显隐信息协同的多视角极限学习模糊系统*
2019-04-18邓赵红王士同
张 特,邓赵红,王士同
江南大学 数字媒体学院,江苏 无锡 214122
1 引言
多视角学习是关注由多个不同特征集来表述数据对象的机器学习问题。该学习机制的出现很大程度上是由于越来越多的真实数据是由不同特征集,或者说不同“视角”,来描述的。例如在食品发酵过程中,可从风速和搅拌速度两个角度来记录食品的发酵指标参数[1]。又比如在基于内容的网页图像搜索中,目标可以同时由来自图像的可视化特征及描述图画的文本特征组成[2]。因此,多视角学习是很有前景的研究领域并且具有广泛的实际应用[1,3-7]。
目前已有的多视角技术主要包含如下3类:
(1)多视角分类技术:Farquhar等人将核典型分量分析(kernel canonical component analysis,KCCA)与支持向量机(support vector machine,SVM)相结合提出了SVM-2K算法[7];Chen和Sun提出了多视角Fisher判别分析[8];Li等人基于直推式SVM,通过引入全局约束变量提出了多视角半监督SVM算法[5];Sun将流行正则化、多视角正则化与传统形式的SVM算法进行整合,提出了多视角拉普拉斯SVM[6]。
(2)多视角聚类技术:Pedrycz在模糊C均值(fuzzy C-means,FCM)中采用了协同聚类的思想,通过对各视角间的模糊划分进行控制,构造了基于划分协同控制的Co-FCM算法[9];Cleuziou等人基于文献[9]的协同思想,同样以经典FCM算法作为基础模型,进一步提出了两种不同的多视角协同划分方法并依此构造了全新的多视角模糊聚类算法Co-FKM[3];Tzortzis等人在核聚类领域内分别基于核k-means算法及谱聚类算法提出了两种多视角聚类算法多视角核k均值(multi-view kernel k-means,MVKKM)和多视角谱聚类(multi-view spectral clustering,MVSpec)[10];Yamanishi等人从概率的角度基于期望最大化(expectation maximization,EM)提出了可用于解决多视角问题的协同聚类算法Co-EM算法[11];Chaudhuri等人针对高维数据的特点,提出了将高维数据投影到低维空间,然后利用多视角聚类技术对低维数据进行分析得到一个全局划分结果[12]。
(3)多视角回归技术:Kakade等人提出的基于典型相关性分析的多视角回归[13]。
近年来,模糊集理论和模糊系统作为智能计算领域重要的研究分支,由于其独特的可解释性以及强大的学习能力,在多视角学习领域有一些成功的应用。在多视角模糊聚类方面,Jiang等人[14]通过引入惩罚因子,基于经典FCM算法,提出了多视角加权的协同模糊聚类算法;Wang等人[15]在经典FCM算法的基础上,引入极小极大优化,提出了多视角MinimaxFCM算法。在多视角模糊分类方面,Jiang等人[16]基于经典TSK型模糊系统(Takagi-Sugeno-Kang fuzzy system,TSK-FS),将最大间距化策略引入其目标函数,采用协同学习的方式整合来自不同视角的特征,提出了具有视角协同学习能力的两视角TSK型模糊系统,在不同应用上得到了较好的表现。特别地,针对癫痫EEG信号识别,Jiang等人提出了一种多视角模糊系统构建方法,取得了较好的癫痫检测效果[17]。
较之于其他多视角智能分类方法,目前已有的基于模糊系统的多视角分类方法在解释性和不确定性建模能力方面均有一定的优势。但是,在多视角信息的协作和利用方面,目前的方法还有待进一步加强。例如,已有的方法主要关注的是多个显性视角的信息,而对于多个高度相关的视角间的隐藏的共性信息还未能充分挖掘和利用。此类隐性信息对多视角学习是非常重要的。例如,各显性视角之间通常隐藏了一个共享的隐空间,该隐空间内的共享数据可以通过不同的映射方式生成不同显性视角的数据。因此,如果能充分挖掘多个显性视角对应的共享隐性视角,对多视角学习将具有很大的帮助。根据上述分析可知,已有的多视角模糊分类方法还未能充分利用各视角间共享的隐空间信息,从而导致受训模型的鲁棒性受到限制。
针对上述挑战,本文提出了一种引入各视角间共享隐空间信息的显隐视角协同的模糊系统建模方法来实现多视角分类任务。岭回归极限学习模糊系统(ridge regression extreme learning fuzzy system,RR-EL-FS)[18]是引入了极限学习机制的0阶TSK型模糊系统,具有训练速度快,在小样本噪音数据集上鲁棒性强的特点。本文以岭回归极限学习模糊系统作为具体研究对象来构建多视角模糊系统分类方法。该方法首先通过矩阵分解技术来学习得到各显性视角的共享隐空间,此隐空间即为得到的隐性视角;在此基础上,进行显性视角和隐性视角的协同学习来辅助模糊系统的构建;最终,可得到显隐视角协同决策的多视角模糊系统预测模型。该方法较之已有的多视角模糊系统预测方法和其他相关方法能有效地基于隐空间的共享信息实现显隐空间的协作,从而能更好地提升所得预测模型的泛化性能。
本文主要贡献可归纳为如下几方面:
(1)基于非负矩阵分解技术,提出了一种获取多视角数据集各显性视角间共享的隐空间信息的方法。
(2)提出了显隐信息协同学习的多视角模糊系统建模框架,并基于该框架,以岭回归极限学习模糊系统为基模型,提出了显隐信息协同的多视角岭回归极限学习模糊系统。
(3)对所提出的显隐信息协同的多视角岭回归极限学习模糊系统进行了广泛的实验分析。
本文剩余部分组织如下:第2章对经典Takagi-Sugeno-Kang型模糊系统、岭回归极限学习模糊系统以及多视角学习进行了简述;第3章首先提出了基于各视角信息学习共享隐空间信息的策略和求解方法,而后详细描述了显隐信息协同的岭回归极限学习模糊系统建模方法;第4章进行了广泛的实验比较与分析;第5章对本文进行了总结和展望。
2 相关工作
2.1 经典Takagi-Sugeno-Kang型模糊系统
经典模糊系统模型可分为以下3类:TSK型模型[19]、Mamdani-Larsen(ML)型模型[20]及广义模糊模型(generalized fuzzy model,GFM)[21]。其中,TSK型模型应用最为广泛[19]。
TSK型模糊系统是基于规则和模糊集的智能系统,具有良好的解释性和不确定建模能力。经典TSK模糊系统的模糊规则如下:
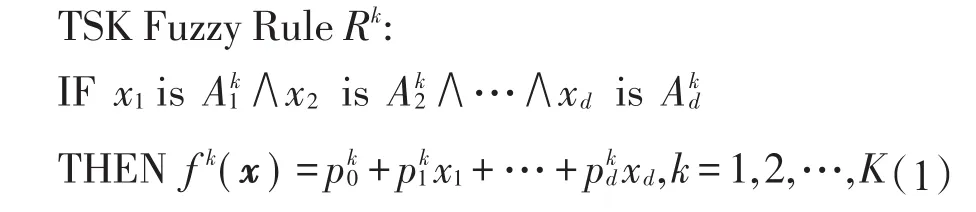

