基于深度神经网络的自适应波束形成算法
2019-04-26柏沫羽陈浩川张振华
柏沫羽,刘 昊,陈浩川,张振华
(北京遥测技术研究所 北京 100076)
引 言
自适应波束形成技术是阵列信号处理的重要分支,其广泛应用于航天领域中的导航、飞行器测控和精确制导等的旁瓣抗干扰中,近年来已经成为新一代航天、雷达和通信领域的关键技术之一。自适应波束形成技术能够通过调整接收通道权系数来有效地实现干扰抑制等功能,在航天、雷达、无线通信、声纳、地震勘测等领域中得到了广泛的应用。传统的自适应波束形成基于最大信噪比SNR(Signal-to-Noise Ratio)、最小均方误差MMSE(Minimum Mean Squared Error)和最小方差无失真响应MVDR(Minimum Variance Distortionless Response)等准则来设计波束形成器。但是当所得到的回波数据量增多时,传统的波束形成算法无法进行及时处理。而深度神经网络模型可以在前期对大量的数据进行训练,之后利用训练好的模型就可以快速准确的进行波束形成,比传统的波束形成算法更加快速,满足了在大数据的情况下进行快速波束形成的需求,具有理论和工程上的研究意义。
因此,将深度神经网络与自适应波束形成技术相结合,具有提升自适应波束形成算法高效性的前景。近年来随着深度学习理论体系日趋完善,人工智能技术应用于越来越多的领域,将波束形成技术和深度神经网络技术相结合已经被业内学者广泛使用[1-6]。2004年Suksmono等人引入了多层感知机来替换传统的LMS算法的单层模型[7],在收敛速度上有所提升,但是依然采用的是迭代的方法,没有充分利用神经网络的非线性拟合能力。1998年Zooghby等人[8],2008年Xin等人[9],2009年Savitha等人[10],2015年张宝军等人[11]均研究了利用径向基神经网络进行波束形成的方法,但是这种方法的神经网络训练过程较为复杂,需要进行额外的k-means聚类等操作,并且为了不使用更深层的神经网络而引入了过多的人工先验假设。2018年冯晓宇等人提出了在低快拍情况下利用径向基神经网络进行波束形成的方法[12],这种方法仅仅是对低快拍情况下的改进,并没有对以上径向基神经网络存在的问题进行解决。本文将径向基神经网络推广为深度神经网络,避免了使用k-means算法而带来的局限性,为神经网络模型应用于波束形成中做了良好的铺垫,达到了更加快速的效果。
本论文根据波束形成原理利用分段训练方式设计深度神经网络,在设计模型时使用了Leaky-ReLU激活函数,解决了模型训练过程中的梯度消失以及神经元提前失活的问题。运用Adam优化器提高模型训练的全局收敛性,加快了算法的速度,并结合Dropout正则化方法提升过参数化网络的泛化性能,提出了基于深度神经网络的波束形成算法NNBF(Neural Network Beamforming)。
