面向视觉检测的深度学习图像分类网络及在零部件质量检测中应用
2019-11-16刘桂雄何彬媛吴俊芳林镇秋
刘桂雄 何彬媛 吴俊芳 林镇秋


摘要:基于深度学习图像分类是视觉检测应用的基本任務。该文系统总结基于模型深度化图像分类网络、基于模型轻量化图像分类网络及其他优化网络主要思想、网络结构、实现技术、技术指标、应用场景,指出网络模型深度化、轻量化分别有助于提高图像分类准确性、实时性。最后,面向零部件质量检测需求,应根据其类型多少、结构复杂程度、特征异同等特点,结合实时性要求,选择合适的图像分类网络构建零部件质量智能检测系统。
关键词:图像分类;深度学习;视觉检测;零部件质量检测
中图分类号:TP301.6 文献标志码:A 文章编号:1674-5124(2019)07-0001-10
收稿日期:2019-05-04;收到修改稿日期:2019-06-02
基金项目:广州市产学研重大项目(201802030006);广东省现代几何与力学计量技术重点实验室开放课题(SCMKF201801)
作者简介:刘桂雄(1968-),男,广东揭阳市人,教授,博导,主要从事先进传感与仪器研究。
0 引言
图像分类是根据图像所反映的不同特征信息,确定特定视觉目标类的概率来标记输入图像。它是目标检测、语义分割等的基础模型,是机器视觉检测应用基本任务,是专家学者研究热点之一[1]。图像分类根据颜色、纹理、形状、空间关系等特征将区分不同类别图像,主要流程包括图像预处理、图像特征描述与提取[2]分类器设计与训练[3]、分类结果评价等。通常在图像特征描述与提取前,会进行图像滤波[4]、尺寸归一化[5]等预处理,图像滤波目的在于增强图像中目标与背景对比度,尺寸归一化有助于图像批量特征提取。不同类别的图像特征具有多样性、复杂性,同一类别的图像特征则存在平移、旋转、尺度变换、颜色空间变换等情况。因此,有效的图像特征描述与提取方法应具备类内图像特征不变性描述能力、类间图像特征分辨与提取能力,是图像分类任务的难点。分类器根据所提取图像特征学习的分类函数或构造的分类模型,传统分类器包括逻辑回归[6]、K邻近[7]与决策树[8]等。经典图像分类方法按照上述流程分步进行,最常用方法为基于视觉词袋(bags of visual words,BoW)方法[9],将图像块仿射不变描述符的矢量量化直方图[10]完成图像特征提取,再输入到朴素贝叶斯分类器(naive bayesclassifier,NBC)[11]或支持向量机(support vectormachine,SVM)[12]完成分类。经典图像分类算法所采用特征均为图像底层视觉特征,对具体图像及特定的分类方式针对性不足,对于类别间差异细微、图像干扰严重等问题,其分类精度将大大降低,在复杂场景中经典图像分类方法难以达到好效果。
随着视觉检测技术发展与计算能力巨大提升,深度网络已在图像分类、视觉检测任务上应用与发展。近年来,各种深度学习图像分类方法已经被广泛探讨[13-18]。美国印第安纳大学2007年详细介绍几种主要先进分类方法和提高分类精度的技术,讨论影响分类性能一些重要问题,认为神经网络等非参数分类器成为多元数据分类的重要方法[13]。南京大学2017年从强监督、弱监督两个角度对比不同深度学习算法,讨论深度学习作为图像分类未来研究方向所面对挑战[14]。美国宾夕法尼亚州立大学2018年研究视觉分析与深度学习的图像分类方法,总结图像分类网络经典架构并展望基于深度学习的图像分类方法应用前景[17]。目前基于深度学习图像分类框架的图像识别算法已广泛应用于医疗CT图像诊断[19]、汽车辅助驾驶[20-21]、制造产品质量检测[22-24]等。在复杂多变的工业图像检测环境下,不同图像分类场景具有不同检测需求,如制造零部件质量检测有类内差小[25]、图像对比度低[26]等特点。经典图像分类方法难以满足复杂的工业检测应用要求,深度学习图像分类方法具备特征不变形描述能力、高维特征提取能力,能较好地解决上述问题。
本文系统总结面向视觉检测的深度学习图像分类网络,对比各种基于深度学习的图像分类网络在ILSVRC竞赛ImageNet2012[27]数据集中的分类性能,指出不同分类方法适用的视觉检测任务场景,并结合基于深度学习零部件质量检测技术加以分析与应用。
