深度哈希卷积网络在图像检索中的应用
2019-04-16王华秋
王华秋,郎 帅
(1.重庆理工大学 两江人工智能学院, 重庆 401135;2.重庆理工大学 计算机科学与工程学院, 重庆 400054)
针对互联网上图像和视频数据的爆炸式增长,大规模的视觉搜索已经在人工智能[1]和计算机视觉[2]中得到广泛应用。考虑到用户对快速检索的需求,对于大规模图像资源,有必要探索图像检索的方法,其目标是在查询图像中返回包含同一类的图像。哈希方法作为近似最近邻(ANN)寻找方法,对于大规模图像检索十分有效,本文着重研究用于大规模图像检索的哈希函数。
因查询速度快和存储成本低,目前已有各种哈希方法用于生成图像的紧致二进制码[3-8]。利用异或运算计算汉明距离,将高压缩的数据加载到主存储器,使得紧致二进制码的相似性搜索得以快速实现。现有的哈希方法分为数据独立和数据相关两类。数据独立的哈希方法通常使用随机映射生成二进制码,例如位置敏感哈希(locality-sensitive hashing,LSH)[3],而数据相关的哈希方法通过从尽可能多地保留数据结构中学习哈希函数。数据相关方法根据是否有监督信息大致分为两组:无监督[3,5,9-11]和监督[6-7,12-14]。由于二进制码的优质性,本文着重研究监督图像的哈希方法。
大多数现有哈希方法的性能取决于所使用的视觉特征。传统上,图像通常由人工设计视觉特征描述,如Gist、HoG、LBP等。然而这些人工设计视觉特征有时不能很好地揭示图像的表达信息,限制了图像检索的性能。因此,提出了一些基于其他特征的哈希方法[8,15-18],例如卷积神经网络(CNN)提取特征。文献[8]首先根据训练图像上的成对相似性学习二进制码,然后根据哈希码学习哈希函数和图像表示。深度哈希通过最小化二进制码与深层网络的输出特征之间的量化误差来生成哈希码[15]。深度监督哈希方法学习紧凑二进制学习代码,以便对大规模数据进行高效的图像检索[18]。
鉴于卷积神经网络具备良好的学习能力,本文利用神经网络提取图像特征来提高图像检索的性能。
1 相关工作
