结合评分时间和用户空间的协同过滤推荐算法
2018-12-13李炎艾均苏湛
李 炎 艾 均 苏 湛
(上海理工大学光电信息与计算机工程学院 上海 200093)
0 引 言
随着科学技术和计算机应用的高速发展,人类进入了信息爆炸的时代。面对海量的信息,用户需要根据其信息需求投入大量的时间进行信息过滤和信息选择,产生了信息过载问题[1]。推荐系统是解决这个问题行之有效的方法,并且在这些年发展迅速。推荐系统根据用户的信息需求,为其提供个性化的推荐,在海量的信息空间中,为用户推荐有用的信息[2]。目前推荐系统主要包括基于协同过滤的推荐[3-4],基于内容的推荐技术[5],基于网络的推荐技术[6]和混合推荐技术[7-9]四类。目前应用广泛且颇受欢迎的是协同过滤推荐算法,在物品推荐的过程中只依赖推荐的社交性而不需要关注物品的信息就可以实现推荐。
协同过滤推荐算法通常根据用户行为计算每一对对象的相似度度量,并向相似的用户推荐一个类似的项目。例如,如果用户A与用户B相似,那么两个用户在项目上做了相同的评价,而用户B喜欢项目C,但是用户A还没有对项目C进行评价,那么此算法可以假定用户A喜欢项目C,并将其推荐给用户A。该过程的核心步骤包括计算对象相似度,根据相似度选择对象的邻居,并根据邻居的评级来预测评级。
传统上,网络科学一直专注于静态网络来探索链接预测。也就是说,在计算过程中,类似的方法会将节点之间的连接持久化。然而,越来越多的人认识到,大多数推荐系统最好被描述为时间网络,其中的链接只是间歇性的或有一定的重量衰减。另外,在推荐系统中节点的空间分布很少是科学家考虑的因素,因为拓扑结构不保持任何空间信息或位置约束,并影响相似计算的结果。很多学者针对时序方面提出了一系列的方案。文献[10]结合物品信息和情境上下文信息,发现情境上下文在提高推荐质量上有明显作用。