1 基于视觉检测的深度学习图像分类网络
基于视觉检测的深度学习图像分类网络按模型结构可分为模型深度化图像分类网络[28]、模型轻量化图像分类网络[29],两者区别主要在于使用更深层卷积层以提取深层图像特征还是通过减小网络参数量、存储空间满足工业应用要求[30]。
1.1 图像分类网络性能评价指标
基于深度学习图像分类方法是通过卷积神经网络(convolutional neural networks,CNN)基本模型实现准确分类,由输入层、卷积层、池化层、全连接层、输出层构成[31]。通过多层卷积运算对图像逐层提取特征,获取更高阶的统计数据再通过分类器实现图像多分类。主要通过图像分类准确率与模型复杂度评价深度学习图像分类方法。
在图像分类任务中,通常采用Top-1错误率、Top-5错误率对分类准确率进行评价[31]。Top-1错误率是用预测概率最大那一类作为分类结果,预测结果中概率最大的那个类错误,则认为分类错误,即Top-1错误率代表预测概率最大的那一类不是正确类别的比率;同理,Top-5错误率是用预测概率最大的前5名作为分类结果,前5名中不出现正确类即为分类错误,即Top-5错误率代表预测概率最大的5个类别中不包含正确类别的比率。
模型复杂度主要由时间复杂度、空间复杂度组成。时间复杂度决定模型的训练、预测时间,如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速地验证模型构建方案、改善模型,也难以实现实时预测。空间复杂度主要由CNN结构决定,CNN规模越大,模型参数越多,训练模型所需的数据量就越大,在提高图像特征提取能力的同时,也会占用更多运算空间且易导致数据过拟合问题[32]。随着硬件水平以及计算能力的快速发展,已经开始研究模型复杂度对训练和预测的影响问题,如应用到一些对实时性要求高的项目中,需要研究更轻量化的网络。时间复杂度可以通过浮点运算次数(floating-point operations,FLOPS)计算,即:
空间复杂度由网络各层卷积核参数、输出特征图参数共同决定,即:式中:M——每个卷积核输出特征图尺寸;
K——每个卷积核尺寸;
Cl——第l个卷积层卷积核个数;
Cl-1——第l-1个卷积层卷积核个数;
D——网络层数。
1.2 基于模型深度化的图像分类网络
基于网络深度化的图像分类模型是通过增加网络深度提高图像特征提取与表征能力,融合颜色、形状等低层特征和语义特征等高层特征,在高特征维度中将不同类别图像分离开来,提升图像分类效果。
1)AlexNet
Alex Krizhevsky等[33]2012年设计出深层卷积神经网络AlexNet,AlexNet是具有历史意义的网络结构,在其被提出之后,更多更深的神经网络被提出,并成为图像分类方法的基础网络模型。图1为AlexNet模型网络结构图,整体结构分为上下两个部分的网络,分别对应两个GPU(特定的网络层需要两块GPU进行交互以提高運算效率)。以一个GPU为例,网络总共的层数为8层,包括5层卷积和3层全连接层,将224×224×3图像输入到第一层卷积层,每一层卷积层的输出作为下一层卷积层的输入,经过5层卷积层后输入到全连接层,每一层全连接层神经元个数为4096,最终由softmax分类器输出图像在1000类别预测中的分类概率。
AlexNet通过多层网络实现深层次图像特征提取以完成分类任务,较传统方法分类准确率有很大提高,且通用性强。AlexNet每层使用线性整流函数(rectified linear unit,ReLU)作为激活函数,因其梯度下降速度更快,使得训练模型所需的迭代次数大大降低,同时使用随机失活(dropout)操作,在一定程度上避免因训练产生的过拟合现象,计算量大大降低。在ILSVRC2012竞赛中AlexNet夺得冠军,其准确率远超第二名(Top-5错误率为15.4%,第二名为26.2%),但受限于当时计算性能,AlexNet在网络深度、特征提取效果上未能达到最理想水平。
