基于深度神经网络的维吾尔文命名实体识别研究
2019-04-17王路路艾山吾买尔吐尔根依布拉音买合木提买买提卡哈尔江阿比的热西提
王路路,艾山·吾买尔,吐尔根·依布拉音,买合木提·买买提,卡哈尔江·阿比的热西提
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2. 新疆大学 新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
0 引言
随着信息化进程的加快,互联网上维吾尔文的信息资源呈逐渐增长趋势,从而使维吾尔文信息化研究显得越来越重要,由此维吾尔语自然语言处理应运而生。命名实体识别作为自然语言处理中的一项基础性任务,旨在从非结构化文本中抽取出具有特定意义的实体,如人名、地名、机构名,并且在信息抽取、机器翻译、问答系统等领域中发挥着重要作用。
随着深度学习研究的不断深入,基于神经网络的命名实体识别已在汉语[1-2]、英语[3-4]等大规模语种上呈现了很好的性能。然而,维吾尔文命名实体识别尚处于起步阶段,面临的主要问题如下: ①维吾尔语是形态丰富的典型性黏着语言,通过附加不同的词缀,一个词将有多种形态,容易造成数据稀疏,从而带来未登录词问题(OOV); ②维吾尔文命名实体中没有大小写特征; ③没有公开的数据集,数据规模的有限性将会影响神经网络方法的识别性能。此外,现有维吾尔文命名实体识别研究主要采用基于统计的方法[5]或者统计与规则相结合的方法[6-7],而这些方法严重依赖于人工提取的特征工程和领域知识。
为了避免繁琐的特征工程,本文提出了基于深度神经网络的维吾尔文命名实体识别的方法。本文的主要工作内容如下: ①实现了对维吾尔文中的人名、地名、机构名同时识别; ②将神经网络方法应用在维吾尔文命名实体识别上; ③分别使用直接串联法和基于注意力机制的加权求和法将词向量和字符级向量进行联合,来动态学习形态丰富的维吾尔文字符间的特征,并对比Bi-LSTM和Bi-LSTM-CRF两种模型的识别效果; ④以联合向量表示作为输入的Bi-LSTM-CRF方法取得较佳的性能,同时有效缓解了未登录词的识别。
1 相关工作
基于神经网络的方法已经成功地运用在命名实体识别序列标注任务上。Collobert等[8]于2011年提出了基于CNN-CRF神经网络模型并进行了命名实体识别研究,随后一系列借鉴此方法的深度神经网络方法被应用于序列标注任务中。Huang等[9]提出了一种以人工提取的特征向量和词向量的拼接向量作为输入的Bi-LSTM-CRF模型,在CONLL2003数据集上F1值达到了90.10%;Lample等[3]引入了由Bi-LSTM获取的字符级向量,F1值达到了90.94%; Rei等[10]提出了利用注意力机制获取字符级向量和词向量的联合向量;Ma等[4]构建了BiLSTM-CNNs-CRF神经网络模型,通过CNN学习字符级向量且优于其他模型。张海楠等[1]提出了一种基于深度神经网络的字词联合方法以实现中文命名实体识别,有效解决了字词稀疏的不足之处;Dong等[11]利用BLSTM-CRF神经网络模型有效结合了字向量和偏旁向量。
