一种基于文本相似计算的校园智能问答系统设计
2019-09-10李月周江
李月 周江

摘 要:问答系统是继搜索引擎之后诞生的又一用来帮助用户在海量数据中提高检索效率的系统。目前常见的问答系统主要应用于商业领域,针对在校学生这一特定用户群體的智能问答系统并不多见。本文在分析问答系统现状以及建设难点的基础上,提出了一种面向学校这一特定领域的,用来提升在校学生学习、生活质量的校园智能问答系统建设方法,并从语料库建设方法、问题及答案提取等多个方面进行了详细阐述。
关键词:问答系统;文本处理;相似度计算;语料库
中图分类号:TP311.52 文献标识码:A 文章编号:2096-4706(2019)22-0009-05
Abstract:Question Answering System(QAS) is a system that appears after the search engine to improve the retrieval efficiency of users in massive data. At present,the common QAS is mainly used in the business field,but the intelligent QAS for the students in school is rare. Based on the analysis of the current situation and difficulties in the construction of question answering system,this paper puts forward a construction method of campus intelligent question answering system,which is oriented to the specific field of school and is used to improve the quality of students’study and life. It also elaborates on the construction method of corpus,the extraction of questions and answers and so on.
Keywords:question answering system;text processing;similarity computing;corpus
0 引 言
随着互联网的快速发展,网络上流通的信息日益增加,人们所面临的问题不再是信息的贫乏,而是信息过载的问题。搜索引擎是目前常见的一种解决信息过载的通用解决方法,人们可以通过使用诸如百度、谷歌、360搜索等系统实现从海量数据里检索自己需要的信息。但是对于一个通用型的搜索系统来说,系统往往提供的也是大量存在冗余的搜索答案,用户还需要进行二次检索和分析才能取得自己真正需要的数据。在此情形之下,问答系统被开发出来并且搭载在各类系统上,成为系统解决用户疑问的一种辅助手段。针对特定用户设计和开发高效问答系统,可以有效解决信息过载的问题,提高用户使用系统的效率。
