大数据统一SQL引擎研究与设计
2019-11-13丁岩杨万祥汪清杨乐胡晓
丁岩 杨万祥 汪清 杨乐 胡晓

【摘 要】大数据统一SQL引擎不管是从现实要求,还是从大数据应用方面来讲,都值得深入研究,目前大数据生态系统中的不同SQL引擎都有各自适合的应用场景,性能指标也不相同,很难选择一种SQL引擎覆盖所有的应用需求。本文提出了大数据统一SQL引擎方案,集成多个SQL引擎,并提供统一的访问接口,用户可以根据需要灵活选用相应的SQL执行引擎,解决传统应用如何快速移植到大数据平台以及多个大数据SQL引擎选型难的问题。
【关键词】大数据;统一SQL引擎;集成;访问接口
中图分类号: TP311.13 文献标识码: A文章编号: 2095-2457(2019)29-0001-004
DOI:10.19694/j.cnki.issn2095-2457.2019.29.001
Research and Design for Big Data SQL Engine
DING Yan1 YANG Wan-xiang1 WANG Qing2 YANG Le2 HU Xiao1
(1.Research Institute of Cloud Computing,Nanjing ZTE New Software Co.Ltd,
Nanjing Jiangsu 210012,China;
2.Information Center of Science and Technology,Nanjing City Public Security Bureau,
Nanjing Jiangsu 210012,China)
【Abstract】Unified SQL engine of big data is worthy to be explored in depth,whether from the practical requests, or from the big data application aspects.In the current big data ecosystem,different SQL engines have own application scenarios,their performance is also not the same,so it is difficult to choose one kind of SQL engines to cover all application requirements.This paper presents an unified scheme of SQL engine for big data,which integrates multiple kinds of SQL engines and provides unified access interfaces.It allows users choose the corresponding SQL engine flexibly,to solve the problem of how to quickly migrate traditional applications to big data platform and how to select the available SQL engine.
【Key words】Big data;SQL engine;Integrate;Access interface
0 引言
目前大數据技术发展及应用越来越成熟[1-4],从工程或者技术的角度来看,大数据的核心是如何存储[5]、分析、挖掘海量[6]的数据来解决实际的问题。对于一个工程师或者分析师来说,如何查询和分析TB/PB级别的数据是在大数据时代不可回避的问题,所以基于大数据的SQL引擎成了大数据应用的重要手段[7-8]。
但对于传统的基于SQL实现的应用如何快速移植到大数据平台上来以及在现有的多个SQL引擎间如何进行选型是个难题。
1 大数据统一SQL引擎相关技术研究
1.1 背景介绍
大数据可以说无所不在,社交媒体、传感设备、机器生成的信息、手持终端设备产生的信息等等,这些“新数据”有相当一大部分都是非结构化的,而且产生速度非常快,是大数据的一个重要部分。通过这些数据的分析,可以更加全面的了解用户的心理、习惯、喜好等等,从而为提供更好的产品和服务。但是也不要忽略了,其实对于很多企业来说,有一些传统的关系型数据可能会是他们更加关心的。比如曾经存储在企业数据库、商业智能应用等中的历史数据,企业为了保证在线平台的实时查询,不得不将这些数据导出来。但这些庞大的历史数据中潜藏着巨大的价值,例如公安交警部门可以通过对车辆过车数据几月、几年的分析,从而分析出交通的拥堵情况、哪些线路需要优化等等。这些数据虽然数据量庞大但是是关系型的,那么对于这类数据,自然的就会产生这样一种需求:能不能利用已经非常熟悉的 SQL 来对这种类型的大数据进行分析?
