基于D-S证据理论的人机交互意图识别技术研究*
2019-04-08于丽平戴志鹏
赵 迪,于丽平,刘 格,戴志鹏
(湖北工业大学 机械工程学院,武汉 430068)
0 引言
目前,在人机协作(Human-Robot Collaboration,HRC)作业中,对于机器人的控制多由人直接发出控制指令。这种方式及时、易执行,但人机交互的效率、流畅性与适应性易受影响[1]。心理学研究表明当两个交互对象在进行协作时,其中某个对象总会倾向于预测交互对象的潜在动作,并根据预测动作采取相应应对措施以达到安全、正确的协作[2-3]。机器人要完成自然HRC过程的首要任务就是对人的意图进行预测[4-5]。
在现有研究中许多学者基于意图识别的自然人机协作做出了许多突破性的进展。如Song D等通过观测用户手部传递或抓取物品动作图像序列并编码,获取动作图像状态,让机器人学习用户手部交互意图[7]。Jang Y M 等提出了一种基于眼球运动模式和瞳孔大小变化的用户潜在意图识别方法,让机器人预测用户意图[8]。Wang Z等提出将意图驱动运动用意向驱动动力学模型(IDDM)进行概率模型建模,使用贝叶斯定理推断观测运动的意图[9]。Elfring J等利用增长型隐马尔可夫模型(GHMMS)总结用户的典型运动模式,与传统基于恒定速度模型相比,隐马尔可夫模型能够显著提升用户意图位置的估计[10]。Gehrig D等提出了多层次(意图、动作、运动)信息融合建模用于用户运动的意图预测[11]。
上述研究表明,机器人可以通过提取用户运动特征或者混合用户运动交互信息,实现用户交互意图的预测或识别。本文通过构建用户交互意图模型,并利用基于Dempster-Shafer (D-S) 证据理论的意图识别算法判断机器人对人的抓取意图,从而预测用户的实际意图表达,如图1所示。

图1 基于D-S证据理论的意图判断流程图
1 用户交互意图模型
机器人对用户意图的预测,不是通过指令输入或人机问答,而是通过感知、分析交互环境及用户动作产生的信息进而给出反馈。机器人对用户意图的感知与识别的前提是对用户交互意图进行建模,通过意图模型去理解用户交互目的,从而有效提高人机交互效率。本文设计了适用于人抓取物体操作时的意图模型,其模型表述如下:
I={Ro,Hu,G,Be,Op,Hg,Rh}

表1 用户交互意图模型参数表
本文将机器人相机视场中人体上肢运动的终点作为预测运动目标点。预测目标点位置的物体被定义为用户可能的抓取操作意图,同时也是人机协同操作中机器人的协同抓取意图。
G={g1,g2,…,gi}
其中,gi∈R3,i=1,2,3,…,N。
gi(gxi,gyi,gzi)表示用户抓取意图,(gxi,gyi,gzi)表示目标在机器人运动坐标系的空间坐标,G是所有潜在的意图目标集。为便于实验可行性,限定抓取意图g只能是有限目标集G中的一个。本文未提及的参数设为默认值,取1。
2 基于D-S证据理论的意图识别
2.1 数据映射
人机交互中用户与机器人同处于同一三维工作空间,机器人通过深度相机捕捉用户抓取操作的实时运动轨迹。为便于机器人实时抓取操作,需要将深度相机空间坐标与机器人运动空间坐标进行映射[13]。Fc=(xc,yc,zc)为深度相机空间坐标,Fr=(xr,yr,zr)为机器人运动空间坐标。

深度相机捕捉深度图像信息Fc,彩色相机捕捉交互彩色图像信息FI=(u,v)。为了进行交互信息融合,需要将深度相机捕捉的用户骨骼空间坐标及目标物体空间坐标与彩色相机捕捉的图像坐标分别进行映射。因为深度图像与彩色图像分辨率及坐标系原点不统一,故可通过以下方式进行坐标转换:

2.2 意图表达因子
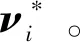
用户手部运动轨迹与潜在目标的欧氏距离用Si表示,i表示潜在目标序号,gi(gxi,gyi,gzi)表示通过主动识别潜在目标在深度相机空间的坐标,t(tx,ty,tz)表示用户手部运动轨迹上前端点在深度相机空间坐标。
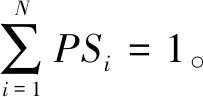
用户手部运动轨迹的速度矢量与目标的方位角用θi表示,手部运动轨迹点与潜在目标的矢量定义为τ,
τi=[gxi-tx,gyi-ty,gzi-tz]T
用户手部运动轨迹的速度矢量ν可以通过连续两次运动轨迹点给出,t′(tx′,ty′,tz′)表示前一帧手部运动轨迹点坐标。
ν=[tx-tx′,ty-ty′,tz-tz′]
其中,
A=(gxi-tx)(tx-tx′)+…
(gyi-ty)(ty-ty′)+(gzi-tz)(tz-tz′)
在交互过程中,用户手部运动运动轨迹的速度矢量与目标的方位角θi越小,表示手部的运动趋势越可能靠近该目标,潜在目标被抓取的概率Pθi越大,Pθi∝1/θi,如图2所示。
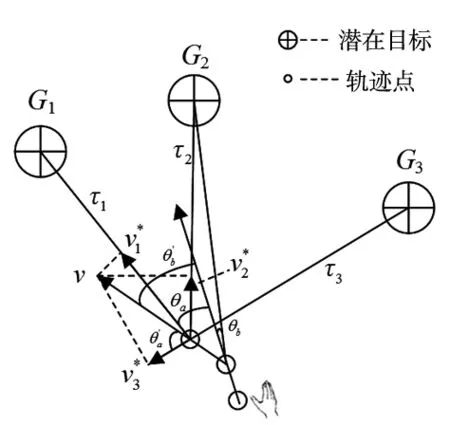
图2 手部运动轨迹与潜在目标之间的关系

在交互过程中用户手部运动轨迹速度矢量与潜在目标之间的相对运动速度矢量可用νi*表示,ν*=ν×cosθ,如图2所示。
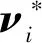
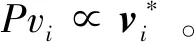
2.3 基于D-S证据理论意图识别
集合G称为识别框架或假设空间。
在用户手臂运动过程中,目标被抓取的概率用P表示,Pi表示第i个目标在此时刻基于D-S证据理论决策后被抓取的概率。
P={P1,P2,…,Pi}
用户意图表达因子在手臂触点抓取运动过程中某时刻对于Θ中潜在目标的概率分布如表2。

表2 目标证据概率分布表
S,θ,ν分别为意图表达因子:在手臂运动过程中手部运动轨迹与潜在目标的欧氏距离,手部运动轨迹与潜在目标的方位角,手部运动轨迹相对于各目标的速度。
PSi、Pθi、Pνi分别表示目标i在意图表达因子S、θ、ν评估下,该目标被抓取的置信度。
利用D-S证据理论结合律,运用Dempster证据合成规则计算关于各目标的组合mass函数[14]:
(PSi⊕Pθi⊕Pνi)(gi)=((PSi⊕Pθi)⊕Pνi)(gi)
证据合成完成,得到最终多证据融合对于各目标的mass函数集P={P1,P2,…,Pi}。

其中,K为归一化常数,
2.4 算法优化
为进一步优化算法,本文增加了概率选择环节。当某时刻融合多意图表达因子后得到某一目标被抓取的概率大于等于0.5且保持持续增长时,系统可直接判定该目标为抓取目标,并将其概率输出为1,从而排除其他目标,如下式。
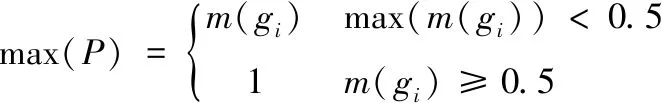
若出现系统无法识别当前意图时,此时取前一帧意图作为本周期意图。

最终预测交互意图为Gt=gi。
3 仿真验证
本文设计了机器人判断人抓取物体意图的实验来验证基于D-S理论融合意图表达因子的意图识别算法。系统配置如下:Microsoft Kinect 2.0体感控制器采集人体骨骼数据;Visual Studio 2013+Kinect for Windows SDK V2.0+OpenCV读取人体骨骼数据,画出人体骨骼特征点,并实时跟踪记录骨骼特征点数据。数据采样周期为1/30 s。其中通过控制器视觉主动捕捉用户抓取意图目标的空间坐标与数量,并利用OpenCV转换到实时交互界面。
该实验台上随机放置4个待抓取实验目标g1、g2、g3,g4(自左向右),进行抓取验证,随机抓取其中一个目标,监测实验数据,完成实验过程。实验过程如图3所示。
图3中4张图依次为手臂运动过程中算法对于用户交互意图预测,绿色圆圈表示其中的目标即为用户抓取意图,据图3可知实验中用户抓取意图为g3。图中红色曲线为用户手臂实际运动轨迹,黄色虚线代表用户手臂运动轨迹端点指向潜在目标的矢量。