目前常见的问答系统通常针对商业领域。在信息检索需求上,除了商业领域的需求之外,还有很多非商业需求。如在校学生在学校生活中往往会遇到各种问题,而这些问题又不具备共通性,即这个学校的学生遇到的问题可能其他学校的学生并没有遇到过,或者这个学校的学生遇到的问题在这个学校的规章制度下具有特定的解答。因此,针对非商业应用的特定领域开发智能问答系统,能较好地解决该领域下用户的疑问,方便该领域用户的生活。本文即针对在校学生开发特定的非商业应用的智能问答系统,提升在校学生这一庞大用户群体在校园生活中使用信息数据的质量。
1 问答系统现状
问答系统的雏形最早诞生于七十多年前,国外科学家希望计算机能像人一样去理解和处理人类自然语言,但是受硬件设备和计算算法的限制,直到1980年左右,问答系统才开始真正受到人们的关注。计算科学之父图灵表示,具有人工智能的计算机应该能够像人类一样理解自然语言并进行交流[1]。随后人们开始关注并开展基于自然语言理解的研究和开发,越来越多的公司和研究机构也投入到基于自然语言处理的问答系统中来。
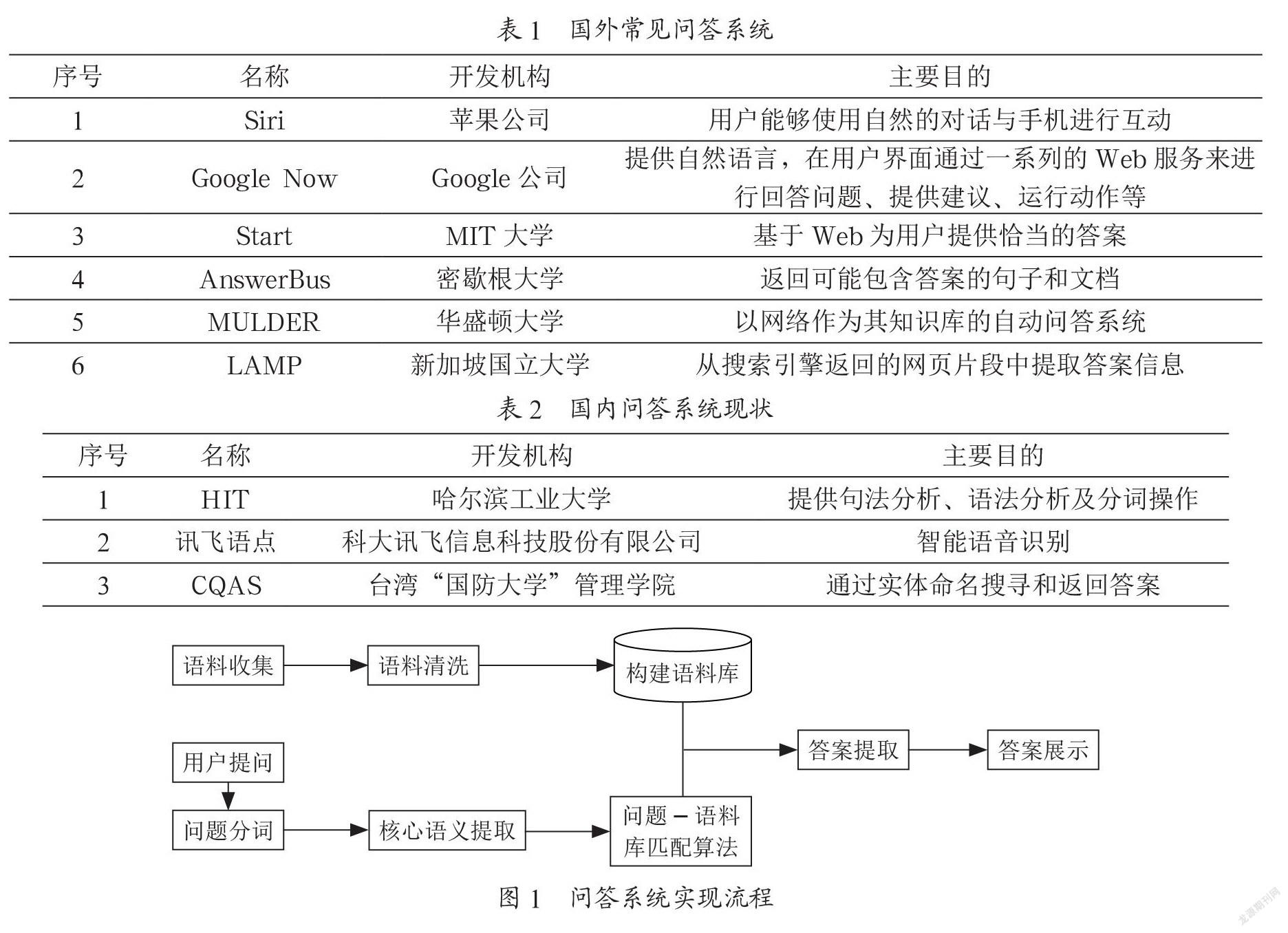
国外在问答系统技术上的研究起步比较早,目前在工业界或者学术界已经产出了一些比较成熟的问答系统和聊天机器人系统,例如,苹果公司的Siri,谷歌的Google Now,MIT大学的Start系统,还有AnswerBus、MULDER、LAMP等,其开发机构和使用目的如表1所示。
与国外研究相比,国内的问答系统发展较为缓慢。主要原因在于中文的信息处理与英文、法文、德文等语言体系不同,在语义解析、词法分析上较为困难,在将国外现有的问答系统迁移到中文系统上时存在较大的语言差异鸿沟。另外,问答系统的构建基础之一是语料库的建设,基于中文的问答系统在构建时需要重新设计和建立语料库,也无法重用国外现有系统的语料资源,因此提升了中文问答系统的建设难度。
国内在问答系统领域走得比较靠前的研究机构主要有清华大学、北京大学、中科院计算所、哈工大、北京语言大学等,另外研究汉语问答系统的还有香港大学、香港中文大学等单位[1]。目前国内常见的问答系统如表2所示。
2 问答系统关键技术
在中文问答系统的实现中需要经过语料收集、问题解析、答案提取及答案展示几个阶段,具体实现流程如图1所示。
在系统实现过程中,首先需要构建庞大的语料库。语料库内容的广度与深度决定了问答系统中答案的质量。如果语料库过小,则问答系统会遇到答案抽取失败的情况。如果语料库质量过低,则在问答过程中则会出现“答非所问”的情形,同样会影响用户体验。但是要构建一个高质量的庞大语料库,需要花费大量的时间及硬件资源。本文所探讨的系统设计针对特定领域,即主要针对学校这一特定环境开发智能问答系统,因此在语料库的建设上必须针对特定领域收集、整理数据。除语料收集具有特定性之外,智能问答系统在建设上还具有分词技术、语义消歧等通用型的问题需解决。