目前学习型的哈希法大致分为以下两种:无监督哈希和监督哈希。
无监督的方法是指仅利用没有标签的图像来学习哈希函数。该类别的主要策略包括:随机映射[3],量化误差最小化[5],重建误差最小化[9]和基于图的哈希[10]。文献[11]进一步探索了无监督哈希学习的底层共享结构。
监督方法是指利用标签信息学习更紧致和区分性的哈希码。Liu等[6]提出了基于内核的一种哈希方法(KSH),最小化类内差距同时最大化类别间差距。Kulis等[7]提出了通过最小化输入与其对应的哈希码之间的平方误差来学习哈希函数。Heo等[12]提出了基于超球面的一种哈希方法,将原始空间分为球体内部和外部两部分。
上述人工设计视觉特征方法限制了图像检索的性能。近年来,深度视觉特征在各种视觉任务中取得了优异的表现,目前一些深度哈希方法[8,15-21]已被提出。特征学习对于图像检索十分重要,一个框架中可以同时学习特征和哈希函数。Xia等[8]建议分两个阶段学习哈希函数。首先,通过对基于图像标签获得的相似性矩阵进行因式分解学习二进制码。然后,基于二进制码和图像标签学习哈希函数和神经网络。由于矩阵分解会占用大量存储而不能处理大规模图像,文献[15]提出了最小化实值特征与其相应二进制码之间的量化误差的方法。在文献[19]中,保留成对相似性以同时执行特征学习和哈希学习。Lin等[21]在CNN中引入了潜层,用于学习图像表示和一组哈希函数。在文献[22]中,保留成对相似性以同时执行特征学习和哈希学习。
与上述不同,本文利用图像的标签信息提出了一种单阶段的方法。利用深度网络的模型来预测图像标签,同时生成二进制码。分类误差和量化误差用于得到更好的特征表示。
2 本文方法
本文提出了用于图像检索的方法,该方法是在统一的框架中最小化分类误差和量化误差的深度哈希。深度神经网络框架如图1所示。本文利用深度神经网络寻求多层次非线性变换以获得图像的特征表示。本文中深度神经网络的最后是两个全连接层,最后一层有k个节点,其中k是所需哈希位的长度。最后一层预测图像的标签并生成哈希码。分类误差和量化误差共同调整神经网络。所提出的方法可以学习哈希函数,该哈希函数根据标签信息为具有相同或相似语义内容的图像生成相同或相似的二进制码。在MNIST和CIFAR-10两个图像集上的实验表明:本文提出的方法在图像检索性能上优于其他几种主流方法。
