知识服务是指以信息知识的搜寻、组织、分析、重组的知识和能力为基础,根据用户的问题和环境,融入用户解决问题的过程中,提出能够有效支持知识应用和知识创新的服务[25]。在此定义的基础上,本研究将智能语音助手的知识服务归纳为三个层次:一是能完成信息的输入与输出,即基础能力;二是对信息知识的搜寻、组织、分析、重组,即初级知识服务能力;三是根据用户问题与环境,给用户提供个性化支持与服务,即高级知识服务能力。这三个层次就成为智能语音助手知识服务能力的一级指标。
在二级指标的选择上,为了保证指标的可信度和代表性, 指标的设置最大限度地借鉴相关研究的成熟量表[23-24,28],结合本研究针对智能语音助手的具体应用情境, 并咨询了相关专家学者来确定最终选择结果。
基础能力下设三个二级指标,分别是识别声音的能力、声音表达的能力和被自动唤醒的能力。其中识别声音能力对应信息获取,声音表达对应知识反馈,而被自动唤醒则是一切知识服务的前提,即语音助手的开关功能。
初级知识服务能力下设三个二级指标,分别是计算、翻译和知识问答能力。一方面,这三项能力指标所代表的功能均在用户的日常生活中被大量使用;另一方面,这三个指标涵盖了数学、语言和各种常识问题,充分反映了智能语音助手获取信息、加工信息的基础能力。
高级知识服务能力下设四个二级指标,分别是知识创造能力、猜测和联想能力、学习能力和个性化服务能力。其中知识创造能力衡量的是语音助手的内容创作力,猜测和联想能力考察语音助手的逻辑,学习能力则是评价语音助手的自主学习能力,而个性化服务能力主要考察语音助手是否能对不同用户提供定制服务。这四个二级指标均体现语音助手对个性化问题与环境(语境)的识别和提供针对性服务的能力。
3.2 基于层次分析法的指标权重确定
本研究运用层次分析法,通过专家经验来衡量各个指标间的相对重要程度,从而确定指标权重。
3.2.1 构建层次结构模型
本研究中的评价层次体系由三个层次组成。目标层为总目标,即智能语音助手知识服务能力,准则层分别为基础能力、初级知识服务能力和高级知识服务能力3个方面,指标层为识别声音的能力、声音表达的能力和被自动唤醒的能力等10个评价指标(见图1)。
3.2.2 问卷设计与发放
考虑到研究对象智能语音助手的特殊性,在指标权重确定的专家人选上,并不局限于学界专家学者,还有业界相关领域的工作人员。为了结果的准确性与客观性,问卷内容分为两个部分:
第一部分为关于专家的基本问题,包括学历、工作单位、使用语音助手频次与种类等。此部分信息用于确定专家对语音助手的了解程度,从而挑选出高质量的问卷样本。
第二部分构造判断矩阵。要求专家依次对从属于上一层某个因素的同层次诸因素用1-9检验值进行两两比较,来确定各因素的重要性。
本研究共发放33份问卷,回收30份,回收率为91%。剔除不符合要求、数据不满足一致性检验的问卷以后,有15份问卷进入到下一步的分析。15份问卷的专家构成中,学界专家有6人,均具有博士学历和副教授以上职称,研究领域为知识服务、人工智能等;业界专家有9人,均来自较知名的通信公司或科技公司(见表1)。
3.2.3 数据处理
将专家数据录入YAAHP 12.1软件(一款针对层次分析法的辅助软件),在对智能语音助手知识服务能力评价指标体系中的各级指标进行进一步分析后,最终得出各指标的权重分配情况(见表2)。
3.3 题库构建
根据智能语音助手知识服务能力的评价指标体系,本研究为各个二级指选取了相应的题目,构建了智能语音助手知识服务能力评价的题库。为保证测试结果的可靠性,题库的来源为相关的书籍、测试以及论文,所选择题目尽量满足代表性与权威性。
