基于自动文摘的答案生成方法研究
2018-12-13黄青松刘利军冯旭鹏
胡 迁 黄青松,2 刘利军* 冯旭鹏
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(昆明理工大学云南省计算机技术应用重点实验室 云南 昆明 650500)3(昆明理工大学教育技术与网络中心 云南 昆明 650500)
0 引 言
随着自然语言处理技术的广泛应用和飞速发展,自动问答系统已然成为了自然语言处理领域的一个热点。传统的搜索引擎只能反馈给用户一系列相关文档,自动问答系统能够使用户以自然语言输入问题,并且反馈给用户一个简洁、准确的答案,而不是一系列相关文档。这表明和传统的搜索引擎相比,自动问答系统更加方便、准确。答案生成是自动问答系统中的一个非常重要的环节,其主要任务是对信息检索得到的原始文档进行处理,得到问题的原始答案集,最终通过一定算法从原始答案集中抽取出正确答案。传统的答案生成方法有:基于表层特征的答案提取,通过关系抽取答案、通过模式匹配抽取答案。自动问答中生成答案的形式主要为:以句子中关键词相似权重最高的句子作为答案,以检索文档中相关词的逻辑组合作为答案,以检索文档的摘要作为答案。孙昂等[2]提出一种基于句法分析的问句-候选答句组合特征集,并以此训练得到答案分类器完成答案抽取的方法,虽然答案抽取的准确率有所提高但得到的是经过分类的一系列候选答案。李鹏等[3]提出一种基于模式学习的形式化答案抽取方法,通过机器学习的方法自动生成用于答案抽取的形式化模板,通过问题模式和答案模式的自动匹配,直接获取答案,虽然取得了较好的答案抽取效果但是不同问题模式的匹配分布不均衡影响了其答案抽取的准确率。李超等[4]利用深度神经网络进行深层特征的提取,将答案抽取问题转化为特征学习与分类问题但是抽出的是精确的答案词,而不是答案句。
大多数浅层模型在增加输入层或隐层时容易出现过拟合现象,并且复杂函数的泛化能力变差。而深度学习作为浅层神经网络的延伸,具有较好的特征学习能力,可以较好地表征复杂函数,大大降低了计算复杂度。随着深度学习在自然语言处理上的广泛应用,近年来神经网络在自动问答系统中被深入探索并取得重大成果,例如,Mikolov等[5]使用神经网络模型得到一种名为词向量(Word Embeding)的词表示形式。Socher等[6-8]设计深度神经网络对句子建模实现了句子的向量表示。文献[9-11]在基于循环神经网络的编码-解码(RNN Encoder-Decoder)结构的机器翻译和自动文摘任务上取得了突破。基于以上的研究成果,针对自动问答答案生成的两个关键问题:如何实现答案的语义表示,如何减小实现问句答案间的语义匹配误差,本文提出了基于自动文摘的答案生成方法,该方法利用LDA(Latent Dirichlet Allocation)模型[12]计算问题文本的主题概率向量并计算问题文本间相似度。获取由与用户问题相似的知识库问题的答案构成的原始答案集后,利用循环神经网络构建基于编码-解码结构的序列到序列学习模型Seq2Seq(Sequence to Sequence)对原始答案集进行摘要生成答案句。
1 基于自动摘要的答案生成方法
本文方法主要工作包括问题之间的主题相似度计算和利用深度强化学习模型训练生成答案。任务流程如图1所示,首先将知识库中的问题文档通过文本预处理转换为文档-特征词矩阵,然后对用户问题文档进行LDA建模计算获得每篇问题文档的主题分布向量θi,基于主题分布向量计算问题文本间的相似度得出与用户问题相似主题的问题-答案对L=(Q,S),最后将这些答案顺序拼接构建成原始答案集S=(S1,S2,…,Sm)并利用Seq2Seq学习模型对原始答案集S进行摘要获得最终答案并反馈给用户。

