数据、信息和知识三层图谱架构的推荐服务设计*
2019-02-13邵礼旭段玉聪周长兵高洪皓陈世展
邵礼旭,段玉聪+,周长兵,高洪皓,陈世展
1.海南大学 信息科学技术学院,南海资源利用海洋国家重点实验室,海口 570228
2.中国地质大学 信息工程学院,北京 100083
3.上海大学 计算机工程与科学学院,上海 200444
4.天津大学 计算机科学与技术学院,天津 300072
1 引言
互联网信息的指数增长造成的信息过载和信息迷航等问题制约了用户对资源的高效使用,随着知识经济的发展,当今社会对人们的知识掌握程度提出了更高的要求。知识图谱已经成为用标记的有向图形式表示知识的强大工具,并能赋予文本信息语义。知识图谱是通过结点的形式将项目、实体或用户表示出来,通过边的形式将彼此相互作用的结点链接起来构造的图形,结点之间的边可以表示任何语义关系。知识库包含一组概念,实例和关系[1]。刘峤等[2]将知识图谱的构建按照知识获取的过程分为信息抽取、知识融合和知识加工三个层次,定义知识图谱是一个具有属性的实体通过关系链接而成的网状知识库,其研究价值在于能以最小的代价将互联网中积累的信息组织成可被利用的知识,从而通过推理实现概念检索和图形化知识展示。
Cowie等[3]将信息抽取划分为实体、关系和属性三个层次,基于对现有知识图谱概念的拓展,可将知识图谱划分为数据图谱、信息图谱、知识图谱和智慧图谱[4],并可应用于回答与5W相关的问题[5]。Malin等[6]提出利用随机漫步模型对演员合作网络数据进行实体消歧,并取得了比基于文本相似度模型更好的消歧效果。Wu等[7]选择维基百科作为数据源,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取。对于关系抽取,出现了大量基于特征向量或核函数[8]的监督学习方法、半监督学习方法[9]和弱监督学习方法[10]。Etzioni等[11]提出了面向开放域的信息抽取方法框架,并发布了基于自监督学习方式的开放信息抽取原型系统。郭剑毅等[12]采用支持向量机算法实现了人物属性抽取与关系预测模型。Zins[13]阐述了定义数据、信息和知识等概念。数据是通过观察数字或其他基本个体项目得到的。信息通过数据和数据组合的背景传达,适用于分析和解释。知识是从积累的信息中获得的一般理解和经验,根据知识能推测出新的背景。
2 资源框架构建
现有的个性化信息服务系统方面的研究并没有考虑到上下文的信息,比如时间和地理位置等。从对现有知识图谱概念的拓展的角度出发,本文提出了一种基于数据图谱、信息图谱和知识图谱三层的可自动抽象调整的解决架构,通过对海量资源进行建模,快速、准确地在资源处理架构中找到用户所需要的信息,并且以更加人性化的方式为用户提供服务。本文对资源形态和三层图谱的定义如下:
定义1(资源元素)资源元素包括数据资源、信息资源和知识资源三种形态。ElementsDIK:= < DataDIK,InformationDIK,KnowledgeDIK>
定义2(图谱)本文对已有知识图谱(Knowledge Graph)的概念进行拓展,将图谱的表达分为数据图谱(DataGraphDIK,DGDIK)、信息图谱(InformationGraphDIK,IGDIK)和知识图谱(KnowledgeGraphDIK,KGDIK)三层。
GraphDIK:= <(DGDIK),(IGDIK),(KGDIK)>
本文对资源在DataDIK、InformationDIK和KnowledgeDIK三个层面上建模,借助从DGDIK上以实体综合频度计算为核心的分析到IGDIK和KGDIK上的自适应的自动抽象的资源优化过程(DIK方法)支持兼容经验知识引入和高效自动语义分析,表1给出了资源类型的渐进形式,借助对应5W(who/when/where,what and how)问题[14]的分类接口衔接用户的学习需求、学习过程和学习目标等的资源化描述,每一个“W”都可以广泛用于探索和评估各种知识理论和系统,为用户提供个性化学习服务推荐。图1给出了面向5W的基于DGDIK、IGDIK和KGDIK三层架构的资源处理框架示意。

Table 1 Explanation of resource types表1 资源类型的解释
DataDIK、InformationDIK、KnowledgeDIK和智慧是渐进关系的层次,从DataDIK挖掘到InformationDIK,从InformationDIK中获取KnowledgeDIK,从KnowledgeDIK中获得智慧。本文对应于DataDIK、InformationDIK、KnowledgeDIK和智慧的递进层次在整体上澄清知识图谱的表达,将知识图谱划分为DGDIK、IGDIK、KGDIK和智慧图谱四个层面。
图2展示了5W问题的分类及转化和四层图谱之间的关系。现阶段本文基于前三层架构对资源进行语义建模,在DGDIK层面上计算DataDIK的三种频度,在IGDIK和KGDIK上分析自适应的自动抽象的资源优化过程以支持兼容经验知识的引入和高效的自动语义分析。本文提出的框架借助对应5W问题的分类接口衔接用户学习需求、学习过程和学习目标等资源化描述,为用户提供个性化学习服务推荐。
2.1 基于DGDIK对DataDIK频度的统计与分析
DGDIK能记录DataDIK出现的频度,包括结构、时间和空间三个层次的频度。本文定义结构频度为DataDIK出现在不同数据结构中的次数,时间频度为DataDIK的时间轨迹,空间频度被定义为DataDIK的空间轨迹。