或许有人会问,MapReduce[9]不能够做这样的分析吗?为什么需要再开发一种新的技术呢?原因有很多方面,但是最重要的原因有以下几个方面:
1)与关系型数据库技术相比,Hadoop 还比较年轻,那么对于 Hadoop 中的 MapReduce 技术掌握的开发人员相对来说还是少数的。开发人员需要额外的花费很多时间去学习这一新的技术框架,这不是很多人所愿意的。
2)如果去直接开发 MapReduce 程序去做数据仓库里面操作,比如最常见的连接查询,代码量、性能调优需要的精力等,都还是蛮大的。
3)提供大数据之上的 SQL 技术会吸引更多的人加入到大数据分析这个方向上来。因为 SQL 的语法大家已经非常熟悉,这之上产品、工具、应用也已经有非常多,所以这是推动大数据广泛应用很吸引人的一件事。
正是在这种需求下,现在市场上出现了大量的 Hadoop 之上的 SQL 产品,所有的这些产品基本都会去考虑以下几个方面,这些也是衡量一个产品是否足够强大的标准:
1)性能,查询速度是否足够快。
2)对SQL语法的支持程度。
因为传统的 SQL 是运行在关系型数据库中的表上的,表中是一条条的记录。但是 Hadoop 之上的文件全部存储在 HDFS 上,没有真正的“表”的概念。 SQL 去运行在这些 HDFS 文件上,并不是容易的事情,它需要在底层做很多工作,来完善对 SQL 语法的支持。不光要简单的能够运行,还要对它进行优化,尽量让查询速度比较快。
3)企业级的特性。
比如安全性,是不是支持类似数据库里面的行安全性、列安全性?比如跟企业其他信息系统的集成,是否支持标准的 JDBC/ODBC 接口等?
4)与 Hadoop 生态系统里面的其他组件的集成。
比如能不能直接访问 Hbase里面的数据?数据能不能被类似于Pig这样的高级MapReduce语言进行查询等等?
综上,基于Hadoop系统的SQL引擎种类繁多,就会面临应用开发选型难等问题。
1.2 现状与优缺点分析
目前业界使用最广泛的大数据SQL引擎有Impala[7]、Hive[8]、Spark SQL[10]和Phoenix[11]等,下面分别进行介绍。
Hive是目前处理大数据、构建数据仓库最常用的解决方案,甚至在很多公司部署了Hadoop集群不是为了跑原生MapReduce程序,而全用来跑Hive SQL的查询任务。Hive是一个基于hadoop的开源数据仓库工具,采用HQL(类SQL)对数据进行自动化管理和处理。支持处理存储在HBase上的数据,将HQL语句解析成MR任务运行,获取结果,适合于长时间的批处理查询分析[12]。
但是存在以下问题:
1)data shuffle时的网络瓶颈,Reduce要等Map结束才能开始,不能高效利用网络带宽。
2)一个SQL经常会解析成多个job,输出都直接写HDFS,大量磁盘IO导致性能比较差。
3)每次执行Job都要启动Task,花费很多时间,无法做到实时。
Impala在HDFS或HBase上提供快速、交互式SQL查询,使用与商用并行关系数据库中类似的分布式查询引擎,适合于实时交互式SQL查询。Impala各个任务之间传输数据采用的是push的方式(MR采用的是pull的方式),也就是上游任务计算完就会push到下游,这样能够分散网络压力,提高job执行效率,所以在性能上有大大地提高。但是在支持group by排序、非结构化到结构化的数据转换、并行化以及表或者列級别的授权等安全问题上存在较多问题。
Spark SQL与传统 “DBMS查询优化器+执行器”的架构较为类似,只不过其执行器是在分布式环境中实现的,并采用Spark作为执行引擎 。与传统方法的区别在于,SQL经过查询优化器最终转换为可执行的查询计划是一个查询树 ,传统DB可以执行这个查询计划 ,而Spark SQL会在Spark内将这棵执行计划树转换为有向无环图 (DAG)再进行执行。中间输出和结果保存在内存中,所以具备较高的查询性能。由于Spark SQL处理数据的原则是能放到内存尽量放到内存,优点是做JOIN时会比较快,缺点是占用内存太大,且自行管理内存,占用内存后不会释放。