2)ZFNet
纽约大学Matthew Zeiler等[34]2013年在AlexNet基础上进行微小改进从而设计出ZFNet网络,提出图像反卷积方法实现卷积特征可视化,证明浅层网络学习到的是图像边缘、颜色和纹理特征,而深层网络学习到的是图像抽象特征,指出网络有效原因与性能提升方法。图2为ZFNet网络结构图,ZFNet基本保留AlexNet骨干结构,由于AlexNet第一层卷积核尺寸、步长过大,提取的特征混杂大量高频与低频信息而缺少中频信息,故ZFNet将第1层卷积核的大小由11×11调整为7×7,步长(stride)从4改为2。
ZFNet设计反卷积网络实现卷积特征可视化,发现第一层的卷积核对特征提取影响大,提出第一层卷积核进行规范化方法,如果RMS(root meansquare)超过0.1,就把卷积核的均方根固定为0.1。同时,ZFNet论证更深网络模型在图像平移、旋转等条件下分类鲁棒性更好,层次越高的特征图,其特征不变性越强。ZFNet是ILSVRC2013分类任务冠军,Top-5错误率为14.7%。ZFNet以实践方法展示网络不同层级的特征提取结果与性能,但没有从理论角度解释网络原理与设计规则。
3)VGGNet
针对AlexNet的大卷积核问题,牛津大学计算机视觉组和Google DeepMind项目研究员共同探索卷积神经网络深度与其性能之间的关系[35],提出用若干较小尺寸卷积核代替大尺寸卷积核,能够有效提高特征提取能力,从而提升图像分类准确性。Karen Simonyan等[36]2014年提出VGG网络模型,其将卷积神经网络深度推广至16~19层,以VGG16为例,图3为VGG16网络结构图,图像输入后经过第一段卷积网络,包括两个卷积层与一个最大池化层后输出,再进入与第一段结构相同的第二段卷积网络,之后通过反复堆叠的3×3小型卷积核和2x2最大池化层,最后通过全连接层输出到softmax分类器。
VGGNet在AlexNet基础上采用多个小卷积核代替大卷积核,增强图像特征非线性表达能力、减少模型参数。如一个7×7卷积核可看作是3层3x3卷积核的叠加,但一个7×7卷积核有49个模型参数,只能提供一层特征图像、一种感受野,而3层3x3卷积核只有27个模型参数,提供3层不同尺度下的特征图像。VGGNet是ILSVRC2014竞赛的亚军,在Top-5中取得6.8%的错误率,VGGNet表明增加网络层数有利于提高图像分类的准确度,但过多层数会产生网络退化问题[37],影响检测结果,最终VGGNet的层数确定在16层和19层两个版本。同时由于网络层数过多而造成参数过多,会使得模型在不够复杂的数据上倾向于过拟合。
4)GoogLeNet
AlexNet与VGGNet均从增加网络深度来提取不同尺度下图像特征进而提高图像分类性能,而Szegedy C等[38]2015年提出的GoogLeNet模型除考虑深度问题,还采用模块化结构(Inception结构)方便模型的增添与修改。GoogLeNet将全连接甚至是卷积中的局部连接,全部替换为稀疏连接以达到减少参数的目的。图4为Inception v1结构结构图,该模块共有4个分支,第一个分支对输入进行1×1卷积,它可以降低维度、减少计算瓶颈、跨通道组织信息,从而提高网络的表达能力;第二个分支先使用1×1卷积,然后连接3×3卷积,相当于进行了两次特征变换;第三个分支先是1×1的卷积,然后连接5×5卷积;最后一个分支则是3×3最大池化后直接使用1×1卷积。
GoogLeNet最大特点是引入Inception结构,优势是控制计算量和参数量的同时,也具有非常好的分类性能。Inception结构中间层接另两条分支来利用中间层的特征增加梯度回传,使得其参数量仅为Alexnet的1/12,模型计算量大大减小;其次网络最后采用平均池化(average pooling)来代替全连接层将准确率提高0.6%,图像分类精度上升到一个新的台阶。Inception模块提取3种不同尺度特征,既有较为宏观的特征又有较为微观的特征,增加特征多样性,Top-5错误率为6.67%。 GoogLeNet网络虽然在减少参数量上做出一定贡献,但大参数量仍限制其在工业上应用。
