论文摘要学术规范自动检测模型研究初探*
2019-04-20叶继元
吕 远 叶继元
(1.南京大学信息管理学院 南京 210023;2.南京工业大学图书馆 南京 211816)
引言
改革开放以来,随着经济社会的高速发展,在科研学术方面我国也取得了令世人瞩目的巨大成就。但与之而来的学术失范、不端现象也是越来越猖獗,论文学术不规范的问题即是其中一个重要表现形式,该问题在高校研究生群体中表现尤为突出。由于研究生群体初涉科研工作,每一篇学术论文的发表都需要经过大量的学术规范方面的评审。目前对论文学术规范方面的评审主要是定性的主观性评价,这需要耗费大量的时间和人力成本。如何对论文的学术规范水平做一个高效的科学合理的客观评价,达到提升评审效率,降低评审成本的预期效果。这已经成为当下亟待解决的一个课题。
近几年关于学术规范和评价研究,国内外的研究成果较为丰富。刘大可从研究生学术规范意识培养的角度进行了研究,界定了学术规范的内涵与作用,并分析了造成学术失范的主要原因,在此基础上,从发挥师生关系作用的角度,提出高等院校及导师对研究生学术规范意识培养的管理机制[1]。王刚教授对社会科学学术研究规范做了详细分析,他认为一个科学、全面的社会科学学术研究规范应该包括以下三个方面:哲学上的思辨、科学上的实证、人文上的关怀。哲学上的思辨为社会科学研究提供研究的源泉和动力,科学上的实证为其提供研究的论证工具,而人文上的关怀则为社会科学研究提供价值规范[2]。叶继元教授对学术规范进行了科学定义,并提出了基本研究规范、研究程序规范、研究方法规范、论著写作规范、引文规范、署名及著作方式规范、学术批评和评价规范等内容体系。早在10多年前就出版了《学术规范通论》一书。一个学术作品是否规范,可以利用叶教授近些年提出的“全评价”理论框架来评价。所谓 “全评价”理论框架,他认为,简单地说就是,“六个要素”(六位一体)和“三大维度”。“六个要素”是指评价主体、评价客体、评价目的、评价标准及指标、评价方法和评价制度,其中评价主体是核心,评价目的是龙头,制约着其他要素。“三大维度”是指任一评价客体都可以从三个维度去考察:形式评价、内容评价和价值、效用评价。形式评价主要是根据评价对象的表象来评价,往往可以定量评价,相对直观、简单。内容评价主要深入评价对象的内核,往往依靠同行专家来评价,费时费力。效用评价是指对评价对象的实际贡献、社会和经济效益、应用结果、人们思想变化等的评价,它依赖于一段时间或较长时间的评价,是“进行时”或“未完成时”,可以用数字,也可以用文字来表述[3]。
