人工蜂群算法优化的特征选择方法*
2019-02-13巢秀琴
巢秀琴,李 炜
1.安徽大学 计算智能与信号处理重点实验室,合肥 230039
2.安徽大学 计算机科学与技术学院,合肥 230601
1 引言
随着大数据时代的到来,人们获得的数据量和数据维数日益庞大,维度灾难随之而来[1],高维数据中往往包含成百上千个特征,然而,这其中包含的许多无用以及被噪声污染过特征,不仅对分类算法的效果没有帮助,反而会增加计算复杂度和算法执行的时间,给数据的分析和整理带来极大的困难。特征选择就是为了能够有效地解决这些问题而提出的一种方法,其从原始特征集中提取特征子集,去除冗余特征和无关特征,实现特征维数的有效约减,提高后续数据处理的效率和预测准确率[2]。
按照特征子集生成方式,特征选择方法可以分为三类:(1)全局最优;(2)启发式搜索;(3)随机搜索。全局最优方法属于穷举类的算法,通过遍历特征空间内的所有组合进而找到最佳的子集组合,启发式搜索包括序列向前和向后选择,时间复杂度较全局搜索小,随机搜索包括随机方法和概率随机两种方法,该方法结合进化算法对所有的特征子集进行进化选择,能够很大程度上加快搜索的进程。
人工蜂群算法(artificial bee colony algorithm,ABC)是一个由蜂群采蜜的行为所启发的群智能进化算法[3],在2005年由Karaboga小组为优化代数问题而提出。该算法通过模拟自然界中蜂群的采蜜行为来寻找优化问题的近似最优解集合,具有初始参数少,步骤简单等优点。
由于特征选择中存在两个相互矛盾的目标,即最小化分类错误率和最小化特征子集大小,因此,特征选择可以看作一个多目标优化问题,可以使用多目标人工蜂群算法来解决此类问题。Palanisamy与Kanmani在2012年首次将单目标人工蜂群算法用来解决特征选择问题[4],但是该算法采用传统的单目标人工蜂群算法,仅仅使用分类准确率作为评价标准,在数据量日趋庞大的现代,仅仅优化一个目标忽略了选择特征数在实际应用中的重要性,无法满足不同的优化需求。在该算法的基础上,2017年,Hancer和Xue首次将改进的多目标人工蜂群算法应用到特征选择中,提出了一种基于人工蜂群优化的pareto前沿面特征选择方法[5],该算法通过改进算法中的引领蜂和跟随蜂变异算子,以达到同时优化分类准确率以及减小选择特征数的目的。Xue的算法中首次将多目标算法应用到特征选择中,并且该算法考虑到了特征选择问题中特征数的同等重要性,但其存在着后期收敛压力偏小导致算法收敛过慢,无法找到算法最优值点的问题,同时算法在处理局部最优值点上存在不足而引起收敛精度下降。
由于Knee Points在提升算法进化速度以及最后得到的结果方面具有优越性[6],其对于增强特征选择分类准确率和减小分类特征数也具有一定的作用[6],因此,本文设计了一种基于Knee Points的改进多目标人工蜂群算法,将Knee Points引入引领蜂以及改进跟随蜂过程中,在两个阶段优先开采Knee Points,并改进算法适应度值的计算,在算法执行过程中采用外部集合记录与维护pareto最优解。在11个UCI分类测试数据集上的结果显示,本文提出的基于改进多目标人工蜂群算法的特征选择方法对提升分类准确率以及消减数据集冗余特征数具有显著作用。
2 基本内容介绍
2.1 人工蜂群算法
人工蜂群算法是受蜜蜂采蜜机制启发而提出的一种群智能进化算法,在原始ABC算法中蜂群一共分为引领蜂、跟随蜂和侦查蜂3类。蜜源代表了优化问题的一个可行解,蜜源的质量对应可行解的适应度,也就是目标函数的函数值[7]。
首先初始化大小为SN的种群,种群初始化公式如式(1)所示[8]。