3.3.1 基础能力题库构建
基础能力考察的是信息输入与输出能力,不同语音助手的实现方式并不存在差异。针对基础能力下3个对应的二级指标,分别对它们构建题库(见表3)。
识别声音的能力是要了解测试目标能否准确理解语音输入的测试题目,要求从语音中识别出正确的文字。测试题目从2015年国际自然语言处理与中文计算会议提供的问题集中随机选择。
声音表达的能力旨在了解语音助手是否合理回答日常对话,若仅仅是考虑是否能进行语音输出,那么此种标准会过于簡单且无意义。为了获得中文的日常对话内容,查阅了《HSK标准教程1》,该书经国家汉办授权,以汉语水平考试真题作为教学素材。此教程是为了帮助汉语初学者学习汉语日常对话所设计,对本研究相应题库的构建有重要的指导意义。本研究从该书中挑选了多个日常对话场景作为测试题目。
被自动唤醒的能力是要了解测试目标是否能通过声音被自动唤醒。实验方式则是通过多次语音说出触发词,观察语音助手能被自动唤醒的次数。
3.3.2 初级知识服务能力题库构建
初级知识服务能力考察的是语音助手对信息知识的搜寻、组织、分析、重组的能力,不同语音助手的实现方式同样不存在区别。针对初级知识服务能力下相应的3个二级指标,分别构建题库(见表4)。
知识问答能力是为了了解测试目标的知识广度。结合人机对话的相关问题集[26]以及相关论文[27],并适当调整使其符合语音助手应用场景,研究将问题分为事实类问题、定义类问题、YES-NO问题和观点类问题。在题目的选择上,做到四种问题兼顾并同时聚焦在小学阶段的必修科目上,如语文、社会和音乐等。
翻译能力是为了了解测试目标对不同语言的转换能力。题库选择上参考了北京大学的《英汉机器翻译测试大纲》[28],从中选出多个句子,包括重点列出的长难句。
计算能力是为了了解测试目标的计算能力、计算速度和正确性。结合目前语音助手的智能水平,选择小学阶段的数学课程标准“全日制义务教育数学课程标准(实验稿)”作为参考,挑选出其中测试运算能力的指标,包括计算万以内的整数、小数、分数、百分数和负数,和掌握四则运算的技能,并依照此分类选择题目。
3.3.3 高级知识服务能力题库构建
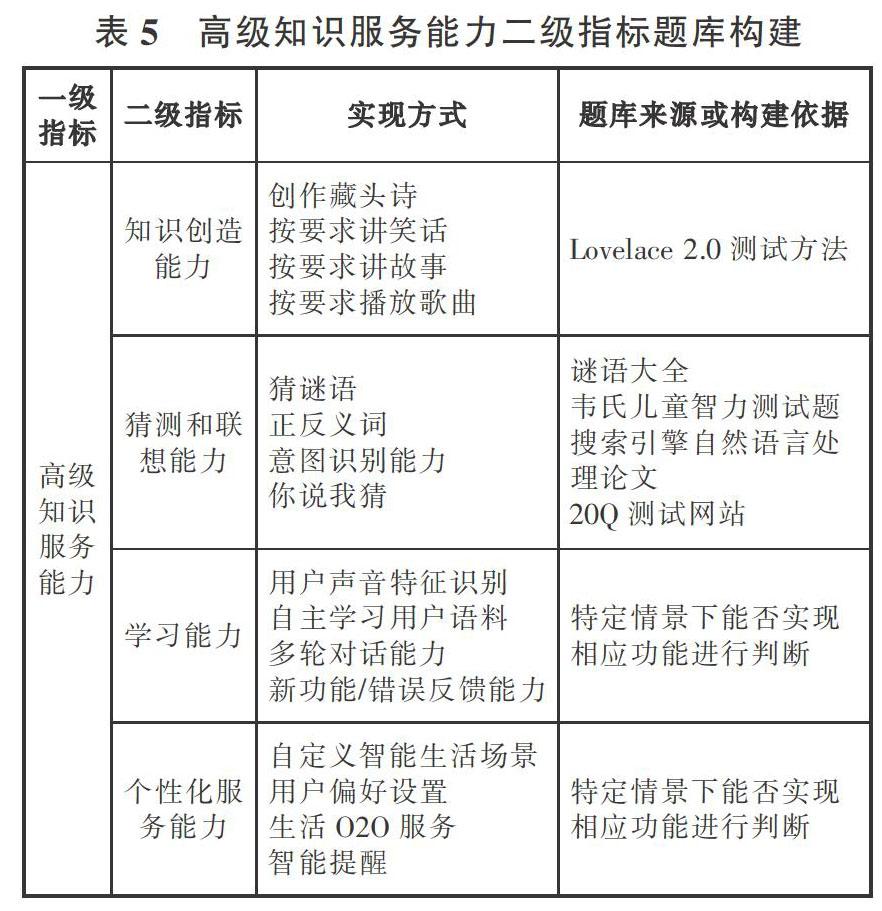
高级知识服务能力,指的是测试目标根据用户的问题与环境在信息收集基础上的创造与服务能力,概念较为抽象,不同语音助手的实现方式多样。为保证实验的准确性与公平性,本研究对常见语音助手进行了深入使用,并结合官网的介绍以及相关测评报道,总结归纳了高级知识服务能力下各个二级指标的实现方式。在全面考虑不同实现方式的前提下构建出相应的题库(见表5)。
知识创造能力是为了了解测试目标按照给定要求,进行二次创造的能力。Mark O. Riedl在语音助手智商测试的实验中提出了Lovelace 2.0[19]测试方法,方法是在创造性活动中添加关键词以增加语音助手直接检索的难度来确定语音助手的知识创造能力。因此,本研究结合现有语音助手功能,对不同创作形式提出不同要求,根据是否能反馈有逻辑的结果来测算语音助手的知识创造能力。
猜测和联想能力是为了了解测试目标根据给定的材料猜测所描绘的事物及联想相关事物的能力。根据上述得分原则,分四类分别构建题库。谜语选自各版本的“谜语大全”。正反义词则来自韦氏儿童智力测试题[29]。对意图识别能力的考量,则是参考了有关搜索引擎自然语音处理的研究结论。用户向搜索引擎输入的简短查询式存在模糊性和歧义性[30],在语音助手应用场景同样适用,所以采取通过语音输入模糊指令来确定其能否准确理解并满足用户要求。你说我猜则是测试语音助手能否通过问用户问题,猜出用户心中所想的一个人物或动物,题库来源于相关娱乐性测试网站。