具体针对论文摘要的学术规范,全国文献工作标准化技术委员会于1986年发布了GB6447—86文摘编写规则[4],其中规定文摘是以提供文献内容梗概为目的,不加评论和补充解释,简明、确切地记述文献重要内容的短文;文摘包含四大要素,分别为目的、方法、结果、结论。基于这一国家标准,很多学者对摘要的规范做了相应的研究。比较有代表性的有:高建群针对中文学术论文摘要的写作规范[5],其将摘要分为研究报告型,综述型,论证型,发现、发明型,计算型五大类,并分别探讨了相应摘要的写作格式,最终概括了摘要的写作总要求“忠实于原文、简洁明了、章法规范”;金丹通过分析《工程索引》(EI)对英文摘要的要求[6],从写作要求、时态、人称和语态、常用词汇等方面,总结了英文摘要写作的规范。她认为英文摘要的结构可以概括为IMARD(Introduction、Material and Methods、Result and Discussion),包括引言、材料与方法、结果和讨论部分。而利用数据挖掘技术对摘要学术规范做自动化监测的相关研究目前尚少。
论文摘要也可以通过计算机自动生成,目前主要有两种方式:一类是以TextRank算法为代表的抽取关键词句的方式[7];另一类则是借助于深度神经网络让计算机自动“造句”,最终生成摘要。由于后者在技术上还有一些关键性的难点有待突破,现在应用比较广泛的是第一种方式。但由于抽取式摘要生成主要是基于词频,并没有过多的语义信息,造成很多相关联的词汇都会被独立对待,以至于无法建立文本段落中完整的语义信息,生成的摘要可阅读性较差。因此借助于计算机自动生成符合学术规范的摘要信息目前还不成熟。
综上可以看出,目前学界关于学术规范及其评价研究的理论已经很充实,相关的模型框架也比较完备。但是在定量化的评价研究方面还有待深入。文章根据“全评价”理论框架,主要就其中的形式评价维度,尝试利用机器学习技术,结合卷积神经网络,以摘要的文本内容为研究对象(涉及到内容评价的一部分),初步构建了一个自动化智能检测模型,相较于传统论文评审方式,不但可以节省大量人力物力,结果亦更具准确性和客观性。
1 相关工作
卷积神经网络(Convolution Neural Network,CNN)自20世纪60年代由Hubel和Wiesel首次提出以后[8],由于当时缺乏训练数据和硬件设备性能不足的原因,一直没有引起足够的重视。2010年以后,像ImageNet这样的大规模标记数据的出现和GPU计算性能的快速提升,使得关于CNN的研究重新得到井喷式的发展。
