基于深度强化学习的城市交通信号控制算法
2019-08-01舒凌洲吴佳王晨
舒凌洲 吴佳 王晨


摘 要:针对城市交通信号控制中如何有效利用相关信息优化交通控制并保证控制算法的适应性和鲁棒性的问题,提出一种基于深度强化学习的交通信号控制算法,利用深度学习网络构造一个智能体来控制整个区域交通。首先通过连续感知交通环境的状态来选择当前状态下可能的最优控制策略,环境的状态由位置矩阵和速度矩阵抽象表示,矩阵表示法有效地抽象出环境中的主要信息并减少了冗余信息;然后智能体以在有限时间内最大化车辆通行全局速度为目标,根据所选策略对交通环境的影响,利用强化学习算法不断修正其内部参数;最后,通过多次迭代,智能体学会如何有效地控制交通。在微观交通仿真软件Vissim中进行的实验表明,对比其他基于深度强化学习的算法,所提算法在全局平均速度、平均等待队长以及算法稳定性方面展现出更好的结果。其中,与基线相比,平均速度提高9%,平均等待队长降低约13.4%。实验结果证明该方法能够适应动态变化的复杂的交通环境。
关键词:深度学习;卷积神经网络;强化学习;交通信号控制
中图分类号:TP311.1
文献标志码:A
Abstract: To meet the requirements for adaptivity, and robustness of the algorithm to optimize urban traffic signal control, a traffic signal control algorithm based on Deep Reinforcement Learning (DRL) was proposed to control the whole regional traffic with a control Agent contructed by a deep learning network. Firstly, the Agent predicted the best possible traffic control strategy for the current state by observing continously the state of the traffic environment with an abstract representation of a location matrix and a speed matrix, because the matrix representation method can effectively abstract vital information and reduce redundant information about the traffic environment. Then, based on the impact of the strategy selected on the traffic environment, a reinforcement learning algorithm was employed to correct the intrinsic parameters of the Agent constantly in order to maximize the global speed in a period of time. Finally, after several iterations, the Agent learned how to effectively control the traffic.The experiments in the traffic simulation software Vissim show that compared with other algorithms based on DRL, the proposed algorithm is superior in average global speed, average queue length and stability; the average global speed increases 9% and the average queue length decreases 13.4% compared to the baseline. The experimental results verify that the proposed algorithm can adapt to complex and dynamically changing traffic environment.
英文關键词Key words: deep learning; Convolutional Neural Network (CNN); reinforcement learning; traffic signal control
0 引言
城市交通信号控制一直以来是一个具有挑战性的研究课题。由于交通系统的复杂性和动态性,随着控制范围的扩大,交通状态信息数据量急剧增加,控制的复杂度呈指数级增长[1]。除此以外,交通信号控制面临着鲁棒性、适应性等问题同样增加了控制的难度。对此,部分研究者提出了分布式控制方案,基于多智能体的方法被广泛用于解决城市交通分布式控制问题[2-6],如文献[4]利用了遗传算法和强化学习算法来训练多智能体,文献[6]采用基于模糊控制的多智能体算法。然而,由于以下原因,交通网络信号控制问题依旧没有得到有效地解决:1)多智能体之间的协作通信基于预定义的规则,导致智能体无法快速适应不断变化的交通状况, 因此,智能体性能缺乏稳定性; 2)随着控制区域范围增大,交通状态信息和交通控制方式复杂度陡增,传统的交通控制方式很难发现交通数据中隐藏的模式,因此,优化控制目标难度增加。
