改进的差分搜索算法的医学图像配准*
2019-04-18邵党国祝晓红
桂 鹏,邵党国,祝晓红,相 艳,王 硕,马 磊
昆明理工大学 信息工程与自动化学院,昆明 650504
1 引言
图像配准是通过一种或一系列的空间变换,使得两幅或多幅图像的特征点或对应点在空间上达到一致,这种一致指的是匹配图像的位置一致、角度一致、大小一致[1]。在医学图像配准上可以理解为,人体上的同一解剖点在两张匹配图像上有相同的空间位置。医学图像配准作为图像处理的一项关键技术,在临床诊断和手术治疗等实际应用中具有重要意义。Viergever等人比较了近20年来医学图像配准方法的差异,并得出近20年医学图像配准的主流算法并没有特别大的改变,大多数经典的方法现今仍旧适用[2]。当前,医学图像配准的两类主要方法有基于灰度的方法和基于特征的方法[3]。其中,基于灰度的配准算法因为不需要进行人工交互和图像分割处理,可以直接利用图像的灰度信息进行配准,使得该方法成为了医学图像配准的常用方法之一。相似性测度和优化算法作为基于灰度的图像配准的两个关键问题,一直是图像配准领域的研究热点,近年来互信息理论更是被广泛应用于图像配准方法中[4]。交叉累计剩余熵(cross cumulative residual entropy,CCRE)就是众多互信息中的一种,Wang等人通过研究发现,CCRE比传统互信息(mutual information,MI)和归一化互信息(normalized mutual information,NMI)曲线更光滑、鲁棒性更强[5]。医学图像配准的实质是相似性测度的寻优问题,即寻找互信息最大时的几个空间变换参数值。基于互信息的医学图像配准常用的优化算法有Powell算法[6]、单纯形法(simplex method,SM)[7]、遗传算法(genetic algorithm,GA)[8]和粒子群算法(particle swarm optimization,PSO)[9]等。这些优化算法各有优点和不足之处:Powell法极易陷入局部极值,而单纯形法收敛速度过慢。遗传算法能够跳出局部最优,但计算时间较长,且不时会搜索到错误的方向而不能得到最优解;PSO能够有效地按照概率进行全局搜索,从而可以克服局部极值并获得全局最优解,但迭代过程中容易出现早熟,对于离散的优化问题处理不佳,从而陷入局部最优。
Civicioglu在观察自然界生物群体从一个食物匮乏的栖息地持续不断迁徙到其他给养充足的栖息地这一自然规律后,提出了一种新的元启发式算法,称为差分搜索算法(differential search algorithm,DSA)。DSA已经证明了该算法在无约束优化问题上相对于粒子群算法、遗传算法、人工蜂群算法(artificial bee colony algorithm,ABC)等的优越性[10],DSA也已在有约束全局优化、无功规划、电化学显微加工等问题上得到应用[11-13]。但是,Civicioglu提出的DSA模型存在生物群搜寻的方向过于发散,从而导致算法不易沿着最佳路径进行优化,且DSA在迭代后期不易找到峰值等局限性,将其直接应用于医学图像配准会导致配准精度不理想等情况。针对DSA的缺点,文献[14]将DSA模型应用到了功率通量问题上,调整了DSA模型使之适应了文章目标参数的求解,但并没有对DSA进行优化。文献[15]提出了一种CDSA(composite differential search algorithm)的解决方法,但该方法仅通过增加算法的复杂度来求取最优候选解,并未对算法的寻优策略进行优化。文献[16]使用了一种BDSA(binary differential search algorithm)的方法用于解决多维度参数的背包问题,但该方法由于其寻优的特性并不适用于医学图像配准中低维度的优化问题。对此,本文基于原始的DSA模型,调整了原模型中布朗运动的搜索模式和活动范围,并优化了虚拟超级生物体寻优的方向,更新了算法迭代的条件,基于原始的DSA模型提出了改进的差分搜索算法(modified differential search algorithm,MDSA),且成功使用MDSA作为搜索策略进行相似性测度寻优。实验部分以CCRE为相似性测度,分别使用DSA和MDSA作为优化算法,对两组不同的医学图像进行了优化曲线对比、单模和多谱配准实验。实验结果证明,MDSA相比DSA,不易陷入局部极值,迭代速度快,鲁棒性强,能高效地完成医学图像配准中的寻优步骤。
2 基于交叉累计剩余熵的图像配准理论
在图像配准中,虽然两幅图像来源于不同的设备或不同的时间,但它们都是基于共同个体的同一位置的解剖信息,当两幅图像的空间位置完全一致时,重叠部分所对应像素的灰度互信息达到最大值。但是由于互信息对重叠区域的变化比较敏感,灰度互信息曲线往往不平滑,寻优算法难以找到最大值甚至陷入局部极值,因此引入一种高效的相似性测度是非常有必要的。
Wang和Rao等人基于随机变量的累计分布原理研究出一种与香农熵(Shannon entropy)相类似的全新的相似性测度,称之为累计剩余熵(cumulative residual entropy,CRE)。CRE 中的随机变量 X,是由累计剩余分布函数P(x>u)中x所定义的,可以表示为:

累积剩余分布函数P(x>u)描述了X的值大于u的概率。采用Wang等人对CRE的定义[5],计算CCRE在浮动图像F和参考图像R之间灰度值的方法如下:
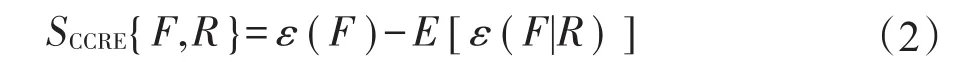
式中,ε(F|R)表示先验设定的CRE,E[·]为期望算子。根据Wang等人提供的函数定义,CCRE表示为累积和边缘分布函数的公式。
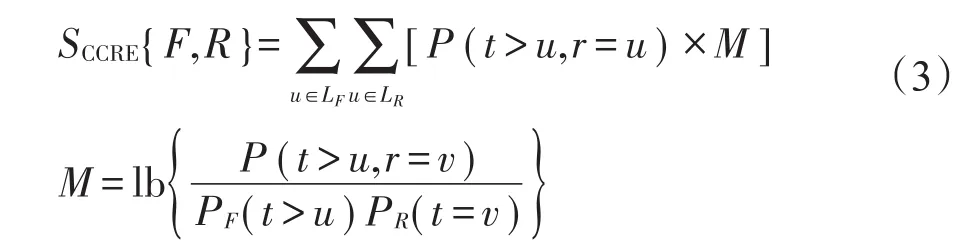
式中,P(t>u,r=u)表示在图像F的像素点中,比灰度值u更高的联合概率;将这些像素点的坐标置于图像R中,则可得到各像素点的灰度值v。图像F的累计剩余分布函数用PF(t>u)表示。
Wang等人[5]已经证明了相对于互信息(MI),CCRE在医学图像配准中展现出了更加优异的鲁棒性,CCRE作为相似性测度能够得到更好的配准质量。CCRE之所以能够优于MI(基于香农熵),其最主要原因是CCRE在处理参数化转换领域时具有更好的噪声稳健性和更广的收敛区间。
3 本文算法
3.1 差分搜索算法原理
差分搜索算法的创作灵感来源于自然界的各类生物体的迁徙过程。自然界中许多群体生物需要不断地迁徙到更富饶的土地上以获取更丰富的食物资源,当大量个体同时进行迁徙时,这些个体就形成一个超级生物体。Civicioglu在DSA中使用了布朗随机运动的搜索方式来模拟超级生物体在大自然中迁徙的过程。在DSA中,算法产生的虚拟超级生物体在经过随机初始点的首次寻优迭代后产生的位置被称作栖息点,借此来模拟超级生物体的出发点。虚拟的超级生物体会不断地迭代寻优,每次寻优找到的位置被称为停留点,此时算法会判断该位置的停留点是否优于上一个位置,如果答案是肯定的,则把此时的停留点替换为最优点。算法会不断更新停留点的值,直到达到算法的迭代终止条件为止。算法流程如下:
(1)初始化DSA并设定初始参数,种群的规模popm,m={1,2,…,S},其中S表示个体总数,总维度popn,n={1,2,…,D},其中D表示所优化问题的维数。
(2)根据初始化参数求出栖息点的值。