当TSK型模糊系统采用乘合取算子、乘蕴含算子、加法组合算子和重心反模糊化操作时,其最终输出可表示为:

2.2 岭回归极限学习模糊系统
RR-EL-FS是引入了极限学习机制的0阶TSK模糊系统[18,22]。其通过随机为二维二值规则结合矩阵C以及三维二值无关特征矩阵DC赋值的方式完成ifthen规则的生成,而后通过岭回归的方式对后件参数进行优化。算法细节如下。
2.2.1 岭回归极限学习模糊系统的前件生成
RR-EL-FS采用高斯函数作为隶属度函数,输入向量的每一维特征都会被划分进5个模糊子集这5个模糊子集对应的高斯隶属度函数中心被固定为[0,0.25,0.50,0.75,1.00],对应的自然语义标签为非常低、低、中、高以及非常高[24]。

其中,k=1,2,…,5,i=1,2,…,d,ak∈{0,0.25,0.50,0.75,1.00},μki为特征xi对第k个模糊子集的隶属度。式(4)中高斯隶属度函数对应的标准差σ通过随机赋值所得。
与极限学习机所采用的随机机制相同,RR-ELFS通过随机为规则结合矩阵C(维度为d特征×5隶属度函数×L规则,其中d为输入样本的特征数,5表示5个隶属度函数,L为规则数)以及无关特征矩阵DC(维度为d特征×L规则)的方式来决定每条规则使用的特征及所用特征相应的隶属度函数。例如,若规则结合矩阵中C(2,3,4)=1则表示特征2对应式(4)中在规则4中被激活。若D(2,4)=1则表示特征2在规则4中是无关(不被使用)的。给定两个输入样本(x1和x2),每个输入样本包含5个特征,若第k条规则所对应的矩阵C及矩阵DC如下:给定输入向量x=(x1x2…xd),其每一维特征对应的模糊隶属度可由下式计算:

则第k条规则可表示为:
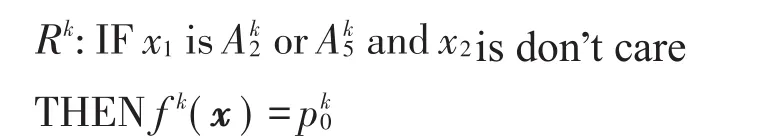
2.2.2 岭回归极限学习模糊系统的后件生成
RR-EL-FS的最终输出为:

其中,L表示规则数,pl0为第l条规则对应的后件参数,ul表示第l条规则的触发强度,其计算如下:
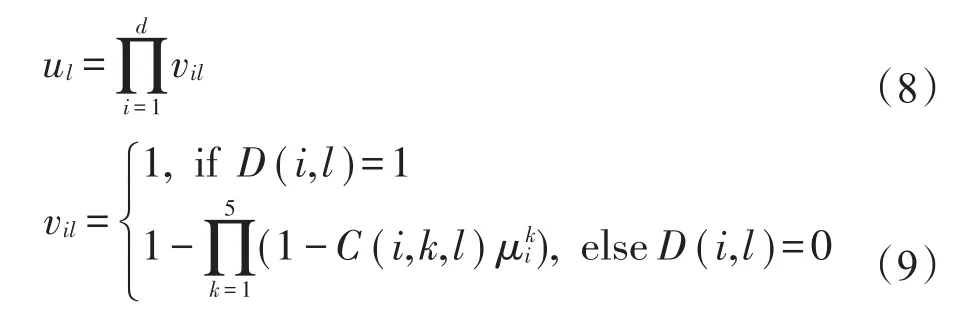
令:

