面向图计算系统的异步计算-加载模型
2019-06-06周晓丽
周晓丽,陈 榕
(上海交通大学 软件学院 并行与分布式系统研究所,上海 200240)
1 引 言
目前,针对大规模数据的图计算系统被渐渐关注起来,许多现实问题都可以被抽象成图模型,并用图计算系统得到解决,例如社交网络、商品推荐等.分布式框架常被用于图计算系统中,例如PowerGraph[1],PowerLyra[2],Giraph[3]文献[4]都是近些年提出的分布式图计算系统.通过集群强大的计算资源,它们可以处理规模庞大的图数据,但机器数量的增多也会为管理、协调带来难度,例如会有负载不平衡和通信代价的问题.
基于外存的核外(Out-of-core)技术为大规模图数据计算提供了另一种解决方案,通过高效访问外存(如,硬盘)和内存,该类系统使得在单个服务器上执行大规模图数据的计算成为可能,例如有GraphChi[5],X-Stream[6],GridGraph[7]等.GraphChi将边划分成不同区间并存储在外存中,它使用“并行滑动窗口”的方法载入这些边进入内存,通过顺序访问来保证合理的I/O性能.X-Stream采用了“边中心”式的计算模型,通过边在顶点间传递数据,它的性能提升主要在于只允许随机访问发生在内存内,而保证对速度较慢的外存访问是顺序的.GridGraph首先提出了二维划分边的方法“网格划分法”,它将边按照起始和结束顶点划分到不同的网格区间中,划分目的是让数据布局更有利于CPU访问.为了减少I/O数量,它在逻辑上将多个网格中的边合并成一个大的I/O数据块,一同载入内存执行.GridGraph的性能要优于GraphChi和X-Stream,这主要是因为它能有效减少I/O数量并且较合理的利用I/O带宽.
目前的out-of-core图计算系统大都侧重于优化I/O性能,例如确保顺序访问,减少I/O数量,充分利用带宽等,却没有意识到随着硬盘带宽的不断提升,计算时间逐渐凸显,尤其对于一些计算密集型的图算法,它们需要更多的计算时间,这些计算时间可能成为系统性能的瓶颈.GridGraph是三个代表性系统中性能最优的,但同样存在上述问题.由于使用了同步计算-加载模型,计算过程和I/O加载过程缺乏并行性,工作线程既要负责I/O任务也要负责计算任务,且计算任务阻塞于I/O任务,这主要因为它使用的同步I/O引擎使得线程在发送I/O请求后,不得不等待I/O操作的完成,浪费了大量的计算资源.
1http://law.di.unimi.it/webdata/clueweb12/
2http://lse.sourceforge.net/io/aio.html
3http://wufei.org/2016/09/16/linux-io-data-flow/
本文通过实验数据说明,当硬盘带宽逐渐增加时,I/O读写的时间会进一步减少,计算时间会越来越突出甚至成为瓶颈.如图1所示,在GridGraph上运行图算法PageRank[8],输入数据为ClueWeb1,当SSD数量从1增加到6时,I/O的带宽能力也呈线性增长,但计算时间与I/O时间的比例也随之增加,当SSD数量为6时,计算时间几乎和I/O时间齐平,可以预见当SSD数量继续增加时,计算时间就会成为整个系统性能的瓶颈.
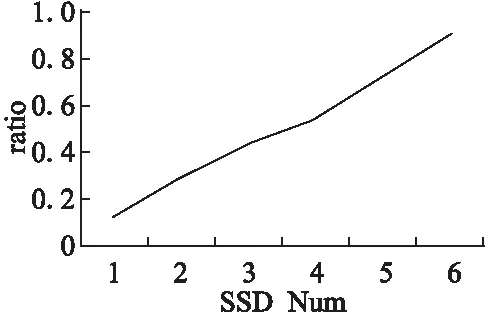
图1 计算时间与I/O时间比Fig.1 Ratio of computation time to I/O time
此外,同步计算-加载模型没有区分计算线程和I/O线程,线程数量往往由服务器的核数决定,这样的线程创建数量的确有利于计算任务的并发性,却不利于I/O访问.一方面,操作系统对外存的访问方式缺乏并行性;另一方面,I/O有限的带宽并不需要服务器核数数量的线程就能填满.这些原因决定了下层I/O无法很好的支持用户程序大量的并发请求,因此在使用同步计算-加载模型的这类系统中,例如GridGraph,它们往往由于不合理的I/O线程数量而无法充分利用硬盘带宽.
