月面巡视器基于深度学习的即时定位与建图
2019-01-10严超华龚小谨
严超华,李 斌,龚小谨
(浙江大学信电学院,杭州 310027)
1 引言
我国嫦娥工程已经圆满完成绕月探测和落月探测,实现了对月球全球性、整体性的综合探测[1]。之后,载人登月将成为我国未来月球探测工程的主要发展目标,这一任务在科学上和工程上都有了更高层次的需求,包括在具有更大科学意义更具挑战性的区域登陆以及月面行走探测更大的范围等,也因此对月面巡视器的导航定位的精度和稳定性提出了更高的要求[2]。
月面巡视器在执行上述任务的过程中必然需要进行路径规划,而高精度导航定位与地图构建则是月面巡视器实现路径规划和运动控制的基础[3]。由于月岩、环形坑及月壤的存在,月面巡视器运动时会产生滑移,导致依赖轮式里程计的定位方法存在较大的误差[4]。基于视觉的即时定位与建图(Simultaneous Localization and Mapping,SLAM)不仅能提供准确的定位信息,且能提供环境的结构信息,是巡视器进行导航定位的主要方案之一。
在计算机视觉领域,SLAM算法从提出至今已近30年[5]。传统的基于视觉的SLAM算法按照是否提取特征点可以分为两大类:特征法和直接法。特征法首先在图像中提取稀疏特征点并计算特征点描述子,然后利用匹配的特征点在不同图像中的投影结果最小化重投影误差来估计相机的运动。代表性算法包括Klein等于2007年提出的PTAM[6]、Mur-Artal等提出的ORB-SLAM[7]等。与特征法不同,直接法不需要进行特征提取,而是通过最小化两帧图像之间的光度误差来估计图像之间的运动。代表性算法包括Newcombe等提出的利用直接法的DTAM算法[8]、以及Engel等提出的同样基于直接法的LSD-SLAM[9]等。在上述传统SLAM方法中,特征的提取与描述依赖于人工设计,模型的参数需要手工调试,限制了模型的性能[5]。
近年来,随着深度学习技术在目标检测、目标识别和场景理解等问题上的成功应用,学术界开始了将深度学习应用在SLAM上的尝试。这些方法可大体分为两类,即深度学习与传统方法结合的SLAM模型,以及端到端的SLAM模型。
1)深度学习与传统方法结合的SLAM模型:2017年,Tateno等[10]提出了CNN-SLAM算法,利用深度网络实现实时的单目SLAM。CNN-SLAM在直接法的单目SLAM算法中,加入通过卷积神经网络(Convolutional Neural Network,CNN)预测的深度信息来取代SLAM算法本身对深度的假设和估计,取得了与传统SLAM算法相当的位姿估计效果。
2)端到端的SLAM模型:2017年,Vijayanarasimhan等提出了SfM-Net[11],通过CNN学习图像对应的深度图、图像帧之间的位姿变换和光流、图像中物体的运动信息等。SfM-Net由运动网络和结构网络两部分构成,其中运动网络预测图像帧的运动信息,结构网络预测图像的深度信息。SfM-Net取得不错的深度预测结果和光流结果,却没有对比位姿估计的结果。同年,Zhou等提出利用CNN从视频中无监督地学习图像对应的深度图和相机的自身运动[12]。他们提出的网络结构和SfM-Net类似,同样由两部分子网络组成,一部分DepthCNN用来预测深度图,另一部分PoseCNN预测图像帧与帧之间的位姿变换。该模型最大的亮点是完全仿照传统方法中的直接法用无监督的方式直接从图像序列中得到深度和位姿信息。从结果对比来看,此网络的结果比缺少闭环检测和重定位模块的ORB-SLAM效果好,稍差于全模块的ORB-SLAM。但由于完全是无监督的方式,相当于传统方法中的单目SLAM算法,在实际运行中会出现与真实世界之间的尺度缺失,从轨迹的可视化中可以看到明显的差异。