本文的目标是学习图像的紧致二进制码,学习到的深度网络表示可以很好地预测图像的标签,还可以直接计算二进制码。因此,所得的二进制码能够保持图像的标签语义信息,使得二进制码在图像检索中具有紧致性和区分性。
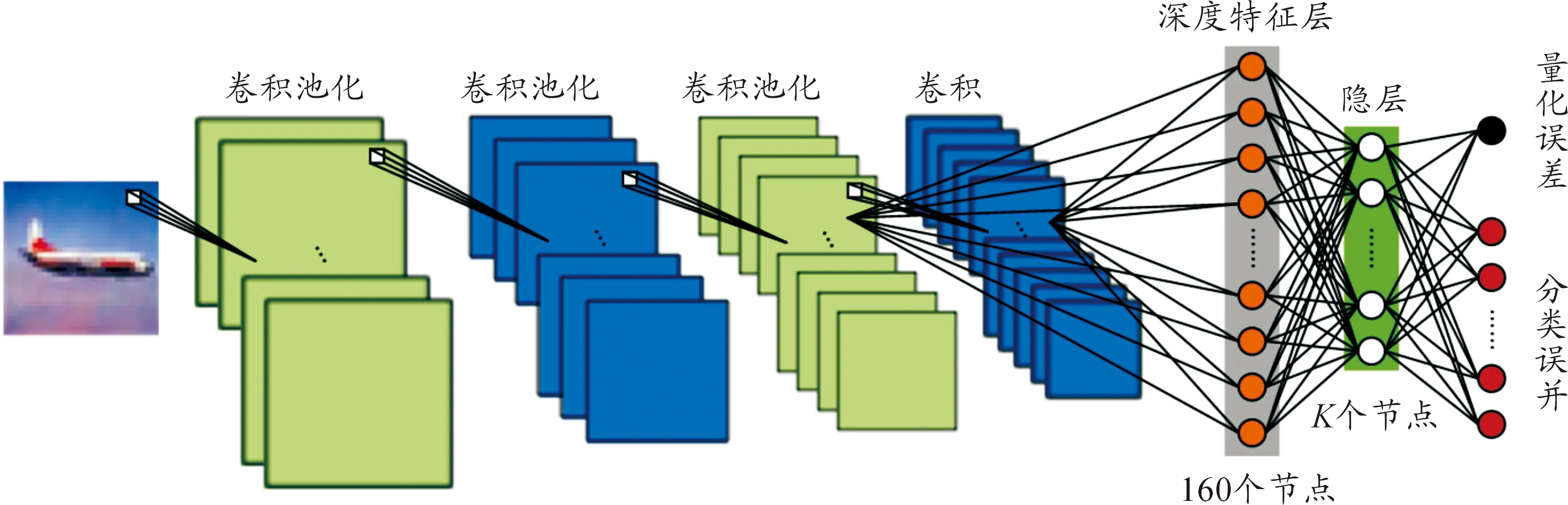
图1 深度卷积神经网的框架
2.1 深度哈希函数
受深度学习在物体识别和图像检索等各种视觉任务中优秀表现的启发,本文通过探索深层架构提出了深度哈希学习框架。为简便,本文直接利用具有强大特征提取能力的卷积神经网络(CNN)。如图1所示,所利用的深层网络有4个带着最大池化的卷积层分层提取特征,然后是两个全连接的层:深度特征层和隐层。由于第4层比第3层提取的特征更全面,深度特征层全连接到第3个卷积后的池化层和第4个卷积层以获得多尺度特征。
考虑由N个图像表示的训练集X=[x1,x2,…,xN]∈Rm×N,给定xi∈Rm是第i个训练图像,m是描述特征的维度,设Y=[y1,y2,…,yN]∈RC×N表示训练图像的标签矩阵,C表示类别的数量。如果第i个图像属于第j个类别,则Yij=1,否则为0。基于学习的哈希方法旨在学习哈希函数为每个图像生成紧致的二进制向量。即学习哈希函数:X→B∈{0,1}K×N,其中,K是所需二进制码的位数。
为了学习哈希函数,将隐层H的输出特征再量化为所需的离散值。因此,隐层H上的节点数被设置为k,其中k是所需哈希位的长度。假设深度特征层得到的图像特征pi∈R1×n表示输出n维向量,隐层H表示为
fi(pi)=Wipi,i=1,2,…,k
(1)
其中,Wi∈Rn×k为H层的权重矩阵。
在隐层用Sigmoid激活函数,将数据映射到(0,1)的范围内,表示为
(2)
其中zi=fi(pi)。
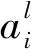