式中,j=1,2,…,D;i=1,2,…,SN;SN为蜜源的个数;D为个体向量的维度;lbj为第j维下界;ubj为第j维的上界。初始化后,种群中3类蜜蜂开始搜索[9]。
(1)引领蜂。它的数量是总共蜜源数量的一半,并一直处于较好的一半蜜源位置上,以获得最好的解,它们在自身蜜源左、右按照式(2)开采蜜源[10]:

式中,Vij为新蜜源的位置;xij和xkj分别为蜜源i和蜜源k的第j维位置;Rij为[-1,1]间的随机数[11]。
引领蜂找到新蜜源后,依照式(3)计算其适应度,并留下适应度好的蜜源。

式中,f(xi)是蜜源xi对应的目标函数的函数值。
(2)跟随蜂。该类型蜂群根据式(4)计算每个蜜源被选择概率[12],并采用轮盘赌方式选择较优蜜源并在其附近位置按照式(5)进行搜索,产生新蜜源[13]:

式中,k为依照轮盘赌方式选择的较优蜜源,g为随机选择的不同于k的蜜源。
(3)侦查蜂。若某一蜜源连续limit代没有被更好的解取代,则启动侦查蜂,按照式(1)随机产生新蜜源代替原蜜源[14]。
ABC算法通过这3种蜂群对解空间的反复搜索、转换最终获得最优解[15]。
2.2 多目标优化
在工程应用和决策过程中遇到的大多数问题皆可归纳为多目标优化问题,由于多目标优化问题的研究具有较强的实用性和较高的研究价值,因此对于该类问题的研究显得十分重要。多目标优化问题可描述如下[16]:

式(6)中,fi(x)表示优化问题的第i个目标函数,n表示目标函数的数量,x表示优化问题中的自变量,ub、lb分别表示自变量x的上下限约束,等式Aeq×x=beq表示对自变量x的线性约束,不等式A×x≤b表示自变量x的非线性约束[17]。
2.3 特征选择
特征选择是一种典型的组合优化问题,其从N个特征集合中选出M个特征的子集(M≤N),去除冗余或不相关的特征,使得处理后的数据集不仅包含的特征个数更少,而且能够提高分类算法在原有特征集合的分类性能[18]。
特征选择按照评价函数与分类算法之间的关系,可以分为过滤式和封装式。如图1所示,过滤式的子集评价与分类算法无关,一般根据数据内部特性(如互信息、相关性)得到。封装式的特征选择方法使用特定的分类器算法进行评价,如图2所示,产生的特征子集都通过特定的分类器进行评价之后再进行下一步选择,该方法产生的子集与使用的分类算法有关。

Fig.1 Filter feature selection图1 过滤式特征选择

Fig.2 Wrapper feature selection图2 封装式特征选择
2.4 Knee Points
在多目标优化算法中,Knee Points作为Pareto最优解集的子集中的解,如图3所示,该类解在直观上表现为Pareto前沿面上最“凹”的部分。在这些Knee Points附近,任何一维目标值的稍微减少都会导致其他维目标值的大幅增大。因此,虽然Pareto前沿面上的解都是互相非支配的,但其中的Knee Points要在一定程度上优于其他的解,从算法决策的角度来看,若没有指定特定的偏好点,则Knee Points应当被优先选择。文献[7]中具体说明了Knee Points在增加多目标优化算法收敛性方面的效果,本文将特征选择的两个目标(最小化分类错误率和最小化选择特征数)作为多目标的两个目标,将Knee Points加速收敛的能力利用到特征选择中,使得最终获得结果在分类性能和选择的特征数上都具有一定优势。

Fig.3 Knee Points explaination图3 Knee Points示意图
3 基于改进多目标人工蜂群算法的特征选择方法
为了将Knee Points加速收敛的能力应用到特征选择中,本文首先提出了一种快速识别Knee Points的算法,并在多目标人工蜂群算法的引领蜂阶段和跟随蜂阶段,使用Knee Points来引导整个种群的进化,在跟随蜂阶段,优先开发Knee Points,进而达到利用Knee Points加速整个种群收敛的目的,最后将改进后的算法结合5-NN分类器应用到特征选择问题中并在多个UCI数据集上进行测试。
3.1 种群蜜源的编码、解码与评价
种群中每个蜜源对应特征选择的一个解,蜜源采用离散编码,如式(7)所示,每个解X中包含n个实数,n为对应数据集的总特征数,其中每一维xi代表是否选择该特征。