针对上述问题,本文提出了异步计算-加载模型,该模型使得图计算系统中计算过程和I/O过程能够并行起来,较长的I/O时间可以很好地“隐藏”计算时间,据此,本文也称这种模型为IOC(I/O Overlapping Computation).该模型将线程按照所执行任务的类型区分为计算线程和I/O线程,并根据不同的访问需求创建不同的线程数量.对于计算线程而言,线程数量应该由服务器的计算能力决定,它们拥有独立的子任务数据,互不干扰,IOC创建与服务器核数一致的线程数量来尽可能提高计算的并发性;对于I/O线程而言,线程数量应该由下层I/O的处理能力决定,IOC的策略是创建能够填满硬盘带宽的最小线程数量,避免造成额外开销.为了进一步提高I/O性能,IOC抛弃了其他系统使用的PSYNC I/O引擎,这类引擎接口简单,但这主要是由于下层操作系统向上屏蔽了很多实现细节,不利于上层用户程序的优化.IOC使用了异步的I/O引擎LIBAIO2,I/O线程使用该类型的接口向操作系统发出I/O请求后,无需等待I/O操作完成就立即返回,继续处理下个请求,通过这种方式,单个线程单位时间内可以处理更多的I/O请求.此外,LIBAIO的batch机制在保证硬盘带宽被填满的前提下,还能接收粒度更细的I/O请求数据,这同样有助于线程间的负载平衡.
本文的主要贡献在于:1)提出了异步计算-加载模型IOC,使得I/O时间能够“隐藏”计算时间,避免了硬盘带宽不断提升后,计算时间逐渐凸显成为瓶颈的问题.2)IOC区分计算线程和I/O线程,并能够结合硬件资源的限制,合理分配计算线程和I/O线程数量,以满足不同执行任务的访问需求.3)IOC使用的异步I/O引擎LIBAIO,在保证充分利用硬盘带宽的前提下,允许上层用户提交粒度更细的I/O数据块,优化了负载的平衡性.4)本文在最后通过实验结果表明IOC模型无论是在运行时间,I/O带宽,还是负载平衡方面都能明显优于同步计算-加载模型.
2 背景介绍
2.1 同步计算-加载模型
比较常用的一类计算模型是同步计算-加载模型.该模型没有区分计算线程和I/O加载线程.在将任务划分之后,每个线程都有一份独自的子任务,每个线程首先从外存中载入子任务所需数据,在I/O加载过程中,各个线程一直处于等待状态,直到该数据被加载进内存,线程才能重新被CPU调度并执行计算过程.在线程等待I/O的过程中,CPU一直处于闲置状态,浪费计算资源.
该模型的问题还不仅仅在于浪费计算资源,不区分计算线程和I/O线程还会影响I/O性能.在使用该模型的系统中,线程数量通常由服务器的核数决定,一般会创建20-40个线程,这些线程并行的向操作系统发出I/O请求,而目前Linux系统对外存的访问方式还缺乏并行性[9],例如Linux内核顺序的对I/O任务排序以及轮询地向底层发送I/O任务.也就是说,下层的操作系统无法满足上层用户程序大量的并行I/O请求.
更糟糕的是过多的线程同时访问I/O会降低I/O带宽.在收到用户的I/O请求后,Linux内核会执行4个操作3:plug,unplug,dispatch,completion.为了优化I/O性能,内核会在unplug阶段对当前所有I/O请求排序,从而尽可能顺序的访问硬盘.内核的这种机制在保证底层硬盘访问性能时,却可能造成对不同线程的I/O请求的响应时间不均衡,这种不均衡在顺序读文件时最为明显,图4 (a)说明了这一点.
目前大部分out-of-core图计算系统都使用同步的计算-加载模型,一方面计算线程阻塞于I/O,大大浪费计算资源;另一方面,这类模型简单的将计算线程用于I/O访问,不仅加重I/O负载、造成额外开销,而且有背于内核的优化原则,影响I/O性能.
2.2 PSYNC和LIBAIO
PSYNC和LIBAIO是Linux系统向上提供的两种I/O引擎接口.PSYNC为同步I/O类型,主要包括pread/pwrite调用,pread根据指定的文件描述符、文件偏移量读取指定长度的数据到内存,pwrite根据文件描述符、偏移量写入指定长度的数据到外存.LIBAIO是Linux的原生异步I/O,用户程序可以通过io_submit系统调用以batch的方式向Linux内核发送I/O请求,通过io_getevents调用来获取一组完成的I/O数据.
