基于决策者风险偏好大数据分析的大群体应急决策方法
2019-08-20徐选华杨玉珊陈晓红
徐选华, 杨玉珊, 陈晓红
(中南大学 商学院,湖南 长沙 410083)
0 引言
近年来,重大突发事件的不断发生,如天津港特大火灾爆炸事故、江西丰城电厂倒塌事故等,不仅给中国经济和人民生命财产带来了严重损失,更严峻的是对社会稳定带来了显著的影响。由于以往的应急决策往往只是由少数专家或政府官员进行决策,广大的社会公众无法分享应急决策过程中的相关信息,这导致政府与公众之间往往存在信息不对称问题。为了解决上述问题,许多学者提出可以采用“分众”方式让公众也参与到应急决策中[1,2],因此为了更好的降低重大突发事件对于社会的不良影响,决策群体应该是包括社会公众在内的大群体。
在当前应急决策研究中,由于突发事件往往是非预期事件,并且随着事件危机情况实时演变,因此为了能够在突发事件发生时进行快速响应,需要提前生成应急预案,并邀请公众参与应急预案的决策。但是,针对突发事件的决策结果一般只能由决策者凭借自己的主观判断和预测给出,而这种由决策者主观判断给出的应急决策一般要求决策者本人是风险中性者,因为风险喜好者和风险厌恶者的决策结果都容易受决策者的个人风险偏好影响。具体来说,文中的应急预案风险定义为预案的损失和收益的不确定性,即高风险代表高收益或高损失,低风险代表低收益或低损失。对于一系列应急决策预案,由于预案本身的风险往往无法统一,风险喜好者倾向于选择风险程度高的预案,而风险厌恶者相反,风险中性者对所有预案的选择不受预案风险的影响,因此更为理性。
传统的多目标群决策中一般都将决策者都视为理性决策者,因此大部分的传统群决策方法只考虑根据决策者给出的效用值进行计算并得出决策结果,如TOPSIS[3]、PROMETHEE[4]、ELECTRE[5]、UTA[6]、AHP[7]等方法。但是,对于有大群体参与的重大突发事件应急决策,由于决策成员在背景、个性特征、情绪表征、知识水平等方面的差别都将导致大群体中的决策者具有不同的风险偏好,且这种个体风险偏好差异往往很难被直接观测。事实上,对于有大量决策者参与的风险性应急决策,若不对参与决策的大群体进行风险偏好筛选,而是将所有的决策者都视为应急决策者,并采用传统的群决策方法,则可能导致决策方法失效且使得决策结果失去准确性。换言之,针对有大群体参与的应急决策,如果不对大群体的成员进行风险偏好筛选,大群体中存在的极端偏好者(风险喜好者或风险厌恶者)往往会给最终的决策结果带来风险,致使最终的决策结果并非最优决策。因此,针对有大群体参与的突发事件应急决策,应根据风险偏好对大群体成员进行筛选,选出风险中立者的决策成员。
