基于高低阶特征交叉的校园课程推荐系统研究
2019-11-16冉昊玺
冉昊玺
摘 要 推荐系统是利用用户的相关特征进行的相关物品推荐,大多应用于商业,展现了不凡的效果。针对当前高 校存在的课程种类繁多、学生选课困难、教学资源浪费等现象,本文迁移商业中的类似人群拓展思想,提出校园课程 推荐系统,并充分利用因子分解机和多层感知机,实现了低阶和高阶的特征交叉,达到了更佳的推荐效果,从而改善 了教学资源利用率,提高了学生的选课兴趣。
关键词 推荐系统 神经网络 因子分解机 在线选课
中图分类号:G645 文献标识码:A
0引言
推荐系统原是电子商务网站通过用户对象的相关信息,为其提供相应的商品信息和建议,并帮助用户实现商品 购买的决策,其中的个性化主要通过用户属性和其兴趣来体现。随着推荐系统在商业中的巨大成功,推荐系统也不断 受到数据挖掘界的重视和深入研究,已经形成了一套相对成熟的科学方法,并应用到了实践中。
随着校园各类型的课程不断增加,学生选到并不适合自己的课程的可能性也随之增高,并且学生因掌握了较少的 课程信息而无法在五花八门的课程中找到最佳的选择。与此同时,学校在课程资源上也造成了相应的损失。由于学生 对于选课的“失误”可能性较高,很多课程因此被埋没或被过高的追捧。比如,一个课程仅仅因为学长单方面的推荐而使 得某一课程有大量的学生选择而使得课程爆满,许多真正适合这一课程的学生无法选到,而另一些并不适合这一课程 的学生进入了这一课程而从此陷入了痛苦中。这一系列的选课不均衡现象反映了学生在时间和精力的浪费,同时,学 校宝贵的教学资源也因此大量浪费。这一切原因,可以归结为学生无处获取很好地选课指导。
针对这一问题,我借鉴了电子商务中的推荐系统,并提出了课程推荐系统(Curriculum Recommendation System, 此后简写为 CRS)将此类问题近似看做一个 click-through-rate 问题,具体来说则是针对是否選择某一课程的二分类 问题,借鉴了 2018 年的腾讯算法大赛,将其中涉及到的问题–类似人群拓展(lookalike)进行了迁移。类似人群拓展 的目标是利用广告主已有的消费者,找出和已有消费者相似的潜在消费者,以此拓展业务。本文中提出的 CRS 系统也 是利用了这一想法,通过某一课程已参与的学生群体作为种子群体(广告行业亦称作种子包),找出和这类群体类似的 学生群体(广告行业亦称作扩展人群),并在他们的个人学生教务管理主页进行课程的推荐。
在模型设计时,考虑到这一问题设计到的特征的多样性和复杂性,需要大规模的特征交叉,于是本文参考了适合 于大规模数据的梯度提升树方法,以及在高阶特征交叉问题中效果显著的神经网络 和在低阶问题 中可以较快的实现大量数据的特征交叉的因子分解机。另外,对于大量的特征,本文在特征选择上则是借鉴了 LightGBM 算法的重要性分析,对重要性指标较高的特征进行了保留。由于数据集存在大量非实数特征,本文采用了 独热和 embedding 的联合方法,实现了由非实数值向实数值的转化以及数据分布的降维。
