云存储环境下的安全密文模糊检索方案*
2019-08-27张昌宏
张昌宏,陈 元,付 伟
(海军工程大学信息安全系,武汉430033)
0 引言
随着用户数据的日益增长,云存储服务[1-2]得以发展并逐渐成为一项热门的数据存储技术。服务商通过整合网络中的存储资源,向用户提供专门的数据存储及访问服务。然而在云存储服务提供商(CSP,cloud storage provider)[3]信任受限的条件下,用户隐私敏感数据的安全性保护成为目前的研究热点之一。
密文检索技术[4-13]可将用户的隐私敏感数据加密后再上传至CSP,并支持授权用户的检索请求,在保证数据机密性的前提下,保持了可检索性。同时,由于检索操作可以直接在密文上进行,而不用将CSP中所有的密文数据下载、解密之后再检索,因此,可以极大地提高用户和服务器的工作效率,并有效降低网络消耗带宽。
在传统的明文检索技术中,由于检索用户掌握的数据与真实数据之间存在着误差,仅仅依靠精确匹配无法完成相应的检索功能,因此,支持模糊匹配是十分必要的。然而,在密文检索中,即使明文数据之间存在较小的误差,加密后密文之间的误差会变得很大,因此,密文模糊检索功能具有很大的挑战性[13]。
本文通过分析传统的明文模糊检索技术,结合密文检索的特点及要求,提出了一种安全且高效的密文模糊检索方案。方案以关键词的频率为权值并引入Huffman树形结构及其编码的思想构建密文关键词索引结构,采用Bloom-Filter存储关键词的模糊集合,最后通过改进的TF-IDF规则对检索出的密文文档进行评分排序,以返回最符合用户需求的Top-k结果。
1 相关研究
根据检索匹配精度的不同,可以将密文检索技术分为精确密文检索[4-8]和模糊密文检索[9-13]:
1)精确密文检索技术。Song等人[4]最早提出基于对称加密体制和伪随机函数的可搜索加密方案,虽然证明了方案的安全性,但是由于性能与密文的长度成正比,效率较低;Boneh等人[5]提出基于双线性对和Hash函数的非对称加密检索方案,实现了明文的机密性和密文的可检索性;Hwang等人[6]提出基于连接关键词的多用户非对称密文检索方案,方案所需的存储空间较大;Wang等人[7]提出连接关键词字域可变的密文检索方案;Cao等人[8]提出支持多关键词排序的隐私保护检索方案,但在排序算法中并未考虑到关键词频率。以上方案均只适用于关键词的精确匹配,不适用于模糊检索。
2)模糊密文检索技术。相比于精确密文检索,模糊密文检索的难度要更高。Park等人[9]提出基于椭圆曲线和Hamming距离的密文模糊检索方案,安全性较高,但是效率较低;Li等人[10]提出基于通配符和编辑距离的模糊匹配模式,效率较低;Liu等人[11]提出基于字典的模糊集构造检索方案,将索引长度降到最低,且效率较高;Wang等人[12]在文献[10]的基础上构建了语义树索引,提高了效率,但抵御统计分析攻击能力不足。
Li等人[13]通过TF-IDF规则对关键词进行评分,并以此为权值构建Huffman索引树,基于通配符和编辑距离建立关键词模糊集,在保证安全性的前提下,提高了密文模糊检索的效率,但是方案不支持结果集的排序。
2 模型描述及设计目标
本节主要对系统模型、敌手模型进行描述,并对其提出相应的设计目标。
2.1 系统模型

