GPU并行计算在FD-OCT成像中加速插值计算的应用
2019-08-05秦晓萌岑颖珊刘碧旺韩定安王茗祎周月霞
易 俊,秦晓萌,岑颖珊,刘碧旺,韩定安,王茗祎,周月霞
(佛山科学技术学院 物理与光电工程学院,广东 佛山 528200)
0 引言

图1 FD-OCT系统组成Fig.1 FD-OCT system composition
频域光学相干层析成像技术(Frequency Doman Optical Coherence Tomography, FD-OCT)是一种高轴向分辨率的新兴无创三维光学成像技术[1]。自提出至今已经得到了迅速发展,能实现对生物组织的功能成像,目前在医学领域有着广泛的应用。近年来,随着FD-OCT 技术的发展及超高速CMOS 线阵相机的更新,FD-OCT 系统的采集速度基本能满足实时成像的要求。在FD-OCT 中,成像计算的关键步骤是插值计算。由于图像重建过程中需要对每一线(即线阵相机的每一次曝光采集到的数据)数据都要进行插值计算并进行正向傅里叶变换。一帧完整的二维图像至少由500 条线组成,数据吞吐量较大,从而加重了重建图像中数据处理环节的计算负担,在Matlab 语言下,基于CPU 算法的程序一幅由500 线组成的FD-OCT 图像实现3 次样品插值需要至少60ms 以上。其中插值计算占据了成像三之二的计算时间。因此,提高插值的计算速度,是提高FDOCT 成像速度的关键核心问题。
为了解决FD-OCT 系统在处理数据方面遇到的问题,相关研究人员提出了许多的解决方法:利用多核CPU 对FD-OCT 成像系统的数据进行并行处理;也有相关研究人员在FD-OCT 系统中增加硬件模块来加快数据处理速度,这样使得系统的成本大大地增加了[2]。随着GPU 技术的飞速发展,它不仅在传统的图像处理方面发挥作用,也早已被用于磁共振成像,系统用于数据处理的加速。Watanabe 和Itagaki 将GPU 应用于FD-OCT 系统,利用其对FD-OCT 数据做了一维正向傅里叶变换,达到了每秒8 帧[3]。本文研究将经济实惠的商用GPU 应用到FD-OCT 系统中,大幅度地加快了系统的数据处理速度。在每线像素点为1024,每帧1000 线的实验条件下,成像重建速度达到52 帧每秒,实现了FD-OCT 的实时成像。
1 系统组成和工作原理
1.1 系统的组成
本文用到的FD-OCT 系统组成如图1 所示,主要包括超辐射发光激光二极管(λ0=1310nm,Δλ=400nm),样品臂、参考臂、光谱仪和计算机(包含数据采集卡、图像采集卡和GPU)5 个部分。其中数据采集卡为美国国家仪器公司的PCIe-6711,图像采集卡采用的是来自美国国家仪器公司PCIe-1429;GPU 采用了英伟达公司的Ge Force GTX1060 显卡(NVIDA CUDA 核心数1280 个,3GB 显存)。
1.2 系统的工作原理
FD-OCT 系统的主要构成是麦克尔逊干涉仪和光谱仪。宽带光源的光被光纤耦合器一分为二,其中一束射向样品臂,另一束射向参考臂;样品臂上的后向散射光和参考臂的反射光在耦合器处相遇,产生相干光,这一部分即为麦克尔逊干涉仪。干涉光通过光谱仪分光,而后该干涉光被CCD 相机接收。根据单色光干涉理论可知,分光镜处的光强可以表示为:
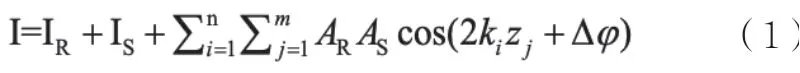
其中,IR和IS是参考光和样品光的直流信号,AR为参考光的振幅,AS为样品光的振幅,zj为等光程面的探测深度,Δφ 为相位差。当干涉光经光栅分光后,CCD 相机的每个线阵单元接收到的强度信号可以表示为:
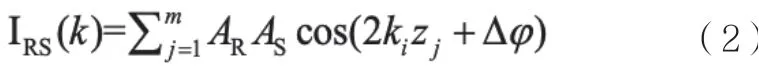
由于光栅方程:

m 为衍射级次,λ 为衍射波长,φ 为入射角,θ 为衍射角以及d 为光栅常数。根据该光栅方程对入射光谱进行分光[4]。干涉光通过光栅分为不同波长的光,之后衍射到线阵CCD 上。因此,相机记录到的信号是一个以波长λ 为参变量的光强信号,根据干涉公式(2),实际需要获得的信号是以波矢k 为参变量的信号。由于将波长信号插值到波矢信号是FD-OCT 成像的关键步骤,需要对相机采集到的光谱信号进行插值,获得真正的干涉信号。占据了成像的三分之二的计算时间,因而提高插值的计算速度是成像的关键核心问题。本文应用了基于GPU 的CUDA 语言编写了一套三次样条插值算法,加速了整个插值计算过程。
1.3 三次样条插值
三次样条插值(Cubic Spline Interpolation),是一种应用广泛的插值函数 。三次样条插值函数是由多段的低次多项式组成,并且它的曲线非常光滑;得到插值点处的函数值及提供(n-1)个边界节点处的导数信息就的三次样条插值函数[5]。
1.3.1 三次样条插值函数的定义[6-8]

图2 三次样条插值求解流程图Fig.2 Three-spline interpolation solution flowchart
假设有以下两个节点x:a=x0<x1<...<xn=b,y:y0y1...yn。样条曲线是一个分段定义的函数。在n+1 个数据点中,共有n 个区间,三次样条插值函数满足以下条件:1)在每个区间[xi,xi+1]上,S(x)都是三次多项式;2)满足S(xi)=yi;3)S(x)的导数S'(x)及二阶导数S"(x)在区间[a,b]上都是连续的,即S(x)是光滑的曲线[9]。所以n 个三次多项式分段可以写作:

其中ai,bi,ci,di代表曲线拟合的4 个系数。
1.3.2 三次样条函数的求解
求解三次样条插值函数是利用n+1 个数据节(x0,y0),(x1,y1),(x2,y2),…,(xn,yn)先计算步hi=xi+1-xi,令mi=Si"(xi),由插值条件Si(xi+1)=yi+1以及Si(x)在样点xi处二阶导数的条件,增加自然边界条件:

得到如下矩阵方程:

解矩阵方程(7),求出二次微分值mi[10],从而求得系数ai,bi,ci,di并将系数代入获得拟合曲线,获得待求插值点的数值,最终完成三次样条插值函数求解。
2 基于GPU并行计算的数据处理模块的实现
2.1 CUDA:并行计算架构
CUDA(Compute Unified Device Architecture)是一种并行计算架构[11]。CUDA 将C 语言作为编程语言,并提供大量的计算指令,使得效率更高的密集数据计算解决方案能够在GPU 突出计算能力的基础上建立起来[12]。
CUDA 构架分为两部分:Host 和Device。通常而言,Host 指的是主机,Device 指的是GPU[13]。在CUDA 构架中,CPU 作为主机,负责执行程序的串行部分;GPU 作为协助处理器主要负责对密集且大量的数据进行并行计算[14]。用CUDA 编写好的程序叫做核(kernel)函数。CUDA 允许程序员定义称为核的C 语言函数或使用CUDA 指令,在调用此类函数时,它将由N 个不同的CUDA 线程并行执行N 次,执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx 变量在内核中访问此ID[15]。在 CUDA 程序中,主程序在调用GPU 内核之前,务必对核执行配置操作,以此确定线程块数和每个线程块中的线程数以及共享内存大小。
2.2 数据处理流程
在FD-OCT 系统处理过程中,首先,CCD 相机采集到的原始数据经过图像采集卡传输到CPU 内存上,然后再传输到GPU 显存上面进行数据处理;其中数据处理的主要过程包括对采集数据进行去背景、色散补偿、波长空间(λ空间)到波数空间(k 空间)的转换、插值、FFT 变换、取模和取对数。最后,把处理好的数据再传输到CPU 内存上并由计算机进行显示。由于插值过程计算复杂且系统采集到的图像数据每列是相互独立的,处理的时候也是分开一列一列数据进行处理的,所以可以基于GPU 强大的并行计算能力对数据进行插值计算,并把CPU 计算插值部分代码改写成在GPU 上执行的kemel 函数,从而加快数据处理的速度,使成像时间减少。
2.3 程序设计
首先,定义整个数据处理过程中需要的变量,并给他们分配对应大小的内存空间;其中Host 端用malloc 函数开空间,Device 端用CUDA 内部指令cudaMalloc 开空间;利用cudaMemcpy 将原始数据以及运算所需中间变量从主机内存复制到设备内存。根据分配的线程空间借用对应ID 进行数据的调用和处理,其中包括调整数据类型以及去除背景噪声。其次,由于CUDA 编程没有自带插值的库函数,本文编写了一套三次样条插值算法并用CUDA 语言编写成在GPU 上运行的kernel 函数。
图2 为三次样条插值函数求解的流程图,首先计算出步长,然后通过计算得到三对角矩阵,利用CUDA 自带的库函数求解三对角矩阵[16];最后用求解矩阵得到的结果去计算多项式拟合系数,并将系数代入得到拟合曲线,获得待求插值点的数值,完成三次样条插值求解。
按照三次样条插值的原理以及流程图,以下为本文编
写的基于GPU 三次样条插值具体程序代码:
//计算步长
__global__ void Kernel001(float *K, float *ks, int *index,float *h, float *dx, float *x31, float *xn)
{
h[idx] = K[idx] - ks[index[idx]];
}
//得到三对角矩阵
__global__ void Kernel002(float *dx, float *x31, float *xn,float *A, float *B, float *C)
{
int idx = threadIdx.x + blockDim.x * blockIdx.x;
C[idx] = x31[0]; B[idx] = dx[1]; A[idx] = 0;
C[idx] = dx[idx - 1]; B[idx] = 2 * (dx[idx] + dx[idx - 1]);
A[idx] = dx[idx];
C[idx] = 0; B[idx] = dx[idx - 2];
A[idx] = xn[0];
}
//三对角矩阵求解
cusparseCreate(&cusparseH);
cusparseSgtsvInterleavedBatch(cusparseH,0, pixel, d_dl0,d_d0, d_du0, d_b, line*pic, d_work);
以上两条函数其专门用于求解三对角矩阵源于CUDA自带的库函数CUSPARSE LIBRARY。第一条用于创建句柄,第二条负责运算求解矩阵。调用GPU 自带函数求解矩阵,极大地提高了数据处理的速度以及精确度。
//用求解矩阵结果计算多项式拟合系数
_global__ void Kernel0061(float *divdif, float *s, float *dx,float *Y, float *dd, float *cc, float *bb, float *aa)
{
int idx = threadIdx.x + blockDim.x * blockIdx.x;
int idy = threadIdx.y + blockDim.y * blockIdx.y;
int idz = threadIdx.z + blockDim.z * blockIdx.z;
if (idy < line && idx < pixel - 1 && idz < pic)
{ aa[idx + (pixel - 1)*idy + idz*s_frame] = Y[idx +pixel*idy + idz*frame];
bb[idx + (pixel - 1)*idy + idz*s_frame] = s[idx + pixel*idy+ idz*frame];
cc[idx + (pixel - 1)*idy + idz*s_frame] = 2 * (divdif[idx +(pixel - 1)*idy + idz*s_frame] - s[idx + pixel*idy + idz*frame]) /dx[idx] - (s[idx + 1 + pix-el*idy + idz*frame] - divdif[idx + (pixel- 1)*idy + idz*s_frame]) / dx[idx];
dd[idx + (pixel - 1)*idy + idz*s_frame] = ((s[idx + 1 +pixel*idy + idz*frame] - divdif[idx + (pixel - 1)*idy + idz*s_frame]) / dx[idx] - (divdif[idx + (pixel - 1)*idy + idz*s_frame] -s[idx + pixel*idy + idz*frame]) / dx[idx]) / dx[idx];
}
}
//系数代入得到拟合曲线,获得待求插值点数值
__global__ void Kernel007(float *h, int *index, float *Y,float *dd, float *cc, float *bb, float *aa)
{ int idx = threadIdx.x + blockDim.x * block-Idx.x;
int idy = threadIdx.y + blockDim.y * blockIdx.y;
int idz = threadIdx.z + blockDim.z * blockIdx.z;
if (idx < pixel && idy < line && idz < pic) {
Y[idx + pixel*idy + idz*frame] = h[idx] * (h[idx] * (h[idx] *dd[index[idx] + idy*(pixel - 1) + idz*s_frame] + cc[index[idx] +idy*(pixel - 1) + idz*s_frame]) + bb[index[idx] + idy*(pixel - 1)+ idz*s_frame]) + aa[index[idx] + idy*(pixel - 1) + idz*s_frame];
}
}
然后,应用CUDA 自带的cuFFT 库函数对插值后的数据做快速傅里叶变化,并改写成kernel 函数;同时添加对快速傅里叶变换后数据进行取模和取对数处理的核函数,实现FD-OCT 系统数据在GPU 完成所有数据处理环节。最后,将最终处理完的数据再次用cudaMemcpy 从显存复制到内存并在计算机上显示和释放所有显存以及内存空间。
3 程序验证以及实验结果分析
本系统采用Microsoft Visual Studio2015 中集成CUDA Toolkit 64 bit 9.2 和Nvidia Driver for Win-dows7 64bit 为开发环境,分别用基于CPU 模式的Matlab 语言和基于GPU 模式的CUDA 语言对采集到的人体表皮图像数据进行数据处理得到图像。Matlab 语言是基于CPU 数据处理单元的串行数据处理方法,而CUDA 语言则用到了GPU 突出的并行计算能力来实现成像。
3.1 判断依据
为了比较两种模式成像速度的快慢,可以通过比较两种模式下处理数据和显示每帧图总用时。因此,对于两种模式,在设计程序时添加了帧率计算及显示和记录,以及通过CUDA 的计时函数和Matlab 的计时函数可得出数据处理每个环节所用时间以及总用时,这方便比较两者的成像速度。
3.2 实验结果及分析
本文用B 扫描模式对人体表皮进行了成像实验(采集到的每帧图像数据大小为1000 线×1024 像素/线×12 字节/像素),实验成像效果如图3 所示,图(a)为基于CPU模式的Matlab 语言B 扫描成像截面图,图(b)为基于GPU模式的CUDA 语言B 扫描成像截面图,图(c)对应于(a)图中白色虚线的强度图,图(d)对应于(b)图中白色虚线的强度图。由图3 可知,基于CPU 模式的Matlab 语言和基于GPU 模式的CUDA 语言处理数据得到的图像质量无明显差异,且经过强度图对比,数据相同。