2.1 中文分词
中文分词是自然语言处理过程中的一个技术问题。在问答系统中,用户的提问是一个完整的句子,里面的内容从形式上看是一个一个的汉字,但是从语义理解上来看,里面包含的既有单个汉字也有连续的词语。中文分词技术就是将汉字序列切割成一个个单独的词语。与英文分词不同,英文的句子里单词和单词之间以空格作为分界符,因此英文分词技术相对来说简单很多[2]。中文句子里通常只包含逗号(,)、分号(;)、顿号(、)等分隔符,分隔出的也是一段具有完整含义的内容,并不存在分隔符将词与词隔开,因此中文分词要显得复杂而困难。
目前常见的中文分词技术主要基于以下三种:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[3]。基于字符串匹配的分词方法又叫作机械分词方法,该方法将需要分解的句子按照一定的规则与一个足够大的词典进行逐词扫描匹配,如果在这个足够大的词典中能找到某个一致的字符串,则将这个词识别出来并将其与周围的字分隔开。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法[4]。
基于理解的分词方法是通过算法让计算机模拟人识别句子的过程,将输入的句子切割成单个单词。但是由于汉语的语言系统历经几千年的发展,具有其特有的复杂性、概括性等特点,难以将中文像英文等西方语言体系一样较好地转化为计算机可以理解的形式,因此目前基于理解的分词系统还处在试验阶段。
基于统计的分词方法主要是采用基于统计学的知识对文本进行识别并分词。从汉语语言的使用习惯上来看,中文词是一种相对稳定的字与字的组合,如果一个字与另一个字相邻出现的频率越高,则这两个字构成词语的可能性就越大。基于统计的分词方法就是统计字与字相邻出现的频率或概率,通过设定一个概率阈值判定是否构成词语[5]。目前基于概率统计的分词方法应用也较为广泛,但是该方法也有一定的缺陷,即会在词语抽取上抽取出一些经常搭配出现,但是在语义上并不构成词语的“伪词”。
2.2 语义消歧
中文问答系统构建中还需要解决的一个问题是语义歧义的问题。与英文词语不同,英文单词是天然有间隔的,计算机在分析句子的时候不存在会将一个单词的一部分与另一个单词的一部分连接起来从而构成新词去理解的情形。但是基于中文系统中词语间不存在间隔的现状,中文问答系统在理解句子时可能会出现对词语存在多种解答的情况。例如一个句子“我家门前有条大河很难过”,这里面可以分割出“我家”“门前”“有”“条”“大河”“很”“难过”一种分词结果,也可能分割出“我”“家门”“前”“有”“条”“大河”“很”“难过”这另一种分词结果。这两种分词下体现的语义就完全不同。在汉语体系里,“家门”和“门前”是完全不同的含义。此外,即使是同一种分词结果,系统在理解上也可能存在歧义。如上一句的分词结果:“我家”“门前”“有”“条”“大河”“很”“难过”,其中对于“难过”一词的理解也会存在不同含义。“难过”可以表示心情低落不开心,也可以表达动作上难以通过的意思,系统在理解上同样可能存在歧义。
