基于区块链的科学数据共享模型研究
2019-10-21王显斌
摘 要:数据密集型科研范式下,科研和创新越来越依赖于海量的科学数据。文章首先分析了科学数据共享目前遇到的困境,探讨了区块链应用于科学数据共享的优势和适用性,其次从共识机制、区块结构和智能合约三个方面进行了模型设计,提出了基于区块链的科学数据共享总体模型,最后,指出区块链技术在科学数据共享中的应用还存在诸多问题和挑战。
关键词:区块链;科学数据共享;数据模型
中图分类号:TP311.13;R-05 文献标识码:A 文章编号:2096-4706(2019)21-0156-03
Abstract:Under the paradigm of data-intensive scientific research,scientific research and innovation increasingly rely on massive scientific data. This paper first analyzes the current dilemma of scientific data sharing,discusses the advantages and applicability of block chain in scientific data sharing,then designs the model from three aspects of consensus mechanism,block structure and intelligent contract,and proposes the overall model of scientific data sharing based on block chain. Finally,it points out that there are still many problems and challenges in the application of blockchain technology in scientific data sharing.
Keywords:blockchain;scientific data sharing;data model
0 引 言
在數据密集型科研范式下,科学研究和科技创新越来越依赖于对海量数据的管理、分析和再利用,数据即服务(DaaS)理念下的科学数据生态系统正在优化发展。然而参与主体的数据共享意愿、个人隐私保护、数据产权归属等问题严重制约了科学数据共享生态环境的可持续发展。在大数据时代,科研人员与数据发生的一切关系中,哪怕是一个极其细小的动作,都会产生一系列电子轨迹。区块链技术可以创造出无法篡改的全生命周期数据轨迹,并且能够安全地记录数据从产生到出版过程中的所有节点,由此可改善科学数据共享中一系列问题。因此,区块链对于科学数据共享模式创新具有重要的意义。
1 科学数据共享困境分析
1.1 科学数据共享阻力分析