此时的popmn即为栖息点的值,由式(4)得出的随机值决定。
(3)迁徙过程中根据布朗随机运动寻找停留点,能有效避免陷入局部最优。

其中,Stopover即为停留点,表示虚拟超级生物体当前位置;R代表虚拟个体搜索的范围,用于模拟布朗随机运动;map是一个由问题维数构成的由0和1组成选择器,决定问题维度是否更新,0代表该问题方向在此轮迭代中不更新,1反之;Pos表示超级生物体目前栖息的位置;Dir-Pos表示超级生物体迁徙的方向。
(4)限制生物个体的边界,Sitemn为虚拟种群的位置,当Sitemn

(5)当个体得到各自的Sitem后,要与当前个体位置区域进行比较,判断所寻找的位置是否比当前位置更优。如果Sitem的位置更加优越,则替换为该个体当前位置。根据此时Sitem的值即可计算出CCRE的值。
(6)虚拟超级生物体不断向全局最优位置迁徙并持续更新CCRE的值,当优化算法满足迭代终止条件或满足迭代终止目标时,结束优化并输出CCRE值最大时的几个空间变换参数值;否则返回步骤(2)继续探索。
DSA与人工蜂群算法[17]和蚁群算法[18]等仿生智能优化算法不同,每个虚拟超级生物体中都包含了若干个虚拟生物体,算法会考虑每一个虚拟生物体的值,不完全依赖于当前全局最优解,很好地结合了搜索的目的性与随机性。
3.2 改进的差分搜索算法
如何平衡MDSA的全局搜索能力与局部搜索能力[19]是改进算法的关键。DSA使用了较大的搜寻范围结合单一迭代方向的迭代模型,这一点充分利用了算法的全局搜索性能,使得DSA难以陷入局部极值,但此迭代模型会在后期的局部搜索中变得乏力,难以找到峰值。而由于搜寻范围过大,DSA会频繁地使用到式(6)进行边界限制,而经式(6)随机产生的种群位置很难优于现有的已更新过的停留点,这种寻优模式极大地降低了算法的更新效率,与算法优化的目标相悖[20]。MDSA调整了式(5)中R×map的搜寻模型,改进了这两个特征的寻优模式。相对于DSA对单一方向进行大规模搜索的迭代模型,MDSA调整成为了对多个方向进行小规模搜索的迭代模型。此模型的改进使得MDSA整体偏向于积极的迭代更新,配合小规模的布朗运动搜索,规避掉了一部分算法因为随机运动带来的不稳定性,使得算法在迭代前期能够稳步更新,迭代后期更加容易找到峰值,更好地平衡了算法前期的广度探索能力和后期的深度探索能力。DSA与MDSA在三维度优化问题上,同一种群中的9个粒子在迭代中的示意图如图1与图2所示。
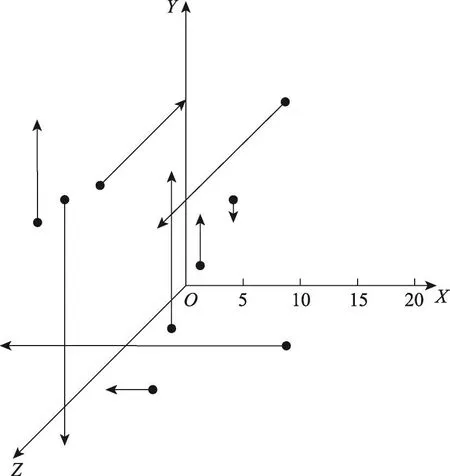
Fig.1 Particle trajectory by DSA图1 DSA种群粒子运动轨迹
图1和图2中所有种群粒子均按照式(4)随机分布初始位置,其迭代搜索方式按照式(5)中R·map·(Dir-Pos)进行。图1中,DSA的种群粒子寻优范围较长且迭代方向单一,图2中MDSA的种群粒子的寻优范围较短且约有1/3的种群粒子会进行两个方向的迭代(用虚线表示),多方向迭代的种群粒子会叠加这两个方向的寻优结果(用实线表示)。
在DSA的原始代码中,式(5)中的R给出了5种预定的设置可供选择,分别是R1=4×randn;R2=4×randg;R3=lognrnd(rand,5×rand);R4=1/gamrnd(1,0.5);R5=1/normrnd(0,5),上述 R1~R5 的取值都存在波动范围较大且不稳定的特点。MDSA迭代模型对R值的要求是数值更小且变化较小,考虑到布朗运动的特性,即随机性与不稳定性,故需要调整MDSA中的R参数,使其搜索范围缩小且保持稳定即可。在本文中,R被赋值为R=2×rand。
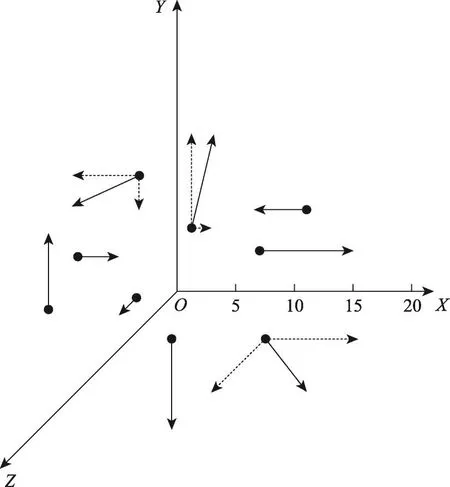
Fig.2 Particle trajectory by MDSA图2 MDSA种群粒子运动轨迹
算法改进的差分搜索算法(MDSA)
要求:N,种群数量,此处i={1,2,…,N};D,问题的维度;G,最大迭代次数。


