复杂网络的重叠社区发现并行算法
2019-01-31戴荣杰任晓春
滕 飞 ,戴荣杰 ,任晓春
(1. 西南交通大学信息科学与技术学院,四川 成都 611756;2. 轨道交通工程信息化国家重点实验室(中铁一院),陕西 西安 710043)
随着信息技术的迅速发展,人类社会已经迈入了复杂网络时代,各种超大规模网络不断涌现,例如智能电网、电话网络、社交网络、引文网络等. 大规模复杂网络中的一些社会化特征在全局层面往往具有稳定的统计规律,可用来理解人类社交关系的结构和行为. 社区发现根据网络的拓扑结构探索网络关系的群组特征,识别出网络中有意义的、自然的、相对稳态的社区结构,对网络信息的搜索与挖掘、舆论控制、信息推荐以及网络演化预测具有重要价值.
早期的社区发现算法主要研究的是非重叠社区结构. 随着人们对网络性质认识的加深和新型网络不断出现,非重叠社区成员属性过于单一,无法体现复杂网络形成的动机和社区结构的丰富内涵. 重叠社区发现问题最早由Palla等提出,允许一个节点同时属于多个社区[1]. Palla等提出派系过滤算法 (clique percolation method,CPM),通过建立重叠矩阵寻找连通部分形成社区划分[2]. 派系过滤算法需要以完全子图为基本单元来发现重叠,这对于很多真实网络尤其是稀疏网络而言,限制条件过于严格,只能发现少量的重叠社团. 此后,非重叠社区算法经过调整也应用到重叠社区发现,例如局部优化法[3-4]、标签传播法[5]、概率模型算法[6]、模糊聚类算法[7],这些方法往往需要预先给定参数,算法的普适性和鲁棒性受到一定限制. Ahn等在《Nature》杂志上首次提出将边作为社区划分的研究对象[8],开创了重叠社区发现的一条新的道路,文献[9]基于点的非重叠社区算法经过调整可应用到重叠社区发现. 复杂网络中的一条边通常对应某一种类型的特定交互,以边为对象使得划分结果更能真实地反映节点在网络中的角色或功能,一条边只归属于一个社区,从而允许一个节点归属于多个重叠社区. 总体来说,基于边的社区发现算法与同类型的基于点的算法相比,无论是时间还是空间复杂度都高出很多,主要是由于网络中边的数量要远远多于点的数量,因此复杂度是设计重叠社区发现算法时需要考虑的重要因素.
并行化是降低运算时间的有效途径,目前可用的并行计算框架不断丰富,如MPI、MapReduce、Spark和专门用于图计算的GraphX、Pregel等. 结合并行计算框架的算法开发,可以缓解大规模复杂网络的计算问题. 一些学者通过并行化实现非重叠社区发现算法的快速迭代,提高了运行时间方面的性能[10-11]. 社区发现并行算法带来效率的提升主要依赖于计算框架的部署规模,其最大难点在于复杂网络数据本身固有的连通性和图计算表现出强耦合性.因此,需要进行有效的图分割,尽可能降低分布式计算的各子图之间的耦合度. 本文选择MapReduce作为并行计算的开发框架,提出了一种适用于大规模复杂网络的重叠社区发现算法PHLink (parallel hierarchical link).
PHLink算法创新性的提出将节点按照复杂网络的无标度特性进行分层,根据建立连边的不同动机来探索节点的多重属性和社区归属. 这种思想也同样适用于其他基于边的社区发现算法,用于降低边计算的复杂度,具有一定的通用性. 其次,PHLink算法在Hadoop平台上将复杂网络进行分割和冗余存储,减弱了图计算的强耦合性,使子图得以独立的并行处理,解决了社区发现算法的分布式计算问题.大量真实网络测试表明PHLink算法综合性能良好,划分社区质量较高,在并行环境下具有良好的加速性和伸缩性,可以处理千万级连边规模的大规模复杂网络.
1 边社区发现算法及其改进
1.1 边社区发现算法及复杂度分析
传统的社区发现算法是将网络划分为若干个不重叠的点社区,每个节点具有唯一属性且仅能隶属于唯一社区. 然而事实上每个节点可以包含多重属性,出于不同动机与他人建立连接,例如亲戚或同事关系. 边社区能更为精确地刻画属性的类别,在应用中更加具有实际意义.