传统SLAM算法中的特征点提取易受场景因素尤其是光照强度和场景内容的影响,而深度网络所提取的特征则具有较好的泛化性能,由此,本文提出利用深度学习对月面巡视器进行即时定位与建图。
2 位姿-深度联合估计方法
2.1 网络结构
在导航定位应用中,最常用相机、激光雷达与GPS/IMU这三类传感器,如百度的Apollo,谷歌的waymo等无人车项目,以及KITTI等导航定位相关数据集的采集用车。对于月球上的应用,GPS将会失效,而月球的重力环境不同于地球,会导致IMU的加速度感知并不可靠,因此本文假设月面巡视器导航所使用的传感器是单目相机和激光雷达。由此,本文设计如图1所示的包含两个网络分支的即时定位与建图深度学习网络:一个分支用于从图像序列中学习帧间的位姿变换(PoseNet),另一个分支用于学习图像的深度信息(DepthNet)。这两个子网络结构主要参考Tinghui Zhou所提出的基于无监督学习估计深度和位姿的方法(具体可参考文献[12])。
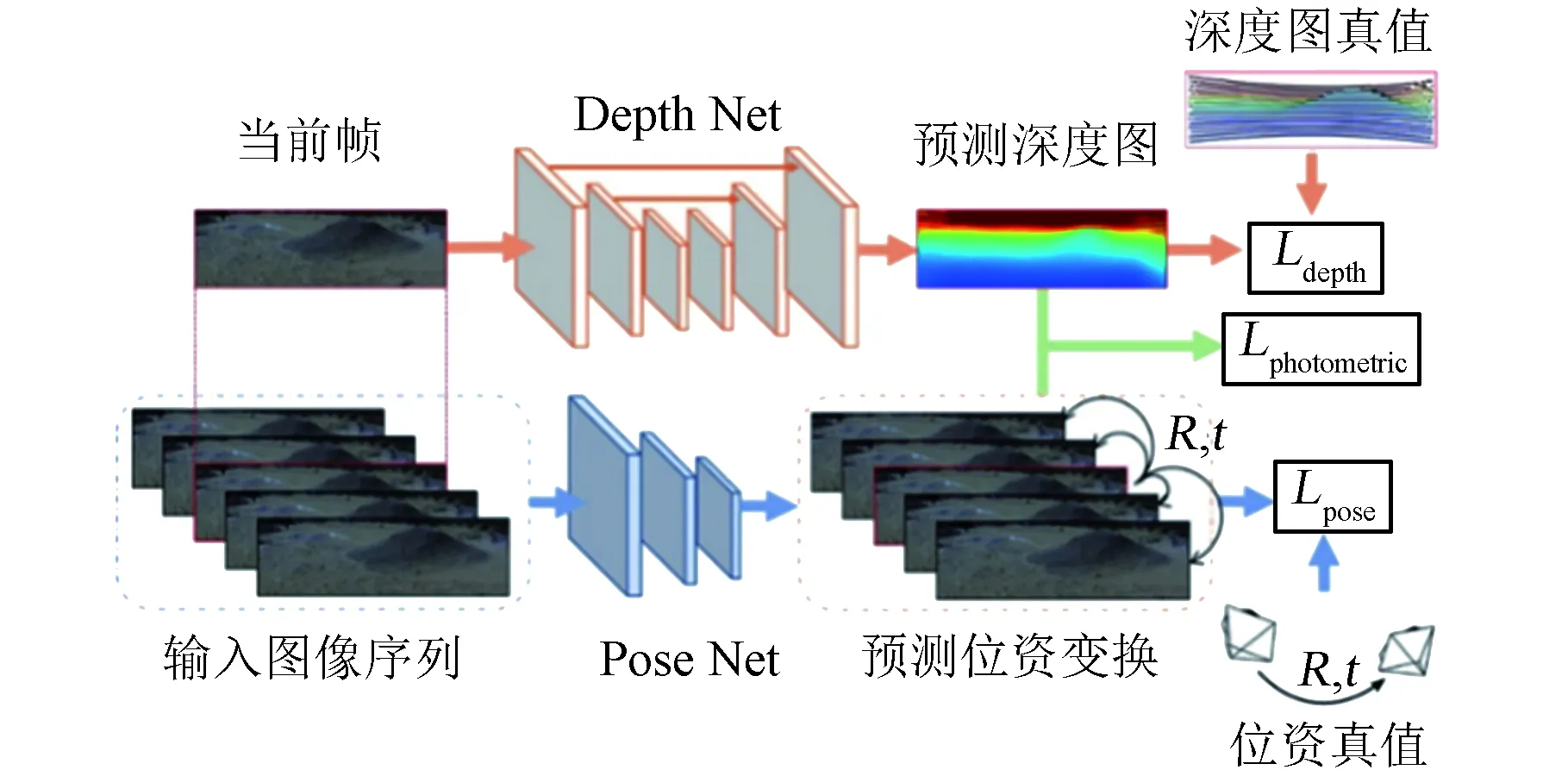
图1 基于深度学习的SLAM网络结构Fig.1 Network structure of SLAM based on deep learning
位姿变换网络PoseNet的输入为连续5帧三通道彩色图像,以通道数为轴将5张图像堆叠起来,构成一个高×宽×(通道数×5)的张量作为输入。输出结果是其余相邻4帧与中间帧之间的相对位姿变换,包括平移量和旋转量共6个自由度。PoseNet由卷积层和全局平均池化层(Global Average Pooling,GAP)构成,具体网络结构设计见表1。前7个卷积层为常见的卷积层,除了前两层的卷积核(Kernel)大小为7×7和5×5,其余每层的局部感受野范围都是3×3。前7个卷积层的步幅(Stride)为2,因此每层提取到的特征图尺寸都是输入的1/2。在特征图尺寸缩小的同时,特征图的通道数每层倍增至256。每个卷积层后连接ReLU作为激活函数,其在增加网络非线性的同时比使用sigmoid、tanh等激活函数有更快的计算速度[13]。经过7个卷积层的特征提取后,这里用1×1的卷积层和GAP取代以往深度网络中常用的全连接层,1×1的卷积层将256通道的特征图降维至所需的输出维度,最后由GAP对每个通道进行全尺寸的平均将每个特征图聚合成一个值。
深度估计网络DepthNet的输入是中间帧彩色图像,输出结果是彩色图像对应的深度图。其网络结构如表2所示,由7组卷积和对应的7组反卷积组成。每组卷积由两个Kernel大小相同的卷积层组成,共同进行特征提取,且对应一组同样大小的反卷积。反卷积层由Zeiler等在2010年提出,在正向和反向传播中执行着和卷积相反的运算[14]。反卷积和卷积一样会通过网络反向传播来优化滤波器参数,可以达到较好的效果,因此被广泛应用在需要输出像素级结果的网络。由于DepthNet估计的深度信息也是像素级别的,所以利用卷积层提取特征后需要用对应的反卷积层将大小还原到原图。
2.2 损失函数
本文所提出的深度网络是基于全监督的,采用已知的帧间旋转、平移以及激光雷达采集并与图像配准的稀疏深度图作为监督信息。因此,设计的网络损失函数主要包含位姿误差、深度误差、深度平滑误差、光度误差四个部分。
位姿误差(Pose Loss)如公式(1)所示,位姿估计的监督项是由网络预测的位姿变换量和真实值之间的L2范数计算得到。
Lpose=‖tpred-tgt‖_2+‖rpred-rgt‖_2
(1)
式中,[tpred,rpred]代表网络预测的位姿变换,[tgt,rgt]代表数据集提供的真实位姿变换。其中,t=[txtytz]T为三个相互正交坐标轴的平移分量,r=[rxryrz]T代表绕各个轴旋转的角度。

