基于CNN-LSTM心音分类方法的研究
2019-09-10于乾坤党鑫陈建霏
于乾坤 党鑫 陈建霏

摘 要:心音为疾病的诊断提供了初步的线索,有助于医生对疾病的评估,但传统的心音诊断训练费用昂贵,难以推广应用。针对以上问题,本文提出了一种基于CNN-LSTM的心音自动诊断分类方法,并给出了该方法的体系结构。网络结构由两个局部特征学习块和一个长短期记忆层组成,局部特征学习块主要包括一个卷积层和一个池化层。CNN利用卷积层和池化层来学习局部相关性,同时提取层次相关性。LSTM层用于从学习到的局部特征中学习长期相关性。文章中设计的网络可以充分利用这两种网络的优点,克服它们各自的缺点。实验采用了著名的Peter Bentley心音数据集,以梅尔频率倒谱系数作为心音特征,实验结果表明,设计的CNN-LSTM在心音识别中具有较好的效果,准确率约提高5%。所设计的网络结构在Peter Bentley数据集上的识别率达到85.4%,远高于LSTM和CNN分别在同一数据集上获得的准确率75.6%和80.5%。
关键词:特征提取;深度学习;CNN;LSTM;CNN-LSTM;心音分类
中图分类号:TN912.3 文献标识码:A 文章编号:2096-4706(2019)22-0079-05
Abstract:Heart sound provides preliminary clues in the diagnosis of the disease and helps doctors to assess the disease. However,traditional trainning of this skill are expensive and hardly to be widely used. Based on the above problems,a new classification method based CNN-LSTM is proposed for the automatic diagnosis of the heart sound. The network structure consists of two local feature learning blocks and a long-term and short-term memory layer. The local feature learning block mainly consists of a convolution layer and a pooling