图论提供了一种用抽象的点和边表示各种实际网络的统一方法,是目前研究复杂网络的一种共同语言,因此本文用图的形式对复杂网络的结构进行描述,刻画边社区.
定义1(复杂网络)复杂网络可抽象为一个由点集V和边集E组成的无向无权图G(V,E),v∈V表示节点,e∈E表示节点之间的连接关系,点集和边集的规模分别为n和m.
定义2(边相似度)[8]具有一个公共节点vl的连边对eil和ejl之间的边相似度是节点vi和vj所拥有的共同邻居的相对数量,记为
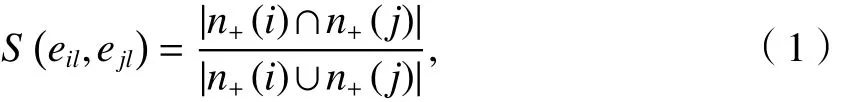
式中:vl、vi和 vj分别为第 l、i和 j个节点,i,j,l =1,2,···;n+(i)为节点vi及其所有邻居节点的集合.
边社区划分可以采用Link单连接凝聚聚类的方法对边集进行聚类[8],该算法具有直观、易理解的优点,然而其复杂度较高,不适用于大规模的复杂网络. Link算法中最重要的步骤为计算连边之间的相似度得到相似度矩阵,该矩阵代表了任意两条边之间的亲疏关系,复杂度为O(m2). 考虑到连边相似度在计算时仅需考虑有共同节点的两个连边,因此相似度矩阵的复杂度可以降至O(nK2),其中,K是网络中节点度的最大值.
1.2 改进思路
在线社交类的复杂网络的一阶度分布已经被证明具有无标度特性,节点度为k的概率正比于k-γ,称参数γ为幂律系数. 有研究显示社交网络的幂律系数范围在 1.5 < γ< 2.5[12]. 以 YouTube 网络为例[13],双对数坐标系下概率分布函数呈线性关系,γ约为1.7. 这意味着,YouTube网络中仅有极少数的点拥有比较大的度,绝大多数的点只拥有少量连接. 比如度超过200节点仅占全部节点的0.2%,这些节点拥有的边占总边数的21%,而相似度计算量占比却高达95%. 因此本文将利用幂律分布特性来减缓边计算内存存储的压力,降低算法复杂度.
一阶度分布刻画的是网络中不同度的节点各自所占的比例,但具有相同度分布的两个网络可能具有非常不同的性质或行为. 二阶度分布显示了度的相关性. Erzsebet等经实际测量研究表明社交网络的层级结构使得集团内部连接紧密,但节点平均度较小,集团间连接稀疏,但负责连接的枢纽节点度较大[14]. 枢纽节点之间的连接描述了核心层的连接情况,其社区密度将远远高于网络的划分密度,也即富人俱乐部连通性现象. 基于以上结论,本文按照一阶度分布把网络节点分为枢纽节点普通节点,分层进行相似连边聚类. 由于枢纽节点往往跨领域连接到其他社区的节点,去除了枢纽节点和其归属边后,由普通节点构成社团的结构将比之前更加清晰,有利于提取社区信息.
2 并行层级连接算法PHLink
本文基于Hadoop平台设计并实现了并行层级连接算法PHLink,可以解决复杂网络由于数据量大而导致的计算时间过长,内存不足等问题. PHLink算法的示意图如图1所示,首先对原始网络G进行预处理,分成G1、G2和G33个子图,其中G1包含了普通节点之间的连边,G2包含了普通节点与枢纽节点的连边,G3包含了枢纽节点之间的连边. PHLink分别对G1和G3进行相似度计算,采用凝聚聚类的方法合并相似的边,形成边社区;接下来将G2中的连边归属到由G1形成的边社区;最后将边社区转换成点社区,并对点社区进行清洗,去掉节点数少于3个的点社区. 至此,PHLink算法得到了非重叠的边社区划分与重叠的点社区划分结果.
