基于SOM神经网络的网络舆情信息分类模型
2019-04-11胡欣杰
胡欣杰,路 川,齐 斌
(航天工程大学, 北京 101416)
随着互联网技术的快速发展,网络成为人们工作和生活不可缺少的工具,使用互联网的用户呈现快速增长的趋势,公众在互联网上发表言论的活跃程度空前高涨,网络媒体成为继电视、报纸、广播之后的“第四媒体”。根据CNNIC第42次中国互联网发展状况统计报告,截止2018年6月,我国网民规模为8.02亿,手机网民规模达7.88亿,舆论观点、意见、情感态度等信息都可以在网络上充分表达。舆情是指在一定的社会空间内,围绕中介性社会事件产生及发展变化,民众对社会管理者产生和持有的社会政治态度[1]。网络舆情是人们通过互联网表达和传播的各种不同情绪、态度和意见的总和[2],在传播、演化和形态上有四个特点[3]:一是传播速度快,网络舆情通过网络,以网页新闻、论坛等形式同时被人浏览、讨论和发表观点,其传播速度之快其他媒介无法企及;二是形态多样,网民在网络上不受约束地发表各种观点、态度和看法,形成了各种形态的舆论;三是传播广泛,网络环境的复杂性使得网民分布在世界各地,各种类型的网民都可以对一个舆情发表观点,通过网民的讨论转发能快速传播至世界各地;四是事件突发,由于网络遍及世界的各个角落,无论在什么地方,一旦出现突发情况,通过网民的讨论转发及传播,事件会被不断地放大,迅速成为网络舆情,引发全社会关注和讨论,因此研究网络舆情检测技术,构建舆情监测系统是非常重要的,是构成国家和军队安全的重要装备。
1 网络舆情信息分类方法
有效地监测网络舆情信息的途径是首先进行网络舆情信息的采集,之后对舆情信息进行预处理,即对采集到的信息进行文本的分析和归类,主要采用的技术有舆情信息的分词、分类聚类、文本的表示与主题发现、话题的识别与跟踪、文本信息的情感性分析等。分词是将连续的字序列信息按照一定的规则分解成词序列,实现信息按词识别,目前已有较为成熟的分词系统,但随着语言的复杂化,要解决多语言的分词方法、词性的标注、歧义词处理和识别等问题;分类聚类是对采集的数据进行归类处理,实现信息按照类别的划分,分类和聚类的方法很多,其目的是实现聚类分类的准确率和高效率;文本表示与主题发现是对各种类型的信息进行文本归一化处理,概括出信息的主题;话题的识别与跟踪是指自动识别新话题和持续跟踪原有的话题;文本信息的情感性分析是指根据文本的观点性词语,分析和总结网民主体的态度和倾向性[4-5]。
舆情信息的分类是指预先定义好文本的类别,对大数据文本进行高效快速的分类,而舆情信息的聚类无需事先定义类别,通过聚类算法划分出群和类别,后者更具有自主学习性,二者都属于舆情信息分类的大范畴,针对信息属性的不同采用不同的方法或二者联合使用[6]。舆情信息文本分类的方法有基于统计的文本分类方法、基于连接的文本分类方法和基于规则的文本分类方法。
基于统计的文本分类算法有朴素贝叶斯算法和支持向量机分类算法,朴素贝叶斯分类算法是以贝叶斯定理为基础,对于文本相互独立,取后验概率最大的一个或几个类别作为文本最终类别,面对网络舆情大数据,使用朴素贝叶斯分类算法训练集的完备性较差,需要花费大量的时间运算和存储管理,时间效率降低;支持向量机算法是基于统计学习理论的机器学习方法,计算相对简单,主要是通过寻找结构化风险最小来提高学习的泛化能力[7]。
