基于集成学习的公交车辆到站时间预测模型研究
2019-11-15荆灵玲王安琪
荆灵玲,解 超,王安琪
(1.中航勘察设计研究院有限公司,北京 100098;2.中国交通通信信息中心,北京 100011;3.中交信有限责任公司,北京 100007;4.北方工业大学,北京 100144)
城市公共交通是交通运输业的重要组成部分,落实“公交优先”政策,大力发展公共交通系统是缓解城市交通拥堵和交通安全问题行之有效的手段[1],而准确、实时地预测公交到站时间是城市智能交通系统(ITS)的重要组成部分。随着定位和通信技术的发展和完善,准确预测公交车辆到站时间有利于市民合理规划出行时间、满足市民多元化出行需求、减少等车时间、缓解乘客焦虑情绪及提供精细化服务,将居民出行方式吸引到公共交通上来,使居民的出行融入可持续发展的交通系统中[2],进而缓解城市交通拥堵等问题,有利于构建以公共交通为主体的畅通、安全、高效、舒适、环保、经济、公平的城市交通系统[3]。
国内外学者在公交到站时间预测方面提出了多种不同的方法。根据数据源可以分为基于历史数据的方法、基于实时数据的方法和两者相结合的方法。从预测方法上可以分为统计模型、回归模型、时间序列模型、神经网络模型、SVM、 Kacman滤波和路况相似性方法等。李天雷等[4]基于大量的历史公交轨迹数据,用多元回归计算各路段分时段的平均速度,基于平均速度进行预测。该统计模型对于路况比较稳定的线路预测性能好,但不能适应路况变化较多的线路。孙棣华[5]在历史平均速度的基础上考虑车辆实时速度、到站距离、车站、信号灯等因素,建立了到站时间预测的线性方程。