学习能力是为了了解测试目标能否根据用户训练,掌握新的规则或知识的能力。其测试方法是在不同实现方式下给出特定情景,通过判定语音助手在该情景下能否完成用户要求来确定。如在多轮对话中针对某个话题展开需要联系前后文的多轮讨论,观察语音助手是否能有逻辑的进行回复来判定语音助手的多轮对话能力。
个性化服务能力是为了了解测试目标个性化服务设置能力,测试方法与学习能力类似。如用户偏好设置下就有一个情景为是否能根据用户喜好实现智能推送,根据是否能实现判断该语音助手的用户偏好设置能力。
3.4 测试方法与评分原则
由于语音助手与用户的沟通是以声音为主。因此实验中的所有问题均采用语音方式输入。考虑到具体环境影响,每个问题将重复三次。
在具体给分上,对于语音助手基础能力以及初级知识服务能力下的各个二级指标,每个测量对象均需回答从题库中随机抽取的相同的10道题(其中被自动唤醒的能力是分10次在不同场景下用语音说出触发词)。每答对一题(被自动唤醒一次)加10分。即每个二级指标满分为100分。
对于语音助手高级知识服务能力,如本文所述,每个二级指标实现方式均可归纳为4类。由于存在语音助手能以不止一类实现方式完成对应的二级指标,所以每类满分为25分,若4类实现方式均能完成,则该二级指标记满分100分。在每类实现方式下设置3个具体场景或题目。若3道均正确完成,则认为该类实现方式完成,记该类满分,即25分。若全不能完成,则该类记0分。若能部分完成,则认为该类还有进步空间,记该类满分的一半,即12.5分。
另外,语音助手在实现某些用户要求时,自身虽不具备相应功能,却可以通过调用或跳转到其他应用来获得答案。这虽表现了自身功能的不够全面,但从侧面体现了该语音助手与其他应用的操控与交互能力,所以对这种状况,同样视为能部分完成。
各项指标分数确定后,最后总体评价结果采用广义智商算法[31]:
F = Wi*Vi (1)
在式(1)中,F为该语音助手总积分,Wi为各指标权值,Vi为各指标的测试分。
4 中文智能语音助手的评价实验
4.1 评价对象选择
中文语音助手应用场景多样,在日常生活中最常见的有三种,分别是手机自带语音助手(如苹果的Siri,三星的Bixby,华为的小E、VIVO的jovi等)、移动应用语音助手(如百度语音助手、搜狗语音助手、咪咕灵犀等)、还有随着智能家居不断发展的智能音箱(如天猫精灵、小米AI音箱、小度在家等)。本研究根据网络诸多测评分别选取了这三大类语音助手中最具代表性的一款产品进行评价研究,即华为小E、咪咕灵犀和天猫精灵。
4.2 评价结果
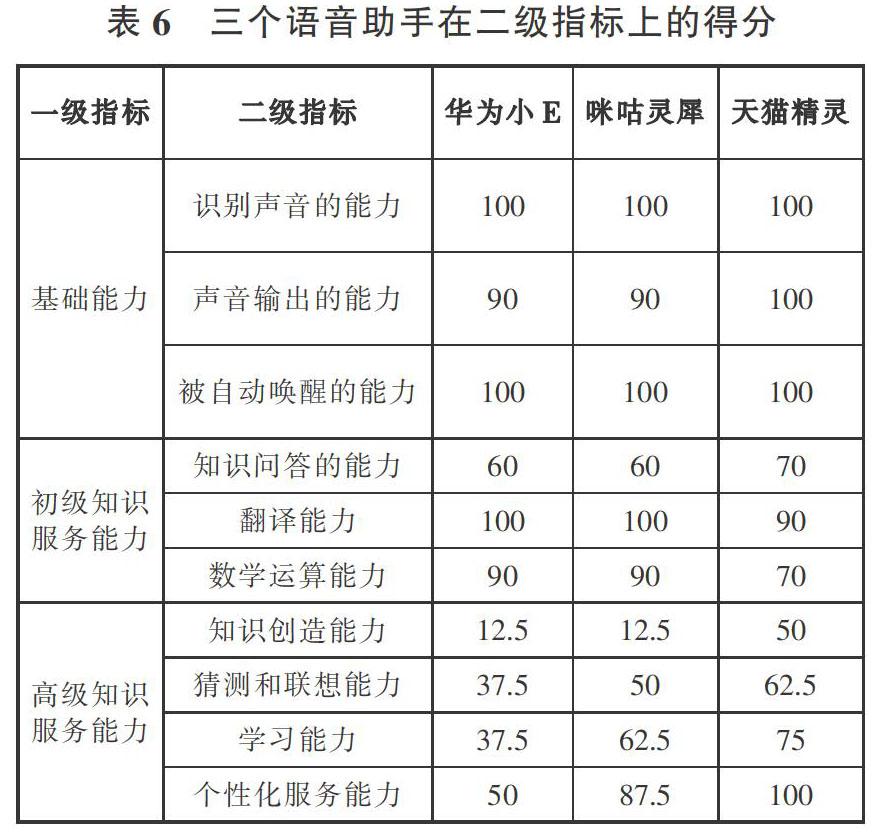
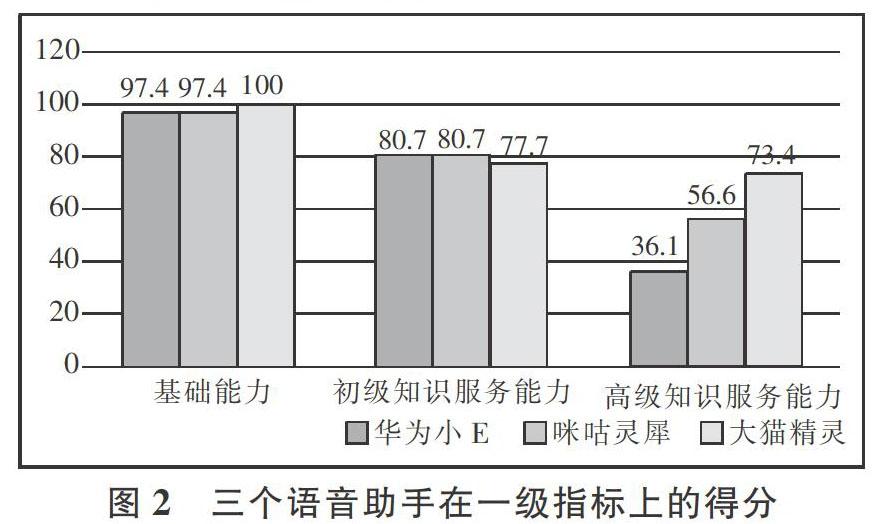
按总得分从高到低排序,天猫精灵、咪咕灵犀和华为小E的知识服务能力得分分别是88.54、85.02、81.24,均超过了80分,说明三个语音助手均具备了一定的知识服务能力。本研究对被测评语音助手各一级指标完成度进行统计(见图2)。
统计得出,在基础能力上,天猫精灵得到了满分,华为小E和咪咕灵犀均得到97.4分;在初级知识服务能力上,华为小E和咪咕灵犀分数亦相同,均为80.7分,而天猫精灵只得了77.7分;在高级知识服务能力上,分数从高到低分别是天猫精灵(73.4分)、咪咕靈犀(56.6分)、华为小E(36.1分),咪咕灵犀和华为小E均低于60分。