基于连接的文本分类方法有人工神经网络算法,人工神经网络是模拟人脑神经系统进行迭代运算,其间输入神经元和输出神经元有大量的节点相互连接,具有自学习和联想存储功能,具有高速寻找最优化解的能力。
基于规则的文本分类方法主要有决策树方法,根据已知各种情况发生的概率,通过训练数据形成决策树,实现对未知数据的分类,决策树算法可读性好、效率高、一次构建重复使用。
文本聚类也是文本分类最有效的方法[8],文本聚类有多种算法:层次聚类算法,可实现自底向上的聚类,也可以实现自顶向下的聚类,此方法对聚类的对象属性没有要求,聚类粒度灵活,可大可小,但不适应动态聚类;基于密度的聚类方法,是通过考察一个临近区域的某个点的密度是否超过一定的阈值,如果超过,则将其纳入聚类中;除此之外还有基于网格的聚类算法、基于模型的聚类算法如SOM神经网络聚类算法等。各种算法有其优缺点,根据应用需求加以选择。
2 改进的SOM分类模型算法和流程
SOM是自组织神经网络,非监督式学习算法,采用竞争式网络架构,其输出层神经元根据输入层神经元的数据特征,将任意维度的输入向量以非线性的投影法映射到二维或低维度的特征空间上。SOM的3层架构包括,输入层、输出层和网络拓扑层,输出层是以网络拓扑层为核心形成的输出神经元的集合。
输入层设有m个输入神经元,用输入向量X={x1,x2,…,xm}表示,每一个神经元相互独立,神经元之间连接权重相互独立,输入层神经元个数依据具体问题确定,没有限制。
输出层由n个神经元组成一维或二维平面网络拓扑结构,每一个输出神经元都与所有的输入神经元连接,依据连接权重作为神经元之间关系的强弱,输出层神经元个数依据问题确定,使用邻近区域来描述邻近神经元之间的关系,包括的参数有邻近中心C,邻近半径R,邻近距离D等。
邻近区域是以邻近中心为原点邻近半径范围内的区域;一般是以网络拓扑中胜出的神经元作为邻近中心,其计算公式如下[9]:
Ck=mink||X-Wk||
(1)
通常情况下,初始的邻近半径设置较大,随着学习训练的次数的增加不断迭代,逐渐缩小,设初始邻近半径为R0,第n次循环的半径为Rn,则n+1次的半径为γRn,0<γ<1,γ为调整系数。
邻近距离表示某个输出神经元k与邻近中心C的距离,一般用欧式距离来计算邻近距离,如式(2)所示[9]:
(2)
使用SOM神经网络进行分类的基本思想是,对于提供给网络的任意一个输入向量,确定输出的获胜神经元s,其中s=arg minc|τ-Wc|,所有的c属于δ。确定获胜神经元s的一个邻域范围,利用迭代计算各输入神经元(输入向量)与输出层处理单元间的连接权值向量,使得内神经元的权重向量向输入向量靠拢,通过竞争学习算法不断调整连接权重值,不仅获胜的神经元要训练调整权值,它周围的神经元也要不同程度的调整权值,Wc=Wc+ε(τ-Wc),所有的c属于M。以获胜神经元为中心,设定一个邻域半径R,该半径圈定的范围为优胜邻域,通过多次训练和迭代,直到输入向量与连接权重的总距离为最小时或者最大学习循环时,停止训练,形成一种分类[10-11]。