为了解决上述问题,本文提出一种基于深度强化学习的城市交通信号控制算法。强化学习[7]是一类重要的机器学习技术,它通过与环境的交互来学习最优的控制决策。交通信号控制领域很早开始运用强化学习方法来解决交通控制问题。智能体以提升车辆平均速度、最小化车辆平均通行时间、减少车辆平均等待队长为目标,通过观察当前交通状态,选择最优的交通控制策略[4,8-11]。这些方法采用人工提取的特征表示交通状态,极大地降低了交通状态表示的复杂度。例如,文献[9]选择每个车道等待车辆队长和信号灯时间作为交通信息状态,通过将数据离散化为不同级别,达到压缩数据的目的。该方法虽然降低了信息的复杂度,但丢失了交通状态潜在的重要信息。因此,单纯基于强化学习的交通控制策略只能应对低维度数据,一旦交通数据量和复杂度增加,该方法无法满足城市区域交通信号的精确控制需求。
深度學习可以很好地解决高维度数据抽象表征问题。受到人脑工作模式的启发, 深度学习将底层特征组合形成更加抽象的高层特征[12]。通过与强化学习结合, 即深度强化学习 (Deep Reinforcement Learning, DRL), DRL能够发掘交通状态信息中隐藏模式,直接从高维数据中学习到有效的控制策略。近年来部分研究者开始在交通信号控制领域采用深度强化学习技术[13-15],但大多数研究仅考虑单个交叉路口的交通控制[13-14]。文献[15]虽能够实现小型交通网络的控制,但文中仍是单个智能体控制单个路口交通,然后利用传统多智能体协调机制来控制交通网络。由于 DRL 算法的训练非常耗时,因此每个交叉路口由单个DRL智能体控制的交通网络的训练将消耗较长的时间;另外,作者在文中指出了其智能体在训练过程中稳定性较差, 因此,对于大型路网来说, 此方法可行性较差。
本文旨在利用深度强化学习的优势高效地控制城市交通。智能体通过不断地与交通环境进行交互以最大限度提高交通通行效率。在此框架下智能体无需预知交通系统控制的内在规则,而是通过不断探索新的策略,根据该策略对环境的影响来学习到最优的控制策略。本文方法主要优点在于:
1)单个智能体对交通路网进行全局控制。
2)交通网络的状态由位置矩阵和速度矩阵联合表示,这样能有效抽象出交通路网中的主要信息。与文献[13-14]相比,矩阵表示法压缩了数据的维度并且缩短了计算时间。
3)通过对智能体超参数的调整,信号控制的稳定性显著提高,训练时间显著减少。
4)所有仿真实验均在著名的微观交通仿真软件Vissim上运行,实验结果可信度高。
3.3 性能提升
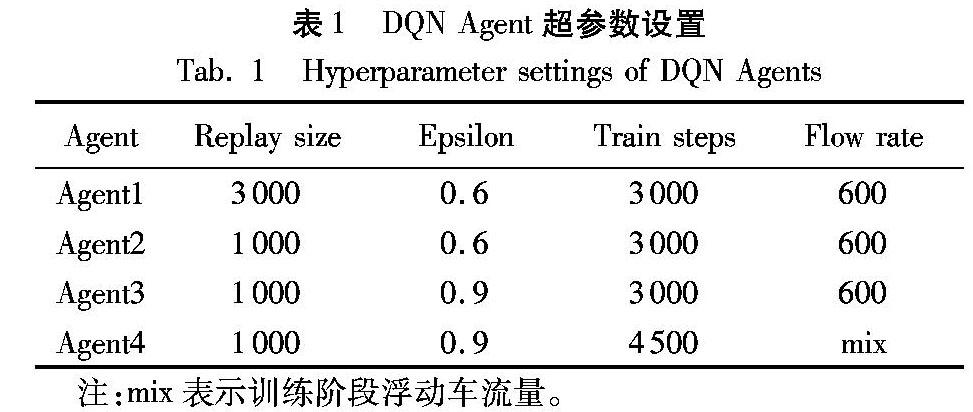
在本节中将在Agent4的基础上通过改变车流量范围进一步提升Agent性能。经过多次实验发现,Agent5在训练时缩小车流量范围至550~650veh/h,其在测试阶段性能优于Agent4。实验结果表明(表2),Agent5平均速度增长约2%。究其原因在于更大的车流量范围增加了交通状态的复杂度,使得Agent训练难度增加,最终导致了Agent性能不稳定,增加神经网络的深度和每层节点数可解决该问题。在原有测试之上本文为Agent5增加了低车流量场景(300veh/h)测试任务(如图4所示),实验表明在高流量环境中训练仍能够在低流量环境中取得良好表现。
4 结语
随着城市交通状况的复杂性增长,交通状态中的隐藏模式难以发现。深度学习提供了从高维数据中挖掘隐藏模式的有效方法。通过与强化学习算法结合,为城市交通控制提供了解决方案。本文提出了一种基于深度强化学习的交通网络交通控制方法,该方法通过与交通环境交互,连续地感知交通环境的状态并挖掘其中隐藏模式,进而找到当前状态下可能的最优控制策略。实验结果表明,该方法能有效控制城市交通,提升交通通行效率,但是此方法依然存在一定的局限性,如随着控制范围的扩大、交叉口数量的增加带来动作空间的陡增;由于深度学习与强化学习结合带来的训练困难等问题。在今后研究中,将考虑从以下方面进一步优化算法:
1)利用文献[19]提出的Wolpertinger 框架解决随着控制范围扩大出现的动作空间指数增长的问题;
2)随着城市交通状况的复杂性增加,训练时间将大幅增加。为了减少训练时间,提升训练效果,拟考虑更先进的深度强化学习技术,如Asynchronous Advantage ActorCritic A3C[20]或DuelingDQN算法[21]。
参考文献 (References)
[1] 李颖宏,王力,尹怡欣. 区域交通信号系统节点分析及优化策略研究[J]. 计算机应用,2010, 30(4): 1107-1109. (LI Y H, WANG L, YIN Y X. Node analysis and optimization strategy for regional traffic network system [J]. Journal of Computer Applications, 2010, 30(4): 1107-1109.)