文献[11]提出结合上下文信息得到的结果更容易获得用户信任。文献[12]提出时间物品提前过滤的方法,也就是说选择与目标时间相同的评分信息当作训练集去训练推荐模型的算法。文献[13]提出结合用户行为的时间信息对于提高推荐质量有明显作用。文献[14]提出的即时推荐系统能够提供量身定制的推荐列表,充分满足用户的需求,帮助他们获得有用的信息以及大数据空间里感兴趣的资源。但以上算法主要研究了用户行为时间特性,而忽略了用户所处的空间对于推荐的影响,所以本文利用用户行为的时间特性和用户空间因素,采用结合评分时间和用户空间的方法对推荐算法进行研究。
在现实生活中,用户的兴趣会随着时间的变化而改变,用户最近的评分相比用户以前的评分更能体现用户的兴趣点。所以在进行用户相似性计算时,对用户评分进行时间衰减,将原来单一评分改为相对时间的评分来降低历史评分对推荐的影响力,相应地增加最近评分对推荐的影响力。这样用户评分的时间特性对推荐的作用得以体现。
对于空间,假设用户在这样的推荐系统中构建一个隐藏的社交网络,每两个用户之间的连接就会推断出他们的品味或者友谊,以及用户在一个空间中的分布情况。在每个用户的空间约束下,可以通过使用用户之间的距离来选择邻居,而不是通过相似性。本文把用户抽象成网络节点,用户之间的相似度作为用户之间连接的边权重,利用复杂网络拓扑布局算法[15]建立用户空间网络布局。通过用户空间布局计算所有用户之间的空间距离,根据用户空间距离选取一定数量的邻居用户,最终计算用户对未评分物品的预测评分值。
1 研究方法
1.1 协同过滤推荐算法
协同过滤推荐算法一般分为两种类型:一种是基于用户的协同推荐(UBCF),另一种是基于项目的协同推荐(IBCF)[3-4]。
UBCF算法从用户角度出发,计算用户相似度,从而确定目标用户的邻居用户,为目标用户进行项目推荐。