使用SOM神经网络实现网络舆情信息的分类聚类,具有简明性和实用性,具备自主学习功能,会取得较好的效果,但是SOM神经网络算法要求网络结构是固定的,不能动态改变,网络训练时有些神经元始终不能获胜,成为“死神经元”,网络连接权重的初始状态,算法中的参数选择对网络的收敛性影响较大,这样在进行网络舆情分类时,降低了分类的查全率,同时受到网络连接权重初始值的影响,查准率也受到影响,为此基于SOM神经网络进行了算法的改进,为每个输出的神经元增加一个阈值,每次使竞争获胜的神经元阈值增加,使经常获胜的神经元获胜的机会变小,避免死神经元的出现,同时为每个输入神经元都增加了学习效率和邻域区域,并按照学习时间自动调整学习效率和邻域的大小,提高了分类的准确性。改进后的SOM算法流程如下:

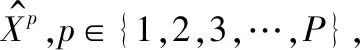


步骤5:为每个输出神经元设置阈值ρj+1=ερ,0<ε<1;
步骤6:定义优胜邻域Nj*(t),该优胜邻域为邻域中心确定时刻的权值调整域,通常设置一个较大的初始邻域,训练时随着训练时间增长逐渐收缩邻域范围;
步骤7:对优胜邻域Nj*(t)内的所有神经元调整权重:
i=1,2,…,n;j=nj*(t)
步骤8:设L=L+1,返回步骤3继续迭代;
步骤9:查看学习率μ(t)是否小于0,或者小于阈值μmin,或者循环次数是否最大为T,是,则结束,否则返回步骤3继续迭代。
3 实验验证及结果分析
衡量分类或聚类算法的优劣,最直观的方法是类内尽可能相近,类间相似度最小,使用平均正确率、平均墒、查全率和查准率均能在一定程度上反映出聚类算法的效果。
本文基于改进的SOM神经网络分类模型算法实现网络舆情分类实验,使用查全率R和查准率P作为检验本算法有效性的参数,查全率R越大表示信息分类聚类覆盖性越全;查准率P越大表示信息分类越准确。事实上,R与P之间是一个相互制约的关系,在极端情况下,只聚类出一个结果且是准确的,P为100%,R则很低,如果把所有的聚类结果都返回,R为100%,P则很低,因此P和R是一个反比的关系。R和P定义如下:
R=(聚类后正确反应主题某一个类的文档数/人工判断主题某一个类所包含的文档总数)×100%
P=(聚类后正确反应主题某一个类的文档数/聚类后输出的反应主题某一个类所包含的文档总数)×100%
以目前比较热门的芯片业“微处理器”为主题,在网络上搜索出以此为主题的网页1 880篇,随机抽取100篇、300篇、500篇、700篇,使用本文改进的SOM神经网络模型进行聚类,分别得到10、13、16、18个分类,均包含有“嵌入式微处理器”类,进行两次聚类,第1次设网络学习总的迭代次数L=15,输出层节点40×40,初始邻域半径20,学习效率为1;第2次设网络学习总的迭代次数L=20,输出层节点60×60,初始邻域半径30,学习效率为1,结果如表1所示。
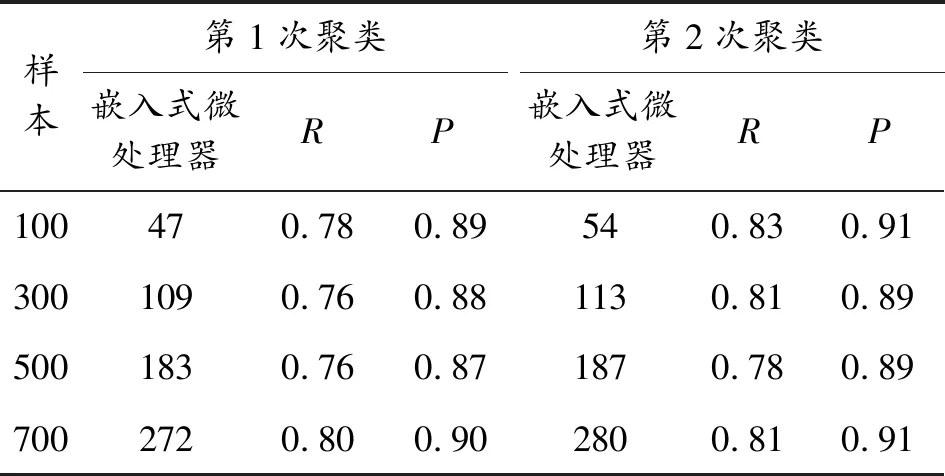
表1 基于改进的SOM聚类模型查全率R和查准率P
按照统计分析SOM神经网络算法的正确率在60%~90%之间,从上表可以看出,通过改进SOM算法,使查全和准确率均有提升;另外当使用该算法将迭代次数增加,输出节点数增加,初识邻域半径扩大,也会提高其查全和准确率。在信息检索中,查全率和查准率是相互制约的,本算法在保证较好的查全率基础上,得到了好的查准率。
4 结论
SOM分类算法用于文本的聚类的优点在于它是一个无监督的学习方法,网络拓扑结构反映了输入文本的分布情况,不需要对文本之间的相对独立性做任何假设,可以自动提供类别标注且易于可视化,但由于其网络拓扑结构的局限性,本文对此进行改进并将其应用到网络舆情信息分类建模中,取得了较好的效果。