对于每个蜜源的每个维度,规定:如果该维值大于给定的阀值(本文中设为0),则表示该维对应的特征被选择;如果小于给定的阀值,则表示不选择该维对应的特征。该过程为解码过程。
将每个蜜源解码转换为对数据集中所有特征的选择方案,也即解码。之后,使用KNN分类器(K=5)对每个蜜源对应的选择方案进行测试分类性能,并依照式(8)计算出该种选择方案对应的分类错误率,其中,TP表示正样本被预测正确的个数,TN表示非正样本被正确预测的个数,FP表示正样本被预测错误的个数,FN表示非正样本被预测错误的个数。将分类错误率结合每个蜜源选择的特征数作为衡量每个蜜源适应度值的两个指标。

3.2 一种快速识别Knee Points的算法
识别Knee Points示意图如图4所示。在图4中,首先,一条极线L由该层Pareto非支配面上的两个极值点D和E(D点在第二维目标上拥有最大值,E点在第一维目标上拥有最大值)根据式(9)确定,式中xD、xE、yD、yE分别为D和E的横坐标和纵坐标,将直线方程标准化为ax+by+c=0形式。接着,通过式(10)计算该层非支配面中的所有点到极线L的距离,式中a、b、c为标准化后极线L方程中的参数,xA和yA分别为点A的x轴和y轴坐标,并通过式(11)计算每个邻域的大小,每个邻域中距离极线L最大距离的点为Knee Point,式中,Range(j,g)表示第g代中第j维上的邻域大小,fmax(j,g)表示第g代中第j维的最大值,fmin(j,g)表示第g代中第j维的最小值,rg为第g代自适应参数,用于自动调节邻域大小,以实现算法整个种群的开采与开发上的平衡。由图中示意可知,A点被识别为Knee Point,因为其在整个邻域中到极线L的距离最大。

Fig.4 Diagram for recognizing Knee Points图4 识别Knee Points示意图

在识别Knee Points的算法中,通过调节r(g)改变邻域大小会直接影响识别出的Knee Points的数量,影响算法种群的进化趋势。为了平衡算法的开发和开采能力,本文设计了一种自适应变化的rg策略。在式(12)中,rg-1为第g-1代中邻域控制因子,tg-1为第g-1代中Knee Points占Pareto集合的比例,T为预先设置的阀值,用于控制Knee Points比例的上限。初代中,t0设置为0,r0设置为1。

识别Knee Points算法流程图如图5所示。

Fig.5 Flow chart of recognizing Knee Points图5 识别Knee Points算法流程图
3.3 基于Knee Points的引领蜂精英搜索机制
文献[19]中指出:算法种群中的精英解是种群中质量较好候选解,在算法对解空间的搜索过程中,充分利用精英解的特征信息引导其他候选解,能够有效促进种群的进化。在原始MOABC(multiobjective artificial bee colony algorithm)算法中,引领蜂寻找优秀的蜜源,并进行记录,之后由跟随蜂进行开采,在此过程中,引领方向决定着整个种群的进化方向。原始MOABC[17]中,采用式(2)所示的方法进行引领蜂的搜索过程,其开发过程遵循完全随机的原则,一定程度上能够增强算法的全局搜索能力,但也存在着搜索方向随机,搜索效率低下的问题。为此,本文重新设计了算法中引领蜂的策略,利用精英解的引导加快算法的搜索,参考了文献[12]中的全局最优引导思想引入gbest个体带领种群进化,从而实现对蜜源解空间的开发,加快种群进化速度提高种群多样性。一方面,通过人工蜂群算法中已存在的基于邻域的搜索机制,使得种群在搜索过程中保持了良好的局部寻优能力,同时,引入gbest引导种群的进化方向,带领种群中的个体向着可能的最优方向搜索,与原始人工蜂群算法相比,较好地保证了算法对全局最优值的搜索能力,两方面结合,本文中提出的算法,保证了算法种群局部寻优与全局寻优能力,且取得了非常好的平衡效果。基于以上,本文提出了基于Knee Point的引领蜂搜索机制,如式(13)所示。