可以看出,三个语音助手在总分上的较好表现主要得益于在基础能力指标上的较高得分,该一级指标的权重高达0.52,而三个语音助手在该项得分均接近或等于满分。在初级知识服务能力上三个语音助手得分接近,均在80分左右,表现良好。但在高级知识服务能力上,各语音助手表现具有较大差异且普遍较差。
对三个语音助手在各二级指标的具体得分进行统计(见表6),通过分析可以发现:
(1)三款语音助手在知识问答能力上均有进步空间。华为小E和咪咕灵犀在多数问题回答上均需借助第三方搜索引擎反馈的结果,其中华为小E还需再次按要求输入以完成跳转。天猫精灵则无法回答部分和地理位置相关的问题,如针对问题“广州高铁站在哪里”“埃菲尔铁塔是在巴黎吗”并不能得到结果。
(2)三款语音助手虽然功能丰富,但触发条件往往较为严苛。如必须完整向华为小E输入“讲一个安徒生的海的女儿”才能被理解,否则均无法完成要求。天猫精灵虽在大多数情形下完成的较为出色,但仍在部分场景如“对话训练”或一些指定游戏中,需特定关键词才可以触发。
(3)三款语音助手均可针对用户需求,完成个性化服务,但程度存在差异。如三款语音助手均可从其他信息源获取外卖信息与快递信息,均可设置智能提醒,但在其他方面如个性化回答设置、推送内容设置以及应用偏好选择上,华为小E均要略输一等。
(4)在初级知识服务能力中的翻译与计算指标上,华为小E和咪咕灵犀更为出色。如咪咕灵犀不仅对于本次测试要求的英语表现优异,更可完成对多种语言的精确互译。反观天猫精灵,在计算上目前只支持一千万以内整数的相关运算,分数或超过范围均不能完成,而翻译中部分长难句翻译准确度低。
(5)在诸多信息分析与场景处理能力要求更高的指标中,咪咕灵犀和天猫精灵表现较好,且天猫精灵更胜一筹。如测试语音助手是否能有逻辑的回答日常对话问题时,选择在下午问候“早上好”,天猫精灵与咪咕灵犀会指出现在已经是下午了,而华为小E依然只会回应早上好。在“知识创造能力”的考察中,要求语音助手播放一首周杰伦的励志歌曲,和以“新年快乐”为主题写作一首诗,只有天猫精灵完成要求,而且天猫精灵也是唯一支持多轮对话的语音助手。
4.3 分析与讨论
(1)智能语音助手是否具备知识服务能力?研究结果表明,主流的中文智能语音助手已经具备了一定的知识服务能力。在诸多场景下,语音助手能以声音为交互介质,提供高智力附加值的知识(或技能) 密集型服务,满足知识服务对象的知识需求。
由于语音可以解放人们的双手和双眼,降低产品使用门槛,同时语音识别与语义理解是人工智能领域相对成熟的技术[32],通过语音交互开展知识服务(多轮对话式问答服务、生活场景中的决策支持服务等)是未来的发展趋势,而在这方面,智能语音助手具有天然的优势。
首先语音助手存在潜在的庞大用户群。语音助手多以智能手机为载体,以APP应用、小程序(智能音箱也往往有对应的小程序)、微信公众号等诸多形式为公众提供知识服务。而随着智能手机的普及,语音助手能以较低成本接入大众生活;其次面对日常生活中多元化、多维度的知识需求,语音助手能够为大众提供普惠的知识服务,使知识服务不局限于专业人士,而是嵌入生活化的场景里,降低用户在信息过载时代中知识获取的成本。
