基于多特征Bi-LSTM-CRF的影评人名识别研究
2019-04-17禤镇宇蒋盛益张礼明
禤镇宇,蒋盛益,2,张礼明,包 睿
(1. 广东外语外贸大学 信息科学与技术学院,广东 广州 510006;2. 广东省网络空间内容安全工程技术研究中心,广东 广州 510006)
0 引言
命名实体(Named Entity)[1]指的是文本中具有命名性指称的词,人名作为命名实体之一,其内部组成更复杂、识别难度较大。当前人名实体研究正从传统媒体转移到社交媒体当中,如微博、Facebook等。作为社交信息之一,影评的句法往往不规则甚至不完整,而其中的人名组成也更为多元。例如,在影评中,“刘德华”“周星驰”等往往会被带主观情感的称谓所替代,如“华仔”“星爷”。这些称谓同样在“具有命名性指称的实体”的范畴当中,却常被忽略不计。此外,由于电影选角和题材上的差异,新电影中普遍存在人名新词,或称未登录词。关于这些问题,目前学术界仍未取得较大的突破。与此同时,对于影评的人名抽取技术日益受到工业界的关注,从影评中抽取相关的主创人物,如导演、演员、角色、编剧等,能为明星营销、主创票房贡献价值分析、情感倾向分析[2]等情报技术提供支持。
传统的中文人名识别方法多是基于规则和概率计算的。李中国等[3]提出了基于边界模板和局部统计的识别方法。首先从标注语料中提取边界模板以定界候选人名词汇,接着利用局部统计量和相关修正规则对候选人名进行修正。倪吉等[4]通过抽取外部人名语料中的用字特征和边界特征,以计算人名内聚度、人名区分度和边界模板可信度的综合概率。而当下主流的方法多是基于机器学习模型进行训练,该类方法对标注语料进行学习,并以序列标注的形式实现人名识别。如最大熵模型、隐马尔可夫模型、条件随机场模型等。机器学习方法的好处在于能够学习特征间的关联性和重要性。曹波等[5]以词作为标注对象,先进行最大概率分词,然后利用人名角色表和词性表,将句中词分为人名内部组成、上下文、无关词等,以此构造特征模板,最后利用最大熵模型进行训练和预测。该方法在1998年1月~5月的人民日报语料中取得了89.43%的识别精度和94.26%的召回率。张素香等[6]以原子特征、全局变量特征、复合特征等构造特征模板,并利用条件随机场模型实现人名抽取。该方法将准确率提升至95%。上述方法均以词作为训练和标注的基本单位。然而目前大多数分词工具仅针对相对规则的人名实体,难以对影评中的人名称谓和人名未登录词进行有效的切分。另一方面,基于字符的方法在基于统计的机器学习模型中存在一定的缺陷,语言学界一般认为词是语义的最小单位,而字符往往缺乏充足的语义信息。近年来深度学习在自然语言处理领域取得丰硕成果,基于深度学习的命名实体识别方法[7-9]逐渐涌现,如长短期记忆网络(Long Short-Term Memory,LSTM)。LSTM具有远距离记忆功能,能够处理标注时的长距离依赖问题。LSTM的这一特性在一定程度上克服了字符级特征的不足。Dong et al.[10]首次将字符级的Bi-LSTM-CRF模型应用到中文命名实体识别任务中,并提出利用汉字部首作为字符的特征表示之一,然而影评中的译名和特殊称谓所包含的汉字并没有明显固定的部首,该方法并不适用于人名识别。
