运动腕表心率序列相似性检测
2019-09-21
(浙江工业大学 计算机学院,浙江 杭州 310023)
近年来学生整体的体质状况呈现下降的趋势。为改善学生体质,高校陆续开始实行“阳光跑步”计划,要求学生开展课外锻炼。为了对学生课外健身跑的情况进行监督,传统方法是在校园内设置一些检查点,学生跑步通过这些检查点时以刷卡或者指纹识别的方式来进行身份识别,按时完成规定的行程,以此保证锻炼的质量。该做法的局限性也是明显的,首先是所有检查点需要有专门人员负责看管,耗费人力与财力;其次,由于专门人员的监管不是全天的,学生只能在特定的时间进行跑步,无法选择自己最合适的锻炼时间;最重要的是监管具有被动性,只获取到每个学生抵达检查点的时间信息,无法深入地分析学生的锻炼状况,更无法进行个性化运动指导。
随着穿戴技术的发展,以上问题可以得到有效解决。采用运动心率腕表是其中一种方法:一则通过腕表实时监控学生课外锻炼状况,学生运动时间不再受监管人员的约束;二则通过采集心率数据了解锻炼强度,由此开展运动效果的分析,进行个性化运动指导;此外,还可以减少监管人力投入。当然也存在一些技术问题需要克服,比如由于缺少直接监督,可能会出现一人佩戴多个腕表替他人代跑的情形,笔者称此为“多表代跑”。为了避免该情况,非常需要一种合适的方案对其进行检测,进而达到有效的监督,保证学生的课外锻炼质量。
1 相关工作
多表代跑的检测本质上属于分类问题,但它又区别于时间序列的分类,并不针对单条序列,而是面向序列对的分类问题。该问题主要涉及三个方面:时间序列表示方法、时间序列相似性度量和时间序列分类。
在时间序列的表示上,有基于时域和基于转换域的两类方法。基于时域方法有分段累积近似法(PAA)[1]、适应性分段常数近似(APCA)[3]、符号化聚合近似法(SAX)[4]、感知要点(PIP)[5]、分段线性表示(PLR)法[6]还有旋转门(SDT)[7]。基于频域的方法有离散傅里叶变换(DFT)[8]和离散小波变换(DWT)[9]。在第4节将会针对多表代跑问题对所有这些方法进行充分讨论。
在时间序列的相似性度量上,主要有基于Lp-范数[10]的曼哈顿距离、欧氏距离和切比雪夫距离,还有动态时间规整[11]和短时间序列(STS)距离[12]。与表示方法一样,第4节将对它们进行充分讨论。
时间序列分类的研究主要有两个关注点。首先有许多研究关注数据自身的性质并对其进行特殊处理。Geurts[13]提出基于时间序列中局部模式的分类方法。Zhang等[14]提出一种使用小波分解并且能够自适应选择参数的表示方法用于分类。基于该表示推导出合适的度量并使用最近邻算法进行分类。Kadous等[15]使用元特征途径(比如时间序列中的局部最大值)来生成分类器。类似地,Yang等[16]使用基于公共主成分的特征子集选择来保留在原始特征集中的关联信息。然后根据分类的有效性对这些选择的特征子集进行评价。另一方面,研究者们关注定制或开发专门用于时间序列数据的分类器。比如,Povinelli等[17]提出一种基于对系统动态建模的信号分类方法。这些动态信息是从使用高斯混合模型对时域特征重建后的阶段中捕获得到的。Rodríguez等[18]研究能较好地对时间序列数据进行分类的区间决策树和基于DTW的决策树,然后使用集成方法将所有基分类器结合起来。此外,Xi等[19]提出一种半监督的时间序列分类器,适用于只有少量带标签样本的情况。由于时间序列分类的研究都是针对单条序列,更适用于解决分次代跑问题。而本研究要解决的多表代跑问题中需要分类的是序列对,这些方法并不适用。
2 问题定义
当前有许多研究工作通过移动终端对数据进行采集[20-22]。笔者将使用某公司生产的运动腕表采集学生的跑步心率数据。图1为一同学在986 s的跑步过程中采集到的心率序列(采样间隔为每秒一次,采集时间精确到秒,心率值精确到整数)。