(2)如何评价智能语音助手的知识服务能力?本研究构造了智能语音助手知识服务能力的评价指标体系,并应用该体系完成了三款主流语音助手的评价实验。运用该评价指标体系,将抽象的智能语音助手知识服务能力具体化为3个一级指标、10个二级指标,可以综合评价和跟踪语音助手行业的进展,对比不同语音助手之间的具体优劣情况,便于从中及时发现好的发展经验和共同问题所在,明确语音助手的研发方向。
本研究得到的指标权重充分反映了专家的认知。识别声音、声音输出、被自动唤醒所代表的基础能力权重超过0.5,其中识别声音的指标权重更是高达0.2576。而初级、高级知识服务能力指标权重占比低,对语音助手的评价结果影响小。这说明在现阶段,专家更重视基础交互能力,对智能语音助手提供知识服务的期望并不高。
本研究建设了相应题库来完成指标的测量。考虑到现阶段人工智能的智商与儿童的智力水平相当[21],且功能在不断的发展丰富中,在构建题库时,并没有完全按照知识服务的最高标准去设计,而是结合语音助手现有的智能水平与发展演化的需求,设置了相应的测试问题,如声音输出指标的题库选自汉语初学者对话教程,高级知识服务能力的测试总结了现有语音助手能够完成的方式。由于题库构建灵活,未来随着人工智能技术的进步、智能产品智力水平的不断提高以及语音助手领域的迅速发展,测试题库支持不断升级,将在题目选择上上升难度,场景设置上更具随机性与普适性。
(3)应该从哪些方面提升智能语音助手的知识服务能力?从相应指标所占的权重来看,语音助手的基础能力仍然是现阶段专家关注的最重要的方面,也是當前用户感知最强烈的方面。因此,亟需提高智能语音助手的基础能力,如在信息输出端注重合成语音的口语化、自然化、人性化[33],在信息输入端提供可视化反馈,增加用户可控感[34],并辅助其它应用,设计出实现各种拓展功能的接口来增加多种信息的交互能力[35]。
在初级知识服务能力方面,根据人们的一般认知,三个二级指标在技术实现难度上从高到低排序分别是知识问答、翻译和数学运算。三个语音助手在知识问答能力上的得分普遍较低,比较不同种类问题回答准确率之后发现,相比于事实类问题和定义类问题,语音助手往往不擅长回答YES-NO问题和观点类问题,这证明在自然语言处理和知识抽取层面仍有待进一步研发。然而,三个语音助手在数据运算能力上的得分却均高于翻译能力,这一方面是由于部分数学运算超过了语音助手的能力范围,如华为小E和咪咕灵犀不能完成“阶乘”运算、天猫精灵不能完成分数或非整数的计算以及大于一千万的整数的运算;另一方面,这反映了在语音交互的场景下,信息系统(智能语音助手)在知识服务相关任务上的表现有别于传统的图形界面交互场景,这也是未来有待进一步探索的方向。
在高级知识服务能力方面,普遍存在两点问题:一是功能情景有限,二是某些功能触发条件只支持用户输入显式查询或命令,即明确的触发词。这不仅导致用户使用感不佳,也使一些功能不易被用户发现。所以建议在保证不干扰用户生活的前提下,提供更人性化的功能触发条件并配以友好的用户指导。如定期提示用户功能更新及其触发方法,或结合语境情景理解用户的隐式对话线索[10]等。
从搭载语音助手的平台上来看,手机自带语音助手的得分明显落后于语音助手APP和智能音箱,而手机自带语音助手却是广大普通用户最容易接触到的语音助手产品[2],具有庞大的用户群体。提高手机自带语音助手的知识服务能力,有利于知识服务惠及更广泛的社会群体,所以,亟需提高手机自带语音助手的知识服务能力。同时,智能音箱在高级知识服务能力上表现较为优秀,特别是在个性化服务能力指标上的表现最为突出,其与智能家居的进一步关联可有效弥补自身便携性不足的固有缺点,有效推进生活智能化。
5 结语