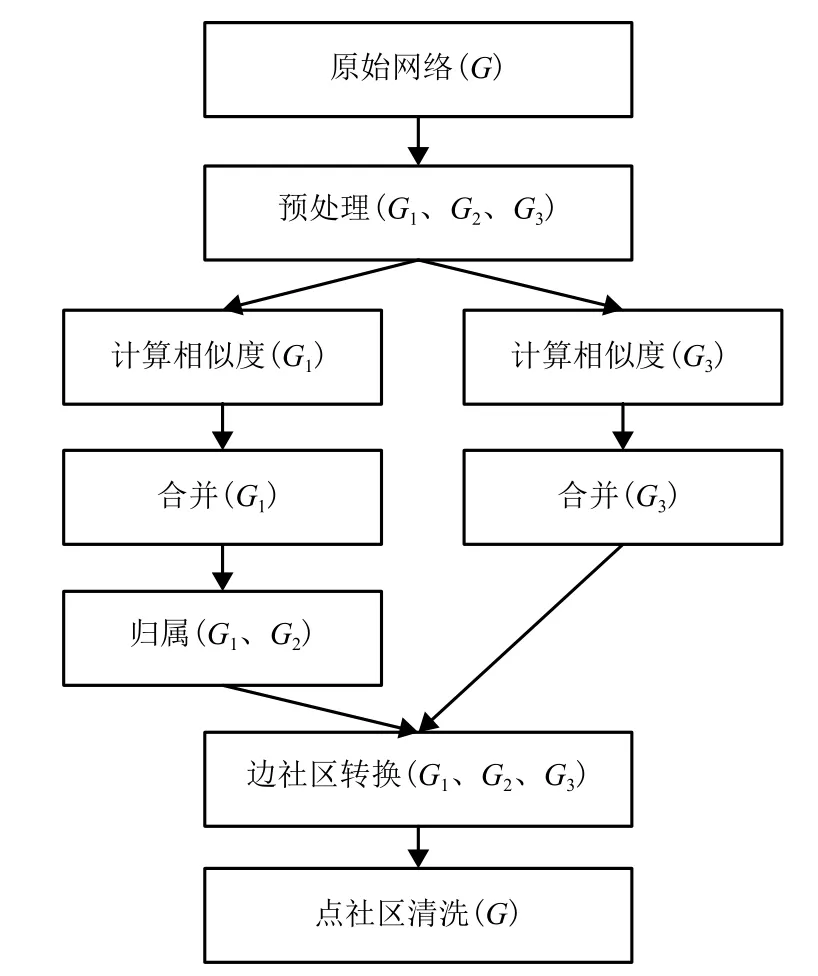
图1 PHLink算法示意Fig.1 Overview diagram for PHLink
在Hadoop平台上实现PHLink算法的难点在于计算相似度、合并以及归属3个步骤,可以用3个MapReduce作业加以实现,需要重点完成Mapper和Reducer自定义类的设计.
2.1 相似度计算
预处理阶段按照节点度将原始网络G分割为3个子网络G1、G2和G3,并以点邻接表的格式存储在 HDFS (Hadoop distributed file system).
算法1相似度计算
Mapper: map()
输入:<k,v > k为 node,v为 node所有的邻居点 adj
θ为相似度值;
输出:<k,v > k为 link,v为 link邻居边 neiglink
(1) 从HDFS读入原始网络G
(2) FOR each v1 in adj
(3) FOR each v2 in adj
(4)intersection=v1.getAdj()∩v2.getAdj();
(5)union=v1.getAdj()∪v2.getAdj();
(6)sim=intersection.size()/union.size();
(7)link1= node+v1;
(8)link2= node + v2;
(9)IF (sim > θ)
(10) write(key:link1,value:link2);
(11) write(key:link2,value:link1);
(12)ENDIF
(13)ENDFOR
(14) ENDFOR
Reducer: reduce()
输入:<k,v > k为 link,v为 link邻居边 neiglink
输出:<k,v > k为 link,v为 link所有的邻居边 linkAdj
(15) itr = neiglink.iterator();//迭代器
(16) WHILE itr.hasNext() DO
(17) linkAdj = linkAdj∪itr.next();
(18) ENDWHILE
(19) write(key:link,value: linkAdj);
算法1中,map函数的输入键值对为点邻接表形式,value值是与key节点相邻的所有节点的集合.输出键值对为边邻接表形式,value值仅包括相似度大于参数θ的邻居边. map函数按照式(1)计算包含有共同点node的两条相邻边的相似度(算法1(4)~(8)),如果相似度大于 θ,将两条边分别作为键和值输出两次(算法 1(9)~(12)). reduce函数对具有相同 key的边进行规约操作(算法1(15)~(18)),输出键值对为边邻接表形式.
