量化容差关系的程度多粒度粗糙集模型
2019-09-20吴照玉
姚 晟, 陈 菊, 徐 风, 汪 杰, 吴照玉
(1.安徽大学 计算智能与信号处理教育部重点实验室,安徽 合肥 230601; 2.安徽大学 计算机科学与技术学院,安徽 合肥 230601)
粗糙集理论[1]是波兰学者Pawlak教授于1982年提出的一种处理不确定、不完整数据的数学模型。目前已广泛地运用于机器学习[2]、数据挖掘[3]、神经网络、深度学习及模式识别[4]等领域[5-10]。对于早期的粗糙集研究而言,其主要是集中在完备信息系统中,而实际生活中,由于一些原因,信息系统中会存在一些缺失数据,含有缺失数据的信息系统被称为不完备信息系统。针对经典粗糙集对不完备信息系统的数据分析存在的局限性,近年来,容差关系和量化容差关系由Kryszkiewicz[11]和Stefanowski[12]等所提出,有效地解决了不完备信息系统中数据缺失的问题,使得粗糙理论有着更为广泛的运用。为了从多个层次和多个角度进行分析和处理问题,多粒度粗糙集模型由Qian[13-14]等所提出来。通过多粒度的视角,粗糙集理论成为强大的数据分析工具之一。
Pawlak粗糙集是基于等价关系的,要求分类是准确无误的。程度粗糙集重视等价类与几何重叠部分的定量信息,考虑一点程度误差的分类。通过将多粒度应用到程度粗糙集中,吴志远[15]等提出了程度多粒度粗糙集。针对不完备信息系统,沈家兰[16]等提出了基于限制容差关系的程度乐观多粒度粗糙集和程度悲观多粒度粗糙集。林梦雅[17]等提出了基于量化容差关系的多粒度粗糙集。
本文针对不完备信息系统,融合了量化容差关系和程度多粒度粗糙集模型的优点,以量化容差关系为分类基础,提出了基于量化容差关系的程度多粒度粗糙集模型,其中定义了基于量化容差关系的乐观程度多粒度粗糙集和悲观多粒度粗糙集,并分析了相关的性质。实验结果表明,基于量化容差关系的程度多粒度粗糙集模型具有更好的近似精度。
1 程度多粒度粗糙集