则式(7)可写为:

RR-EL-FS采用岭回归的方式对后件参数pg进行求解。给定N个训练样本(xn,yn)∈Rd×R,将所有训练样本对应的触发强度结合成矩阵,即:
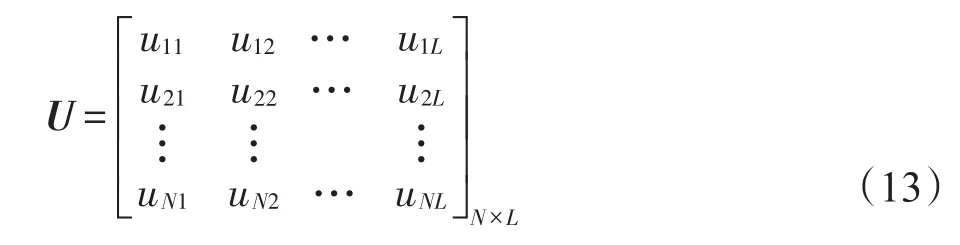
则求解后件参数的目标公式可表示如下:
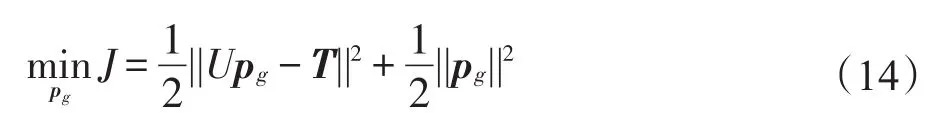

式(15)中,Id为d×d的单位矩阵。
2.3 多视角学习
2.3.1 传统多视角学习框架
多视角学习技术旨在通过对同一对象的不同特征集合(即各视角)所构造的数据样本进行分析,并利用各视角间的协同找出视角间的相关性,进而得到一个最合理的全局决策结果。由于多视角技术全面地考虑了被研究对象在各个视角下所存在的特征信息,因而在求同存异的指导思想下所得到的决策结果,要比在仅基于单一视角特征空间所得到的决策结果更为全面可靠。一个经典的多视角学习框架的原理如图1所示。
2.3.2 基于单视角模糊系统建模的多视角建模
传统的模糊系统建模技术均是针对单视角场景设计。当面对多视角建模场景时,通常采用的策略是针对不同的视角仅利用单个视角下的样本构建与之对应的单视角模糊系统,然后对各系统决策结果进行简单集成,例如求取各视角输出的均值作为最终的数据结果。相关流程如图2所示。
上述策略为单视角建模方法在多视角场景下的应用提供了一种可行的方案。由于其针对每一视角独立建模的方式在一定程度上破坏了多视角数据集之间的关联关系,这通常会造成不同视角所获得之模糊系统泛化能力存在良莠不齐的现象。目前,针对这一问题,已有学者提出了相关的改进算法。例如,Jiang等人将最大间隔化的思想与协同学习相结合,提出了一种2视角模糊系统的建模方法,该建模方法相对传统单视角模糊系统在面对2视角数据时具有较明显的优势[16]。此外,在文献[17]中,提出了一种可以处理多视角数据的癫痫EEG识别模糊系统分类方法。