目前,考虑决策者心理行为的风险性应急决策方法大部分需要定义决策者的心理理想参考点,如程铁军等[8]对应急决策者的心理有限理性、对损失的规避性和对突发事件相关因素敏感性进行定量化测度,设立了属性的正、负理想点作为参考点来确定应急风险的概率,利用概率结合各个预案的基本属性值对其进行排序;Wang等[9]将突发事件的实时损失水平与决策者心理参考点进行比较,根据二者的比较结果对应急预案进行实时调整,保障了预案实施的有效性;樊治平等[10]对决策者的综合心理感知水平进行定量化描述,通过计算各预案的前景效用值对其进行排序等。上述研究虽然从决策者心理行为方面对风险性应急决策进行了有效的研究,但还难以直接应用于风险性大群体应急决策中,因为应急决策过程中涉及到的群体成员数目过多且背景十分复杂,他们对于各预案之间的偏好不确定性很难由单一的理想点进行参考。
基于上述分析,首先对参与决策的大群体成员进行筛选,即通过对大群体中决策者风险偏好进行聚类分析,识别出大群体中成员的风险偏好,然后从中挑选属于风险中立者的决策成员聚集,在该聚集内的决策者被视为决策参与者,并参与到后续的应急决策中。
由于在应急决策过程中的决策者风险偏好是隐藏变量,无法直接测得,因此对于如何识别大群体中成员的风险偏好,本文主要考虑决策者对于具有不同风险程度的预案往往会有不同的效用,而这种效用就可以很好的代表该决策者的风险偏好。具体来说,首先由专家群体利用定性方法,如主观概率预测法[11]、德尔菲[12]和情景分析[13]等生成应急预案的各项风险属性并赋予权重;其次,针对上述应急预案,利用证据推理算法[14~16],根据各项风险属性[17]对应急预案进行风险评估,这样可得决策者对各预案的风险评估值;然后根据各预案的风险评估值,决策者进一步给出各预案的效用值;最后将预案的效用值与预案的风险评估值进行加权组合,得出决策者的个人风险偏好值,可以很好地反映决策者的风险偏好类型。一般来说,风险厌恶者对于风险值高的预案所给出的效用值会很低,而风险喜好者与之相反。
然而,由于参与应急决策的大群体成员数目往往比较庞大,其提供的偏好信息构成高维复杂大数据,因此想要利用风险偏好值对大群体进行初步筛选,须用到大数据分析方法,聚类算法就是一种对庞大数据进行预处理的方法[18,19]。考虑到传统采用的k-means聚类算法中的k值往往很难选取确定值,本文采用R语言中的聚类算法为层次聚类法[20~22],利用R语言提供的可视化工具包,可以根据聚类后生成的图表对大群体决策者进行风险偏好识别,识别出大群体中的风险中立者聚集后,将此聚集视为应急决策群体并再次聚类,以预案风险评估值为基础对该决策群体进行聚类分析,可得决策群体的组成结构,在此基础上对决策者权重和预案的最终效用值重新计算,可得预案的最终排序结果。
1 方法基础
1.1 证据理论