2.2.1 阻塞与非阻塞
PSYNC为阻塞式的I/O.用户程序在发起阻塞I/O调用后,会一直处于等待状态,直到内核将完成的I/O数据拷贝到用户程序空间后,才从相关系统调用中返回,用户进程阻塞于整个pread过程.而LIBAIO却是一种非阻塞型的I/O机制.用户进程发起io_submit系统调用后,无需等待I/O完成就可返回,内核负责向底层设备传递I/O请求并将返回的I/O数据先载入到内核缓冲区中,整个过程期间用户进程可以执行其他操作.当用户进程需要I/O数据时,主动发起io_getevents进行数据“收割”,内核负责将数据拷贝至用户进程的内存空间.

图2 非batch和batch的比较 Fig.2 Comparison of non-batch and batch
不难发现,阻塞型I/O会造成用户进程大量的等待时间,但目前的很多图计算系统都采取这种方式.它们通常开辟服务器核数的线程,并行发起pread/pwrite调用,这些线程阻塞于整个I/O调用过程,无法进行计算,导致大量计算资源的浪费.
2.2.2 非batch和batch
LIBAIO可以batch提交I/O请求,通过参数BLOCKSIZE、IODEPTH可以分别指定单个IO请求块的大小和批量处理的块数量.相比PSYNC,LIBAIO的batch机制可以用来支持更细粒度的I/O请求.上文提到了Linux系统处理I/O请求的四个阶段plug,unplug,dispatch,completion,在plug阶段,内核会将每个I/O task对应的I/O请求块合并到plug-list中,当plug-list中的数量达到一定阈值之后才会进入unplug阶段,之后才会向底层硬盘发出传输请求.为了最大效率的利用硬盘带宽,上层用户程序需要尽可能快的提交一定数量的I/O请求数据来填满plug-list,如图2所示,没有batch机制的PSYNC只能增大每次请求数据的BLOCKSIZE,而支持batch机制的LIBAIO可以通过增大batch的数量IODEPTH,从而支持更细粒度的BLOCKSIZE.
在同步计算-加载模型中,每个线程的计算数据的粒度和I/O请求数据的粒度相同,如果该模型使用PSYNC,I/O请求数据的粗粒度也直接决定了计算数据的粗粒度,在动态分配任务的计算模型中,将会导致各个线程工作负载的不平衡,从而影响整体系统的性能.
3 异步计算-加载模型IOC
异步计算-加载模型IOC区分了计算线程和I/O线程,计算线程无需管理I/O的读写,仅仅负责数据的计算,只要有待处理的数据就会不断地被CPU调度执行.I/O的读写操作由专门的I/O线程管理,这些线程无需关心上层计算,只负责发送I/O请求和“收割”I/O数据,只要有足够的内存空间就会不断地将数据从硬盘中载入进来.计算线程和I/O线程并行执行各自的任务,这样一来较长的I/O时间便可以“隐藏”计算时间,从用户程序的角度,整个系统的运行时间就只有I/O时间.
3.1 挑战
但实现IOC模型并不容易,关键难点就在于如何在内存容量限制的前提下,协同I/O线程和计算线程:I/O线程将从硬盘中载入的I/O数据块缓存在内存缓冲区中,计算线程从缓冲区中获取待处理的数据块,那么如何在内存缓冲区剩余空间不足时,同步I/O线程放慢(或停止)I/O操作,当没有新载入的I/O数据块时又如何通知计算线程.这看起来像一个生产者-消费者问题,但却复杂的多.
传统的生产者-消费者算法存在两个明显弊端:
1)生产者和消费者都是按序连续的使用内存缓冲区,不够灵活.
2)生产和消费过程都涉及到数据的拷贝,并且拷贝时相应线程独占整个缓冲区资源,其他线程只能等待,缺乏并行性.在IOC中,计算线程相当于消费者,I/O线程相当于生产者,但如果直接使用上述算法,还是会有不少问题:
1)按序连续使用内存的方式不够灵活,只能支持同步I/O引擎PSYNC,而支持不了异步I/O引擎LIBAIO,这主要因为当I/O线程主动调用io_getevents请求“收割”I/O数据时,操作系统将I/O数据从内核缓冲区拷贝至用户的内存缓冲区中,但并不能保证按照用户内存的地址顺序来进行拷贝,也就无法保证内存缓冲区被连续使用.