2.3 未登录词识别
问答系统对于问题的理解是基于语料库知识的理解,而语料库的创建具有时效性,可能会出现在问答过程中出现语料库未收集词语的情况。在自媒体与微媒体日益发达的今天,用户的语言习惯也发生了巨大的改变,许多基于互联网的新词层出不穷并且扩散速度很快,很可能有一个词上个星期还不存在,但是这个星期人们在互联网上已经开始大面积使用了。这些未被收集及识别的词即称之为“未登录词”。常见的未登录词包含一些人名、地名、公司名、互联网流行语等等。在问答系统中,对于新词的收录更新率也成为了问答系统用户体验度的检验标志之一。
2.4 短文本语义提取
在问答系统中,用户的提问往往就是一两个简单的句子,文本篇幅较短。对于用户提问,要抽取正确答案,还需要理解用户提问数据的核心内容,也就是需要对用户问题实现核心语义提取。在用户语义提取上,即需要理解用户问题的关键词,也需要结合用户问题的语境,还需要综合考虑用户提问时的上下文环境,在多方面数据信息结合的基础上,才能够正确理解用户问题的核心本质,从而从语料库中抽取最符合该问题的答案[6]。目前关于自然语言处理中的核心语义提取主要还是基于关键词的提取方式。
3 特定领域问答系统构建方法
本文主要针对校园环境这一特定领域用户构建智能问答系统,因此系统构建不论从用户分类、使用目的、语料库构建上都存在与学校这一特定环境相关的特定内容。与通用型的问答系统不同,针对校园环境构建的问答系统用户主要面向在校学生,他们希望获取的信息内容主要和在校生活相关,如课程相关问题、学籍管理问题、校园制度问题、后勤管理问题等。除此之外,也存在校外游客需要针对校园相关问题提问并获得解答。因此,针对校园领域的智能问答系统的用户主要包含以下三种,如表3所示。
3.1 语料库构建
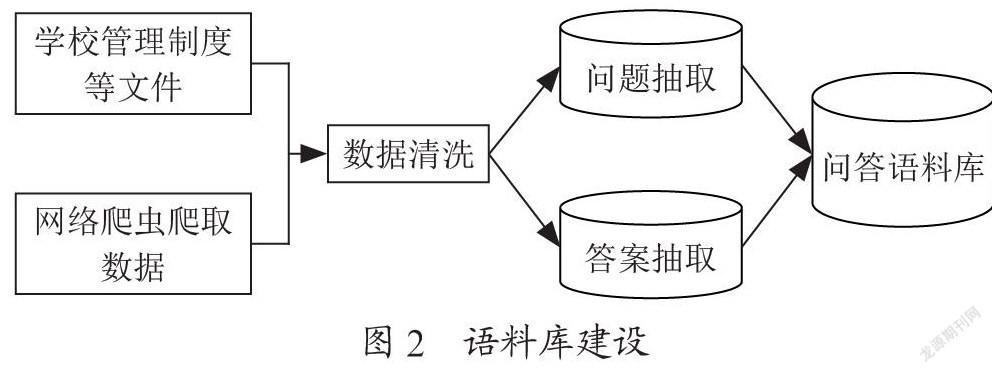
针对校园环境这一特定领域的问答系统在语料库构建上并无太多可以借鉴的已有语料知识,主要原因在于不同的学校具有不同的管理制度,数据信息存在较强的个性化特点,因此要构建一个智能化的校园问答系统,首先需要收集各类校园相关的数据资料作为语料库构建的基础。语料来源可以是学校的有关规章制度、工作手冊或管理规范,也可以来源于学校在信息化建设中形成的网络数据信息。对于网络数据信息可以采用爬虫技术爬取相关内容,然后经过数据清洗形成可以进入语料库的数据。在语料库构建上可以采取基于以下流程的建设方法,如图2所示。
对于获得原始语料信息,需要将长文本切割成短文本以方便实现问题和答案的抽取。对于整理形成的短文本,还需要运用分词技术提取文本核心信息。目前常见的中文分词工具包括开源及商业应用两种,应用较为广泛的开源分词工具包括HanLP、结巴分词、FudanNLP分词、THULAC分词等,这些工具在实现上涵盖了支持Java、C++、Python等主流编程语言的实现方式。虽然不同工具分词的准确率和时间效率有所差异,但是对于校园环境下的问答系统建设而言,这些开源工具的分词结果都是可以接受的。