为了融合多粒度粗糙集和程度粗糙集的优点,程度多粒度粗糙集由吴志远[15]等提出,并构建了乐观和悲观两种不同的程度多粒度粗糙集。
定义1[15]设信息系统IS={U,AT},A1,A2,…,Am⊆AT,k为非负常数,∀X⊆U,定义X的程度乐观多粒度下近似、上近似分别为
|[x]A2|-|[x]A2∩X|≤k∨…∨
|[x]Am|-|[x]Am∩X|≤k}
(1)
(2)
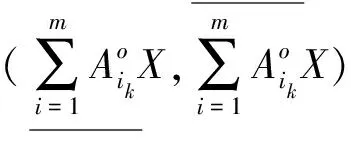
定义2[15]设信息系统IS={U,AT},A1,A2,…,Am⊆AT,k为非负常数,∀X⊆U,定义X的程度乐观多粒度下近似、上近似分别为
|[x]A2|-|[x]A2∩X|≤k∧…∧
|[x]Am|-|[x]Am∩X|≤k}
(3)
(4)
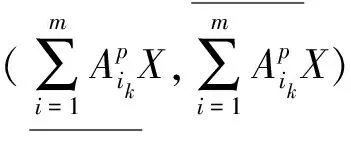
2 量化容差关系的程度多粒度粗糙集
在不完备系统中,考虑到等价类与重叠部分的定量信息也是相当重要,因此考虑将程度多粒度粗糙集引入其中。Wang[18]所提出的改进量化容差关系要比限制容差关系要求更加严格,相比之下,比相似关系要求宽松些,从而对论域的分类更加合理,并又结合了量化容差关系,因此提出了基于量化容差关系的程度多粒度粗糙集。
定义3 对于不完备信息系统DIIS={U,AT},设w为属性子集序列的分类阈值。对于∀x∈U,A∈AT,k为非负整数,在w量化容差关系VTw(A)下,X的程度粗糙集下、上近似分别定义为
(5)
(6)
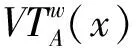
定义4 对于不完备信息系统DIIS={U,AT},设A1,A2,…,Am∈AT为m个属性子集序列,w1,w2,…,wm分别对应m个属性子集序列下的分类阈值,其中k为非负整数。∀x∈U,则X基于A1,A2,…,Am下w1,w2,…,wm量化容差关系族VTw1(A1),VTw2(A2),…,VTwm(Am)下的程度乐观多粒度粗糙集下近似、上近似分别定义为
(7)
(8)