定义3(结构频度)结构频度(stru_f)表示DataDIK出现在不同数据结构中的次数。DataDIK的结构频度应根据DataDIK出现的最大数据结构进行计算。例如,如果在图形结构的分支中以树结构出现的DataDIK,将按图结构来计算DataDIK的结构频度为1,不重复计算DataDIK在树结构中出现的频度。
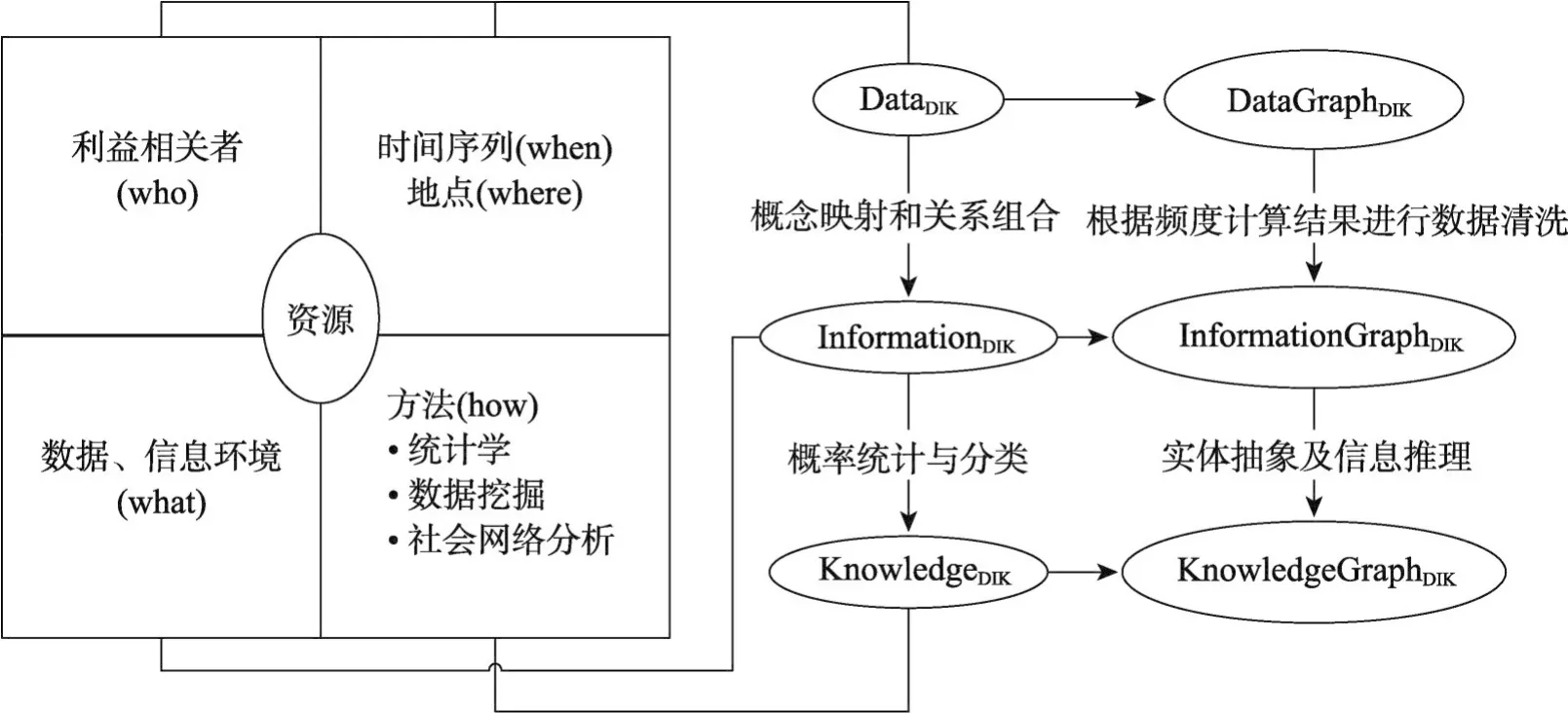
Fig.1 5W oriented resource processing architecture based on DGDIK,IGDIKand KGDIK图1 面向5W基于DGDIK、IGDIK和KGDIK的资源处理框架
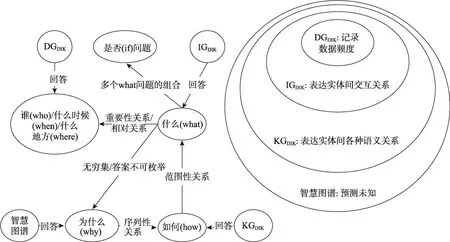
Fig.2 Type division of 5W problems and relationships among graphs图2 5W问题类型划分及图谱关系
定义4(空间频度)本文将空间频度(spat_f)定义为DataDIK在不同空间位置出现的次数,描述多个对象的相对位置,空间频度用来标识实体之间的空间关系。
定义5(时间频度)时间频度(temp_f)表示DataDIK在不同时间段内出现的次数。初始获取到的DataDIK集合可能不完整,对于具有时间性的流式数据,如果观察到流式DataDIK,应该及时做出响应,因为过期的DataDIK是无意义的。
定义6(综合频度)综合频度(DFreq)为一个三元组,包含DataDIK的结构频度、空间频度和时间频度。
DFreq:=
本文给出对学习点DataDIK资源进行建模时,对DataDIK的频度统计示例,如图3所示,知识点DataDIK的时间频度表示该DataDIK的课时数,空间频度为该DataDIK出现在不同专业体系的次数,结构频度表示为该DataDIK的教育方式。但DGDIK上未对DataDIK的准确性进行分析,可能出现不同名称的DataDIK但表达相同含义,即冗余。DGDIK只能对图谱上表示的DataDIK进行静态分析,无法分析和预测DataDIK的动态变化。DataDIK是通过观察获得的数字或其他类型信息的基本个体项目,但是在没有上下文语境的情况下,它们本身没有意义。
2.2 基于IGDIK对InformationDIK的抽象处理
2.2.1 基于IGDIK记录结点的交互度
InformationDIK是通过DataDIK和DataDIK组合之后的上下文传达的,经过概念映射和相关关系组合之后的适合分析和解释的信息。IGDIK通过关系数据库来表达。在IGDIK上进行数据清洗,消除冗余数据,根据结点之间的交互度进行初步抽象,提高设计的内聚性。