Phoenix是一个java中间层,可以在HBase上执行SQL查询。不像Hive那样使用MR任务,而是直接使用HBase api进行操作。基本原理是将一个对于HBase client来说比较复杂的查询转换成一系列Region Scan,结合coprocessor和custom filter在多台Region Server上进行并行查询,汇总各个Scan结果。优点是相对于Hbase支持更多的数据类型、直接使用JDBC操作数据、支持二级索引等,但在JOIN支持上、大规模数据传输、计算逻辑复杂时的内存占用上存在较多问题。
由上面的分析可以看出,大数据生态系统中的不同SQL引擎都有各自适合的应用场景,性能指标也不相同,很难选择一种SQL引擎覆盖所有的应用需求,为了解决上述问题,本方案及系统提供统一的大数据SQL引擎,集成多个SQL引擎,并提供统一的访问接口,用户可以根据需要灵活选用相应的SQL执行引擎。
图1 Impala系统架构
2 大数据统一SQL引擎
2.1 系统概述
本方案及系统的总体目标是提供统一的大数据SQL引擎,集成多个SQL引擎,并提供统一的访问接口,用户可以根据需要灵活选用相应的SQL引擎,解决传统应用如何快速移植到大数据平台以及多个大数据SQL引擎选型难的问题。
项目主要研究的内容包括:
1)面向警务云平台中的各种大型应用系统
通过SQL处理海量数据的共性需求,基于Hadoop的海量数据存储和并行计算框架,研究和建立一个统一的大数据SQL引擎。
2)在综合分析和抽象提炼各应用系统在通过SQL方式处理分析海量数据的共性问题的基础上,面向警务云应用的数据多样性,建立一种统一SQL引擎,提供适应于应用系统中不同场景的SQL应用需求。
3)为了解决基于SQL的海量数据分析查询问题,在总结各种应用数据共性的基础上,引入并集成了Hive、Impala、Spark SQL和Phoenix等大数据SQL引擎,并提供统一的SQL引擎接口,以便能应用系统能根据需要灵活选择合适的SQL引擎实现基于SQL的数据查询与分析。
4)开发并研究SQL Agent技术,引入并集成多个SQL处理引擎,并能够根据技术发展的趋势动态扩展。对于适合于长时间的批处理查询与分析使用Hive;对于系统资源较为充足的应用,实时交互式查询可以采用Imapla;对于系统资源较为充足且join使用较多的应用可以采用Spark SQL;对于在Hbase上使用SQL且使用到二级索引的场景采用Phoenix,通过SQL Agent技术将应用相应的SQL分析查询请求转发到相应的SQL引擎进行分析处理。。
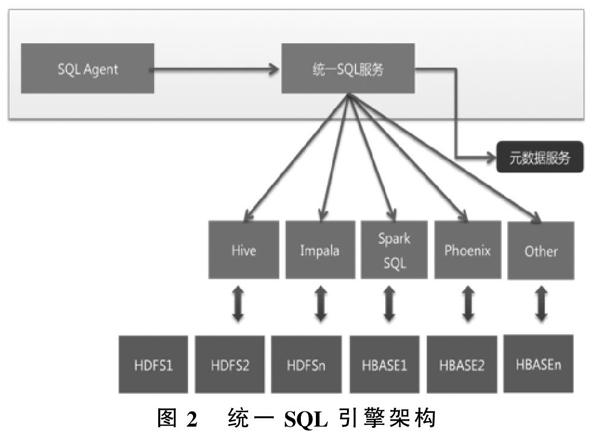
图2 统一SQL引擎架构
5)集成以上几项关键技术,研究开发一个大数据统一SQL引擎的软件应用系统,为了验证该软件应用系统的有效性,以公安320项目中的现有数据为基础进行验证性开发,检验所研发系统的有效性。
2.2 关键技术
1)大数据SQL引擎技术
下面以Impala[13]为例介绍大数据SQL引擎技术。Impala系统架构如图1所示。
Impala提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala使用的列存储格式是Parquet,未来还将支持 Hive并添加字典编码、游程编码等功能。Impala使用了Hive的SQL接口(包括SELECT、 INSERT、Join等操作),但目前只实现了Hive的SQL语义的子集,表的元数据信息存储在Hive的 Metastore中。StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册、错误检测等功能。 Impala在每个节点运行了一个后台服务Impalad,Impalad用来响应外部请求,并完成实际的查询处理。Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。QueryPalnner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
在实际测试中发现,Impala的查询效率比Hive有数量级的提升[14]。从技术角度上来看,Impala之所以能有好的性能,主要有以下几方面的原因[15-16]。
(1)Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
图3 传统数据库与Impala性能对比
(2)省掉了MapReduce作業启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
