基于Transfer-crf神经网络的电子表格智能识别算法
2019-11-15毛尚伟张志清郑成坤符云清
毛尚伟,张志清,汤 槟, 郑成坤,翟 波,符云清
(1.中冶赛迪技术研究中心有限公司, 重庆 401122;2.重庆中冶赛迪信息技术有限公司, 重庆 401122; 3.重庆大学, 重庆 400044)
电子表格是一种交互式计算机应用程序,用于以表格的形式组织、分析和存储数据,已被广泛用于构建、排序和共享表格列表的任何环境中。据微软公司统计,在全球范围内Excel用户的数量已超过4亿人次,如果加上其他一些电子表格软件,这个数目将会更加庞大。据弗雷斯特研究公司(Forrester Research)的调查估计,有50%~80%的企业在商务活动中使用了电子表格[1]。
电子表格通常具有高度灵活的编辑方式,可呈现的表格结构形式广泛,利于用户快捷使用。然而,当进行大规模的电子表格自动处理时,表格形式的多样性给计算机的自动处理带来了挑战,严重影响了基于电子表格的复杂数据分析、可视化、错误检测等功能。因此,对海量表格的结构识别是获取表格数据、利用表格数据的必要步骤。目前,国内外对电子表格的识别主要集中在表头结构,如Dou等在2018年提出了一种表格的可扩展组检测方法[2],以表头位于表格的前4行为前提,构建了基于行的类型、格式以及类型和格式这3种规则来推断表格的表头结构。Abraham等采用分类的方法研究表头识别方法[1],提出了一种基于分类算法的表头框架。总体而言,现有相关研究较少,且存在算法识别条件较为苛刻、算法精度不高等问题。针对这些问题,本文对电子表格结构的自动识别进行了研究。
本文主要针对工商业大量使用的纵向表格,采用深度学习模型transfer算法与条件随机场算法(CRF)相融合,实现对电子表格行属性的自动识别。本文基于中国国家统计局以及相关政府机构公开的电子表格数据集开展工作,采用提出的transformer-crf算法进行实验,并与CRF算法进行比较。实验结果表明:本文提出的算法识别精度优于CRF算法,能够满足电子表格自动化处理需求。
1 表格结构识别定义与分析
电子表格按内容布局方式可分为纵向电子表格、横向电子表格、混合电子表格。由于纵向电子表格是商业和工业中最为常见的表格布局方式,本文重点研究纵向电子表格的结构识别,后文电子表格均指纵向电子表格。典型的纵向排布电子表格如图1[3]所示。

图1 纵向电子表格样例
电子表格通常由若干行内容组成,可记为如下形式:
R=[r1,r2,r3,…,rn]T
(1)
其中ri(i= 1,2,3,…,n)表示表格的一行内容。表格的一行内容可能是表格的表头、变量名、数据或者表尾,假设表格的行属于且仅属于前述4种行类别中的一类。表格的具体定义如表1所示。
对于纵向电子表格的结构识别,需要识别出表格中每一行内容的类别,R的类别标签序列可记为:
A=[a1,a2,a3,…,an]T
(2)
其中ai是ri的类别标签,ai∈{0,1,2,3}。其中,0是表头的标签,1是变量名的标签,2是数据的标签,3是表尾的标签。
表格结构识别模型M的目标是判断表格各行的类别标签,可记为:

A=M(R) (3)
2 表格结构识别的问题建模
2.1 表格结构特征提取
为量化电子表格结构,本文提出了一系列的表格结构特征,并以此为基础构建表格结构识别模型,见表2。

