利用读者行为的协同过滤推荐方法的研究
2019-09-09刘宇航
刘宇航


概要:在大数据时代下,越来越多的公共图书馆的服务正在经历由业务驱动转型为数据驱动,传统的图书推荐多由工作人员进行整理后推荐。文章提出一个基于协同过滤的推荐算法,利用读者借阅行为(预约、借书、还书)数据进行分析,构建出读者行为评分矩阵、图书相似矩阵,再利用两个矩阵进行推荐的方法。结合广西壮族自治区图书馆业务数据测试,该方法确实可以。
关键词:协同过滤 读者行为 公共图书馆 推荐算法
引言
在当今大数据时代下,数据驱动使得服务模式发生变化。公共图书馆的服务策略应该由传统的被动式服务转变成主动式服务,而主动提供服务的其中一个特征就是提供推送式推荐服务。协同过滤推荐算法是推荐算法中的经典,其实现通常依赖于构建用户物品评分矩阵,然后对用户偏好或相似物品分析,从而实现推荐。在此基础的推荐方式上,衍生出许多分析不同特征实现推荐的方式。一种是通过精准把握读者兴趣偏好,实现成功推荐是推荐。其是通过分析资源内容和跟踪读者在阅读时产生的浏览行为两个维度进行相似度匹配,从而实现成功推荐。但是这种跟踪读者浏览行为的方式,局限于数字资源,而面对实体文献资料的推荐就显得力不从心;一种是通过分析图书语义,既利用LDA计算图书摘要语义建立偏好模型,实现推荐。这种方式可以利用商业数据库等方式轻松获取该文献的摘要建立模型,但是,该思想的提出是基于高校图书馆,两类图书馆的定位存在本质的不同,因此该算法能否很好的服务公共图书馆有待进一步的研究。还有一种是基于读者主动标记标签进行图书推荐,根据读者对兴趣资源主动标注,然后利用余弦相似度找到读者标注的临近标签进行资源的推荐。该方法充分利用了读者的主观能动性,在一段时间内可以较快的推荐出较为准确的资源,但是从长远来看,该推荐思路极大的受制于读者主观意识,随着主观意识的改变.可能最后回归成“RSS式”的推荐。
针对上述研究所产生的问题,本文拟利用一种从多个维度出发,分析读者行为的方式进行图书的推荐。首先找到当前图书馆活跃的读者,尽可能减少不活跃读者的行为干扰,然后在根据活跃读者的行为习惯找到合适的推荐该推荐算法所需的数据集公共图书馆易于采集,且该算法从更客观的角度为读者推荐图书,避免了主观意识对推荐结果的过分影响,形成“扎堆”推荐。
1基于读者行为推荐方法
1.1 获取数据集
公共图书馆面向的读者群体注定公共图书馆的读者人员成分较为复杂,一些读者甚至呈现出周期性的变化,因此过多考虑非活跃读者和未充分考虑活跃读者都会影响推荐的效果。本文通过读者借阅行为提出了一套活跃度的计算方法,获取单位时间可供进行行为分析的数据集。通过选取合理的数据集,可以一定程度上避免不活跃的用户和刷分的用户的行为数据的干扰,为实现更为精准的推荐作保障。
通过式l表示出可供分析的数据集。Uo表示可供分析的读者行为的数据集,A表示读者活跃度的平均值,σ表示读者标准差。
最后选取正负一个标准差内的数据集作为该读者可供分析行为的数据集。
1.2 方法的描述
协同过滤算法主要是依据用户评分进行推荐的,但本文介绍的是利用读者行为数据进行推荐的,因此需要将用户行为数据转换为潜在的评分。
(1)行为评分的生成
在公共图书馆读者行为主要产生在文献的流通上,而流通的主要行为就是预约、借阅和续借。因此通过选择合适的颗粒度,可以将借阅时长与续借时长转换为具体的评分,同时将评分与该单位时间的活跃度相乘可得最终评分,如果用B表示借阅时长,R表示续借时长,P表示允许预约最大时限和完成预约所需时间的差值,A表示该行为所在时间段的活跃度,可以得到评分公式:
由于并非所有读者都會阅读所有的图书,且并非所有的图书都有读者进行借阅,因此Anm是一个稀疏矩阵。
(3)构建图书相似度矩阵
公共图书馆的文献资料都会使用分类法进行分类,这是判别图书分类的一个比较重要的依据,但仅此判别是远远不足的,还需要从一些客观条件进行判别。本文还在已进行分类的图书中,再通过出版时间、页数组成三个维度计算出闵可夫斯基距离作为相似度的判别依据。