证据理论是由Dempster[23]在1967年首次提出并由Shafer[24]进行理论延伸和完善,故证据理论又称D-S理论,其优点是可以区分不知道和不确定的情况,证据理论的基本定义如下:
设辨识空间θ={Hn|n=1,…,s},其中Hn表示第n个评价等级,对于任意i,j∈{1,…,s}有Hi∩Hj=Ø,Ø表示空集。现定义一个概率分配函数mass,令其满足m(Ø)=0且ΣA⊆θm(A)=1。因为mass函数已经精确测量了分配给A的置信度,故可用来表示证据对A的支持强度。证据理论的关键在于利用Dempster的合成规则将不同来源的证据结合起来,该条规则假定各信息来源是独立的,即m=m1⊕m2⊕m3⊕…⊕mk。
1.2 证据推理算法中的信度结构
证据推理算法是一种在证据理论(D-S)的基础上,引入信度结构模型来解决决策者的认知不确定性问题[25],并采用合适的证据合成规则对多属性评价信息进行合成,最终对合成结果进行相应的效用计算,从而可对一个含有不确定性的多属性问题做出评估决策[26]。
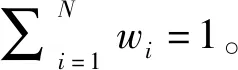
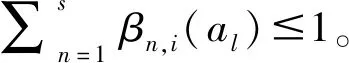
若评价模型中的全部基本属性的信度结构均已知,则可以通过证据推理算法合成其对于综合属性的置信度,本文主要采用模糊证据推理算法。
1.3 基于R语言的层次聚类算法
层次聚类算法主要是对给定的数据集进行层次分解,对于大数据汇总和可视化,用层次树状结构表示对象是十分有用的[27]。通过对具有不同风险偏好的决策群体进行层次划分,我们可以很容易地对大群体在层次结构中的数据进行特征化,这样的数据可以用来发现大群体成员的不同组成。层次聚类方法主要有两种,分别为凝聚和分裂,其中凝聚是指按照自底向上的策略把不同对象进行合并到同一层次中,分裂则与之相反,本文采用的层次聚类算法均是基于凝聚方法。
凝聚的层次聚类过程为:首先,将所有的数据点均看为一个簇,然后根据某种准则逐步进行合并,合并后的簇再次与其它簇按照相应准则进行合并,该过程不断重复,直到将所有对象最终合并成一个簇,使用树状图来表示层次聚类的过程和结果。
层次聚类的合并规则是基于两簇之间的距离来决定,采用四种簇距聚类度量方法,分别为最小距离、最大距离、均值距离和平均距离,包含此类算法的R语言包有stats、fastcluster和pvclust等,除此之外,由于有时候无法确定层次聚类的距离度量,还可以使用概率模型进行簇之间的合并,比如贝叶斯层次聚类算法,包含该类算法的R语言包有BHC。考虑到本文中决策者的风险偏好信息为高维数据且数据量大,而应急决策对于时间的敏感性较高,因此本文主要采用fastcluster包进行层次聚类,其基础是基于距离度量的快速层次聚类法。
2 方法原理