layer. CNN uses convolution layer and pooling layer to learn local correlation and extract hierarchical correlation at the same time. LSTM layer is used to learn long-term dependencies from the learned local features. The designed network in this paper can take advantage of the strengths of both networks and overcome the shortcomings of them. The widely known Peter Bentley heart sound dataset is used in this paper. The Mel-Frequency Cepstral Coefficients used as heart sound feature in this work. The experimental results show that the designed CNN-LSTM has a good effect in heart sound recognition,and the accuracy is improved by about 5%. The recognition rate of the designed network structure on Peter Bentley data set is 85.4%,which is much higher than the accuracy of 75.6% and 80.5% obtained by LSTM and CNN on the same data set respectively.
Keywords:feature extraction;deep learning;CNN;LSTM;CNN-LSTM;heart sound classification
0 引 言
心音是心臟机械振动而产生的一种声音,能够表征人体生理状态,病变心音中含有大量的病理信息。目前心音的自动诊断识别有两种主流方法,一种是基于传统机器学习的分类方法,另一种是基于深度学习的分类方法。前者主要采用支持向量机、随机森林等分类算法,如Balili等人提出的一种基于小波分析和随机森林分类器的心音分类方法[1],虽然分类效果不错,但仍存在一些问题,如在前期人工提取的特征不能全面地反映数据的本质特征,后期计算也比较复杂,而后者是利用一些神经网络模型对心音进行分类,如人工神经网络、卷积神经网络等。T.Leung等人利用的是时频特征和人工神经网络对心音进行分类[2],Nilanon等人提出的是利用卷积神经网络进行心音分类[3]。这些方法也明显取得了很好的分类效果,但也存在一些不足,如特征信息提取不完全以及对大量数据的处理存在问题。
本文提出了一种新的心音分类方法,即将卷积神经网络和长短期记忆神经网络相结合进行心音分类,可以有效地学习心音特征。本研究基于Peter Bentley数据集,即分类心音挑战赛2011[4],它包含两类数据集,本文使用的是数据集B。采用梅尔倒谱系数(MFCC)表征心音数据特征,因为在语音识别和说话人识别方面,最常用到的语音特征就是梅尔倒谱系数,它能够很好地表征音频特征[5,6]。实验结果表明,所设计的网络在心音分类任务中取得了良好的性能,可以有效帮助医生诊断相关疾病,具有良好的推广前景。
1 心音分类方法
1.1 预处理
有两个不同的数据集可以验证提出的模型,但本文使用数据集B,因为样本相对来说比较多,不容易过拟合,总共有461个样本,数据集B有三类,分别是extrasystole、murmur和normal heartbeat,其中149个样本含有噪声。本文使用这个数据集做对比实验,验证本文的深度学习模型。数据集B中音频文件的长度不一,在1秒到30秒之间,因此首先进行预处理,预处理包括移除短于2秒的心音文件,因为这种音频文件不包括一个完整的周期,最终有407个心音样本被使用,最后使用谱减法除噪算法对样本进行降噪处理。
1.2 梅尔倒谱系数
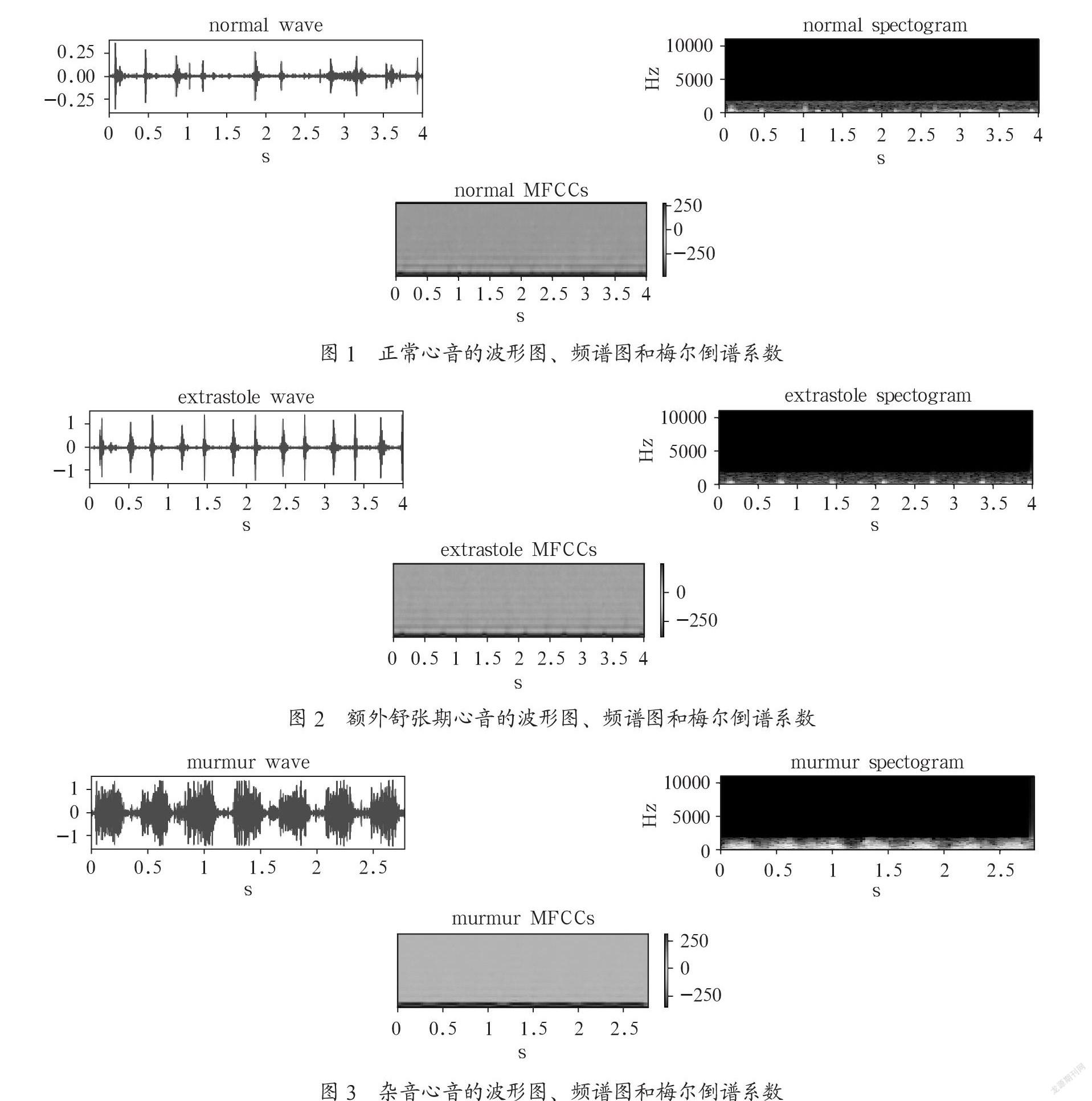
在语音识别和说话人识别方面,最常用到的语音特征就是梅尔倒谱系数,因为它能很好地表征音频特征。Librosa是本次实验用来提取特征的python library,基于此,首先把一维PCG音频信号转换二维time-frequency表示,即梅尔频谱,然后在梅尔频谱上取对数,做离散余弦变换(实验中dct_type取值为2)得到梅尔倒谱系数,对梅尔倒谱系数二维矩阵进行转置,然后对各列求均值,最终从每个音频文件中提取40个特征,然后拼在一起用来训练网络,时域信号波形、频谱图、梅尔倒谱系数如图1—图3所示。
1.3 神经網络
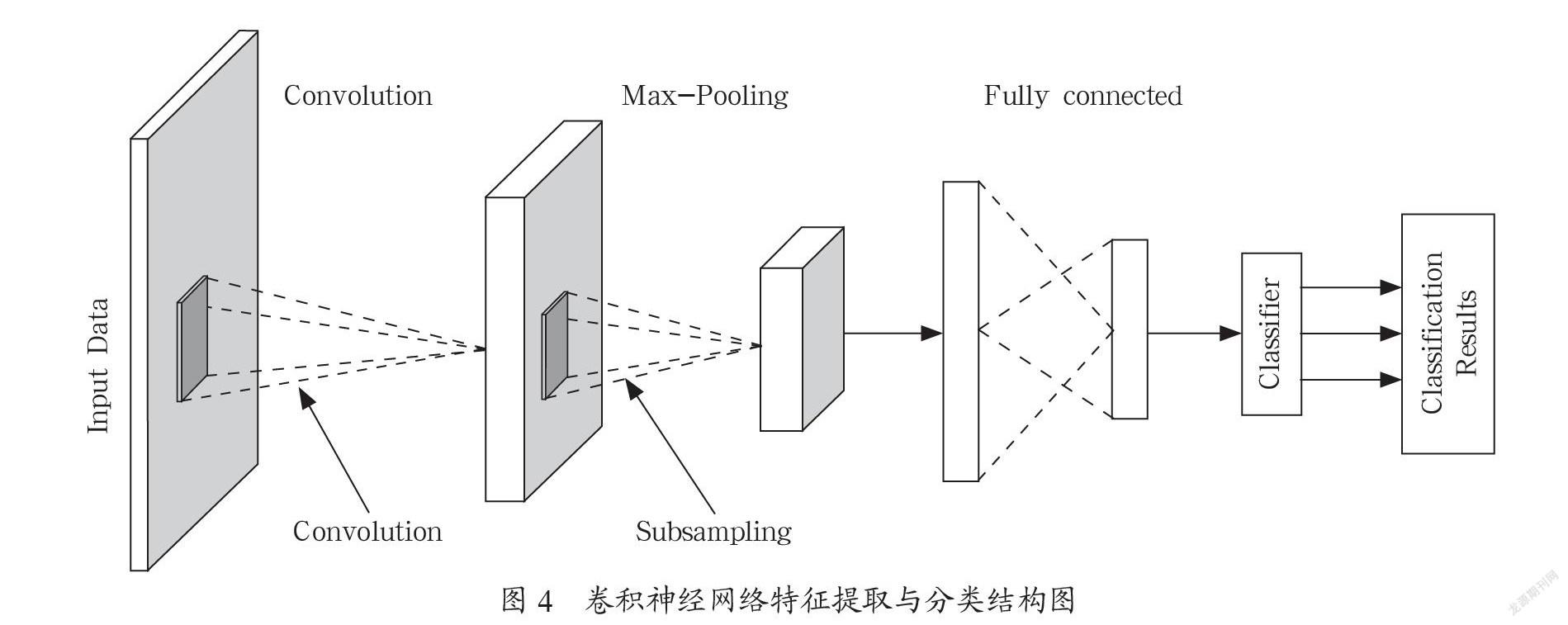