5)ResNet
为了解决网络层数过多而造成梯度弥散或梯度爆炸问题,Kaiming He等[39,2016年提出ResNet(residual neural network)网络,通过残差块模型解决“退化”问题,该模型是ILSVRC 2015冠军网络。ResNet提出的残差块(residual block)结构主要思想是在网络中增加直连通道,即高速路神经网络(highwaynetwork)思想。图5为ResNet网络结构图,图像输人后,维度匹配的跳跃连接(short connection)为实线,反之为虚线,维度不匹配时,可选择两种同等映射方式:直接通过补零来增加维度、乘以W矩阵投影到新的空间,使得理论上网络一直处于最优状态,性能不会随着深度增加而降低。
当模型变复杂时,会出现准确率达到饱和后迅速下降产生更高训练误差、随机梯度下降(stochasticgradient descent,SGD)优化变得更加困难等现象。Residual结构用于解决上述问题,使得网络模型深度在很大范围内不受限制(目前可达到1000层以上),ResNetTop-5错误率为4.49%,同时参数量比VGGNet低,效果非常突出。ResNet是目前深度化模型代表,但是深度化使得网络庞大,所占存储空间更多。
综合以上分析,基于模型深度化图像分类网络采用增加网络层数提高图像特征提取效果,引入残差块模型解决层数过多带来的“退化”问题,提取并融合深层网络图像抽象特征与浅层网络图像边缘、颜色和纹理特征,有效提高图像分类高准确率,但网络深度化模型复杂、占用空间大,适合用于图像特征复杂、图像分类实时性要求不高的场合。
1.3 基于模型轻量化的图像分类网络
与图像分类网络深度化方法不同,基于模型轻量化的图像分类网络主要是解决模型存储问题和模型预测速度问题,使得图像分类网络兼顾分类准确率的同时提高效率,实现分类网络移动端应用。图像分类轻量化方法有对参数和激活函数进行量化以减少占用空间、设计更高效的特征提取方式和网络结构等。
1)ShuffleNet
ShuffleNet网络是由Face++团队Zhang X等2017年提出的轻量化网络结构,其主要思路是使用点态组卷积层(group convolution,Gconv)与通道混合(channel shuffle)来减少模型使用的参数量[40]。图6为ShuffleNet网络结构图,在ResNet基础上将1×1卷积核换成1×1Gconv,其次在第一个1×1Gconv之后增加1个通道混合以实现分组卷积信息交换,最后在旁路增加平均池化层,以减小特征图分辨率带来的信息损失。
ShuffleNet采用ResNet的思想,在提取图像深层次特征同时通过减少模型参数量实现卷积层信息交换。在ImageNet 2012数据集上时间复杂度为38 MFLOPs,但通道混合在工程实现时会占用大量内存及出现指针跳转而导致耗时。
2)DenseNet
Gao H等[41]2017年通过脱离加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从图像特征角度提出DenseNet网络。DenseNet网络通过特征重用和旁路设置,减少网络参数量及在一定程度上缓解梯度消失问题产生。图7为DenseNet网络构图,第i层输入不仅与i-1层输出相关,还有之前所有层输出有关,对于一个L层网络,DenseNet共包含L×(L+1)12个连接,相比ResNet,这是一种密集连接,而且DenseNet是直接连接来自不同层特征图,能够实现特征重用与融合。
DenseNet作为另一种有较深层数的卷积神经网络,具有如下特点:相比ResNet参数数量更少;通过旁路加强特征重用与新特征提取;网络更易于训练,并有一定正则效果;缓解梯度消失与模型退化问题。250层DenseNet参数大小仅为15.3MB,在ImageNet 2012数据集中Top-5错误率为529%。
3)MobileNet v2