2.1 基于模糊证据推理算法的决策预案风险效用值
具有不同风险偏好的决策者在对含有不同风险的预案进行选择时,其偏好的预案往往会有所区别,而这种区别可代表该决策者对于风险的偏好态度,故在计算决策者风险偏好时,首先必须评估各个决策预案所具有的风险值。对预案进行风险评估的方法有许多种,在对预案进行风险评估时应结合该决策者的经验信息,这种经验信息一般是模糊的、不精确的以及不完全的,而模糊证据推理算法[28,29]中的信度结构可以很好地测量出这种经验信息,故本文采用模糊证据推理算法对预案的风险值进行评估,基本符号及定义如表1所示。

表1 模糊证据推理算法基本符号及定义
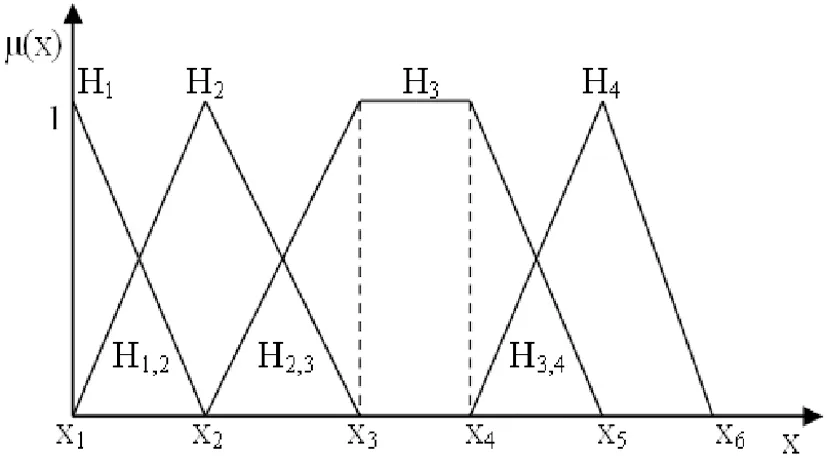
图1 模糊风险评价等级
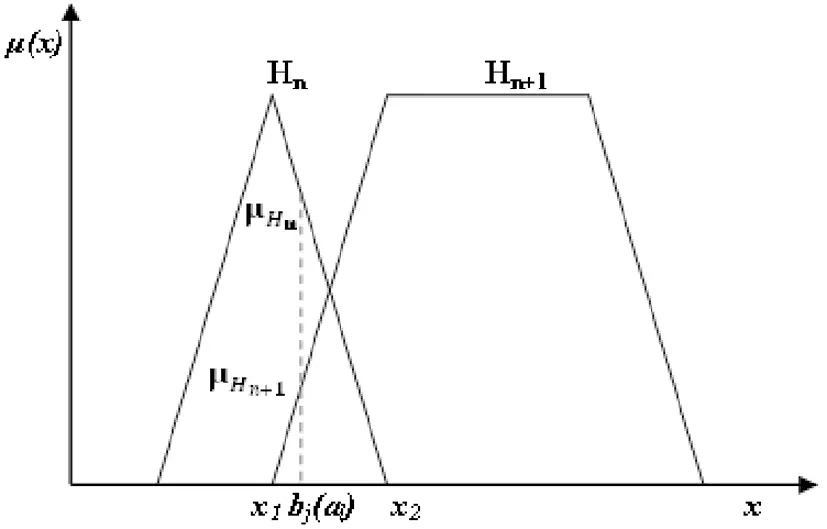
图2 风险值对应的等级隶属度
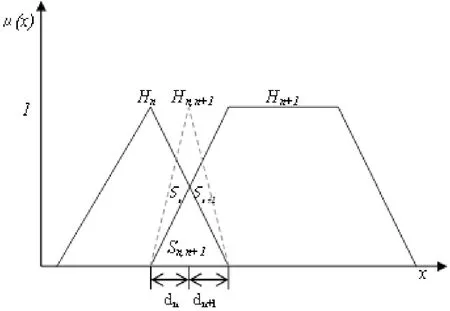
图3 模糊等级交集置信度分配
(1)
(2)
其中,γ(al)即为决策者ei对于预案al的最终风险效用值,L为风险效用值放大系数,u(Hn)为各模糊评价等级对应的效用值,给定评估等级效用值的取值区间为[0,1],故H1为最低效用值对应的等级,其效用值为0,其他效用值根据等级数目s将该区间均分。例如s=6,则H1~H6对应的效用值分别为{0,0.2,0.4,0.6,0.8,1}。
2.2 基于风险偏好大数据分析的大群体聚类
对于参与到应急决策中的大群体需要进行两次聚类。首先,根据决策者之间风险偏好值的差异,利用层次聚类法将大群体分为风险喜好者、风险中立者和风险厌恶者三个层次子群体。然后,选择风险中立者群体为应急决策群体,再利用决策者之间的风险效用值相似度进行聚类,得出应急决策群体的组成结构,具体计算过程如下。
(1)决策者的风险偏好值
由于决策者的风险偏好值是将决策者的预案风险效用值γ(al)和预案偏好值v(al)组合而得,因此为计算决策者的风险偏好值,决策者对全体预案给出自己的预案偏好值,该预案偏好区间给定为[0,10],将偏好值v(al)归一化后可得决策者心中对各预案的权重ρ(al),其计算公式如下:
(3)
故最终的决策者风险偏好值计算公式如下:
(4)
根据公式(4)可知,在大群体中,风险厌恶者的风险偏好值δ(ei)将处于较小水平,而风险喜好者的风险偏好值δ(ei)处于较高水平,因为风险厌恶者往往对具有较小风险评估值的预案给予较大权重,而风险喜好者与之相反。
得出决策者风险偏好值后,可利用R语言进行第一次聚类,根据聚类结果挑选出风险中立者并组成应急决策群体后,还需基于应急决策群体中决策者风险效用值之间的差异,通过决策者的风险效用值相似度进行第二次层次聚类。