信息交互是业务处理、信息协作和系统集成的域信息系统的基础。在IGDIK上记录实体之间的交互频度,只考虑实体之间交互的方向,而不考虑交互关系的类型。本文将IGDIK定义为有向图G(V,E),其中V表示结点的集合,E表示边集合,使用综合度(Com_degree)来衡量信息图谱上结点的重要性,计算方式如式(1)所示:
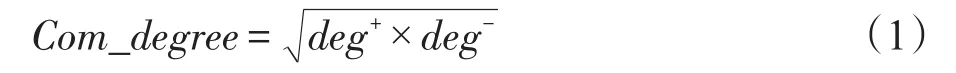
其中,deg+是结点的入度,deg-表示结点的出度。如图4所示,结点E1和E2在DGDIK上属于低频结点,结点E3和E4在DGDIK上属于高频结点,但在IGDIK上E1和E2两个结点之间交互频繁,仅通过综合频度来衡量结点的重要性容易丢失信息。因此在IGDIK通过计算Impor来进一步衡量结点的重要性,计算方式如式(2)所示:
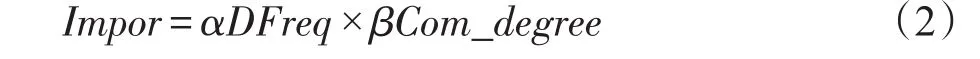

Fig.3 Statistics on stru_f,temp_f and spat_f of DataDIK图3 统计DataDIK的结构频度、时间频度和空间频度
其中,α和β分别表示结点在DGDIK上和综合频度和在IGDIK上的交互度对衡量该结点重要性所占的权重,可以通过数据训练获得。
2.2.2 根据交互度处理DataDIK集成和实体抽象
IGDIK反映了实体之间的对话和多重交互。如图5所示,通过将图3中的DataDIK形态的资源进行集成,生成了新的概念。线性表、队列和树等DataDIK资源联系紧密,为提高资源架构的表达,可将联系紧密的DataDIK进行集成,得到了InformationDIK资源“数据结构”。通过圈定特定数量的实体,计算内部交互度和外部交互度,如式(3)所示,内聚性(cohesion)等于内部交互度和外部交互度的比值,约束所圈定的实体之间必须相互连通。内聚度是衡量实体之间关联程度的指标。IFreqEI表示实体之间外部交互的次数,IFreqII表示实体之间内部交互的次数。将具有最大内聚度的不同实体以属性或操作的形式集成到同一模块中,以增强模型设计的内聚性并提高抽象度。新集成的模块在IGDIK上以新结点的形式被标记,并在DGDIK的层次上重新统计该结点的结构频度、空间频度和时间频度。
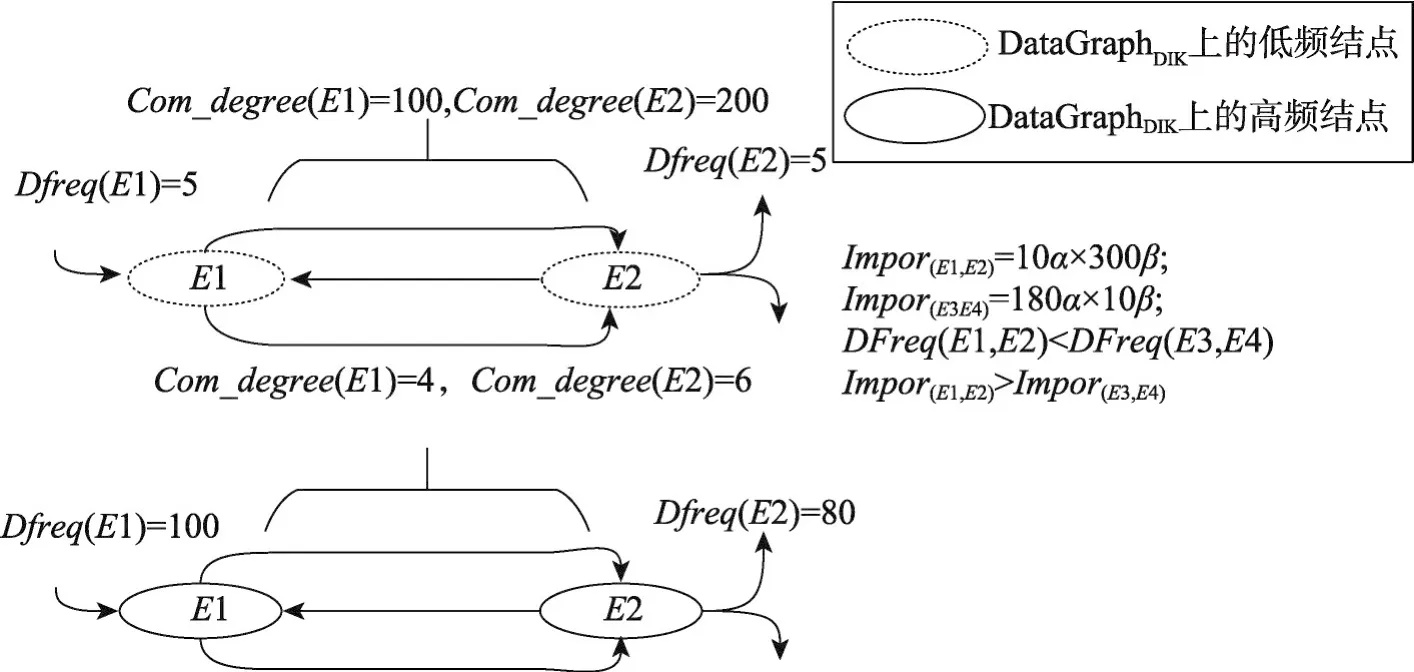
Fig.4 Measuring importance of entity through DFreq and Impor图4 通过综合频度和交互度衡量实体重要性

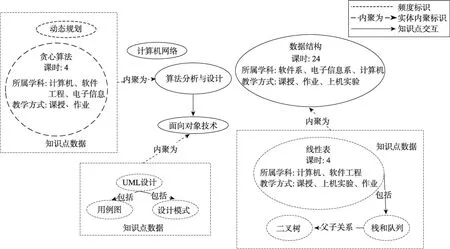
Fig.5 Automatic abstraction results of entities on IGDIK图5 IGDIK上实体的自动抽象结果
2.3 基于KGDIK对KnowledgeDIK的分析与处理
2.3.1 在KGDIK上进行信息推理和知识预测