从诸多研究和调查结果来看,科学数据共享的阻力主要来自于以下几个方面:(1)数据生产者的回报如何得以保证的问题。即如何精确计算每个生产者的贡献并给予其相应的回报;(2)时间、人力和资金成本问题。科学数据的生产不同于一般的数据生产,每一项数据的产出需要耗费大量的人力物力和时间,成本越高共享门槛就越高;(3)数据共享的发布和再利用等过程中涉及的法律问题。科学数据是在科学研究过程中产生的,通常并未严格确权和出版,往往容易引起知识产权等纠纷;(4)保密问题。即涉及的用户隐私和保密问题,及泄密事后追溯问题等;(5)对数据的错用、误用和错误诠释带来的影响以及对数据原始生产者和使用者的潜在危害。
通过区块链分布式账本发布的科学数据,从数据的产生、更新和使用都将被广播到每一个节点,每个人对于数据的贡献和使用都是透明可追溯的。任何人都可以知道数据是从哪里来、如何更新、如何使用以及利益如何分配、权利和义务方是谁,从而可以制定完善的保障和激励规则,促进科学数据的共享。
1.2 科学数据使用问题分析
科学数据在共享之后的使用过程中,存在的主要问题包括:(1)结果重现性差。科学数据可能因为数据不完整、技术太复杂、数据错用误用等原因,导致重现原来的研究结果困难重重;(2)倾向于发布正面结果。科学研究中错误方法和结果具有很高的价值,可以让后来者避免无效重复工作,提高研究效率。但是错误的科学数据往往会被丢弃;(3)学术信用评价难度大。在科学数据共享过程中并不存在完全可信的中介,由于科学数据数量巨大,缺少统一评价体系,信用评价难度大且权威性不足[1]。以上问题的存在,严重影响了科学数据共享的有效利用。
区块链允许去中心化的、持续版本的数据,这样就可以创建一个共享的基础架构,在其中存储每一笔交易。在区块链上工作,意味着无论何时何地,研究人员以任何方式在任何阶段创建的内容和交易,无论是正面还是负面的结果,都将存储在一个分布式平台所有节点中,从而保证了数据的完整性。通过区块链的不可篡改、安全可信、集体维护等特性,可以让所有节点的研究人员参与到对数据正确性的审查和验证当中,从而保证了数据的正确性。通过区块链技术,科学数据的学术信用评价维度将变得多样化,由于评价过程的可追溯性,评价者必然会更加严谨和客观。
2 科学数据共享应用区块链的适用性分析
首先,具有结构适用性。科学数据共享的本质是协作创建、修改、使用和共享大量动态信息和数据,需要建立分布式共享数据库。区块链作为创新性的去中心化基础架构与分布式计算范式,其分布式账本数据模型本质上就是分布式共享数据库。其次,具有对象适用性。科学数据共享需要众多参与对象的协调与支撑,共享行为主要发生在地位相对平等的主体之间。区块链通常采用对等式网络组织分布式、自治性节点参与数据验证,各节点地位对等且以扁平式拓扑结构相互联通。因此,科学数据共享的对象特征与区块链去中心化、自治性等特点高度契合。最后,具有功能适用性。区块链技术能够有效解决分布式系统交互过程中普遍面临的难题——拜占庭将军问题[2],即在缺失可信任第三方机构情形下,分布式节点怎样达成共识、建立互信。区块链的这个功能特点与促进科学数据共享驱动机制完善、共享意愿达成的功能需求相匹配。
3 科学数据管理区块链模型构建
区块链包括公有链、联盟链和私有链,三者使用范围有所不同。公有链各个节点可以自由加入和退出网络,并参加链上数据的读写,读写时以扁平的拓扑结构互联互通,网络中不存在任何中心化的服务端节点;联盟链各个节点通常有与之对应的实体机构组织,通过授权后才能加入与退出网络,各机构组织组成利益相关的联盟,共同维护区块链的健康运转;私有链各个节点的写入权限收归内部控制,而读取权限可视需求有选择性地对外开放[3]。通过以上描述可以发现,具有对应实体机构组织的、有限规模的科学数据共享比较适合采用联盟链。