(3)Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
(4)通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
(5)用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
(6)使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
2)大数据统一SQL引擎技术
大数据统一SQL引擎提供统一的数据服务,业务访问大数据,均通过SQL Agent接入提供统一SQL服务,通过元数据服务,提供数据路由,如图2所示。
基于SQL Agent的统一SQL服务引擎,通过引入并集成多个SQL处理引擎实现,并能够根据技术发展的趋势动态扩展。对于适合于长时间的批处理查询与分析使用Hive;对于系统资源较为充足的应用,实时交互式查询可以采用Imapla;对于系统资源较为充足且join使用较多的应用可以采用Spark SQL;对于在Hbase上使用SQL且使用到二级索引的场景采用Phoenix,通过SQL Agent技术将应用相应的SQL分析查询请求转发到相应的SQL引擎进行分析处理。
2.3 实施与验证
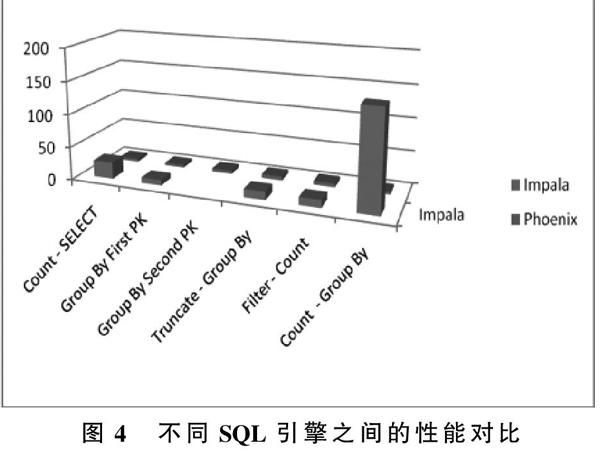
图4 不同SQL引擎之间的性能对比
本方案与系统是在大数据统一SQL处理基础理论和技术方法研究的基础上,从现有的大数据SQL引擎系统入手,结合警务云海量数据的特点和技术问题,研究建立适用于警务云处理海量数据的SQL引擎的架构和模型,并研究解决一系列关键性技术方法,最后设计实现整个大数据统一SQL引擎系统。
整个系统在具体实施时主要分为以下几步:
1)大数据统一SQL引擎设计
在分析Hadoop生态圈现有常见的SQL引擎的的基础上,设计实现SQL Agent,做好元数据服务的统一管理。
通过SQL Agent技术将应用相应的SQL分析查询请求转发到相应的SQL引擎进行分析处理,并进行基本的对比和分析验证;
2)大数据统一SQL引擎设计与实现
研究设计基于Hive、Impala、Spark SQL和Phoenix的SQL Agent系统,应用在使用SQL进行分析查询时,直接与SQL Agent进行交互处理,由SQL Agent判断并选择合适的SQL引擎进行执行,并将正确的结果返回给应用系统。
3)大数据统一SQL引擎的优化
针对应用在调用大数据统一SQL引擎的过程进行跟踪统计,尽可能的获取各个SQL执行引擎的性能数据并进行对比分析,以便在后续使用时进行合理的调度分配,大大提高系统的易用性。
4)原型系统开发与应用验证
在上述关键技术研究实现的基础上,实现大数据统一SQL引擎系统,同时为了验证和改进该软件框架和平台,选择320项目原始的监控点位数据、实时过车信息数据进行实际的验证。
3 应用成效与推广价值
本方案与系统实现了大数据统一SQL引擎的设计,主要完成了以下几方面的工作。
1)从大数据SQL引擎的业务需求着手,收集并整理大数据SQL引擎相关技术和实现要求;
2)为实现该系统,难点在于大数据SQL引擎方案设计、统一SQL引擎设计等问题,通过统一SQL引擎元数据管理,采用SQL Agent解决大数据不同SQL引擎接入的问题;
3)完成了大数据统一SQL引擎的整体解决方案设计,最终实现整个系统的实施与验证。
下面以实际的数据进行说明,数据量以万为单位,纵坐标代表响应时间,以查询操作为例,统一SQL使用Impala的结果如图3所示,可见随着数据量的增大,传统数据库的查询性能显著降低,当达到亿级数据时系统几乎不可用。
对于同样基于大数据存储与计算平台的SQL引擎来讲,不同的SQL引擎性能指标也不相同,下面以Imapla和Phoenix为例进行说明,如图4所示。
大数据统一SQL引擎不管是从现实要求,还是从大数据应用方面来讲,都值得深入研究,目前大数据生态系统中的不同SQL引擎都有各自适合的应用场景,性能指标也不相同,很难选择一种SQL引擎覆盖所有的应用需求。本方案及系统提供统一的大数据SQL引擎,集成多个SQL引擎,并提供统一的访问接口,用户可以根据需要灵活选用相应的SQL执行引擎,解决传统应用如何快速移植到大数据平台以及多个大数据SQL引擎选型难的问题。
4 后续改进方向