Fig.1 Classical multi-view learning framework图1 一种经典的多视角学习框架图

Fig.2 Framework of multi-view modeling using single-view fuzzy system图2 基于单视角模糊系统的多视角建模框架
虽然已有的多视角模糊系统建模方法在分类等方面体现了较之于单视角模糊系统方法的优越性,但多视角学习方面还存在许多不足。其中一个重要的挑战就是多视角数据的共性隐信息未能充分挖掘,进而未能基于共性隐信息和各显视角信息进行全面的学习。因而探讨显隐信息协同的多视角模糊系统建模方法很有必要。
3 显隐信息协同的多视角岭回归极限学习模糊系统建模
由于岭回归极限学习模糊系统(RR-EL-FS)具有训练速度快,对噪音数据集鲁棒性较强的特点,本文以岭回归极限学习模糊系统为基础模型,提出具有多视角学习能力的岭回归极限学习模糊系统。
3.1 显隐信息协同的多视角岭回归极限学习模糊系统建模框架
为了充分利用各视角间的共享隐空间信息,同时使得单视角岭回归极限学习模糊系统建模方法具备多视角学习的能力,本文探讨了显隐信息协同的多视角岭回归极限学习模糊系统建模方法(ridge regression extreme learning fuzzy system with cooperation between visible and hidden views,RR-EL-FS-CVH)。RR-EL-FS-CVH的总体框架如图3所示。
从图3可知,该建模方法较之传统单视角和已有的多视角模糊建模方法而言,具有如下特点:(1)充分利用了各个视角间共享的隐空间信息;(2)不再将各视角下的数据样本孤立开来进行独立的模糊系统构建,而是通过多视角协同机制来训练不同视角下的模糊系统;(3)不仅各显性视角可以协作,显性视角和隐性视角也进行了协作,因而通过多个视角的有效协作,最终所获得的各视角的模糊系统泛化能力得到提升。
3.2 共享隐空间的生成
3.2.1 隐空间特征提取机制
对于多视角数据集,一个合理的假设是:所有视角间存在一个共享的隐空间,基于该隐空间数据可以通过不同的映射把共享空间特征映射到不同视角所在的空间生成不同视角的数据。因此,找到该隐空间对于获得多视角数据的共性信息来辅助面临的多视角建模任务是很有意义的。给定拥有K个视角,N个样本的多视角数据集X,第K个视角对应的数据集合可表示为,第k个视角的数据可用矩阵形式表示为为了获取各视角共享的隐空间,以及该隐空间到各个视角的映射矩阵,通常可构造如下的优化目标[25]:对于式(16),说明如下:
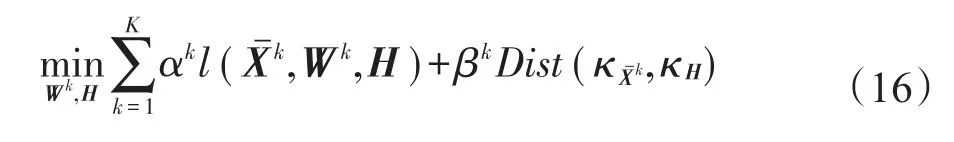
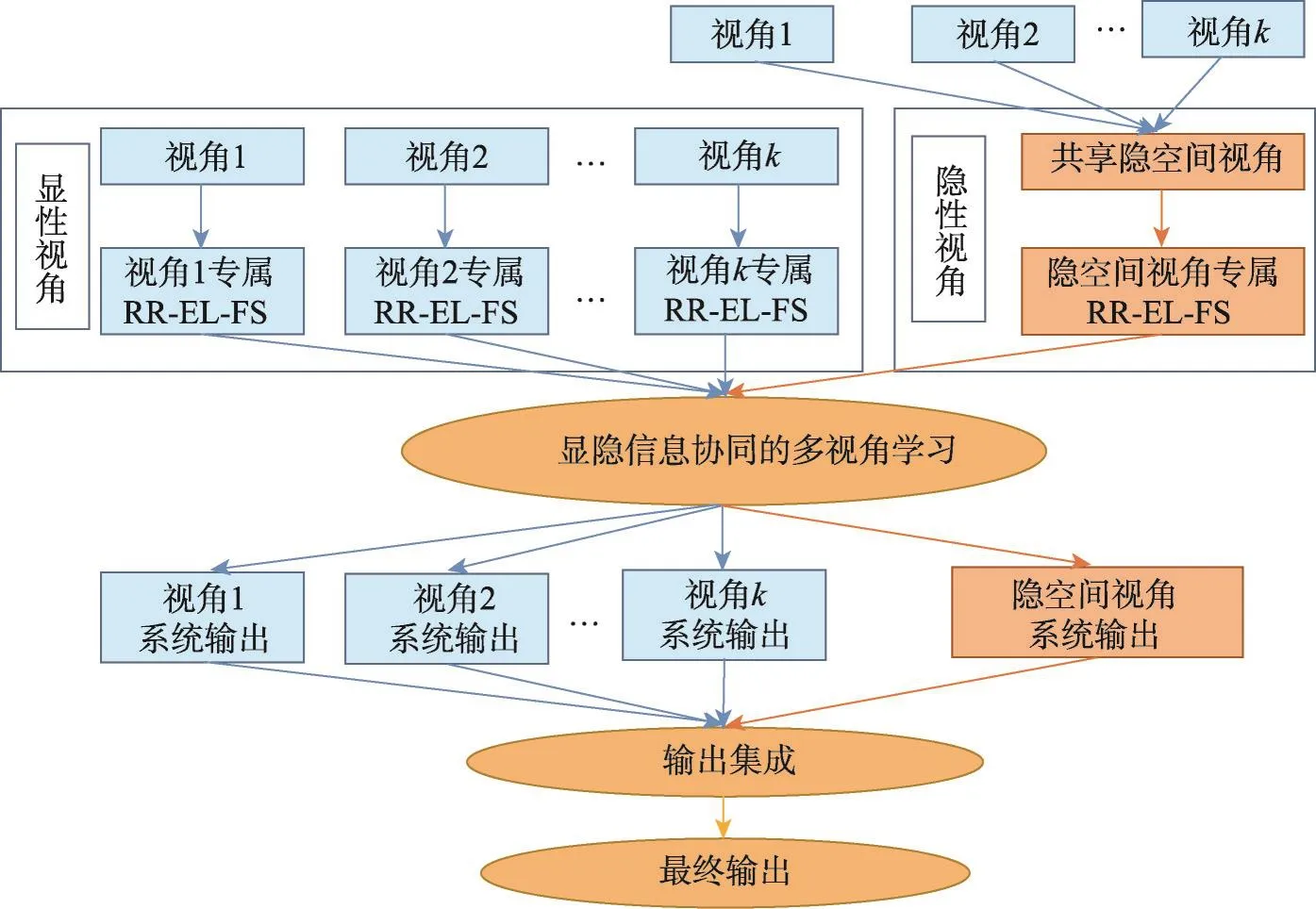
Fig.3 Framework of RR-EL-FS-CVH图3 显隐信息协同的多视角岭回归极限学习模糊系统框架
(1)式中Wk∈Rr×dk表示将隐空间数据映射到视角k所在特征空间的映射矩阵(dk为视角k特征空间的维度;r为隐空间的特征维度,1≤r≤min{d1,d2,…,dk});数据集H=[h1,h2,…,hN]T∈ RN×r为各视角数据在共享隐空间对应的共享数据的矩阵表示;αk表示视角k的所占权重,且。