1 理论背景
1.1 LMS算法(Least Mean Square Algorithm)
NNBF算法是基于LMS算法进行构造的,LMS算法是自适应波束形成算法中广泛使用的一种,它的本质是基于MMSE准则构造损失函数,使损失函数达到最小,是一种迭代算法。假设一维线阵一共有N个阵元,t时刻的期望信号为d(t),信号处理机接收到的数据为X(t),第i个阵元的权重值为Wi,根据MMSE准则,目的是使y(t)–di(t)的均方值最小,其中y(t)=WiHx(t),则损失函数为
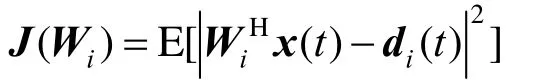
之后利用迭代方法来求最佳值,权矢量更新的表示式为[13]
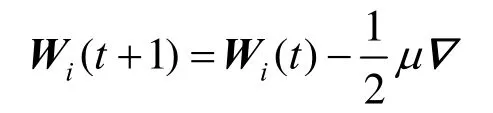
其中,μ为用来决定算法收敛速度的学习率。当学习率μ为常数时,有
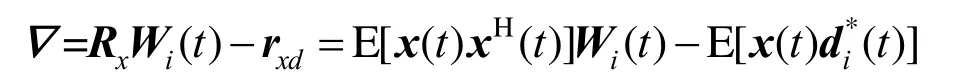
用相应的瞬时值表示,则可得出在时间点t时对梯度的估计为
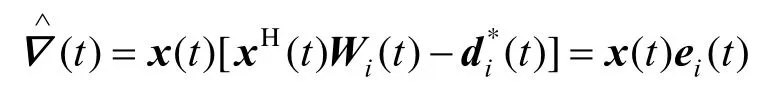
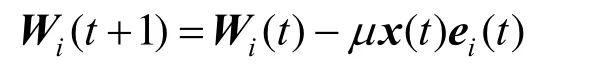
μ值与收敛速度有关,μ值越大,迭代次数越少,收敛速度越快,但是有可能导致无法收敛的情况。μ值越小,迭代次数越多,收敛速度越慢,但是可以保证收敛到最优值。因此这种传统的波束形成算法无法满足收敛速度和收敛性之间的平衡,而利用深度神经网络模型建立的NNBF算法可以解决这个问题,具有良好的性能。
1.2 深度神经网络
深度神经网络算法是机器学习中的一种算法,以人工神经网络算法为基础,是人工神经网络的一个方向[14]。此外,深度神经网络[15]是一种拥有良好泛化性能的非线性模型,相对于普通的神经网络而言,其拥有更多的参数并且能更好的提取数据隐含的层次特征。虽然根据万能近似定理,在拥有足够参数的情况下,单隐藏层的神经网络可以以任意精度拟合任意初等函数,但是研究表明[16],在相同的参数下,更深的神经网络比更浅的神经网络拥有更好的泛化性能。因为神经网络的每一层都是对原有输入数据的一次抽象,所以多层神经网络能够更加深刻认识到问题的本质。神经网络的结构如图1所示。
其中x为神经元的输入,v,w为第一层和第二层神经元的连接权重,f为激活函数,θ为阈值,y为输出。将上述关系表示为公式的形式
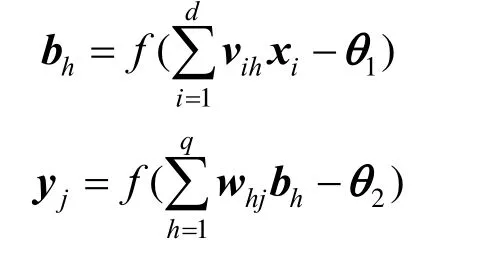
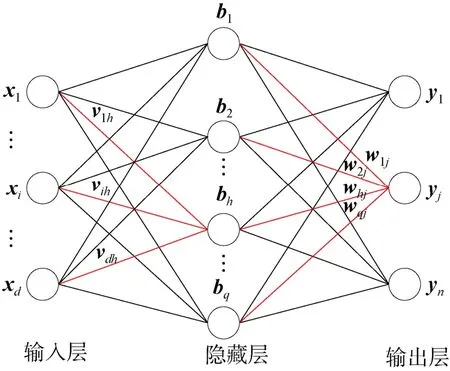
图1 神经网络结构Fig.1 Neural network structure
2 基于深度神经网络模型的波束形成算法
2.1 问题描述