2.2 合并
得到边邻接表之后,可以将每条边及其邻居边初始化为边社区. 合并作业的目的是将具有单边连接关系的小社区合并为大社区. 本文利用并查集将小社区进行连通,解决了分布式计算中网络耦合的问题. 考虑到合并具有层次性,本文采用多次合并的策略平衡计算中的时空复杂度,由map任务完成局部边集的合并,reduce任务对map合并的结果进行汇总合并,有且仅有一个reduce任务. map和reduce具有相同的功能,两者采用了相同的算法.
算法2中,map函数通过扫描边和其所在的社区编号找到社区之间的连通关系. 输入键值对为初始边社区,key为社区编号,value为社区对应的边集. 输出键值对为合并后的边社区. linkMap存储边的社区编号,如果一条边已经存在linkMap中,则把已存储的编号和当前的编号组成一对组合pair,标记两个社区是连通的(算法 2(4)~(6)),更新边的社区编号(算法2(7)). 否则,将边与其所属的社区编号组成新键值对存储到linkMap (算法2(8)~(9)). 遍历初始化社区中的每一条边可以获得所有社区与社区之间的连通关系,存放在pairSet (算法2(3)~(11)). cleanup函数通常在执行完毕 map后,进行相关变量或资源的收尾工作,仅且执行一次. 合并算法的cleanup函数利用并查集将社区进行连通(算法 2(12)~(14)). clusterMap存储所有的边社区,每条边通过查询并查集找到所归属的社区(算法 2(17)~(19)),如果社区不存在,则新建社区并加入 clusterMap (算法 2(21)~(23)). 由此,可以完成将具有单边联系的小社区合并为大社区的效果.
算法2合并
Mapper: map()
输入:<k,v > k为社区编号 id,v为边社区 inCluster
输出:<k,v > k为社区编号 id,v为边社区 outCluster
(1) 初始化 linkMap;//存放所有边的 map 映射
(2) 初始化 pairSet;//存放社区之间连通关系的 set集合
(3) FOR each link in inCluster
(4) IF (linkMap.constainsKey(link))//边已存在
(5)preId=linkMap.get(link);
(6)pairSet.add(preId,id);//当前 id 与前一个 id组成pair
(7)linkMap.put(link,id);
(8)ELSE
(9)linkMap.put(link,id);//新边加入 linkMap
(10)END IF
(11) END FOR
Mapper: cleanup()
(12) FOR each pair in pariSet
(13) unionFound.union(pair.v1,pair.v2)//利用并查集对pair进行连通
(14) ENDFOR
(15) 初始化 clusterMap;//存放所有社区的 map 映射
(16) FOR each link in linkMap
(17)clusterId = unionFound.find(linkMap.get(link))//查找link应归属的社区
(18) IF (clusterMap.containedKey(clusterId)) //已存在社区
(19) clusterMap.get(clusterId).add(link);//加入边
(20) ELSEIF
(21) outCluster = null;//增加新社区
(22) outCluster.add(link);
(23) clusterMap.put(clusterId,outCluster)
(24) ENDIF
(25) ENDFOR
(26)write(key:clusterId,value: outCluster);
Reducer:reduce()
(27) 同 Mapper:map()
Reducer:cleanup()
(28) 同 Mapper:cleanup()
map函数的时间复杂度为 O(sms),其中,s为map分片中键值对的个数,即输入社区数,ms为map分片中不重复的边数,也即社区的最大规模.cleanup函数中通过查询并查集,为每条边找到对应的社区编号,时间复杂度为O(mslog s). linkMap和clusterMap存储的是map分片中每条边的社区编号,空间复杂度为O(ms).