表 1 PoseNet的网络结构

表2 DepthNet的网络结构
注:其中Convib表示该卷积层以Convi层的输出为输入,且该层的输入输出尺寸相同;Upconv层表示反卷积层,Iconv层表示该卷积层的输入来自多个网络层跨接。
深度误差(Depth Loss)为深度图的监督项设置成网络预测的深度图与真实值之间的绝对值差值的平均,如式(2)所示。如果深度图真值是致密的,可以直接计算每个像素的预测结果和真值之间的误差;如果深度图真值是稀疏的,需要增加一个掩图M(p)来过滤没有真值影响结果的像素。掩图是一张二值图,有稀疏深度的像素位置M(p)为1,否则为0。
(2)
式中,Dpred为网络预测的深度图,Dgt为数据集提供的真实深度图,p为图像I中的一个像素坐标,N为所有像素总量。

(3)
在直接法SLAM中,假设同一个空间点在相邻帧之间的图像得到的灰度值基本一致可以构造用于优化的光度误差(Photometric Loss)[8]。图2展示了计算单个像素对应光度误差的方式,通过位姿变换将相邻帧的像素点投影到当前帧的对应位置,并计算该位置上两个像素点的灰度差,具体的推导过程如下:假设空间点P在相邻两帧图像上的成像像素坐标分别为p1,p2,则对于该像素点而言,直接法的光度误差e计算如式(4):
e=Ic(p1)-Ir(p2)
(4)

图2 光度误差示意图Fig.2 Schematic of photometric error
式中,I(p)为像素位置p的灰度值,Ic代表当前帧,Ir代表相邻帧。p1、p2两个像素坐标之间存在如式(5)所示的投影关系:
(5)
式中K为相机内参矩阵,d1为该相机坐标系下像素p1对应的空间点P的深度(由深度图提供),d2为该相机坐标系下像素p2对应的空间点P的深度(由空间点P通过变换矩阵计算得到)。由于p1通过两重投影到得到的p2坐标不一定是整数,本文通过双线性插值以相邻的四个像素值获得该像素对应的像素值,这一系列计算记作ω(*),单个像素点的光度误差可以写作式(6):
e=Ic(p1)-Ir(ω(p1,D(p1),Tcr))
(6)
其中,D为当前帧对应的深度图,Tcr为当前帧和相邻帧之间的位姿变换估计。作用于整张图像的可视化效果如图3所示。