相比于汉语或者英语等大规模语种,维吾尔文命名实体识别研究起步较晚,近几年许多学者针对命名实体中某一类别展开研究。艾斯卡尔·肉孜等[5]利用条件随机场,引入了词性、词干、音节等特征进行人名的识别;加日拉·买买提热衣木等[12]提出了统计与规则相结合来识别维吾尔人名,主要借用边界词提取人名;塔什甫拉提·尼扎木丁等[7]从维吾尔语黏着特点出发,利用条件随机场识别维吾尔文人名,然后再用基于规则的方法对汉族人名识别进行优化;买合木提·买买提等[6]采用条件随机场和规则相结合的方法研究了维吾尔文地名识别,并取得了较高的性能;麦合甫热提等[13]提出了利用语法语义知识实现了基于规则的维吾尔文机构名识别;阿依古丽·哈力克等[14]提出了基于正则表达式对维吾尔语中的时间、数字、量词进行识别。以上维吾尔文命名实体识别的研究主要采用基于规则的方法或者基于统计的方法,而这些方法较为传统,在分析语言特性时常常需要人工编制规则或者构建复杂的特征工程,因此维吾尔文命名实体识别具有一定的改进空间。
2 特征向量表示
近年来,分布式向量表示已广泛应用于自然语言处理领域,尤其是深度学习研究。本文采用词向量作为基本的特征,引入字符级向量来验证词向量和字符级向量的联合向量表示对维吾尔文命名实体识别的影响,本文将考虑以下特征向量。
2.1 词向量
分布式向量表示能够从大规模的未标注语料中获取单词的语义信息,与one-hot向量表示相比,它可以有效地降低维度,获取单词间的语义相关性。Word2Vec[15]和Glove[16]是目前常用于训练分布式词向量的自然语言处理开源工具,其中Word2Vec包括CBOW和Skip-gram两种模型。为了获取高质量的词向量,本文利用新疆多语种信息技术实验室自然语言处理组搜集的385万句的维吾尔文语料,采用Word2Vec中Skip-gram模型获取预训练的300维向量,词向量表中共包含1 249 649个单词/字符及其实数值向量。本文通过词向量查找表获取输入文本中每个token的预训练词向量,如果某个token不在表中,将被映射到一个统一的向量表中。
2.2 联合向量表示
维吾尔语属于形态丰富的黏着语,通过在词根的前后附加不同的词缀来实现语法功能,因此词汇量庞大,容易造成未登录词问题。单纯的词向量对未登录词问题处理仍存在不足。但是字符级向量包含丰富的结构特征,对于形态丰富的语言来说字符级向量是非常有用的,它能够学习前缀和后缀信息等形态信息,从而缓解数据稀疏问题。此外,字符级向量能够有效地处理语言模型或者词性标注中的未登录词问题[17]。
首先,随机初始化包含不同字符的字符向量查找表;然后,将单词word中每个字符的向量通过Bi-LSTM模型获取单词的前向传播向量lword和反向传播向量rword;最后将前向传播向量lword和反向传播向量rword进行拼接获取cword=[lword;rword]。
假设单词word在词向量查找表中的向量为wword,字符级向量为cword,本文将讨论以下两种联合向量方法。