这种方式考虑了车辆的速度及其他影响因素,但由于公交车的密度不足以覆盖所有时段和路段,所以在实时速度方面难以达到较高的覆盖率和准确率。Li等[6]和Tetreault等[7]基于时间、历史速度、实时速度、天气、路段长度和交叉口数量等影响因子构建多元回归方程进行预测,由于路况的多变和影响因子较多,线性回归模型的拟合能力有限。孙玉砚等[8]对历史路况进行聚类,找到与当前路况相似的历史路况来预测站点到站点的行程时间,这种方法在复杂路况下的聚类和相似性判断方面难以达到较高准确性。
另外,不少学者使用人工神经网络模型(ANN)来预测到达时间。 Chien[9]提出了基于link和stop的ANN预测模型。与线性模型相比,该模型学习能力更强,预测更准确,但是需要大量的训练数据且在线性能较差。
卡尔曼滤波模型由于对历史数据依赖小、抗干扰能力强被许多学者采用。Shalaby[10]提出用卡尔曼滤波来预测公交到站时间和离站时间。卡尔曼滤波利用通过某路段的前车数据对后面通过该路段的公交车时间进行预测。这种方法较好地考虑了实时路况,对历史数据要求不高,但是由于公交车运行在各路段和各时段的不均衡,会导致数据稀疏。此外,由于长距离预测时路况变化较大,所以在实际应用中存在较多限制。
SVM 作为主流机器学习方法,因非线性拟合能力强、适合小样本的特点常被用来预测到达时间。Yu[11]提出了基于SVM的预测模型,把时间、天气、路段、当前路段的行程时间和下游路段的行程时间作为特征。实验结果表明,该模型的预测精度优于历史平均模型和ANN模型。陈旭梅等[12]在卡尔曼滤波基础上结合SVM对BRT进行了行程时间预测,效果较好。由于公交线路及路况的复杂性远大于BRT系统,所以该模型在公交系统上的适用性还需要进一步验证。