深度神经网络是一种能够构建复杂非线性关系的模型,在通过一定数量的样本训练之后,它也可以推断未知数据之间的未知关系,拥有较强的泛化性能。波束形成技术是一种通过回波信息和约束关系来合成波束的一种技术,传统的波束形成算法运算量大,运算时间长,占用资源多,在接收到大量回波数据时无法快速的进行实时处理。因此利用深度神经网络对传统的波束形成技术进行改进,可以使波束形成的时间缩短,还可以根据所得的回波数据不断更新网络模型,使训练出来的神经网络可以更好的应对各种情况,具有良好的稳健性。
根据波束形成的原理,抽象深度神经网络模型,深度神经网络的模型输入为回波信号X,n为接收信源的数目,batch为训练样本的数量。不失一般性,以一维线阵为例,天线阵元数为16,模型的输出为形成的波束信号Y,自适应波束形成权重因子为Z,W为模型的权重,其中X∈Rbatch×n,Y∈Rbatch×1,W∈Rn×1。
使用深度神经网络进行自适应波束形成有两种潜在的解决方案,以下是对这两种解决方案的分析。
2.2 端到端训练方式
端到端自适应波束形成神经网络训练框架可用如下公式(1)~(4)进行表示:
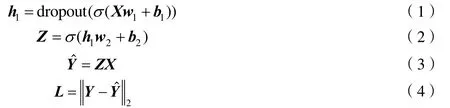
其中w,b分别为神经网络的权重和偏置,σ为Leaky-Relu激活函数,为实际形成的波束信号,L为实际波束与期望波束的均方误差函数。
采用这种模式训练的好处是模型训练简单,可以直接利用X,Y这种原始的训练样本,并且在模型部署之后依然可以方便的使用原始样本进行模型更新,实现模型的在线学习。
但是问题在于,对于相同期望信号方向以及干扰方向的X输入,模型输出的Z并没有相似性约束,这就导致模型会将相同期望信号方向和干扰信号方向的不同Y产生不同的权重因子Z,导致模型过拟合,波束形成效果很差。采用端到端训练模式得到的波形如图2所示。
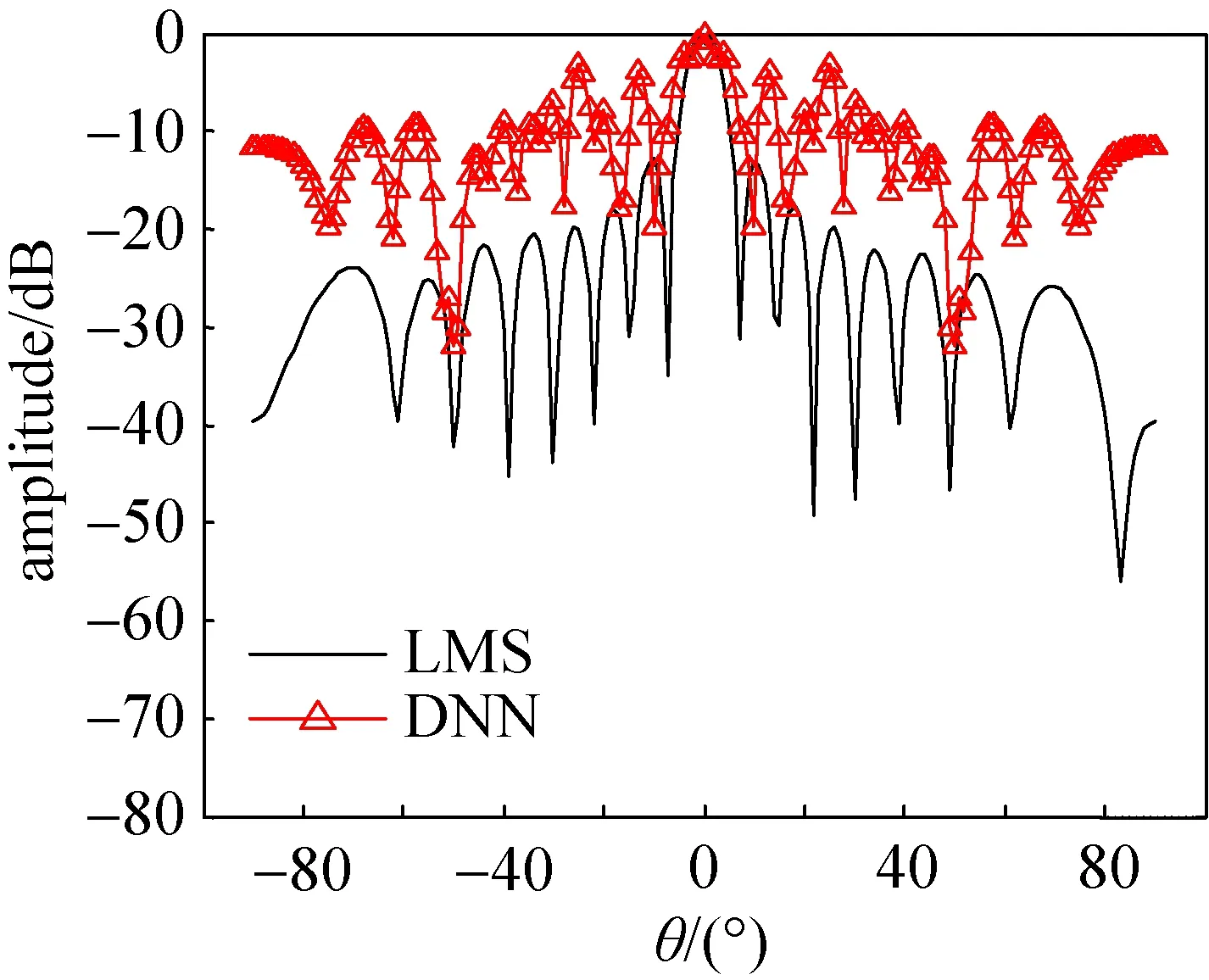
图2 采用端到端方式的深度神经网络算法和LMS算法的天线方向图Fig.2 The antenna pattern of end-to-end deep neural network algorithm and LMS algorithm
从图2中可以看到,在期望信号方向为0°,干扰信号方向为–50°情况下,LMS算法可以很好的对波束进行合成,但是采用端到端的神经网络模型时,波束形成的期望信号方向不准确,干扰信号方向也没有很好的进行抑制,因此采用这种模型方式对于波束形成来说并不适用。
如果将端到端训练方式中对Z添加相似性约束的损失函数,训练框架可用公式(5)~(10)进行表示:
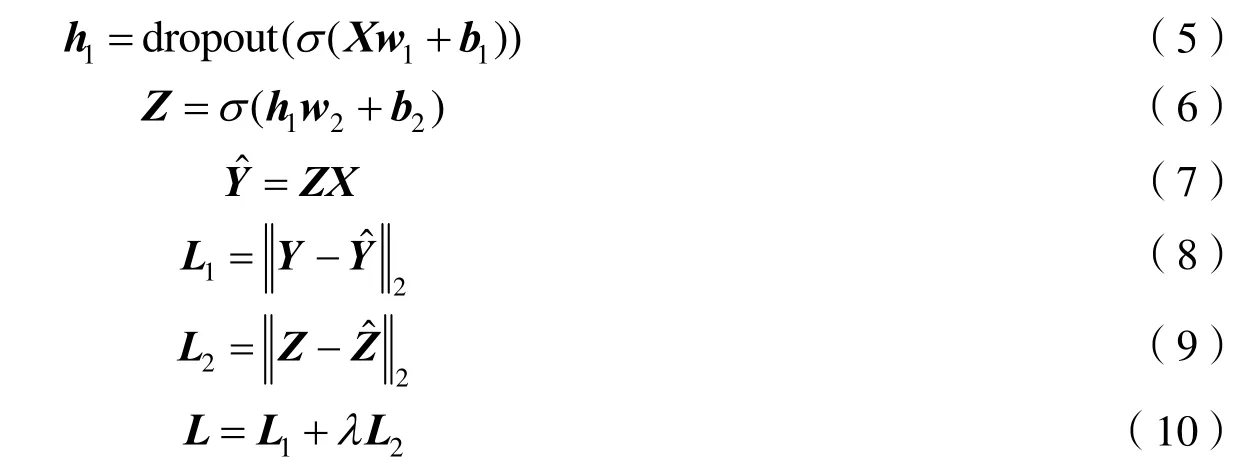