综合上述提到的问题,本文提出一种基于深度学习的影评人名识别方法。该方法将预训练的字向量(Character Embedding)和传统方法中常用的人工特征(边界特征和用字特征)整合为统一的字符级(Character-Level)特征;采用Bi-LSTM-CRF模型[11]进行字符序列标注,从而实现人名识别。
1 模型
图1为所提出模型的整体架构,该模型通过构建字向量表、边界向量表和用字向量表为字符提供特征支撑。模型首先提取字符对应的三类特征,三类首尾特征拼接后作为Bi-LSTM层的输入,经过Bi-LSTM提取隐藏层特征h1,h2,…hn;并以此作为CRF层的输入,CRF对上下文标注以进一步约束后,输出序列标注结果y1,y2,…yn。
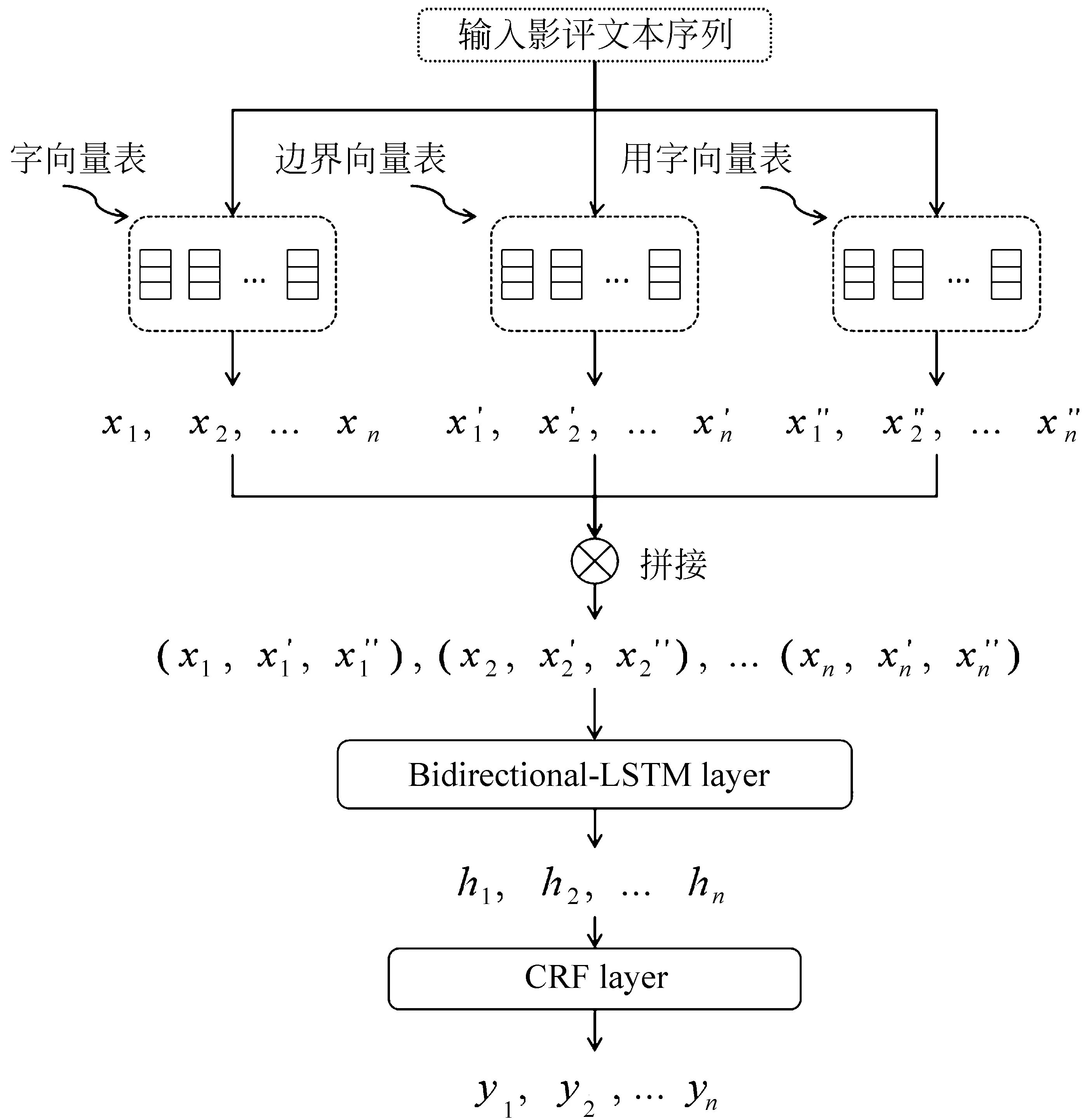
图1 多特征Bi-LSTM-CRF模型框架
1.1 特征
模型采用的特征包括字向量、边界特征和用字特征。这些特征均为字符级的,下面详细描述三类特征的构造和向量化。
(1) 字嵌入
字嵌入也称字向量,是对文本集合中各字符的分布式表示,字向量能够表示字符的句法和语义信息。字向量的概念源于词向量,其实质就是把语料中的每一个词映射至同一向量空间中,从而将两个词的语义距离转换为向量空间中的物理距离。当前对词嵌入的研究较广泛[12-14]。其中较为著名的属Mikolov et al[15]提出的Word2Vec和Jeffrey et al.提出的GloVe[16]。
Skip-gram是Word2Vec中的模型,其实质是一个三层的神经网络,它基于当前词来预测一定窗口内的上下文,模型训练目标是获取最大概率产生当前序列观测数据的隐藏层参数。而GloVe是一种更新的基于共现矩阵(co-occurrence matrix)的词向量模型。GloVe通过矩阵分解的方法,不仅考虑到Word2Vec窗口的上下文信息,也考虑到全局信息,因此GloVe能更全面地表达词或字符的语义。利用GloVe对大规模影评数据进行字向量训练,使得人名之间可以进行相似性的度量,其意义在于与已有人名相似的未登录词更容易被识别,从而提高人名识别的召回率。
GloVe首先通过滑动窗口构建词与词间的共现矩阵。定义Xi,j,表示词j和词i共同出现在窗口内的次数。定义Xi=∑kXi,k,表示在词i窗口内出现的总词数,k为窗口内的词。定义Pi,k=Xi,k/Xi,表示词k出现在词i窗口内的概率。定义ratioi,j,k=Pi,k/Pj,k,ratioi,j,k的值揭示了词i、j、k之间的相关性。