面对知识服务对象大众化、服务手段多样化、服务内容智能化的时代趋势,社会亟需一个普惠的工具来满足泛在的知识需求、服务大众的日常生活。智能语音助手作为新型知识服务主体,具有填补该空缺的天然优势。
本文对智能语音助手的知识服务能力进行了评价研究。首先,构建了智能语音助手知识服务能力的评价指标体系,通过专家调查得到的指标权重很好地反映了现阶段人们对智能语音助手的期望和态度;其次,根据智能语音助手现阶段的技术水平和智能程度,构建了相应的测试题库,且这一题库可以随着智能语音助手技术水平和智力程度的提高进行动态升级,以保证本研究提出的评价方法具有一定的动态性和灵活性;第三,对典型的中文智能语音助手进行评价实验,发现了目前存在的问题和不足,提出了相应的建议。但本研究仍存在一些不足,如评价指标体系可以进一步完善、专家调查的人数和范围可以进一步扩大等。在后续研究中,将进一步优化智能语音助手知识服务能力的评价指标体系、扩大层次分析法专家调查的规模。
*本文系国家自然科学基金面上项目“探寻式搜索过程中的路径识别与评价研究”(项目编号:71874130)、国家自然科学基金重点国际(地区)合作项目“大数据环境下的知识组织与服务创新研究”(项目编号:71420107026)与中国科协青年人才托举工程和武汉大学青年学者学术团队项目(项目编号:Whu2016013)研究成果之一。
参考文献:
[1] 吴小燕.一文带你了解中国智能语音市场发展情况[EB/OL].[2019-04-21].https://www.qianzhan.com/analyst/detail/220/181011-c90dd13b.html.
[2] UKONAHO V.Smartphones:Global Artificial Intelligence Technologies Forecast:2010 to 2023 [EB/OL].[2019-04-21].https://www.strategyanalytics.com/access-services/devices/mobile-phones/emerging-devices/reports/report-detail/smartphones-global-artificial-intelligence-technologies-forecast-2010-to-2023.
[3] PRADHAN A,MEHTA K,FINDLATER L.“Accessibility came by accident”:use of voice-controlled intelligent personal assistants by people with disabilities[C].Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems.ACM,2018:459.
[4] MORRIS R R,KOUDDOUS K,KSHIRSAGAR R,et al.Towards an artificially empathic conversational agent for mental health applications:System design and user perceptions[J].Journal of medical Internet research,2018,20(6):e10148.