Sandler M等[42]2018年研究更高效的网络结构MobileNet v2,以深度可分离的卷积作为高效的构建块,提出倒置残差结构(inverted residual structure,IRS),提高梯度在乘数层上传播能力、内存效率。图8为MobileNet v2倒置残差结构图,方块的高度代表通道数,中间的深度卷积较宽,先使1×1卷积层升维,再使用3X3卷积层ReLU对特征滤波,最后用1×1卷积层+ReLU对特征再降维,呈现倒立状态,理论上保持所有必要信息不丢失,获得更优精确度。
MobileNet v2网络在参数为MobileNet v170%的情况下减少两倍运算数量,在Google Pixel手机上测试结果比MobileNet v1快30%~40%。该网络能保持类似精度条件下显著减少模型参数和计算量,使得实时性与精度得到较好平衡。
基于模型轻量化的图像分类网络突破深层化网络模型复杂度高、网络退化的问题,通过设计更高效的卷积方式以减少网络参数、自动化神经架构搜索网络优化計算效率而不损失网络性能,使得图像分类网络实现工业检测或移动端的实时应用。
1.4 其他分类网络
除基于模型深度化、轻量化的图像分类网络外,一些图像分类网络通过多模型融合进一步降低模型复杂度、提高模型分类准确性。
1)Inception v2、v4
Szegedy C 2017年在Inception v1基础上研究,指出利用中间层特征增加梯度回传可以提取多层图像特征,但没有真正解决大参数量导致训练速度问题。Szegedy C等[43],在 Inception v2中提出BN(batch normalization)在用于神经网络某层时会对每一个小批量数据内部进行标准化处理,使输出规范化到N(0,1)正态分布,减少内部神经元分布的改变,使得大型卷积网络训练速度加快很多倍,同时收敛后分类准确率也可以得到大幅提高,一定程度上可以不使用dropout降低收敛速度的方法,却起到正则化作用,提高模型泛化性。Inception v4将Inception模块结合残差连接(residual connection),极大地加速训练,同时极大提升性能[44]。
2)DPN
多模型融合通过结合多个网络优势提高图像分类网络性能。Chen Y等[45]2017年提出DPN(dualpath networks)融合ResNet与DenseNet的核心思想,利用分组操作使得DPN模型、计算量更小,训练速度更快。DPN结合ResNet特征重用与DenseNet提取新特征优势,通过双路径网络共享公共特性,同时保持双路径体系结构探索新特性的灵活性,DPN在ImageNet数据集上达到与ResNet-101相当的分类效果基础上,其模型尺寸、计算成本、内存消耗仅为后者的26%、25%、8%。
表1为各种图像分类网络性能对比表。可以看出,基于模型深度化、宽度化的图像分类网络分别在分类准确率、模型复杂度性能上表现优异,在工业应用中,应根据应用场景、任务要求选择图像分类网络。
2 图像分类网络在零部件质量检测中应用
零部件质量图像检测过程中,首先对获取的零部件装配图像进行特征提取,其次根据零部件类型、缺陷等进行分类识别,最后根据零部件图像分类结果完成质量评价。结合零部件质量检测应用需求,发挥图像分类网络在特征提取、识别分类中的优势,能够有效完成零部件图像特征提取、零部件质量检测任务[46-47]。
2.1 零部件图像特征提取
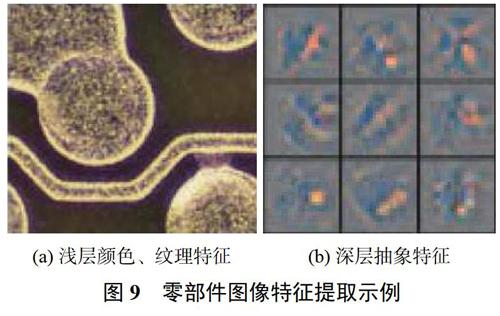
图像特征提取是分类的基础。在零部件质量检测过程中,由于零部件种类各异,不同零部件图像有不同特点,需根据具体检测对象选择合适的特征提取网络,进而完成质量检测任务。传统零部件图像特征提取采用提取图像角点特征实现图像分类。郭雪梅等[48]2017年提出面向标准件装配质量的PI-SURF检测区域划分技术,利用SURF(speeded-uprobust features)提取特征描述感兴趣点,实现机箱装配标准件分类;黄坚等[49]2017年分析Harris、Shi-Tomasi、Fast方法角点特征提取机理与判定条件,提出多角点结合的机箱标准件图像特征提取方法。图9为零件图像特征提取示例,传统图像特征提取方法能够很好地学习零部件颜色、纹理等特征,在类型差异大、颜色对比鲜明的零部件特征提取效果较好,但对对比度低、类内差小零部件则需要提取其深层抽象特征。