但通过对训练结果进行仿真分析发现,训练难以符合预期,其原因是添加的相似性约束的损失函数绝对值相较于Y的损失函数而言太小,二者的损失函数占比难以手动设置,这就导致训练初期Y损失函数的梯度会迅速覆盖Z相似性约束的梯度,导致最终结果依然是倾向于对于每一对相同期望信号方向和干扰信号方向的X、Y提供不同的Z。因此本论文最终不采用端到端训练方式而采取了后文所说的分段训练方式。
2.3 分段训练方式
2.3.1 训练流程
为了解决端到端训练带来的模型过拟合问题,本论文采用分段训练方法,即首先将相同的期望信号方向、干扰信号方向的数据进行分组,每一组训练样本先采用传统的波束形成算法获得的期望权重因子Z向量,然后将Z作为新的训练样本目标,训练框架可用下述公式进行表示:
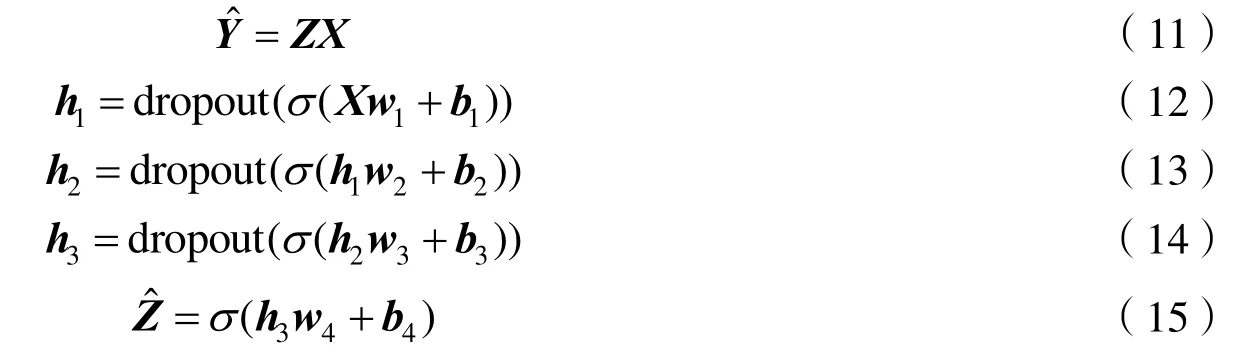
其中,公式(11)表示波束形成算法的原理,公式(12)–(15)表示神经网络的原理。在训练神经网络的过程中,发现含有一层和两层隐藏层的神经网络无法在训练集中达到较好的训练误差,而有三个隐藏层的深度神经网络能在测试集和训练集中都达到较好的效果。因此,本论文设计的神经网络是一个含有三层隐藏层的深度神经网络,各层神经网络的权重和偏置分别为w1,b1,w2,b2,w3,b3,w4,b4,w1为一个16×1024的矩阵,w2为一个1024×512的矩阵,w3为一个512×256的矩阵,w4为一个256×16的矩阵,σ为Leaky-ReLU激活函数。
训练流程如图3所示。
综上所述,端到端的训练方式缺点在于,需要显式的添加同一组期望方向和干扰方向的权重向量的相似性约束,这会引入一个难以调节的超参数,导致训练难以收敛到带约束的最优解。分段算法相较于端到端的训练方式而言,主要是在训练流程中就隐含了权重向量相似性的先验知识,相当于隐式的为模型添加了结构化先验,使分段训练过程不容易产生过拟合的现象。此外,分段训练避免了手动调节超参数,更便于找到带约束的最优解。
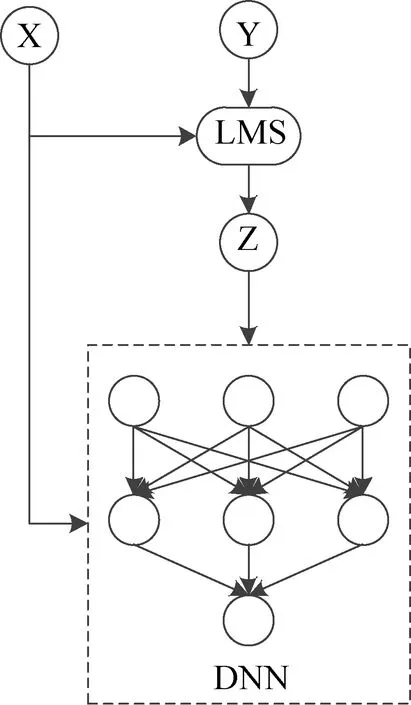
图3 分段训练流程Fig.3 Segmentation training flow char
2.3.2 Leaky-ReLU激活函数
训练模型由于是多层神经网络,有三层隐藏层,因此需要仔细选取每一层的激活函数才能获得较好的结果。sigmoid,tanh等激活函数会使得在训练过程中处于饱和状态的隐藏层梯度很小,根据求导的链式法则可知,对于靠近输入的隐藏层,梯度的连乘使得损失函数对其的导数非常小,这就导致了梯度消失。为了防止训练过程中梯度消失,深度神经网络一般不使用sigmoid,tanh这些激活函数。
ReLU是一种常用的激活函数,拥有不饱和的激活区域,并且求导计算开销很小。但是ReLU激活函数依然存在其缺陷,在神经网络训练过程中,如果某个神经元在非激活状态,ReLU函数会导致这个神经元输出为0,这在深度学习中称之为神经元死亡。神经元的死亡会导致该神经元梯度无法更新并反向传播,这种情况在神经网络训练初期大量出现,并且将会极大影响训练结果。