3.1 共识机制
公有链的运行模式决定了其必须需要代币才能保证共识机制的有效性。科学数据共享联盟链有具体资产(科学数据)上链,可以使用Token对资产标记,不需要发行代币。如果需要对资产进行定价,该Token根据科学数据真实价值可以转换成代币。为保证海量科学数据的共享效率,需要有足够快的出块速度,因此科学数据共享联盟链采用BFT-DPoS(带有拜占庭容错的委托股权证明)共识机制进行轮流记账[4],类似于董事会运作模式。董事会成员数量有限,由大家选举产生,被选中的董事会成员可以行使记账权利。具体做法是全部节点周期性地投票选举出可信的N个超级节点,然后由他们随机或轮流生产区块(记账),这样就避免了POW算法的耗时问题,相当于提前建立新人。同时,这些超级节点也负责对新区块进行确认投票,收到的确认数一旦超过设定阈值,即表示达成共识。
3.2 区块结构
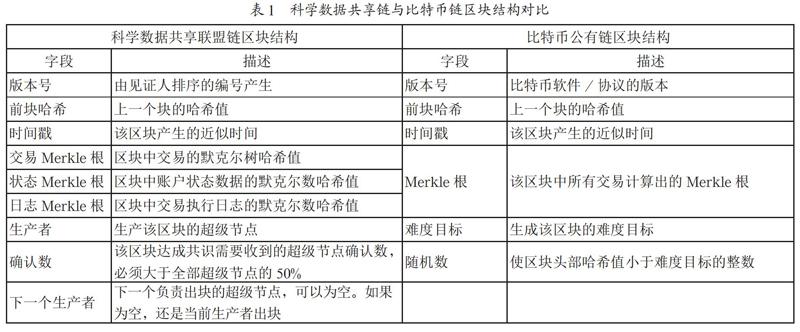
区块链数据模型分为交易模型和账户模型。交易模型,即以数字货币为基础的区块链中的交易,通常就是转账。比特币就是典型交易模型,其数据结构如表1所示,每个区块由区块头和区块体两部分组成,区块体中存放了自前一区块之后发生的所有交易;区块头中存放了前块哈希、随机数、Merkle根等。交易模型虽可方便地验证交易,但却无法快速查询账户状态。参考以太坊、Hyperledger Fabric等采用的账户模型[5,6],本文设计的科学数据共享账户模型中,区块头除含有交易Merkle根外,还含有针对账户状态数据的状态Merkle根、针对交易执行日志的日志Merkle根。根据BFT-DPoS共识机制,区块头还含有生产者、确认数、下一个生产者三个字段。生产者就是超级节点,负责对每一笔科研数据共享交易及科研用户状态变化进行记账,即生产新区块,具体见表1。
3.3 智能合约
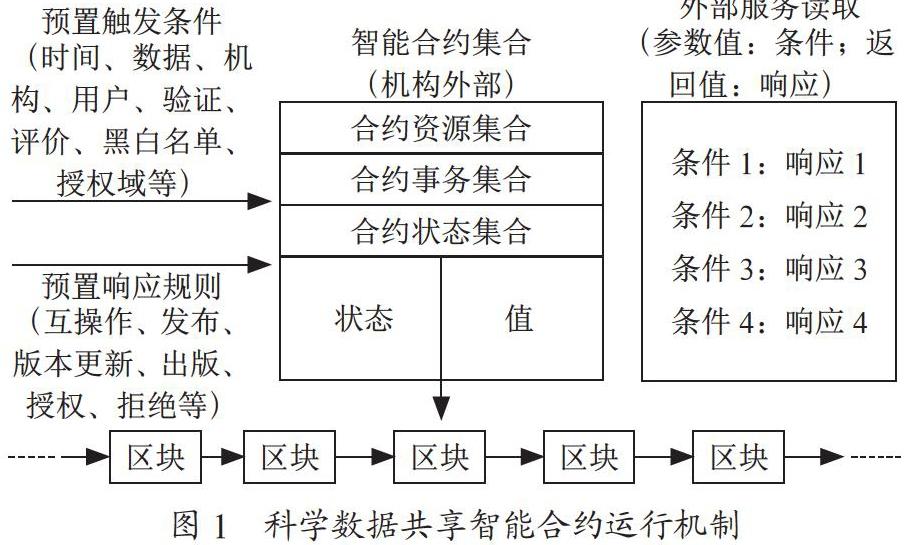
区块链本质上是一个分布式数据库,通过“交易”来进行数据更改。智能合约其实是一段被存储在区块链上的代码,由区块链预置条件触发,它从区块链数据库读取或写入数据,因此可以类比地看作是区块链数据库里的“存储过程”。因为区块链是分布式的,在科学数据共享场景下,智能合约受到如下限制:(1)无法隐藏机密数据。因为每个节点都保存着一份完整区块链数据库副本,通过技术手段不难获取里面的机密数据。此外,智能合约代码对所有节点可见,导致包括安全漏洞在内的所有缺陷都可见;(2)智能合约不适合通过外部服务触发。因为科学数据共享区块链为了达成共识,参与验证的每个节点都需要读取至少一次外部服务,造成对外部服务的反复读取,因网络故障、延时和攻击等因素,使其可靠性下降。
图1 科学数据共享智能合约运行机制
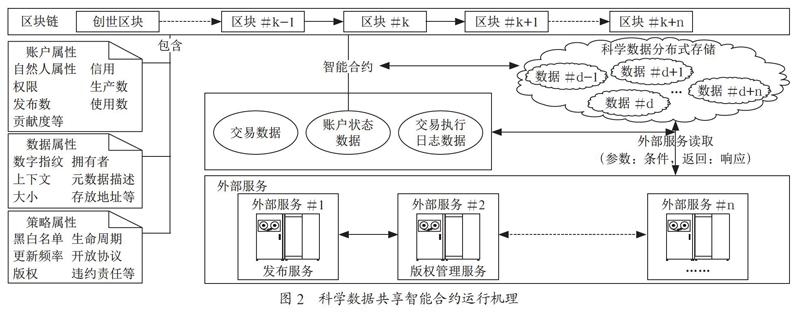