3.2 文本相似度量算法
在构建尽可能完善的语料库的基础上,提高问答系统效率、提升用户使用感受的另一影响因素是对用户问题在语料库中的匹配检查。因为问答系统中用户提交的是文本数据,因此在语料库中寻找与用户问题匹配的答案时最关键的技术就是基于文本相似度的计算。
目前基于文本的相似度计算主要包含三种方法[7,8]。第一种是基于单词重叠数量统计的计算方法。该方法主要分析两个不同的文本中相同单词重叠的数量,数量越多,则认为两个文本越接近。但是这种方法仅仅考虑单词出现的数量而不考虑单词出现的位置,以及其他单词对文本语义的不同贡献,属于较为粗略的文本分析方法,在使用过程中也常常会出现提取共性失败的情况。第二种方法是基于单词语义相近度度量的方法。该方法通过将单词转换成向量,计算不同向量之间的相似程度来衡量不同单词的相似性。该种方法解决了中文中同一含义可能有不同表达方式的情况,比起机械衡量两个单词是否一样更加切合问答系统的实际使用情形,但也存在无法整体解析句子含义、上升到句子层面整体衡量相似度的缺陷。第三种方法是以句法作为衡量依据,通过计算两个句子之间的相似程度提取问题核心。该种方法更加符合用户实际情况,可以减少问答系统中提取失败或者对应到语料库时问题精确度低的情况。本文设计的问答系统主要针对句子进行相似度的计算。
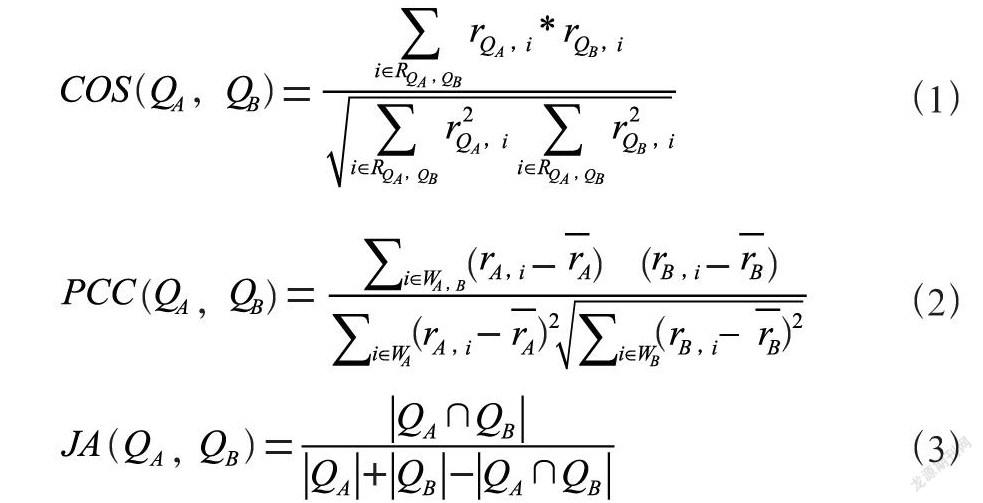
針对文本进行相似度计算首先需要将中文文本转换成计算机可以识别并计算的形式。通常情况下是将文本转化为一个向量矩阵。对于学校领域下的智能问答系统,首先可以将用户问题转化成向量Q,其中Q=(q1,q2,q3,…,qn),其中Q表示问题向量,qi表示向量中的第i个维度。对于两个文本向量,可以对其相似度进行计算。常用的相似度计算方法有余弦相似度计算(COS)、皮尔森相关系数计算(PCC)、Jaccard系数计算(JA)等方式,对于两个问句A和B,其计算公式如下:
在文本相似度计算中,不同的相似度计算方法带来的计算结果也各不相同。因为本文探讨的智能问答系统中,用户提问往往是一两个简短的句子,因此收集到的文本属于较短的文本类型。对于短文本通过转化形成的向量,往往具有较低的维度。因此,在计算问答系统中的提问文本相似度时,对于低维度数据,选用Jaccard系数进行计算比较有计算优势。
3.3 相似度阈值
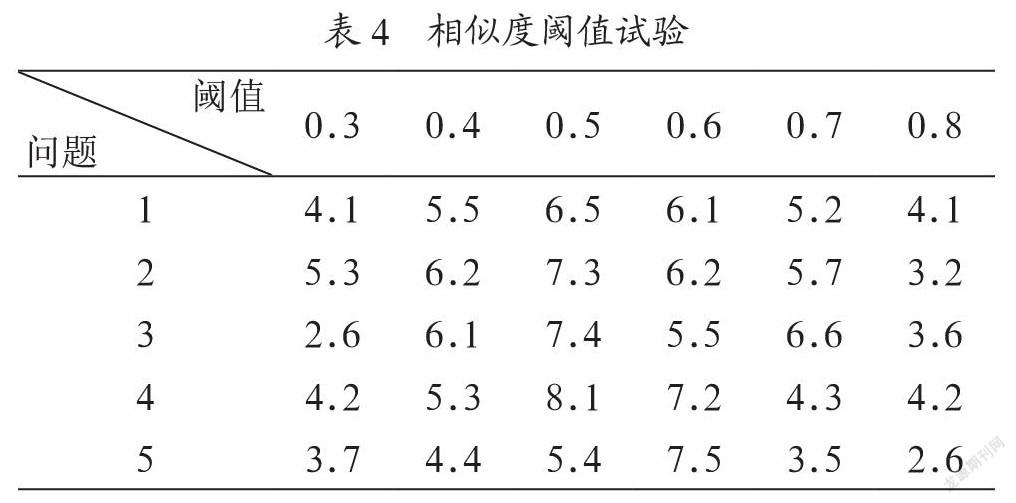