因此,本论文采用Leaky-ReLU激活函数作为隐藏层的输出[17],这种激活函数在神经元抑制区域依然拥有非零的梯度值,使得隐藏层的神经元在训练过程中不会大量死亡,可以让更多的神经元得到充分训练,并且Leaky-ReLU也拥有ReLU激活函数计算开销小的优点,对于嵌入式系统十分友好。
2.3.3 Adam优化算法
由于深度神经网络是一个非凸优化问题,拥有很多的局部极值点以及鞍点,普通的梯度下降算法很容易让模型陷入局部极值以及鞍点。所以应该采用带动量的一阶优化算法,以便使算法能够跳出局部最优值以及鞍点,得到更优质的解。
SGD算法是一种固定学习率的经典算法[18],而Momentum方法是一种通过添加动量[19],提高收敛速度的算法,Adagrad算法让不同的参数拥有不同的学习率[20],并且通过引入梯度的平方和作为衰减项,而在训练过程中自动降低学习率,AdaDelta算法则对Adagrad算法进行改进[21],让模型在训练后期也能够有较为合适的学习率。Adam方法就是根据上述思想而提出的[22],对于每个参数,其不仅仅有自己的学习率,还有自己的Momentum量,这样在训练的过程中,每个参数的更新都更加具有独立性,提升了模型训练速度和训练的稳定性,其公式如下所示[23]:
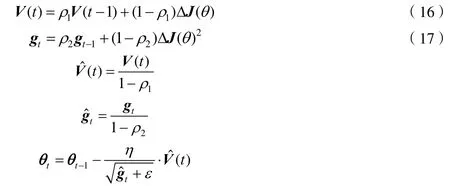
一般地,ρ1设置为0.9,ρ2设置为0.999。可以看到公式(16)表示了Momentum算法,公式(17)表示了Adadelta算法,因此Adam算法本质上是Momentum算法和Adadelta算法的结合,通过下述图4也可以看到这一结论。
综上所述,应用Adam优化算法的自适应学习率调节功能可以使得神经网络训练梯度下降初期更加迅速,后期更加稳健,并且不会提前停止;对于收敛性而言,Adam优化算法的动量部分能够使得模型收敛到相较于普通梯度下降算法更优的局部最优解上,大大提高了模型的性能。
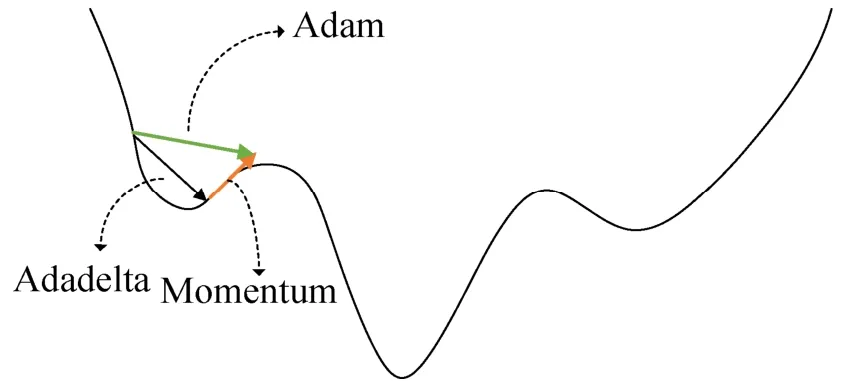
图4 Adam算法原理Fig.4 Adam algorithm schematic
2.3.4 Dropout在NNBF算法中的应用
在训练过程中发现设计的深度神经网络相较于训练样本而言是过参数化的,很容易过拟合。为了降低深度神经网络过拟合的风险,本论文采用了Dropout方法来进行深度神经网络的正则化。
Dropout算法是一种神经网络的正则化方法[24],其功能是防止神经网络的过拟合。其实现方式是在训练过程中的某些隐藏层输出随机选一些置为零,相当于每次训练都在对当前神经网络进行一次剪枝,并训练一个剪枝后的神经网络。训练完毕之后去掉Dropout层,从而将之前训练的所有子网络的输出进行平均,以此达到更好的预测结果。因此图1神经网络经过Dropout后变为图5。