(1) 基于直接串联的联合向量表示。将wword和cword直接拼接构成的串联向量作为序列标注模型的输入向量eword,即eword=[wword;cword],如图1所示。
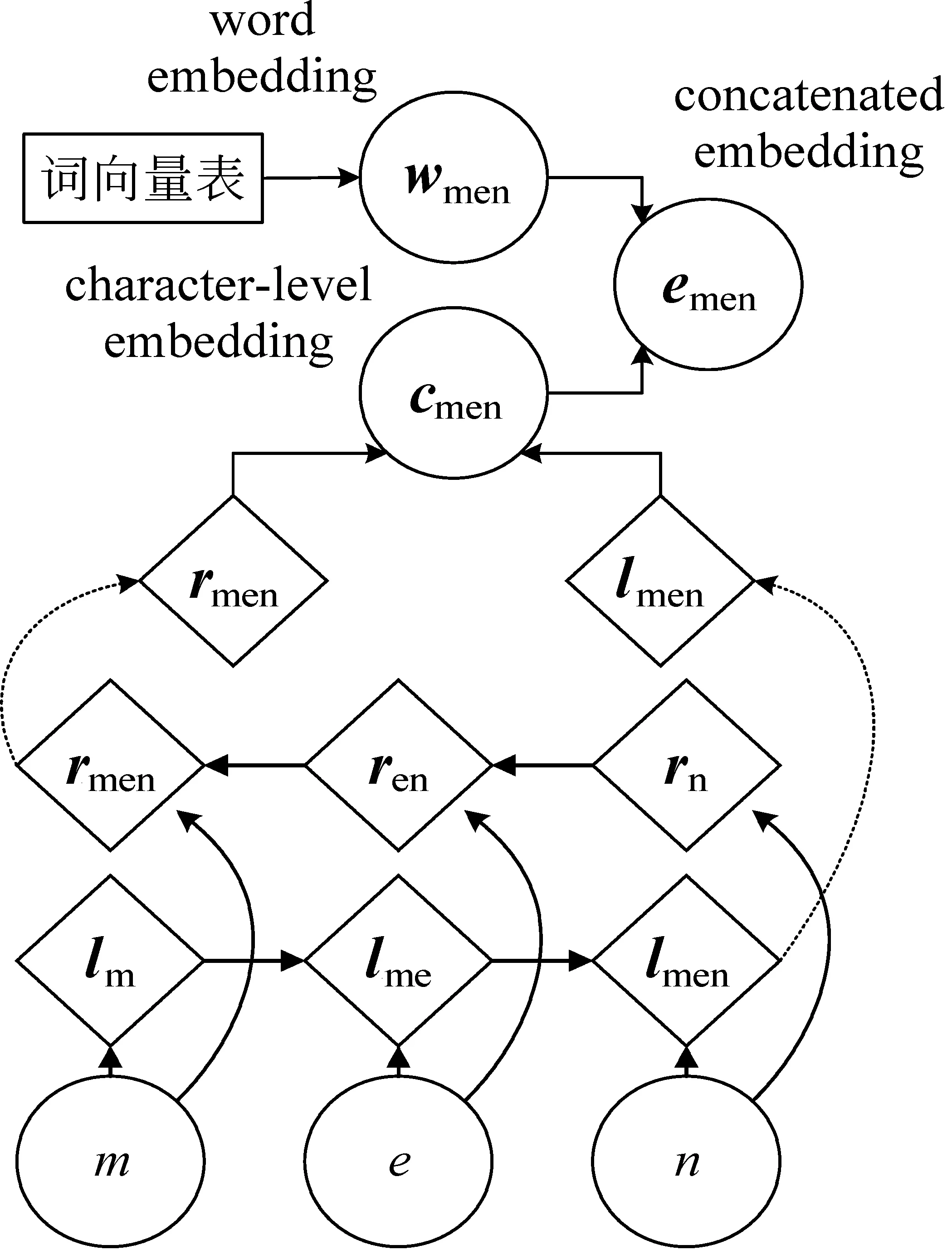
图1 基于直接串联的联合向量表示
(2) 基于注意力机制的联合向量表示。本文借鉴Rei等[10]的方法使用注意力机制将词向量和字符级向量加权求和进行联合,如图2所示。其中注意力机制的权重a是通过两层前馈神经网络学习的。
eword=a·wword+(1-a)·cword
(1)
(2)

图2 基于注意力机制的联合向量表示
3 基于Bi-LSTM-CRF的维吾尔文命名实体识别
将联合向量表示作为Bi-LSTM模型的输入,获取前向传播向量和反向传播向量;然后将两个向量的拼接向量表示输入序列,再通过tanh层将向量缩小至[-1,1];最后通过条件随机场判断出最优的标记序列。为了充分理解维吾尔文命名实体识别研究,本文以拉丁维吾尔文“men junggoni söyimen” (中文意思: 我爱中国)进行举例。
3.1 Bi-LSTM
循环神经网络(recurrent neural network,RNN)是处理序列标注问题的一种神经网络语言模型,它能够利用历史信息处理长距离依赖信息,但是未能有效地解决梯度消失和梯度爆炸问题。长短时记忆网络(LSTM)[18]是RNN的变种,明显在该问题上表现占优,主要通过记忆单元连接各个门结构使得模型记忆有效的上下文信息。LSTM门结构有输入门、遗忘门、输出门。LSTM的形式化表示如式(3)所示。
(3)
其中,σ是非线性sigmoid函数,⊙代表点乘运算,tanh表示双曲正切函数,xt、ht-1、ct-1分别表示t时刻的输入、上一时刻的输出、上一时刻的单元状态。W、U、V分别表示对应门或者状态的权重,b表示偏值项。
为了充分利用上下文信息,本文将采用Bi-LSTM模型。Bi-LSTM 在LSTM的基础上增加了反向传播层,可以将信息序列分别从两个方向出发输入模型,然后经过隐含层保存两个方向的信息序列,即历史信息与未来信息。对于输入序列S=(e1,e2,…,en),Bi-LSTM将获取前向传播向量l=(l1,l2,…,ln)和反向传播向量r=(r1,r2,…,rn),则Bi-LSTM的最终输出为ti=(li;ri),在Bi-LSTM之上的tanh层用于预测每个单词所有可能标记序列的置信度,如式(4)所示。
hi=tanh(Whti)
(4)
其中,Wh表示隐藏层的权重矩阵。
Softmax作为Bi-LSTM的输出层,可以对各个位置独立进行多分类。Softmax函数是计算每个单词的所有可能标记信息的归一化概率分布,如式(5)所示。
(5)
其中,p(yi=j|ht)表示输入序列中第i个单词对应的标记yi是j的概率,K表示标签集合。在训练过程中通过最小化负对数似然函数优化模型,如式(6)所示。
(6)
3.2 Bi-LSTM-CRF
