基于结构-语义图的短文本分类
2019-03-12胡代艳
胡代艳
(四川大学计算机学院,成都 610065)
1 研究现状
考虑到短文本的特点,首先,短文本没有足够的上下文信息也没有足够的统计信息量;其次,也由于没有足够的信息量,难以识别和处理短文本中的语义模糊。所以处理短文本分类的方法主要着重于扩展文本特征,现有的短文本分类算法主要从两个方面来丰富文本。第一类是基于内部资源的方法,通过使用规则或隐藏在当前短文本中的统计信息来扩展特征空间,S.Zhang[1]等提出了一种基于“信息路径”的方法,利用短文本中子序列的相关性传递来进行分类,该方法不需要外部知识库的复制,但是过于依赖数据集,如果数据集中没有相应的信息的路径,将会影响分类结果,张勇[2]提出基于词性的特征选择方法结合LDA主题模型的方式来进行文本分类,第二类是基于外部资源的方法,基于外部资源的分类方法又包含基于搜索引擎和大规模语料库两类,其中Sahami M[3]通过搜索引擎将短文本作为关键字进行检索,用搜索结果对短文本进行扩充,由于该方法依赖于搜索引擎的匹配规则,对分类结果的影响较大,同时搜索过程会消耗大量的时间,实时性较差;另一种是基于大规模语料库,如维基百科、Probase[4],M.Shirakawa[5]提出了一种基于维基百科的语义相似度测量方法,它将维基百科中的实体添加到文本中作为其语义表示,并使用实体向量来计算语义相似性,Peipei Li[6]通过Probase引入更多的语义来弥补数据稀疏性,通过最大概率的概念簇来消除歧义,Wen Hua[7]利用Probase提供的语义知识,用知识密集型方法重新定义了文本分段,词性标记和概念标记。近年来,也有学者对图结构文本表示方法进行了尝试和研究。如Svetlana Hensman[8]提出基于辅助词典Verb Net和Word Net的文本概念图表示模型。Uchida H[9]提出了用于多文档摘要提取的文档图模型表示方法。Schenk⁃er A[10]提出了一种较为简单的基于图模型的文档表示方法,但是他们的模型主要建立在文本特征词条的位置布尔关联的基础上,并没有考虑相邻词间不同词性的相互影响。
2 基于结构-语义图的算法
随着科技的发展,互联网上的信息越来越丰富,但是网上的数据主要是由自然语言表示的。那么如何衡量两个文本的相似性?例如“the President of America”和“Chief Executive”没有相同的单词,但是这两者表示了相似的含义,它们均是指美国总统,这就上升到了概念层次,不止在词语层面来考虑两者的相似性,由此本文引入了概念语义网络Probase;又如“band for wed⁃ding”和“wedding band”由于词序不同,这两者所表达的含义也不同,前者是婚礼乐队而后者是结婚戒指,又如“watch harrybotter”和“read harrybotter”,对于 Harrybot⁃ter而言,前者是电影而后者是书籍,说明了词与词之间的相互影响。针对上述短文本中内部结构对语义的影响,结合外部语义网络来提高短文本的分类性能。本文所提出的短文本分类算法步骤如图1所示。

图1 短文本分类算法流程图
2.1 基于Proobbaassee的语义扩展
Probase是由微软开发的概念知识库,该知识库中的数据是通过动态的无监督机器学习算法从大量的网页中学习得到的,其中包含了540万个概念,相较于现有的知识库(如Freebase约有2000个概念,CYC约包含12万个概念),Probase蕴含的知识更加丰富,并且以概率的形式来表示实例和概念之间的相关性,这样能够更为直观地表示事物之间的关联度。于是本文选择用Probase知识库来对短文本进行语义扩展。在Probase中用概率来表示实例和概念之间的典型性,如公式(1)和(2)所示。

本文的短文本分类算法通过图结构来保留短文本中的内部结构,同时引入Probase对短文本进行语义扩充。在短文本的组成中,名词、形容词、动词等词性的词语对文本的语义分析有重要作用,但是在Probase中只包含了名词词性的词语,但是为了保留其他词性的语义特征,通过大量语料,提取名词和动词以及名词和形容词的常用搭配生成了相应的动词|形容词-概念词典vadj-C。所以对于一个给定的短文本,可以用特征向量Vd={ }T1,T2,…,Tm={tij|1≤i≤m,1≤j≤ni}表示,其中Ti表示文档d中第i个句子,tij为名词、动词和形容词词性的单词或短语。
(1)基于Probase的术语识别
为了识别短文本中的术语,首先使用斯坦福自然语言处理工具Stanford CoreNLP对短文本进行语法分析以及去除停用词,然后通过逆向最大匹配算法(BMM)获取所有的术语,并保留语序,如下语句(识别出的术语用下划线标记)。
Apple had agreed to license certain parts of its GUI to Microsoft for use in Windows 1.0.
接下来,对于识别出来的术语,我们需要定义的规则来区分名词术语的类型,如公式(3)所示,其中|I(t)|表示术语t在Probase的concept中出现的频率,|C(t)|表示术语t在Probase的instance中出现的频率,,由此短文本的特征空间可以表示为