[5] LURIA M,HOFFMAN G,ZUCKERMAN O.Comparing social robot,screen and voice interfaces for smart-home control[C].Proceedings of the 2017 CHI conference on human factors in computing systems.ACM,2017:580-628.
[6] LIN SC,HSU CH,TALAMONTI W,et al.Adasa:A Conversational In-Vehicle Digital Assistant for Advanced Driver Assistance Features[C].The 31st Annual ACM Symposium on User Interface Software and Technology.ACM,2018:531-542.
[7] SAAD U,AFZAL U,EL-ISSAWI A,et al.A model to measure QoE for virtual personal assistant[J].Multimedia Tools and Applications,2017,76(10):12517-12537.
[8] REIS A,PAULINO D,PAREDES H,et al.Using intelligent personal assistants to strengthen the elderliessocial bonds[C].International Conference on Universal Access in Human-Computer Interaction.Springer,Cham,2017:593-602.
[9] MATANI J,GERVAIS P,CALVO M,et al.Matching language and accent in virtual assistant responses[EB/OL].[2019-04-21].https://www.tdcommons.org/dpubs_series/1239.
[10] VTYURINA A,FOURNEY A.Exploring the role of conversational cues in guided task support with virtual assistants[C].Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems.ACM,2018:208.
[11] KISELEVA J,WILLIAMS K,AWADALLAH H A,et al.Predicting user satisfaction with intelligent assistants[C].Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval.ACM,2016:45-54.
[12] MYERS C,FURQAN A,NEBOLSKY J,et al.Patterns for How Users Overcome Obstacles in Voice User Interfaces[C].Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems.ACM,2018:6.