图3 人体表皮B扫描实验图(1000Lines)Fig.3 Human epidermis B scan experiment (1000Lines)

图4 不同大小图片在基于CPU模式的Matlab语言和基于GPU模式的CUDA语言的成像时间对比Fig.4 Comparison of image times for pictures of different sizes in the CPU-based matlab language and the GPU-based CUDA language
除此之外,本文还改变了每帧图像的线数,得到两种模式的成像时间如图4 所示。从图中可以得出,在不同线数每帧图的情况下,基于GPU 模式的CUDA 语言的成像时间都要比基于CPU 模式的Matlab 要短15 倍左右。特别是随着数据量的变大,应用GPU 进行插值计算以及成像的速度更快,用时更短;而基于CPU 的Matlab 语言则随着数据量的增加变得更慢,进一步说明了把GPU 应用到FD-OCT系统中的插值计算以及并行数据处理极大地提高了FDOCT 成像的速度。
4 结论
本文在没有改变任何硬件的FD-OCT 系统的基础上,将基于GPU 的CUDA 语言应用到系统的数据处理过程中,特别是针对三次样条插值巨大且重复的数据计算,很好地利用了GPU 突出的并行计算能力,将插值计算以及需要并行计算的数据处理过程用CUDA 进行改写,使得整个的成像时间缩短了一个数量级。在国内已有的相关研究中,刘巧艳,刘锐,朱珊珊等人也把GPU 应用到OCT 成像系统的数据处理中,取得了不错的成绩。本文着重是应用GPU 对整个数据处理过程的插值计算部分进行加速和优化以达到整个数据处理过程加速,速度比单一的基于CPU 的Matlab语言处理速度加快了将近15 倍。所以说明GPU 加速模式很好地解决了传统基于CPU 的Matlab 语言插值计算慢以及不能实时成像的问题,实现了FD-OCT 系统实时的2D 成像。但是,整个程序的图像显示环节没有实现并行化处理,整个成像速度还有提升的空间,需要进一步探索,更大程度地发挥GPU 的突出并行计算能力。本文研究为FD-OCT系统三维实时成像打下了坚实的基础。