KnowledgeDIK是从积累的InformationDIK中获得的总体理解和意识,将InformationDIK进行进一步的抽象和归类形成KnowledgeDIK。KGDIK通过包含结点和结点之间关系的有向图来表达。KGDIK蕴含各种语义关系,在KGDIK上能进行信息推理和实体链接。KGDIK的无结构特性使得KGDIK可以无缝链接,从而提高KGDIK的边缘密度和结点密度。信息推理需要有相关关系规则的支持,这些规则可以由人手动构建,但往往耗时费力。目前,它主要依赖于关系的同现,并使用关联挖掘技术自动查找推理规则。路径排序算法使用每个不同的关系路径作为一维特征,通过在KGDIK中构建大量的关系路径来构建关系分类的特征向量和关系分类器来提取关系。根据式(4)计算关系的正确度Cr,Q表示实体E1到实体E2的所有完整路径,π表示一条路径,θ(π)表示路径π的权重,最后正确度超过某一阈值后认为该关系成立,路径的权重以及正确度的阈值均可由训练得出。

2.3.2 结合关系语义类型衡量结点重要性
KGDIK的广泛采用,在很大程度上是由于它的无模式性质,使得KGDIK可以无缝扩展,并允许根据需要添加新的关系和实体。在KGDIK上标记并处理实体之间不同类型的语义关系。每个语义关系都由自己的权重(θ)来表示该关系的重要性,根据式(5)来全面评估结点在KGDIK上的重要性(Final_impor):
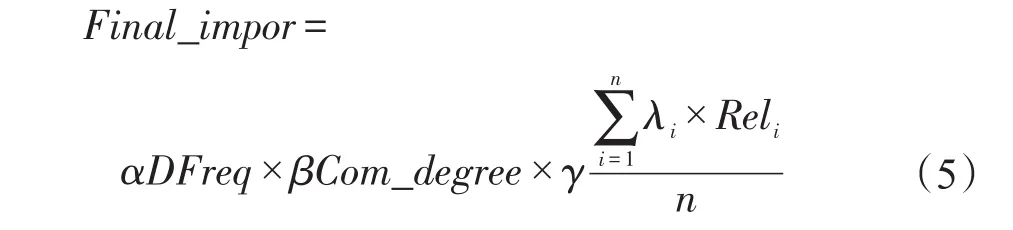
其中,λi是关系Reli的权重,n是关系类型的数量。
如图6所示,综合DGDIK、IGDIK和KGDIK三层架构,衡量结点的重要性有三个指标:DGDIK上结点的综合频度,在IGDIK上与其他实体的交互程度,以及在KGDIK层面上与外部结点交互的语义关系类型。通过综合考虑结点在三层图谱上的重要性,设计人员可以避免频度低但与外部实体有重要关系交互的结点被误删除。
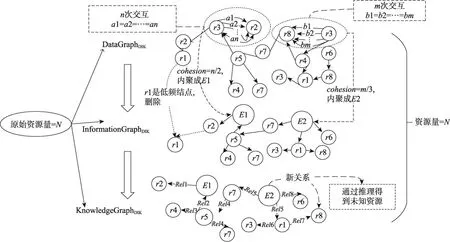
Fig.6 Resource processing based on DGDIK,IGDIKand KGDIK图6 基于DGDIK、IGDIK和KGDIK对资源的处理示意图
3 DIK方法框架的应用
资源有 DataDIK、InformationDIK和 KnowledgeDIK等形态,对这些DataDIK、InformationDIK和KnowledgeDIK等形态的资源的原始表述的自然语言的机器理解、自动处理、自动综合和自动分析等成为了巨大的挑战。基于DGDIK、IGDIK和KGDIK的三层资源处理框架能够有效地将经验知识与训练模型结合在一起,减少人工专家交互负担。DataDIK是通过采集或观测得到的离散资源,存在缺失、错误、冗余和不一致等问题。