合并作业的极端情况是每个map只处理一个社区,不进行合并,合并工作全部由唯一的reduce完成. 此时,m1为待合并的社区数,社区的最大规模为邻居边的个数2K1,K1为子图G1节点度的最大值. 故合并作业的并行算法时间复杂度为O(m1K1),空间复杂度为 O(m1).
2.3 归属
已知G1网络的边社区的划分结果outCluster,归属作业把G2网络的边加入到已知边社区中. 算法3中map函数的输入键为枢纽节点stone,值为与stone相连的所有的普通节点. 输出键值对为边社区,key为社区编号,value为社区对应的边集.
map函数从HDFS读入边社区划分outCluster,将键值对中包含的每条边stone-node归属到可以使ΔD 增加最多的社区(算法 3(4)~(16)). reduce函数对具有相同key的社区进行规约操作(算法3(18)~(22)),输出 key和 value.
算法3归属
Mapper:map()
输入:<k,v > k为枢纽节点 stone,v为 stone的邻居点adj
输出:<k,v > k为 id,v为边社区 cluster
(1) 从 HDFS 读取 outCluster;
(2) max=-1;
(3) id=-1;
(4) FOR each node in adj
(5) link = stone+node;
(6) FOR each cluster in outCluster//查找增量最大的社区
(7)IF (node in cluster)
(8) calculate ΔD;//计算增量
(9) IF (ΔD > max )
(10) max=ΔD;
(11) id=clusterId;
(12) END IF
(13)END IF
(14)END FOR
(15) END FOR
(16) clusterMap.get(id).add(link);//加入增量最大的社区
(17) write(key:id,value: clusterMap.get(id));
Reducer: reduce()
输入:<k,v > k为 id,v为 inCluster边社区
输出:<k,v > k 为 id,v为 outCluster 边社区
(18) itr = inCluster.iterator();//迭代器
(19) WHILE itr.hasNext() DO
(20) outCluster = outCluster∪itr.next();
(21) ENDWHILE
(22) write(key:id,value: outCluster);
归属并行算法时间复杂度为O(sq1),其中,q1是G1子图划分的社区数. 算法从HDFS中将G1子图的社区划分读入内存,空间复杂度为O(m′1),此时,m′1为G1子图的边数.
综合相似度计算、合并、归属3个作业的复杂度分析,考虑到map分片的大小是人为可控的,子图G3的规模远远小于子图G1,PHLink算法的时间复杂度为 O(m1K1),空间复杂度 O(m). 可见,PHLink算法具有较好的扩展性,可以通过增加工作节点,降低运行时间.
3 实验分析
本实验使用的Hadoop集群环境由12台Dell E5506服务器组成,每台服务器拥有4核CPU、12 GB内存、500 GB硬盘、安装了hadoop-2.4.1,并以千兆以太网相连. 本文中是实验数据来自SNAP (Stanford network analysis project)实验室真实网络数据[13],如表1所示,其中带星号的3个网络标注有groundtruth高质量社区.
3.1 评价指标
假设真实社区为C*,由社区发现算法识别出的社区为,社区匹配定义为

表1 基准测试数据集Tab.1 Benchmark datasets

式中: Ci和分别为i个真实社区和第j个识别出的社区.
准确率定义为
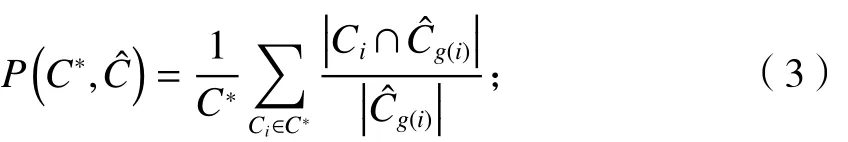
ˆCg(i)g(i)
式中: 为第 个识别出的社区.