(2)决策者的风险效用值相似度计算
因为通过证据推理算法得出的决策者风险效用值为高维数据,这将导致传统的距离度量法将不再适用于高维空间,但对于聚类分析来说,定义各数据对象之间的相似度距离公式至关重要,针对预案al,采用的决策者ex和ey相似度距离计算公式如下[30]:
d(γex(al),γey(al))
(5)
其中,d越大表明两个决策者之间越相似,且d的取值区间为(0,1]。该公式表明若两决策者对于某预案的风险效用值越接近,则这种相似距离在总距离公式中越占主导,即只要在某些预案上两名决策者给出的风险效用值差别较小,我们就可以认为该两名决策者具有一定的相似,相似的预案越多,两名决策者也越相似。
(3)大群体聚类算法
综上所述,大群体聚类算法的基本思路为先利用R语言软件对风险偏好值δ(ei)进行层次聚类,得出风险中立者的决策群体,再根据公式(5)对决策群体再次进行聚类得到应急决策群体成员的组成结构,大群体聚类的步骤主要如下。
(1)利用R语言中的fastcluster快速聚类包,对大群体风险偏好大数据进行层次聚类得到层次聚类结果。
(2)分析聚类结果并选择合适的聚集数k,再利用R语言软件对聚类结果进行层次划分,得出具体的聚集Ck和该聚集内所有成员的风险偏好值的均值δ(ei)。
(3)根据聚集均值对各聚集所处的风险偏好层次进行划分,均值最小的聚集判定为风险厌恶者聚集,均值最大的聚集判定为风险喜好者聚集,均值大小处于中间水平的聚集可被视为风险中性者聚集,至此,完成对大群体风险偏好者的筛选。
(4)对于风险中性者聚集,将其视为应急决策群体,因为决策者的风险评估值为高维数据,根据决策者预案风险效用值γ(al)并利用R语言软件对该群体进行层次聚类分析,利用公式(5)计算出各决策者的相似度距离信息并导入到R语言中,最终,生成应急决策群体的层次聚类树状图。
(5)再次根据生成的聚类结果进行分析并选择合适的聚集数k,最终可得该应急决策群体的决策者组成结构。
2.3 应急决策预案排序
(6)
其中,nei表示决策者ei所属于的聚集Ck的成员数目nk。
然后,根据决策者权重,还需计算应急预案的最终风险效用值,其计算公式如下:
(7)
考虑到应急决策的风险性,对于最终预案效用值的计算必须要考虑该预案的风险效用值,一般来说,最终选出的决策预案所具备的风险程度应该是越小越好,因此,将预案的最终风险效用值θ(al)与预案的偏好值v(al)进行组合,可得最终预案的效用值计算公式如下:
(8)
则最终的预案排序结果为V={v(a1),…,v(aP)},该结果综合考虑了决策者的预案偏好值和预案的风险效用值。综上所述,本方法的具体流程如图4所示。其中,大部分的计算和分析过程均由计算机完成,因此该算法可以实现对突发事件的快速响应。