本文将维吾尔文命名实体识别看作序列标注任务并采用了BIO标注形式,这种标记形式有很强的约束性,例如“I-ORG”之前不可能是“B-LOC”或者O。若仅仅用Bi-LSTM则不能充分解决此类问题,但是CRF能够考虑上下文标签之间的关系,从而能代替softmax层获取全局最优的标记序列,因此最终本文考虑将Bi-LSTM和CRF结合,即将Bi-LSTM-CRF模型用于维吾尔文命名实体识别中,如图3所示。

图3 基于Bi-LSTM-CRF的维吾尔文命名实体识别
首先将第2节中的特征向量表示作为Bi-LSTM的输入向量,通过Bi-LSTM编码器获取输出结果P(原理同2.1节),其中P的大小为n*k,n表示输入序列的长度,k表示标签集合的大小,则其第i列是由式(4)获取的向量hi,Pi,j表示输入序列中第i个单词对应第j个标记的分数。通过引入转移矩阵T作为CRF模型的参数,Ti,j表示连续单词由标签i到标签j的转移概率。对于输入序列预测的标签序列y={y1,y2,…,yn},定义概率表示如式(7)所示。
(7)
得到概率后利用最大似然函数训练模型,如式(8)所示。
(8)
在预测过程中寻找条件概率最大的输出序列y*,如式(9)所示。
(9)
4 实验结果与分析
本文进行了多组对比实验来验证深度神经网络对维吾尔文命名实体识别的有效性,并探索不同的输入向量对识别效果的影响。
4.1 实验数据
本文采用新疆多语种信息技术实验室标注的命名实体数据集,共计39 027条句子,包含命名实体102 360个,人名、地名、机构名占比分别约为27.81%、41.60%、30.58%。按照交叉验证法将数据集以7.5∶1∶1.5的比例分为训练集、验证集、测试集。具体的分布信息如表1~表3所示,其中NE表示命名实体,OOV表示未登录词(未在训练集中出现的词),ROOV表示未登录词的占比。

表1 维吾尔文命名实体识别数据集的统计信息

表2 开发集OOV统计信息

表3 测试集OOV统计信息
4.2 评测指标
实验采用F-值(F1)来评测命名实体识别效果,其中F-值由准确率(P)、召回率(R)来决定。计算如式(10)~式(12)所示。
4.3 参数设置
本文参考前人的工作[10],采用基于batch的梯度下降优化超参数,其中batch的大小为64,使用Adadelta优化算法,并设置其初始学习率为1.0;为了防止过拟合问题,设置Dropout参数为0.5; LSTM的前向传播和反向传播的字符向量维度均为50;LSTM中隐藏层节点数为200;在Bi-LSTM顶部上tanh层的大小设置为50。根据维吾尔文命名实体识别的词向量验证,最终确定训练词向量采用Skip-gram模型且其维度为300维;具体参数设置如表4所示。

表4 参数设置
4.4 实验设置与结果分析
为了验证基于神经网络的维吾尔文命名实体识别方法的有效性,本文以基于CRF和半监督学习的维吾尔文命名实体识别方法为基线系统(新疆多语种信息技术实验室自然语言处理组提供的服务),分别以词向量、基于直接串联的联合向量表示、基于注意力机制的联合向量作为输入向量,在Bi-LSTM和Bi-LSTM-CRF两种模型上进行实验,实验结果如表5所示。