hi=(z1,z2,…zi)T,i=1,2,…,k
(3)
预测的哈希位可以通过以下函数得到:
(4)
其中sign(*)是对向量或矩阵的逐元操作。
2.2 损失函数的定义
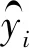
(5)
其中hi是所提出的深度神经网络对第i个图像的学习表示。
分类的损失函数可表示为
(6)
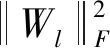
(7)
其中Iij是一个指标变量,如果Yij=1则Iij=1,否则为0。
为了得到二进制码,本文使用符号函数将实值特征量化为二进制码。为了形式化量化误差,用H和B表示隐层的输出和预测的二进制矩阵。理想的二进制矩阵可以通过B=sign(H)计算。由于上述等式过于理想,一般不成立,因此本文提出通过H和B之间的差异来学习B,使学习的二进制矩阵B和实值矩阵H之间的量化损失最小:
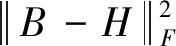
(8)
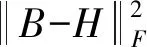
通过对隐层的输出加以上述约束,预期学习的实际值H能很快接近1或0。理论上,它能够在量化之前降低那些实际值约0.5的错误分类率,提高图像检索性能。
为了学习有判别的哈希函数,本文研究了上述两个方面,并把学习特征、哈希函数及分类放入统一的框架中。本文的整体损失函数如下:
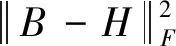
(9)
其中:γ是控制量化的重要参数;β是控制正则化的权重。将式(9)表示如下:
(10)
为了学习所提出的模型,本文采用子梯度下降法为局部最优解设计迭代优化算法,给出了J关于WH的梯度公式:
(11)
(12)
其中η是学习率。神经网络的参数可以根据文献[15]计算并更新。
在训练阶段,不必使用其他任何预训练的网络,直接使用随机梯度下降训练小批量大小为50的网络。一旦学习了所提出的网络,就可以通过量化隐层H处特征表示得到新图像的哈希码。
2.3 网络架构及初始化方案
