基于低阶条件独立测试的因果网络结构学习方法
2019-10-19洪英汉郝志峰麦桂珍陈平华
洪英汉,郝志峰,麦桂珍,陈平华
(1. 广东工业大学 计算机学院,广东 广州 510006;2. 韩山师范学院 物理与电子工程学院,广东 潮州 521041;3. 佛山科学技术学院 数学与大数据学院,广东 佛山 528000)
从计算角度进行归类,因果推断可表示为关于变量的概率图模型,变量间的因果关系则可用模型中的有向边表示. 高维数据不同于传统的低维数据,它的复杂度更高,常用的基于条件独立测试或约束的方法只能得到变量间局部的因果关系. 考虑如下情形,X⊥Y|Z(给定条件变量集Z,X和Y条件独立),可推知X(Y)没有附加信息到Y(X),进一步可知直接的因果关系在X和Y两者之间并不存在. 马尔科夫等价类问题尽管可以被现有的因果推断方法所解决,如IC算法,然而,算法所执行的时间不仅会随着维度的增加而增长,而且会随着样本量的增多,呈指数增长. 因此,高维数据中隐含的因果关系难以被现有的方法推断得到. 例如,现有的方法难以利用条件独立(Conditional Independent,CI)测试方法从变量数目超过50个的数据集中推断出其因果关系. 目前研究表明,高维数据因果推断面临的问题可总结为以下两个.
1) 难以在有效时间内从数据中搜索出可用于测试X⊥Y|Z的CT测试中条件集Z的所有可能结果.
2) 当Z为高阶条件集时(个数变多),测试每一对变量的CI测试方法通常并不可靠;若CI测试得到的错误结果也被接受,陷入第二类错误的情况则极有可能发生. 若X、Y直接连接则不会被任何其他变量集D分离,也就是说,X̸⊥Y|Z,而CI测试的结果相悖地认为X和Y是可D分离的.
有研究者为了克服上述问题提出SADA-LINGAM算法[1]——一种基于分裂−合并策略的递归方法. 为简便起见,下文将采用SADA的英文缩写表示SADA-LINGAM算法. 该算法用至少2个子集划分原来的变量,分别对应利用现有的因果推断方法求解的各个子问题;通过对所有子问题的结果进行合并,最后推断出原始问题的因果关系. 考虑以下例子,给定某个集合V,把其划分为V1,V2和C=(C1,C2,C3);其中,V1,V2并不相连,V1,V2,C1,C2,C3都是V的子集.接着,分别推断(V1,C)和(V2,C),逐次递归直至子问题的变量数目足够小. 然而,设计出一个合适的分区过程并非易事,因为每次迭代都需要搜索集合C. 与此同时,条件集Z所形成的“维度灾难”问题也不容忽视.
文献[2]开创性地提出一种新的REC因果分区方法. 其主要思想如下:移除满足x⊥y|Vx,y条件的x,y∈V的每对变量间的边,进而重建无向独立图. 类似地将无向独立图分解为V={V1,V2,C}(其中,V1,V2在C条件下独立);递归分解初始变量集V直到得到无法再分解的每个子集,再将特定的约束方法应用于求解上述得到的子问题,并将所得子结果合并,最终获得原始问题的结果. 对比文献[3-4]所提出的方法,该分区方法更为有效. 文献[4]的方法采用直接删除条件集,这点不同于文献[2]需要每个分离图都包含完整无向图的处理方法;在依据变量集V的情况下,它可以分解整个无向独立图,但不能分解对应的子图. 为此,一种基于无向独立图的新分区方法被Liu等[5]提出,该方法不同点在于它基于评分搜索[6]解决子问题.
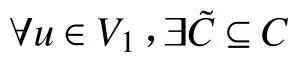