其中,||∙||F为Frobenius范数;为使模型简单且具有较高解释性,常引入对Wk以及H的非负约束。

其中,Lk=Dk-Sk为拉普拉斯矩阵。
结合式(17)及式(18),对于式(16)可得如下最小化问题:
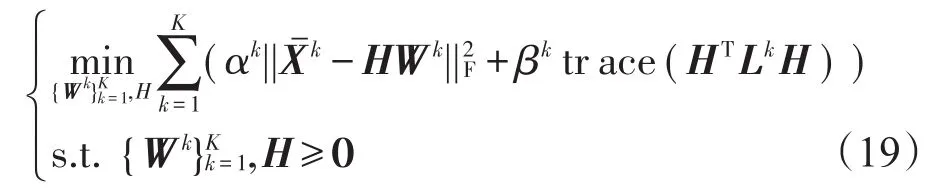
通过求解该问题,可以获得各显性视角在隐空间的共享数据H以及共享隐空间到各个显性视角的映射矩阵Wk。
3.2.2 隐空间及映射矩阵的求解
式(19)对应的优化问题本质上是个非负矩阵分解(non-negative matrix factorization,NMF)问题,一种常用的求解方法是利用坐标下降方法进行迭代求解[26]。基于迭代优化的思想,式(19)的迭代求解可分如下两步:固定H求解映射矩阵Wk,而后固定Wk求解H。具体方式如下。
(1)计算映射矩阵Wk
当固定H=H((t)t为当前迭代次数)时,式(19)中,仅将Wk作为变量的子优化问题为:
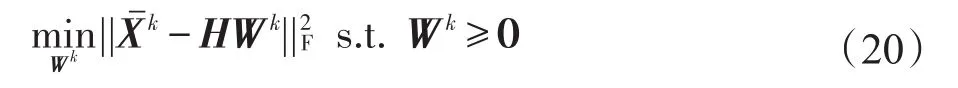
该非负二次规划问题形式与传统NMF模型相同。因此,Wk可采用NMF的经典方法求解。例如,基于文献[26]的求解策略,可得如下的更新公式:

(2)计算隐空间H

可以得到H如下的更新公式[26]:
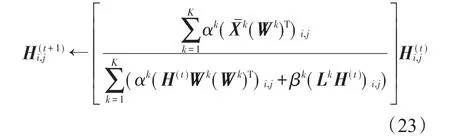
3.3 具备显隐视角协同学习能力的目标函数构建
给定如3.2.1节所述多视角数据集,为了充分利用各视角间共享隐空间特征,首先采用3.2节所示方法提取出各视角间共享的隐空间对应的共享数据集其矩阵形式为 H=[h1,h2,…,hN]T∈ RN×r。然后,将所提取出的隐空间特征作为一个全新的视角加入到原始多视角数据集中得到最终用于系统训练的多视角数据集,此时新数据集共有k+1个视角,即k个显性视角和1个隐性视角。在得到加入隐空间信息的数据集后,为充分利用不同视角的特有特征,以及利用各视角特征间内在的关联关系,本文采用协同学习的方式进行模糊系统的构建。
若视角k的专属岭回归极限学习模糊系统具有Lk条规则,隐空间视角的专属岭回归极限学习模糊系统具有J条规则,参考2.1节及2.2节,则第k个显性视角对应的模糊系统在其规则生成的高维空间对应的线性模型可表示如下:

第k+1视角,即隐性视角专有岭回归极限学习模糊系统对应的高维空间的线性模型为:

基于上述变换和表达,本文设计的具备多视角协同学习能力的岭回归极限学习模糊系统优化目标函数式如下:

式(26)中,yi为第i个样本的类标签,为2.2节所述岭回归极限学习模糊系统通过视角k训练所得专有模糊系统的后件参数,wk为其对应的权值。为协同项,(为了表示方便,这里)。为所有视角(包括隐空间视角)的权重对应的负香农熵,为正则化项。
对于式(26)的优化目标函数可进一步解释如下:
(2)仅仅考虑各视角间样本的数据对于整个多视角岭回归极限学习模糊系统的构建是不够的,因此,考虑到视角间的关联关系,所提方法构造了具备协同学习能力的协同项,即式(26)中的。上述协同项可使各视角(包括隐空间视角)间进行协同学习,最终达到各视角所对应的模糊系统之输出趋于一致,从而避免因视角特征的差异而造成各视角模糊系统泛化性能的剧烈变化。
(3)许多已有的多视角方法在最终组合各视角结果进行决策时,如何决定各视角的重要性具有一定的主观性,例如采用取均值的方式或人为给定权重。针对此,本文方法通过引入香农熵来实现各视角权重的自适应调节和控制。令,可将权值视为概率分布,其对应的香农熵即为,熵的极大化使得各概率分量尽可能均等,即引入了极大熵理论。此项的引入,可以避免对式(14)的第一、二项进行优化时,某个视角的权重占绝对优势而造成其他视角的信息被完全忽视。由于式(14)为最小化目标函数,因此,极大化香农熵在式中形式为最小化负熵,即最小化。
(4)式(26)中正则化参数λ1>0,λ2>0,λ3>0用于控制模型中各项的影响,其数值可通过交叉验证等策略选取合适的值。
3.4 参数学习规则
采用迭代优化方法,对式(26)中的专有模糊系统后件参数及对应权值可进行迭代学习,更新公式如下:


给定具有K个视角特征的测试样本x,系统最终的输出为:

4 实验结果与分析
4.1 实验设置
为对本文所提显隐信息协同的岭回归极限学习模糊系统(RR-EL-FS-CVH)建模方法的性能进行验证和评估,本节基于分类任务,首先将所提算法与单视角算法在人工构造的以及真实的多视角数据集上进行了实验研究;而后又将所提算法在相同数据集上与几种多视角算法进行了对比。数据集详细信息将于4.1.1节中描述,算法细节及实验硬件平台将在
4.1.2 节中描述。实验中所有分类数据集的输入部分均进行了归一化处理。实验指标为分类准确率,分类准确率越高,表示算法泛化性能越好。实验采用五倍交叉验证的方式将数据集划分为训练集和测试集,具体地,通过分层采样的方式将原始数据均分成五组,将每个子集数据分别做一次验证集,其余的四组子集数据作为训练集。以五次在测试集上所得分类准确率的平均值作为最终的指标对算法性能进行评估。
4.1.1 数据集描述
本文所用人工构造数据集及真实多视角数据集均来自UCI数据集库[28]。其中,人工构造的数据集本身并非多视角数据集,但其特征可以人为划分为多视角数据,因此在本文中,这类数据集被称为人工构造的多视角数据集。
本文所采用的人工构造数据集为Iris数据集以及Forest type数据集,所采用的真实数据集为Multiple feature数据集、Image segmentation数据集以及Dermatology数据集。各数据集细节如表1所示。
4.1.2 对比算法及实验硬件平台
本文将RR-EL-FS-CVH算法分别与5个单视角模糊系统算法和2个多视角算法进行了比较。5个单视角模糊系统算法分别为将模糊规则嵌入到极限学习机隐层节点的模糊极限学习机(fuzzy extreme learning machine,F-ELM)[22]、基于 IQP(iterative quadratic programming)优化算法的ε-不敏感损失函数的TSK模糊系统(IQP)[29]、基于LSSLI(learning by solving a system of linear inequalities)优化算法的ε-不敏感损失函数的TSK模糊系统(LSSLI)[29]、MATLAB工具箱中基于模糊C均值算法的模糊系统GENFIS(generate fuzzy inference system)[30]以及基于模糊子空间聚类的O阶L2型TSK模糊系统(fuzzy subspace clustering based zero-order L2-norm TSK fuzzy system,L2-TSKFS)[31]。多视角模糊系统算法为引入最大间距化策略和协同学习思想的两视角TSK模糊系统(two view TSK fuzzy classification system,TwoV-TSK-FCS)[16],多视角非模糊系统算法为引入了极大熵的多视角极大熵判别算法(alternative multiview maximum entropy discrimination,AMVMED)[32]。这 7 种对比算法中,TwoV-TSK-FCS以及AMVMED算法为二分类算法,对于多类分类,本文对于二分类算法采用1对1策略来实现多分类问题。
实验平台,CPU,Intel®CoreTMi7-4790;主频,3.60 GHz;内存,16 GB;操作系统,Win 7 64位操作系统;编程环境,MATLAB 8.1.0.604(R2013a)。
4.2 与单视角算法对比实验
本节将所提RR-EL-FS-CVH算法与几种经典单视角模糊系统算法进行了对比。对于单视角算法,本文将多视角数据集所有视角特征合并为一个全视角数据集,然后将单视角算法用于该全视角数据集。所有单视角模糊系统算法规则数以及RR-EL-FSCVH中任一视角专有模糊系统的规则数的寻优范围均设定为k={3,4,9,16,25,36,49。}RR-EL-FS-CVH算法与单视角模糊系统算法在各数据集上所得分类准确率见表2。