图1 基于自动文摘的答案生成方法流程图
本文充分考虑了自动问答中用户以自然语言提出的问题句式结构复杂并且存在多种语义的特点,提出通过多个相似问题答案的组合构建原始答案集,然后抽取摘要形成最终答案的方法。相较于传统自动问答中直接用最相似问题的答案作为最终答案的方法,本文所提出的方法不仅避开了传统答案生成方法存在的单一主题偏向性问题,还提高了答案的主题覆盖率并且提高了生成答案的准确率。本文通过计算问题文本间的主题相似度查找出知识库中用户问题的相似问题集,相较于传统以特征词计算相似度,不仅减少了工作量,更提高了句子间相似度计算的准确性。
1.1 基于主题的问题相似度计算
主题模型是文本挖掘的重要工具,用来在一系列文档中发现隐含主题的一种统计模型,可以对文本进行语义挖掘。主题模型自动分析每个文档,统计文档内的单词,根据统计的信息来断定当前文档的主题信息[13]。常用的主题分析方法包括LSA(Latent Semantic Analysis)、PLSA(Probabilitistic Latent Semantic Analysis)和LDA。其中,LSA模型认为特征之间存在某种潜在的关联结构,将高维空间映射到低维的潜在语义结构上,并用该结构表示特征和对象,消除了词汇之间的相关性影响,并降低了数据维度,增强了特征的鲁棒性。但是LSA无法解决一词多义的问题,由此在LSA的基础上Hofman提出了PLSA模型。然而,PLSA中,主题分布和词分布都是唯一确定的,而LDA则不同。在LDA中,主题分布和词分布是不确定的,在LDA中主题分布和词分布使用了Dirichlet分布作为它们的共轭先验分布。针对自动问答中用户以自然语言提出的问题句式结构复杂并且存在多种语义的特点,本文采用LDA模型完成用户问题和知识库中问题文档的主题相似度计算。
LDA模型是一种非监督的文档主题生成模型,用来高效率识别大规模语料库中的主题信息。LDA模型由经验参数(α,β)确定。设θi=(T1,T2,…,TK)表示第i个问题主题的概率分布,而Tk表示该问题文本下第k个主题的概率。
利用LDA模型计算问题文本相似度过程如下:
(1) 根据Dirichlet分布Dir(α)得到m个问题文本的主题分布概率矩阵θ=(θ1,θ2,…,θm)作为m个问题文本的语义表示,每个问题的主题分布是一个服从参数为α的Dirichlet先验分布中采样得到的Multinomial分布,则根据LDA模型我们可以得到第i个文本的主题分布概率向量θi主题k的Dirichlet的分布期望Tk为:
(1)

(2) 利用余弦公式计算用户问题文档主题概率向量与知识库中问题文档主题概率向量的距离。从问答知识库中选出与用户问题最为相似的若干问题-答案集L=(Q,S),将问题-答案集L中的答案顺序取出构成原始答案集S=(S1,S2,…,Sm)作为下一步生成用户问题的答案的训练集。利用余弦公式计算问题的主题相似度的过程如下:
(2)
式中:θ1表示用户问题的主题概率向量,θ2表示知识库问题的主题概率向量。余弦值越接近于1,表明两个问题文本的主题概率向量的距离越近即问题文本的主题相似度越高。
1.2 基于自动文摘的答案生成
文中采用自动摘要的形式生成最后答案。自动摘要,从技术上来说主要分为抽取式摘要、压缩式摘要和理解式摘要。本文以问答知识库中选出的与用户问题最为相似的若干问题的答案集构成的初始答案集S=(S1,S2,…,Sm)作为原始语料,利用循环神经网络构建Seq2Seq学习模型对训练语料进行建模,形成基于多文档的抽取式答案生成方法。
近年来基于神经网络的编码-解码结构的序列到序列学习方法已经在自然语言处理任务中取得了重大成果。Paulus等[14]提出一种结合注意力机制序列到序列学习方法和深度强化学习的摘要算法,在编码时采用双向长短期记忆网络LSTM(Long Short-Term Memory),解码时采用单向LSTM并引入注意力机制,最后使用监督加强学习的方法优化输出。由于,本文的原始语料是基于原始答案S的简单拼接而成,所以存在较多冗余信息,这严重影响了生成摘要的可读性。为此,本文在上述模型的基础上进行了改进,提出在解码部分引入词频估计子模型[15-16]WFE(word-frequency estimation sub-model)在摘要生成时进行冗余剪除,得到简洁的准确答案。
本文所提出的基于自动摘要的答案生成方法是基于结合注意力机制的序列到序列学习模型。本文在编码阶段应用两层双向LSTM进行编码,在解码阶段应用一层单向的LSTM进行解码,并分别于编码解码阶段引入注意力机制防止解码阶段对编码的同一部分重复解码,使得解码器在处理长文档时不会产生重复,然后在解码器中嵌入WFE模型控制解码生成字符的频率,防止冗余生成。其解码流程图如图2所示。

图2 解码器流程图
(3)

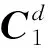
(4)
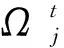
(5)
(6)

