融合图结构与节点关联的关键词提取方法
2019-10-21马慧芳
马慧芳,王 双,李 苗,李 宁
(1. 西北师范大学 计算机科学与工程学院,甘肃 兰州 730070;2. 桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004;3. 中国科学院 信息工程研究所,北京 100093)
0 引言
随着网络技术的普及,网页新闻与各类电子文档快速地融入人们的生活,用户如何从海量文档中获取有价值的信息,文本关键词提取技术显得至关重要。在大多数的文本挖掘任务中,关键词提取均表现为根据词项对文本内容的相关程度对其排序,所以各种单篇文本的关键词提取算法也随之而生。
单篇文本的关键词提取技术依赖于词项所处的上下文语境,在去除停用词并按照某种特定规则生成关键词的候选集后,可采用基于统计的方法[1-4]、基于潜在语义分析的关键词提取方法[5-6]、基于图的关键词排序方法[7-10]从候选集中选取关键词。基于统计的方法关注词项在文本的内部统计特征和在语料库的外部统计特征,例如,词频—逆文档频率[1](term frequency-inverse document frequency,TF-IDF)、JSD[2](Jensen-Shannon Divergence)等算法关注词频与词项位置等内部特征统计信息,基于Query logdoe的抽取关键词方法[3]、语义关联抽取关键词方法[4]等结合搜索引擎记录关注词项在语料库中的词频、链接次数等外部特征统计信息,通过计算权值选出高权重的词项作为关键词。从潜在语义而言,PLSA[5],LDA[6]采用文档主题生成模型技术来识别大规模文档集中潜在的语义信息,其重点关注建立词项、主题和文档三层结构,并得到词项与文档之间的隐藏语义关系。基于图对关键词排序算法的基本来源为PageRank[7]。PageRank模仿上网者以一定概率在各个页面游走,经过有限次游走可到达一个稳定状态的概率分布,该分布即为节点的排名依据。TextRank[8]将PageRank应用于文本的关键字和关键句提取,可自动生成文本摘要。GraphSum[9]认为节点之间的关联性联系有强弱之分,负关联关系的节点之间投票时应降低相应的Page-Rank分数。AttriRank[10]指出计算节点的重要性时不仅要考虑图的结构,更要关注节点属性之类的外部信息。
本文综合考虑节点的图结构属性、语义信息与节点间的关联性特征,提出了一种融合图结构与节点关联的关键词提取方法(A Keywords Extraction Method via Combining Graph Structure with Nodes Association,GSNA)。首先,为了避免挖掘冗余的频繁项集造成执行效率低下,本文挖掘文档的频繁封闭项集并生成强关联规则集合;其次,将强关联规则集合中不重复的规则头与规则体作为节点,节点之间有边当且仅当彼此存在强关联规则时,以关联规则的关联强度作为边权重构建文档的关联图;然后,使用GSNA在关联图上随机游走,迭代计算每个节点的重要性分数;最后,为了避免提取的关键词之间有语义包含关系,对结果降序排序,并选取前若干个节点聚类,取出所有的类中心作为文档的关键词提取结果。基本技术流程如图1所示。
本文致力于脱离语料库的单篇长文本关键词提取,依据节点的图结构属性、语义信息和彼此间的关联性对词项排序,主要贡献如下:
(1) 通过挖掘频繁封闭项集生成强关联规则用于构建关联图,得到的强关联规则规模小、速度快且无信息损耗,避免了重复扫描事务集与提取冗余的频繁项集导致图结构过于复杂的问题,提高了算法的整体执行效率。
(2) 综合考虑关联图中节点的图结构属性与语义信息,计算节点在关联图中的相似度,增大与关联图相似程度更大的节点被选中的概率,解决了节点之间等概率跳转的缺陷。

图1 基本技术流程图
(3) 考虑节点间的关联性事实,在关联图上随机游走时,节点间投票有正负关联之分,加强节点间的正关联投票分数,降低节点间的负关联投票分数,使得节点得分更加合理。
1 相关理论
文档可视为由句子构成的事务数据库,文档的关联图刻画了节点所代表词项之间的关联关系。本文的关键词提取算法作用于关联图之上,首先将文本处理为一个事务集,然后将CLOSE[11]算法作用于该事务集,挖掘强关联规则集合,最后将强关联规则集合建模成关联图。
1.1 文本预处理
文本在经过数据去噪、分词、停用词过滤等预处理步骤后,可视为由一组停止标记(“。”,“?”,“!”,“……”)分隔的句子集合S={s1,s2,…,sn}。si是由一组不重复的词项序列构成的句子,wiq是si的第q个词。假设si存在与之对应的事务ti,那么wiq可视为事务ti的第q个词项。所以,由S中每个句子对应的事务就构成了文档的事务集T={t1,t2,…,tn}。表1是一篇文档的原始内容,经过预处理后,得到该文本的事务集T,如表2所示。