笔者分别对两种类型的数据进行采集:代跑序列和正常序列。代跑序列指的是一位同学替其他同学代跑产生的心率序列,有两种情形:1) 同时戴多个心率腕表代替其他同学跑产生的序列;2) 多次替他人跑步产生的心率序列。笔者聚焦“多表代跑”的情形,通过机器学习算法自动分辨代跑,分次代跑问题留到后续研究解决。正常序列指的是学生运动中只戴一只腕表采集得到的自身心率序列。
完成了心率序列的采集,所有的序列还需要先经过适当的处理才能被使用。此外,互为代跑关系的两条序列在完成采集后,它们各自采集起始时间的偏移都会被记录下来。因为在后面的实验部分,所有的心率序列会被分配在一个限定的时间域中进行现实场景的模拟,两条代跑序列的采集起始时间偏移仍应该在模拟环境中保留。
Si=
例如,在一段时间内采集到的4条时间序列A,B,C,D,如图2所示。横轴代表时间,序列的高低与心率值无关,仅为互相区分。序列A与B的采集时间存在重叠,它们由多表代跑产生,属于代跑序列对;序列A与C存在时间重叠,但它们心率波动趋势不同,不属于多表代跑产生序列,属于正常序列对。图2中属于正常序列对的还有A与D,B与D。

图1 学生跑步过程中采集到的心率序列Fig.1 Heart rate series gathered when student is running
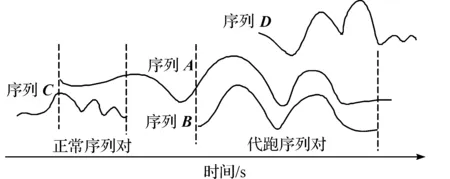
图2 正常序列对和代跑序列对Fig.2 Normal series pair and fake running series pair
由此可知:当两段序列存在时间重叠,它们将组成一个序列对(正常序列对或代跑序列对)。在给定的一段采集时间内,会存在大量这样的序列对。本研究的任务是提出一套代跑检测方案识别其中的多表代跑序列对。
3 表示方法与相似性度量的选择
本节讨论表示方法和相似性度量的选择,这两方面是开展时间序列分析的关键。讲述笔者选择PAA、差值序列、斜率序列和百分比序列作为潜在的表示方法(当然还包括原始序列),以及选择曼哈顿距离、欧氏距离、短时间序列距离、堪培拉距离还有Bray-Curtis距离作为潜在的相似性度量方法的考虑与理由。所有这些潜在的表示方法和相似性度量将组合在一起,在进行特征抽取时每个组合对应的距离值都作为特征集合的一部分。
3.1 表示方法
时间序列通常被转换成合适的表示形式,在转换后的序列上进行相应的分析[1]。目前时间序列表示方法主要可分为两类:基于时域的表示方法和基于转换域的表示方法。下面将针对当前的研究对一些主要的方法进行讨论。
基于时域的时间序列表示法之一是对原始时间序列进行分段处理,将其分成等长的片段,计算出每个片段中数据点的平均值,该方法被称为分段累积近似法(PAA)[1]。该表示虽然压缩了原有信息,但可能抽取出具有代表性的片段进而提升检测效果,因此将在实验方案中尝试。另一种表示方法是适应性分段常数近似(APCA)[3],APCA作为分段累积近似法的扩展版本被提了出来,该方法中各片段的长度不固定,随时间序列的形状自适应变化,不能合理地在相应时间匹配序列对,将不纳入实验方案。
另一种通用类型的时间序列表示方法的思路是将数值化的时间序列转换为符号化的表示。这类方法先将原始的时间序列离散化为一个个片段,然后再把每个片段映射到不同字符上。在这类方法中,最有代表性的是由Lin等[4]提出的符号化聚合近似法(SAX)。SAX本质上是对PAA表示的进一步压缩。使用PAA已经损失掉大量原始序列的信息,如果效果不佳,那么使用SAX只会让最终的效果更差。所以将先在实验中对PAA方法的效果进行观察,根据情况决定是否在后续研究中将SAX纳入实验方案。