另外,其w1,w2,…,wm量化容差关系的程度乐观多粒度粗糙集模型近似精度定义为
(9)
定义5 对于不完备信息系统DIIS={U,AT},设A1,A2,…,Am∈AT为m个属性子集序列,w1,w2,…,wm分别对应m个属性子集序列下的分类阈值,其中k为非负整数。∀x∈U,则X基于A1,A2,…,Am下w1,w2,…,wm量化容差关系族VTw1(A1),VTw2(A2),…,VTwm(Am)下的程度悲观多粒度粗糙集下近似、上近似分别定义为
(10)
(11)
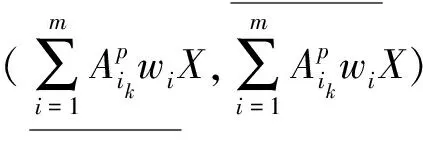
另外,其w1,w2,…,wm量化容差关系的程度悲观多粒度粗糙集模型近似精度定义为
(12)

定理1 设不完备信息系统DIIS={U,AT},A1,A2,…,Am∈AT为m个属性子集序列,w1,w2,…,wm分别对应m个属性子集序列下的分类阈值,其中k为非负整数。∀x∈U,则量化容差关系下的程度乐观多粒度粗糙集有如下性质。
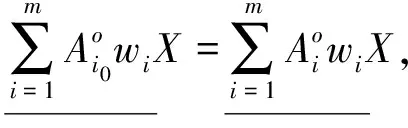
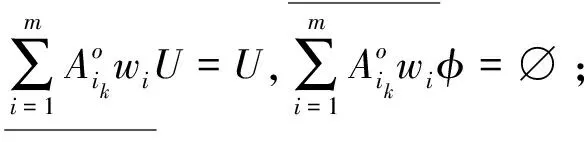
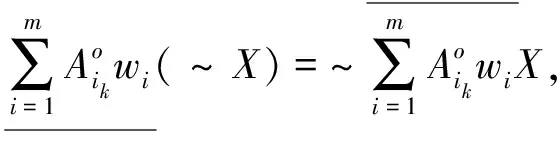
④k1,k2为非负常数,若k1≤k2,
证明:
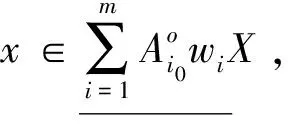
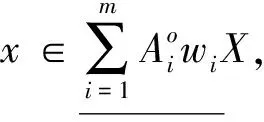
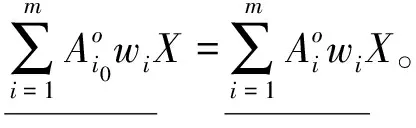
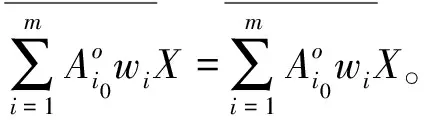
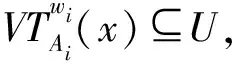
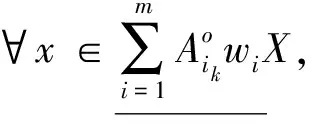
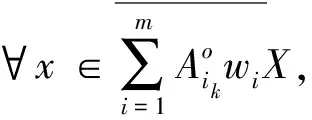