[2] CHIU S, CHAND S. Selforganizing traffic control via fuzzy logic[C]// Proceedings of the 32nd IEEE Conference on Decision and Control. Piscataway, NJ: IEEE, 1994:1897-1902.
[3] NAKAMITI G, GOMIDE F. Fuzzy sets in distributed traffic control[C]// Proceedings of IEEE 5th International Fuzzy Systems. Piscataway, NJ: IEEE, 1996: 1617-1623.
[4] MIKAMI S, KAKAZU Y. Genetic reinforcement learning for cooperative traffic signal control[C]// Proceedings of the 1st IEEE Conference on Evolutionary Computation. Piscataway, NJ: IEEE, 1994: 223-228.
[5] MANIKONDA V, LEVY R, SATAPATHY G, et al. Autonomous Agents for traffic simulation and control[J]. Transportation Research Record Journal of the Transportation Research Board, 2001, 1774(1):1-10.
[6] LEE J H, LEEKWANG H. Distributed and cooperative fuzzy controllers for traffic intersections group[J]. IEEE Transactions on Systems, Man & Cybernetics Part C: Applications & Reviews, 1999, 29(2):263-271.
[7] SUTTON R S, BARTO A G. Reinforcement learning: an introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5):1054-1054.
[8] MEDINA J C, HAJBABAIE A, BENEKOHAL R F. Arterial traffic control using reinforcement learning Agents and information from adjacent intersections in the state and reward structure[C]// Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems. Piscataway, NJ: IEEE, 2010: 525-530.
[9] PRASHANTH L A, BHATNAGAR S. Reinforcement learning with function approximation for traffic signal control[J]. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(2): 412-421.
[10] ABDULHAI B, PRINGLE R, KARAKOULAS G J. Reinforcement learning for true adaptive traffic signal control[J]. Journal of Transportation Engineering, 2003, 129(3):278-285.
[11] BINGHAM E. Reinforcement learning in neurofuzzy traffic signal control[J]. European Journal of Operational Research, 2001, 131(2):232-241.
[12] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553):436.
[13] LI L, LYU Y S, WANG F Y. Traffic signal timing via deep reinforcement learning[J]. IEEE/CAA Journal of Automatica Sinica, 2016, 3(3):247-254.
[14] MOUSAVI S S, SCHUKAT M, HOWLEY E. Traffic light control using deep policygradient and valuefunctionbased reinforcement learning[J]. IET Intelligent Transport Systems, 2017, 11(7):417-423.
[15] van der POL E. Deep reinforcement learning for coordination in traffic light control[D]. Amsterdam: University of Amsterdam, 2016: 1-56.
[16] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[J/OL]. arXiv Preprint, 2013, 2013: arXiv:1312.5602 [2013-12-09]. https://arxiv.org/abs/1312.5602.
[17] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Humanlevel control through deep reinforcement learning[J]. Nature, 2015, 518(7540):529.
[18] LI Y X. Deep reinforcement learning: an overview[J/OL]. arXiv Preprint, 2017, 2017: arXiv:1701.07274 [2017-01-25]. https://arxiv.org/abs/1701.07274.
[19] DULACARNOLD G, EVANS R, SUNEHAG P, et al. Reinforcement learning in large discrete action spaces[J/OL]. arXiv Preprint, 2016, 2016: arXiv:1603.06861 [2016-03-22]. https://arxiv.org/abs/1603.06861.
[20] MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[J/OL]. arXiv Preprint, 2016, 2016: arXiv:1603.01783 [2016-02-04]. https://arxiv.org/abs/1602.01783.
[21] WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]// Proceedings of the 33rd International Conference on International Conference on Machine Learning. New York: JMLR.org, 2016: 1995-2003.
[22] DULACARNOLD G, EVANS R, HASSELT H V. Deep reinforcement learning in large discrete action spaces[J/OL]. arXiv Preprint, 2015, 2015: arXiv:1512.07679 [2015-12-24]. https://arxiv.org/abs/1512.07679.