深度学习图像分类网络能从浅层网络提取图像边缘、颜色和纹理特征,从深层网络提取图像抽象特征。李宜汀等[50]2019年提出基于Faster R-CNN(faster regions with convolutional neural network)的缺陷检测方法,提取零件图像稀疏滤波与VGG-16双重深度特征,实现零件缺陷分类。基于模型深度化的图像分类网络能够满足多层图像特征提取要求,分类准确性高。
2.2 零部件质量检测
根据图像分类网络提取的图像特征,网络完成零部件分类识别,结合零部件质量评价标准完成零部件质量检测。Deng等[51]2018年提出PCB自动缺陷检测系统,通过深度神经网络完成缺陷分类,降低PCB缺陷检测的误检率与漏检率。笔者团队前期研究机箱装配质量智能检测方法[52],目前正在研究基于深度学习图像分类网络在机箱装配质量检测应用,图10为机箱装配零部件质量检测流程图,待测机箱装配图像输入后通过CNN网络进行零部件特征提取,根据各层提取信息完成零部件分类,最后结合制定的装配标准实现机箱装配质量检测。
零部件质量检测首先提取图像浅层及深层特征;其次利用分类器对零部件分类,分类有时需满足检测具体要求,如有无缺陷、遮挡等;最后根据质量评价标准对分类结果做出评判。零部件质量检测属于对象复杂、特征多的图像识别检测任务,且需要满足一定实时性要求,应选择网络层数较深且模型复杂度较小的网络以满足其准确性和实时性。
3 结束语
图像分类是机器视觉检测应用的基本任务,根据网络模型特点可分为深度化图像分类网络、轻量化图像类网络和其他改进网络。基于深度学习图像分类网络广泛应用于零部件质量检测领域,总结如下:
1)基于模型深度化图像分类网络采用增加网络层数,提取深层网络图像抽象特征与浅层网络图像边缘、颜色和纹理特征,实现图像分类高准确率。深度化图像分类网络特点是分类准确性高,适合用于图像特征复杂的检测任务。
2)基于模型轻量化图像分类网络突破深层化网络瓶颈问题——网络退化、模型复杂度高,通过设计更高效的卷积方式以减少网络参数、自动化神经架构搜索网络优化计算效率而不损失网络性能,适用于实时工业检测或移动端。
3)一些图像分类网络通过多模型融合方法,发挥不同网络在不同层级图像特征提取优势,结合参数量小、计算速度快优点,进一步降低模型复杂度,提高模型分类准确性。
4)零部件质量检测任务包括零部件图像特征提取、零部件分类识别、结合质量评价标准的零部件质量评价。应用过程中应根据零部件类型復杂、特征多等特点,结合实时性要求,构建零部件质量智能检测系统。
参考文献
[1]FREEMAN W T,ADELSON E H.The design and use ofsteerable filters[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,1991(9):891-906.
[2]ZHANG D,LIU B,SUN C,et al.Learning the classifiercombination for image classification[J].Journal ofComputers,2011,6(8):1756-1763.
[3]BAY H,TUYT].,AARS T,VAN G L.Surf:Speeded uprobust features[C]//Springer.European Conference onComputer Vision,2006:404-417.
[4]ITTI L,KOCH C,NIEBUR E.A model of saliency-basedvisual attention for rapid scene analysis[J].IEEE Transactionson Pattern Analysis&Machine Intelligence,1998(11):1254-1259.