召回率定义为

F1定义为
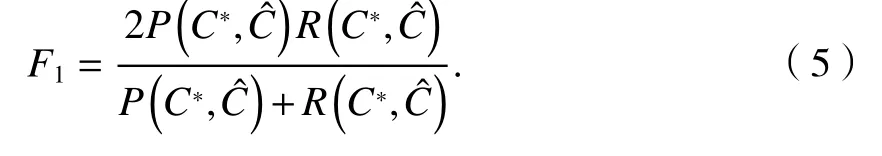
定义任意两个节点u、v所归属的社区数量的准确性为[6]
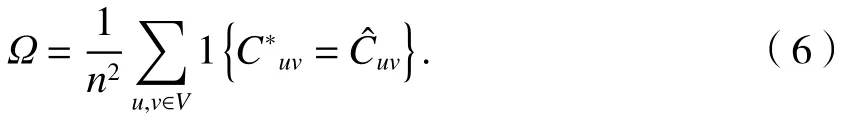
扩展的规范化互信息(extended normalized mutual information,ENMI )[6]度量了基准网络的社区集合和挖掘算法发现的社区集合的一致性程度,定义参见文献[3].
社区覆盖率[8]定义为属于非平凡社区(3个或以上节点的社区)的节点所占的比例.
社区重叠率[8]定义为每个节点所属的非平凡社区的平均值.
3.2 枢纽节点比例阈值对计算效率的影响
PHLink算法计算效率受到枢纽节点比例阈值的影响. 比例阈值越高,计算效率越高,综合指标相应降低. 比例阈值需根据实际网络的特性和规模选取.
如表2所见,大规模网络的无标度特性更强,如YouTube、Skitter网络,极少数的点拥有绝大多数的连边,仅选择度最大的0.1%的节点即可节省94%以上的计算量. 随着比例阈值进一步提高,计算量随之减少,但降低幅度变缓. DBLP和Amazon网络的枢纽节点对计算量的影响较弱,是由于网络本身特性决定的. 比如在DBLP中,单一学者的论文数量有限,一般最多能到达百篇量级,DBLP中节点的最大度为347,因此无标度特性比YouTube较弱.
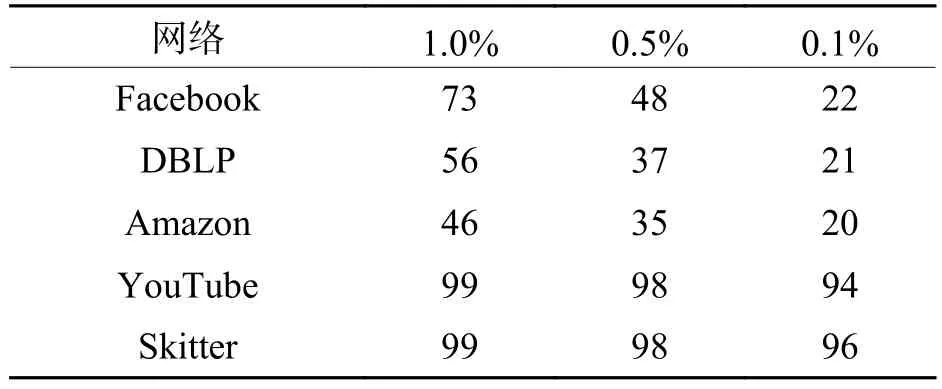
表2 比例阈值对计算量的影响Tab.2 Effect of proportional threshold on computation %
3.3 运行时间及网络规模
本文选取了重叠社区发现的经典算法CPM[2]、Bigclam[6]、Link[8]与 PHLink 进行比较. 实验中 You-Tube和Skitter网络规模较大,采用12个节点并行处理,其余网络仅用单个节点进行计算. Bigclam算法需要提前设置社区数作为输入参数,其中DBLP和Amazon按照网络的真实社区数取值,其他数据集由于社区数未知,取值30,如表3中括号所示.CPM算法设置完全图参数为4,PHlink设置枢纽节点比例阈值为0.1%,结果如表3所示.