智能公交系统在长时间运营过程中积累了海量的公交轨迹数据。 作为一项数据驱动的技术,机器学习在众多领域取得了成功。集成学习作为机器学习的一个重要研究领域,通过联合若干弱模型来提高效果,与单一模型相比可以得到更好的预测效果。张威威等[13]利用实测的车辆旅行时间数据,提出了多步预测的主成分分析-梯度提升决策树 (PCA-GBDT) 方法,实验结果表明该方法具有更高的预测精度与算法稳定性。
本文提出了一种基于集成学习的公交车到站时间预测方法。利用集成学习方法,确定优化目标,把公交车到站时间相关的影响因素进行特征化,基于海量历史数据训练出机器学习模型,预测公交到站时间。
1 数据与方法
1.1 数据源
数据源包括静态数据和动态数据。静态数据主要指公交线路及站点,动态数据主要指车辆上报GPS坐标流。公交线路及站点见图1,公交车辆GPS坐标流见表1。
图1 北京市公交站点线路

线路编号车辆编号GPS上报时间纬度经度10016b8c4f149860901339.873 863116.458 18110016b8c4f149860902039.873 849116.458 85310016b8c4f149860902739.873 914116.459 15210016b8c4f149860903439.874 104116.459 43110016b8c4f149860904139.874 065116.459 