考虑到部分词共现属于噪声,不利于模型学习参数。在构造损失函数时,引入赋权函数f(Xi,j),完整的损失函数如式(1)所示。
(1)

(2)
通常,设a=0.75,xmax=100。
(2) 边界特征
中文人名一般具有边界模糊的问题。所谓边界是指与人名相邻接的词或字。传统方法[3]一般通过构建边界模板以定界候选人名。但在采用序列标注模型时,一般难以确定一个人名的长度。本文以已标人名作为种子词,在未标注语料中进行上下边界字符的提取。表1列举了人名上下边界中的高频字符。

表1 上下边界字符频数
统计发现,上边界共有2 601种不同字符,前15种字符占了总频率的26.2%,下边界则有2 633种不同字符,前15种字符占了总频率的22.1%。其中,“帅”、“爱”、“@”、“#”、“演”、“太”、“很”等高频边界表明影评的强领域性。而人名边界的集中分布情况也说明边界信息具有一定的人名区分能力。考虑到高频字符中存在常见的停用词,如表1中的“和”、“的”等,本文采用以可信度作为边界特征的衡量标准,可信度定义见式(3):
(3)
式(3)中,ci表示训练语料中的第i个字符,fci表示字符ci作为上文(下文)边界的频率。wci表示ci在未标注语料中的频数。为了将特征融入神经网络模型,对可信度C进行标准化和离散化处理,以获取可信层级R,通过为各层级赋予唯一向量进行表示,以输至神经网络模型,可信层级R定义如式(4)所示。
(4)
式(4)中,round函数为四舍五入计算,k为切割值,控制离散化后的特征数。离散化后的边界特征可参照字向量的形式映射至向量空间当中,作为神经网络的输入。
(3) 用字特征
在中文人名识别中,用字特征一般以布尔值或可信度进行衡量[5]。本文在此基础上进行了改良。本文将用字特征分为7类,包括姓用字、单名字、双名首字、双名尾字、译名首字、译名中字、译名尾字等。这7类用字不仅对中文人名和国外译名的识别有帮助,大多数人名称谓也存在这7类用字,例如“华仔”和“吴先生”。其中“华”是双名尾字或者单名尾字,“吴”则是姓用字。在衡量特征值时,对大规模的中文人名和国外人名语料进行字符频数统计。与边界特征一样,离散化后随机映射至向量空间中,并作为神经网络的输入。用字特征的计算和离散化过程见式(5):
(5)
其中c为字符,v为字符c对应特征值,fc为c的字符频率,fmax为频率最大值,fmin为频率最少值,k为切割值,控制离散化后的特征数量。
1.2 Bi-LSTM
LSTM网络以上一时刻的隐藏层输出向量和当前字符向量作为当前标注的衡量信息,计算上一时刻的标注对当前标注的影响。LSTM中的输入门、忘记门和输出门能够有效控制网络中的信息传递和保存。LSTM具体工作流程如式(6)~式(10)所示。

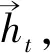
1.3 Bi-LSTM-CRF
Bi-LSTM-CRF在Bi-LSTM的基础上扩充了CRF层,其结构如图2。CRF[17]模型在序列标注任务中的优越性能已被多次验证。在Bi-LSTM-CRF模型中,CRF的主要作用是进一步增强前后标注的约束,避免不合法的标注情况出现,如标签“B-nr”后面接标签“E-nr”的情况。对于Bi-LSTM的输出序列h=(h1,h2,…,hn),通过概率模型CRF获得候选标签序列y={y1,y2,…,yn},CRF原理如式(11)所示。

图2 Bi-LSTM-CRF
(11)

(12)
最大似然估计的目标是调整相关参数W和b,使得L(W,b)最大化。在使用CRF进行标注时,选取概率最大的候选标注序列作为最终标注结果。
1.4 模型训练
训练时采用Adam[18]作为优化器,学习速率为0.001;dropout[19]为0.3;预训练的字嵌入设为200维,上下边界特征和各类用字特征均设为32维。每一层LSTM网络设256个神经元。模型训练时,若连续迭代5次后,验证集对应的损失值均未下降,则训练完成。
2 实验结果
2.1 实验语料
影评数据获取自微博电影[注]http: //movie.weibo.com。共获取1 224部电影,总计600多万评论。接着对80部电影(除动画)进行了标注,最终获得有效评论2 247条。标注时,将影评中的人名实体分为中文人名、国外译名和人名称谓。表2列出了人名实体的定义。外部人名语料获取自网络语料,共获取中文人名120万和国外译名48万。

表2 影评中的人名定义
为验证本文方法,设置两组数据集: 数据集A,忽略影评所属电影,将已标评论集进行随机的切分;数据集B,从80部电影中随机抽取65部作为封闭集,15部作为开放集,以模拟在已有电影的情况下对新电影评论进行人名识别。表3给出两组数据集中各类人名的情况。两组数据中各类人名占比基本一致,主要差异在于未登录词的数量。未登录词指开放集中存在而封闭集和外部人名语料中均不存在的人名实体。数据集B中的人名未登录词约占总数的31%,远高于数据集A的14%。