IBCF算法从项目角度出发,计算项目相似度,从而确定该项目的相似项目,为用户进行项目推荐。
UBCF算法主要通过以下5个步骤实现物品的推荐:
(1) 初始化用户行为信息,建立用户评分矩阵;
(2) 通过相似度公式计算用户相似度;
(3) 根据用户相似度结果,选取目标用户的邻居用户;
(4) 求出用户对物品的预测评分,生成评分预测矩阵;
(5) 根据评分预测矩阵,选择前N个项目组成推荐物品集合进行Top-N推荐。
推荐系统中用户集合为U={ui|1≤i≤m},表示有m个用户,物品集合为O={oj|1≤j≤n},表示有n个物品。用户的评分矩阵集合为R={ria}∈Rm,n,其中ria表示用户i对物品α的评分值,评分值的差异反映了用户对物品兴趣度。另外设置一个与评分矩阵集合对应的集合A={aiα}∈Rm,n,若用户i对物品α评过分,则aiα为1,否则为0。表1即为UBCF算法的用户-物品评分矩阵模型。虽然表1显示了用户对物品的行为信息,但用户行为的时间特性并没有表现出来。
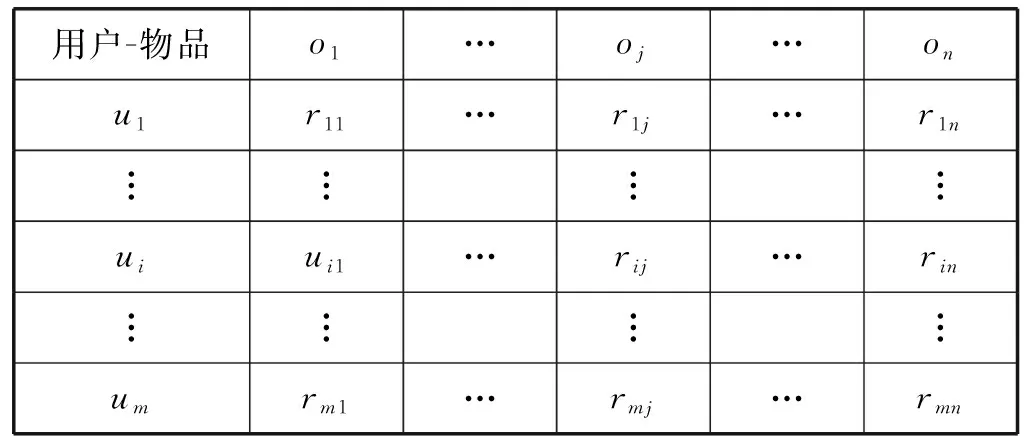
表1 用户-物品评分矩阵
UBCF算法通过用户相似度确定用户的邻居用户。本文采用基于用户的皮尔逊相似度计算公式计算用户相似度[16],公式如下:
(1)
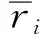
UBCF算法选择相似度最高的前m个用户作为其邻居用户,构成邻居用户集合Ti。由于已知用户相似度以及邻居用户的评分信息,利用式(2)对目标用户ui的所有未评分物品oj进行评分预测。
(2)
1.2 基于时间和空间的用户相似算法
考虑到一个包含n个节点和m条边的复杂网络G,我们认为网络G分布在一个空间区域内。其中t表示G的时间属性,而且节点代表推荐系统中的用户,边代表用户之间的连接,比如用户之间的相似性。