80210016b8c4f149860904839.873 881116.460 54910016b8c4f149860905539.873 678116.460 77010016b8c4f149860906239.873 124116.460 82610016b8c4f149860906939.872 554116.460 84610016b8c4f149860907639.872 268116.460 92810016b8c4f149860909039.871 643116.460 82710016b8c4f149860909739.871 442116.460 88810016b8c4f149860910439.871 539116.461 16110016b8c4f149860911139.871 977116.461 21310016b8c4f149860911839.872 714116.461 21110016b8c4f149860912539.873 374116.461 215
1.2 预测方法
本文采用集成学习GBDT的方法进行公交车辆到达站点的时间预测。
集成学习通过构建并结合多个学习器来完成学习任务[14]。GBDT是集成学习的一种算法。GBDT算法(gradient boosting decision tree)由Friedman最早提出,它利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值拟合一个回归树[15]。GBDT通过迭代地训练一系列的分类器,使每个分类器采用的样本分布都与上一轮的学习结果有关。GBDT算法输入是训练集样本T={(x1,y1),(x2,y2),…,(xm,ym)},最大迭代次数T,损失函数L。GBDT算法描述如下[16]:
步骤1初始化f0(x);
步骤2迭代轮数t=1~T,有:
1) 对样本i=1,2,…,N,计算负梯度rit:
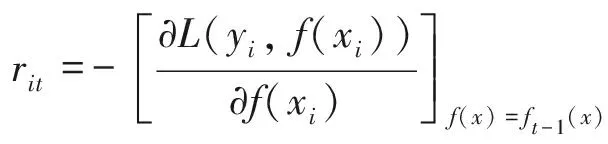
2) 利用(xi,rit)(i=1,2,…,N),拟合1颗CART回归树,得到第t颗回归树,其对应的叶子节点区域为Rjt,j=1,2,…,Jt。其中J为回归树t的叶子节点的个数;
3) 对j=1,2,…,Jt,计算最佳拟合值cjt:
4) 更新ft(x):
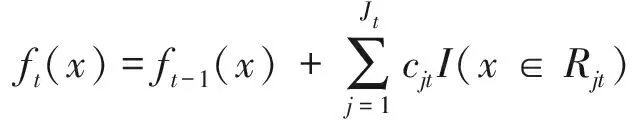
步骤3输出f(x)
GBDT预测方法框架(如图2)包括:① 目标函数定义;② 特征工程:确定特征因子和分析其重要性。公交车辆到站时间预测涉及影响因素主要有历史路况、实时路况、站点分布、路段距离、红路灯数量和路口数量等;③ 离线训练与验证;④ 在线预测。
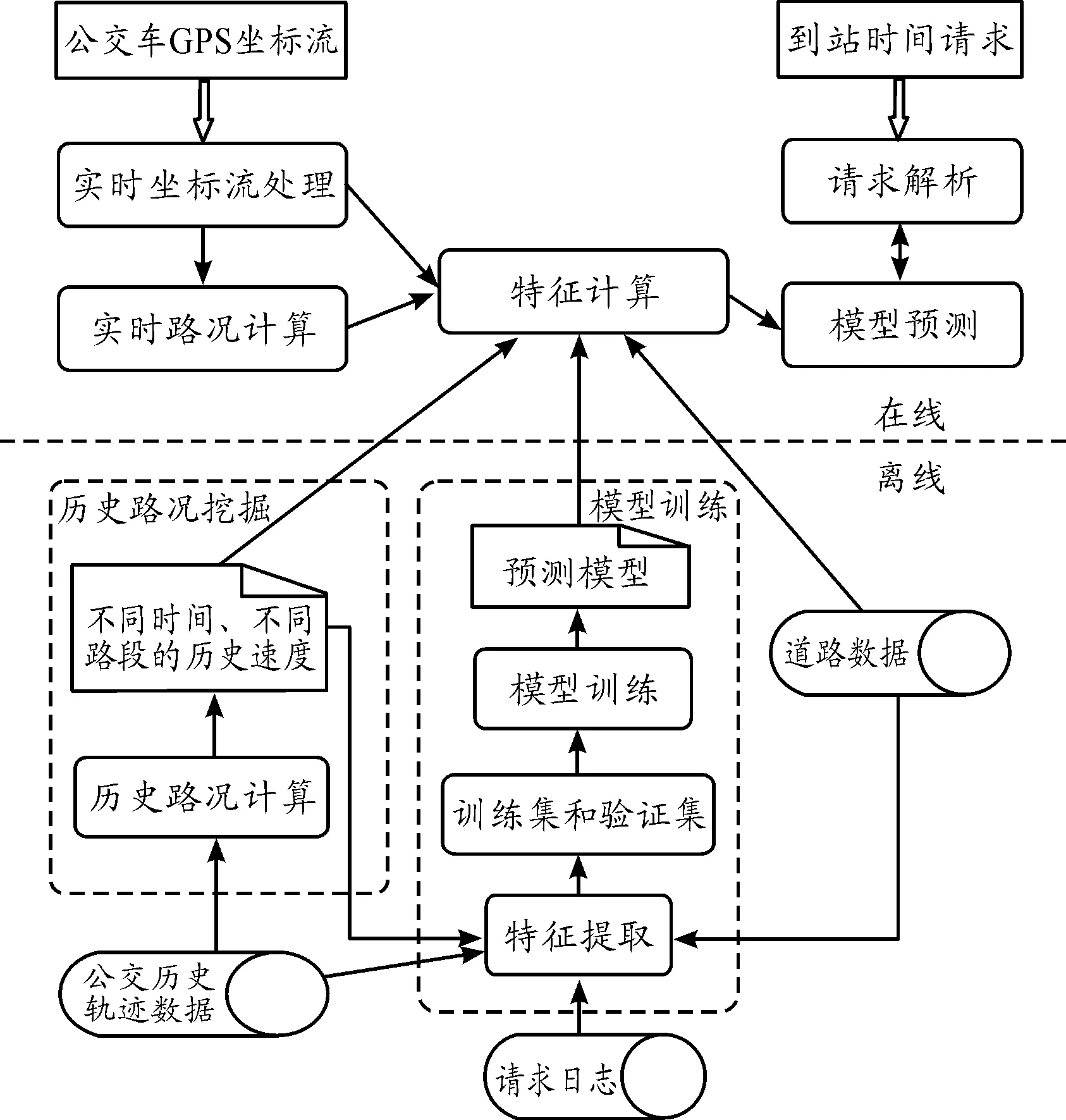
图2 GBDT预测方法框架
1.3 评价指标
常用的回归预测评价指标有MAE、RMSE和MAPE等,具体含义详见表2。本文采用预测误差MAPE作为集成学习目标函数。
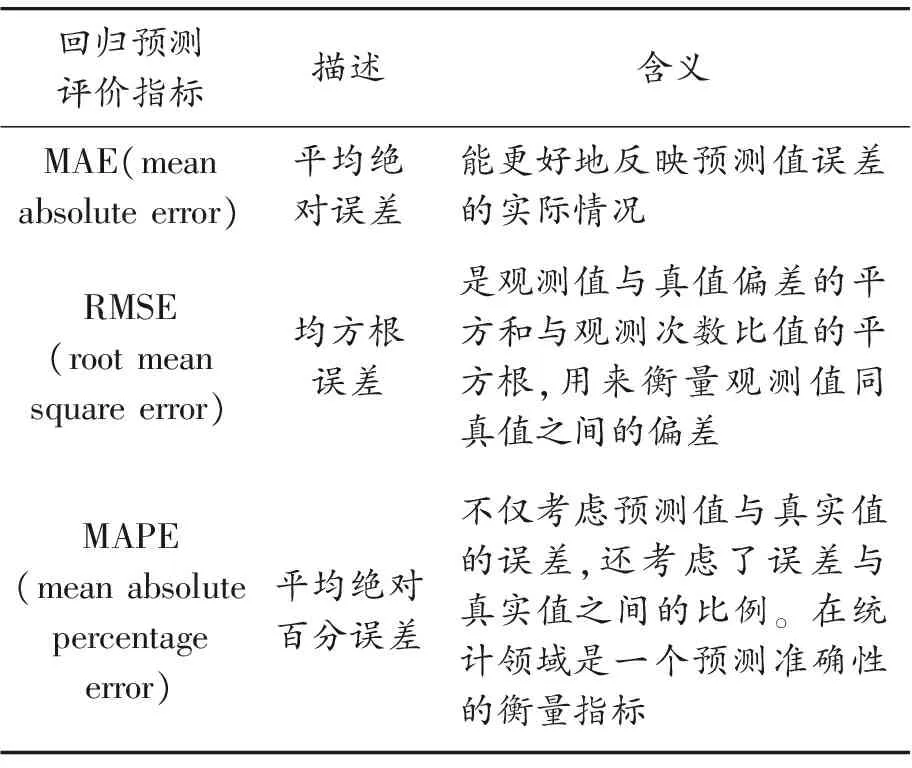
表2 评价指标MAE、RMSE和MAPE的含义