1特征工程
1.1特征构造
在特征构造这个阶段主要是进行对长度特征的构造。其中涉及到的特征主要为向量特征,如学生信息的历史课程 特征和教师信息中的历史教学课程特征。长度特征即为将特征中的向量的长度进行统计。
另外,对于离散化特征,则是通过神经网络中的 embedding 层进行模型可以进行计算的形式。
1.2特征提取
在特征提取阶段,本文主要是针对业务逻辑和经验,对一些特殊的特征进行了提取。对于选课信息中的选课时间, 可从中提取两个特征。先进行时间范围的划分。出于实际考虑,选课阶段分为预选、正选、不推选三个阶段,我们将 选课阶段提取出来构造为一个离散型特征。此外,在每个阶段的时间也有所不同,在每个阶段选课时间的分布会随着 天数的增加而不断下降,形成一个类长尾分布,并且选课时间只是在一天的一个固定时间段进行(例如 10:00am - 6: 00pm),因此我们可以将某一天的某一个小时内的时间作为一个数值,在这个时段内的时间均为这个数值,从而形成 一个数值型特征。这样我们便得到了选课时段和选课具体时间两个特征。而对于选课年份,我们也同样需要进行保留。
对于学生信息中的 id,同样可以进行特征的提取。由于学号的特殊性,我们可以从中获得学生的年级,所在学院 及专业,编号等信息,其思想较为简单,这里不再赘述。需注意一点,这些提取特征均为离散型特征。
1.3特征选择
当前的特征相对较少,但是当特征的不断挖掘,亦或是实际计算环境对于数据量的限制较高时,大量的特征由于 计算时间过长,并不能较好的达到工程上对于的需求,因此,在这里需要对特征进行筛选,亦即特征选择。
本文主要利用的是 GDBT 算法实现的特征重要性分析,较为便利的工具是开源的 LightLGB 。它利用 生成的梯度提升树,通过分析不同特征在分类时的利用次数实现了重要性的分析。在计算环境受限的情况下,可以选 择保留前 20 个特征作为最终数据进行训练。
2 CRS系统
2.1高低阶特征交叉
在这里,高低阶特征交叉分为两个的部分:高阶部分和低阶部分。低阶部分可视为因子分解机的改进,高阶部分 则是使用了神经网络和 embedding 的方法。
2.1.1低阶部分
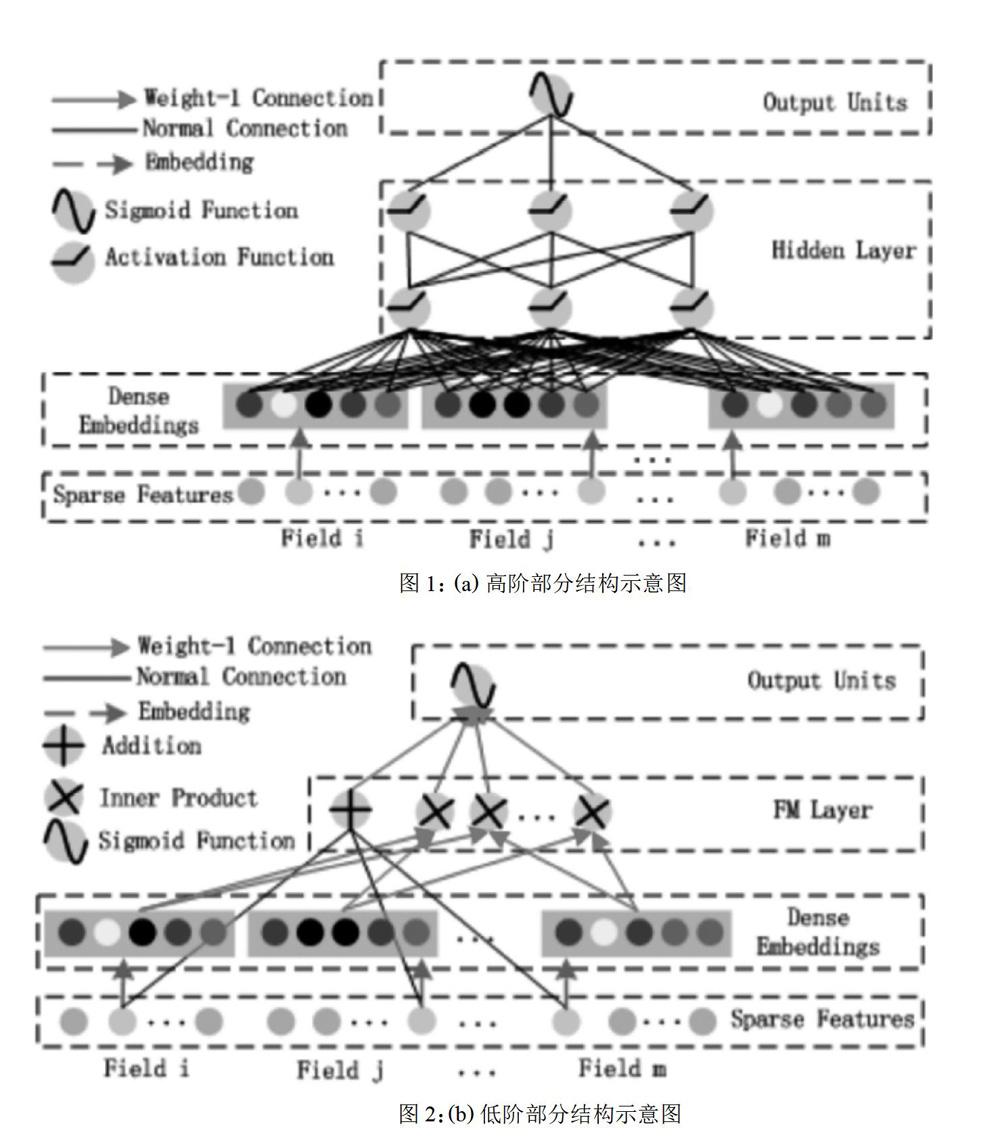
如图 1 所述的是模型设计所用到的因子分解机的优化形态。其构造主要分为一阶部分和二阶部分,一阶部分可以 看做为单特征在一阶特征空间的映射,二阶部分则是针对问题进行的对原因子分解机进行的优化,它将特征向量先通 过 Deep 部分训练好的 embedding 层,从而实现降维,再进行特征的两两交叉。这样,便实现了一个自动化的特征工程。 然而,FM 算法暴露的缺点是其缺乏灵活性,即其只是进行了两个特征的结合,对于多特征的情况却有所缺失。Deep 部分则通过其对于高阶特征交叉的学习,很好的弥补了这一点。