2)如果每次计算线程和I/O线程“生产”和“消费”时都需要进行数据拷贝,首先会增加内存负担,其次拷贝过程需要消耗一部分计算资源,这些都将影响IOC的性能.所以,实现IOC并不能简单的套用传统的“生产者-消费者”模型,具有一定挑战性.
3.2 关键设计
为了解决上面的问题,图计算系统需要更加灵活的异步计算-加载模型IOC,灵活体现在允许离散的使用内存缓冲区空间以支持LIBAIO引擎;此外,还需减少计算、加载过程中数据的拷贝.为了解决这些问题,本文提出了基于地址管理的IOC模型.
首先将内存缓冲区按照I/O数据块的大小进行划分,假设内存缓冲区的总空间为BUFSIZ,I/O数据块的大小为BLKSIZ,那么就将缓冲区划分成BUFSIZ/BLKSIZ块,第i块的地址为i*BLKSIZ.IOC将这些块区分为数据块和空闲块,并使用队列来记录它们的地址,队列中相邻的块地址可能指向离散的物理内存空间.
如图3所示,队列computing记录着等待计算线程处理的数据块地址,I/O loading队列记录着等待I/O线程载入数据的空闲块地址.两组线程分别查找各自队列以获取所要的块地址,避免了竞争,同时也通过彼此队列实现同步.图3描述了具体的同步过程:
1)计算线程访问computing queue,请求获取可计算的数据块地址,如果队列为空,则进入等待状态,否则成功返回;
2)计算线程通过地址访问到该数据块并执行计算,计算结束后就释放该数据块以用于载入新的I/O数据,将该数据块的地址插入到I/O loading queue中,该数据块变为空闲块.
4http://law.di.unimi.it/webdata/uk-union-2006-06-2007-05/
3)I/O线程访问I/O loading队列,请求获取一个可用空闲块的地址用来载入I/O数据,如果该队列为空则等待,否则执行I/O操作.
4)I/O操作完成后,该地址指向的空闲块中填充了I/O数据,下一步就是交给计算线程计算,I/O线程将该空闲块的地址插入到computing queue中,空闲块又变为数据块.从静态角度看,在某个时刻,缓冲区内的某个内存块为数据块或空闲块,它们对应的地址只可能出现在两个队列中的其中一个.从动态角度看,这些内存块的地址在两个队列之间不停流转,构成了整个IOC的同步过程.

图3 异步计算-加载模型IOCFig.3 Model of asynchronous computation-I/O (IOC)
计算和I/O线程并行执行各自任务,并通过队列同步、协作,共同完成图计算系统的任务,算法1也表示了这一过程.最开始,computing队列为空表示当前无可计算的数据块,所有内存块都是空闲状态,它们的地址都被插入到 loading队列中.队列通过锁机制保证了多线程访问时数据的正确性,front_pop()为同步操作,只有当队列不为空时,当前线程才能成功获取地址,否则进入等待状态.计算线程可以通过返回地址p_data_blk访问到数据块data_blk,并进入处理数据阶段.传统的“生产者-消费者”算法先将数据块内容拷贝至计算线程自己的内存空间中,释放锁之后再计算,但拷贝操作无疑会增加内存和计算资源的负担.考虑到大部分图算法的计算过程都比较简单、时间较短,IOC中计算线程会直接对内存缓冲区中的数据data_blk进行计算,而不是预先拷贝副本,直到处理完data_blk中的数据后,才会通过间接操作地址的方法释放该数据块.它将data_blk的地址p_data_blk插入到loading队列中,等待I/O线程主动获取并重新利用.I/O线程成功获取空闲块地址p_free_blk后,开始执行do_io操作,并准备向操作系统发送I/O请求,IOC灵活使用内存的方式可以用来支持异步发送I/O请求.当I/O线程通过LIBAIO提供的io_submit发送请求时,会向操作系统传递两大基本参数:需要读取的数据块地址范围、读到内存的地址p_free_blk,传递完毕后就返回.之后,操作系统将该范围的数据块从外存载入到内核缓冲区中,在“收割”数据阶段,再直接将数据从内核缓冲区拷贝至p_free_blk指向的空闲块中.完成“收割”后,该空闲块转化为数据块,I/O线程随即将该块地址插入到computing queue中.