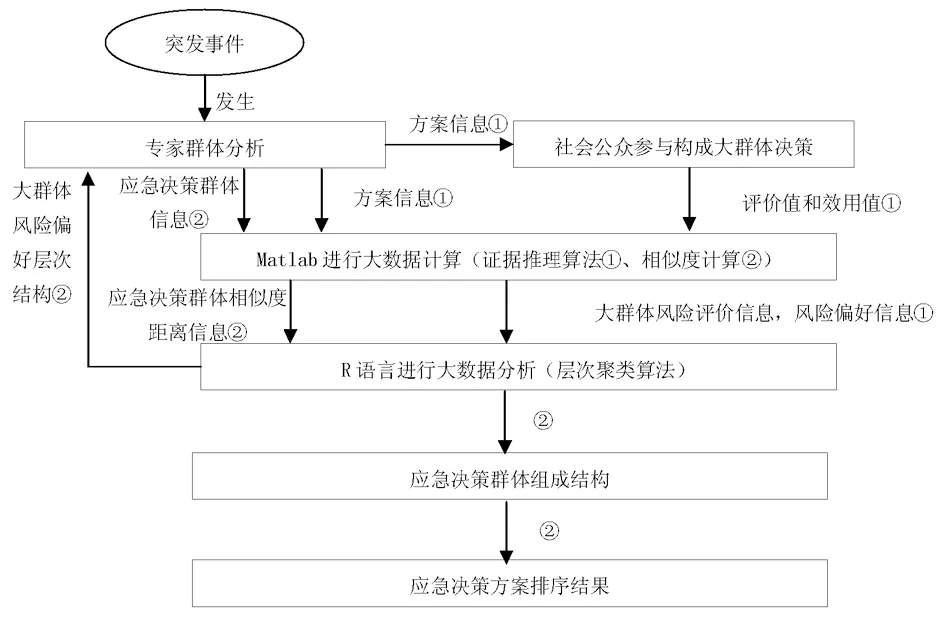
图4 基于决策者风险偏好大数据分析的大群体决策方法流程
3 算例分析
为提高应对突发事件的处置能力,某地应急指挥中心针对当地化工厂进行了一次突发事件应急演习,假设该化工厂突发爆炸,相关应急部门迅速响应,集合了10名决策专家对该应急事件进行初步定性分析,专家群体迅速给出了15个响应预案(P=15)和对各预案进行风险评估时应该考虑的5个风险属性(N=5),即花费成本,技术要求,动员人数,环境影响,实施时间。其权重分别为w={0.25,0.25,0.1,0.1,0.3},现考虑到社会公众对于突发事件往往具有极大的敏感性,因此政府部门也通过网络等途径邀请140名公众参与到预案风险评估中,故总大群体决策人数M=150。
大群体决策成员首先需要对各预案进行风险评估,具体的模糊风险评估等级如图5所示,即n=6,Hn={无风险,极低,较低,中等,较高,极高}。下面以决策者1为例,进行风险评估过程计算,决策者1给出的各预案风险评估值如表2所示。
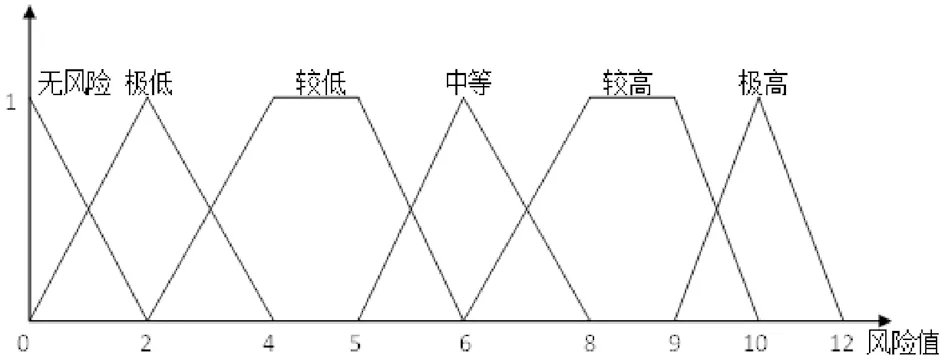
图5 模糊风险评估等级
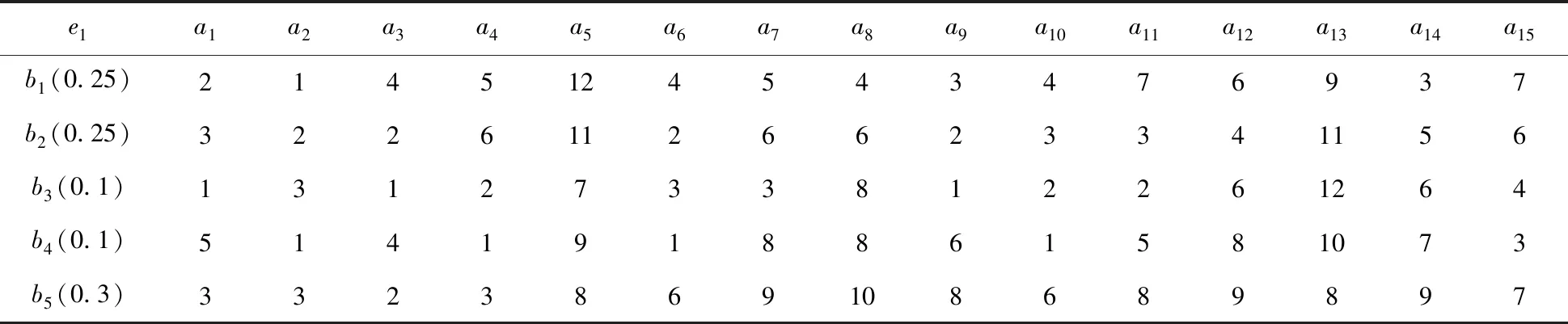
表2 决策者1的风险评估值
利用模糊证据推理算法[28,29],可得决策者1对各属性的信度结构如表3所示, 对各预案的信度结构如表4所示,最终的风险评估信度结构如表5所示。

表3 决策者1对各属性的风险评估信度结构
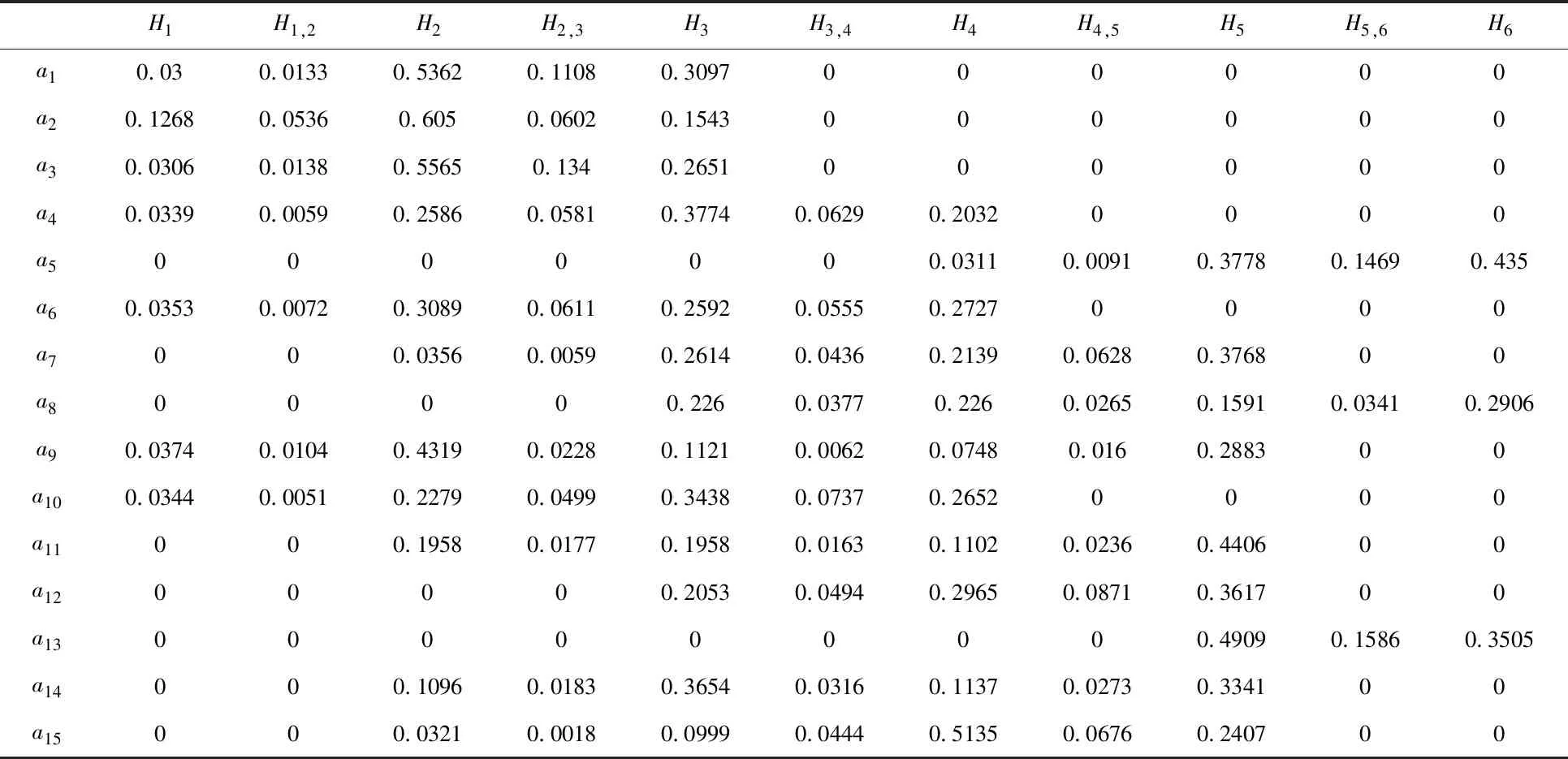
表4 决策者1对各预案的风险评估信度结构
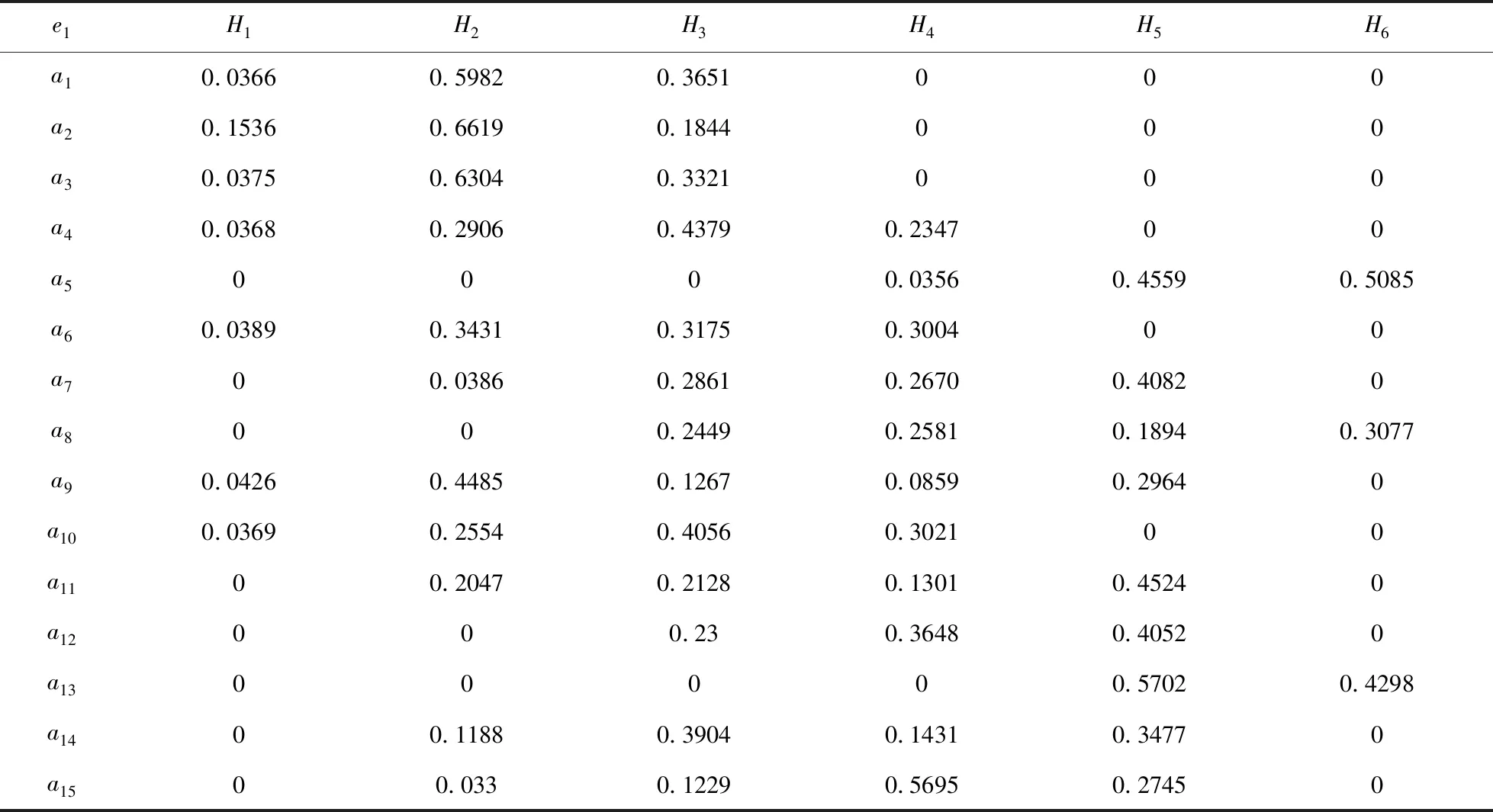
表5 决策者1的风险评估信度结构
现将决策者1的信度结构转换为风险效用值,因为s=6,故H1~H6对应的效用值分别为{0,0.2,0.4,0.6,0.8,1},利用公式(1)~(2),最终结果如表6所示。

表6 决策者1的风险效用值(L=100)
决策者1对各预案给出的偏好效用值为v={6,6,5,4,1,6,3,2,5,5,3,3,1,3,3},利用公式(3)可得最终决策者1 的风险偏好值为δ(e1)=5.543。
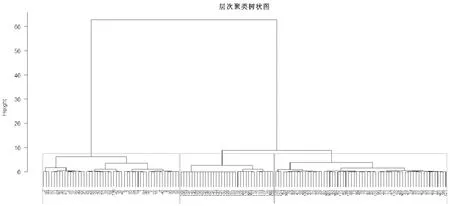
图6 大群体风险偏好值聚类树状图