表3 数据集的人名分布情况
2.2 评价指标
实验结果采用识别准确率(P)、召回率(R)和二者的调和平均F1值(F)作为评判指标。P指正确识别的人名占总计识别的人名的百分比,R指正确识别的人名占测试集中所有人名的百分比,F是P和R的调和平均值,综合考量模型的性能。
2.3 实验结果与分析
首先以Bi-LSTM-CRF为基础分别对字嵌入(E)、边界特征(B)、用字特征(U)等特征进行测试,测试在数据集A中进行。实验基线为基于字符的Bi-LSTM-CRF模型,模型随机生成向量作为字符特征。字嵌入的测试对比了skip-gram以及GloVe;边界特征和用字特征的测试则分别设置不同的k值,以对比特征带来的增益。实验结果(表4)表明,相较于skip-gram,GloVe的字嵌入表示效果更优,而在边界特征和用字特征方面,当kB=2和kU=5时,特征对模型带来的增益达到最高。当k值继续增大时,特征泛化能力减弱,F1值逐渐下降。当组合各特征(EBU)时,模型的综合F1值达到89.8%,高于所有单特征模型。后续实验均在特征参数最优的情况下进行。
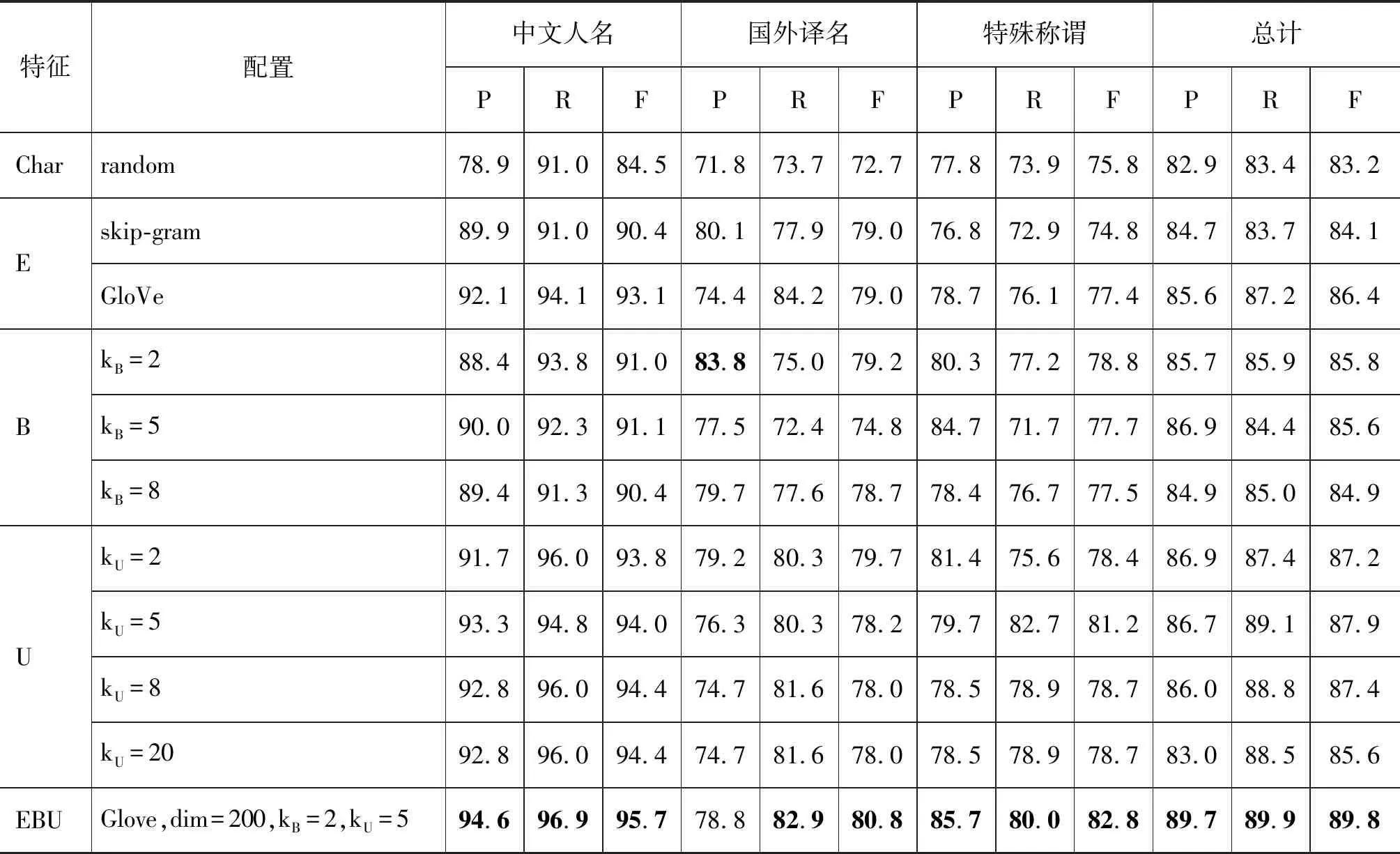
表4 各特征对识别效果的影响(%)