此外,通过仅保留那些关键数据点来降低时间序列的维度也是一种很有前景的方法。这些关键点被称作感知要点(PIP)[5]。对于一条时间序列P={p1,p2,…,pn},通过PIP鉴别过程,对序列P中所有的数据点根据其重要性进行排序,从而发现那些最重要的数据点。该表示找出的关键点很容易受到序列中噪声的影响,比如一些由于噪声带来的极值点也会被选为关键数据点,进而偏离了原始序列的信息。同时当序列对重叠区域的两片段被转换之后,各自得到的关键点的时间戳往往是不一致的,无法匹配进行距离计算。此外PIP需要通过特定算法对每条序列进行一个关键点的寻找过程,这会带来过多的计算消耗。
使用线段来拟合时间序列是另一种表示法,称为分段表示法。其中的一个典型方法是分段线性表示(PLR)法[6]。设S(pi,…,pj)为一个子序列片段,其中pi,pj表示该序列中的数据点,该方法用连接pi和pj的线段作为该子序列的近似表示,该方法将这些连续片段的端点对齐,得到一个前后连接的线段组成的分段近似表示。具体地说,PLR是一个自底向上的算法,它先将时间序列中前后直接相邻的两个点作为片段创建一个最细粒度的近似;之后不断地合并所需代价最低的相邻片段对,直到当前的片段数达到所需的数量。当两个相邻的片段合并之后,该算法将会分别计算这个新片段与其前后相邻片段合并所需的代价。与PLR类似,旋转门(SDT)[7]算法也用于原始时间序列的线性分段表示,该算法在一定误差范围内用起点和终点确定的直线来代替两点之间其他的数据点,并保存起点和终点的时间及数值大小,且前一压缩区间的终点即为后一压缩区间的起点。这两种表示与PIP的问题类似,无法对转换后表示中的线段进行匹配,因为这些线段是根据各自原始序列的波动特征而生成的,它们所覆盖的时间范围并不一致。
前面提到的方法主要都是直接在时域对时间序列进行表示,然而也可以在转换域中表示它们。离散傅里叶变换(DFT)是另一种表示法[8]。傅里叶变换可以视为一个基变换,把一个向量从无穷维的时域空间变换到另一个无穷维的频域空间中;离散傅里叶变换也是一个基变换,它把原来一个n维的点变成了k维,因此,它也可以对时间序列数据进行降维处理。在DFT之后,Chan等[9]发现离散小波变换(DWT)可以很好地代替离散傅里叶变换。不同于傅里叶变换,其变量只有频率,小波变换有两个变量:尺度(scale)和平移量(translation)。尺度控制小波函数的伸缩,平移量控制小波函数的平移。尺度就对应于频率(反比),平移量就对应于时间。傅里叶变换只能得到一个频谱,而小波变换却可以得到一个时频谱,小波变换可对非稳定信号进行时频分析。这两种方法虽常被用于时间序列的研究,但并不适用于当前工作。首先,代跑鉴别是基于两条序列在重叠区域里片段的比较展开的,在这个区域内可能只有少量的对齐数据点,这样贫乏的信息不足以让频域表示方法捕捉到心率序列信号的波动特征;其次,将心率序列转换为频率上的系数后,时域中时间戳的对应关系将会丢失,频域中两条序列很可能对应不一样的频谱,此时不能再通过比较两序列在重叠区域里对齐数据点的差值来进行度量。
此外,除了前面提到的PAA,笔者还考虑了差值序列(前后时间戳对应心率值的差值)、斜率序列(前后时间戳对应心率值的差值/前后时间戳的差值)、百分比变化序列(前后时间戳对应心率值的差值/前一时间戳对应的心率值)这些基本的转换作为后面实验中尝试的表示方法,其优点有:1) 操作方便;2) 能从不同的角度去表示原始心率序列中蕴含的信息;3) 使用它们进行表示依然可以保留两条序列在时间戳上的对应关系,这为后面距离的度量带来了极大的便利。
3.2 相似性度量