表1 原始文档

表2 文档的事务集
1.2 CLOSE算法
关联规则[11]反映了事务中不同项集之间的关联关系,基本形式为A→B,其中A∩B=∅,A≠∅且B≠∅。关联规则的挖掘建立在事务集之上,文档的事务集为T,词典为I={w1,w2,…,wm},基本概念定义如下:
定义1(k-项集)一个项集中项的数目称为项集的长度,长度为k的项集称为k-项集。
定义2(项集的支持度)令TA表示T中包含项集A的事务集合,则A在事务集的支持度如式(1)所示。

(1)
定义3(关联规则的支持度)对于关联规则A→B,A⊆I,B⊆I,A∩B=∅,令TA∪B表示T中包含A∪B的事务集,则关联规则A→B的支持度如式(2)所示。

(2)
定义4(关联度)对于关联规则A→B,A⊆I,B⊆I,A∩B=∅,则A→B的关联度如式(3)所示。

(3)
由于lift(A→B)=lift(B→A),所以lift满足对称性。由条件概率分析可知,当lift(A→B)=1时,A与B服从独立概率分布,表明A与B无关联关系;当lift(A→B)>1时,表示引入A后B的后验概率高于B的先验概率,说明A与B之间存在正关联关系;反之,当lift(A→B)<1时,表示A与B之间存在负关联关系。
定义5 (强关联规则)对于关联规则A→B,A⊆I,B⊆I,A∩B=∅,若满足sup(A→B)≥minsup且lift(A→B)≤max-lift或lift(A→B)≥min+lift,则A→B为强关联规则。其中,minsup为关联规则的最小支持度阈值,max-lift为最大负关联度阈值,min+lift为最小正关联度阈值。
定义6(频繁封闭项集)项集X为频繁封闭项集当且仅当sup(X)≥minsup且S(X)=X。其中,(X)为X的闭包运算[12],minsup为X在事务集中的最小支持度。
为了快速地从文档事务集中提取有效的强关联规则,本文应用CLOSE算法挖掘频繁封闭项集,进而生成强关联规则集合,该算法使用闭包运算,结合广度优先策略搜索项集空间,实现非频繁项集与非封闭项集的快速剪枝。相比于传统的关联规则挖掘,CLOSE算法提高了执行效率。在获取到不同长度的频繁项集集合L={L1,L2,…,Lk}后,由Li中的i-频繁项集生成m-项集(1≤m≤i-1)的规则头与(i-m)-项集的规则体;然后,根据L计算lift(m-项集→(i-m)-项集),对CLOSE算法中抽取强关联规则的步骤改进;最后,取出lift≤max-lift或lift≥min+lift对应的强关联规则。本文对CLOSE算法中抽取强关联规则的改进步骤如表3所示。

表3 强关联规则生成步骤
1.3 关联图构建
从文档事务集中挖掘得到的强关联规则集合为AR,将AR中所有不重复的规则头与规则体作为关联图的节点集合N。关联图中的任意两个节点之间有边当且仅当彼此存在满足lift≤max-lift或lift≥min+lift的强关联规则,由于lift具有对称性,所以节点之间只要有强关联关系就一定存在双向边,且边的权重定义为lift值。
表4为预处理后的文档事务集样例,假设minsup=0.6,min+lift=1.2,max-lift=0.95,由CLOSE算法得到该事务集的频繁封闭项集为FC={{a,c},{b,e},{c},{b,c,e}},导出强关联规则集合AR={a↔c,c↔be,c↔b,c↔e,b↔ce,b↔e,e↔bc},抽取出AR中不重复的规则头与规则体作为关联图节点N={{b,c},{b,e},{c,e},{a},{b},{c},{e}},以强关联规则的关联强度作为边权重,构建得到如图2所示的无向加权关联图。