如上述伪代码所示,MDSA在激活虚拟个体的模式上与原始DSA完全不同[10]。首先,MDSA移除了DSA中人为设定的用于调节map激活状态的p1、p2两个控制参数,加强了算法的自动化程度且提高了算法的更新效率;其次,MDSA中虚拟个体的激活方式也被重新调整了(伪代码7~20行)。在DSA中,所有虚拟个体的活性,即式(5)中map是被随机激活的,未被激活的虚拟个体在此次迭代中不进行搜索。在MDSA中改进了虚拟个体的激活选择模式,图3表示了在1 000次模拟下,3个维度的种群粒子激活比例,即在初始化时 popm,m={1,2,…,S},S=1 000,popn,n={1,2,…,D},D=3的条件下,式(5)中map在3个方向上的虚拟个体是否激活。
如图3所示,在DSA中激活单个虚拟个体(001,010,100)的比例非常大(90%左右),即DSA在大多数迭代过程中,仅会执行某一个问题维度的求解,导致其寻优效率偏低。此外DSA还包括了000这种不激活的模式,不激活即代表在3个问题维度上此轮迭代都不会进行更新,即在此轮迭代中,算法并未进行更新。MDSA则加大了多个体(110,101,011)的激活比例(33%左右)。因为MDSA算法对伪代码中7~20行代码的改进,使得MDSA中的多问题维度能够同时更新,使得MDSA能够更快、更高效地更新停留点,且舍弃掉了000这种不更新的选择,使得MDSA能够有效地规避掉某些无意义的随机搜索。