卷积神经网络(CNN)有一维卷积、二维卷积、三维卷积之分,一维卷积多用于在自然语言处理和语音识别领域,常用于序列模型,二维卷积多用于图像处理领域,三维卷积多用于视频处理领域(检测动作及人物行为)。本次实验使用的是一维卷积,卷积神经网络主要的隐藏层是卷积层和池化层,卷积层提取的是局部特征,池化层主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。然后全连接层对局部进行综合操作,从而得到全局信息,卷积神经网络结构图如图4所示。
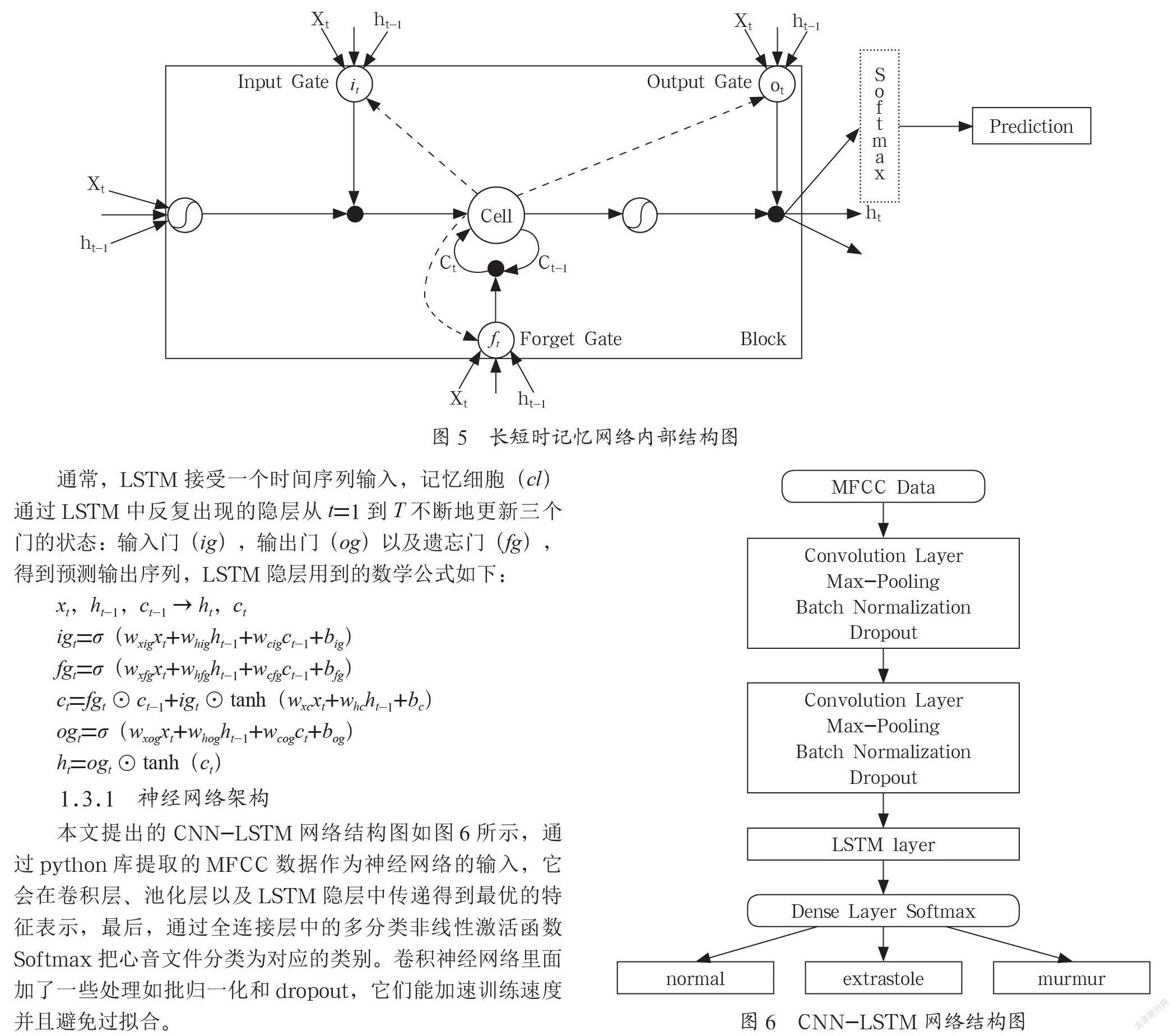
长短期记忆网络(LSTM)是RNN的变种,本质上也是一种循环神经网络,引入LSTM是为了解决RNN的梯度爆炸和梯度消失问题,长短期神经网络有一个记忆细胞块,主要由三个门与一个记忆单元组成。遗忘门的作用是将细胞状态中的信息选择性地遗忘,输入门的作用是将新的信息选择性地加入到细胞状态中,输出门的作用是根据细胞状态选择性输出信息,内部结构如图5所示。
通常,LSTM接受一个时间序列输入,记忆细胞(cl)通过LSTM中反复出现的隐层从t=1到T不断地更新三个门的状态:输入门(ig),输出门(og)以及遗忘门(fg),得到预测输出序列,LSTM隐层用到的数学公式如下:
1.3.1 神经网络架构
本文提出的CNN-LSTM网络结构图如图6所示,通过python库提取的MFCC数据作为神经网络的输入,它会在卷积层、池化层以及LSTM隐层中传递得到最优的特征表示,最后,通过全连接层中的多分类非线性激活函数Softmax把心音文件分类为对应的类别。卷积神经网络里面加了一些处理如批归一化和dropout,它们能加速训练速度并且避免过拟合。
1.3.2 实验设计
本文实验使用的是Keras神经网络框架,首先调用python库把数据集B按9:1的比例划分为训练集和测试集,把train_test_split函数中的random_state参数设为0,保证每次训练和测试的数据一样,然后把标签转换为对应的one-hot向量,在实验时把batch size设为12,训练轮数设为200,权重更新使用的是Adam优化器,损失函数使用的是交叉熵损失函数,然后进行参数设置,网络超参具体设置如表1所示,基于划分相同的数据进行训练以及测试,通过调整参数,记录LSTM、CNN,以及CNN与LSTM组合的网络不同层数最优结果。
2 结果
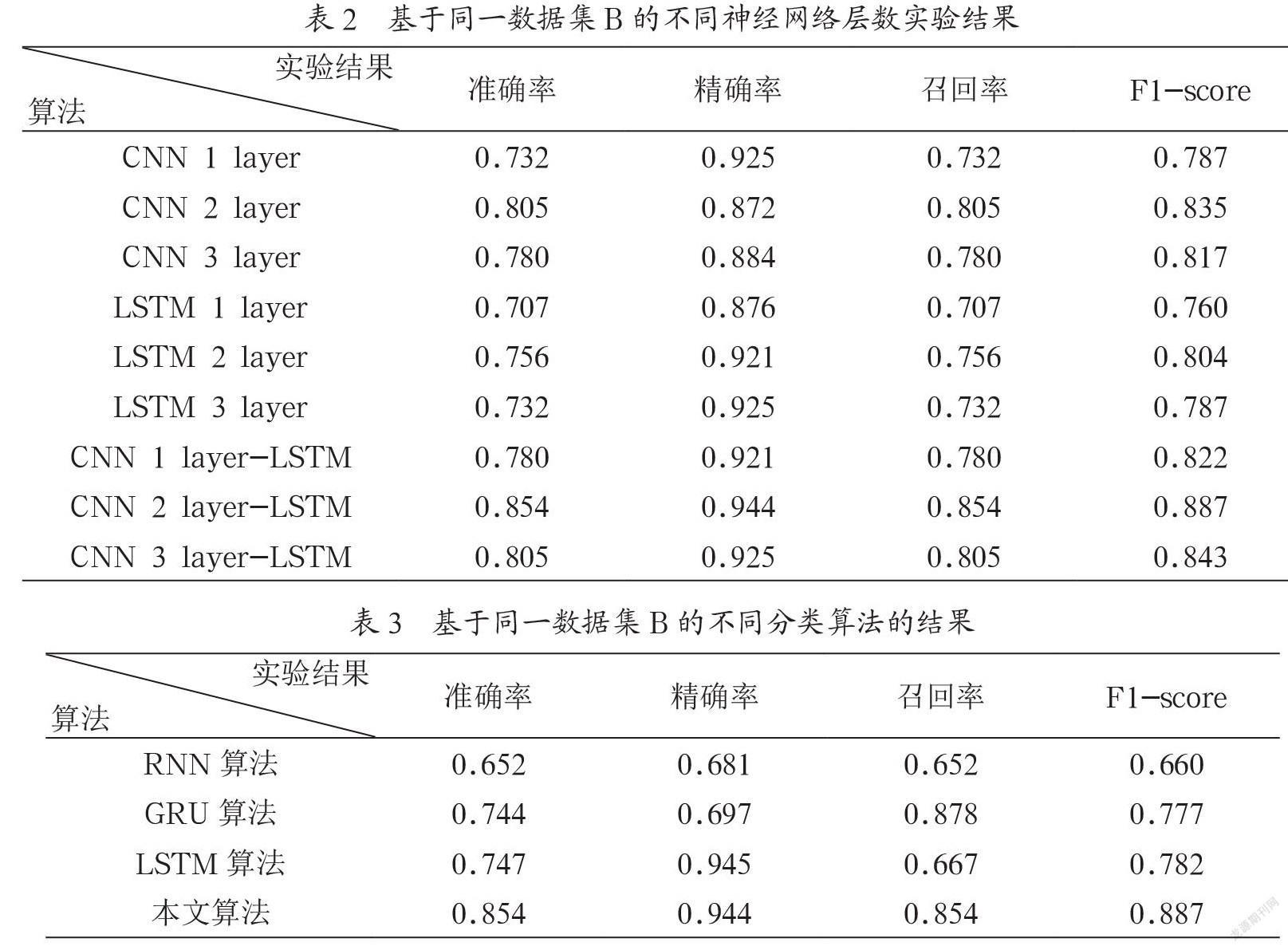