表4 文档事务集样例

图2 文档的关联图
1.4 PageRank算法
PageRank[7]为网页排名算法,其认为节点A有边指向B可看作A对B投票,节点的入边权重总和越高则该节点的重要性越高。PageRank模仿上网者,能够在关联图上的相邻节点之间移动,也可以从当前节点跳转至非邻居节点。在经过有限足够多次游走后,各点达到稳定状态,即节点的重要性分数趋于定值。每经过一次游走迭代,就会产生一次节点排序,该排序值即为PageRank分数。节点Ni为关联图中的第i个节点,e表示Ni的入边条数,PR(Ni)表示Ni的PageRank分数,C(Ni)表示Ni的出边条数,d用于衡量一个节点跳转至另一个节点的衰减系数,Ni的PageRank分数定义如式(4)所示。
(4)
其中,节点间的跳转为等概率事件即1/|N|,而理论上,相似节点之间跳转的可能性会更大。另外,节点之间还存在正关联关系和负关联关系,所谓正关联关系为一个节点的出现后往往伴随着另一个节点出现,而负关联关系为一个节点出现后使得另一个节点出现的概率降低。对于节点间的正关联关系,需要增大PR投票分数,而对于负关联关系,应降低PR的投票分数。
2 融合图结构与节点关联的关键词提取
关联图中不同的节点对文本的重要性往往是不同的,GSNA算法分别从节点的图结构相似性与关联性对PageRank加以改进。衡量节点的相似性时,GSNA考虑了节点在关联图中的结构属性与隐含的语义信息;衡量节点的关联性时,需要增强正关联传播,降低负关联传播。GSNA合理地调节PR分数,使得节点排名更准确。
2.1 节点间的图结构与语义相似性
从图结构形式而言,若两节点与其余节点的连接形式相似,则它们极可能为图结构形式相似节点。
为了量化节点的图结构属性,本文使用表5所示的6个指标。其中,attr1~attr3直观地表示了一个节点与其余节点的关联能力,attr4体现了一个节点与周围邻居节点的相似匹配程度,attr5、attr6定量地说明了一个节点在关联图中的传播能力。对于节点Ni,可将其形式化表示为Attri=(attr1,attr2,attr3,attr4,attr5,attr6)。