式中,Vij为新蜜源的位置;xij和xkj分别为蜜源i和蜜源k的第j维位置且i≠k;xmj是当前蜜源的Knee Points集合中随机选择的蜜源m的第j维位置;Rij为[-1,1]间的随机数;Tij为[0,2]间的随机数。
3.4 基于Knee Points的跟随蜂搜索机制
多目标函数的评价值包含至少两维的适应度值指标,式(4)所示的单目标ABC算法中的蜜源选择概率的计算方式已经不适用于多目标MOABC算法的跟随蜂过程,而且由于算法种群后期进化压力的缺失,在跟随蜂阶段优先选择Knee Point作为邻域搜索的对象,能够很大程度上提升种群的进化速度。基于以上两点,本文中提出了一种将二元联赛方法[17]应用到引领蜂的选择过程并优先考虑Knee Points的搜索机制,如图6所示。首先整合已有信息得到每个蜜源的适应度值,分为三方面:(1)该蜜源所在的Pareto面序号;(2)该蜜源是否为种群中的Knee Point;(3)该蜜源的拥挤距离。接下来,根据该适应度对每个蜜源进行排序,分配优先级序号,适应度越好的蜜源优先级越高。最后,使用二元联赛方法[17],随机选择两个蜜源进行比较,将优先级高的蜜源加入待进化蜜源集合中,重复以上选择操作,直到集合中保存指定数量的蜜源,最后根据式(5)使用跟随蜂算子对ES(external strategy)中的蜜源进行开发。
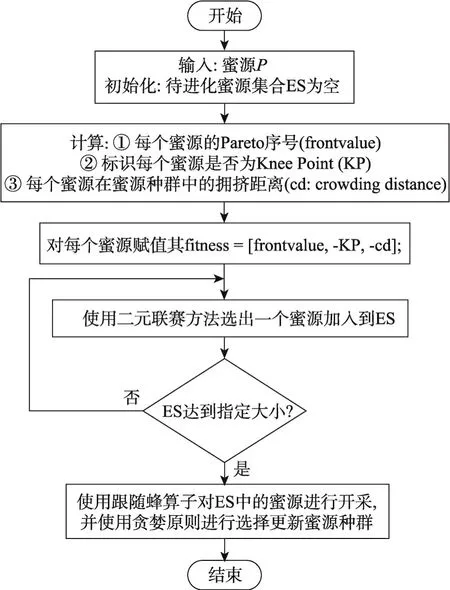
Fig.6 Flow chart of onlooker bee图6 跟随蜂算法流程图
3.5 基于Knee Points的改进多目标人工蜂群算法的特征选择方法流程
本文首先提出一种基于Knee Points的改进多目标人工蜂群算法,主要工作为:(1)设计一种快速识别Knee Points的算法;(2)将Knee Points应用到引领蜂过程中,帮助引领蜂确定进化的方向;(3)提出一种整合适应度值的方案,并将其与二元联赛方法结合应用到跟随蜂的开采过程中;(4)改进跟随蜂阶段,在该过程中优先选择非支配前沿面上且具有较大拥挤距离的Knee Points蜜源进行开采,确保算法更快地找到最优的蜜源。最后将该改进算法应用到特征选择问题中,具体流程如下。
步骤1初始化。给出算法的相关参数,其中包括算法种群大小N;最大迭代次数Iter;识别Knee Points算法中的参数r0和t0;每个蜜源可尝试的最大失败开采次数limit。并根据数据集信息随机产生数目为N的初始种群,其中每个蜜源的维度与数据集每个样本的特征数一致,每个蜜源采用实数编码。
步骤2按照3.1节所述对每个蜜源进行解码和评价,计算该蜜源对应的分类错误率和选择的特征个数作为该蜜源的适应度值。
步骤3根据式(5)和式(9)~(11)识别蜜源集合中的Knee Points蜜源,并记录为KP。
步骤4进行引领蜂的开采过程,对每个蜜源按式(13)搜索产生新蜜源,使用贪婪选择机制保存处于支配位置的蜜源,若两个蜜源互相非支配,则随机选择。
步骤5根据3.1节计算每个蜜源的适应度,并添加到集合T中用来进行跟随蜂开发过程。
步骤6根据式(5)进行跟随蜂的开发过程,对步骤4中产生的集合T中每个蜜源进行开发,运用贪婪机制保存较好的蜜源。
步骤7根据式(1)进行侦查蜂过程对指定的蜜源重新初始化,代替原来的蜜源。
步骤8判断是否达到预设的Nmax,若是,则输出所有蜜源的第一层Pareto面上的蜜源作为结果;否则,转至步骤2。
4 性能仿真和分析
4.1 数据集以及实验参数设置
表1所示的是实验中采用的11个UCI机器学习数据集的具体信息,包含二分类和多分类数据集,特征数规模从13到166,样本数从32到1 212。该11个数据集具有一定的代表性,其中,Musk1数据集的特征数达到了166,十分考验算法消除冗余特征的能力,该数据集上的选择结果能够充分代表算法在大规模特征数数据集下的优化效果;Wine数据特征数最少,为13,对这种特征数少的数据集,要求算法能够精确识别非冗余特征,并要求具有足够的跳出局部最优的能力,防止提前收敛;Hillvalley数据集具有最多的样本数,在样本数非常大的数据集上,算法的收敛速度显得至关重要,同时,该数据集上的结果也显示了算法解决过拟合问题的能力;Lungcancer数据集只有32个样本,使得算法很难在运行过程中达到充分的训练,该数据集上的结果能够充分验证算法在样本不足的情况下优化性能;其他数据集结合了以上数据集的优化难点,对算法的全面优化能力提出了更高当前要求,因此,在这11个数据集上的测试结果能够较为全面地反映各种算法的性能指标。实验仿真在主频为2.93 GHz,内存为8.0 GB的PC机上实现。软件环境为MATLAB R2013b。