(2)基于概念簇的特征扩展
在上一个步骤中,获取到了所有的术语,并区分了其类型,对于instance类型的术语可以通过Probase获取其Top10的概念生成名词相应的概念特征向量,对于名词和形容词词性的术语通过词典vadj-C获取其Top10的概念生成相应的概念特征向量,短文本的特征向量可表示为然后利用概念聚类算法[11]对概念进行聚类生成概念簇,一个概念簇是由一个概念集合构成的,对于一个概念簇 VCL={C1,C2,…,Cn},第 i个概念 Ci在该概念簇中的权重 wi=p(,最终获得短文本的特征向量可表示为公式(4)。

2.2 结构--语义图的构建
传统的基于统计的文本分类方法由于没有保留文本本身的结构信息,可能造成语义缺失。文本结构信息如术语出现的先后顺序,同个文本中句子间的联系等。对于文本而言,不同的语序,不同的文字组织结构可能会产生完全不同的语义。本文利用图结构来保留短文本的内部结构信息,一个图结构是由节点、边、边与边之间的权重组成的结构。将文本与图结构相对应,将文本的特征抽象为节点,特征之间的邻接关系或句子与句子之间的关联关系抽象为边,特征与特征间的语义相关性则为边与边间的权重。
算法1:结构-语义图的构建算法
输入:短文本的概念簇特征向量Vd;
输出:短文本di的图结构
算法:
1. 将短文本按句子划分得到序列S={S1,S2,…,Sk};
4. 初始化节点集合Vdi,边集合Edi和权值集合Wdi;
5. While S序列中还有未处理的句子
6. 将句子si的特征作为节点添加到图结构中,节点的权值为该特征的权值wj;
7. 将句子中的词序关系作为边添加到图结构中,如 clij和 clij+1的词序关系由 ej,j+1表示,该边的权值为 clij和clij+1语义相关度wij;
8.End While
上文描述了图模型的构建方法,并将短文本的结构-语义图存储在文件中,构建好了结构-语义图模型后,通过比较计算两个图结构之间的相似度,构造分类器完成分类。
3 实验结果与分析
3.1 实验数据
实验数据主要来自于TagMyNews,该数据集是从流行新闻网站(nyt.com,usatoday.com和reuters.com)的RSS提要中提取的32k英文新闻,包含了32600篇英文RSS新闻,包含了7个类别,每篇文档由标题和描述组成,平均文档长度为14.9。

表1 实验数据集
3.2 实验分析
本文主要以精确率和召回率作为评价指标,根据分类器在测试集上的预测结果分为4类:
●TP:将正类预测为正类数;
●FN:将正类预测为负类数;
●FP:将负类预测为正类数;
●TN:将负类预测为负类数。
两种评价指标的定义如下:
精确率:

召回率:

其中召回率用于衡量分类器是否能找全该类的样本,精确率用于衡量分类器的精确性,为了兼顾两个评价指标,引入F1值:
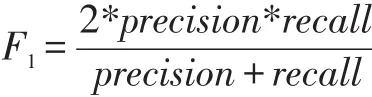
本次实验采用了与SVM算法的对比实验,实验结果如图 2、3、4 所示。
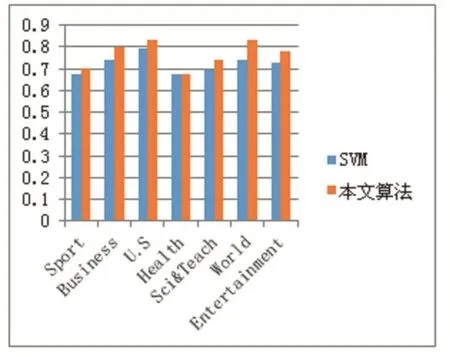
图2 精确率对比

图3 召回率对比

图4 F1平均值比较
通过以上的对比实验可以发现,基于结构-语义图的分类器相较于基于向量空间模型的SVM算法,具有更好的性能,F1值有所提高。从实验结果来看,本文提出的算法在短文本分类的效果上有所提升,由此可见,在引入外部语料库的同时,用图结构保留短文本的内部结构信息,充分利用了内外部信息对短文本的特征进行扩充,是有助于提高短文本分类的性能的,同时也说明了本文提出的基于结构-语义图的短文本分类算法的合理性。
4 结语
本文针对短文本分类,提出并设计了结构-语义图的短文本分类框架。该框架针对短文本的特征,用图结构最大限度的保留了短文本的内部结构信息,其中考虑了不同词性的相邻词对名词语义的影响,同时本文引入了第三方语料库Probase来扩充短文本的特征,结合内部结构和外部语义网络,在保留内部结构的同时引入丰富的知识来提高短文本分类准确性。从实验结果来看,在短文本分类的性能上有所提高,但是在图结构的处理上还有一些问题,如短文本中提取出的特征点较少会使得图结构之间的重叠部分较小,因此还需在图结构上进一步优化。