算法1.异步计算-加载模型(IOC)
// completed or not
Boolean done = 0;
Queue computing { 0 };
Queue loading { BUFSIZ/BLKSIZ };
1 procedurecompute() {
2 while (!done) {
3 Addr p_data_blk = computing.front_pop();
4 do_compute(p_data_blk);
5 loading.append(p_data_blk);
6 }
7 }
8 procedureio() {
9 while (!done) {
10 Addr p_free_blk = loading.front_pop();
11 do_io(p_free_blk);
12 computing.append(p_free_blk);
13 }
14 }
基于地址管理的IOC算法更加灵活.当某个空闲块地址中的内存被填充好I/O数据后,它就立刻被I/O线程处理,并被插入到computing queue中,而无需等待那些地址在它之前但还未完成I/O操作的空闲块,这点可以用来支持异步的I/O发送接收方式(LIBAIO引擎).当某个数据块被处理完毕后,计算线程随即将它插入到loading queue中,而无需因为内存连续使用的限制而等待.此外,两组线程都是通过内存地址直接对缓冲区中的数据进行操作,有效避免了数据的拷贝,从而节省了一部分内存和计算资源.
3.3 使用LIBAIO支持更细粒度的I/O数据块
IOC使用LIBAIO作为I/O引擎.一方面,I/O线程可以非阻塞的发送I/O请求,而无需等待I/O操作的完成,这样可以增强系统发送I/O请求的能力,尽快地填满硬盘带宽.另一方面,LIBAIO的batch机制可以支持更细粒度的I/O数据块,这些I/O数据块被填满I/O数据后,地址被插入到computing queue中,等待计算线程的处理,这就相当于通过“动态分配”的方式让所有计算线程来“竞争”这些数据块.粒度更小,各个工作线程的负载就越平衡,4.3通过实验说明了这点.
3.4 合理的I/O线程数
为了适应内核的I/O访问机制,合理的做法是分配能够填满I/O带宽的最小线程数量,IOC也遵从这一原则.例如对于1个SSD(最大带宽为450MBps),单个线程就可以填满,IOC仅分配1个I/O线程.在顺序读取文件时,单个线程按照文件顺序发出I/O请求,文件偏移量低的数据块会优先到达,内核也会按照这样的顺序向I/O通道传递请求,这样一来,到达的数据块都会被及时处理,I/O请求的完成时间比较均衡.
为了更有说服力,本文通过实验比较了对文件顺序读时,使用40个线程和1个线程的I/O请求时间.实验在GridGraph上运行PageRank算法,输入数据为UK图4,使用1个SSD.结果如图4所示,横轴为按照文件偏移顺序排列的各个I/O请求,纵轴为请求的完成时间.图4(a)为40个线程顺序读时各个I/O请求的时间,抖动很大;图4(b)为使用单个线程的结果,各个I/O请求的完成时间比较均衡且远远低于40个线程的数值.这也就说明了过多的I/O线程不仅会加大I/O负载,还会造成I/O请求完成时间的不均衡,增大延迟,从而影响整个图计算系统的I/O性能.
5http://law.di.unimi.it/webdata/gsh-2015/
6http://law.di.unimi.it/webdata/eu-2015/

图4 I/O完成时间比较Fig.4 Comparison of I/O completion time
4 性能评测
GridGraph是目前性能比较出色的out-of-core图计算系统,它的性能要优于X-Stream和GraphChi,这也是本文选取它为参照的原因.GridGraph使用同步计算-加载模型,并通过PSYNC提供的I/O接口来处理I/O请求.本文的实验直接修改了GridGraph代码,使它支持使用LIBAIO引擎的异步计算-加载模型,并着重探究两种模型对图计算系统性能的影响,主要从以下三个方面探究:运行时间,计算负载的平衡性,I/O带宽.

表1 实验数据集Table 1 Experimental data sets
4.1 实验环境
本文的所有实验均在单个多核服务器上完成,服务器配置为:40个超线程vCPU cores,25MB LLC Cache,116GB memory,1-6 800GB SSDs,6个SSD顺序读的最大吞吐量均可达到450MB/s-500MB/s.
4.2 运行时间
下面实验分别在使用不同计算-加载模型的GridGraph中运行PageRank和SPMV[10]算法,使用6个SSDs (RAID0),输入数据如表1所示,这些图数据(UK,GSH5,ClueWeb,EU6)描述了从不同域名爬取的网页信息.PageRank和SPMV均为计算密集型算法,计算时间所占比重较大,使用IOC模型之后,它们的计算时间被I/O时间“隐藏”,因此整体系统性能的提升比较明显.图5(a)为PageRank算法下两种模型的时间比较,左边为GridGraph的运行结果,包括下面的I/O时间和上面的计算时间,紧挨着的右边为基于IOC模型的GridGraph (IOC-Grid)的运行总时间.两个模型的运行时间都随着输入图规模的增加而上升,但IOC-Grid的运行时间要始终少于GridGraph,这主要归功于计算时间被I/O加载时间“隐藏”;此外,IOC能更好的利用硬盘带宽,I/O加载时间少于GridGraph,这主要归功于IOC模型灵活的区分I/O线程和计算线程,并创建合理的I/O线程数,既能填满硬盘带宽又不会造成额外开销,从而提高了I/O性能.图5(b)为SPMV算法的运行结果,IOC-Grid性能依然保持领先.SPMV算法中的边是带权重的,与PageRank相比,需要多载入边的权值数据,因此也就需要更多的运行总时间.