上述内容引发这样的思考:当重构一个粗糙因果骨架时,用来D分离两个变量的最小分离器的大小能否确定?如果能,即可以基于不同的阈值d更准确地区分两个非相邻变量是否D分离.
基于此,本文提出了基于低阶条件独立测试的因果分割方法(Learning Causal Structure based on Causality Division,LCSCD)——一种具有可扩展性和有效性的因果推断方法. LCSCD算法只使用了低阶(变量个数小于等于2)CI测试方法,即可把原始的问题分割为多个子问题;在此基础上,再使用现有的因果推断算法如PC算法,逐一处理这些子问题;最后,合并所有子问题的结果,推断出完整的因果关系图.
为验证LCSCD算法具备更高的效率和可扩展性,实验针对较小、中等、较大3种规模的真实网络进行. 其中,按照目前因果推断的相关工作,较小、中等、较大是按照最小分离器的变量数量区分的,依次是指变量数目小于等于2、变量数目是3或4、变量数目大于或等于5时.
对比目前较为流行的算法SADA方法,LCSCD算法有两个优势:1) LCSCD算法在因果划分时更具可靠性;2) LCSCD在执行时间上耗时更短.
1 准备知识
用G=(V,E)表示有向无环图(DAG),其中V是变量集,E是有向边集,图G中没有循环. 有向边
如果在V′集内没有两个或以上的变量共享V外面的因果变量,则变量V′⊆V集是充分因果关系.u⊥v表示u和v独立,u⊥v|Z表示在Z条件下u和v独立[8-10]. 一般地,假设通过在G中进行D分离检测在V中变量的概率分布的所有依赖性,称为忠诚假设,即所有独立和条件独立可以在图G中表示[11-13]. 因此,在DAG中用 ⊥来表示D分离. 遵循现有研究的共同假设,关于G可以通过测试两个变量是否D分离,基于约束方法如PC算法来发现因果骨架或一组马尔科夫等价类. 然而,随着所需的样本大小随着V的大小呈指数级增长,直接用PC算法一般无法恢复高维数据所有变量之间的因果关系.
2 LCSCD算法
2.1 算法框架
首先定义有效因果分区[1],然后提出LCSCD方法的框架.
定义1 给定G=(V,E)在变量集V中表示一个DAG,从图G中进行因果分区得到3个不重叠的变量子集V1,V2,C. 当且仅当1)V1∪V2∪C=V;2) ∀u∈V1,∀v∈V2,且u和v不相邻.
直观来说,V1中的任意节点到V2中的任意节点间的通路被C阻塞. 因此,可以用2个较小子集V1∪C和V2∪C的因果推断代替变量集V上的因果推断.
LCSCD方法的描述如算法1的伪代码所示,其中输入的参数包括集合V、阈值δ和自定义采用的现有因果推断算法A(如PC算法). 当递归分区过程的子集的变量数小于所设置的δ时,终止递归. 算法1主要包括两个过程:1) 寻找一个因果分区(对应于伪代码第6行);2) 更新子网络至大网络(对应于伪代码第8行). 详细的算法流程如下:
算法1:LCSCD
1: Input: datasetV, thresholdδ , algorithmA
2: Output: Causal skeletonS
3: Construct a fully connected graphGonV.
4: To search a causality division (V1,V2,C) overV.
6: LCSCD(V1∪C,δ ,A)
7: else
8: Update the skeletonStoGbyA(V1∪C).
9: end if
10: Do the same process (Lines 4-8) toV2∪C.
2.2 寻找因果分区
LCSCD算法的重点之一在于因果分区的搜索过程. 算法采用CI测试处理输入变量以识别潜在的因果分区. 该过程如算法2的伪代码所示.
算法2:Searching Causal Division (寻找因果划分)
1: Input: The variables setV; σ: The maximum order of CI tests;
2: Output: The causal division (V1,V2,C);
3: Construct fully connected graphGonV.

5: end if
7: for ∀vi∈Vdo
8: AddviintoV1ifviand ∀vj∈V2are non-adjacent;
9: AddviintoV2ifviand ∀vj∈V1are non-adjacent;
10: AddviintoC, if ∃vj∈V1and ∃vk∈V2such thatviis adjacent tovjandvk.
11: end for
12: Return the causal division (V1,V2,C).

同样,获得关于子问题的一个子集Vt={v1,v2,···,vn},由于相应的粗糙图G是在前一次迭代获得,用遵循类似(伪代码第7~11行)的过程来获得因果分区Vt={V1,V2,C}.
3 实验分析