大数据统一SQL引擎系统后续会在如下方向进行改进:
1)不同的SQL引擎都有各自的元数据管理方案,完全兼容比较困难,需要改造、适配[17]。
2)不同的SQL引擎支持的SQL语法不尽相同,同样的SQL语句在有的SQL引擎上可以执行,在另外的SQL引擎上可能没法执行,需要SQL Agent进行适配[18]。
【参考文献】
[1]梁吉业,冯晨娇,宋鹏.大数据相关分析综述[J].计算机学报,2016(1):1-18.
[2]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[3]迈尔-舍恩伯格,库克耶,盛杨燕,周涛.大数据时代:生活、工作与思维的大变革[M].浙江人民出版社,2013.
[4]赵彦云,刘子烨.统计学要在大数据科学中扮演重要角色——ASA发布统计学科建设的发展报告[J].中国统计,2015(12):4-5.
[5]Aisha,SIDDIQA,Ahmad,et al.Big data storage technologies:a survey[J].信息与电子工程前沿:英文版,2017(8):1040-1070.
[6]Sowmya R,Suneetha K R.Data Mining with Big Data[C]. International Conference on Intelligent Systems and Control. IEEE,2017:246-250.
[7]Kornacker M,Behm A,Bittorf V,et al.Impala:A Modern, Open-Source SQL Engine for Hadoop.[C].conference on innovative data systems research,2015.
[8]Thusoo A,Sarma J S,Jain N,et al.Hive:a warehousing solution over a map-reduce framework[J].very large data bases, 2009,2(2):1626-1629.
[9]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of The ACM,2008,51(1):107-113.
[10]Armbrust M,Xin R S,Lian C,et al.Spark SQL: Relational Data Processing in Spark[C].international conference on management of data, 2015: 1383-1394.
[11]欧陈庚.基于HBase的复杂关联查询技术研究[D].中国科学院大学,2016.
[12]宋杰,郭朝鹏,王智,等.大数据分析的分布式MOLAP技术[J].软件学报,2014, 25(4):731-752.
[13]贾传青.开源大数据分析引擎Impala实战[M].清华大学出版社,2015.
[14]郭超,刘波,林伟伟.基于ImpaIa的大数据查询分析计算性能研究[J].计算机应用研究,2015(5):1330-1334.
[15]Li X,Zhou W.Performance Comparison of Hive,Impala and Spark SQL[C].International Conference on Intelligent Human-Machine Systems and Cybernetics.IEEE Computer Society,2015:418-423.
[16]王艷,潘晨光.基于HDFS和IMPALA的碰撞比对分析[J].电视技术,2015,39(14):94-98.
[17]佘楚玉,温武少,肖扬,等.一种自适应文件系统元数据服务负载均衡策略[J].软件学报,2017,28(8):1952-1967.
[18]Lu X,Su F,Liu H,et al.A unified OLAP/OLTP big data processing framework in telecom industry[C].International Symposium on Communications and Information Technologies.IEEE,2016:290-295.