所用网络有4个卷积层和3个最大池化层及2个全连接的层(深度特征层和隐层)。为了实现所提出的方法,设置这些层的大小,本文所用的神经网络的设置见表1。
根据深度学习的教程对所用的网络权重参数进行初始化。隐藏层权重的初值依赖于在激活函数对称区间上的均匀采样结果。
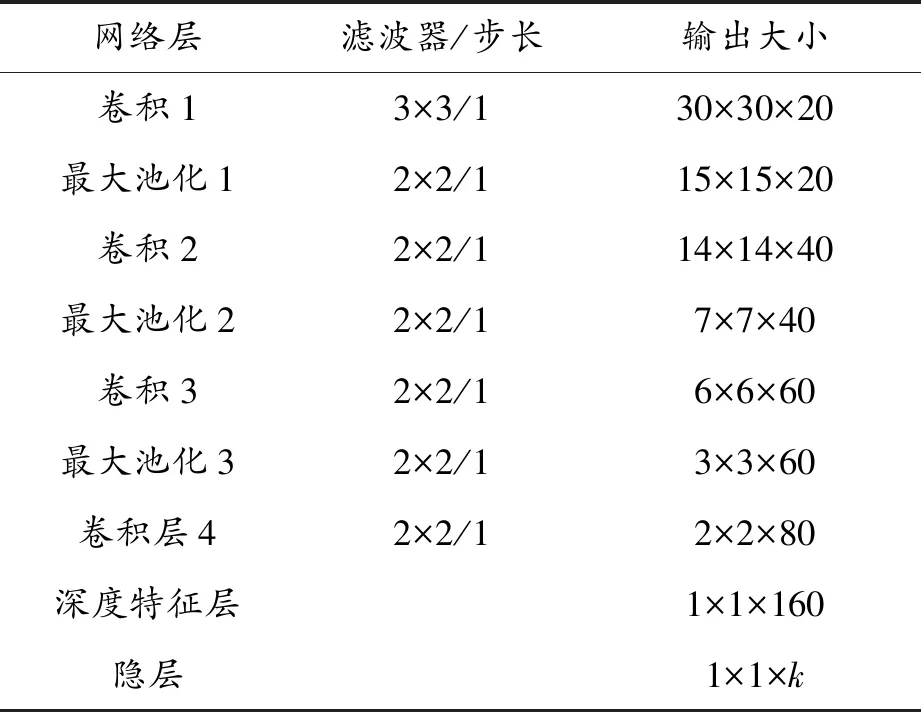
表1 提出的神经网络中的层的大小
3 实验结果分析与应用
为验证所提出方法的有效性,在MNIST和CIFAR-10两个图像集上模拟实验。MNIST图像集包含了70 000张大小为28×28的灰度图像,由0~9组成的10类手写体数字。其中包含了60 000张手写体训练图像集和10 000张手写体测试图像集。CIFAR-10图像集包含了60 000张大小为32×32的彩色图像,由车、马等组成的10个分类。从每个类别中随机选取5 000张图像作为训练集和1 000张图像作为测试集。
3.1 实验设置
实验环境:64位Windows10系统,内存12 G,主频2.50 GHz,Intel(R) Core(TM)i7-6500U CPU处理器,开发软件为Matlab 2016b。
为了评估所提出方法的检索性能,实验对比其他几种主流哈希方法。例如,无监督的哈希方法:LSH[3](随机生成位置敏感的哈希函数),SH[4](通过将原空间中的相似性保持到汉明空间中的相似性来学习哈希函数),ITQ[5](最小化数据映射到二进制值的量化误差,生成表达能力很强的哈希码);监督的哈希方法:KSH[6](监督核哈希模型,通过最小化相似对上的汉明距离,同时最大化不同对上的汉明距离来学习哈希函数),BRE[7](通过最小化输入距离和重构汉明距离之间的误差的平方损失来构造哈希),以及利用深度学习与哈希技术相结合的哈希方法CNNH[8](首先是从训练图像上成对的相似性来学习哈希码,然后根据学到的哈希码学习哈希函数)。
对于浅层学习方法LSH、SH、ITQ、KSH、BRE,在MNIST和CIFAR-10两个图像集上的每个图像分别由512维GIST特征向量表示。对于深度学习的方法CNNH和所提出的方法,直接使用原始图像像素来描述视觉内容。