表5 节点的结构属性表
从节点的语义信息而言,若两节点与词典中词项的共现分布情况相似,则它们有可能为语义相似节点。预处理后文档的词典为I={w1,w2,…,wm},节点Ni与I的共现分布为P={p1,p2,…,pm},pj表示同时包含Ni与wj的句子在事务集中的归一化值,Nj与I的共现分布为Q={q1,q2,…,qm},则Ni与Nj的语义距离[3]如式(5)所示。
(5)
综合节点的图结构属性与语义信息,节点Ni与Nj的相似度衡量如式(6)所示。当Ni与Nj的图结构属性或语义分布差异越大时,相似度sij越低,反之当Ni与Nj的结构属性或语义分布越接近时,sij相应越高。
(6)
关联图中存在强关联关系的节点之间有相似度,无强关联关系的节点之间相似度为0,则可形成关联图的相似度矩阵S|N|×|N|。为了更形式化地度量一个节点与所有节点的相似程度,本文将每个节点在关联图中的相似度计算归一化,如式(7)所示。
(7)
其中,ri表示Ni与图中所有节点的相似程度,使用ri修正PageRank公式,使得节点不再服从等概率跳转,而是使与关联图相似程度更大的节点被选中的概率更高,如式(8)所示。
(8)
由于关联图为无向图,所以式(8)中C(Nk)表示节点Nk的度,e表示Nk的邻居个数。
2.2 节点间的关联性
在关联图中,两节点之间有边当且仅当它们之间存在强关联规则。为了加强正关联节点间的PR投票分数,降低负关联节点间的投票分数,本文使用lift值对式(8)改进得到式(9)。
(9)
式(9)融合了节点的图结构属性、语义信息与节点之间的关联性,使得节点重要性排名更加合理。lift(Ni,Nk)表示Ni与Nk的关联强度,当Ni与Nk为负关联关系时lift<1,为正关联关系时lift>1,所以lift能够根据正负关联性恰当地放缩PR(Nk)的大小,实现了加强正关联传播、降低负关联传播的目的。
根据式(9)在关联图上随机游走,迭代计算每个节点的PR值、直至满足式(10),使节点分数达到收敛状态,其中δ为随机游走终止阈值,往往取为10-4。
(10)
2.3 关键词语义聚类
为了避免提取的关键词之间有语义包含关系,对词项的PageRank分数降序排序后进行语义聚类,最后取出所有的类中心作为文档的关键词提取结果。
关联图的节点是根据不同长度的频繁封闭项集取子集形成的,k-项集一共含有2k-1个非空子集。例如,1-项集一定是(k-1)-项集的子集,这种现象可视为(k-1)-项集对1-项集有语义包含关系。为了防止得到的关键词之间存在语义包含关系,本文将排序后前P个节点进行K-Medoid聚类[12]并抽取所有的类中心作为最终的关键词。K-medoid利用语义距离作为类中心选择的基准,保证类中心的语义能够兼收该类中其他词项的语义。
本文抽取出文本的强关联规则集合AR后,依据AR构建文本的关联图,使用GSNA在关联图上随机游走计算每个节点的PR分数,并对节点聚类得到文档的关键词。首先,初始化每个节点的PR分数为1/|N|;其次,计算相似度矩阵S|N|×|N|,并归一化得到每个节点在关联图中的固定相似度值ri;然后,在关联图上随机游走,迭代计算每个节点的PR值直至收敛;最后,对前P个词项聚类,取所有的类中心作为文档的关键词。
3 实验与结果分析
为了验证本文算法的可行性,首先选取中英文数据和恰当的评价指标,其次寻找最佳关联图模型对应的输入参数,然后在最佳关联图的情形下对关键词的抽取规模做出讨论,最后选取4种关键词提取算法与GSNA对比,验证GSNA的优越性。
3.1 实验数据与评价指标
为了验证GSNA算法的有效性,本文选取达尔文的汉译版著作《物种起源》[13]作为中文实验数据,选取Li编写的文献[14](Li’paper)作为英文实验数据。以《物种起源》为代表的大规模数据和以Li’paper为代表的小规模数据,已被许多学者用于验证各种新型关键词提取算法的准确性[2-8]。在经过数据去噪、中文文本分词、英文数据大小写转换与词干还原、停用词过滤和事务词项去重等预处理步骤后,《物种起源》共含有39 599个词项、3 495个句子,分布在14个章节的各个段落;Li’paper共含有3 315个词项,402个句子。此外,本文分别选取《物种起源》的重要词汇注解表中的15个重要词项与专家对Li’paper列举的7个关键词作为评价中文与英文关键词提取是否有效的基准。
本文将提取的关键词序列标记为Mret,将词汇表序列标记为Mrel,所涉及的评价指标包括MAP[15](Mean Average Precision)、召回率Recall[3]和Fβ。其中,MAP定义如式(11)所示。
(11)
式(11)中,Mret(j)表示关键词返回序列Mret的第j个词项;g(t,Mrel)为指示函数,若词项t出现在原词汇表序列Mrel中则返回1,否则返回0;P(i)与AP(i)分别表示Mret中前i个词项的准确率与平均准确率。
本文期望检索到的关键词不仅准确率高而且排名尽可能居前,所以将MAP引入Fβ的计算。相比于召回率,本文更侧重于提升准确率,故Fβ指标中β取值为0.5,其计算如式(12)所示。
(12)
3.2 关联图模型参数分析
关联图的形式结构直接决定了关键词提取的效果,不同参数设置可能会对结果带来不同程度的影响。CLOSE算法中的minsup设置过高则会丢弃大量有意义的词汇,设置过低则会包含众多冗余词汇,min+lift与max-lift的变化会直接影响关联图的形式结构,同时GSNA算法在随机游走时衰减系数d的调节也会影响关键词的提取效果。
在预实验过程中发现,相比于节点的图结构属性,节点的关联性对关键词的提取效果影响更大,所以本文设置minsup=0.8%,d=0.65。令降序排序后的关键词序列为Mv,为了避免过多参数变化导致分析过程复杂,暂不考虑关键词的提取数量,在调节模型参数时,均抽取每次所得关键词序列Mv的前|Mrel|个词项作为提取的关键词序列Mret,并绘制关联图模型的输入参数与MAP的变化曲线。
对于中文数据,图3和图4显示当max-lift与min+lift分别在[0.55,0.75]和[2,14]区间内变化时,GSNA算法的平均准确率呈上升趋势,而max-lift与min+lift的轻微增加就会引起MAP的急速下降,这是因为数据中重要词汇彼此间的负关联度与正关联度更多地集中于[0.65,0.75]与[11,14]范围内。所以,当min+lift=14,max-lift=0.7时,在中文数据上构建的关联图模型能取得最佳提取效果。

图3 max-lift对关键词提取效果的影响[中文数据]

图4 min+lift对关键词提取效果的影响[中文数据]
由于英文数据规模相对较小,本文设置max-lift以0.4为基数,以步长为0.1的速度增长;min+lift初始值为2,以步长为2的速度增长。图5和图6表明,当min+lift=6,max-lift=0.7时,MAP达到峰值0.904 8。