CNN的应用早期主要在手写字符分类、图像分类领域,比较有代表性的CNN结构模型有Krizhevsky 2012年提出的AlexNet[9],该模型在ImageNet图像分类竞赛中以绝对优势夺冠。随后不断有新的CNN模型提出,比如牛津大学的VGG(Visual Geometry Group)、Google的 GoogleNet、微软的ResNet等,这些研究都使得CNN的性能在图像识别和分类的应用中不断得到提升。
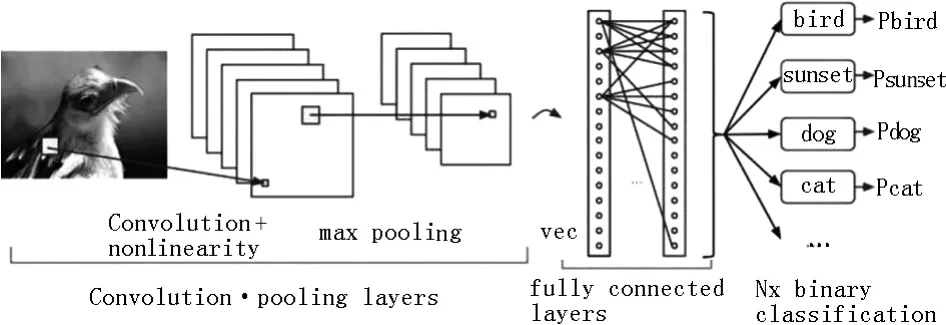
图1 CNN基本结构
近几年,CNN的应用正逐步向更深层次的人工智能发展,自然语言处理就是其中一个重要领域。较有代表性的,2014年Yoon Kim提出了一个经典的用于文本分类的单层CNN 模型[10]。
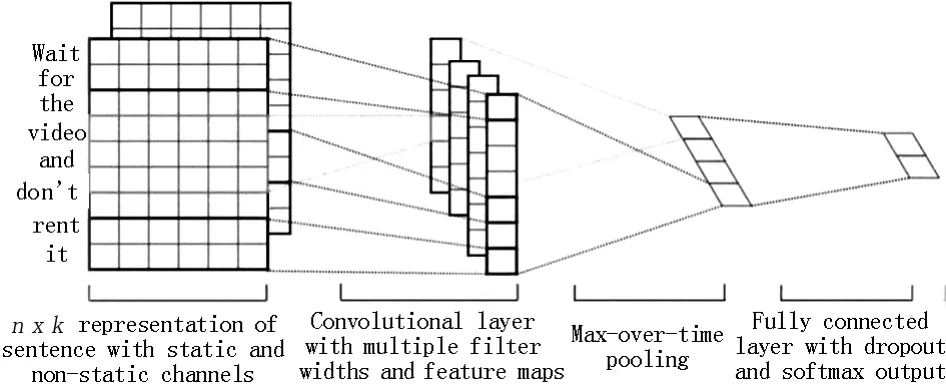
图2 Yoon Kim提出的CNN结构
该结构使用长度不同的过滤器对词向量进行卷积,过滤器的宽度等于词向量的长度,然后使用Max-polling池化层对每一个过滤器提取的向量进行操作,最后模型的预测都是基于这些拼接起来的过滤器。较经典的多层CNN模型为Nal Kalchbrenner 2014提出的Dynamic Convolutional Neural Network[11]。相较于前者,该模型更加复杂,多加入了一层用来实现“情感聚类”。
CNN作为一种特殊的神经网络,在自然语言处理过程中,它的局部关联特性能够对输入文本进行大量的特征提取,从而可以对输入对象进行精确的模拟;另外由于在卷积层中权重参数都是共享的,这就大大降低了模型的计算复杂度,与 N-Gram相比,运行速度更快。总体而言,CNN在自然语言处理中的性能表现是不错的。文章就是同时基于Yoon Kim的单层CNN结构和传统经典的CNN模型结构,试图将两者结合起来,对论文摘要建立学术规范评价模型。

图3 Nal Kalchbrenner提出的CNN结构
2 以摘要为对象的学术规范评价模型的构建
根据国家有关论文摘要的撰写规范,摘要通常应具有研究目的、研究方法、研究结果和结论的陈述。摘要撰写是否规范,专家通过阅读文本即能判断。如果要大规模的检测摘要撰写的规范程度,利用专家来阅读和判断的话,那很费时费力。如果能通过机器自动检测,则可以大大节省专家阅读和判断的时间和精力,且在某个方面可提高检测精度。