图5 GridGraph与IOC-Grid的运行时间Fig.5 Runtime of GridGraph and IOC-Grid
IOC-Grid在不同的输入数据集上有不同的性能提升,其中ClueWeb图的提升最为明显,这主要因为该图的计算时间最突出,几乎与I/O时间齐平.GridGraph的计算性能受数据布局的影响较大,好的数据布局有助于顶点数据的顺序访问,提高cache命中率,从而减少计算时间.但ClueWeb的数据布局不及其他三个数据集,这点从表2所示的LLC 未命中率就可以看出,这就导致它的计算时间最为突出,几乎与I/O时间齐平.IOC将这最明显的计算时间“隐藏”,使得整体性能能够提升到一半.

表2 不同数据集的LLC 未命中率Table 2 LLC cache miss rate of different data sets
4.3 计算线程负载的平衡性
为了比较两种模型下计算线程负载的平衡性,下面实验在原先和修改后的GridGraph上分别运行PageRank算法,创建了40个计算线程,输入的图数据为UK,使用1个SSD.图6(a)为GridGraph的运行结果,使用了PSYNC引擎的同步计算-加载模型;图6(b)是支持LIBAIO的IOC模型的运行结果.可以明显看出IOC中计算线程的负载要更加平衡,这主要归功于LIBAIO可以支持更细粒度的I/O数据块.Grid-Graph使用的PSYNC引擎为了填满硬盘带宽,I/O数据块小被设定在24MB,而IOC为128KB.两者的I/O数据块大小都决定了计算数据块的大小,128KB和24MB相比明显粒度更细,这也使得IOC中负载的分配能够更加公平,各个计算线程的负载更加均衡.
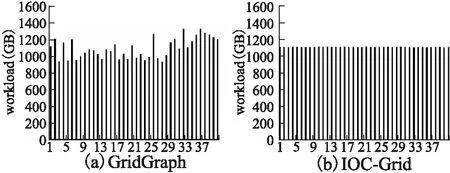
图6 GridGraph与IOC-Grid的负载平衡性Fig.6 Load balance of GridGraph and IOC-Grid
4.4 不同SSD数量下的带宽比较
表3为不同SSD数量下,IOC-Grid和GridGraph的带宽比较结果.可以发现,IOC-Grid始终能保持更高的带宽利用率,在1个SSD下最为明显.这主要归功于IOC能够根据下层I/O的处理能力合理的分配I/O线程数量,而GridGraph中 I/O线程数量取决于服务器核数,大量的I/O线程数量会增加资源竞争和额外开销.随着SSD数量增多,下层I/O的处理能力增强,能够稍微缓解上层大量I/O并发请求的竞争,GridGraph受益于此,I/O带宽有所提升,但依然不及IOC-Grid.

表3 不同SSD数量下的带宽,单位MBpsTable 3 I/O bandwidth under different SSD number,MBps
5 结 论
核外(Out-of-core)图计算系统使得在单点服务器上执行大规模图数据成为可能,已有的该类型系统都是通过优化I/O访问来提高性能,却忽略了随着硬盘访问能力的提升,计算时间越来越突出的问题.对此,本文提出了异步计算-加载模型IOC,在该模型中计算过程不再阻塞于I/O加载过程,较长的I/O时间能够“隐藏”计算时间.IOC根据硬件资源的访问能力分配不同数量的线程数,既保证高效的计算能力又保证充分的带宽利用.IOC摒弃了传统同步计算-加载模型使用的PSYNC I/O引擎,改用LIBAIO,异步的处理方式提高了接受I/O请求的能力,LIBAIO提供的batch机制也使得各个线程的负载更加均衡.本文最后通过实验结果说明,IOC能将out-of-core图计算系统的性能提升高达1倍,并且有更好的带宽利用率和负载平衡性.