用公式表示Dropout的原理,即
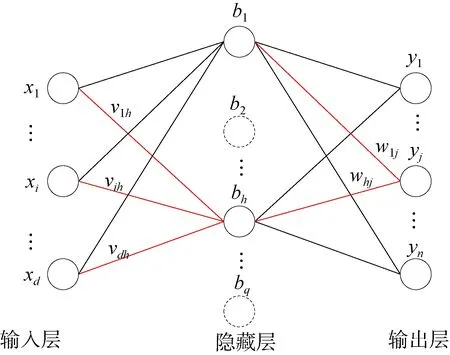
图5 神经网络经过Dropout后的结构Fig.5 Structure diagram of neural network after Dropout
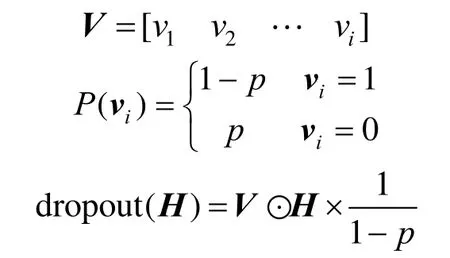
其中H代表神经元,⊙表示哈达玛乘积,Dropout实现方式是根据提供的概率p生成一个0,1随机向量V,其中0出现的概率是p;然后用p和隐藏层H进行逐元素相乘,最后再将结果向量乘以1/P,从而抑制较少的隐藏层带来的输出值变小的后果。经过交叉验证,隐含节点Dropout概率等于0.5的时候效果最好,原因是概率为0.5的时候Dropout随机生成的网络结构最多。其最直接的作用就是提升模型的泛化能力,提高模型的健壮性和通用性。因此在深度神经网络模型中一般都会采用Dropout算法对模型进行优化。
综上所述,Dropout在训练过程中可以让神经网络的多个子神经网络得到充分训练,并且每个子神经网络的训练数据集都不一样,相当于集成学习中个体学习器准确性更高,多样性更好,因此带Dropout的神经网络会带来更好的泛化性能。
通过上述各个流程的操作,深度神经网络模型的总体原理如图6所示。
其中,三个隐藏层的神经网络原理如图7所示。
综上所述,NNBF模型可以利用深度神经网络的强大非线性拟合能力以及良好的泛化性能,根据回波信号直接推断出波束形成的权值向量,避免了传统的LMS算法需要迭代的缺点,大大提高了波束形成的速度。此外,深度神经网络的性能会随着训练数据的增大而加强,可以通过更多的离线训练来提高波束形成的准确度,并且不影响实际使用过程中的推断速度,解决了传统LMS算法需要在准确性和速度之间作权衡的矛盾。
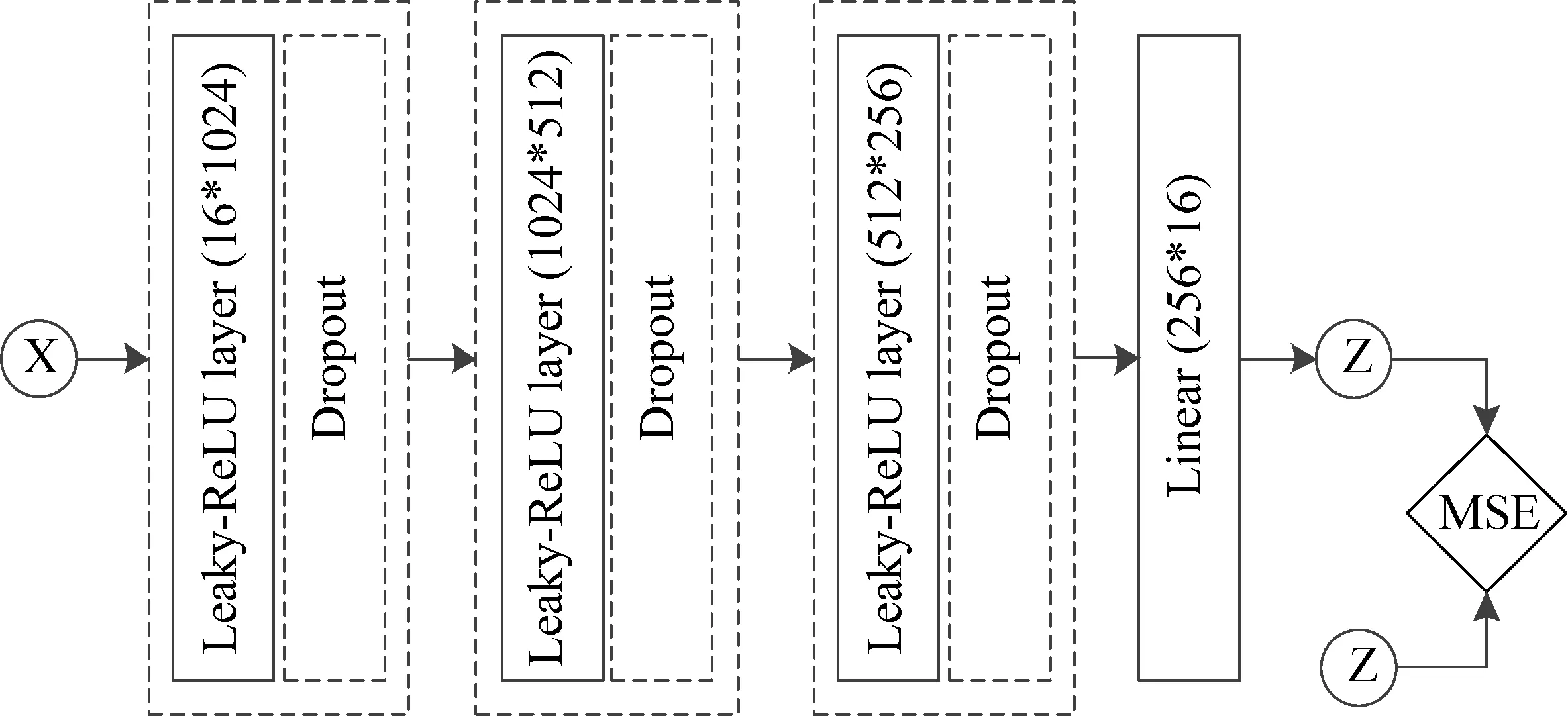
图6 模型的总体原理Fig.6 Overall schematic of the model
3 仿真与分析
由于在雷达系统中模型输入、输出、参数均为复数,所以本实验将数据拆分成实数域和复数域两部分,分别进行算法的实现。采用这种拆分方法,原复值函数计算每次需要进行四次实数乘法,三次加减法;但是如果拆分为实数域和复数域分别计算,则只需要进行两次实数乘法计算,提高了运算速度,节省了运算时间。为了不失一般性,以一维线阵为例进行仿真。其中天线阵元数为16,阵元间距为半波长,信噪比为10dB,干噪比为30dB,取6个不同目标方向和干扰方向的6000个训练样本和60个测试样本,其来波方向分别为0°,10°,20°,30°,40°,50°,对应干扰方向分别为–50°,–40°,–30°,–20°,–10°,0°。此外,在下述仿真中,验证NNBF算法的可行性以及意义时,均采用传统的LMS算法作为基准。下述所有仿真图均基于此条件进行仿真分析。