定理2 设不完备信息系统DIIS={U,AT},A1,A2,…,Am∈AT为m个属性子集序列,w1,w2,…,wm分别对应m个属性子集序列下的分类阈值,其中k为非负整数。∀x∈U,则量化容差关系下的程度悲观多粒度粗糙集有如下性质。
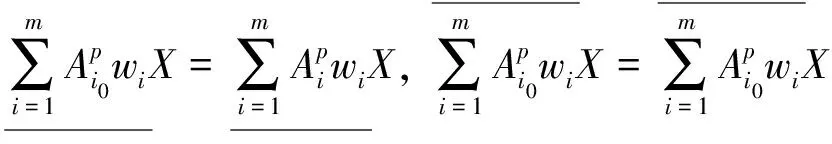
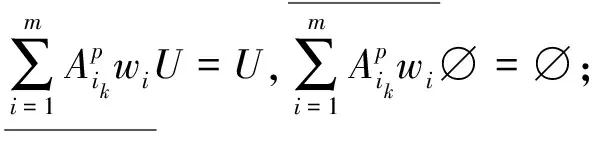
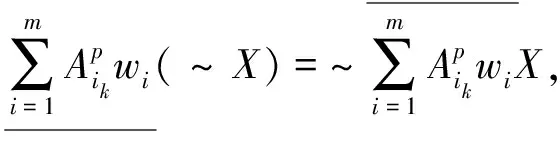
④k1,k2为非负常数,若k1≤k2,
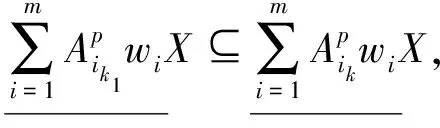
证明:定理2的证明类似于定理1的证明。
3 实验分析
为了验证所提出的基于量化容差关系的程度多粒度粗糙集模型具有一点的优越性,从UCI机器学习数据库中获取4个数据集进行试验。表1给出了各个数据集的类分布情况。

表1 UCI数据集
表1所示的4个数据集全部为完备数据集,为了满足本文所研究的基于量化容差关系的程度多粒度粗糙集模型,在实验前将会随机地剔除掉一部分数据,通过人为方式构造出不完备数据集进行试验。
为了验证所提模型具有一定的优越性,其中k=1,首先将4个数据集分别放在5%,10%,15%,20%,25%,30%数据缺失程度条件下进行试验;然后将程度多粒度粗糙集决策过程中限制容差类与集合重叠部分的定量信息考虑进去,对于每个数据缺失程度下,求取每个决策类在量化容差关系下的程度乐观多粒度粗糙集模型的近似精度,并计算出属于同一个数据集的所有决策类近似精度的平均值,即称平均值为数据集的平均近似精度;并且采用多个分类阈值的情形,即每个粒度的分类阈值w选取不同的值。最后对于4个数据集处于不同数据缺失程度下,随着阈值的变化,4个数据集的平均近似精度发生不同程度的变化,结果如图1~图6所示。
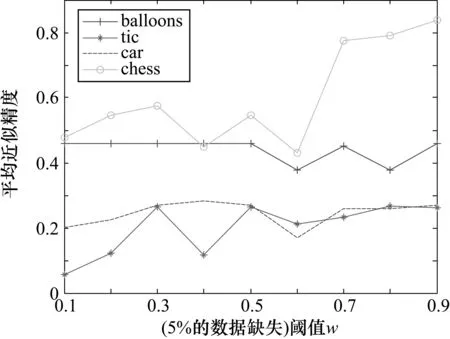
图1 4个数据集在5%的数据缺失条件下的结果分析