对于多表代跑检测问题,需要度量的是两序列在重叠时间范围内片段之间的相似性。由于两片段中数据点的对应关系是可以由时间戳准确锁定的,所以不必考虑局部时间位移的问题,只需将所有数据点配对的偏差累加起来即可。另外采集过程中如果个体的运动强度过大,获取的心率值很可能受到汗水或者腕表脱落的影响导致不够精确。因此可考虑在度量中加上一定的权值,尽可能减少这种现象带来的影响。
更全面的时间序列相似性度量方法可参考文献[1],本节讲述典型的几类方法。相似性度量在时间序列分析中是非常关键的一步。时间序列相似性度量是基于近似匹配的方式定义的。基于Lp-范数[10]的欧氏距离[23]和它的变种是度量时间序列相似性最直接的方法。Lp-范数也被称作闵可夫斯基距离。对于两条长度相等的时间序列x和y,Lp-范数通过计算它们之间所有两两对应时间点的距离之和来衡量两条序列的近似程度。该距离和越小,相似程度越高。计算该距离和的公式为
(1)
式中:p取1时为曼哈顿距离;p取2时为欧氏距离;p取无穷大时为切比雪夫距离。欧氏距离和它的变种含义清晰、容易理解,它们还具有线性时间复杂度、易于实现、不需要设定额外的参数等特性。Ding等[1]尝试通过实验对各种不同的相似性度量方法进行比较,发现欧氏距离相比于其他更复杂的相似性度量方法更有竞争力,尤其是在数据库/训练集相对比较大的时候。曼哈顿距离和欧氏距离都是通过累加两条序列对齐数据点的差值作为距离的度量结果。该思路原理简单,相对于其他度量方法具有更低的时间复杂度,将会在后续的检测方案中使用。切比雪夫距离以两序列对齐数据点中最大的偏差作为最终距离,可以看出该方法很容易受到局部噪声的影响,两条序列之间只要有一对偏差较大的数据点,它们就被认为是高度不相似的。该方法至多只能作为初步的筛选,无法准确度量两条序列之间的相似度,不纳入实验方案。
Lp-范数也有局限性,由于该度量对于两时间序列内点的对应是固定的,其对噪声和错误的对齐非常敏感,且没有办法解决局部时间位移的问题(Local time shifting),比如两个时间序列片段相似但在位移上有一定的偏差。
为了对存在一定程度变形的时间序列进行相似性度量,Berndt等[11]提出了动态时间规整(Dynamic time warping)。该技术可以通过一种非线性的方式对齐,计算相似但局部存在偏移的两序列之间的相似性。在本研究中,由于已经能够获得序列中每个时间戳确定的时间,将重叠区域时间戳相同的数据点对齐,然后进行距离的度量,所以并不需要该方法的特性。而且使用该方法很可能会因为它的弯曲对齐使得相似性的度量结果更不准确。
为了对具有相同但不均匀采样率的两条时间序列进行相似性度量,Möllerlevet等[12]提出了短时间序列(STS)距离,计算公式为
(2)
式中:x,y表示两条不同的序列;n为两条时间序列的长度。
虽然当前使用序列采样率均匀,但这种基于斜率偏差的距离度量是一种新思路,值得在实验中尝试。
除了曼哈顿距离、欧式距离和短时间序列距离外,笔者还考虑了另外两种方法。堪培拉(canberra)距离本质上是权重化的曼哈顿距离。权重是指会给不同对齐数据点的差值分配不同的权重,这个权重由两个数据点对应值的绝对大小来决定。假设有两条时间序列x=
(3)
在本研究中该度量方法可以理解为对心率绝对水平较高情况的差值给予更多的惩罚。因为在实际心率数据采集过程中,当采集人的运动状态越来越剧烈,他的心率就会不断上升,这时更容易出现手环松动、汗水干扰的情况,进而影响心率采集的精确度。若对这种情况的心率给予更多的惩罚,那么最终的度量结果有可能也会更接近于真实的序列相似情况。
此外还考虑将Bray-Curtis距离加入到检测方案中。假设有两段时间序列x和y,它们的Bray-Curtis距离为
(4)