本文采用了四个常用的指标描述每种算法的性能。实验结果显示,基于本文提出的网络结构,即两层的卷积神经网络和一层的循环神经网络相结合,能够获得更高的识别准确率。表2显示的是CNN-LSTM与CNN、LSTM单一网络不同层数的对比实验结果。表3显示的是本文提出的方法与其他作者提出的方法实验结果的对比。文献[7]中,作者使用了三种记忆网络,分别是RNN、GRU和LSTM进行对比实验,RNN识别准确率是0.652,GRU的识别准确率是0.744,LSTM的识别准确率是0.747,其他指标结果如表3所示。
3 结 论
实验结果表明,卷积神经网络和长短期记忆网络的结合比单一神经网络具有更高的分类准确率,分类准确率达到0.854。即使在数据集相对较少的情况下,本文所提出的方法与其他方法相比也有很好的分类效果。在文献[7]中,即Sujadevi V G使用三种记忆网络在同一数据集上进行实验,这些网络分别是RNN、LSTM和GRU,其中LSTM的分类准确率最高,达到0.747,相信该方法在今后的实际应用中会得到推广。接下来,我们会收集更多的数据,并将其分为两类,以验证这种分类方法的通用性,此外,还需要改进特征提取技术和处理不平衡数据集,以提高模型的分类结果。
参考文献:
[1] BALILI C C,SOBREPENA M C C,NAVAL P C. Classification of heart sounds using discrete and continuous wavelet transform and random forests [C]// 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR),November 3-6,2015. Kuala Lumpur,Malaysia:IEEE,2016.
[2] LEUNG T,WHITE P,COLLIS W,et al. Classification of heart sounds using time-frequency method and artificial neural networks [C]// Proceedings of the 22nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (Cat. No.00CH37143),July 23-28,2000. Chicago,USA:IEEE,2000.