Table 1 Description for datasets表1 数据集说明
为了验证算法的有效性,将本文中的算法与MOPSO(multi objective particle swarm optimization)[20]、NSGAII(nondominated sorting genetic algorithm)[21]和PAES(Pareto archived evolution strategy)[21]3种经典多目标算法在上述11个UCI数据集上进行测试对比。算法具体参数如下,种群大小P=30,算法最大迭代次数T=100,对每种算法单独运行40次后的结果进行求均值处理以公平比较。各种算法中的参数设置如下,KnABC(artificial bee colony algorithm based on Knee Points)中,蜜源最大可重复开采次数limit=60,用于识别Knee Points的自适应参数r0=1,t0=0,解码中预值设置为0,大于0表示选择对应的特征,小于0表示舍弃对应的特征。MOPSO中粒子最大速度vmax=0.6,惯性权重w=0.729 8,加速因子c1=c2=1.496 18。NSGAII中,变异概率mrate=1/n,n为种群个体的维度,也即对应的数据集的维度,交叉概率crate=0.9,PAES算法中的参数同上。上述所有算法都嵌套进封装方式的特征选择中,并采用五近邻(5-NN)算法测试每个蜜源代表的特征子集优劣。
本文实验中,参考机器学习中的实验设置,每个测试数据集被划分为训练集和测试集。其中,训练集占70%,测试集占30%,在训练过程中,每一个蜜源代表一种特征子集选择方式,通过5-NN分类器并采用十折交叉验证[2]计算每一种特征子集选择方式的分类错误率和特征选择数以此代表该蜜源的适应度值,并在算法最后,在测试集上对这些蜜源进行测试并将得到结果作为最后算法得到的结果。
4.2 实验结果分析
实验中,KnABC与MOPSO、NSGAII以及PAES每种算法在11个数据集上分别运行40次进行测试,得到每次运行的第一前沿面,并将这40次运行得到的第一前沿面依照特征数计算分类错误率的平均值,该结果用于表示算法最后的性能,此方式能够很好地避免算法的随机扰动,同时将特征数和错误率作为两个指标并作出相关对比图能够直接地展示算法的性能。
如图7所示,是本文算法与3种对比算法在11个数据集上的结果。其中,X轴坐标表示选择的特征数,Y轴坐标表示40次运行所得到的结果在X轴特征数下的平均错误率,其中分类错误率ErrorRate=,该公式具体含义已在3.1节中具体介绍。
图7所示的11个数据集的结果图像中,在所有数据集上,相较于选择所有特征进行分类得到的结果,4种算法都能够使用较少的特征数而实现较小的错误率,成功排除了部分冗余特征,提升了分类器的分类性能。与此同时,KnABC得到的结果在各个测试集上的最小错误率上均优于其他3种对比算法,充分验证了本文算法的优越性。