图1 密文模糊检索模型
如图1所示,密文模糊检索模型主要由4个角色组成:数据拥有者(DO,Data Owner)、可信第三方(TTP,Trusted Third Party)、云存储服务提供商(CSP,Cloud Storage Provider)和数据检索者(DS,Data Searcher)。
1)DO:数据拥有者将隐私敏感数据及其关键词发送给可信第三方,同时可以提出密文检索请求;
2)TTP:可信第三方加密明文数据并根据DO提供的关键词建立模糊检索集及其索引,将加密后的索引及密文上传至CSP;当DO和DS提供检索请求时,TTP会根据用户提供的关键词生成检索陷门并发送给CSP;
3)CSP:向用户提供数据存储、下载及检索服务;
4)DS:数据检索者经DO授权后可以提出密文检索请求并获取相应的数据信息。
2.2 敌手模型描述
本文将CSP视为“忠实但好奇”的半可信敌手模型。一方面,CSP能够忠实履行与用户之间的服务等级协定(SLA,Service Level Agreement)[14],向其提供稳定的数据上传、下载及检索等服务;另一方面,CSP出于好奇会对用户的访问行为和记录进行分析,因此,用户隐私敏感信息存在着一定的安全性威胁。
2.3 设计目标
模型的设计目标主要有以下3个方面:
1)安全。保证用户隐私敏感数据的安全性,包括明文、关键词索引及陷门和检索过程的安全性;
2)高效。符合绿色计算的要求,既要减小存储空间,又要保证密文检索的效率;这里所说的存储空间主要是指关键词索引所占的存储空间;
3)可靠。系统能够给用户提供可靠的数据存储和密文检索服务。
3 安全密文模糊检索方案
通过分析传统的明文模糊检索技术,并结合密文检索的特点及要求,本节提出了一种安全且高效的密文模糊检索方案。为提高检索效率,方案以关键词的频率为权值构建Huffman树并将其作为密文关键词索引;通过Bloom-Filter存储关键词的模糊集合,既能够减少存储空间又可以实现快速匹配;最后通过改进的TF-IDF规则对检索出的密文文档进行评分排序以返回最符合用户需求的Top-K结果。
3.1 预备知识
3.1.1 Huffman树及其编码
Huffman树又被称为最优二叉树,是一种带权路径长度最小的树形结构。由于权值越大的节点深度越小,访问路径也越短,因此,将其应用于索引结构构建方案中会极大地提高检索效率。以权值分别为1、2、3、4、5的节点为例,Huffman树的构造过程如下:
1)将这5个权值节点作为5棵只有根节点的二叉树,左右子树均为空;
2)选取权值最小的两棵二叉树即1、2节点,将其作为左右子树构造成一棵新二叉树,其权值为左右子树节点的权值之和即3;
3)删除已用的1、2节点,并将新构造的3节点作为一棵新的二叉树;
4)重复2)和3),直至用完所有的权值节点,最终构造成Huffman树。
对Huffman树进行二进制编码时通常用0表示左分支、1表示右分支,则图2中1~5节点的编码分别为010、011、00、10、11。
3.1.2 Bloom-Filter(布隆过滤器)


图2 Huffman树形结构
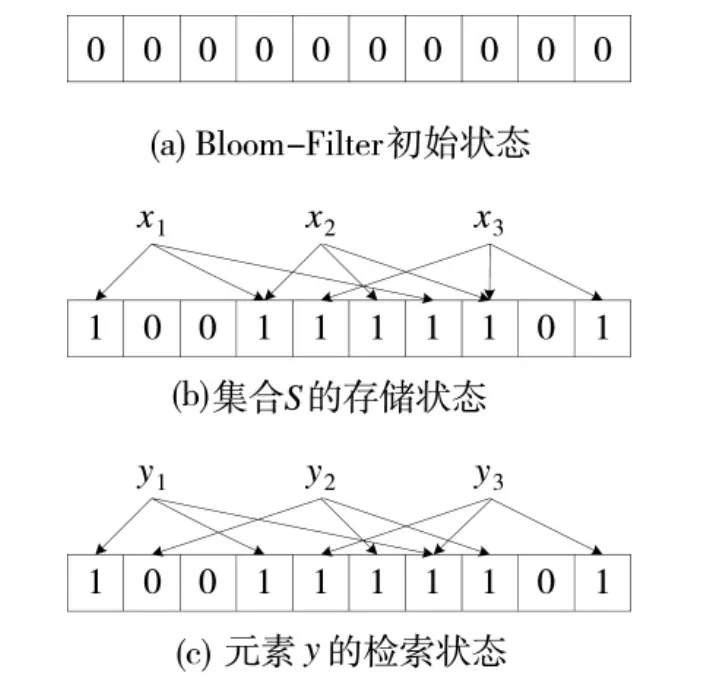
图3 Bloom-Filter存储及检索示意图
如图3所示,根据判定原则,y1极有可能属于集合S,但也存在误判的情况;y2不属于S;虽然y3对应的值全为1,但是位置不对,因此,也不属于S,而是假阳性元素[13,15]。
3.1.3 TF-IDF规则
TF-IDF规则是一种基于权值的评分排序机制。在整个文档集中,关键词与指定文档的关联程度与该关键词在指定文档中的频率成正比,与该关键词检索命令中的文档数成反比。针对关键词wi,文档Fi的评分为:

其中,TF指关键词wi在指定文档Fi中的词频;指文档Fi在整个文档集中的频率,N表示文档总数,DF表示关键词wi命中的文档数。
3.2 基于Huffman树和Bloom-Filter的安全密文模糊检索方案
方案主要分为关键词模糊集生成、Huffman树形索引结构构建、陷门生成及检索和密文文档排序4个部分。
3.2.1 关键词模糊集生成
对字符串的操作通常有字符删除、插入和替换3种,本文采用基于通配符和编辑距离的关键词模糊集生成方法。其中,通配符“*”表示对关键词任一位置上的操作,编辑距离D(w,w')表示由关键词w生成模糊关键词w'的最小字符操作次数,Sw,D表示对关键词w至多操作D次得到的关键词模糊集合。
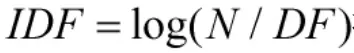