图3 光度误差计算过程Fig.3 Calculation process of photometric error
将光度误差应用在网络的损失函数构造中可以得到式(7):
(7)
以上各误差项通过不同的权重参数构成网络最终的损失函数,如式(8)所示。
L=Lpose+λpLphotometric+λdLdepth+λsLsmooth
(8)
3 实验验证
3.1 实验数据集
传统的SLAM算法没有学习的过程,而深度学习以数据驱动进行学习,需要大量的数据来训练模型。本文的实验主要在地面真实道路场景的KITTI数据集以及仿月表环境数据集中进行。
其中,KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集,数据集中的Odometry模块包含了11个图像和三维点云序列,提供了行驶轨迹的真值用作训练和调试算法。这里将00-08序列作为训练序列,09和10两个序列用作测试[15]。由于KITTI数据集只提供了激光雷达的三维点云,需要事先配准到图像上得到稀疏的深度图用于网络预测深度的监督。
仿月表环境数据集由项目组的实验车在仿月表环境采集,包含用ZED相机采集的双目图像及Velodyne 16E激光雷达采集的三维点云序列,整个数据集共有9个序列,这里将05、06序列用于测试,剩余序列作为训练序列。与KITTI数据集类似,激光雷达三维点云数据需要预先配准到图像上得到稀疏的深度图。
3.2 训练设置
网络的具体实现使用TensorFlow框架(该框架详见文献[16])。参考文献[12]中网络训练的设置,我们网络训练过程中的基本参数设置如下:图像大小为(128,416), 图像序列长度为5(中间一帧为当前帧,余下帧作为相邻帧),学习率为0.0001,批量大小为4,优化器为Adam[17],其中β1=0.9,β2=0.999,损失函数的各项参数设置为λp=1,λd=1,和λs=0.5,训练约210000次迭代时网络基本收敛。网络的训练和测试都在实验室的GPU服务器上进行,服务器配备了2个XEON E5-2620V4 2.1 GHz的处理器、64 G内存和4块11 GB GDDR5X显存的NVIDIA 1080TI显卡,训练时长约为20 h,测试阶段每个样本所需时间平均约为95 ms。
3.3 评价标准
本文的实验结果主要从定量和定性两个方面进行分析,对比的方法包括在传统SLAM算法中效果较好且开源的ORB-SLAM[7]和Zhou提出的一种基于无监督深度学习的SLAM方法[12],下文将其统一称为Unsupervised模型。
定性分析主要是通过序列恢复的运动轨迹图对比此方法和已有方法的效果。主要从轨迹图来直观地比较各个算法的效果,通过每个短序列预测的位姿结果将整个测试序列的行驶轨迹恢复,其中选择第一帧的相机坐标系作为全局坐标系,随后将每一帧的位姿从局部位姿转换为全局位姿,再投影至垂直相机的平面。
定量分析将使用已有公认的评价标准对此方法预测得到的结果和已有的方法进行对比。本文计算预测的位姿结果和真值之间的误差所用的评价标准是2012年Sturm等提出的绝对轨迹误差(Absolute trajectory error,ATE)[18]。由于预测的位姿和真值可能不在同一个参考系下,需要先对两者进行对齐,即通过刚体变换将两个不同来源的位姿变换到同一个参考系下。参考Horn提出的方法[19],两者的刚体变换存在闭式解S。通过变换后,两者在第i时刻的绝对轨迹误差的计算如式(9)所示:
(9)
式中,Pi为估计的位姿变换矩阵,Gi为对应的真值。对于一条完整轨迹,可用式(9)计算轨迹上各个时刻的绝对轨迹误差,并用其均方根误差来表示整个序列的误差,如式(10)所示。
(10)
其中trans(·)表示位姿变换矩阵中的平移向量部分。
3.4 基于KITTI数据集的定量分析
在KITTI数据集上,用于对比的算法包括开源的传统算法ORB-SLAM、Unsupervised模型和本文的算法。其中,Unsupervised模型有在KITTI上训练好的网络参数可以直接复现其论文的结果。对于ORB-SLAM算法,这里使用了两种输入方式来得到位姿估计的结果:第一种是整个序列作为输入(ORB-SLAM-long),这样算法的闭环检测和重定位功能可以发挥作用;第二种是为了保持实验的对照性,采用和网络同样的5帧的短序列作为输入(ORB-SLAM-short)。从表3可以看到,同样是深度学习的方法,本文的位姿预测误差较Unsupervised模型小。和ORB-SLAM比较,本文的预测结果误差远小于同样输入方式的ORB-SLAM(short),精度稍逊于整个序列作为输入的ORB-SLAM(long),原因在于对整个序列ORB-SLAM可以进行全局优化。