本质上该方法相当于是曼哈顿距离的调整。当使用曼哈顿距离,得到距离值后,将除上对齐点的个数,作为最终度量结果。而这里,除的值与序列本身的数值有关。由于心率值都是正的,不用考虑负数的情况,该方法便包含这样的含义:如果两序列心率值的总体水平比较高,那么它们之间的曼哈顿距离就会得到更多的惩罚。
4 代跑检测方案
4.1 整体框架
已获得的原始心率数据集需要先转换为对应的样本集才能供分类器训练和测试。为了对分类器检测效果进行合理的评价,样本集将划分为训练集和测试集两部分,分别用于分类器训练和代跑检测。训练分类器时,将依次经历特征缩放、特征选择还有模型训练的环节。代跑检测时,前面两环节与训练时一致,最后将针对代跑检测问题确定合理的指标对检测结果进行评价。
本方案主要包含3个部分:样本集生成、分类器训练还有代跑检测。代跑检测方案为
名称:代跑检测方案。
输入:原始心率数据集(包含标签和采集时间)。
重叠阈值:两条序列的重叠部分需要有多长的时间才能被认为是合法序列对。
输出:代跑检测分类结果。
1) 样本集生成。样本集生成:根据心率数据集中的所有序列对生成样本集;训练集和测试集划分:根据指定的比例将数据集划分为训练集和测试集两部分。
2) 分类器训练。对训练集中的特征进行缩放;对训练集中的特征进行选择;调整SVM的模型参数并根据训练数据进行训练。
3) 代跑检测。对测试集中的特征进行缩放;对测试集中的特征进行选择;使用训练好的SVM对测试集中的数据进行代跑检测。
4) 分析最终得到的代跑检测结果。
4.2 样本集生成
笔者将根据学生跑步时采集到的心率序列生成对应的样本集。对于采集到的心率序列:ξ1,ξ2,…,ξn,若序列ξi.[start, end]∩ξj·[start, end]≠φ,则依据ξi与ξj在重叠时间区间上的片段生成特征集。提取的特征,除两条序列之间的距离度量外,还包括各种统计特征。根据两条序列在采集时的实际关系赋予当前样本对应的标签(戴多表采集的代跑关系为1,独立采集的正常关系为0)。由此,得到样本集。为了序列对提取特征时能够获得更充分的信息,要求重叠的时间区间达到一定长度,提升代跑鉴别的效果。若对该区间限制过大将导致一些重叠范围较小的代跑序列对被忽略,这种序列归入多次代跑问题中去解决。重叠区间大小对检测效果的影响将在后续的实验中作进一步分析。
下面讲述特征序列的生成。
4.2.1 距离度量特征
距离度量可以用来直接表示两条序列之间的相似程度[1],也可以用某种相似性度量计算两条序列在特定表示下的距离作为该序列对的一个特征。笔者将对前面所选的表示方法和相似性度量进行组合,由此得到的距离值作为样本特征集的一部分。
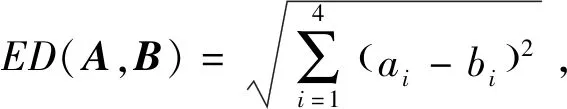
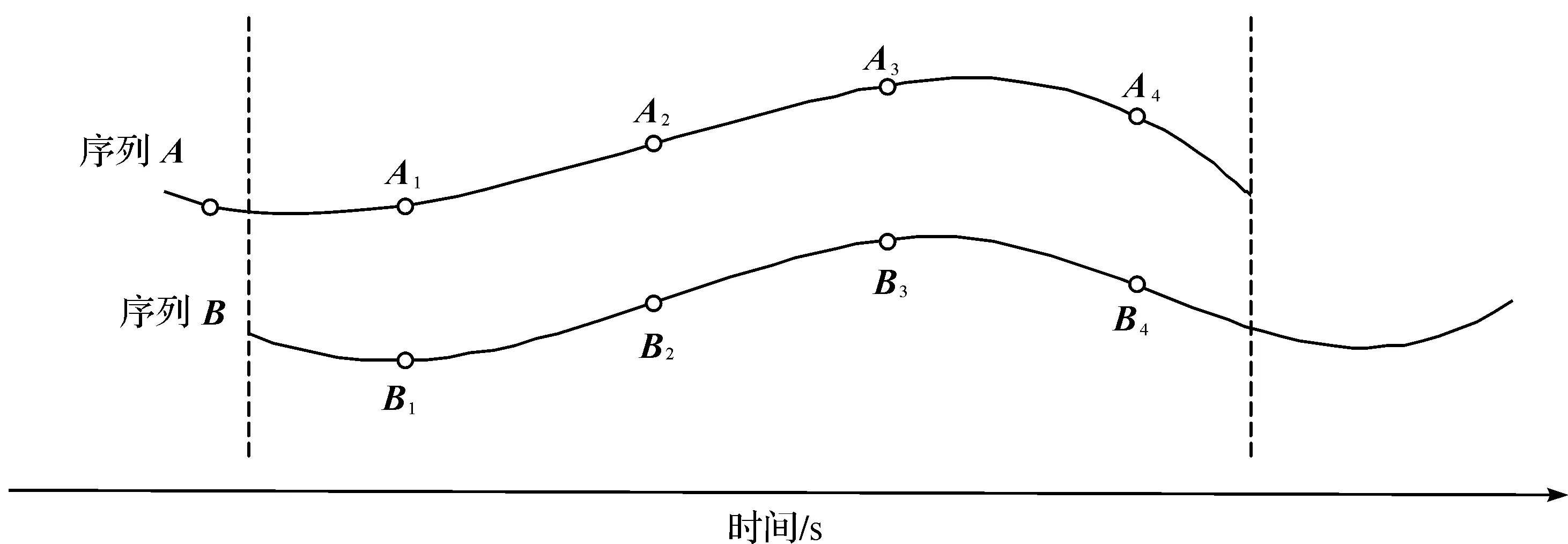
图3 序列对在重叠区域的距离度量Fig.3 Distance measurement of series pair within overlapping area
Bray-Curtis距离的度量值已经消除了数据点个数的影响,使用上文提到的其他度量方法计算两序列间的距离时都需除以对齐数据点的个数。
4.2.2 统计相关特征
为表征代跑序列的相似性,除距离度量之外,还可引入许多统计相关的特征:均值、平均绝对误差、最大值、最小值、标准差、平均标准误差、倾斜度、峰度、协方差、关联性、绝对能量、绝对变化和、复杂不变距离、高于均值计数、低于均值计数、最大值首次出现位置、最小值首次出现位置、有无重复数值、最大值是否重复、最小值是否重复、最大值最后出现位置、最小值最后出现位置、高于均值的最长连续子串长度、低于均值的最长连续子串长度、平均绝对变化、变化和的平均、二级导数的中心近似、中位数、重复出现数据点的比例、唯一数据点的比例、样本熵、重复出现数据点之和、重复出现数值之和、所有数值之和、方差是否大于标准差。