本文进一步对比了CRF、CRRM[20]、Bi-GRU-CRF、Bi-LSTM-CRF、Bi-GRU-CRF(EBU)、Bi-LSTM-CRF(EBU)在数据集A、B上的表现(表5)。CRRM在传统模型CRF的基础上加入了可信度衡量和规则的方法。GRU[21]也是RNN中的一种主流结构,相比LSTM,其结构更简单、参数更少。GRU只有两个门,分别为更新门(update gate)和重置门(reset gate)。该门结构能起到信息保存的作用,使得依赖信息不会由于长距离的传播而完全丢失。实验结果显示,Bi-LSTM-CRF(EBU)在综合指标上表现最佳,在数据集A和B上的F1值分别为89.8%和81.9%,远高于传统方法CRF和CRRM,神经网络模型对比方面,在一般情况下(数据集A)Bi-LSTM-CRF(EBU)的F1值与Bi-GRU-CRF(EBU)相当,仅高出0.3%。而在面对未登录词更多的情况(数据集B)表现更佳,比Bi-GRU-CRF(EBU)高出0.8%。
为了进一步验证并对比字嵌入、用字特征、边界特征在未登词识别时的增益,本文对数据集B进行了对比实验。实验结果表明(表6),字嵌入和边界特征虽然对模型的准确率提升不大,但能够使模型识别更多的未登录词,召回率分别提高了7.4%、2.7%。相较于二者,用字特征为模型带来了更大的增益,召回率提升高达16.8%,可见通过外部语料提取相关用字知识能够有效提升模型的人名新词识别能力。