其中 w ∈ Rd, Vi ∈ Rk。相加单元(〈w, x〉)代表一阶特征的重要性,而其后的内积单元表示二阶特征交叉的重要性。 如图 2 所述的为一个含有 embeddiing 层的前馈神经网络。由于在 CTR 预测问题中,特征存在很多类别型特征从 而变得高度稀疏,所以为了将这些特征变成纯粹的、连续的数值型特征,我们引入了 embedding 层,从而使得 CTR 问题得以在神经网络中进行学习。
2.2 CRS 系统
在模型设计之初,考虑到当下极为火热且实际工程中效果极佳的神经网络,便尝试将其加入模型中,然而,神经网 络在处理复杂问题的优秀能力使其轻易达到了高阶的特征交叉,却自然的忽视了最为基础的低阶特征交叉。于是,参 考因子分解机的原理,并结合这一行业的特质,将独热处理后的多特征看做一个域,并实现域与特征的交叉,从而达 到更具说服力的特征输入。
此外,对于模型输入,大部分特征为非实数型特征,而神经网络和因子分解机输入的数据均为实数型数据,因此, 我们需要对类别特征进行独热处理(one-hot)。但是,与此同时,我们需要用 embedding 的方法来解决独热处理带来 的数据分布维度过高问题。这样,我们就将模型输入分为三类:单值连续型、单值离散型、多值离散型,其中,单值连 续型即为可以直接进行特征交叉的实数型特征,而单值离散型和多值离散型均需通过 embedding 层来实现实数向量的这一模型的输出为一个实数值,即为某一学生选择某一课程的相关性,我们将这一学生对多个候选课程进行相关 性计算,并对每个结果进行排列,取最高的几个值对应的课程进行推荐(例如 top10)。这样,便实现了模型从设计到 训练再到具体环境的流程。
CRS系统,不仅可以辅助学生进行课程的决策,更可对其进行功能的延展。例如,课程推荐系统可以通过预测学 生的選课情况,从而了解学生对于课程的偏好,从侧面实现了对某一课程的评估,使得课程评估变得更具客观性。这 样一来,CRS 系统可以帮助校方进行课程信息的调整及开设。
此外,CRS 系统经过模型与数据集的改动,可以解决回归问题,实现学生对于某一课程的选课情况的预测。这样 可以更好地帮助校方调整课容量,从而摒弃了以往仅仅通过主观、感性的判断而人为设定的课容量,对于新课的开设 也是具有很好的指导意义。例如,对某个新开设的课程,其在多个校区均有开设,通过 CRS 系统,便可预测不同校区 的选课情况,并对这一课程的教室类型和容量进行调整。这样一来,校方减少了教学资源的浪费,实现了精度化的课 程开设。从这些应用来看,课程推荐系统同样对于学校有着巨大的指导作用。
3实验验证
3.1实验环境