Table 1 Description of multi-view datasets表1 多视角数据集描述
表2中最优值次数指标是指在所有数据集中该算法所得指标为各算法中最优值的次数。观察表2可得如下结论:(1)RR-EL-FS-CVH算法所得分类精度在所有数据集上均高于单视角模糊系统算法,这也说明RR-EL-FS-CVH算法相对于单视角模糊系统算法具有更好的分类性能。(2)从在多个数据集上的平均精度来看,RR-EL-FS-CVH算法的平均精度相对于几种单视角算法优势非常明显。

Table 2 Comparison between this paper and single-view fuzzy systems(Mean±Std)表2 本文算法与单视角模糊系统算法比较(均值±方差)
4.3 与多视角算法对比实验
为进一步对所提算法的性能进行评价,本文将所提算法与两相关多视角算法进行了对比。同时,采用对单视角算法输出值进行加权整合的方式,把几种单视角算法改造为相应的多视角算法。具体改造过程为:针对每一个视角的特征,训练出一个单视角分类器,而后对每一视角的输出值进行加权求和得到算法的最终输出(如有K个视角,则每个视角的分类器权值为1 K)。为与单视角算法做出区分,本文将基于F-ELM、IQP、LESSLI、GENFIS2以及L2-TSK-FS改造得到的多视角算法分别称为F-ELM(MV)、IQP(MV)、LESSLI(MV)、GENFIS2(MV)以及L2-TSK-FS(MV)。同样,为保持模糊系统的简洁性,所有模糊系统的规则数寻优范围被设定为k={3,4,9,16,25,36,49}。RR-EL-FS-CVH算法与多视角算法在各数据集上的分类准确率如表3~表7所示。
观察表3至表7可得到如下结论:(1)对于这些得到的各视角模糊系统,无论是从独立的单一视角看,还是从不同视角之间系统的泛化性能关联关系角度分析,本文所提RR-EL-FS-CVH算法在大多数数据集上得到了最高的分类精度,说明所提方法具有较好的分类性能。(2)本文所提算法各视角集成后所得分类精度均大于仅使用单一视角数据的分类精度,说明所提算法不仅能充分利用单一视角的数据,还能通过协同学习的方式充分利用各视角数据之间有效的相关信息,提升分类性能。(3)部分单视角简单集成后的多视角算法,在某些数据集上采用各视角集成后所得分类精度反而不如只用单一视角数据所得分类精度,如IQP算法在Dermatology数据集上,仅使用组织病理学视角特征时,可以达到0.827 4的分类精度,而引入临床视角特征后所得全视角精度为0.753 1,这说明简单的多个视角集成不一定能提升模型的性能,有时可能会起到负作用。
5 结束语
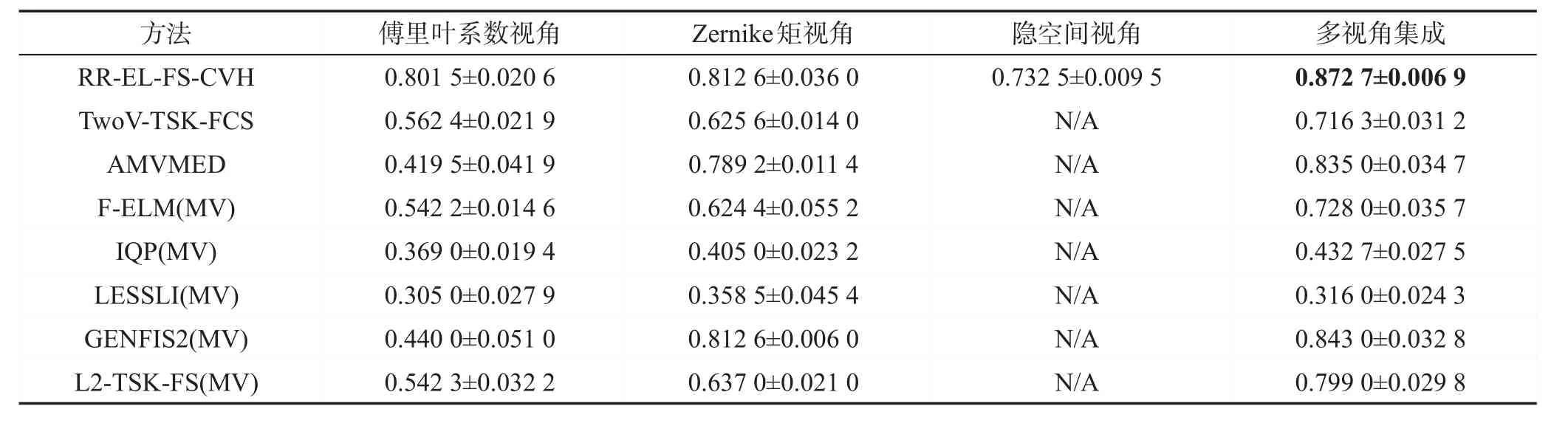
Table 3 Classification accuracies on multiple feature dataset(Mean±Std)表3 在Multiple feature数据集上的分类准确率(均值±方差)
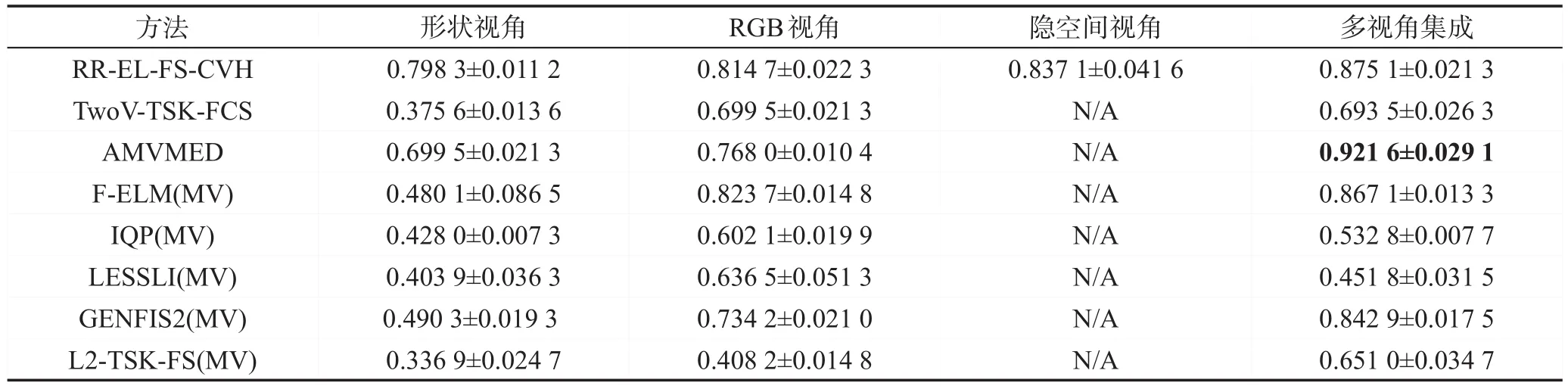
Table 4 Classification accuracies on Image segmentation dataset(Mean±Std)表4 在Image segmentation数据集上的分类准确率(均值±方差)