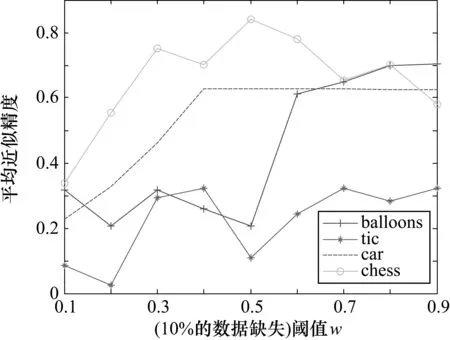
图2 4个数据集在10%的数据缺失条件下的结果分析
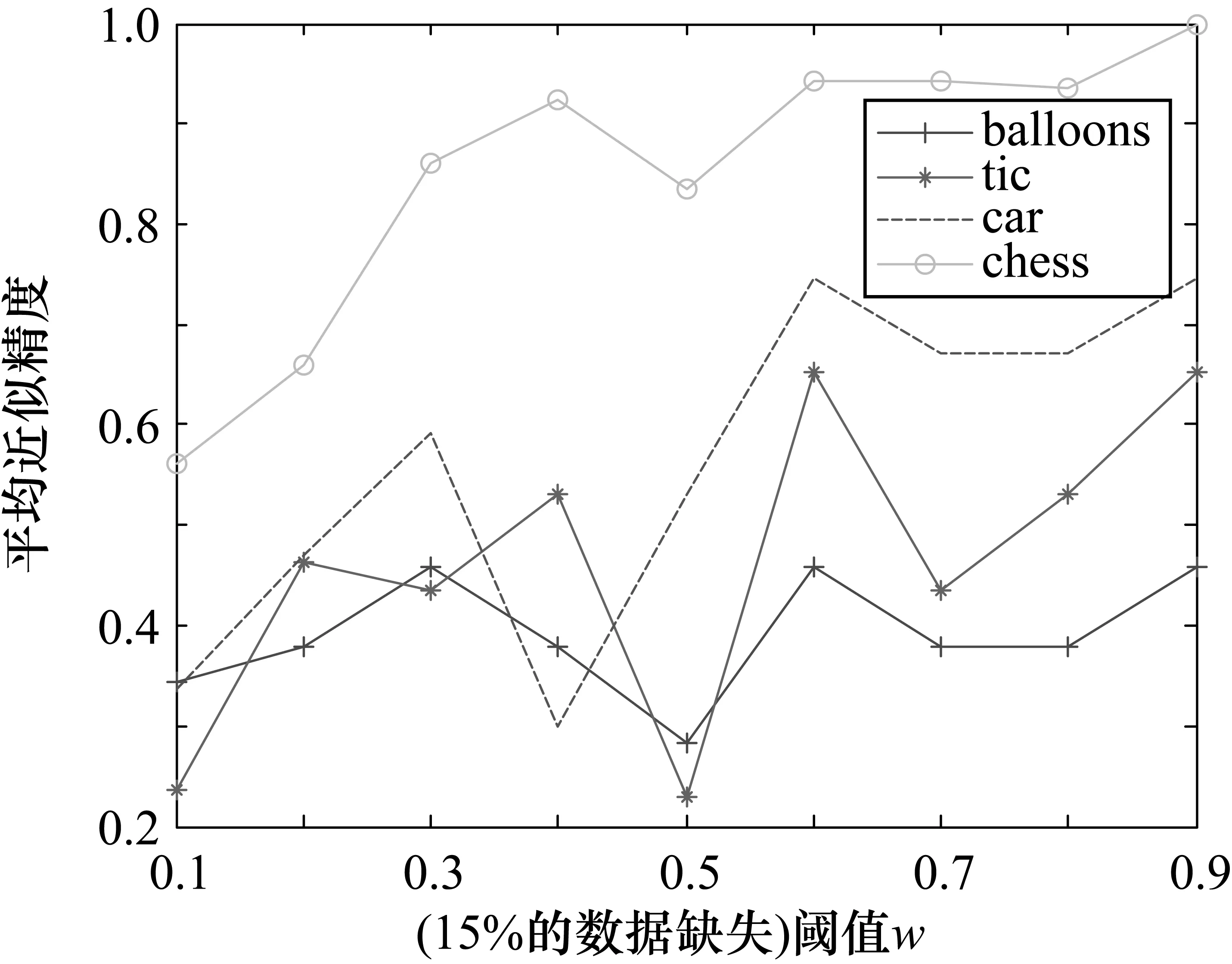
图3 4个数据集在15%的数据缺失条件下的结果分析
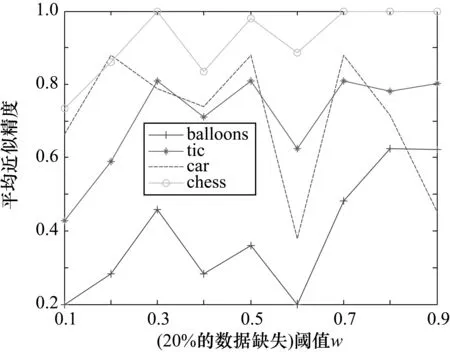
图4 4个数据集在20%的数据缺失条件下的结果分析
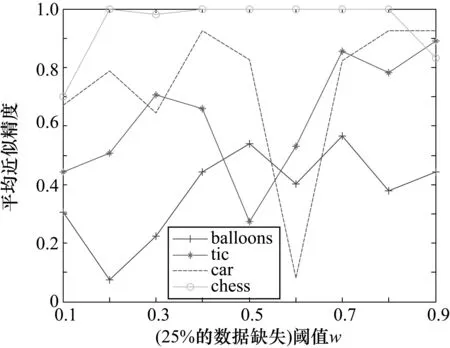
图5 4个数据集在25%的数据缺失条件下的结果分析
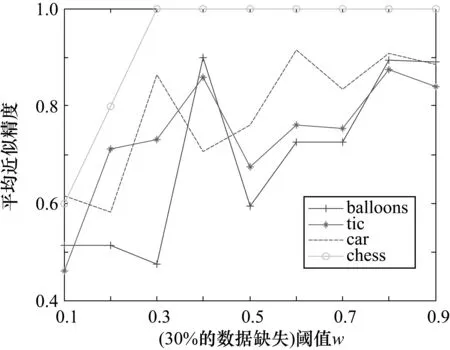
图6 4个数据集在30%的数据缺失条件下的结果分析
由于本文所提出的模型为多粒度粗糙集模型,每个数据集的条件属性需要构造一组属性子集,将数据集1和数据集2构造了4个属性子集,数据集3构造了3个属性子集,数据集4构造了9个属性子集。
从图1~图6可知,4个数据集在相同的数据缺失比下,不同的阈值对类精度具有很大影响。当分类阈值较小时,分类精度比较小,这主要是由于较小的分类阈值对分类较为宽松,使得对象划分较为粗糙,从而对应的近似精度较低;反之,则使得对象划分较为精细,从而对应的近似精度较高。从图1~图6还可以看出,在同一个分类阈值下,随着4个数据集缺失的百分比逐渐增大,4个数据集的平均近似精度总体来说在逐渐增大,这是由于数据缺失的较多,使得对象之间的相似程度降低,每个对象的量化容差类也减小,因此近似精度也会增加。实验结果表明基于量化容差关系的程度多粒度粗糙集模型具有较好的分类效果。
4 结束语
本文从程度多粒度的角度出发,基于量化容差的关系提出程度乐观、程度悲观多粒度粗糙集模型,并通过在不同粒度下定义的分类阈值w的不同取值来得到苛刻程度不同的对象分类,使得本文提出的模型具有一定的稳定性和灵活性。实验分析可以看出,所提出的模型具有一定的优越性。接下来,将对基于量化容差关系的程度多粒度粗糙集的属性约简和规则提取问题进行研究。