2 基于集成学习的ETA预测模型实现
2.1 目标函数定义
定义目标函数L为
训练目标为求解最优化:
2.2 特征工程
将特征因子分为初阶和高阶特征。初阶特征包括请求时间、到站点距离、经过站点数等;高阶特征分为路网(路口数量、红绿灯数量)和统计特征(历史路况和实时路况),特征列表见表3。
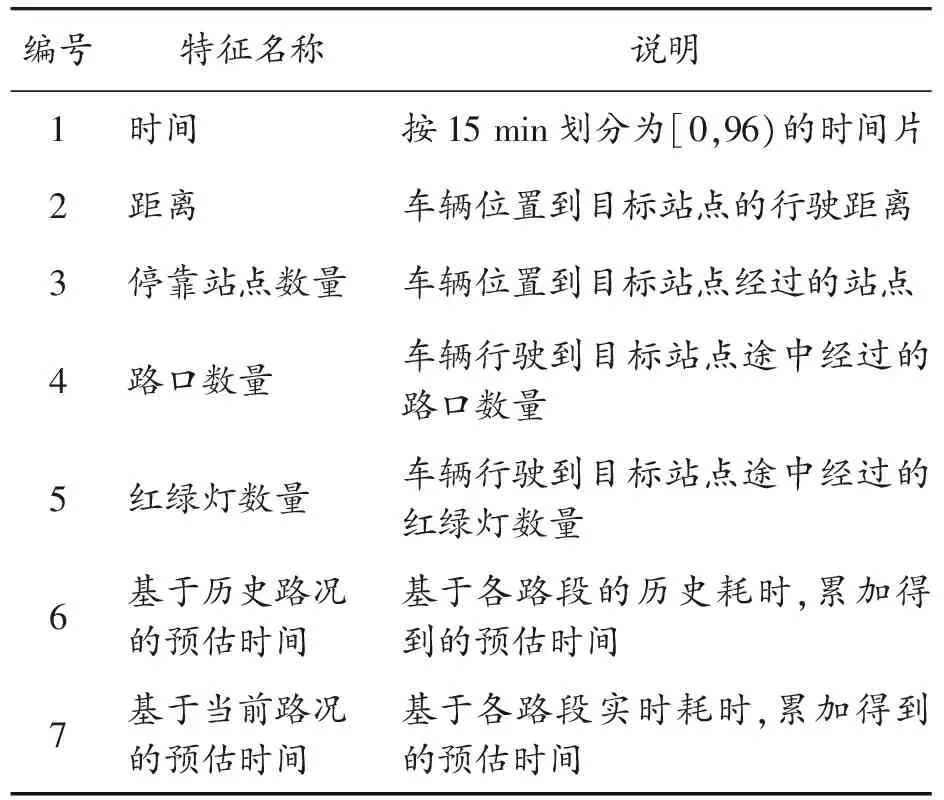
表3 特征列表
2.2.1特征因子计算
请求时间:按15 min作为时间片段,用[0,96)来表示全天各个时间片段。
路网特征:利用公交线路对应的道路数据提取路口数量及红路灯数量。
统计特征:历史路况和实时路况。
1) 历史路况计算
基于公交线路历史轨迹计算历史平均路况。计算某一路段在某一时间窗口的平均速度,该过程主要考虑时间块划分(t)和路段划分(s)问题。
时间块划分(t):路况随时间变化呈现出明显的高峰期和平峰期、工作日和休息日的差异规律。公交车排班也呈现明显的高峰期、平峰期、工作日和休息日的差异。
基于公交车排班差异将工作日和节假日采用不同的时间片划分方式,主要差异在早晚高峰的划分上。基于公交车排班差异可保证时间片内有足够的样本数量。基于这两点采用如表4的时间块划分,时间块是将每天的各个时间区间映射成一个数值。
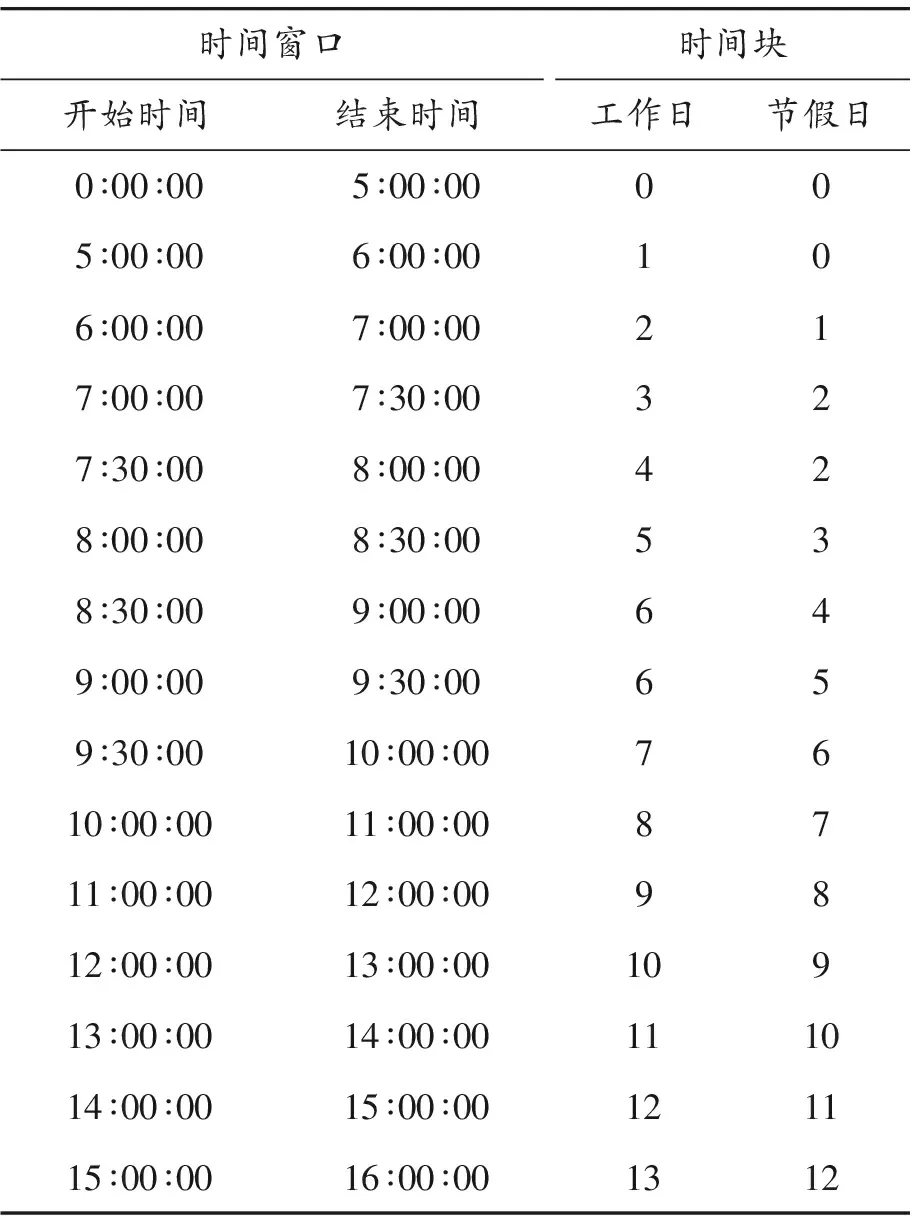
表4 时间块划分
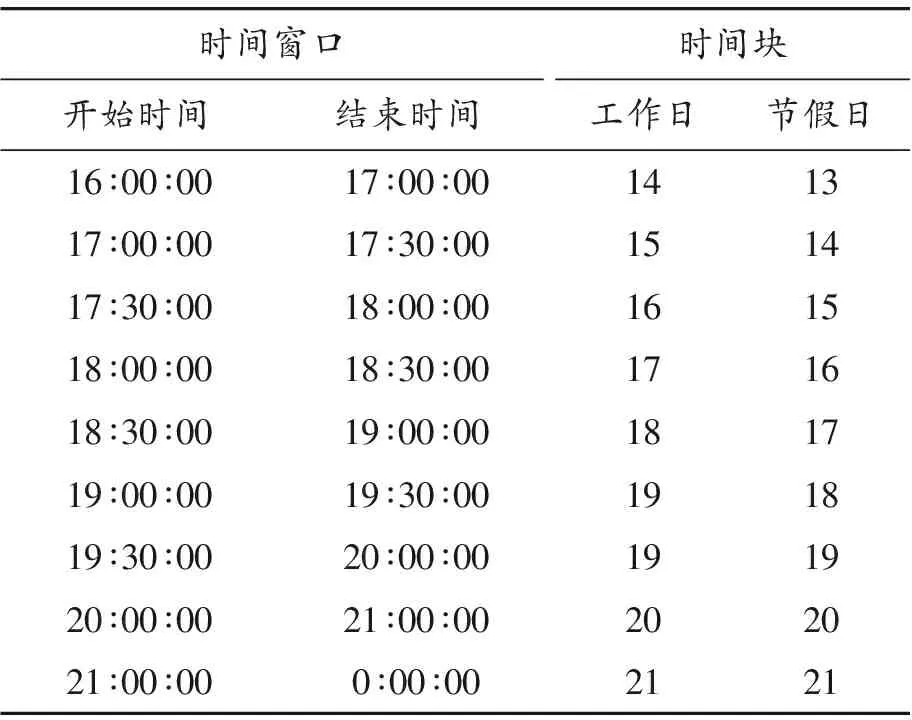
续表(表4)