(3) 混合训练目标。

(7)
通过每次迭代产生两个独立输出序列:
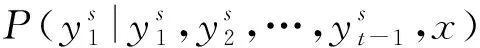

③ 定义r(y)为输出序列y的奖励函数,将其与真值序列y*相比较作为我们的评估指标。
(8)
从式(8)中可以看出,如果抽样获得比基线输出更好的奖励,最小化Lrl相当于最大化抽样序列ys的似然估计。
定义γ为Lml和Lrl大小差别的换算系数,可以得到最终的混合训练目标:
Lmixed=γLml+(1-γ)Lrl
(9)
由于,我们的最大似然函数训练目标本质上是条件语言模型,基于先前序列yt-1来预测下一个序列yt的概率,最终的优化目标使得学习算法生成更为自然的摘要作为答案反馈给用户。
2 实 验
2.1 数据准备
为了验证模型在自动问答答案生成中的效果,本文从百度知道中获取了来自文化领域12 756条、财经领域11 044条、健康领域11 200条,共计35 000条问答语料作为自动问答知识库进行训练,通过数据清洗、分词、词性标注之后进行文摘训练。
2.2 实验设计
本实验使用准确率(P)、召回率(R)和F-Measure(F)对实验结果进行分析。这里准确率采用人工标注的方式对检索到的问题相似度等级进行判定:
P=检索到相似度高的问题数/实际检索到总问题数
R=检索到与用户问题相似问题数/系统中所有相似度高文档总数
在自动文摘部分,本实验使用ROUGE[17](Recall-Oriented Understudy for Gisting Evaluation)和人工可读性评价分数作为自动文摘对比实验性能标准。
本实验计划分为4个部分:预处理;参数设置;加入词频估计子模型的深度强化学习的摘要算法与普通深度强化学习的摘要算法的性能对比实验;本文算法与传统自动问答的答案抽取算法的对比实验。
实验中预处理部分,采用中文分词工具对实验语料进行分词处理,并除去停用词,将文本表示为文本-词向量。
基于循环神经网络的编码-解码框架在自然语言处理领域有着非常广泛的应用,在本文实验中选用其作为基本框架,用双向LSTM作为编码器,单向LSTM作为解码器。
实验中参数设置部分,在自动问答中问题语句通常不会过长,因此本文在利用LDA模型对问题文本进行相似度计算中设置主题个数为9。LDA处理中设置先验超参数为α=5.55、β=0.01。在文本摘要算法部分,我们采用200维的LSTM用于双向编码,400维的LSTM用于单向解码,限制输入字符不大于150 000,输出字符不大于50 000。