Fig.3 Comparison of DSAand MDSAof activation 1 000 operating map mode图3 DSA与MDSA激活1 000次种群粒子(map)比较
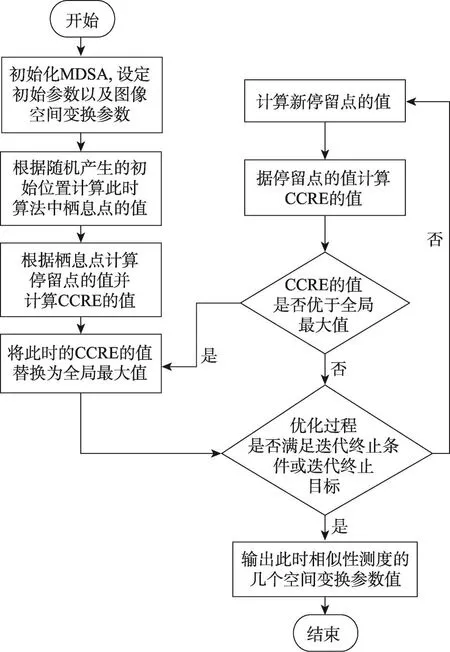
Fig.4 Flow chart of medical image registration based on MDSA图4 基于MDSA的医学图像配准流程图
3.3 基于改进的差分搜索算法的医学图像配准
以二维医学图像配准为例,可以将图像的X轴和Y轴以及旋转的角度θ等变换参数看作解空间中的一个三维向量,并利用基于CCRE的不同互信息测度,将根据该变换参数计算出的互信息值作为目标函数值,这样便可以使用优化算法在解空间中进行搜索。以MDSA为优化算法,CCRE为相似性测度的医学图像配准流程如图4所示。
上述流程图中具体步骤如下所示:
(1)初始化MDSA并设定初始参数,种群的规模popm,m={1,2,…,S},其中S表示个体总数,总维度popn,n={1,2,…,D},其中D表示所优化问题的维数。在本文实验中,个体总数S=10,优化问题的维数D=3;个体位置的上限与下限值分别设定为upn=10,lown=-10,最大迭代次数为200次。
(2)根据初始化参数求出栖息点的值,由此栖息点可得到一个CCRE值,并将此CCRE值设为全局最大值。
(3)更新停留点的值,由此停留点可得到一个CCRE值,比较此时的CCRE值与全局最大值,若CCRE的值优于全局最大值,则将此时的CCRE值替换为全局最大值。
(4)判断此时算法是否满足迭代终止条件或满足迭代终止目标,若为否则返回步骤(3)。
(5)输出此时的全局最大值,即CCRE的最大值,此外还有此时的3个空间变换参数值。
4 实验与讨论
4.1 单模图像配准
本文使用的单模配准图像数据集是美国Vanderbilt大学的“回顾性图像配准评估(Evaluation of Retrospective Image Registration)”项目里patient_001和patient_002两位病人的脑部CT图像(512×512×29 pixels)和T1、T2图像(256×256×26 pixels)。所有的图像都选择第15片断层作为实验图像,如图5所示。实验将经过空间变换后的CT、T1、T2图像当作浮动图像,实验使用CCRE作为相似性测度,DSA和MDSA作为优化算法进行寻优。

Fig.5 Single mode image registration图5 单模图像配准
实验在X轴和Y轴以及旋转的角度θ上,用在某一区域(6~7)随机产生的空间变换参数来模拟浮动图像与参考图像之间的空间变换。由于元启发式算法的不稳定性质,对每一幅图像DSA和MDSA都会进行50次实验。计算出来的误差值,即真实参数和配准参数在X轴和Y轴以及旋转角度θ上的误 差值用ΔX、ΔY和Δθ来表示,此外本实验加入了一个综合性能指标实验将patient_001和patient_002的CT、T1、T2图像配准结果取平均值来当作最后的实验结果。6幅实验图像配准误差参数值如表1所示。

Table 1 Statistical analysis of DSAand MDSAin 6 single mode medical image registrations表1 6组单模医学图像配准中DSA和MDSA的性能统计
表1中6组数据分别代表了图5中(a)~(f)的图像配准结果。在上述所有实验中,MDSA的最差配准值都是最小的,说明MDSA相对于其他两种算法更加稳定,鲁棒性更强。就平均误差而言,MDSA在3个性能指标上的表现(ΔX,ΔY,Δθ)大部分优于DSA,就整体误差Delta而言,在上述所有实验中,MDSA均为最小,此两点说明MDSA的配准精度更高。就配准完成所需时间而言,MDSA的配准速度也更快。实验证明MDSA相对于DSA而言,鲁棒性也更强,配准精度更高,配准耗时更少。
为了进一步展现MDSA和DSA在优化过程中的差异,下面引入了两种算法在patient_002 T1图像中,空间变换参数ΔX、ΔY和Δθ取值均为7时的迭代优化曲线,如图6所示。
图6中,MDSA比DSA更早完成迭代,MDSA在17次迭代时就完成了寻优,DSA在40次迭代时才完成寻优;MDSA的空间变换参数ΔX、ΔY、Δθ最终配准结果分别为7.94、6.23、7.08,相对于DSA的最终配准结果,即8.18、5.94、6.82,MDSA的3项空间变换参数都更接近预设值7,配准完成时MDSA相似性测度CCRE的值(67.55)也优于DSA的相似性测度CCRE的值(65.99)。