路段划分(s):① 不同路段路况不同,两站点间距离从几百米到几公里不等,会导致严重的路况异质性;② 某一路线存在多条公交线路的车辆数据,这些不同公交线路的历史轨迹都可以用来计算该路段的历史路况。基于以上两点提出网格划分的线路离散化方法。该方法将公交线路抽象成一系列连续的网格,网格大小为100 m,如图3所示。
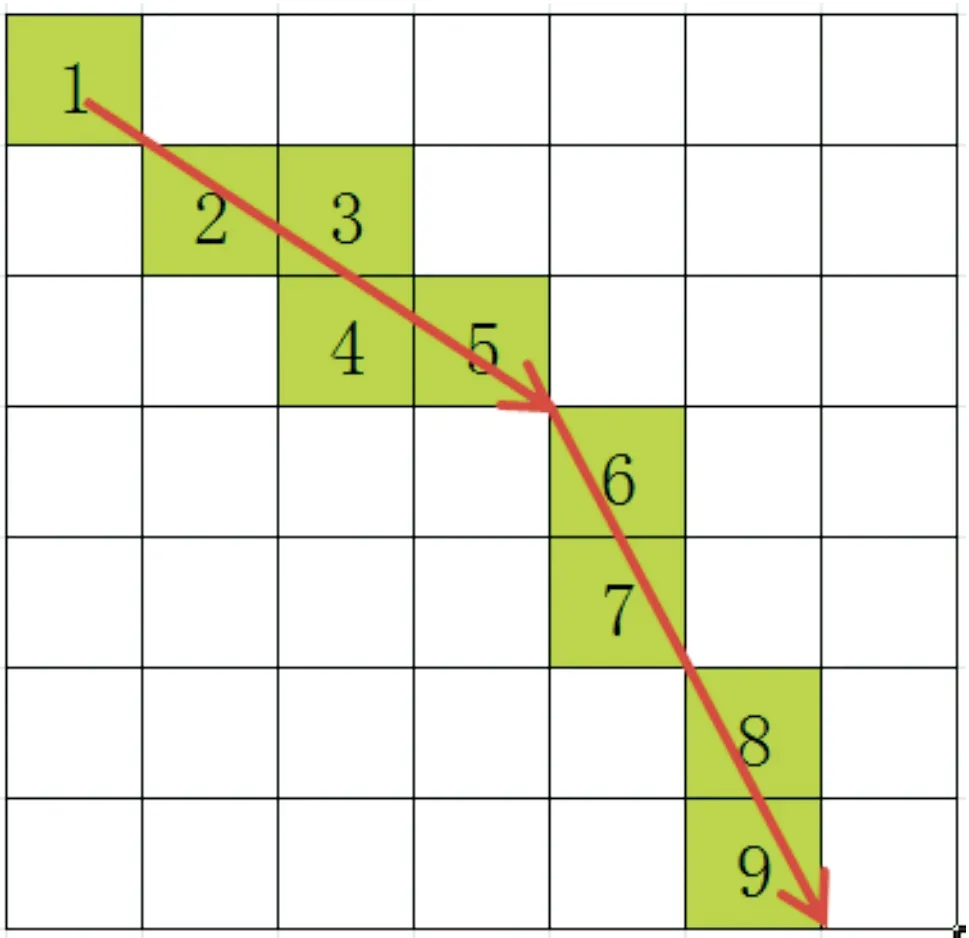
图3 线路离散化网格
历史路况计算采用cost单条轨迹计算方法,方法如下:
步骤1将轨迹数据映射到线路网格;
步骤2计算网格耗时。如图4所示,2个轨迹点落在2号网格和5号网格;每个网格的耗时为 avg = (T1-T0)/ (5-2);
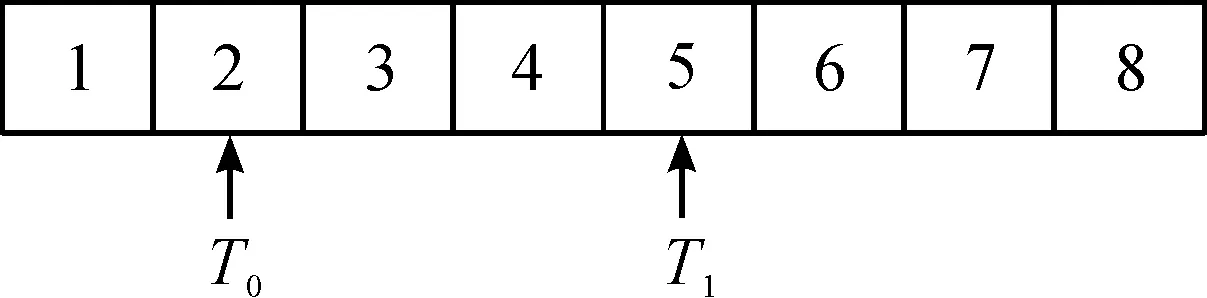
图4 轨迹数据映射到线路网格
步骤3计算网格耗时异常值过滤和均值。当有若干条轨迹数据需进行异常值检验之后进行平均计算,最终得到每一个网格的平均耗时。
2) 实时路况计算
计算方式与历史路况类似,统计了过去15min内通过该路段的公交车辆平均耗时。
2.2.2特征因子重要性评价
特征的选取和处理决定了预测效果的上限。对于特征j,全局特征重要性通过在每棵树中的重要度的平均值来计算:
其中M是树的数量。
特征j在1棵树中的特征重要性为
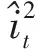
2.3 训练与验证
采用过去N天公交车辆到站时间请求数据,按2.2方法计算出所有特征,并计算出实际到达时间。从训练集随机抽取10%作为验证集。本文测试了不同训练参数下的不同效果,如表5所示。