基于时空的推荐算法由以下规则组成:
规则1初始化用户之间的连接。
规则2初始化用户之间的位置。
规则3用户对物品的评分改变了它们的连接和位置。
规则4用户对物品的评分随着时间的变化而有一定程度的衰减。
规则5对于用户的评分预测,其对项目的评分取决于项目的平均评分和用户最近邻居的评分。
把用户集合U中所有用户抽象成网络节点,记用户节点数n,通过式(1)计算用户之间的相似度S(i,j),把用户之间的相似度作为用户节点之间连接的边权重,记用户之间的连接边为m。利用复杂网络拓扑布局算法建立用户之间的网络布局。由于数据量庞大,本文对用户网络布局中的边进行筛选,公式如下:
(3)
以k=1为例,用户空间网络布局如图1所示。

图1 k=1时用户网络布局
在用户空间网络布局中,对于每一个用户ui都会生成一个坐标(xui,yui,zui),因此,利用欧几里得距离公式可以计算出相关联用户之间的空间距离,公式如下:
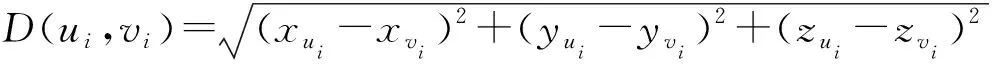
(4)
对用户空间距离升序排列,用户之间距离越小,说明用户之间相关联程度越高。取出与目标用户距离最近的前m个用户作为其邻居用户集合TDi。
例如,有10个用户,用户编号为1到10,其中用户1为目标用户,其余9个用户为用户1的相似用户,取用户1的5个邻居用户。用户相似度如表2所示。
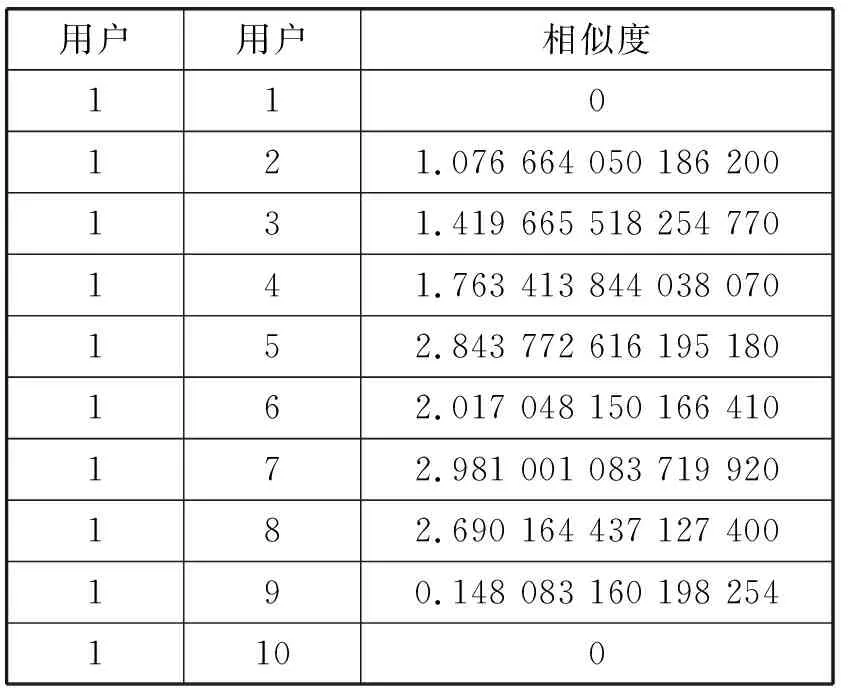
表2 用户1与其余用户相似度
本文对于邻居用户的选择是基于用户空间距离,有别于传统的基于用户相似度选取邻居用户的规则。用户1的空间布局如图2所示。
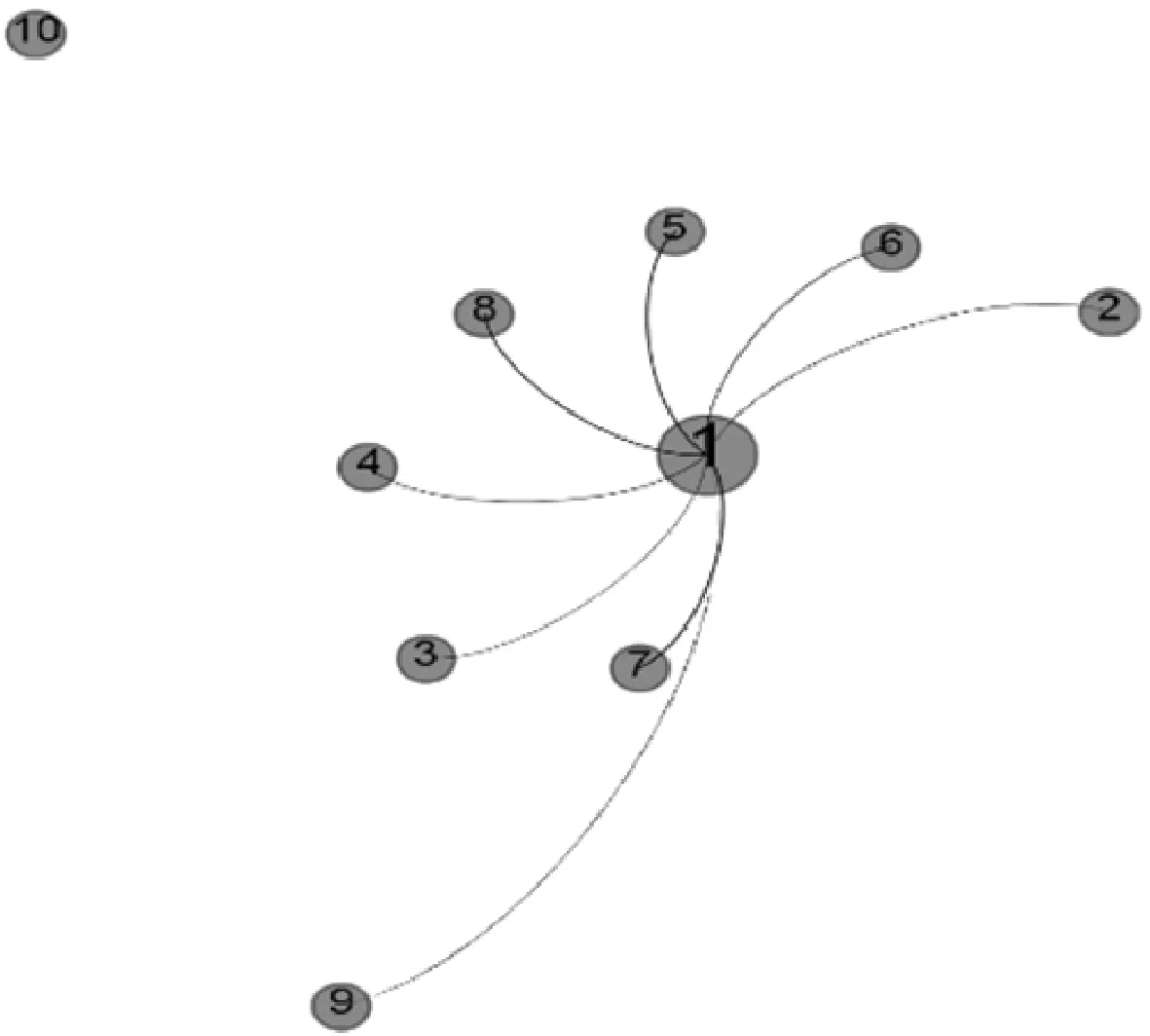
图2 用户1的空间布局
图2清晰地展示了用户1与其余用户的拓扑结构图。用户之间的空间距离也能直观地显示在图中,并且距离越近的邻居,与用户1的连边越清晰。