本文采用汉明排序和哈希查找。汉明排序是指计算查询与数据库中的图像之间的汉明距离,然后根据汉明距离从列表的顶部返回图像。哈希查找是指查找表在查询图像的小汉明半径r内的图像集。依据返回图像和查询图像是否有相同的标签信息评估检索性能结果。在汉明排序中,计算前M个返回图像的准确率。在哈希查找中,设置r=2,假如没有返回图像,那么相应的准确率为零。此外,平均查准率(MAP)用于评价检索方法的整体性能指标。本文根据每个测试查询图像的汉明距离对所有图像进行排序,从中选取前M个图像作为检索结果,然后计算所有测试图像的MAP值。为了能更好地展示所提出方法在图像检索上是可行有效的,给出了在不同位数下top-k的检索准确率、查准-查全率(P-R)和不同位数下汉明距离小于2的准确率上的检索性能比较结果。常用如下公式:
(13)

(14)

(15)
所有比较方法中,有一些超参数需要提前设置。本文采用交叉验证方法调整和选择超参数。本文中的超参数β和γ在MNIST和CIFAR-10两个图像集中都设置为β=γ=10-3,学习率η设置为0.005。
3.2 实验结果与分析
首先,通过实验从前M个图像的MAP来评价比较方法在图像检索中的整体性能。对MNIST和CIFAR-10两个图像集,M设置为1 000,哈希码的长度设置为12、32和48。从表2、3给出的不同方法的MAP值的结果可以看出:与其他几种主流方法相比,本文方法具有显著优势,采用标签信息的监督方法优于无监督方法。与浅层哈希方法相比,具有良好表示能力的深层架构的CNNH和本文方法表现较好,显示了深层特征的优点,与现有的研究结果一致。最后,与CNNH相比,由于本文方法考虑了分类误差和量化误差,MAP值明显更高。特别地,在CIFAR-10数据集中MAP比CNNH方法提高了15%左右。独特的框架带来了大的改进,包括特征学习,哈希函数学习和分类同时进行,这3项任务可以相互促进,以改善结果。以上结果证实了所提出方法的有效性。