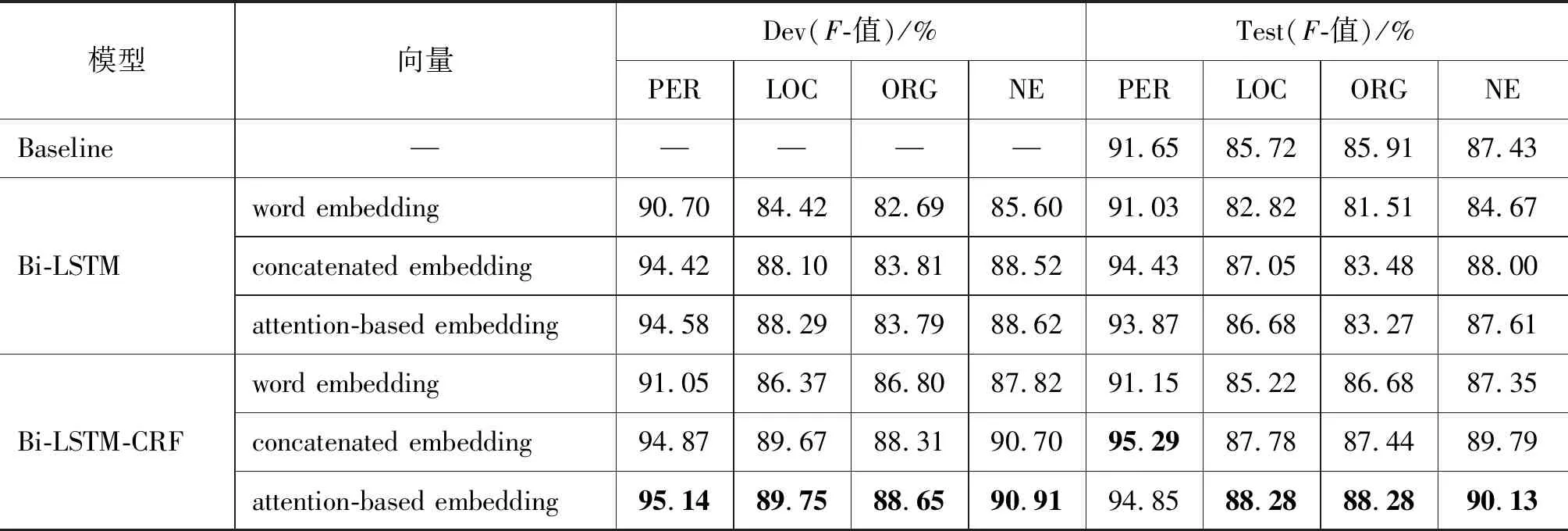
表5 不同模型的对比实验结果
从表5中看出,与基线系统相比,Bi-LSTM和Bi-LSTM-CRF两种模型仅在词向量为输入向量的情况下在命名实体识别上表现稍弱,但是在联合向量表示为输入向量的情况下均有提高,说明引入字符级向量的联合向量表示方法进一步提高了维吾尔文命名实体识别的性能,同时能够有效地减少人工提取领域特征的工作量;从总体上看,Bi-LSTM-CRF模型优于Bi-LSTM,说明条件随机场能够有效学习相邻标记之间的关系,从而联合解码以得到最优序列标注;相较于词向量,两种联合向量表示在Bi-LSTM和Bi-LSTM-CRF模型中的识别效果明显提高,说明引入字符级向量,能够有效地学习形态特征,从而缓解形态丰富语言面临的问题;在Bi-LSTM模型上,与两种联合向量表示相比,基于注意力机制的联合向量表示在开发集上稍有提高,测试集略低;在Bi-LSTM-CRF上,对输入向量进行比较,发现基于注意力机制的联合向量表示在整体的命名实体识别上F-值达到了90.13%,且高于基于直接串联的联合向量表示,说明基于注意力机制的联合向量表示能够使Bi-LSTM-CRF模型动态地选择词向量和字符级向量中的信息,且适用于形态丰富的维吾尔语。
为了更好地验证深度神经网络模型的影响,本文将开发集和测试集中所有的OOV抽取出来,进一步对OOV识别进行了分析,如表6所示。

表6 OOV识别的对比实验
从表6中可知,神经网络模型在OOV识别上优于基线系统;无论是哪种神经网络模型,引入字符级向量,OOV识别性能几乎都提高2%左右,说明联合向量表示可以有效缓解未登录词的识别;基于直接串联的联合向量表示与基于注意力机制的联合向量表示相比,在OOV识别上相差不大,由此可以说明基于直接串联的联合向量表示在非OOV上识别效果略差,进一步说明了基于注意力机制的联合向量表示能够充分地学习有效信息。
5 结束语
现有的维吾尔文命名实体识别研究依赖于人工的特征工程和领域知识,针对该问题,本文提出了基于深度神经网络的方法,主要采用基于不同输入向量的Bi-LSTM-CRF的神经网络模型。首先通过大规模的无监督学习语料训练词向量以建立词向量查找表,从而获取每个单词具有语义的词向量;然后由Bi-LSTM获取的字符级向量进行联合,分别获取基于直接串联的联合向量表示和基于注意力机制的联合向量表示;最后通过Bi-LSTM-CRF神经网络模型对进行实体标注。实验表明,基于注意力机制向量表示的Bi-LSTM-CRF方法的识别效果最佳,由此说明基于注意力机制的联合向量表示能够使模型动态地利用字符级向量或者词向量中的有效信息。
在未来的研究工作中,我们将继续研究基于深度神经网络的维吾尔文命名实体识别,探索其他神经网络模型组合或者在模型中引入注意力机制,验证出最适合于维吾尔文命名实体识别的模型;此外,将利用迁移学习实现其他黏着语种的命名实体识别。