表2 表格结构特征

续表(表2)
2.2 基于Transformer-CRF神经网络结构的表格结构识别
表格各行的类别标签之间存在关联,如表头下面很有可能是变量名而不是数据,数据行下面更可能是表尾而不是表头等。因此,表格结构识别问题可转换为序列标注问题,如式3所示。
近几年深度学习技术的快速发展使自然语言处理的各项任务取得了较大进展,特别是近两年出现的Transformer[4]结构,基于注意力机制构建特征提取和表示模型,突破了原有LSTM模型不能很好地处理远距离依赖关系的限制,进一步提升了针对语言序列的特征提取和表示能力,基于该结构的GPT[5]、GPT2.0[6]、BERT[7]等预训练模型刷新了各大自然语言处理任务测评比赛最佳成绩。
本文基于Transformer和CRF构建一种新的深度学习序列标注模型,如图2所示。该结构由row encoder、table encoder、CRF 3部分神经网络组成。row encoder网络用于对表格内容的每一行进行编码,目的是期望提取表格各行的语义信息,table encoder网络则是对整个表格进行编码,重新得到表格各行的特征表示,以期提取表格行与行之间的关系,然后再经过一层线性网络得到CRF的发射概率,该结构类似于BiLSTM-CRF[8],CRF层构建了转移概率矩阵。最后,基于table encoder层输出的发射概率和转移概率计算条件概率最大的输出序列。
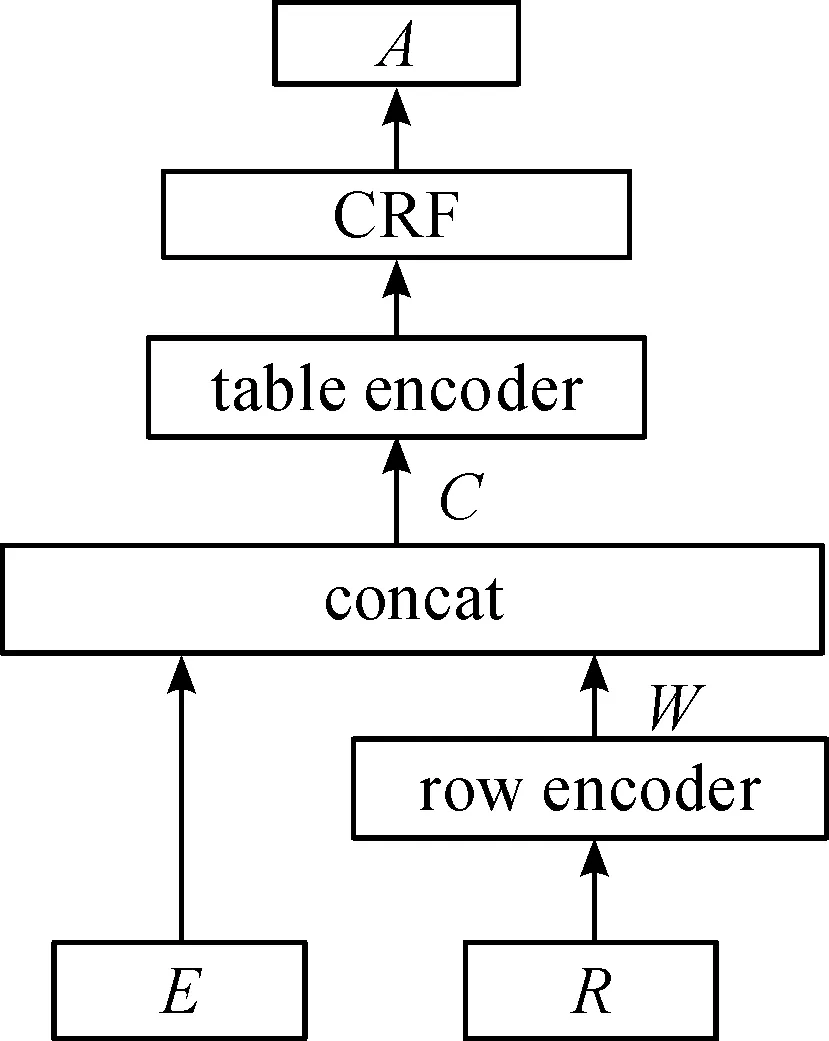
图2 Transformer+CRF网络结构
Transformer-CRF网络的输入有人工特征E和表格内容R两部分。人工特征E来自表2的特征,表格内容R表示了整个表格的内容信息。为了便于提取语义信息,将每一行的单元格内容拼接在一起形成长字符串,并利用预先构建的字符集将字符串映射为数值向量[9-11]。
输入的E和R在网络中传输的过程可用下式表示:
Wn,b=row(Rn,m)
(4)
Cn,a+b=[Wn,b;En,a]
(5)
Tn,4=table(Cn,a+b)
(6)
An,1=CRF(Tn,4)
(7)
式(4)中的Rn,m是n×m的矩阵,表示n行且每一行的内容长度为m的表格。在row encoder层对每一行独立进行编码后得到Wn,b,b为编码长度。具体row encoder层的示意图如图3所示。rij(j= 0,…,m) 表示了ri行的第j个字符,ri进入网络后首先经过embeding将单数值rij映射为连续向量,然后再进入transformer提取高阶信息,最后将ri1对应的输出作为整个序列的编码结果wi。Wn,b由wi组成,可表示为
(8)
图2中的concat可用式(5)表示,其中En,a是n×a的矩阵,保存了n行a维人工特征向量;符号[A;B]表示将矩阵A和B水平方向拼接,式中Cn,a+b即是Wn,b与En,a拼接的结果。
式(6)表示了table encoder的处理过程,输出的Tn,4是n×4的矩阵,矩阵T的列之所以为4,是因为待预测的行标签有4类。式(7)表示了CRF推断过程,输出表格的行标签序列A。图3、4表明了table encoder和CRF的结构,C进入网络后首先经过transformer进行表格编码提取表格行关系特征,然后经过linear层将每一行的编码映射成4维向量得到CRF发射概率矩阵Tn×4,最后进入CRF层推断输出标签序列Anx1。