考虑到以上限制,科学数据共享智能合约将被限制在区块链数据库中,只处理与“交易”有关的事务,处理过程中禁止读取外部服务,但处理结果将提供给外部服务读取。此外,科学数据被获取之后的信息因不属于“交易”信息,且可能会揭示科研机构内部机密,将不再由智能合约进行处理,而是由外部服务进行处理。科学数据共享智能合约整体运行机制具体如图1所示。
基于区块链的科学数据共享模型总体设计思路是:本模型采用联盟链,以BFT-DPoS(带有拜占庭容错的委托股权证明)作为共识算法,由超级节点(生产者)负责记账。区块头包括交易、状态和日志三种Merkle根。考虑到科学数据的海量性,区块链只存储其信息索引,该索引可以是透明的,因为最终获取实际数据的环节仍将通过区块链验证其行为的合法性。智能合约以策略属性作为预置触发条件的基础,包括资源、事务和状态三个合约集合。智能合约只处理与“交易”有关的事务,且不能读取外部服务。外部服务通过读取区块链(含智能合约)上的数据,完成相应的事务逻辑处理,例如:获取某一科学数据,包括三个步骤,即:(1)取得其信息索引;(2)验证访问合法性;(3)下载到本地。前两个步骤都需要外部服务读取区块链才能完成相应处理。科学数据共享模型具体如图2所示。
4 结 论
区块链最初主要应用于金融领域,然后逐渐向物联网、能源、法律、知识产权保护等其他领域迅速扩展[7]。信息资源管理领域区块链的使用尚处于起步阶段。基于区块链的科学数据共享具有独特优势的同时,也存在着一些问题,例如海量的科学数据,基本不可能直接存储在区块链上,而只能对其信息索引进行存储。这种方式会产生对云存储的依赖,削弱去中心化效果。另外,由于区块链的不可更改特性,记录在区块的数据不能删除也难以屏蔽,这给信息监管带来很大困难。总之,區块链技术在科学数据共享中的应用有许多不可替代的优势,但也还存在诸多问题仍需解决和改进。
参考文献:
[1] 赵斌.在区块链上进行科学研究和数据共享:理念与举措 [EB/OL].(2018-05-16). http://blog.sciencenet.cn/blog-502444-1114310.html.
[2] 范捷,易乐天,舒继武.拜占庭系统技术研究综述 [J].软件学报,2013,24(6):1346-1360.
[3] 邵奇峰,金澈清,张召,等.区块链技术:架构及进展 [J].计算机学报,2018,41(5):969-988.
[4] 区块链斜杠青年.EOS的BFT-DPOS共识机制的进化过程及背后逻辑 [EB/OL].(2018-05-18).https://blog.csdn.net/itleaks/article/details/80359033.
[5] Ethereum. Ethereum for Beginners [EB/OL].[2019-08-19]. https://ethereum.org/beginners/.
[6] Hyperledger. About Hyperledger [EB/OL].[2019-09-12]. https://www.hyperledger.org/about.
[7] 何蒲,于戈,张岩峰,等.区块链技术与应用前瞻综述 [J].计算机科学,2017,44(4):1-7+15.
作者简介:王显斌(1983.10-),男,汉族,湖南湘西人,图书馆馆员,毕业于华中师范大学,硕士,研究方向:数字图书馆与数据挖掘。