表3 在KITTI测试序列上的误差对比
在KITTI数据集的测试序列上的轨迹结果如图4所示,由于ORB-SLAM(short)用单目短序列作为输入,导致算法经常初始化不成功而使得算法跟踪失败,序列预测结果不连续,所以轨迹图中只使用ORB-SLAM(long)的结果作为对比。同样由于单目视觉定位算法尺度缺失导致ORB-SLAM和Unsupervised模型的结果与原序列的轨迹差异较大。而本文的算法由于有位姿真值作为监督,在尺度上与原序列差异不大,但预测结果仍存在明显偏移。

图4 在KITTI上的轨迹图(单位:m)Fig.4 Trajectory of KITTI test sequences (unit: m)
KITTI数据集测试序列上的深度预测结果比较如图5。因为有稀疏的深度图真值监督,本文算法得到的深度图结果比Unsupervised模型的细节更为丰富,在第三列开阔的场景下仍有合理的深度图结果。

图5 在KITTI上的深度图结果Fig.5 Depth Map of KITTI Test Sequences
3.5 仿月表面数据集的实验比较
在仿月表面数据集上,我们由于没有手段获取精度足够的位姿真值,最后以双目版本ORB-SLAM在数据集上的定位结果作为训练的伪真值,因此在最后的实验结果中,我们只将本网络的输出结果与ORB-SLAM的结果进行对比。
根据表4的结果,我们的网络在仿月表面数据集上的误差与在KITTI数据集上的误差近似。而从图6中可以看到,我们的方法在仿月表面数据集上的定位性能相比于KITTI数据集有一定程度地下降,且预测的轨迹尺度明显偏小。
性能下降的一个原因在于仿月表面数据集与KITTI数据集有两点较为明显的差异,导致网络的性能不同:
1)KITTI和仿月表面两个数据集中采集图像所使用的相机内部参数并不相同,而我们的网络是隐式地学习相机内部参数,因此在不同的相机参数图像上效果会受到影响。
2)仿月表面数据集的深度真值来自于16线的激光雷达,而KITTI数据集则是使用64线激光雷达,在深度指导信息上,KITTI数据集更加丰富,因此对于尺度信息的恢复效果也优于仿月表面数据集。
另外仿月表面数据集相比于KITTI数据集而言数据的数量较少,因此我们测试时使用的模型是在KITTI数据集上进行预训练后,用仿月表面数据集进行微调得到的,因此网络在仿月表面数据集上有性能下降符合我们的预期。

表4 在仿月表面数据集测试序列上的误差对比
受限于本数据集中位姿真值的精度,我们无法做进一步的定量分析来评判网络性能,但我们依旧可以认为我们的网络对于仿月表面这种场景特征相对较少的环境依旧有一定的适应能力。而要进一步提升该算法在仿月表面环境中的性能,首先需要进一步扩充仿月表面数据集,另外对于网络模型则要进一步考虑相机的内部参数,使其能够适用与不同的相机。

图6 在仿月表面数据集测试序列上的轨迹图(单位:m)Fig.6 Trajectory of sim-moonscape dataset test sequences (unit: m)
4 结论
本文设计的一个全监督的卷积神经网络对单目SLAM建模,从图像序列中直接估计平移量和旋转量,减少了传统方法中人工设计特征和根据场景设置各种参数阈值的局限性,增加算法对环境的适应性和鲁棒性。另外,本文引入三维点云构成的稀疏深度图作为监督,采用光度误差构造的损失函数将深度信息和位姿信息结合,带来了丰富的场景深度信息,克服了不同场景深度预测的难点,同时为地图构建提供了三维信息。
本文的方法在没有闭环检测的情况下在KITTI数据上取得了与ORB-SLAM算法相近的性能,同时对自行采集的仿月表面数据集中的场景也有一定的适应能力。
在实际应用中,目前的工作还有进一步提升的空间:当前的网络只以5帧连续图像序列为输入,无法考虑闭环信息,这样在全局性能上显著弱于传统SLAM算法;网络只是隐式地学习相机内部参数,因此只适用于训练数据对应的相机,需要提升其对不同相机的适应能力。