Fig.6 Iterative optimization process of DSAand MDSA图6 DSA与MDSA的配准优化曲线
4.2 多谱图像配准
本文使用的多谱配准图像数据集是Brain Web数据集里的T1、T2和PD图像,如图7所示。图7中(a)~(c)的图像的噪声等级为0%,强度非均匀等级分别为0%,切片厚度均为1 mm,切面层数均为第90断层。
实验将T1和T2图像作为参考图像,将PD图像作为浮动图像,在X轴和Y轴以及旋转角度θ上,用3组不同的空间变换参数(0~1,3~4,6~7)来模拟浮动图像与参考图像之间的空间变换。DSA和MDSA的各种参数与单模实验配置相同,每一次配准仍旧进行50次实验后取均值,表2所示数据为6组配准结果的平均值。实验设定了6项评价指标,分别是交叉累计剩余熵(CCRE)、传统互信息(MI)、归一化互信息(NMI)、归一化积相关(normalized cross correlation,NCC)、最小均方差(least mean-square error,LMSE)以及时间(Time),文中的时间单位统一以秒为单位。

Fig.7 Multi-spectral image registration图7 多谱图像配准
表2列出了多谱医学图像配准中DSA和MDSA的性能统计,大部分的实现结果表明MDSA是优于DSA的。表3为表2所示所有数据取平均值的结果,从整体上看,MDSA在多谱图像配准实验中,所有指标都优于DSA。相对于DSA而言,MDSA在CCRE这项指标上提高了近1个单位;在MI上提高了0.5个单位;在NMI这项指标上,DSA劣于MDSA 0.06个单位;在NCC这项指标上,DSA也略低于MDSA;LMSE数值越低性能越优秀,相对于DSA,MDSA在此项的表现也更为优异。从时间上看,MDSA整体迭代的时间也更快,从表3能够看出MDSA比DSA平均配准速度提高了近1 s,证明了虽然MDSA迭代更加频繁,但是由于MDSA较DSA会更少地用到边界限制,MDSA寻优的速度相对于DSA反而变快了。上述结果说明了MDSA在单模和多谱医学图像配准中均展现出了更高的配准精度、更快的配准速度以及更好的鲁棒性。

Table 2 Statistical analysis of DSAand MDSAin 6 multi-spectral medical image registrations表2 6组多谱医学图像配准中DSA和MDSA的性能统计

Table 3 Average statistical performances between DSAand MDSAfor multi-spectral medical image registration表3 多谱图像配准整体DSA和MDSA的平均值统计
5 结束语
MDSA重新定义了停留点的更新方法,改进了虚拟个体的激活方式,配合小规模的迭代更新,减少了边界限制的使用频率,从而提高了算法的寻优效率,相对于DSA更好地平衡了算法的全局搜索和局部搜索性能。此外,相对于原始DSA,MDSA并没有增加算法的复杂度或增添更多的特征值,且简化了控制参数。在实验部分,本文使用了MDSA和DSA对Vanderbilt大学以及BrainWeb数据集进行了实验比较。结果表明,本文提出的算法在进行二维单模刚体配准时,配准精度高,配准速度快,不易陷入局部极值,鲁棒性强;进行多谱刚体配准时,各项指标均表现优异,且配准耗时较短。本次实验在一定程度上提高了医学图像配准算法在临床医学中的实际应用价值。