由于闵可夫斯基距离计算结果大小与相似度成反比,因此为方便后续计算,以D表示闵可夫斯基距离,详见式4,S表示相似度,可得公式:s=1/D。 当D无限趋近于0时,S趋近于l,当D趋近于正无穷时S趋近于0。本文从三个维度进行计算,因此在式4中P=3。
2实验过程及讨论
2.1 数据来源与环境约束
为验证基于读者行为的协同过滤推荐算法,从广西壮族自治区图书馆近5年的业务经办系统部分业务数据中抽取出实验数据集,部分业务经办数据有83055个读者和5831720条行为记录,从中随机抽取出1000个读者作为实验数据集。
在读者行为评分中,活跃度的颗粒度、预约时长、借阅时长、续借时长的确定,均是建立在广西壮族自治区图书馆现行制度下。活跃度颗粒度约定为1个自然月,单位时长约定为12个月。预约时长、借阅时长和续借时长分别约定为7、30和10个自然日。根据上述约定,单个读者最高评分 Rating max =A(B+ R+P)=1* (30+ 10+7) =47分,最低分为0分。
2.2构建读者行为评分矩阵
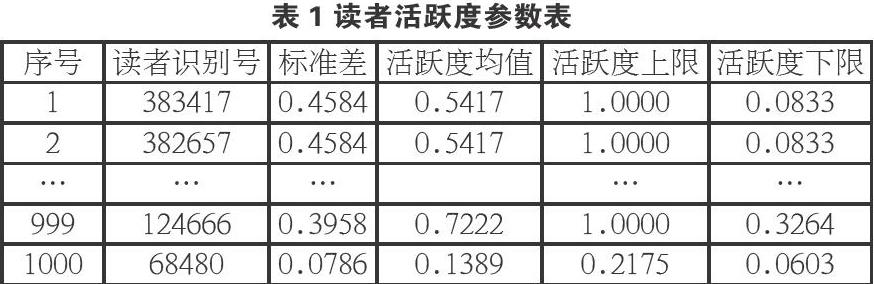
通过对数据集进行计算出得到用于活跃度的参数表,如表l。然后根据活跃度上下限判别读者行为记录是否纳入计算,纳入范围的行为记录记人数据集。图1和图2分别为读者有效记录活跃度的散点图和抖动图。根据散点图可以得到随机抽取的有效读者行为记录活跃度分布较为平均,以y轴负方向为收敛趋势,符合广西壮族自治区图书馆的读者行为趋势,因此随机抽取读者行为样本具有代表性。
根据原始数据,通过活跃度和行为评分的乘积,得到有效的读者行为评分,生成矩阵。将实验数据有效的读者行为评分通过热力图绘制后,得到图3。
2.3 构建图书相似度矩阵广西壮族自治区图书馆是依据第五版《中国图书馆分类法》进行分类,因此将图书分类法映射为数据作为一个维度,配合出版年份,页数三个维度计算出相似度。
根据现有资源库,随机抽取出2000本图书(包含上述读者行为关系的图书),构建出相似矩阵。由于相似矩阵庞大,此处采用MysoL数据库进行存储。将抽取的样本数目的闵可夫斯基距离绘制成热力图(如图4),横坐标轴和纵坐标轴表示2000本书目映射编号。由于横纵坐标均相同,因此矩阵呈明显对称性。
2.4生成推荐矩阵
在获取了行为评分矩阵和相似度矩阵的基础上,可以将两个矩阵相乘,所得的乘积就是加权评分,而分数高的就是推荐矩阵。此处通过SQLAlchemy创建数据库表模型,再利用python的numpy库完成两个矩阵的相乘得到推荐矩阵。以横坐标轴为图书映射编号,纵坐标轴为读者映射编号绘制出推荐矩阵热力图(如图5所示)。
每个读者根据预先设置好的阈值,可以从推荐矩阵中找到超过阈值的图书,然后将这类图书推送给对应读者,即可实现图书的推荐。
3结语
个性图书的推荐属于是未来的发展趋势,本方法能够利用读者群体自身的行为动作建立数据模型,在根据此模型对其他相似读者进行推荐。下一步将对读者异常行为(预期、损坏等)等动作进行分析,完善推荐模型。
参考文献
[1]景民昌,于迎辉,基于借阅时间评分的協同图书推荐模型与应用[J].图书情报工作,2012,56(03):117-120.
[2]严凡,张霁月.基于图书语义信息的推荐方法研究[J].图书馆学研究,2018(21):40-45.
[3]向菲,彭昱欣,邰杨芳,一种基于协同过滤的图书资源标签推荐方法研究[J].图书馆学研究,2018(15):46-52.
[4]DeGang Xu,Pan-Lei Zhao.Chun-Hua Yang,WeiHuaGui.Jian-Jun He.A Novel Minkowski-distance-based ConsensusClustering AlgorithmLJl.lnternational Journal of Automation andConlputing,2017,14(01):33-44.