至此,单个决策者的风险偏好即可求得。而针对大群体给出的风险评估数据,只需将其输入到Matlab软件,通过该软件计算即可求得大群体中所有决策者的风险值和效用值以及最终的风险偏好值,如表7所示。并将该计算结果全部导入到R语言程序中,利用R语言中的fastcluster包对大群体风险偏好进行聚类分析.其中,为了验证层次聚类能够有效的根据风险偏好值将大群体进行区分,模拟给出大群体偏好数据带有相应的风险偏好特征,具体为:决策者1至决策者50为风险厌恶者,决策者51至决策者100为风险喜好者,决策者101至决策者130偏好随机生成以及决策者131至决策者150为风险中性。具体聚类结果如图6所示。

表7 大群体风险偏好值
本文层次聚类选择的方法为最小方差法,此方法在合并两个簇时总是选择使离差平方和增加最小的两类进行合并,这样可以尽量保证聚集内部的一致性,从图6红线处可以看出,该大群体可主要分为3个聚集,利用R语言进行进一步数据分析可得具体的聚集结果如表8所示。

表8 大群体风险偏好聚类结果
根据表8可以发现,该大群体主要由3种不同风险偏好群体组成,各聚集组成人数并不一致,为了明确各聚集对应的风险偏好,需要计算每个聚集内部成员的风险偏好值均值,然后再按照均值大小进行排序,根据该顺序可以得出每个聚集对应的风险偏好类型。即偏好均值最大的聚集为风险喜好者群体,而偏好值最小的聚集为风险厌恶者群体,值得注意的是并不是将所有大群体风险偏好聚类后都只得到三个聚集,因此多个聚集(大于3)对应的偏好类型的划分还需要根据具体的偏好均值进行分析。
将聚集结果与最初给定的大群体偏好特征进行比较,可以发现有特定风险偏好的决策者均落入到了其对应的风险偏好聚集中,例如模拟给定1~50决策者均为风险厌恶者,会对风险值较高的预案给出较低的偏好效用值,而该部分决策者的风险偏好值再通过层次聚类后均落入了风险厌恶者聚集,具体结果如表9所示,通过该表可得知该层次聚类法适用于大群体风险偏好聚类。
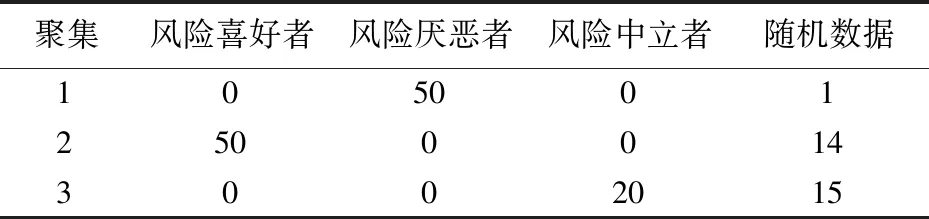
表9 大群体偏好数据特征聚集结果
本文认为因为应急决策具有极大的风险性,对应急事件进行决策的群体最好是保持风险中立态度的决策者,这样的决策者做出的决策才较为理性,故该大群体通过风险偏好聚类后只挑选聚集3的成员作为应急决策成员,其成员为:104,106,108,109,112~118,120,127 ~129,131~150。因为决策者给出的预案风险值往往跟决策者的风险知识水平相关,所以可以根据聚集3内决策者给出的各预案风险值再次进行聚类,即根据各决策者风险知识水平的差异,利用公式(5)计算决策者之间的相似度距离,最终可得聚类结果如图7所示。
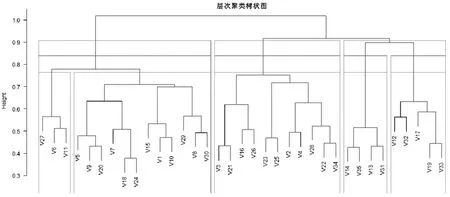
图7 风险中立决策者风险知识水平聚集结果
由图7可获得该应急决策群体中的不同决策者聚集,其中V6代表为该聚集中的第6人(即决策者113),由图中红线可以得出根据不同的高度水平,该群体聚集数可以分别取5,4,3,本文认为聚类数为4更为合理,因为此时的各聚集树节点所处高度最为合理,结果如表10所示。