图3 Row encoder结构

图4 Table encoder结构
3 实验结果与分析
3.1 数据集
本文以中国国家统计局及相关政府机构的官方网站获取的电子表格作为实验数据集,主要来自:中国统计年鉴、工业物料清单、采购订单、工业生产数据和市场调研表。数据集中包含10 265张表格,共计661 937行。将其按照7∶3的比例(考虑到表格划分的一些特殊情况,实际的比例约为7.07∶2.93)分成训练集和测试集,其中训练集中包含了7 257张表格,共计466 115行;测试集中包含了3 008张表格,共计195 822行。
3.2 评估指标
对于行属性每个类别的预测,可将其视为二分类问题。根据模型的预测结果可以划分为:真正例TPi、 假正例FPi、假负例FNi。以表头的预测结果为例,TP0即真实类别为表头且模型预测结果也为表头的行的数量;FP0即真实类别为非表头且模型预测结果为表头的行的数量;FN0即真实类别为表头且模型预测结果为非表头的行的数量。以上述指标为基础,本文从行和表格这2个角度分别评估模型的优劣程度,分别构建了行评估指标和表格评估指标。
3.2.1行评估指标
行评估指标由以下2个指标构成:
1) 微平均(Micro-average)
包括微平均准确率mP,微平均召回率mR,微平均F1分值mF1,计算公式如下:
(9)
(10)
(11)
2) 宏平均(Macro-average)
包括宏平均准确率MP,宏平均召唤率MR,宏平均F1分值MF1,计算公式如下:
(12)
(13)
(14)

3.2.2表格评估指标
表格评估指标为整表识别准确率FTP,即模型对该表格所有行的类别全部识别正确的表格数NRT与测试集中总表格数NT之比:
(15)
3.3 实验步骤
1) 配置实验平台
平台主要软硬件参数:CPU为 i7-6850k,64 G内存,显卡GeForce GTX 1080Ti 2块,软件核心平台python 3.7.2,深度学习框架为PyTorch 1.1.0,CRF 模型使用crfsuite(集成于sklearn)。
用本文2.1节的方法对表格特征进行提取构造CRF模型的数据集,将表格内容和表格信息进行拼接,构造字典,利用字典构造词向量,作为Transformer-CRF的数据集。将数据集按照7∶3分为训练集和测试集。
3) 分别对CRF、Transformer-CRF模型进行训练
模型网络结构见图2。Transformer-CRF模型训练部分核心代码如下:
model = TableNet(vocab_size_w,w_embd_size,c_embd_size,r_embd_size,
class_size,class_embd_size,row_info_size,row_info_embd_size,
bilstm_hidden_dim)
optimizer = optim.SGD(model.parameters(),lr=0.01,weight_decay=1e-4)
neg_log_likelihood_avg_min = 1000000000
1、农田区域建造防护林网。农田防护林网是治理风沙的一项基本生态工程。低矮灌木和林木根系可以防止土壤风蚀,乔木林冠带可以截留随风飘移的颗粒,从而减少土壤及其中营养物质的损失,从根本上保证土壤营养质的保留,为农作物的生长与防护林的进一步固化成长具有重要的奠基作用。
for epoch in tqdm(range(epochs)):
neg_log_likelihood_avg = 0
for afile in tqdm(train_data):
model.zero_grad()
# Step 3.Run our forward pass.
neg_log_likelihood = model.neg_log_likelihood_wh([afile[1]],[afile[2]],[afile[3]],[afile[4]])
neg_log_likelihood_avg += neg_log_likelihood
# Step 4.Compute the loss,gradients,and update the parameters by
# calling optimizer.step()
neg_log_likelihood.backward()
optimizer.step()
print(epoch)
temp = (neg_log_likelihood_avg/len(train_data)).data[0]
print(temp)
if neg_log_likelihood_avg_min >= temp:
neg_log_likelihood_avg_min = temp
joblib.dump(model,′best_model.pkl′)
4) 对训练好的模型在测试集进行测试
按照本文3.2.1、3.2.2节进行评估计算。
3.4 实验结果
使用此前筛选和构造的特征在训练集上分别训练了传统的CRF模型和Transformer-CRF模型,并使用训练好的模型分别在测试集上进行了测试和验证。
根据各个模型在测试集上的测试结果,计算并得到了CRF、Transformer-CRF模型在测试集上的评估指标结果,如表3、4所示。

表3 2种模型在测试集上的行评估指标对比
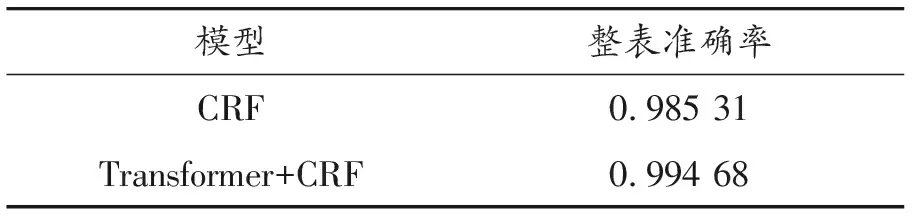
表4 2种模型在测试集上的表格评估指标对比
从实验结果来看,transformer-CRF模型在识别表格每一行的类别方面的性能优于CRF模型。
4 结束语
本文就电子表格的结构识别进行了研究,使用人为构造的表格特征模板,采用序列标注模型对表格结构的识别进行建模,提出了transformer-CRF的模型结构用于表格结构识别。实验结果表明:本文方法能较好地识别表格的行类别,transformer-CRF模型结果最优识别在本文实验数据集上,行识别精度高达99.988%,整表识别准确率高达99.468%。