本文使用拓扑布局算法,为空间中每个用户生成空间坐标。利用式(4),计算用户1与其他用户的空间距离。需要说明的是,对于没有连边的用户,即使也有相应的空间坐标,但是默认与用户1的空间距离无限大。用户1与其他用户空间距离如表3所示。对表中与用户1的空间距离进行升序排序,由于取用户1的前5个邻居,故取与用户1距离最小的前5个用户,分别为7,5,8,6,4。
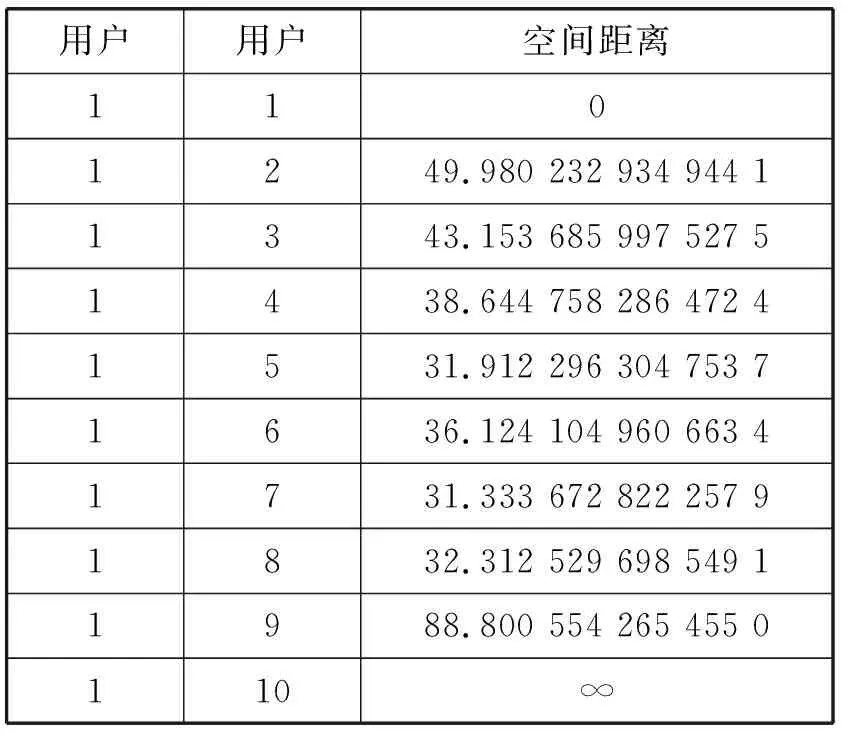
表3 用户1与其余用户的空间距离
对于用户评分的时间效应,本文引入时间衰减函数,公式如下:
(5)
式中:t为推荐时间;t(riα)为用户i对物品α的评分的时间信息;γ为时间衰减因子,取值为[0,1)之间的小数。当衰减因子γ递增时,衰减函数w(t,t(riα))呈递减趋势,当γ越大时,说明时间的影响越大,可以动态的调整γ值来优化推荐结果。当衰减因子γ=0时,公式没有衰减,即不考虑时间因素,仅考虑用户空间因素对推荐结果的影响,这种情况需要与衰减后的情况进行对比。
式(5)按照历史评分产生的时间对评分的重要性进行了衰减,生成用户-物品的衰减评分值RT(ui,oj)。
1.3 算法基本思想
根据以上描述,本文的算法思想如下:
输入:<用户(user),物品(item),用户行为(rating),时间戳(TimeStamp)>。
输出:预测评分值矩阵
步骤1根据用户对物品的评分信息建立“用户-物品-评分-时间”模型。
步骤2利用式(1)计算用户相似度S(i,j),利用复杂网络拓扑布局算法建立用户空间网络布局,并且为每一个用户生成空间坐标(xui,yui,zui)。
步骤3利用式(4)计算所有用户之间的空间距离D(ui,vi),然后选取前m个用户作为其邻居用户集合TDi。