图8是期望信号方向为0°、干扰信号方向为–50°、LMS算法和NNBF算法的天线方向图,可以看到LMS算法和NNBF算法都可以在期望信号方向进行很好的波束形成,并且在干扰信号方向都可以进行很好的抑制,因此通过上述图像可以知道NNBF算法有良好的波束形成性能。
图9是在四个训练数据集下采用LMS算法,算法学习率为0.0001,统计每次迭代的均方误差值。通过LMS算法性能图可以看到在30步迭代之后,LMS算法依然存在均方误差超过10的情况。而本论文提出的NNBF算法可以完全替代掉LMS算法的迭代过程,大大提高自适应波束形成算法的效率。
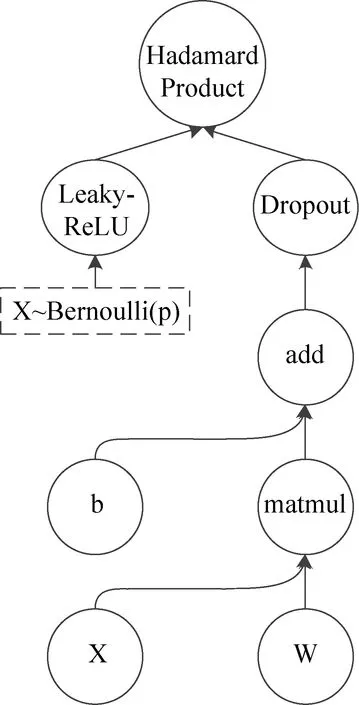
图7 隐藏层的神经网络原理Fig.7 Hidden layer neural network schematic
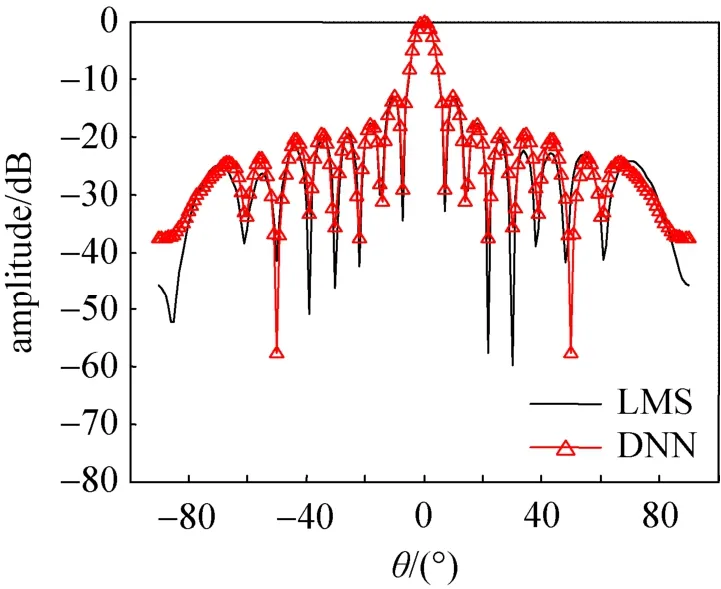
图8 LMS算法和NNBF算法的天线方向图Fig.8 Antenna pattern of LMS algorithm and NNBF algorithm
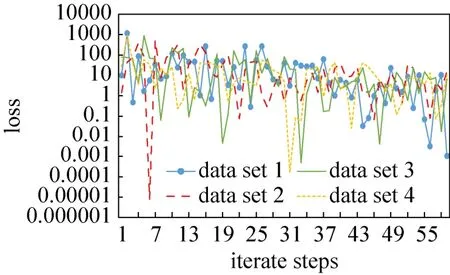
图9 LMS算法性能Fig.9 LMS algorithm performance chart
之后为了验证NNBF算法的泛化性能进行仿真实验,实验方法是取6个不同目标方向和干扰方向的6000个训练样本和60个测试样本,先采用LMS算法将6组数据的权值向量生成出来,然后作为6000个训练样本的目标输出。然后在6000个训练样本上训练2000步,此时深度神经网络的尺寸为:第一层隐藏层神经元数目为1024,第二层隐藏层神经元数目为512,第三层神经网络神经元数目为512,第四层神经网络神经元数目为512,每一层Dropout屏蔽掉神经元的概率是0.5。图10是60个测试数据上权重向量的拟合均方误差,由于本论文采用的深度神经网络是实值网络,因此对于自适应波束形成算法的复数值权重用两个实值深度神经网络来替代,这两个实值神经网络分别拟合权重矩阵的实部和虚部。
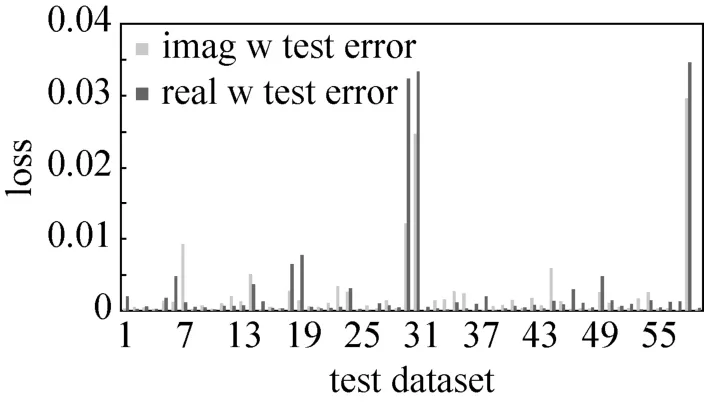
图10 NNBF算法的性能Fig.10 Performance graph of NNBF algorithm
从图10中可以看出,不论是实部神经网络还是虚部神经网络在测试时都有较小的误差值,说明在测试数据集上神经网络对于没有见过的数据展现出了良好的泛化性能,网络确实可以总结出输入的回波信号中所蕴含的目标信号方向以及干扰信号方向等信息,从而拟合出正确的权重向量。