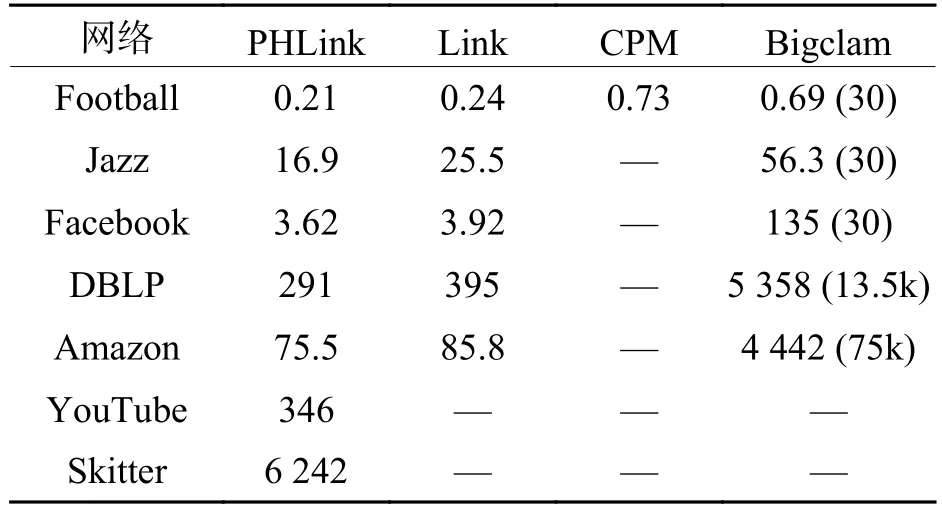
表3 运行时间比较Tab.3 Comparison of computation time s
PHLink无论从运算时间还是网络规模都明显好于其他几种算法. 值得注意的PHLink处理Jazz网络的时间要高于Facebook网络,主要原因是PHLink算法的复杂度不仅与网络规模有关,也受到网络的稠密程度(平均度)的影响.
对于YouTube和Skitter两个网络,本文通过改变集群规模,考察PHLink算法的并行能力,如表4所示.

表4 PHLink算法加速性能Tab.4 Speedup for PHLink s
由表4可知,PHLink算法有着良好的并行加速性能,而且随着网络规模的增大,加速比接近于1.
3.4 社区质量评价
评价指标采用 3.1 节中定义的 F1、 Ω 、ENMI、重叠率和覆盖率,将5项指标的取值分别进行归一化,使得每个指标最大值为1,最小值为0.5项指标的归一化值加和用于评价算法的综合性能,其最大取值为5,最小取值为0.
PHLink和Link算法采用单连接凝聚聚类的方法对边集进行聚类,将生成大量平凡社区,因此用来测度社区划分准确性的F1、 Ω 、ENMI 3项指标将以5 000个高质量社区作为基准,重叠率和覆盖率计算的是全网中属于非平凡社区的节点. 如图2所示,PHLink和Link的综合性能相差无几,其中,F1、Ω两项指标优于Bigclam算法. ENMI在Amazon数据集下逊于Bigclam算法,这与网络数据集的特性有关. Amazon与DBLP相比,平均社区规模小,节点分布广,社区结构较为松散. PHLink和Link算法的重叠率略高于Bigclam,但覆盖率低于Bigclam,主要原因是Bigclam算法本身可以避免生成平凡社区. 而实际网络DBLP中,度为1的节点比例高达14%,存在大量的平凡社区.
4 结 论
本文重点阐述了大规模复杂网络重叠社区发现并行算法 PHLink 的工作原理,基于MapReduce并行计算框架,解决了大规模复杂网络中社区的识别问题. 根据复杂网络的无标度特性将节点分为枢纽层和普通层,对不同节点建立连边的原因进行分析和归类,以边作为社区划分的研究对象,用以识别网络中具有重叠性的社区结构. 由于节点分层处理,大大降低了计算量,并在此基础上实现并行化,缓解了对内存限制,使子图得以独立的并行处理,解决了传统社区发现算法无法处理的大规模复杂网络社区划分问题. 实验在真实大规模复杂网络上进行,与多种经典的重叠社区发现算法进行对比,验证了本文PHLink算法对大规模复杂网络社区识别的时效性,可以处理千万级连边规模的大规模复杂网络.

图2 综合性能比较Fig.2 Comparison of composite performance
致谢:中铁第一勘察设计院集团有限公司轨道交通工程信息化国家重点实验室开放课题(SKLK16-04).