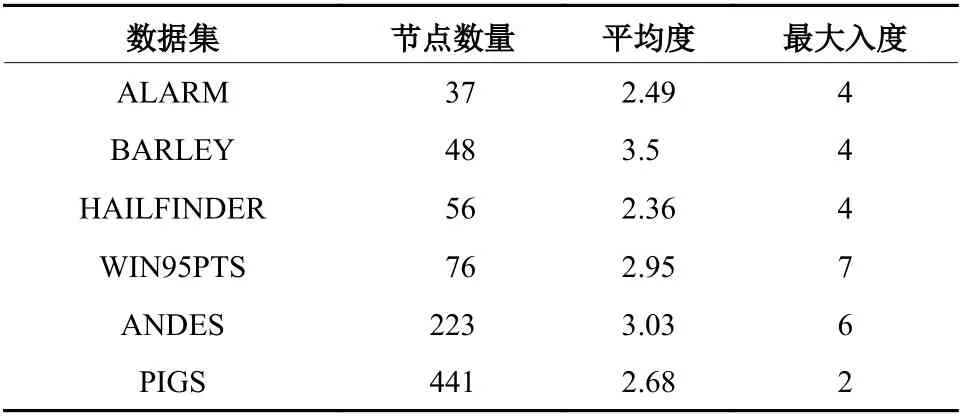
表 1 6个不同网络结构的参数情况Tab.1 Parameters of 6 different network structures
为探索LCSCD算法在因果分区的性能表现,采用与当前流行的SADA算法[1]进行对比实验. 在6个不同网络下分别以样本数{25,50,100,200,400}来评估两种算法之间的性能和准确率. 此实验寻找的因果骨架是无方向的,因为目前可用于判断现成网络骨架中的因果方向的算法有很多,如V结构方法[14-16]、ANM方法[17-21],以及IGCI(信息几何因果推断)方法[22-26]等. 实验采用文献[27]中用到的CI测试方法,设置阈值为5%;为了防止子网络数目呈指数级增长,把各数据集的子网络维度大小都设置为δ=|V|/10,当算法达到阈值时停止分区. 一般而言,这样划分得到的子网络的维度已足够小,接着应用现有的因果推断算法(如PC算法)判断其中的网络方向.
LCSCD算法和SADA算法在6个不同数据集、不同样本下进行Recall(召回率)、Precision(精度)和F1评价指标的比较,结果如图1所示,这些指标的定义如下:

式(1)~式(3)中,实际因果网络中各节点间的因果关系称之为真实因果节点,利用算法推断得到的各节点间的因果关系则是因果推断节点. 推断所得因果网络正确边的方向与实际因果网络的比值定义为召回率,而精度则是推断所得因果网络正确边的方向与推断网络之比.F1是评价算法中的一种标准.
观察并分析图1可知:1) 从总体上观察综合评价指标F1的值可知LCSCD算法在6个不同网络、不同样本的情况下得到的数值比SADA算法所得的结果更优;2) SADA算法的Recall值和Precision的准确率均随样本量的增加而增加,但后者增幅较小;3) LCSCD算法和SADA算法的F1值均与样本量呈正相关关系,但前者在小样本量时增长率较快.
通过对比表2统计的执行时间情况,易知:1) LCSCD算法的执行时间远小于SADA算法,特别当样本量大、数据维度高时,后者的执行时间是前者的近10倍;2) LCSCD算法在相同数据集、不管样本大小下的执行时间基本保持稳定,而随着数据集维度的增加,SADA算法的执行时间将不断增长;3)特别在维度达到441维的PIGS数据集,当样本量超过25时,LCSCD算法仍能够得出结果,而SADA算法则无法在有效时间内得出结果.

图 1 6个不同网络结构在不同样本下的评价指标比较Fig.1 Evaluation comparison of 6 different network structures under different samples

表 2 LCSCD算法和SADA算法在不同数据集和样本下的执行时间Tab. 2 LCSCD algorithm and SADA algorithm are performed under different samples and datasetss
4 结束语
本文提出一种兼具有效性与扩展性的因果推断算法——LCSCD算法. 即使当数据集属于高维度范畴时,该算法仍可采用低阶CI测试对数据集进行分区推断(应注意条件集的变量数目一般不大于2).LCSCD算法的主要流程可分为3步:首先,把目标的大问题分割成数目小于某设定阈值的子问题,该过程可采用分区的方法处理;其次用现有的算法如PC算法,对分割的每个子问题进行因果推断;最后,对所得的子网络结果进行合并以获得所需的完整的因果网络骨架图. 为了验证本文所提算法的性能,将算法应用于6个规模相异的网络,并不失一般性地以样本量作为变量. 通过对比实验,可知本文提出LCSCD算法无论在效率还是准确率都要优于目前较为先进的SADA-LINGAM算法. 本研究后续工作将进一步探讨优化算法的分区模式以提高算法的准确率和性能.