图2、3分别给出了在MNIST和CIFAR-10数据集上的其他检索性能比较曲线,得出与表2、3类似的结论。本文方法明显优于其他几种主流哈希方法,这是因为所提出的方法同时考虑了最小化的分类误差和量化误差,学习到的哈希码具有判别力。
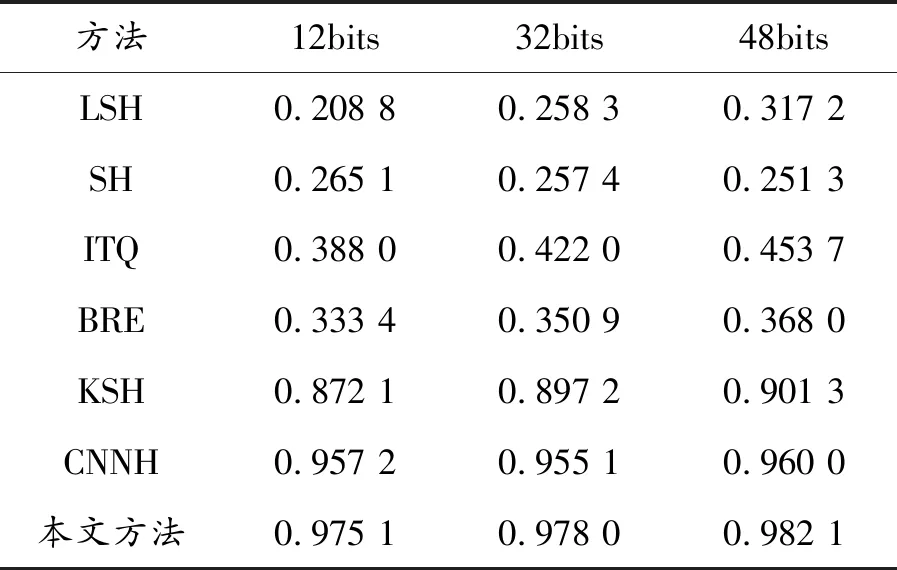
表2 数据集MNIST上不同哈希码位的MAP值
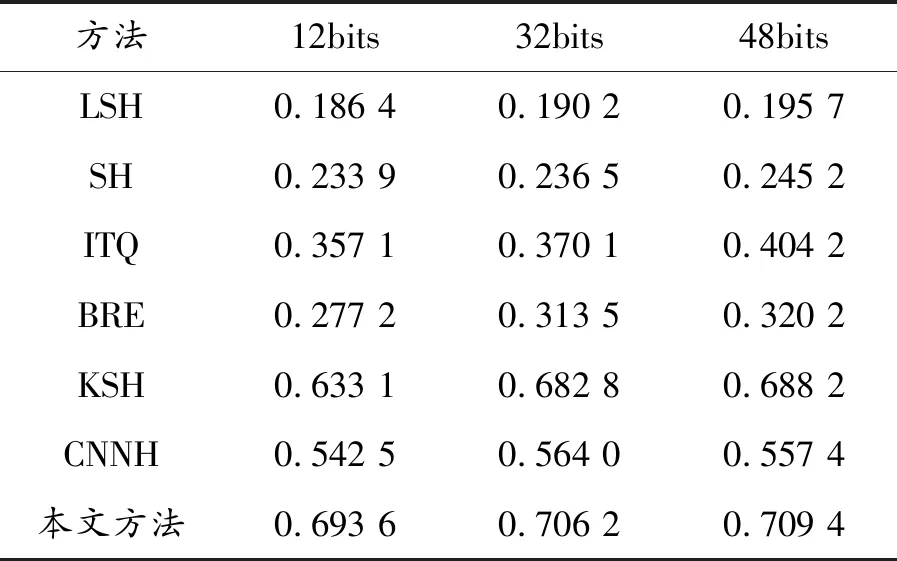
表3 数据集CIFAR-10上不同哈希码位的MAP值
参数γ通过交叉验证来调整分类误差和量化误差的相对重要性,且当MNIST图像集的γ=10-2,CIFAR-10数据集的γ=10-3时获得最佳结果。可以得出:为了发现有判别力的信息,分类标准比量化损失更重要。
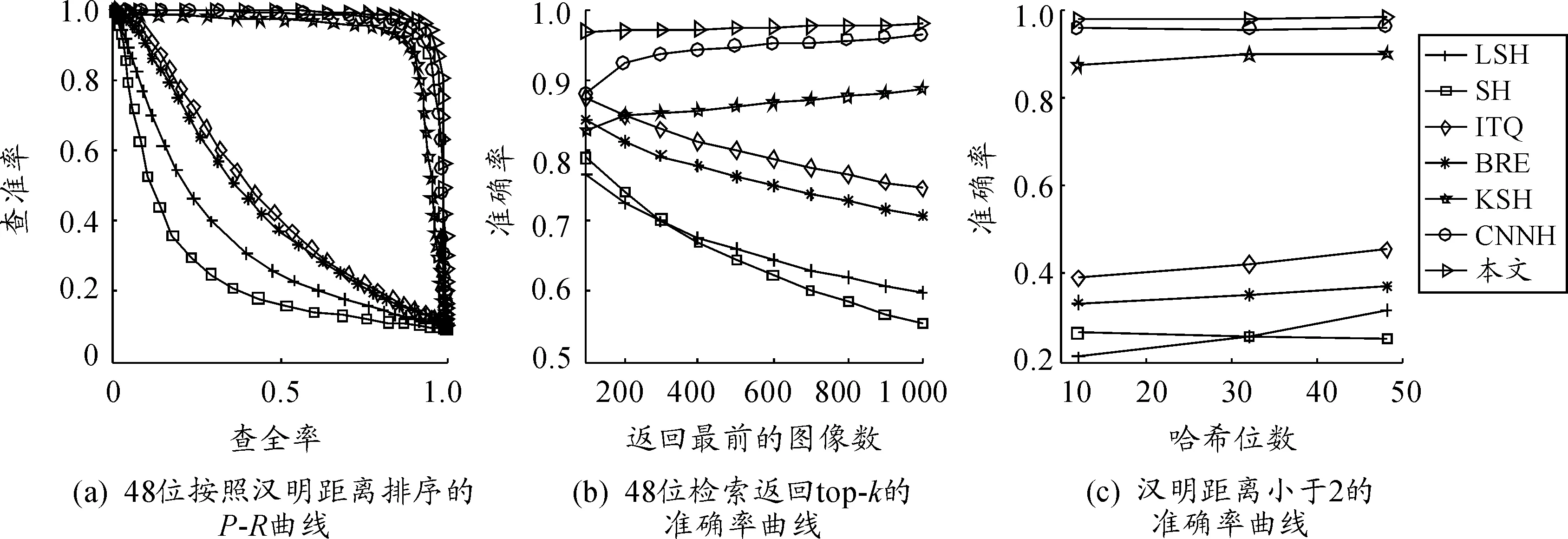
图2 在数据集MNIST上的对比结果
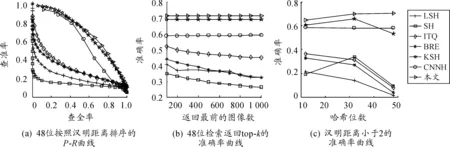
图3 在数据集CIFAR-10上的对比结果
根据表2、3以及图2、3的实验结果,可以得到以下结论:① 该方法在MNIST和CIFAR-10这两个图像集上实现了最佳性能;② 深度神经网络哈希方法的结果优于人工设计视觉特征的浅层方法;③ 所提出的深度哈希方法优于另外一种CNNH的深度哈希方法;④ 实验结果显示有监督的哈希方法优于无监督方法。上述实验结果表明:在同一个学习模型中统一学习哈希函数和分类是有效、合理的。由监督信息学习的哈希码可以更好地获得图像之间的语义结构,从而得到更好的检索效果。
3.3 本文在图像检索中的应用
利用深度哈希卷积神经网络能够较好地提取图像的特征,实现图像之间的相似度计算,进而返回与检索图像相似度较高的图像。本文将该方法用于Metel多媒体教学资源平台的图像检索中。
3.3.1 Metel多媒体教学资源平台的特点分析
Metel多媒体教学资源平台(http://www.metel.cn/)是全球最大的高校课程资料库。在该平台的图像资源里,有很多专家教授的人脸图像,他们的课程放在Metel平台上等待学生学习。