[5]GUO Y,LIU Y,OERLEMANS A,et al.Deep learning forvisual understanding:A review[J].Neurocomputing,2016,187(C):27-48.
[6]MENAR]]S.Applied logistic regression analysis[M].London:Sage Publications,2002:61-80.
[7]AMATO G,FALCHI F.OnkNN classification and localfeature based image similarity functions[C]//InternationalConference on Agents and Artificial Intelligence,2011:224-239.
[8]BREIMAN L.Random forests[J].Machine Learning,2001,45(1):5-32.
[9]BAY H,ESS A,TUYTELAARS T,et al.Speeded-up robustfeatures(SURF)[J].Computer Vision and ImageUnderstanding,2008,110(3):346-359.
[10]DENIZ O,BUENO G,SALHDO J,et al.Face recognitionusing histograms of oriented gradients[J].Pattern RecognitionLetters,2011,32(12):1598-1603.
[11]MARON M E,KUHNS J L.On relevance,probabilisticindexing and information retrieval[J].Journal of the ACM(JACM),1960,7(3):216-244.
[12]JOACHIMS T.Making large-scale SVM learning practical[R].Universitat Dortmund,1998.
[13]LU D,WENG Q.A survey of image classification methodsand techniques for improving classification performance[J].International Journal of Remote Sensing,2007,28(5):823-870.
[14]羅建豪,昊建鑫.基于深度卷积特征的细粒度图像分类研究综述[J].自动化学报,2017,43(8):1306-1318.
[15]RAWAT W,WANG Z.Deep convolutional neural networksfor image classification:A comprehensive review[J].NeuralComputation,2017,29(9):2352-2449.
[16]杨真真,匡楠,范露,等.基于卷积神经网络的图像分类算法综述[J].信号处理,2018,34(12):1474-1489.
[17]YANG L P,MACEACHREN A,MITRA P,et al.Visually-enabled active deep learning for(geo)text and imageclassification:a review[J].ISPRS International Journal ofGeo-Information,2018,7(2):65-103.
[18]田萱,王亮,丁琪.基于深度学习的图像语义分割方法综述[J].软件学报,2019(2):440-468.
[19]LIU X,HOU F,QIN H,et al.Multi-view multi-scale CNNsfor lung nodule type classification from CT images[J].PatternRecognition,2018,77:262-275.
[20]TONUTTI M,RUFFALDI E,CATTANEO A,et al.Robustand subject-independent driving manoeuver anticipationthrough Domain-Adversarial Recurrent Neural Networks[J].Robotics and Autonomous Systems,2019,115:162-173.
[21]李云鹏,侯凌燕,王超.基于YOLOv3的自动驾驶中运动目标检测[J].计算机工程与设计,2019(4):1139-1144.
[22]马晓云,朱丹,金晨,等.基于改进Faster R-CNN的子弹外观缺陷检测[J/OL].激光与光电子学进展:1-14[20]9-05-04].http://kns.cnki.net/kcms/detail/31.1690.TN.20190308.1705.004.html.
[23]常海濤,苟军年,李晓梅.Faster R-CNN在工业CT图像缺陷检测中的应用[J].中国图象图形学报,2018,23(7):1061-1071.
[24]IWAHORI Y,TAKADA Y,SHINA T,et al.DefectClassification of Electronic Board Using Dense SIFT andCNN[J].Procedia Computer Science,2018,126:1673-1682.
[25]赵浩如,张永,刘国柱.基于RPN与B-CNN的细粒度图像分类算法研究[J].计算机应用与软件,2019,36(3):210-213,264.
[26]王陈光,王晋疆,赵显庭.低对比度图像特征点提取与匹配
[J].半导体光电,2017,38(6):888-892,897.
[27]RUSSAKOVSKY O,DENG J,SU H,et al.Imagenet largescale visual recognition challenge[J].International Journal ofComputer Vision,2015,115(3):211-252.
[28]REDMON J,DIVVALA S,GIRSHICK R,et al.You onlylook once:Unified,real-time object detection[C]//Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition,2016:779-788.