这些特征对应的特征值都是基于序列对在重叠时间区域上的片段计算得到的;特征抽取时,将为两条序列重叠区域上的片段分别计算出某个特征的值,然后计算两者之间的差值的绝对值;布尔值特征不需计算差值,只需比较两片段的布尔结果,根据是否相同赋值0或1;大部分特征都可以在文献[24]中找到详细的说明。
4.3 分类器训练
对于本研究中提到的二分类问题,需要选择一个合适的分类器从训练数据中学习并对测试数据进行检测。支持向量机(SVM)非常适合解决本研究中的分类问题。给定一组训练样本,其中每个样本都属于两个类别中的一个。SVM训练算法可以在被输入新的样本后将其分类到两个类别中的一个,使自身成为非概率二进制线性分类器。SVM将训练样本表示为空间中的点,它们被映射到一幅图中,由一条明确的、尽可能宽的间隔分开以区分两个类别。随后新的样本会被映射到同一空间中,并基于它们落在间隔的哪一侧来预测它属于的类别。
SVM有许多优点:首先,它背后的理论基础十分完善;其次,相对于其他分类器,SVM尽量保持与样本间距离的性质使其抗攻击的能力较强;此外,SVM除了能够处理线性分类问题还可以通过核函数来高效地解决非线性分类问题,即隐含地将SVM的输入映射到高维的特征空间当中;最后,在实际的应用效果上,SVM在很多数据集上都有优秀的表现[25]。
在训练SVM前,需要对生成样本集的所有特征进行缩放。文献[26]中提到使用支持向量机分类任务前进行特征的缩放非常重要。特征缩放可避免数值范围较大的特征主导数值范围较小的特征,同时还能避免一些数值计算问题。具体地,该文推荐将特征缩放到[-1, +1]或者[0, 1]的区间,即使用0-1标准化的方法进行特征的缩放,笔者将参照该建议进行后续的实验。
完成了特征的缩放,还需要对现有的特征集进行特征选择。笔者挑选了以下3 种较常用的特征选择方法:
1) 方差法:预先设定一个方差阈值,如果某个特征的方差小于阈值,则将该特征删除。
2)F检验:可以被用来估计两个随机变量之间的线性相关程度。进而可以通过该方法筛选掉高度线性相关的冗余特征。
3) 互信息:两个随机变量之间的互信息是一个非负值。通过它可以度量两个变量之间的依赖程度。当该值为0表示两个随机变量是相互独立的,如果值更高说明两者依赖更强。
实验前,不存在足以选出最合适的特征选择方法的依据,因此将对这3 种方法进行实验评估,根据每种方法对应实验结果的优劣进行选择。具体的方案设计与结果会在实验部分详细说明。
选择支持向量机作为本研究使用的分类器后,仍需对核函数的类型进行选择,线性核和径向基内(RBF)核是最常用的两种。线性核主要用于线性可分的情形。线性核参数少、速度快,对于大部分数据集的分类效果都比较理想。RBF核主要用于线性不可分的情形。RBF核参数多,分类结果非常依赖于参数。由于缺少充分的选择依据,与特征选择方法类似,将通过实验进行详细比较。
除了核函数之外,SVM还有两个重要的参数γ和C需要确定。γ是针对RBF这种非线性核函数的。直观上而言,它决定了模型对于特征向量之间区别的敏感度。较高的γ值会使训练后的SVM偏差较高,方差较小,反之亦然。参数C又称为惩罚项,指的是SVM里拉格朗日乘数的约束程度。C的大小决定了SVM对于outlier的忍受程度。较低的C值会使得决策平面更光滑,而较高的C值将会让模型去选择更多的样本作为支持向量,进而能够对所有训练样本进行更准确的分类。对任意特征选择方法与核函数组合,将对这两个参数进行网格搜索,即对两个参数在特定范围内进行遍历,然后以最优实验结果代表当前特征选择方法与核函数组合的效果。