2.3 实验结果及分析
在实验的第3部分,为了评价本文所提出的基于摘要的答案生成算法,我们首先构建原始答案集S,从问答语料中随机抽取400组问答语料作为测试集,对其预处理后进行LDA建模找出知识库与测试集主题相似的5组问答语料集,实验结果如表1和表2所示(以其中一条测试语料为例)。
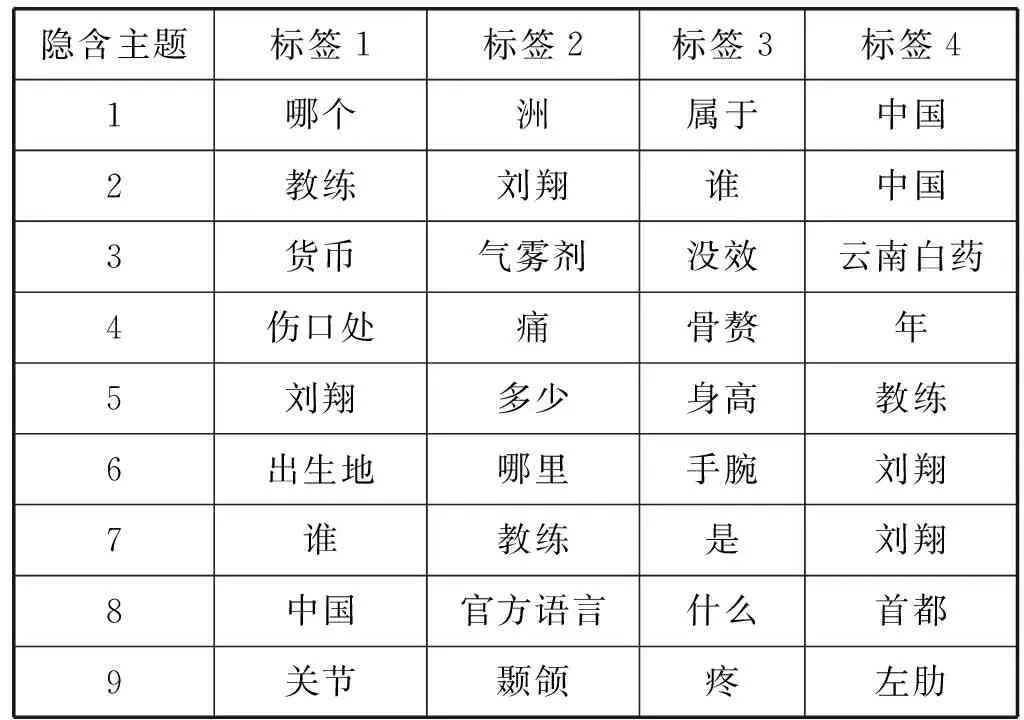
表1 隐含主题标签构成
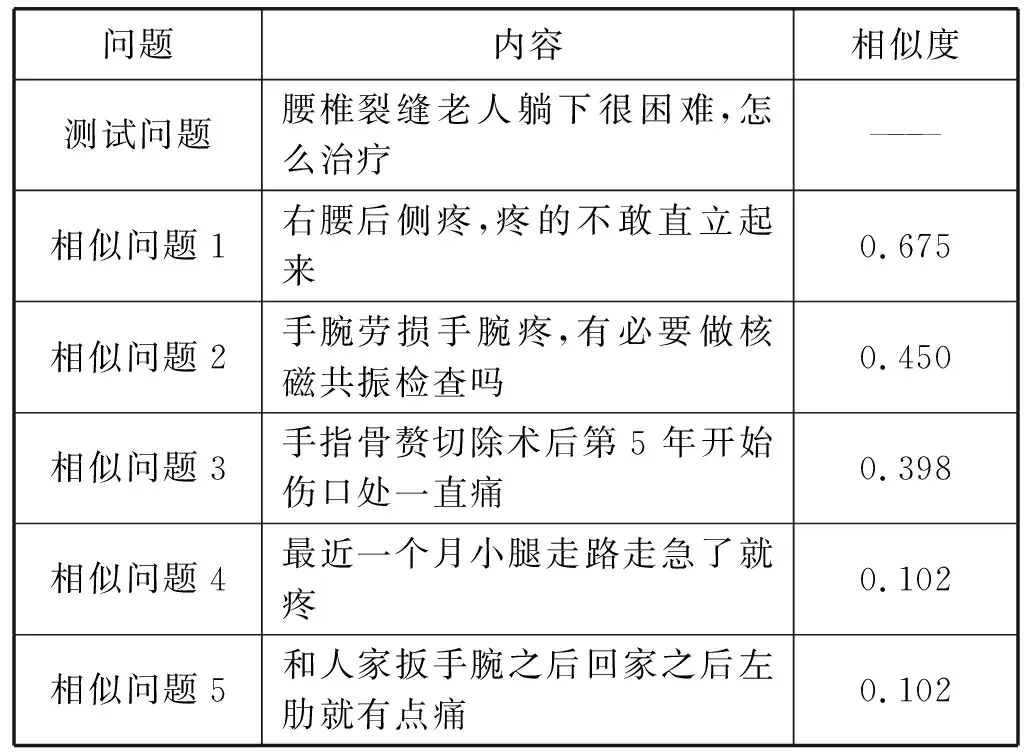
表2 与测试语料最为相似的5组问句语料
利用5个相似问题对应的答案语料进行顺序拼接构成原始答案集S=(S1,S2,S3,S4,S5),我们使用400组测试语料原始答案集的进行文摘对比实验,在对比实验中采用ROUGE中ROUGE-1、ROUGE-2、ROUGE-L的分数和人工可读性评价分数作为评价指标,并以ROUGE-L的分数作为加强奖励。实验结果如表3所示。
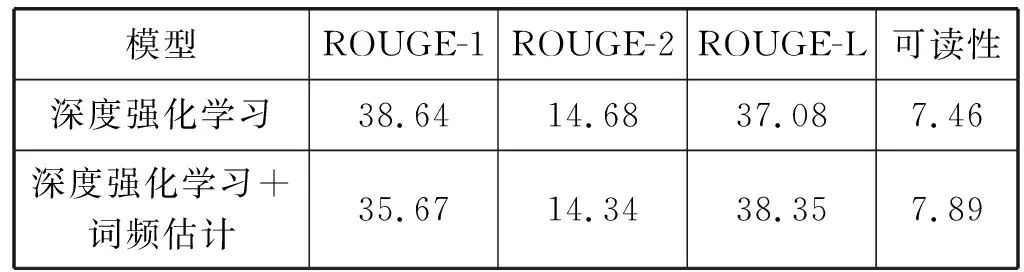
表3 文摘部分两种模型的定量结果
从表3中可看出,虽然本文提出的算法在ROUGE-1和ROUGE-2的得分比深度强化学习稍低,但是在ROUGE-L与可读性指标上得分稍高,这表明在针对原始答案集S进行摘要的问题上,本文提出的算法有着较优的表现。由于本文提出的算法在解码阶段阻止了出现频率过高字符的再次生成在一定程度上解决的原始答案集S本身存在大量冗余的问题,本文所提出的算法比单一的基于深度强化学习的摘要算法有着较优的可读性,实验与预期结果相符。
在实验的第4部分,本文分别就文化领域、财经领域和健康领域的问答语料集,以准确率(P)、召回率(R)和F-Measure为标准分别对本文所提出的答案生成方法与传统自动问答中的答案生成方法进行了对比实验。在第4部分对比试验中,本文设计了针对问答语料集,与文献[2]提出的基于句法分析和答案分类的答案抽取方法(SA-AC)、文献[3]提出的基于模式学习的形式化答案抽取技术(FAE)和文献[4]提出的句法分析和深度神经网络的答案抽取方法(SA-DNN)的对比实验。实验结果如图3-图5所示。