通过对DataDIK在DGDIK上进行频度统计和计算,过滤综合频度较低的DataDIK,减少错误DataDIK、无用DataDIK的出现;在IGDIK上对DataDIK的表达形式进行统一,消除冗余DataDIK,将交互频繁的DataDIK进行集成和抽象,得到总结性的规律InformationDIK资源。DataDIK和InformationDIK之间的关系缺乏层次性和逻辑性,对InformationDIK进行分类和统计,纳入经验性知识,从而对未知的信息进行推测,得到概率性答案。受DataDIK、InformationDIK和 KnowledgeDIK之间的关系限制,用户无法在DataDIK上直接获得InformationDIK和KnowledgeDIK,在InformationDIK层面无法直接获得KnowledgeDIK。跨层查找资源存在查找不到、无尽查找、查找得出的资源与问题不匹配等情况,如在DGDIK层上无法找到KnowledgeDIK。但在IGDIK上一定能找到DataDIK资源,在KGDIK上一定能查到DataDIK和InformationDIK等资源。通过对资源进行建模,在整合后的资源里分层对应查找相关资源,不同情形下应用不同的资源框架,在DGDIK上查找DataDIK,在IGDIK上查找InformationDIK,在KGDIK上查找KnowledgeDIK。
4 基于DIK架构的学习推荐服务应用
资源有 DataDIK、InformationDIK和 KnowledgeDIK等形态,对用户来讲,学习点就是资源,因此在构建学习点资源处理架构时,将学习点对应到DataDIK、InformationDIK和KnowledgeDIK三个层面上去处理,不同情形下应用不同的资源。本文提出的DGDIK、IGDIK和KGDIK三层资源处理架构借助对应5W问题的分类接口衔接用户的学习需求、学习过程和学习目标等的资源化描述,每一个“W”都可以广泛用于探索和评估各种知识理论和系统,并能根据5W引入的DataDIK、InformationDIK和KnowledgeDIK等资源不断更新处理资源框架,自适应地为用户提供个性化学习服务推荐,通过建立学习者模型,根据用户的当前学习状况、能力水平和学习目标有针对性地为用户提供一个高效的导学策略,考虑用户之间特征的差异,因材施教,保证用户按需学习。
4.1 隐性学习者模型构建