[29]LAW H,DENG J.Cornernet:Detecting objects as pairedkeypoints[C]//Proceedings of the European Conference onComputer Vision(ECCV),2018:734-750.
[30]CHOLLET F.Xception:Deep learning with depthwiseseparable convolutions[C]//Proceedings of the IEEEconference on computer vision and pattern recognition,2017:1251-1258.
[31]JIA Y,SHELHAMER E,DONAHUE J,et al.Caffe:Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference onMultimedia,2014:675-678.
[32]HE K,SUN J.Convolutional neural networks at constrainedtime cost[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2015:5353-5360.
[33]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenetclassification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012:1097-1105.
[34]ZEILER M D,FERGUS R.Visualizing and understandingconvolutional networks[C]//European Conference on ComputerVision,2013:818-833.
[35]LIN T Y,MAR S.Visualizing and understanding deep texturerepresentations[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2016:2791-2799.
[36]SIMONYAN K,ZISSERMAN A.Very deep convolutionalnetworks for large-scale image recognition[C]// 2015International Conference on Learning Representations,2015:1-14.
[37]BENGIO Y,SIMARD P,FRASCONI P.Learning long-termdependencies with gradient descent is difficult[J].IEEETransactions on Neural Networks,1994,5(2):157-166.
[38]SZEGEDY C,LIU W,JIA Y,et al.Going deeper withconvolutions[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2015.
[39]HE K,ZHANG X,REN S,et al.Deep residual learning forimage recognition[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2016:770-778.
[40]ZHANG X,ZHOU X,LIN M,et al.Shufflenet:An extremelyefficient convolutional neural network for mobiledevices[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition,2018:6848-6856.
[41]HUANG G,LIU Z,VAN DER MAATEN L,et al.Denselyconnected convolutional networks[C]//Proceedings of theIEEE Conference on Computer Vision and PatternRecognition,2017.
[42]SANDLER M,HOWARD A,ZHU M,et al.Mobilenetd2:Inverted residuals and linear bottlenecks[C]//Proceedings ofthe IEEE Conference on Computer Vision and PatternRecognition,2018:4510-4520.
[43]IOFFE S,SZEGEDY C.Batch normalization:Acceleratingdeep network training by reducing internal covariateshift[C]//International Conference on Machine Learning,2015:448-456.
[44]SZEGEDY C,IOFFE S,VANHOUCKE V,et al.Inception-v4,inception-resnet and the impact of residual connections onlearning[C]//Thirty-First AAAI Conference on ArtificialIntelligence,2017.
[45]CHEN Y,LI J,XIAO H,et al.Dual path networks[C]//Advances in Neural Information Processing Systems,2017:4467-4475.
[46]TAO X,ZHANG D,MA W,et al.Automatic metallic surfacedefect detection and recognition with convolutional neuralnetworks[J].Applied Sciences,2018,8(9):1575.
[47]SHIPWAY N J,BARDEN T J,HUTHWAITE P,et al.Automated defect detection for fluorescent penetrantinspection using random forest[J].NDT&E International,2019,101:113-123.
[48]郭雪梅,劉桂雄,黄坚,等.面向标准件装配质量的PI-SURF检测区域划分技术[J].中国测试,2017,43(8):101-105.
[49]黄坚,刘桂雄,林镇秋.基于多角点结合的机箱标准件图像特征提取方法[J].中国测试,2017,43(9):123-127.
[50]李宜汀,谢庆生,黄海松,等.基于Faster R-CNN的表面缺陷检测方法研究[J/OL].计算机集成制造系统:1-19[2019-05-04].http://kns.cnki.net/kcms/detail/11.5946.tp.20190110.1415.002.html.
[51]DENG Y S,LUO A C,DAI M J.Building an AutomaticDefect Verification System Using Deep Neural Network forPCB Defect Classification[C]//2018 4th InternationalConference on Frontiers of Signal Processing(ICFSP),2018.
[52]何彬媛,黄坚,刘桂雄,等.面向机箱标准件装配质量局部特征的智能检测技术[J].中国测试,2019,45(3):18-23.
(编辑:李刚)