本文使用Python语言和TensorFlow深度学习工具实现,云端服务器配置有16核CPU,64GB内存和4个NVIDIA RTX2080Ti。
3.2学生-课程的相关性预测和排序
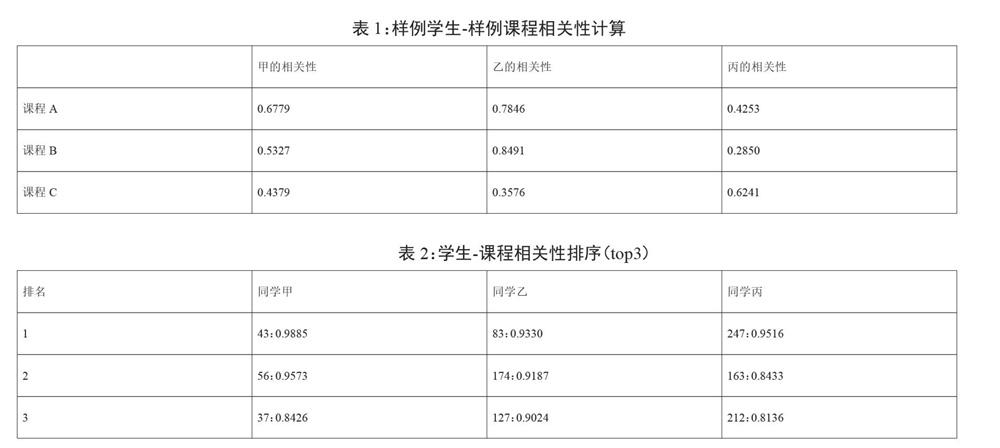
为了验证模型设计和实验方案的可行性,利用现有的已经清洗并脱敏的学生属性、选课属性数据集进行了学生-课程相关性的计算实验。表1中的相关性为样例学生和样例课程的相关性计算,表2为学生-课程相关性的前三相关性,即推荐候选课程排名前三的名单。由表2可以简单得出,通过CRS系统的计算,可以将学生的已有信息转化为一种更为普遍的对课程的偏好,如同学丙的top3课程均与文学和历史相关,而同学丙便是历史学院的学生;由表1同样可以得到一些和常识相对应的信息,如同学甲、乙均位于校区0,而他们对于开设在校区1的课程相关性较强(如课程A和课程B)。当然,通过CRS一样可以挖掘出一些有趣的事件,如生源地为河北的同学大多有对计算机类课程的偏好。以上实验结果因此可以简单验证CRS系统的可行性。
4总结
本作提出了 CRS 系统,其不仅可以充分的利用大学现有的校园数据资源,实现对学生个性化的课程推荐,甚至可 以利用其很好的延展性,应用到校方的课程开设中并为其做出指导作用,最终实现了对学生进行课程推荐和辅助学校 进行课程开设决策的最终目的。
然而,在实际应用中,由于每个课程,计算量相当庞大,这在实际情况下是不可行的。因此我提出了以下方案:率 先进行课程的聚类,通过 CRS 系统对课程组别的推荐来减少这一计算量;另外,我们也可设定一个学生与课程相关性 指标的阈值,将高于这一阈值的课程放入这一学生的候选课程名单,减少课程数从而降低计算的复杂度。
在校园的课程数据的应用中,仍有许多的特征亟待挖掘,由于推荐系统的复杂性,为了简化挖掘过程,本文在实 现时,对大量的学生特征进行了适当的取舍(如选择某一课程的学生的信息,以及由于选修和必修课程出现的一些差 异情况),使得 CRS 系统的适用性更强,适用范围更广。
参考文献
[1] Junxuan Chen&Baigui Sun&Hao Li&Hongtao Lu&Xian-Sheng Hua. Deep ctr prediction in display advertising[J].In Proceedings of the 24th ACM international conference on Multimedia,2016:811–820.
[2] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system[J].In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining,2016:785–794.