在建立学习者模型时,显性模型必须先了解用户的信息,而现实情况下,存在用户不愿透露的信息,以及显性模型无法度量的信息,隐性模型通过挖掘用户的行为得到用户自己可能无法表达的信息,比显性模型的准确率更高。本文提出将学习者的学习情况看作数据、信息和知识等类型化资源的集合,基于数据图谱、信息图谱和知识图谱对学习者进行建模,以结点和边的形式表达学习者对学习点的掌握情况。学习者模型的构建包括资源和能力构建两部分,分别对应学习者的学习情况和学习能力。资源包括学习者已学知识点、未学知识点和目标知识三个组成部分,用于统计学习者的知识掌握情况和知识需求。能力构建部分包括用户的记忆能力、计算能力和逻辑能力的评估。学习者能力水平分为三个等级,分别是“弱”“中”“强”。通过提示用户进行习题测试统计用户的知识掌握情况,评估学习能力。
4.2 基于DIK资源处理框架的学习推荐流程
图7展示了基于DGDIK、IGDIK和KGDIK三层资源处理架构的学习推荐服务流程,根据现有海量DataDIK、InformationDIK和KnowledgeDIK等资源构建学习点资源处理架构,通过大数据训练得出用户群体学习每个学习点所要花费时间和精力的平均水平,即学习投入,作为学习点的权重在资源处理框架上做出标记。
获取学习者预期的学习投入(Expected_effort)和学习目标,学习者预期的学习效率(Expected_effi)计算公式如式(6)所示:
其中,Total_know表示目标知识包含的学习点总量。根据用户的学习目标类型,确定在哪一层资源处理框架上进行遍历。若用户学习目标比较简单,预期学习投入较少,学习能力较弱,则基于DGDIK向该用户推荐学习点和学习路径;若用户学习目标难度一般,预期学习投入一般,学习能力一般,则基于IGDIK向该用户推荐学习点和学习路径;若用户学习目标难度较大,预期学习投入多,学习能力较强,则基于KGDIK向用户推荐学习点和学习路径。在资源处理框架上标记学习者已学知识和目标知识点,遍历图谱,获取目标知识点的所有先序结点。将存在“或”关系的知识点按学习该知识点所需要的学习投入(即权重)进行排序,输出完整的学习路径并推荐给用户。用户按照推荐的学习路径进行学习,在学习过程中,系统不断获取用户反馈并监测外部学习环境的变化。用户实际的学习效率(Actual_effi)计算公式如式(7)所示:
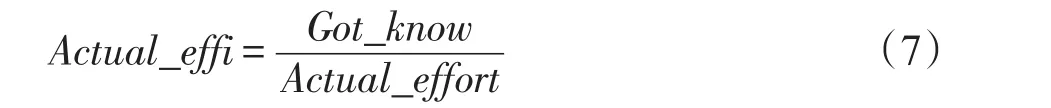
其中,Got_know表示学习者已学到的学习点,Actual_effort表示学习者的实际学习投入,统计学习者的能力变化,更新学习者模型;根据外部学习环境的变化,更新处理资源框架。按照更新后的学习者模型和处理资源框架,重新获取学习者的学习目标及预期的学习投入,根据用户当前学习状况重新规划学习路径。
图8给出了关于计算机系课程的部分知识体系,假设用户的学习目标是要掌握数据挖掘这门课,当前已掌握和未掌握课程已经在资源体系中作出标记,每门课程标记的数字代表学习这门课所需投入的平均水平,获取用户的预期学习投入后,则可以向其推荐图中所示三种学习方案。
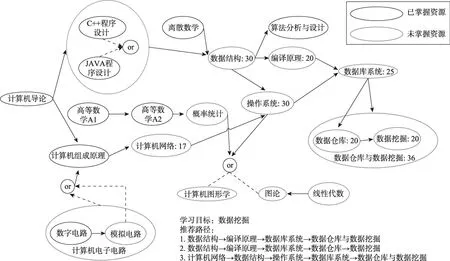