图3 各方法准确率对比图

图4 各方法召回率对比图
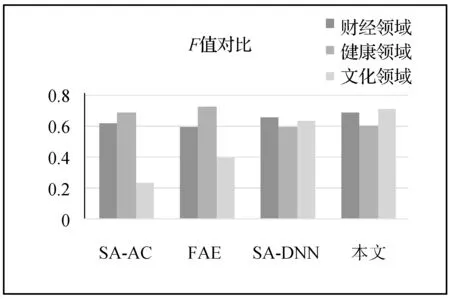
图5 各方法的F值对比图
(1) 从准确率对比图中可以看出,SA-AC、FAE、SA-DNN和本文在财经领域的准确率上的虽然差别并不大,但是本文所提出的方法有着最高的准确率。然而就健康领域看,FAE有着相对较好的效果。这是因为在健康领域的测试语料中包含较多的医学专业术语,基于模式学习的形式化答案抽取方法命名实体辨别性能较好,相反基于句法分析和神经网络的答案无法有效识别专业词汇,但是在文化领域本文所提出的方法有着最高的准确率。
(2) 从召回率对比图中可以看出,本文所提出的方法在三个领域都有着较高的召回率。本文提出以问题文本的主题概率向量作为特征完成问题间相似度计算并最终完成答案抽取的方法,相较于其他方法有着较高的主题覆盖度,所生成的最终答案也更为全面可靠。
(3) 从F值对比图中可以看出,在财经和文化领域本文所提出的方法有着最好的表现,在健康领域本文所提出的方法虽然表现较差却较SA-DNN有着较好表现。
由实验结果对比图可以看出,本文所提出的答案抽取方法在财经领域和文化领域都有着相对较高的准确率和召回率,取得了较好的结果,但是在健康领域结果较差。这是因为健康领域语料中包含了较多医学上的专业术语导致本文在提取其主题向量并生成答案时产生了比较大的误差。
综合以上实验结果可以得出,本文提出通过问题的主题向量计算问题相似度的方法相比SA-AC方法不仅减少了文本向量空间,还忽略了文本本身的结构,减小了句法分析中由于问题文本本身结构混乱语义复杂带来的误差。除此之外,本文提出通过原始答案集摘要生成答案的方法相比FAE,避免了单一模式匹配生成答案的偏向性问题,主题涵盖范围更广,并且本文以答案句作为结果相比SA-DNN的结果更具有可读性。最终可以得出结论,本文所提出答案抽取方法可以有效提高生成答案的准确度和可信度,但是在专业名词的深层语义辨析上存在一定的缺陷。
3 结 语
本文提出了一种基于自动文摘的答案生成方法。将问句文本通过分词、停词等文本预处理转换成文档-词向量矩阵,利用LDA模型对句子进行建模得出每个问句的主题概率分布向量并计算问句间的相似度。根据问答知识库中与用户问题相似的若干问题的答案构建原始答案文档集,并进行Seq2Seq学习模型训练摘要得出最终答案反馈给用户。实验表明本文的模型在自动问答答案生成的准确度上有一定程度的提高,但是本文所提出的方法在专业名词的深层语义理解上仍然存在很大的缺陷,本文后续将继续探讨基于自动问答的文本挖掘。