Table 5 Classification accuracies on Dermatology dataset(Mean±Std)表5 在Dermatology数据集上的分类准确率(均值±方差)
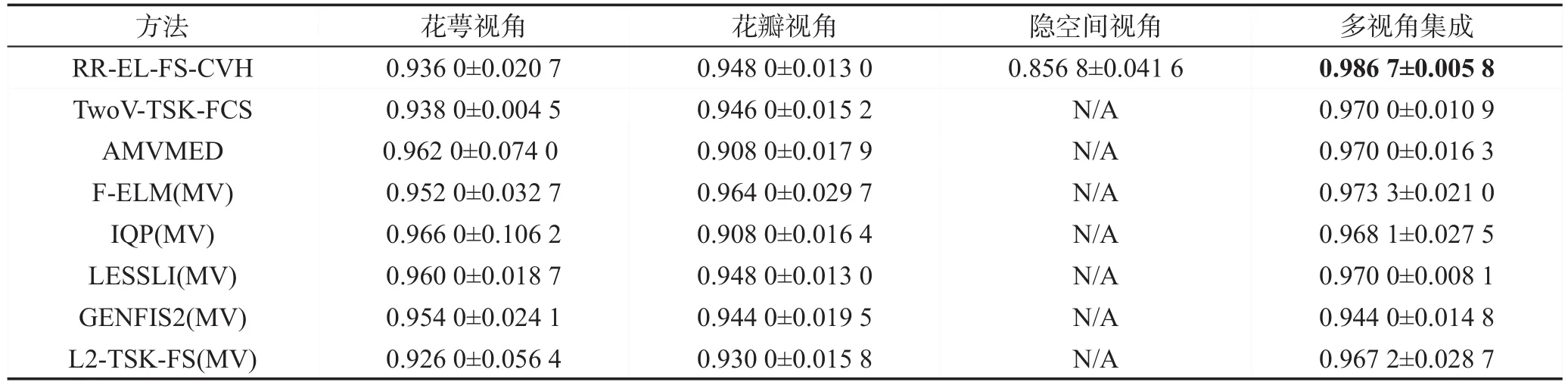
Table 6 Classification accuracies on Iris dataset(Mean±Std)表6 在Iris数据集上的分类准确率(均值±方差)

Table 7 Classification accuracies on Forest type dataset(Mean±Std)表7 在Forest type数据集上分类准确率比较(均值±方差)
本文针对传统的模糊系统建模方法在处理多视角场景仅利用到了多视角数据集的显性信息,而忽略了各视角间共享的隐空间信息之不足,提出了显隐信息协同学习的多视角岭回归极限学习模糊系统。该方法不仅能充分利用多视角数据集的显性信息,同时能充分利用各视角间共享的隐空间信息,进而提高各视角下模糊系统的泛化能力并通过协同学习机制进一步稳定各视角模糊系统的性能。在构造数据集以及真实数据集上的仿真实验结果表明:本文所提方法比传统的单视角建模方法以及仅利用多视角数据集显性信息的多视角算法具有更好的泛化能力。
尽管本文所提算法表现出了较好的分类性能,但仍有需要进一步研究的地方。例如,本文所提算法利用交叉验证策略对超参数进行优化会带来较大的时间开销,如何有效地降低参数寻优的时间复杂度将是进一步研究的重点工作之一。