为了对论文摘要数据进行数据挖掘,首先要建立数据集。文章以中国知网(CNKI)为数据源,选定图书情报为检索学科,检索出了有结构化数据的摘要信息2 500余条(均为符合规范的完整摘要文本),经过导出和数据预处理操作,得到9 767条数据(同时包含规范和非规范的人造摘要文本),利用这些数据建立相应的训练数据集(Train set,7 867条)、校验数据集(Validate set,1 500条)、测试数据集(Test set,400条)和词汇表(Vocabulary set)。
2.1 源数据预处理
以中国知网为检索源,选取《图书情报工作》和《情报科学》期刊为文献来源,将检索出来的摘要中有“目的/意义”“方法/过程”“结果/结论”标识的论文下载下来,经过剔除一些会议通知等无关内容之后,将论文的摘要单独提取出来,共计2 500余条数据信息。
经过以下数据预处理操作:
将每一条摘要中的“目的/意义”“方法/过程”“结果/结论”分别提取出来,分别用A、B、C标识。
构造训练数据集、校验数据集、测试数据集和词汇表。其中数据集的结构主要包含三个部分:id、cotent和label,其中id为每条数据的唯一标识,content为文本内容,label验证结果(1为符合学术规范,2为缺少目的意义,3为缺少方法过程,4为缺少结果结论)。label的判定规则如下:如果content中同时包含A、B、C,则label为1;如果content中没有包含A,则label为2;如果content中没有包含B,则label为3;如果content中没有包含C,则label为4。(这里主要以期刊发表为准则,即基于以下事实:如果论文在期刊中发表,则默认该论文的摘要部分符合学术规范;对于个别有明显错误的摘要内容,辅之于人工标注)
将每一条摘要中的A、B、C分别排列组合,构造相应的训练数据(共计7 867条)。对训练数据进行数据清洗操作,包括清除无效数据、对空数据进行补全等。通过编写相应Python程序,构造好的数据集如下图所示:

图4 数据集图
2.2 模型的构建
首先采用传统的CNN模型(以下简写为模型1),完整结构如下图所示,包含输入层、3个卷积层、1个池化层、1个全连接层和输出层:其中模型的输入为词向量(Word embedding),输出为每一段文本对应的标签(即1、2、3、4,各自代表相应的含义)。由于模型的参数对结果的准确性影响很大,利用网格搜索经过反复调参,对模型作如下参数初始化:
模型词向量(Word embedding)维度设定为64,卷积核个数为8,卷积核大小为64,全连接层中神经元个数为64,初始权重矩阵随机选取符合正态分布的数值。池化层中采用Max Polling方式,输出层中激活函数采用修正线性单元(Rectified linear unit,ReLu)激活并采用SoftMax进行分类。准确率校验过程采用交叉熵测度(Cross Entropy),权重优化过程采用自适应矩估计优化器(Adam Optimizer)。另外,由于模型的数据量较小,为避免模型训练过程中发生过拟合,将Dropout比例设定为0.7,迭代次数为10。
类似的,利用Kim Y的单层CNN结构(见图2),对该模型(以下简写为模型2)参数做如下初始化操作:
模型词向量(Word embedding)维度设定为520,卷积核大小有三类,分别为3、4、5,每一类卷积核的个数均为128,初始权重矩阵随机选取符合正态分布的数值;池化层中采用Max Polling方式,输出层中激活函数采用修正线性单元(Rectified linear unit,ReLu)激活并采用SoftMax进行分类;准确率校验过程采用交叉熵测度(Cross Entropy),权重优化过程采用自适应矩估计优化器(Adam Optimizer);Dropout比例为0.5,迭代次数为200;L2 规范化参数为0。
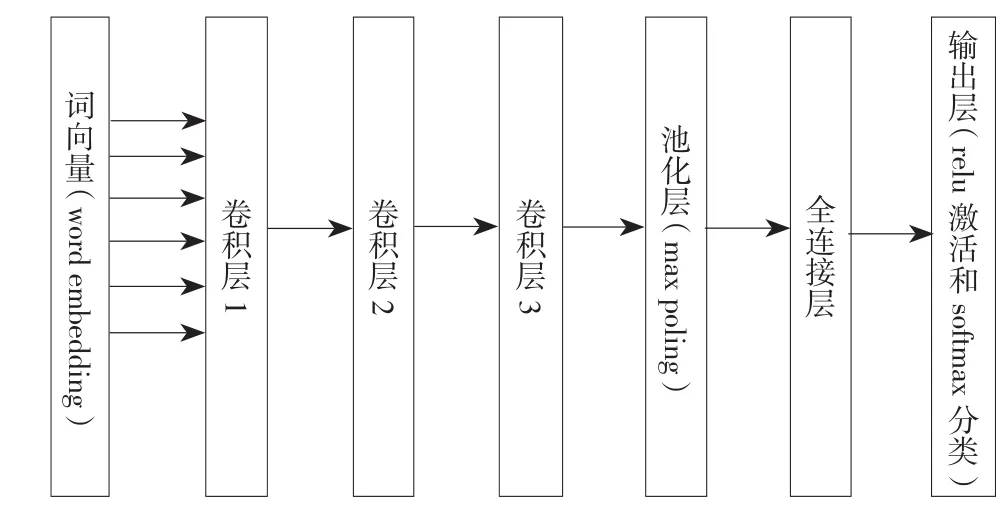
图5 CNN结构图
根据模型1和模型2的输出结果可以判断一段文本是否完整包含摘要结构的四要素,如果不包含的话,亦可指出文本具体缺少哪一个要素。
2.3 模型的评估和预测
利用TensorFlow和Sklearn框架,通过编写Python程序可以将上述两个模型很方便的实现出来。运行程序发现,模型1在测试集上的精确度为80.13%,模型2精确度为82.57%,基本达到了预期目标(大于80%)。
结合TensorFlow提供的TensorBoard分析工具,可以看到模型图(Graph)结构分别如下所示:
图6 模型1图结构(Graph)
图7 模型2图结构(Graph)
其中模型训练过程中的精度(accuracy)和损失率(loss)变化趋势图如下:
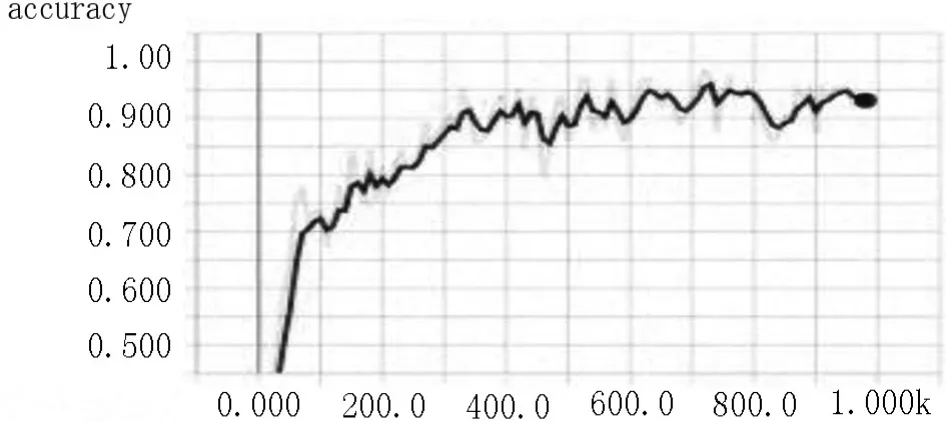
图8 模型1精度趋势图
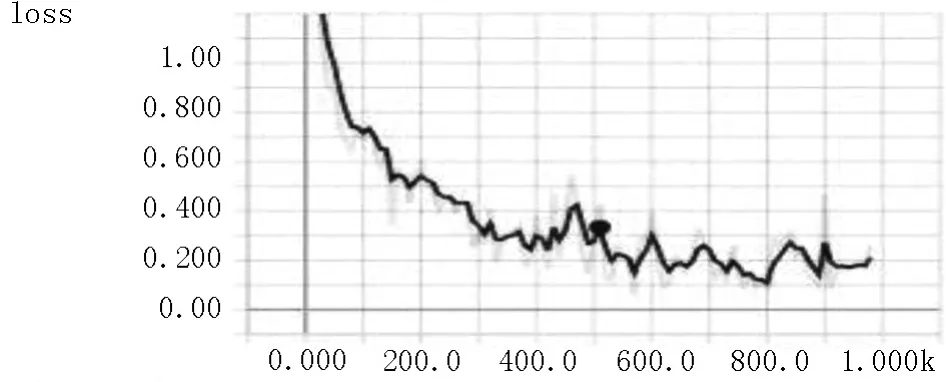
图9 模型1损失率趋势图
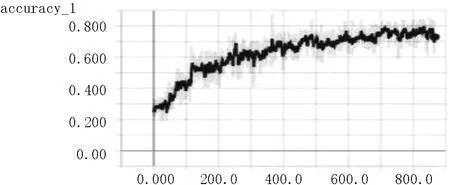
图10 模型2精度趋势图

图11 模型2损失率趋势图
进一步观察程序输出结果中的模型评估指标:

图12 模型1评估指标
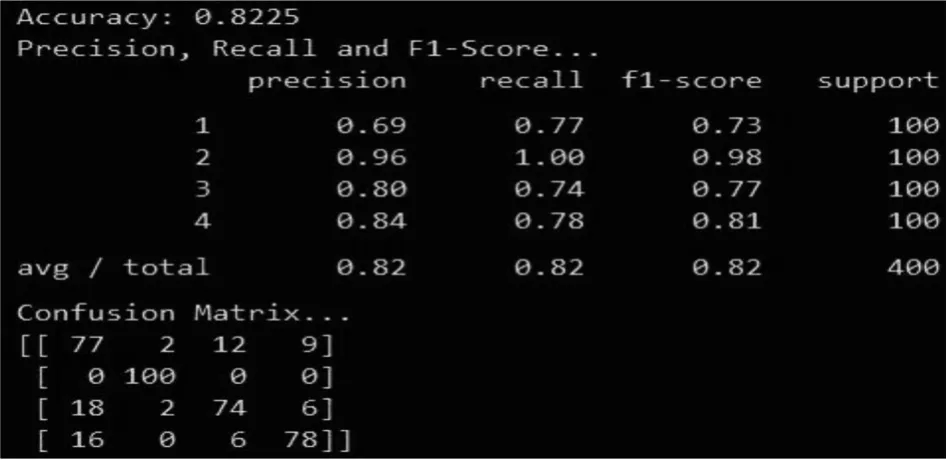