表10 第二次聚类结果
至此,我们已经从大群体决策者中识别出了合适的应急决策者,并对这些应急决策者进行了再次聚类,从而得到应急决策群体的组成结构。利用公式(6)~(8)进行计算可得最终的预案排序结果为V={0.0603,0.0625,0.0624,0.0588, 0.0697,0.0557,0.0578,0.0672,0.0592,0.0549,0.0633,0.0747,0.0652,0.0580,0.0627},故可得最优预案为第12预案,该预案不仅对于绝大多数决策者具有较大的效用值,即大部分决策者都看好该预案,且自身所具有的风险值也较低,即该预案实施起来所面临的风险并不大。因为该预案为最优预案。
5 结论
本文把社会公众引入到大群体应急决策中,先利用证据推理算法得出公众对各预案的风险效用值,并进而结合预案偏好值得出大群体决策者的风险偏好值,再利用相关大数据分析技术,根据决策者的风险偏好值进行聚类分析,得出应急决策的决策群体,最后再根据应急决策群体对应急预案的效用值,得出最优的应急方案。通过本文对决策者风险偏好进行大数据分析可以得出以下结论:
(1)通过许多文献分析可以得知,以前的应急决策往往都是只依靠少数专家进行决策,这些专家群体因为具有丰富的决策经验,因此一般情况下不会受自身的风险偏好影响,可以被视为理性决策者。但是然而随着社会经济的发展,突发事件给社会带来的危害也在逐渐增大,社会公众对于突发事件的敏感性也开始提高,他们参与应急决策的积极性也在逐步上升,且网络技术的发展也为社会公众参与到应急决策中来提供了方便的渠道。可是,与专家群体相比,社会公众构成的大群体决策由于其组成过于复杂,往往很难判断哪些决策者是真实可靠的。大数据分析技术的快速发展为判断大群体决策者是否可靠提供了很好的技术支撑,类似于大数据分析中的数据预处理,应急决策中也可以采用该分析方法对大群体决策者进行可靠性分析,而本文正是基于此思路,在数据预处理中运用聚类技术,以决策者的风险偏好作为判断决策者是否可靠的标准,对大群体决策者进行了初步筛选,从中得出了应急决策群体的成员和其内部组成结构,并最终得出方案排序结果,从中选出最优方案。
(2)通过上述算例分析可以发现本文所用的聚类算法可以很好的识别出大群体中具有不同风险偏好的成员,这种对风险偏好的识别保证了应急决策者内部风险偏好的一致性,从而让接下来所使用的群决策方法可以建立在理性决策者的基础上,并让应急决策结果的可信度增加,而最终计算得出的最优预案也综合考虑了方案本身所具有的风险程度和决策者对该方案的偏好程度,从而使得该预案更为贴近最佳方案。
当然,在本文中还存在着许多值得探讨的问题,如决策者风险偏好动态变化等,因此在未来的研究中将在这方面进行更深入的研究。