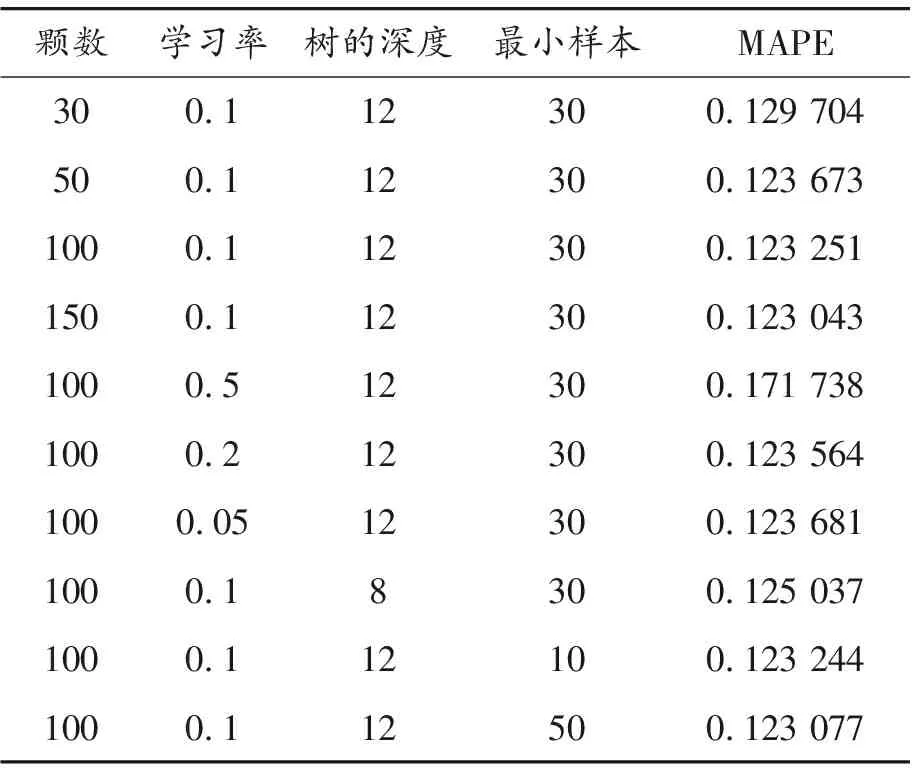
表5 不同训练参数下的不同测试效果
2.4 线上预测
线上预测部分主要包括特征生成模块、预测模块和验证模块。线上生成特征向量传入预测模型,最终得到结果。验证模块会记录公交车实际到达每个站点的时间,进而计算出预测的精度。
3 实例研究
本文选取北京市2017-06-01—2017-06-30公交车辆的轨迹数据作为训练集,以07-01—07-07日的数据作为测试集,利用XGBoost进行训练,验证公交到站时间预测模型的有效性。不同方法的测试效果见图5。
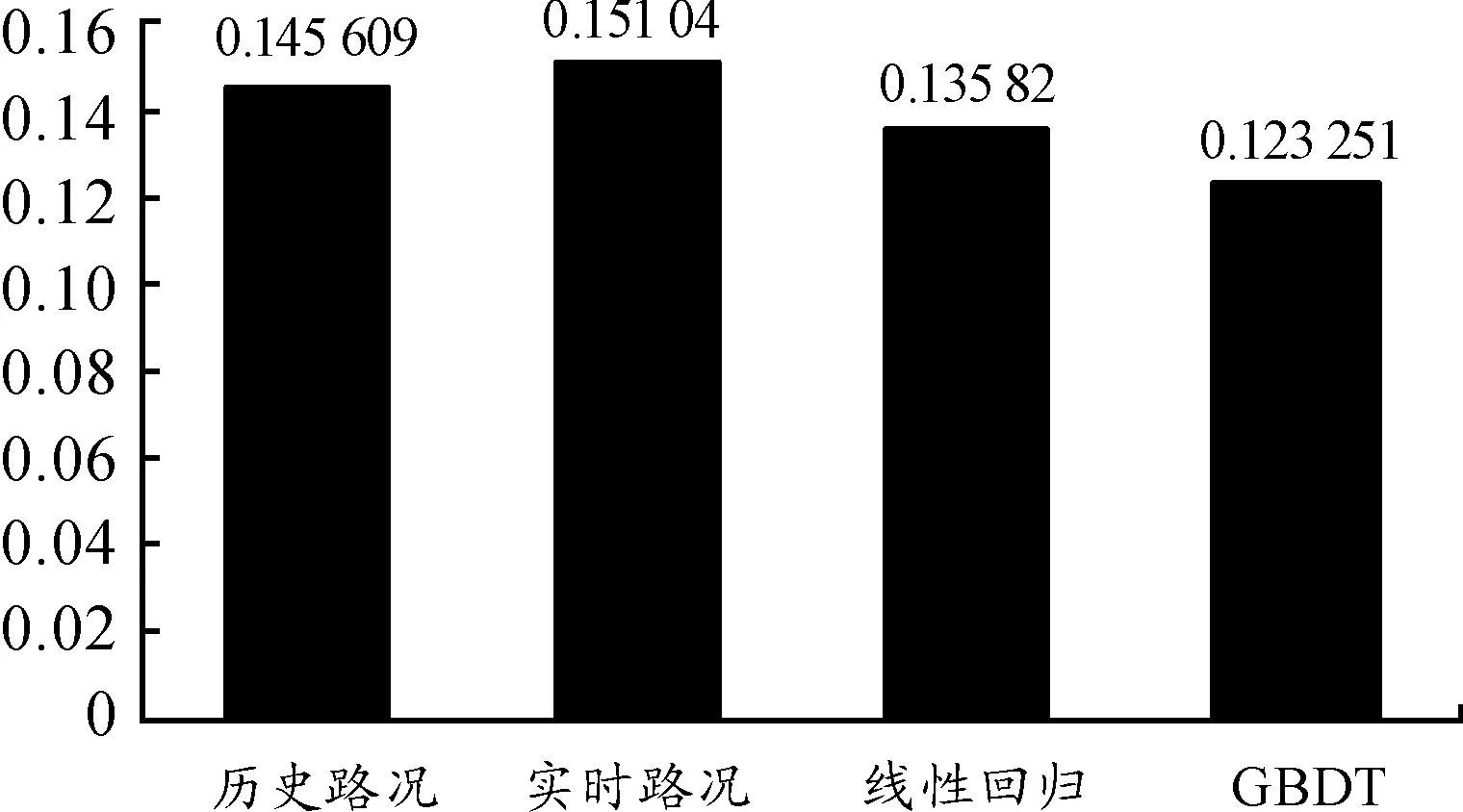
图5 不同方法测试效果
4 结束语
本文利用数条重合线路的坐标流数据,提出将集成学习GBDT方法用于预测公交车辆到站时间,提高了公交到站预测的准确性。通过实例分析和验证发现,基于GBDT方法的预测性能明显优于其他方法,可灵活处理混合类型特征,包括连续值和离散值,无需特征归一化处理,且预测准确率更高;有特征组合的作用,可自然地处理缺失值,对异常点鲁棒,具有易于实现、抗干扰能力强及泛化能力强等优点。但该方法也有一定的局限性,在ETA预测中,不同的线路、不同的司机都会影响到达时间,这些特征在GBDT模型中较难表达。另外,对突发的路况变化预测精度不够, 例如,在北京等大城市,由于道路突发事件较多,类似体育比赛、临时封路等也会影响周边路况,实时路况特征无法表达这种特殊路况持续的时间和波及的区域,会影响长距离的到达时间预测精度。这些存在的问题有待进一步的研究。