图5 max-lift对关键词提取效果的影响[英文数据]
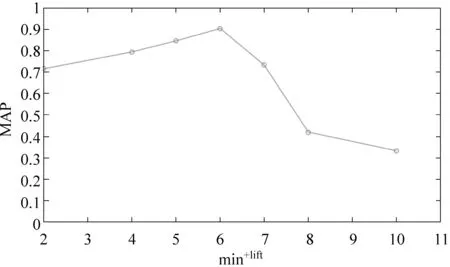
图6 min+lift对关键词提取效果的影响[英文数据]
由于两种语料库的规模不同,所以效果最好时的min+lift相差较大。min+lift的取值越大就会去除越多的关联词项,而小规模语料库的关键词候选量较少,为了更准确地提取关键词,所以较中文数据而言,英文数据的min+lift取值较小。
3.3 关键词提取规模
关键词提取注重挑选出与文本最相关的词汇,所以选取关键词的数量规模显得至关重要。本文引入关键词抽取规模参数scale=Mret/Mv,图7展现了Fβ在两种数据上随着scale的增长而变化的曲线。

图7 scale对关键词提取效果Fβ的影响
对于《物种起源》而言,在最佳关联图的情形下,经过语义聚类后得到Mv=23个重要词汇。当scale=85%时,Fβ取得最大值0.854 8,实验表明可选取规模为Mret=0.85×Mv的词序列作为该数据的关键词提取结果。对于Li’paper,聚类后返回Mv=7个重要词项,当scale=80%时,Fβ取得最大值 0.810 2。
3.4 算法对比及分析
为了验证本文算法的优越性,将TextRank[8]、GraphSum[9]、考虑图结构而不考虑节点关联性的关键词提取方法(Key Words Extraction Method by Nodes Association,NA)、考虑节点关联性而不考虑图结构的关键词提取方法(Key Words Extraction Method by Graph Structure,GS)与本文算法进行对比。
表6和表7列举出5种关键词提取算法分别作用于中文与英文数据上关于MAP、R、Fβ指标上的对比结果。其中,最优指标值用粗字体标出,带有灰色背景的关键词表示未出现在Glossay的词项。TextRank在中文数据上的词项共现窗口长度为20,在英文数据上的词项共现窗口长度设为5,GraphSum、NA与GS算法均在GSNA所得的最佳关联图上迭代计算节点的重要性分数。
均未考虑节点的图结构属性与关联性的Text-Rank算法得到的关键词效果最差。值得注意的是,分别只考虑节点关联性与图结构属性的NA与GS算法的MAP和R指标明显高于GraphSum和Text-Rank,说明NA和GS能检索到更为重要的关键词。GSNA算法从Fβ上比NA和GS的效果更加可观,说明关键词提取过程中节点的图结构属性与关联性均不容忽视。相对于GSNA算法,GraphSum缺少词项的语义聚类环节,导致提取结果存在语义冗余的词项,故其MAP和R指标均低于GSNA。

表6 中文数据集上不同关键词提取算法的结果对比分析

表7 英文数据集上不同关键词提取算法的结果对比分析
值得关注的是,5种方法在以《物种起源》为代表的大规模数据集上的性能均高于在以“Li’paper”为代表的小规模数据集上的性能。这是因为大规模的数据在构建关联图时能够形成更为复杂的图结构形式,同时更能充分地揭示大量节点间的关联关系与词项间的语义关系,所以文本规模越大,GSNA的效果会越好。
3.5 算法效率分析
为了观测GSNA的运行效率,本节在Celeron 1.40GHz处理器的Windows操作系统下,比较了TextRank、NA、GS、GSNA与GraphSum这5种方法在不同词量规模下的执行时间,如图8所示。由于GSNA考虑了图结构、语义信息、节点间的关联性信息,所以在同等词量规模下,GSNA的执行效率会比其他方法更低。但随着词量规模的扩大,GSNA的运行时间接近于线性增长,当词项规模不超过40 000时,GSNA可在10s内完成关键词提取的过程。

图8 5种方法在不同词量规模下的执行时间
4 总结
本文提出了一种融合图结构与节点关联的关键词提取方法,能够在脱离外部语料库的情况下检索到单篇文本的关键词。首先将挖掘到的强关联规则建模成关联图,然后利用GSNA在关联图上随机游走计算节点的重要性分数,最后对结果进行降序排序与语义聚类。实验选取中、英文验证数据,分别探索了关联图模型参数的影响、关键词的提取规模、5种关键词提取算法的性能,综合分析,本文算法性能最佳。未来工作将致力于构建新型关联图模型,优化GSNA算法,提高整体执行效率。