对于计算得到的相似度数据,还需要根据实际情况设置相似度阈值。如果相似度阈值设置过高,那么在系统实际运行过程中会出现用户问题在语料库中找不到匹配问题的情况,导致系统无法给出回答,会极大地影响用户体验感受。同时,如果相似度阈值设置得过低,则会在系统运行中出现用户的一个问题可以在语料库中匹配到多个答案的情况,这样系统实现的效果将与普通搜索引擎毫无区别,用户依然需要从大量数据中二次检索答案。因此,一个合理的相似度阈值设置在系统设计中至关重要。在本文中,为找到短文本相似度设置的最佳阈值进行了多次试验,在相同语料库的基础上,采取50名志愿者对系统给出的答案进行评分(10分记为满分),每个问题的评分取50个用户的评价平均值。每个问题在语料库中搜索答案时,相似度阈值分别从0.3、0.4、0.5递增至0.8。对于不同问题在相同语料库下获得的答案满意度试验数据如表4所示。
表4 相似度阈值试验
从上表数据可以看到,在相似度阈值较低和较高的情况下,用户评分都不理想,在相似度阈值为0.5或0.6时可以取得试验中较为满意的评价。但是需要注意的是,用户满意度除了与相似度阈值的设定有关系之外,还和语料库的大小有关。只有在语料库数据充分涵盖用户实际生活中会遇到的问题时,用户才能获得较好的问答体验。否则在语料库不充分的情形下,即使将相似度阈值设置为试验取得的最好数据,用户也会产生较差的用户体验。
4 结 论
问答系统经历了多年的发展,已经取得了一定的成就。但是目前的问答系统一般针对商业应用领域,针对在校学生构建的问答系统并不多见。我国现有2000余所高校,在校学生人数超过3000万人,针对这一庞大的用户领域构建面向学生的问答系统具有较高的应用价值。但是针对特定领域的问答系统构建不论从语料库的建设还是问答方式的设计上都需要针对领域问题寻找最适合的方法。在本文探讨内容的基础上,还可进一步研究在智能问答系统中加入语料库自动增长、语料库自动纠错的设计,从而使得面向学校这一特定领域的问答系统具有更高的智慧。目前问答系统虽然已有一定的建设成果,但是在大数据和人工智能蓬勃发展的今天,面向特定领域的问答系统也还有更多的建设细节亟待建设者去思考和探索。
参考文献:
[1] 冯升.聊天机器人问答系统现状与发展 [J].机器人技术与应用,2016(4):34-36.
[2] 黄伟,范磊.基于多分类器投票集成的半监督情感分类方法研究 [J].中文信息学报,2016,30(2):41-49+106.
[3] 王朝.面向网上订餐的垂直搜索引擎的设计与实现 [D].成都:电子科技大学,2016.
[4] 徐晓.智能答疑系统的设计与研究 [J].微型机与应用,2014,33(5):8-10.
[5] 雷鹏飞.舆情系统中特征选择和情感分析的研究与实现 [D].成都:电子科技大学,2017.
[6] 郭浩,许伟,卢凯,等.基于CNN和BiLSTM的短文本相似度计算方法 [J].信息技术与网络安全,2019,38(6):61-64+68.
[7] 赵永标,张其林,谷琼.社区问答系统中基于当前兴趣的问题推荐研究 [J].现代信息科技,2019,3(11):1-4.
[8] 张明辉.情感分析在商品评论中的应用 [J].现代信息科技,2019,3(10):187-190.
作者简介:李月(1979-),女,汉族,湖北荆门人,讲师,硕士研究生,研究方向:机器学习、人工智能、软件工程。