步骤4在用户-物品-评分-时间模型中,利用式(5),计算用户-物品的衰减评分值RT(ui,oj),再利用式(1)计算评分衰减之后的用户相似度ST(i,j)。

2 实验结果及分析
2.1 实验数据
在数据集选取方面,MovieLens数据集不仅记录了943个用户对1 682部电影的100 000条评分[17],而且记录了用户行为的时间戳信息,所以可以作为实验的数据集。
实验将数据集划分为训练数据集和测试数据集,其中训练数据集占80%,测试数据集占20%。这样有利于减少偶然因素带来的不利影响,保证实验的准确性。为了检验结合评分时间和用户空间的协同过滤推荐算法(TS)的有效性,本文用基于皮尔逊用户协同过滤算法(UCF-Pearson-Opt)和基于皮尔逊物品协同过滤算法(ICF-Pearson-Opt)作为对比[18]。
在实验结果对比中,邻居个数选择从10开始,直到150,每次增加10。需要说明的是,邻居个数为5的对比结果也一并列出。
2.2 评价指标与结果及分析
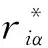
(6)
(7)
实验使用MAE值和RMSE值度量推荐算法的准确度,MAE值和RMSE值越小,说明准确度越高。
本文提出的算法中,衰减系数γ是至关重要的参数。因此,首先通过实验研究了衰减系数γ对推荐结果的影响,选取最优的衰减系数。评价指标结果如图3和图4所示。
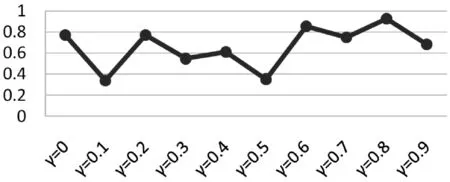
图3 算法的MAE值随着的变化
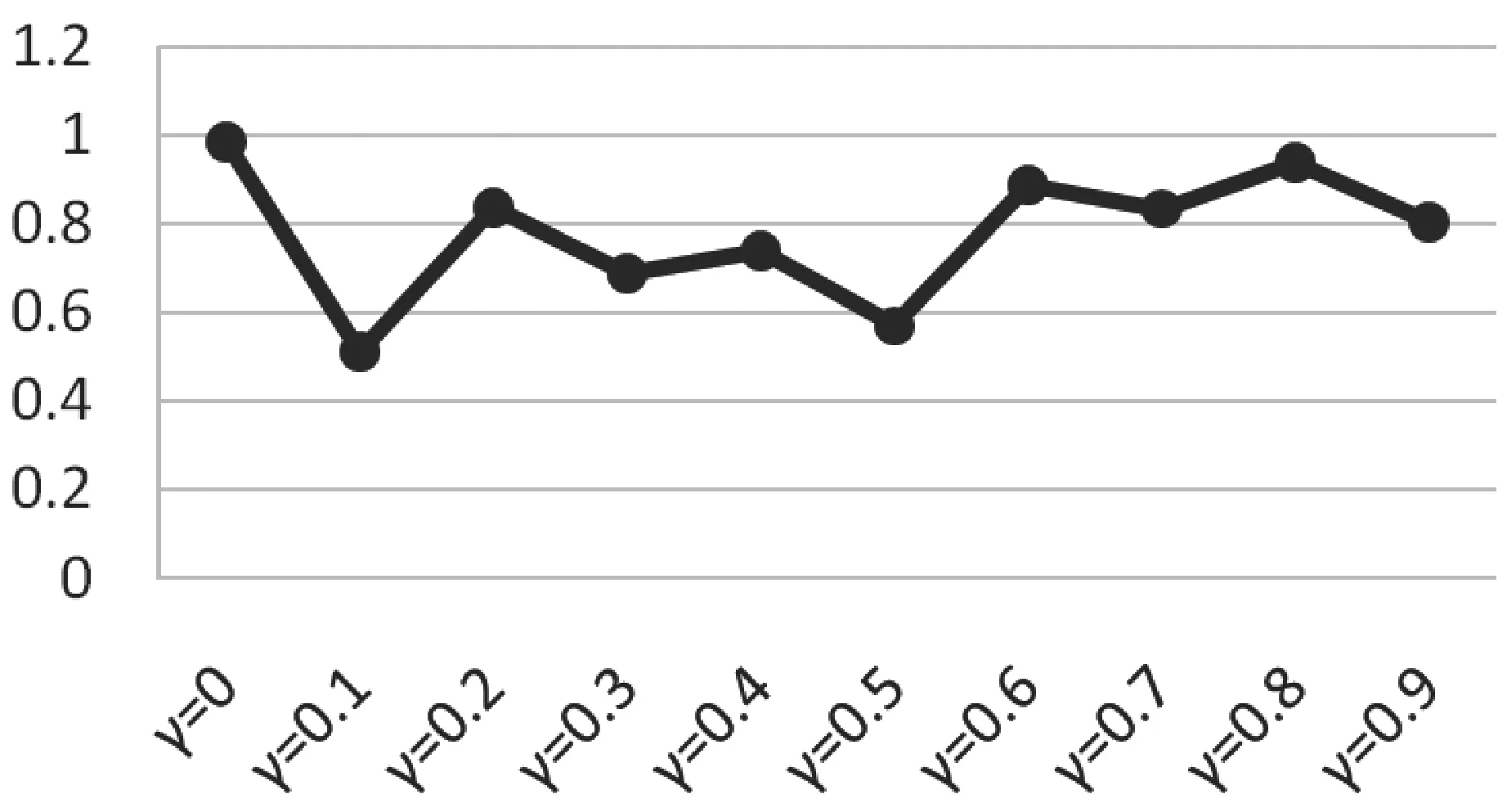
图4 算法的RMSE值随着的变化
在图3和图4中,横坐标均代表衰减因子γ,纵坐标分别代表MAE值和RMSE值。可以看出,当衰减因子从0增加到0.9时,MAE值和RMSE值波动比较大。当衰减系数γ=0.1时,MAE值和RMSE值均取最小值。