表5 各模型的识别效果

表6 各特征对人名未登录词识别的增益

续表
我们抽取部分识别结果来对比本文模型和CRF在某些人名称谓上的识别差异(表7)。多特征Bi-LSTM-CRF能完整识别出“我林哥哥”,而CRF仅识别出“我林哥”;可见本文模型能够较好地克服称谓中的边界模糊问题。此外,本文模型还从语料中学习到“吴宝”、“兴宝”这类以“宝”为结尾的称谓模式,可见模型能较好的适应人名称谓的组成多元性。

表7 CRF和本文模型所识别出的人名称谓
3 总结与展望
近年来,随着电影行业的蓬勃发展,相关的信息抽取和分析技术日益受到行业内的重视,其中对电影主创人物的分析尤为重要。如何从影评中自动抽取主创人名成为重要的基础工作。本文提出一种基于多特征Bi-LSTM-CRF的影评人名识别方法。该方法通过利用外部人名语料和未标注影评提取字符级的特征;并采用Bi-LSTM-CRF模型进行人名字符序列标注。实验结果表明,该方法能够有效识别影评中的复杂称谓和人名未登记词,从而有效地抽取影评中的人名实体。对于未来的研究,本文认为如何将先验知识和深度学习模型进行有效结合,是一个务实而具有意义的研究方向。因此,我们希望能在未来提出一个具有普适性的先验知识整合框架,以提高现有深度学习模型在各类非规范文本中的命名实体识别能力。