[3] Yuchin Juan&Yong Zhuang&Wei-Sheng Chin&Chih-Jen Lin. Field-aware factorization machines for ctr pre- diction[J].In Proceedings of the 10th ACM Conference on Recommender Systems,2016:43–50.
[4] Guolin Ke&Qi Meng&Thomas Finley&Taifeng Wang&Wei Chen&Weidong Ma&Qiwei Ye&Tie-Yan Liu. Lightgbm:A highly efficient gradient boosting decision tree[J].In Advances in Neural Information Processing Systems,2017:3146–3154.
[5] Steffen Rendle.Factorization machines[J].In 2010 IEEE International Conference on Data Mining,2010:995–1000.
[6] Ruoxi Wang&Bin Fu&Gang Fu&Mingliang Wang.Deep & cross network for ad click predictions[J].In Proceedings of the ADKDD17,2017:12.
[7] Jun Xiao&Hao Ye&Xiangnan He&Hanwang Zhang&Fei Wu&Tat-Seng Chua. Attentional factorization machines: Learning the weight of feature interactions via attention networks[J].arXiv preprint arXiv:1708.04617,2017.
附录
A 数据集相关细节
数据集的来源为四川大学学生部分数据中的学生基本信息和选课信息。我们将数据分为五个部分:学生基本信息 数据、选课信息、教师基本信息、教室信息。另外,特征存在三类:数值型(numeric),离散型(discrete),向量型 (vector),长度型(length),时间型(time)。其中,数值型为浮点数;离散型为类别 id,可进行独热处理;向量型为单个特征中存在多个离散值的数组,且数组长度不定;长度型为特殊的数值型,其为从向量型特征中数组长度的取值; 时间型为特殊的数值型,由于在这个背景中涉及到时序问题,将数据中涉及的时间特征按从小到大进行独热处理,并 按数值型特征对待。
对于训练集和测试集中的标签表示某个学生是否选择某个课程,分为两个值:0、1。0 表示选课,1 表示不选课。
下面将对数据集中的主要特征进行列举:
(1)学生基本信息:学生 id(discrete),年龄 (numeric),年级 (numeric),性别 (discrete),生源地 (discrete),历史 课程 (vector)。
(2)选课信息:选课 id(discrete),课程名,开设学院 id(disc rete),课程号 id(discrete),课序号 id(discrete), 选课时间,开设学院 id,课程类型 id,教师 id,校区 id,周次,教学楼 id,教室 id,课容量。
(3)教师基本信息:教师 id,教师所属学院 id,性别,年龄,历史教学课程。
(4)教室信息:教室 id,所在教学楼 id,所在楼层,教室类型,教室大小,教室新舊情况注意:①在学生 id 中需保留原始学生号用于之后的特征工程。②选课信息为选课信息和课程信息的合并,为便于总结,在这里进行了简化。③教师基本信息和学生基本信息中,历史课程均为课程 id 的集合。④教室信息中,教室新旧情况可视为简化特征,例如将最近的装修年份作为新旧程度划分的标准;教室大小可按照教室面积的标准划分;教室类型为人为界定特征,比如未有任何设备的教室为最低级别,具有多媒体、师生互动设 备等条件则为不同的类型。
下面将对训练集和测试集的基本内容进行分析:
训练集和测试集均包括选课 id、学生 id 以及是否选课这三个特征,其中训练集与测试集的比例按照 20:1 划分。另 外,由于这个分类问题中正负样本数量的明显差距,我们采用正负样本 1:20 来进行数据的采样。对于空缺值及异常 值,均以-1 填充。
B 模型训练细节
以下列举了一些主要参数及对应的默认值:
feature_dim_dict – 特征字典,以字典的格式保存特征的域,例如 {sparse:{field_1:4,field_2:3, field_3:2},dense:{field_4,field_5}}
embedding_size=8 – embedding 层的输出向量长度 dnn_hidden_units=(128, 128) – deep 部分的网络结构 l2_reg_linear=0.00001 – 应用在 FM 部分的 L2 正则化 l2_reg_embedding=0.00001 – 应用在 embedding 层的 L2 正则化 l2_reg_dnn=0 – 应用在神经网络隐层的 L2 正则化
task=binary – 训练任务,这里默认的是二分类问题