[3] NILANON T,PURUSHOTHAM S,LIU Y. Normal/Abnormal Heart Sound Recordings Classification Using Convolutional Neural Network [C]// 2016 Computing in Cardiology Conference (CinC),September 11-14,2016. Vancouver,Canada:IEEE,2016.
[4] BENTLEY P,NORDEHN G,COIMBRA M. Classifying Heart Sounds Challenge [EB/OL].(2012-03-30). http://www.peterjbentley.com/heartchallenge/index.html.
[5] CHAKRABORTY K,TALELE A,UPADHYA S. Voice recognition using MFCC algorithm [J]. International Journal of Innovative Research in Advanced Engineering (IJIRAE),2014,1(10):158-161.
[6] MOHAN B J,RAMESH B N. Speech recognition using MFCC and DTW [C]//2 2014 International Conference on Advances in Electrical Engineering (ICAEE),January 9-11,2014. Vellore,India:IEEE,2014:1-4.
[7] SUJADEVI V G,SOMAN K P,VINAYAKUMAR R,ET AL. DEEP MODELS FOR PHONOCARDIOGRAPHY (PCG) CLASSIFICATION [C]// 2017 International Conference on Intelligent Communication and Computational Techniques (ICCT),December 22-23,2017. Jaipur,India:IEEE,2017.
作者簡介:于乾坤(1992-),男,汉族,河南周口人,硕士研究生,研究方向:自然语言处理和音频信号处理;党鑫(1983-),男,汉族,天津人,副教授,工学博士,研究方向:音频信号处理、计算医学应用和嵌入式系统开发。