[13] LOPATOVSKA I,RINK K,KNIGHT I,et al.Talk to me:Exploring user interactions with the Amazon Alexa[EB/OL].[2019-04-21].https://doi.org/10.1177/0961000618759414.
[14] PORCHERON M,FISCHER J E,REEVES S,et al.Voice interfaces in everyday life[C].Proceedings of the 2018 CHI conference on human factors in computing systems.ACM,2018:640.
[15] GUZMAN A L.Voices in and of the machine:Source orientation toward mobile virtual assistants[J].Computers in Human Behavior,2019,90:343-350.
[16] MACHINERY C.Computing machinery and intelligence-AM Turing[J].Mind,1950,59(236):433.
[17] DOWE D L,HERN?魣NDEZ-ORALLO J.IQ tests are not for machines,yet[J].Intelligence,2012,2(40):77-81.
[18] BRINGSJORD S,BELLO P,FERRUCCI D.Creativity,the Turing Test,and the(Better)Lovelace Test[J].Minds and Machines,2001,11(1):3-27.
[19] RIEDL M O.The Lovelace 2.0 Test of Artificial Creativity and Intelligence[EB/OL].[2019-04-21].https://arxiv.org/pdf/1410.
6142v1.pdf.
[20] MALINOWSKI M,FRITZ M.Learning smooth pooling reigns for visual recognition[J].Electronic proceedings of the British Machine Vision Conference,2013(2):1-11.
[21] OHLSSON S,SLOAN R H,TUR?魣N G,et al.Measuring an artificial intelligence systems performance on a verbal IQ test for young children[J].Journal of Experimental & Theoretical Artificial Intelligence,2017,29(4):679-693.
[22] YANG Q.Intelligent planning:a decomposition and abstraction based approach[M].Springer Science & Business Media,2012.
[23] 劉峰.基于互联网智商评测算法的搜索引擎智商测试研究[D].北京:北京交通大学,2015.
[24] LIU F,SHI Y,LIU Y.Three IQs of AI Systems and their Testing Methods[EB/OL].[2019-04-21].https://arxiv.org/ftp/arxiv/papers/1712/1712.06440.pdf.
[25] 张晓林.走向知识服务[M].成都:四川大学出版社,2001.
[26] 微软亚洲研究院三角兽科技.了解人机对话—聊天、问答、多轮对话和推荐[EB/OL].[2019-06-16].https://www.jianshu.com/p/cde686e81b15.
[27] 罗玲鑫.基于J2ME的手机常识测试系统的设计与实现[D].成都:电子科技大学,2011.
[28] 俞士汝,段慧明.英汉机器翻译译文质量测试大纲[J].计算机世界,1998(13):10-11.
[29] 林传鼎.韦氏儿童智力量表中国修订本[M].北京:北京师范大学出版社,1986.
[30] 张晓娟.查询意图自动分类与分析[D].武汉:武汉大学,2014.
[31] 刘东,尹怡欣,涂序彦.智能系统的广义智能定性评价之研究[J].计算机科学,2007(1):351-357.
[32] 百度人工智能交互设计院.2019.AI 人工交互趋势研究[EB/OL].[2019-04-21].http://aiid.baidu.com/982/.
[33] BUCK J W,PERUGINI S,NGUYEN T V.Natural Language,Mixed-initiative Personal Assistant Agents[C].Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication.ACM,2018:82.
[34] LURIA M,HOFFMAN G,ZUCKERMAN O.Comparing social robot,screen and voice interfaces for smart-home control[C].Proceedings of the 2017 CHI conference on human factors in computing systems.ACM,2017:580-628.
[35] GHOSH D,FOONG P S,ZHANG S,et al.Assessing the Utility of the System Usability Scale for Evaluating Voice-based User Interfaces[C].Proceedings of the Sixth International Symposium of Chinese CHI.ACM,2018:11-15.
作者简介:赵一鸣,武汉大学信息资源研究中心、武汉大学信息管理学院副教授;朱奕蓉,武汉大学信息管理学院、图书情报国家级实验教学示范中心(武汉大学)本科生;吴林容,武汉大学信息资源研究中心、武汉大学信息管理学院硕士研究生。
收稿日期:2019-05-14;责任编辑:柴若熔;通讯作者:赵一鸣(zhaoyiming@whu.edu.cn)