图13 模型2评估指标
可以看到模型1、2的查准率(Precision)和召回率(Recall)这两个指标均达到80%以上,由于两者是互斥的关系,80%的结果基本符合预期。
综合利用上面两个预测模型,对模型1、2的输出结果求平均值,以该值作为我们最终模型的最终结果。观察最终模型的评价指标如下:
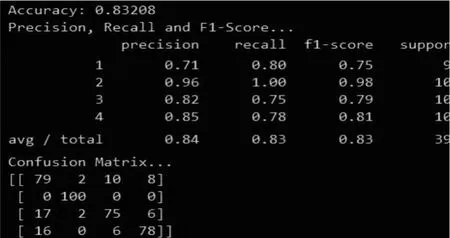
图14 最终模型的评估指标
可以看到最终模型的各项指标都要高于单个模型(模型1、2)。其中精确达到83.20%,查准率和召回率分别为84%和83%。
3 总结和进一步优化
文章基于数据挖掘技术初步构建了一个以论文摘要为研究对象的学术规范检测模型,准确率总体达到了83%+,虽然还没有符合产品级的高精度(95%+)要求,但其证明通过利用机器学习的相关技术实现论文学术规范的智能化检测是可行的。概括起来,该模型相较于传统学术规范评审方式有以下几方面优势:
评审效率高,节省大量人力成本。上述模型除了在训练阶段耗费较长时间(模型1为11分钟,模型2为28分钟),在应用阶段对400条样本的预测仅耗时5秒,效率得到大幅度提升;并且模型只需初始训练一次即可,后续阶段无需再次训练。
结果更具有客观性和统一性。传统的人工评审方式主观性较大,可能会出现错误, 甚至不同的专家之间也可能得出不同的结论。而利用机器学习的技术手段评审,就可以避免主观性的误判,提高评审的准确率。
有利于论文的学术规范标准化。由于论文是由计算机评审,省去人工评审繁琐的工作,从而可以把精力主要放在论文内容的学术规范的评定上。标准作为模型训练阶段的一个基石,标准统一了,评审结果也就更具有一致性。
为了进一步提高模型的准确率,对上述CNN模型的进一步优化,后续工作可以考虑从以下几方面展开:
数据集数量规模较小。模型训练数据集总量共计7300余条,这对于构建一个高精度的神经网络而言,是远远不够的,一般来说,数据集的量级最好在万以上。CNN模型结构过于简单。模型1目前仅包含三个卷积层和一个池化层,可以考虑引入多个卷积层和多个池化层以提高精度,比如采用LeNet模型等。词向量的构建目前采用的Id标识(即每个字唯一对应于词汇表中的相应Id),这样不能从语义上对词义相近的字进行区分,优化过程中可以考虑采用Word2vec或Tf-Idf的方法。模型的初始权重矩阵目前为随机矩阵,可以考虑采用Xavier初始化方法[12],防止梯度消减和梯度爆炸,从而提高模型的稳定性。
(来稿时间:2018年10月)