代跑序列对只占所有序列对的小部分,由这些序列对产生的样本集会存在类别不平衡的问题,所以在训练SVM时需要考虑类别权重。权重值将与γ,C一起在限定范围内进行网格搜索,具体细节将在实验章节说明。
4.4 代跑检测
在代跑检测环节,训练得到的分类器会对测试样本集的数据进行分类,根据分类结果对分类器进行相应评价。
在对特征集的处理上(特征选择和特征缩放),只要和前面训练时的处理方式保持一致即可。处理完特征集之后,这些样本将交给分类器去判断,并和实际的标签进行比较。关于分类的评价指标,这里主要考虑分类器对于代跑序列对(正例)的鉴别情况,即针对正例的精准度、召回率。仅仅是分类的准确度不能较好地反映代跑检测的分类效果,因为整个样本集中包含了大量的负例和少量的负例,一个把所有样本都认为是负例的分类器都可以取得较高的准确度。同时经过大量的实验后发现,针对负例的精准度,召回率基本都是接近1的,有时可能会因为分类器把一些正例误认为是负例使得针对负例的精准度略微降低。而针对正例的精准度反映了正例的判别能力,将负例判别为正例(正常跑步同学判定为代跑同学)是急需避免发生的情况,因此该指标的理想值应为1。针对正例的召回率反映了正例的回收情况,该值越高表示分类器鉴别出代跑的能力就越强。综上,在正例的精准度控制在1的前提下,希望针对正例的召回率越高越好。
5 实 验
本节通过实验验证所提代跑检测方案的有效性。首先介绍实验数据,然后比较不同SVM内核与不同特征选择方法组合下的检测效果,最后通过实验分析序列对重叠时间限制对代跑检测效果的影响。
本实验使用的所有数据都是由学生跑步时佩戴运动腕表所采集得到。目前共有代跑序列508 对(1 016 条)和正常序列800 条,数据具体情况见表1。

表1 数据概要Table 1 Data summary
5.1 模拟环境构建
由于本研究中使用的心率序列并不是在特定时间段内一并采集的,而为了对笔者提出的代跑检测方案进行合理评估,需要将所有心率序列都分配在一个特定的时间域中。这样可以使所有序列之间存在更多的重叠,产生更多区别于代跑序列对的正常序列对,使得最终的评价结果更有说服力。
为了构建这样一个模拟的测试环境,需要预先给定一个时间域的范围,即开始时间与结束时间。然后便可以在这个时间域中为所有序列随机分配新的采集开始时间。当每条序列都被分配好新的采集开始时间后,模拟测试环境的构建便已完成,然后进行样本集的生成。
考虑到本实验使用的心率序列数量和长度,时间域将设为4 h,即所有的心率序列的起点都会被分配于该时间范围中的任意秒上。虽然该选择并没有足够的依据支撑,但主要考虑了如下几点:1) 使重叠的序列对更多,能对代跑序列对的鉴别产生干扰;2) 该范围相当于一个下午内适宜锻炼的时间长度,可以使实验更接近真实的场景;3) 只要保证时间域中存在充分数量的重叠序列,该时间域的范围是可以自由调整的。
5.2 不同特征选择算法对检测结果的影响
本实验分别使用方差法、F检验和互信息这3 种特征选择算法对SVM的线性核和RBF核进行实验比较,用以判定哪种特征选择算法与内核的组合最适用于解决代跑检测问题。4.4节已对代跑检测的目标进行说明,下面的实验中将不对负例(正常序列对产生的样本)的精准度和召回率进行讨论。具体地,每一种组合都将对SVM参数γ(只针对RBF核)、C还有类别权重这3 个参数进行网格搜索。这3 个参数都以指数增长的序列作为搜索范围,其中γ=10-3,10-2,…,103,C=10-3,10-2,…,103,类别权重(正例与负例权重之比)=20,21,22,23,24,25,26,27。