通过调研发现学生们很少访问该网站,老师提醒可以到某些数字资源平台上去看英文资料,学生由于没有发现感兴趣的课程而逐渐淡忘了。一方面是学识渊博的教授,另一方面是知识相对贫瘠的学生,在这种情况下开发一个以人脸搜索为主的Metel多媒体教学资源图像检索系统,使学生可以从海报、网站等渠道通过拍照、下载等方式获得教授的照片,然后通过图像检索系统和教授的照片检索到该教授的课程资源,从而快速认识教授,了解教授,然后顺理成章地学习教授的课程。
3.3.2 图像检索系统流程
本检索系统支持基于深度卷积神经网络的图像检索。图像检索流程如图4所示。
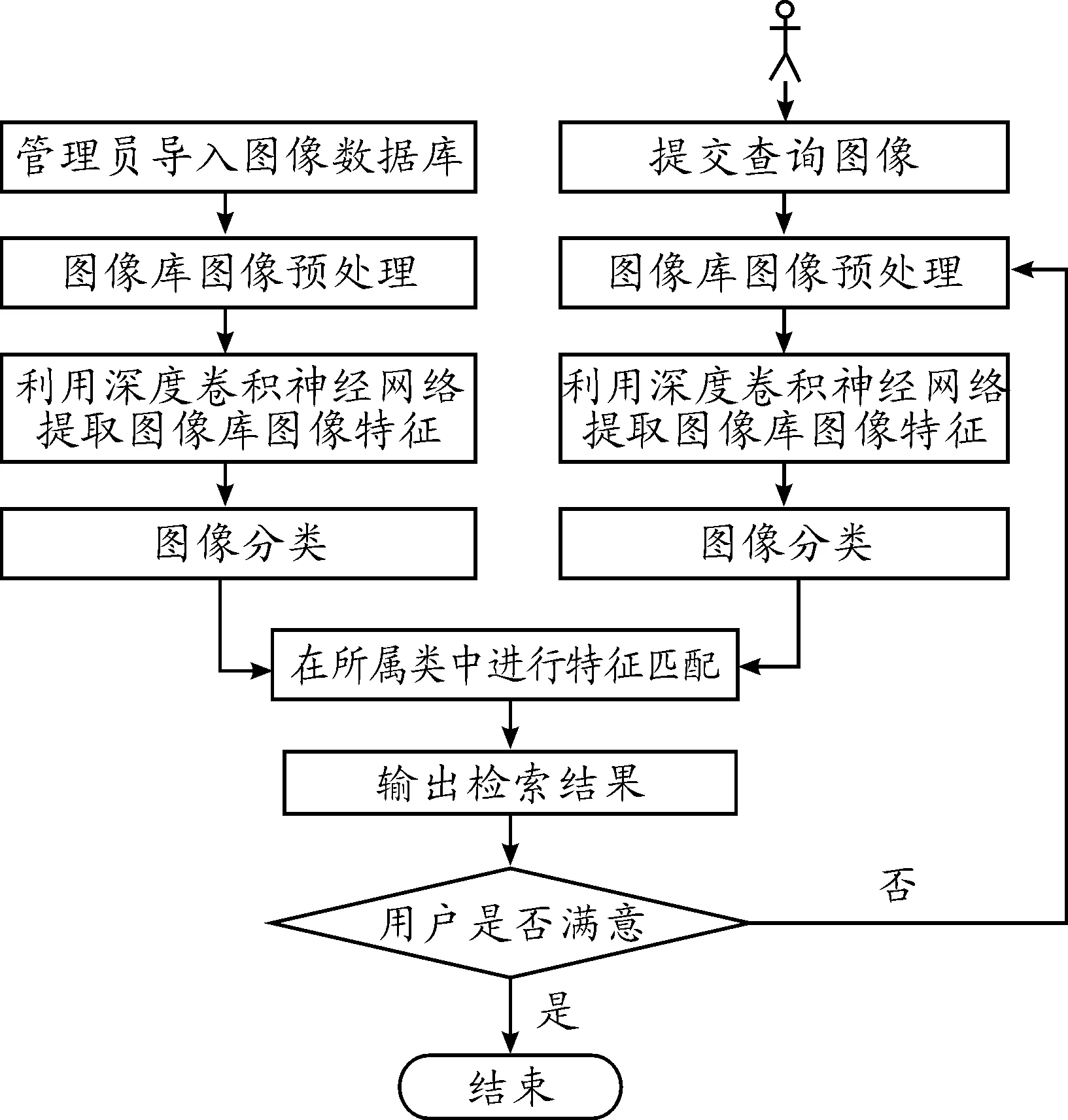
图4 图像检索流程
在图像检索完成后,用户选择任一检索结果,可以看到该图像链接的互联网上的内容。Metel多媒体教学资源平台检索结果及相关链接如图5所示。
3.3.3 图像检索应用性能评价
由于图像检索的匹配准则的选择具有很强的主观性,因而需要一个指标体系来评估图像检索系统性能的优劣,本系统采用常用的查全率和查准率作为性能指标。由于一次检索并不能反映系统的检索性能,因此,根据每次的检索结果,统计检索结果和图库中同类图像的数目,计算出每次检索结果的查全率和查准率,再对多次检索后得到的查全率和查准率进行平均化处理,得到平均检索性能。Metel多媒体教学资源平台的平均检索性能如图6所示。

图5 检索结果及相关链接
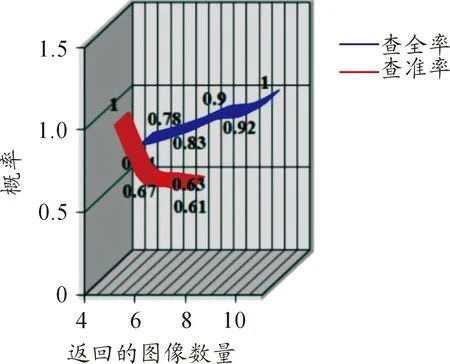
图6 平均检索性能
4 结束语
本文提出了一种基于分类误差和量化误差的深度哈希模型,采用共同学习判别特征表示和紧致二进制哈希码,通过优化定义的分类误差和量化误差的目标函数,学习的哈希码具有很强的判别力,提高了图像的检索性能。在MNIST和CIFAR-10两个图像集上的实验结果表明:本文方法与其他几种主流哈希方法相比具有更好的检索性能。最后将本文提出的深度卷积神经网络应用于Metel多媒体教学资源平台的图像检索中,表明检索性能较好。