3.2.2 Huffman树形索引结构构建
方案以关键词频率为权值构建Huffman树形索引结构,并通过高效的Bloom-Filter实现模糊集的存储和检索。

2)TTP将这n个带权节点构造成一棵Huffman树;
3)如图4所示,根据关键词模糊集编辑距离的不同,将Sw,D分为相应的集合,如当D=3时,Sw,3分别为Sw_1、Sw_2、Sw_3。分别对集合进行加密,然后映射到布隆过滤器BFw_1、BFw_2、BFw_3中,并将过滤器作为索引树的叶子节点。

图4 索引树的叶子节点
4)如图5所示,TTP构建Huffman树形索引结构,并将其和加密后的密文文档上传至CSP。其中,1-3节点存储加密后的关键词,Bloom-Filter存储加密后的模糊关键词,两者均指向密文文档。

图5 Huffman树形索引结构
3.2.3 陷门生成及检索
3.2.4 密文文档排序
为给用户提供最符合需求的Top-k个结果,本文采用改进的TF-IDF规则给检索出的密文文档评分排序。文档排序不仅需要考虑关键词与指定文档的关联程度,更要考虑与模糊关键词的编辑距离,而且后者所占的权重比较大。因此,改进后的TF-IDF规则为:

4 方案分析
本节主要就方案的安全性、复杂度以及Bloom-Filter的误判率和假阳性进行分析,并通过实验测试进行性能对比分析。
4.1 安全性分析
方案安全性主要考虑用户隐私敏感信息、索引结构以及检索过程的安全性。
4.1.1 用户信息及索引安全在本文方案中,用户隐私敏感信息和关键词都是采用经典的密码学对称算法——AES算法来实现加解密,因此,在保证密钥长度合适的前提下,方案是安全可靠的。关键词模糊集在加密之后通过Bloom-Filter来存储,而过滤器通过一组独立同分布的Hash函数进行映射,在理论上具有不可逆性,因此,攻击者无法对其进行破译。

4.1.2 检索安全

4.2 复杂度分析

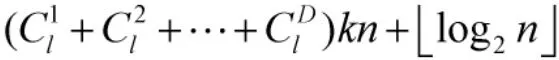
4.3 Bloom-Filter误判率及假阳性分析
在Bloom-Filter的数据存储及检索中,存在着误判和假阳性的情况。
4.3.1 Bloom-Filter误判率分析
由于Hash函数不是一一映射,可能存在多对一的关系,因此,当Bloom-Filter的某一位设置为1后,其值不再改变,再次判定时可能存在误判的情况。只有设置较长的Bloom-Filter向量才能减少这种碰撞,使误判率较低,但是相应的存储空间也会增大。
4.3.2 Bloom-Filter假阳性分析

4.4 实验测试及性能分析
为对本文方案进行性能分析,选取1 000篇IEEE数据库中计算机专业相关的英文论文作为测试文档,大小约为700 MB。选取50个高频且重复前缀较少的关键词,平均长度为7.5,最大编辑距离设定为3。实验平台配置在一台处理器为Intel(R)Core(TM)i5-2450M 2.50 GHz,RAM 4 GB的PC机上。本节主要在索引构建时间、索引规模、模糊检索效率方面与文献[13]方案进行性能对比分析。
4.4.1 索引构建时间

图6 索引构建时间
如图6所示,在本文方案和文献[13]方案中,索引构建时间都随着测试文档数量的增加呈线性增加;由于本文方案以关键词频率为权值构建索引树,而文献[13]方案基于TFIDF规则对关键词进行评分,并以此为权值构建索引树,因此,与文献[13]方案相比,本文方案的索引构建时间较少。
4.4.2索引规模
如下页图7所示,在本文的测试环境下,方案的索引规模为MB级,符合云存储环境的要求。由于本文方案与文献[13]方案都以关键词信息构建Huffman索引树,其索引规模相当。
4.4.3模糊检索效率
由于本文方案与文献[13]方案都是对索引树进行遍历查询来实现模糊检索,因此,基于关键词信息的索引树生成之后,测试文档数量对模糊检索效率的影响会比较小,而检索请求数量对效率会产生线性的影响;由于方案对检索请求的处理方式不同,文献[13]方案中增加了DS的检索关键词加密和TTP的解密过程,因此,本文方案的模糊检索效率提高了约10%。

图7 索引规模

图8 模糊检索效率
5 结论
随着军事数据获取方法的不断发展,数据总量日益增长,这对涉密信息的安全性和检索高效性提出了更高的要求[16]。本文通过分析传统的明文模糊检索技术,并结合密文检索的特点及要求,提出了一种安全且高效的密文模糊检索方案。方案以关键词的频率为权值构建Huffman树形密文关键词索引结构,并通过Bloom-Filter存储关键词的模糊集合,最后通过改进的TF-IDF规则对检索出的密文文档进行评分排序,以返回最符合用户需求的Top-k结果。本文方案主要满足单用户的需求,对于多用户需求的密文模糊检索,将是下一步的主要研究重点。