Fig.7 Comparison between KnABC and contrast algorithms on 11 datasets图7 KnABC与对比算法在11个数据集上的对比结果
对每个具有代表性的数据集进行单独分析。German数据集是一个样本数1 000,特征数24的二分类数据集,在该数据集上,与另外3种多目标算法的对比结果显示,KnABC在相同的特征数下,实现了更小的分类错误率,而且与采用所有特征进行分类得到的错误率相比,本文算法提升了约10%的准确率,与此同时,消除了14个冗余特征,表示算法在实际分类应用中,能够很大程度上减小分类算法的时间复杂度,提高分类效率。Hillvalley是一个特征数100,样本数1 212的数据集,MOPSO和NSGAII的结果中特征数最小为1,相较而言,本文算法在该数据集上的最小特征数为7,在消减冗余特征方面,不如MOPSO和NSGAII,然而在减小错误率方面,本文算法明显小于其他3种对比算法,该数据集上的结果显示本文算法在数据集样本数很大时,依然能够获得很好的效果。Lungcancer数据集是一个特征数56,然而样本数只有32的数据集,在样本数不足的情况下,已有的算法通常情况下无法通过已有的信息排除无效特征[2],但本文算法在选择特征数为6的时候,得到了约10%的分类错误率,比采用所有特征进行分类的错误率低了46.56%,极大提升了算法性能,随着选择特征数的增加,分类错误率反而增大,该现象也间接表明了冗余特征对分类算法性能的巨大影响。Hillvalley和Lungcancer数据集上的结果表明,本文算法在面对样本数差异非常大的数据集时都具有很好的优化作用。
数据集的特征数大小也是影响算法优化性能的关键,在11个数据集中,Musk1数据的特征最大,为166,在该数据集上,KnABC在最好的一次结果中,剔除了131个冗余特征,并将分类错误率从19.30%降低至3%左右,同时,KnABC在选择的特征数和分类错误率方面均优于其他3种对比算法;特征数最少的数据集为Wine数据集,该数据集总特征数为13,采用所有特征进行分类时,其错误率为32.47%,使用4种算法对这些特征进行选择之后,得到的分类错误率均小于32.47%,并且在分类错误率上,KnABC也比其他3种对比算法更优秀。
对于多分类数据集Zoo,从图中的结果可以看出,本文算法在特征数为7时,得到了2.3%的分类错误率,小于其他3种对比算法的最小分类错误率,并且在特征数为1、3、4和5时,分类错误率均低于其他3种算法,但随着选择特征数的上升,本文算法在特征数为8时,分类错误率明显增加,表明算法的稳定性还具有改进的空间。
在上述6种数据集上的单独分析表明,KnABC面对特征数,样本数多样,以及多分类和二分类数据集时,都能取得良好的效果。
如表2所示,是4种算法在11个数据集上的最小错误率对比,其中加粗显示的是最好的结果,从中可以看出在这11个数据集上,KnABC的结果都优于其他3种算法,表明本文算法在消除数据集冗余特征方面具有明显作用,能够极大地减小数据集的实际特征数,提高分类算法性能。

Table 2 Comparison of minimum error rate of algorithms表2 算法最小错误率比较 %
5 结束语
本文针对传统分类算法中存在的缺陷,结合当今大数据的趋势,分析当前分类算法面临的特征冗余,维度爆炸等问题,提出了一种基于Knee Points的多目标人工蜂群算法并将其应用到特征选择中,以去除数据集中的冗余特征,减小分类错误率,提高分类器性能。在11个UCI数据集上的结果显示,本文算法在减小数据集特征数的同时能够极大地提高分类的准确度,相较于采用所有特征的分类方式,应用本文算法削减特征数后,能够大体上减小约10%的错误率,个别数据集能够达到50%左右,与其他3种多目标经典算法对比结果显示,本文算法也具有极大的优势。