但是权重向量本身的绝对值较小,只是观测获取到的权重向量本身的均方误差值不足以体现深度神经网络的算法性能。因此本论文继续对比了LMS算法产生的权重向量以及神经网络产生的权重向量在期望信号拟合上的性能。表1展示了在测试集上LMS算法产生的权重向量,不带Dropout的深度神经网络产生的权重向量以及带Dropout的深度神经网路产生的权重向量在拟合期望信号时产生的均方误差。
从表1中可以看出,Dropout机制确实有效降低了NNBF的泛化误差,使得NNBF算法在较少的训练样本下就达到了较好的泛化性能。相较于传统LMS算法而言,NNBF算法的优势是可以通过更大的数据规模进一步提升其预测准确性。

表1 LMS算法、不带Dropout的神经网络和带Dropout的神经网络的性能Table 1 Performance of LMS algorithm, neural network without Dropout and neural network with Dropout
在四核Intel-i7 4700HQ CPU,16G内存的情况下,使用tensorflow作为实验平台,16个阵元,测量方法为测试20次取平均值,传统LMS算法收敛到误差为0.01以下的用时和NNBF算法一次前馈计算的时间如表2所示。

表2 LMS算法和NNBF算法的计算时间分析Table 2 Calculation time analysis of LMS algorithm and NNBF algorithm
综上所述,基于深度神经网络的波束形成算法拥有更高的准确性和更快的运算速度,算法速度提高了7~8倍,节约了运算时间,并且随着数据规模的提升,NNBF模型的性能将超越现有LMS算法的性能,是一种性能优良的算法。
4 结束语
对于航天导航、飞行器测控、地面通信和新体制雷达等领域而言,自适应波束形成技术是一种良好的空域抗干扰技术。本文以LMS算法为根本,利用深度学习模型对LMS算法进行改进,使算法可以在大数据的情况下依旧能够快速稳健的进行波束形成。
深度学习是机器学习领域中一个新的研究方向,它能够学习样本数据的内在规律和层次表示,因此拥有较好的泛化性能。本论文探究了多种深度学习技术在自适应波束形成中的作用,证明了深度学习在自适应波束形成领域的意义。
NNBF算法采用深度学习的相关技术,设计了自适应波束形成的权重推断网络,并使用Adam优化器增强深度神经网络训练的全局收敛性,然后用Leaky_ReLU激活函数解决深度神经网络的梯度消失问题,并利用Dropout方法抑制深度神经网络的过拟合问题,使得自适应波束形成的权重推断网络在准确性以及泛化性上均有较好的性能。在同样的计算资源下,NNBF算法将LMS算法收敛速度提高了约7倍,并且在未来随着训练数据的增加,权重推断网络的泛化性能以及准确性能够继续提高。因此应用深度神经网络改进后的自适应波束形成算法和传统的波束形成算法相比拥有更好的性能,具有较大的理论和工程的应用价值。