Fig.8 Example of learning service recommendation based on DGDIK,IGDIKand KGDIK图8 基于DGDIK、IGDIK和KGDIK架构学习推荐服务例子
5 相关工作
随着统计机器学习方法的引入,共指消解技术进入了快速发展阶段。McCarthy等[15]使用决策树来解决商业合资企业领域分类不同短语的系统中的共指消解问题。本体被用作语义网中的知识表示的标准形式[16],微软发布的Probase利用统计机器学习算法抽取出概念之间的“IsA”关系[17]。对于复杂的实体关系,借助TBox和ABox将基于描述逻辑的推理归结为一致性检验问题[18]。杨志等[19]利用动态规划的思想提出了一种基于本体的服务推荐方法。彭建伟[20]提出了一种改进的Memetic算法以及一种基于Memetic算法的个性化学习路径推荐策略。Fader等[21]提出一种开放问答(open question answering,OQA)方法,从未标记的问题语料库和多个知识库中挖掘数百万个规则来解决问题解析和查询重构等问题。Wang等[22]提出一种通过概念注释来促进跨语言知识链接的方法。Trojahn等[23]提出了一种语义导向的跨语言本体映射框架,以增强涉及多语言知识库系统的互操作性。Liu等[24]利用K-最近邻算法和条件随机场模型,实现了对Twitter文本数据中实体的识别。王泊学[25]设计了一种基于上下文感知的自适应服务组合系统,将上下文环境转移到服务组合系统中。潘伟丰等[26]提出的服务分类方法为服务提供分类信息,提高服务发现、检索及服务资源管理的效率。
6 结束语
如何快速、准确地在网络中找到用户所需要的资源,并且以人性化的方式为用户提供服务,已经成为一项挑战。本文的贡献在于综合性地处理互联网上的资源,通过分析和抽象海量的DataDIK、InformationDIK和KnowledgeDIK等形态的资源,消除概念的歧义,剔除冗余和错误概念,提高DataDIK、InformationDIK和KnowledgeDIK等资源的质量。基于DGDIK、IGDIK和KGDIK建立资源处理框架,对不同资源需求在最匹配的资源层面上进行查找,有效提高查找效率。本文提出的架构借助从DGDIK上以实体综合频度计算为核心的分析到IGDIK和KGDIK上自适应的自动抽象的资源优化过程,支持兼容经验知识引入和高效自动语义分析,将经验性和理论性DataDIK、InformationDIK、KnowledgeDIK和智慧融入学习推荐的方法中,协助用户隐含意图的信息表达,并能有效处理资源不一致、冗余、缺失等问题,通过自动抽象和动态规划进行有效和自适应的资源搜索和自组织,进而向用户推荐和优化服务。当前工作在各个环节进行了实例讨论,下一步将扩大数据规模进行验证。