图4,5是使用F检验作为特征选择算法的实验结果,分别显示了正例精准度和召回率随特征选择个数变化的情况。F检验将高度线性相关的特征删除。所选特征的个数由5到55,间隔为5。从图中可以看出:只有RBF核选择5 个特征可以达到100%的精准度。正例召回率随着特征选择个数的增多有上升的趋势,而正例精准度并没有呈现出明显的趋势。
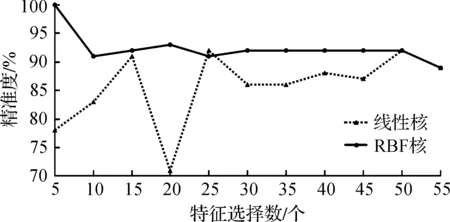
图4 通过F检验进行特征选择时的正例精准度Fig.4 Positive sample precision using F test

图5 通过F检验进行特征选择时的正例召回率Fig.5 Positive sample recall using F test
图6,7是使用互信息作为特征选择算法的实验结果,类似前一实验,分别显示了正例精准度和召回率随特征选择个数变化的情况。互信息将高度相互依赖的特征删除。所选特征范围与前一实验相同。从图6中可以看出:使用互信息作为特征选择算法时,精准度最高只能到95%左右。正例召回率和正例精准度和前一实验情况相同。

图6 通过互信息进行特征选择时的正例精准度Fig.6 Positive sample precision using mutual-info

图7 通过互信息进行特征选择时的正例召回率Fig.7 Positive sample recall using mutual-info
图8,9是使用方差法作为特征选择算法的实验结果,显示内容与前面实验一致。方差法将方差小于设定阈值的特征删除。其中,当方差从0到0.02按0.002递增时(预先对不同方差阈值进行实验后确定的范围),剩余的特征个数分别为:54,53,50,46,41,37,36,34,31,26,24。从图8,9中可以看出:此时线性核不论是在精准度还是召回率上都明显优于RBF核。其中方差阈值设为0.01,0.012和0.014时线性核能在最高的精准度下达到的最高召回率。考虑到0.01和0.014为这个最优范围的边界,实际效果可能会存在一定的波动,因此选择0.012作为最终选择的阈值。综上,通过方差法以0.012阈值筛选出的特征集通过线性核SVM进行训练能够达到最优的检测效果。后面将以该组合进行实验。
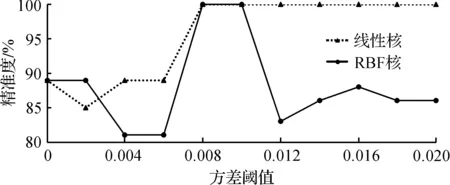
图8 通过方差法进行特征选择时的正例精准度Fig.8 Positive sample precision using variance

图9 通过方差法进行特征选择时的正例召回率Fig.9 Positive sample recall using variance
5.3 不同重叠时间限制对检测结果的影响
图10是使用不同重叠时间限制生成样本集后,使用5.2节选出的最优方案组合的实验结果,显示了检测结果随重叠时间限制变化的情况。其中,重叠时间限制从100 s到500 s按50 s递增。从图10中可以看出:随着该参数增大,精准度并未有明显改变,而召回率虽然有波动但总体呈现出上升的趋势。召回率这样变化的原因很可能是由于重叠时间限制增大后,正常序列对便会减少,使得代跑序列对的相对比率更高,分类器也能更侧重正例的辨别。

图10 序列对重叠时间限制对检测效果的影响Fig.10 Effect of limit overlapping time to detection
6 结 论
由学生的跑步监测提出了多表代跑的问题,并根据该问题提出了一套基于SVM的代跑检测方案。该方案先由大量序列对生成样本集,再基于部分样本集训练SVM,最后使用训练得到的分类器进行剩余样本的代跑检测。笔者也对当前最有效的几种特征选择算法进行了比较,确定方差法为最适合本类型问题的方法。实验对所提方案进行了充分的比较和验证,结果表明所提方案能够在精准度为100%的情况下取得较高的召回率。