(a)第3帧 (b)第13帧

(c)第23帧 (d)第33帧 图3 不同时间序列(帧)下抓取目标时的意图识别实验
在抓取实验过程中,用户意图实际是由多个意图表达因子共同表达。图4表示了在抓取g3时,分别基于不同意图表达因子及利用D-S证据融合的多意图表达因子意图识别算法中的各目标抓取概率序列。
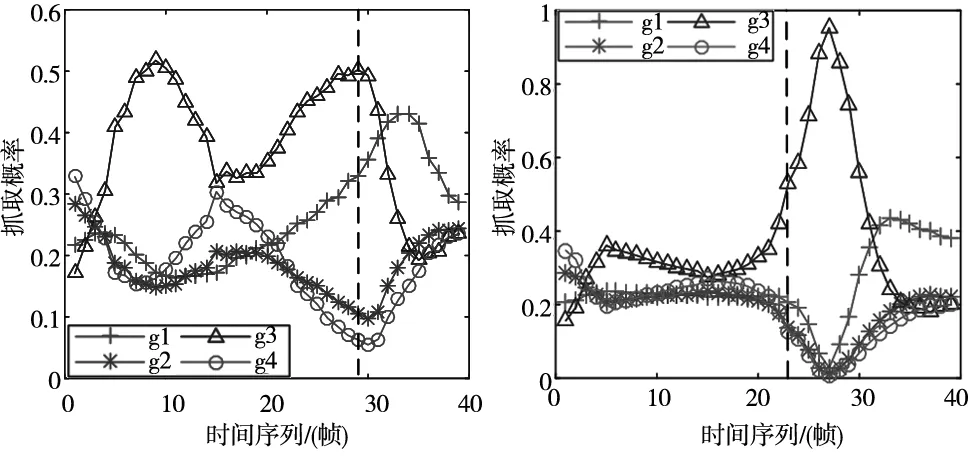
(a)基于相对速度v*的目标 抓取概率变化 (b)基于方位角θ的目标 抓取概率变化
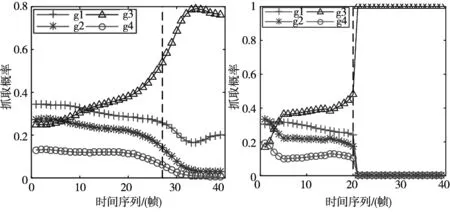
(c)基于欧氏距离S的目标 抓取概率变化 (d)基于意图识别算法的目标 抓取概率变化图4 在不同意图因子判断下各目标抓取概率
虚线表示在不同意图表达因子下能判断抓取意图的帧数。可以得到如下结论:
在手臂运动过程中,基于相对速度v*的目标判断需要近30帧,前期真实目标和干扰目标概率波动较大;基于方位角θ的目标判断需要近25帧,前期真实目标和干扰目标概率较为接近,区分不强。两者后期实际目标概率均下降很快,故识别效果很差,甚至容易造成误判。
虽然基于欧氏距离S的目标判断能较准确地识别出真实目标,但其收敛速度较为缓慢。而基于多意图表达因子的目标判断能快速且精准得在20帧左右识别出真实目标。
相比单意图表达因子目标抓取概率实验,多意图表达因子融合意图识别算法能快速收敛,在保证准确性的基础上能够将预测时间减少25%以上,进而也验证了算法的有效性与正确性。
4 小结
本文尝试建立了人抓取物体操作时的意图模型,通过深度相机获取人的运动,以自然交互的方式进行意图表达,采用D-S论据融合意图表达因子的意图识别算法。用实验验证,该算法相比于单意图表达因子能更快速收敛于真实意图,故在意图识别上具有较高的准确性和可信性,在人机交互中具有实际应用价值。