为了比较不同算法的预测效果,计算UCF-Pearson-Opt和ICF-Pearson-Opt与本文提出的TS在不同邻居数目的平均绝对误差和均方根误差。需要说明的是,当衰减系数γ=0时,即没有考虑时间因素,仅考虑在用户网络布局中,空间距离因素对于推荐算法结果的影响。结果分别如图5和图6所示。
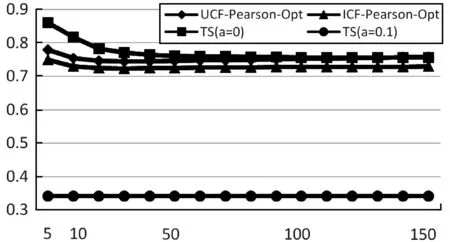
图5 三种算法的MAE值,TS为本文算法

图6 三种算法的RMSE值,TS为本文算法
在图5和图6中,横坐标均代表目标用户的邻居用户数目,纵坐标分别代表MAE值和RMSE值。可以看出,本文所使用的TS算法在衰减因子γ=0.1时效果最好,在目标用户邻居数目为5时MAE值最低,为0.340 102 736;当邻居数目为80时RMSE最低,为0.508 920 893,并且随着用户相似邻居数目的增长,曲线呈水平增长,说明TS算法的稳定性较好。
TS算法在衰减系数γ=0.1时的误差比ICF-Pearson-Opt算法更低,MAE值提高了38%,RMSE值提高了41%,说明了本文算法的有效性。当衰减因子γ时,随着邻居数目的增加,MAE值和RMSE值由远远高于UCF-Pearson-Opt和ICF-Pearson-Opt算法逐渐归为持平状态,说明在仅考虑用户空间因素方面还有待改进和优化。
3 结 语
结合三种算法的结果可知,TS算法在衰减系数γ=0时,推荐效果并不显著。当衰减系数γ=0.1时效果最好,相比ICF-Pearson-Opt算法,MAE值提高了38%,RMSE值提高了41%。综上所述,在MovieLens数据集上,通过实验证明,与传统的协同过滤算法比较,本文所用算法的准确率有显著提高,并且算法的时间复杂度较低。
